Benchmark für KI-Code-Review-Tools
Mit der zunehmenden Nutzung von KI-Codierungstools sind Codebasen anfälliger für Schwachstellen geworden, was den Bedarf an effektiven Code-Reviews erhöht hat. Um dem zu begegnen, stellen wir RevEval (KI Code Review Eval) vor, das die vier führenden KI-Code-Review-Tools anhand von 309 Pull Requests aus Repositories unterschiedlicher Größe vergleicht und ihre Leistung mithilfe von Eingaben von 10 Entwicklern und einem LLM-as-a-Judge bewertet.
Benchmark-Ergebnisse
CodeRabbit wurde bei 51% der 309 Pull Requests als erfolgreichstes Code-Review-Tool eingestuft:
Zur Messung der Rangfolge verwendeten wir die LLM-as-a-Judge-Bewertungen. Wir untersuchten, welches KI-Code-Review-Tool in jedem PR die höchste Punktzahl erzielte (bewertet mit unserem LLM-as-a-Judge) und berechneten dann den prozentualen Anteil aller PRs, in denen jedes Tool den ersten Platz belegte.
CodeRabbit erzielte sowohl bei den manuellen menschlichen Bewertungen als auch bei den LLM-as-a-Judge-Bewertungen die höchsten Werte, gefolgt von Greptile und GitHub Copilot:
Bei der Berechnung der Durchschnittsbewertung wurden alle drei Bewertungskategorien gleich gewichtet. Die Bewertungen großer und kleiner Repositories wurden durch den LLM-as-a-Judge vorgenommen, und die Entwicklerbewertungen wurden manuell durchgeführt, um die LLM-as-a-Judge-Bewertungen zu überprüfen.
Menschliche Bewertungen
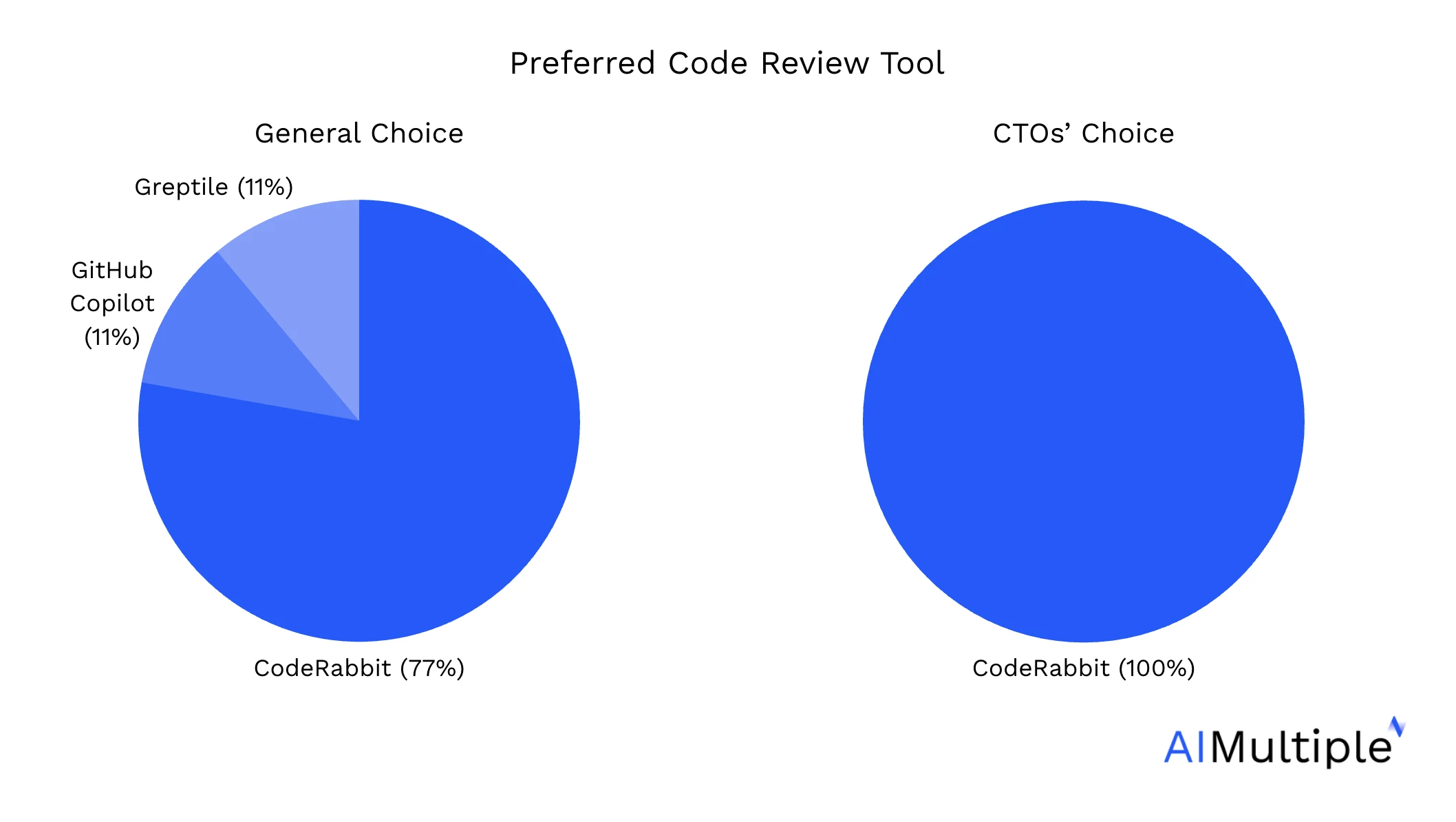
Wir fragten die an den Bewertungen beteiligten Entwickler, welches KI-Code-Review-Tool sie bevorzugt in ihre Arbeitsabläufe integrieren würden. Da CTOs eine zentrale Entscheidungsrolle in der Softwareentwicklung spielen, haben wir ihre Antworten in einem separaten Diagramm hervorgehoben:
Detaillierter Vergleich
Wir berechneten die durchschnittliche Anzahl von Bugs pro PR, indem wir alle von jedem Code-Review-Tool gemeldeten Bugs/Probleme zählten und durch die Gesamtzahl der PRs (309) teilten. Nicht alle PRs in unserer Codebasis enthalten Bugs oder Probleme. GitHub Copilot meldet nicht explizit, wenn es einen Bug in einem PR erkennt; daher wurde es von diesem Vergleich ausgeschlossen.
Unsere Methodik finden Sie unten.
Funktionen
* Wird durch CodeRabbits Funktion „Agentic Pre-Merge Checks“ bereitgestellt. Sie validiert Pull Requests automatisch anhand von Qualitätsstandards und benutzerdefinierten organisatorischen Anforderungen vor dem Merge und gibt Bestanden/Nicht-bestanden-Ergebnisse mit Erklärungen direkt im PR-Durchlauf zurück. Jede Prüfung kann so konfiguriert werden, dass sie Entwickler entweder warnt oder Merges vollständig blockiert. Während GitHub Copilot, Cursor BugBot und Greptile PR-Review-Funktionen bieten, fungieren sie als beratende Systeme, die Feedback und Vorschläge anbieten, und nicht als systematische Validierungs-Frameworks.
** Cursor und GitHub Copilot bieten möglicherweise mehr Funktionen über ihre Code-Review-Komponenten hinaus; nur die Funktionen von Cursor Bugbot und GitHub Copilot Code Review sind in unserem Vergleich enthalten.
Die Funktionen variieren je nach Abonnementplan, sodass einige der oben als verfügbar gekennzeichneten Funktionen in Ihrem Abonnement möglicherweise nicht verfügbar sind.
Bei automatisierten Code-Reviews waren CodeRabbit, GitHub Copilot und Cursor Bugbot einfacher zu konfigurieren als Greptile, da automatisierte Code-Reviews für ein leeres Repository in Greptile nicht aktiviert werden können.
Funktionsvertiefung
CodeRabbit
- 40+ integrierte Linter und Sicherheitsscanner.
- AST-pattern-basierte benutzerdefinierte Anweisungen.
- Passt sich im Laufe der Zeit an Entwicklerfeedback an.
- Entwickler können @coderabbitai taggen, um Nachfragen zu stellen, Korrekturen anzufordern oder Empfehlungen zu hinterfragen.
- Unterstützt benutzerdefinierte MCP-Server für zusätzlichen Kontext.
GitHub Copilot Code Review
- „Vorschlag umsetzen“-Schaltfläche übergibt an den Copilot-Coding-Agenten.
- Enge Integration mit dem GitHub-Ökosystem.
- Benutzerdefinierte Anweisungen über copilot-instructions.md.
Greptile
- Lernt die Codierungsstandards des Teams aus dem PR-Kommentarverlauf.
- Mit Pattern-Repos können Entwickler verwandte Repos in greptile.json referenzieren, um zusätzlichen Kontext bereitzustellen.
- Entwickler können mit @greptileai für Nachfragen oder Korrekturvorschläge antworten.
- Greptile lernt aus Daumen-hoch/Daumen-runter-Feedback.
- Sequenzdiagramme werden automatisch für alle PRs generiert.
Cursor BugBot
- Nachdem ein Bug von BugBot identifiziert wurde, können Entwickler die Schaltfläche „In Cursor beheben“ verwenden, um Cursor schnell zu öffnen und den Bug zu beheben.
- Entwickler können ihre Code-Review-Regeln in BUGBOT.md-Dateien anpassen.
Wir beabsichtigten auch, Graphite zu benchmarken; aufgrund eines Bugs in deren Dashboard konnten wir jedoch keine automatisierten Code-Reviews für neue Repositories aktivieren. Wir kontaktierten deren Support-Team am 25. Oktober 2025, aber die Antwort löste das Problem nicht. Trotz Folge-E-Mails und einer Nachricht in deren Slack-Kanal blieb das Problem ungelöst.
Komponenten und Integrationen
* Alle diese Lösungen unterstützen GitHub.
Methodik
Wir erstellten separate Benchmark-Repositories für jedes Tool innerhalb unserer dedizierten GitHub-Organisation.
Nach der Aktivierung automatischer Code-Reviews für jedes Tool in seinem zugewiesenen Repository öffneten wir Pull Requests nacheinander, warteten darauf, dass das Tool seine Überprüfung abschloss, und schlossen dann die PRs, um die Ergebnisse aufzuzeichnen. Wir haben keine Tool-Einstellungen geändert oder optimiert. Jedes Tool wurde mit seiner Standardkonfiguration bewertet, genau wie installiert.
Unser Workflow beginnt mit dem Klonen des Quell-Repositories, wie es zu einem ausgewählten Basis-Datum existierte, und dem anschließenden Wiederholen der nach diesem Datum eingereichten Pull Requests, einen nach dem anderen, wobei die ursprüngliche Repository-Struktur erhalten bleibt.
Wir verwendeten die Versionen aller Produkte vom November 2025. Unser Benchmark bestand aus 2 verschiedenen Bereichen von Quell-Repositories:
1. Bekannte, mittelgroße bis große Repositories
Wir wollten sehen, wie gut KI-Code-Review-Tools Repositories mit großen und komplexen Strukturen verstehen. Wir haben insgesamt 289 PRs über 7 Repositories hinweg überprüft.
2. Kleine und neue Repositories
Wir sind uns bewusst, dass wir unseren LLM-as-a-Judge bei großen Repositories nicht mit dem
gesamten Repository füttern können, da deren Kontextfenster dafür nicht ausreichen. Um dies zu überwinden, bewerteten wir daher auch die ersten 3-5 PRs von neuen und kleinen Repositories. MCP-Server passten perfekt zu unseren Anforderungen. Folglich wählten wir 8 offizielle MCP-Server aus und ließen 20 PRs darauf überprüfen.
Unser Dataset enthält Code, der von erfahrenen Entwicklern geschrieben wurde. Wir haben die Leistung bei vollständig KI-generierten Codebasen nicht bewertet.
Entwicklerbewertungen
Wir wählten zufällig 35 PRs aus und wiesen sie 10 Entwicklern zu, wobei jeder PR 5-mal von Entwicklern bewertet wurde. Unser Ziel bei der Wiederholung der Bewertung war es, die Voreingenommenheit der Entwickler zu minimieren. Die Entwickler bewerteten die Ergebnisse auf anbieterneutrale Weise.
Die meisten von ihnen kamen zu denselben übergeordneten Erkenntnissen:
- Die detaillierten Reviews von CodeRabbit sind hilfreich und es ist erfolgreich bei der Bug-Erkennung.
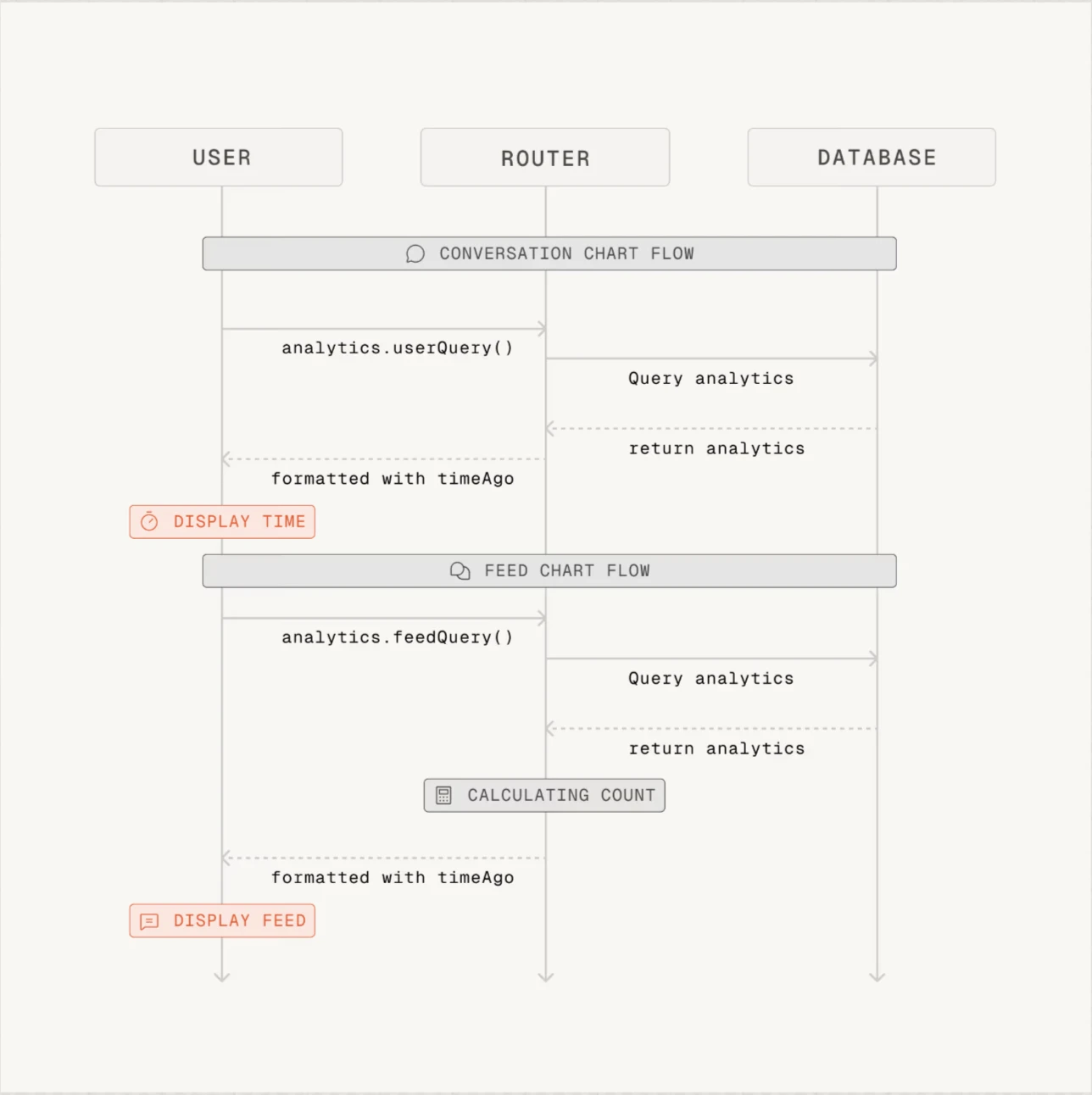
- Greptile lieferte erfolgreiche Zusammenfassungen, aber die generierten Sequenzdiagramme sind für einige PRs nicht notwendig.
Abbildung 1: Beispiel für ein von Greptile bereitgestelltes Sequenzdiagramm. Greptile generiert die Diagramme für jeden PR.1
- GitHub Copilot ist sehr erfolgreich beim Finden von Tippfehlern im Code und macht treffsichere Vorschläge; seine Analyse ist kürzer als die von CodeRabbit und Greptile.
- Cursor Bugbot liefert weniger detaillierte und weniger genaue Analysen.
Nach den Bewertungen gaben sie auch an, dass sie beginnen werden, sie in ihren eigenen Repositories als Unterstützungstool für Entwickler einzusetzen.
LLM-as-a-Judge
Wir verwendeten GPT-5, um die Reviews zu bewerten. Nach der Bewertung verwendeten wir GPT-4o, um die Ausgabe im JSON-Format zu strukturieren.
Unser Bewertungs-Workflow umfasst:
- Für große Repositories: Den ursprünglichen PR-Body, Diff und Kommentare/Reviews der Tools.
- Für kleine Repositories: Die gesamte Codebasis, den ursprünglichen PR-Body, Diff und Kommentare/Reviews der Tools.
Hier ist der vollständige Prompt, den wir verwendet haben:
Bewerten Sie jedes Tool anhand dieser Dimensionen (Skala 1-5):
1. Korrektheit
Sind die identifizierten Probleme tatsächlich echte Probleme/Bugs/Korrekturen im Code?
– 5 (Hervorragend): Alle identifizierten Probleme sind echte Probleme
– 4 (Gut): Die meisten Probleme sind echt, geringfügige Fehlidentifikationen
– 3 (Akzeptabel): Mischung aus echten und fragwürdigen Problemen
– 2 (Schlecht): Die meisten identifizierten Probleme sind keine tatsächlichen Probleme
– 1 (Gescheitert): Kann keine echten Probleme identifizieren, alle Ergebnisse sind falsch
2. Vollständigkeit
Wurden wichtige Probleme erkannt? Wie umfassend ist das Review?
– 5 (Hervorragend): Erfasst alle kritischen Probleme und die meisten wichtigen.
– 4 (Gut): Erfasst die Hauptprobleme, übersieht einige kleinere
– 3 (Akzeptabel): Erfasst einige wichtige Probleme, hat aber nennenswerte Lücken
– 2 (Schlecht): Übersieht mehrere kritische Probleme
– 1 (Gescheitert): Übersieht alle oder fast alle kritischen Probleme
3. Umsetzbarkeit
Sind die Vorschläge klar und umsetzbar? Enthält es Patches/Korrekturen? Wenn keine Bugs im Code sind, schreiben Sie „null“ zur Umsetzbarkeit für alle Tools, vergeben Sie keine Punktzahlen für diesen PR.
– 5 (Hervorragend): Alle Vorschläge enthalten klare Patches/Korrekturen und sind direkt umsetzbar
– 4 (Gut): Die meisten Vorschläge haben klare Anleitung, einige enthalten Patches
– 3 (Akzeptabel): Vorschläge sind einigermaßen klar, aber es fehlen Patches für einige Probleme
– 2 (Schlecht): Vorschläge sind meist unklar oder nicht umsetzbar
– 1 (Gescheitert): Keine klaren Vorschläge oder Anleitung bereitgestellt
4. Tiefe
Zeigt es Verständnis für die Logik und den Zweck des Codes?
– 5 (Hervorragend): Zeigt tiefes Verständnis für Codelogik, Architektur und Zweck
– 4 (Gut): Zeigt gutes Verständnis mit geringfügigen Lücken
– 3 (Akzeptabel): Oberflächliches Verständnis, verpasst etwas Kontext
– 2 (Schlecht): Oberflächliche oder falsche Erklärungen des Code-Verhaltens
– 1 (Gescheitert): Kein Verständnis für die Logik und den Zweck des Codes
Ausgabeformat
Für jedes Tool, geben Sie an:
1. Detaillierte Begründung: Was hat es gefunden? Hat es wichtige Probleme übersehen? Patches enthalten? Tiefes Verständnis der Codebasis? Konkrete Beispiele.
2. Einzelbewertungen (1-5 für jede Dimension, unter Verwendung der obigen Skalierung)
Beispielausgabe
Tool A:
Begründung: Tool A zeigte hervorragende Korrektheit, indem es ein echtes Speicherleck in der Connection-Pooling-Logik in Zeile 145 identifizierte und einen spezifischen Patch unter Verwendung eines Context-Managers bereitstellte. Es erkannte auch die fehlende Fehlerbehandlung im API-Endpunkt mit umsetzbarem Code. Die Vollständigkeitsbewertung spiegelt wider, dass es zwar die Hauptprobleme fand, aber die Race Condition im Async-Handler übersah, die Produktionsprobleme verursachen könnte. Alle 4 Kommentare waren substanziell und direkt umsetzbar. Die Tiefe war stark und zeigte ein Verständnis für die Ressourcenmanagement-Muster und Fehlerweitergabe in der Codebasis.
Korrektheit: 5
Vollständigkeit: 4
Umsetzbarkeit: 5
Tiefe: 4
Tool B:
Begründung: Tool B identifizierte korrekt die Input-Validation-Schwachstelle in Zeile 89 und lieferte eine klare Korrektur unter Verwendung von Parameter-Sanitization. Die Vollständigkeit litt jedoch erheblich, da es die kritische Sicherheitslücke im Authentifizierungsablauf übersah, die Token-Wiederverwendung ermöglicht. Die Umsetzbarkeit war größtenteils gut – Vorschläge enthielten Code-Snippets. Die Tiefe war akzeptabel, aber oberflächlich und konzentrierte sich auf oberflächliche Prüfungen statt auf das Verständnis des Sicherheitsmodells oder der Datenflussimplikationen.
Korrektheit: 4
Vollständigkeit: 1
Umsetzbarkeit: 4
Tiefe: 2
Zu bewertende Tools: CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Seien Sie objektiv und gründlich. Verwenden Sie konkrete Beispiele aus den Reviews, um Ihre Bewertungen zu untermauern.
Was ist KI-Code-Review?
KI-Code-Review ist die automatisierte Analyse von Quellcode mithilfe von Machine-Learning-Modellen, vor allem Large Language Models (LLMs), um Bugs, Ineffizienzen und potenzielle Schwachstellen zu identifizieren. Zusätzlich zur Erkennung von Problemen können diese Systeme kontextbezogene Erklärungen liefern, konkrete Korrekturen vorschlagen und Patches generieren, die Entwicklern helfen, sowohl die Codequalität als auch die Wartbarkeit zu verbessern. Viele KI-Review-Tools unterstützen auch die Dokumentation, indem sie Änderungen zusammenfassen und beschreibende Kommentare oder Erklärungen für neu hinzugefügten Code erstellen.
Da KI-Modelle Code schnell und in großem Umfang bewerten können, beschleunigen sie den Review-Prozess erheblich und erleichtern es, Probleme frühzeitig zu erkennen und gleichzeitig konsistente Codierungsstandards in großen oder schnelllebigen Projekten aufrechtzuerhalten.
In modernen KI-gestützten Entwicklungsumgebungen wie Cursor oder Claude Code können Entwickler unbeabsichtigt den Überblick darüber verlieren, wie sich ihre Codebasis entwickelt, wenn sie „Vibe Coding“ betreiben oder sich stark auf automatisch generierte Vorschläge verlassen. Dies kann versteckte Schwachstellen oder logische Inkonsistenzen einführen. KI-Code-Review-Tools helfen, diese Risiken zu mindern, indem sie eine zusätzliche Ebene strukturierter und systematischer Analyse zur Validierung und Verbesserung von KI-generiertem Code bieten.
Vorteile von KI-Code-Review
Effizienz und Geschwindigkeit
KI-Code-Review-Tools können Code in Echtzeit analysieren und sofortiges Feedback geben sowie potenzielle Probleme während der Arbeit der Entwickler kennzeichnen. Sie sind in der Lage, Fehler und Sicherheitslücken zu erkennen, die menschliche Prüfer möglicherweise übersehen, insbesondere in großen oder sich schnell entwickelnden Codebasen. Durch die Automatisierung von Routineprüfungen ermöglichen diese Tools den Entwicklern, sich auf übergeordnetes Denken, komplexe Problemlösungen und architektonische Entscheidungen zu konzentrieren.
Verbesserte Codequalität
KI-Code-Review-Tools helfen, konsistente Codierungsstandards über Teams hinweg aufrechtzuerhalten, indem sie stilistische Inkonsistenzen und Abweichungen von Best Practices identifizieren. Sie bieten auch detailliertes Feedback und Empfehlungen zu einer Vielzahl von Codierungsproblemen, von kleineren Verbesserungen bis hin zu erheblichen Bugs. Im Laufe der Zeit können Entwickler aus diesem Feedback lernen, ihre Codierungsgewohnheiten verfeinern und neue Techniken übernehmen, die Gesamtqualität ihrer Arbeit stärken.
Einschränkungen und Herausforderungen
Übermäßige Abhängigkeit von KI-Tools
Ein häufiges Problem bei KI-Code-Review ist die übermäßige Abhängigkeit von automatisiertem Feedback. Obwohl KI eine wertvolle Erkenntnisquelle sein kann, sollte sie nicht als vollständiger Ersatz für menschliche Expertise betrachtet werden. Automatisierte Reviews können Arbeitsabläufe beschleunigen, aber menschliche Prüfer bleiben unerlässlich, um Korrektheit, Kontextbewusstsein und Ausrichtung an den Projektzielen sicherzustellen. In unserem Benchmark gaben die Entwickler übereinstimmend an, dass sie sich nicht blind auf diese Tools verlassen würden. Sie betrachteten sie als Assistenten, die das menschliche Urteilsvermögen ergänzen und nicht ersetzen.
Umgang mit False Positives und False Negatives
False Positives treten auf, wenn das Tool funktionierenden Code fälschlicherweise als problematisch identifiziert, während False Negatives auftreten, wenn echte Probleme übersehen werden. In unserer Bewertung war das größte Problem die False Negatives. Die Tools übersahen eher wichtige Probleme, als dass sie falsche Warnungen ausgaben. Dies unterstreicht die Notwendigkeit kontinuierlicher Verbesserungen der zugrunde liegenden Modelle und Algorithmen.
Um diese Herausforderungen zu bewältigen, müssen sich KI-Code-Review-Tools durch besseres Training, verbesserte Kontextverarbeitung und präzisere Argumentationsfähigkeiten weiterentwickeln.
Best Practices für den Einsatz von KI-Code-Reviews
Tipps von Experten
KI-Reviews mit menschlichen Erkenntnissen kombinieren: Nutzen Sie KI-Code-Reviews neben menschlichen Reviews, um sicherzustellen, dass der Code sowohl technisch einwandfrei ist als auch mit den Projektzielen übereinstimmt.
Regeln an Ihr Projekt anpassen: Passen Sie die Regeln des KI-Tools an die Codierungsstandards Ihres Projekts an, um unnötige Warnungen zu reduzieren.
KI-Feedback als Lernwerkzeug nutzen: Betrachten Sie KI-Vorschläge als Möglichkeit zum Lernen und zur Verbesserung, indem Sie mit Ihrem Team besprechen, um zu verstehen, warum und wie ähnliche Probleme in Zukunft vermieden werden können.
Danksagungen
Wir sprechen den Entwicklern, die ihre Zeit und Expertise für die manuellen Bewertungen zur Verfügung gestellt haben, unseren aufrichtigen Dank aus:
Aziz Durmaz (CTO bei einem Transport- und Logistikunternehmen)
Berk Kalelioğlu (Mitgründer eines Spielentwicklungsstudios)
Elif Ece Örnek (Softwareentwicklerin bei einer Reise-Website)
Haydar Külekçi (Berater bei einem Suchtechnologie- & KI-Unternehmen)
Mehmet Şirin Can (Entwicklungsleiter bei AIMultiple)
Mehmet Korkmaz (CTO bei einem Medienunternehmen in der E-Sport- und Videospielbranche)
Murat Orno (ehemaliger CTO bei einer regionalen Zahlungsplattform mit 500+ Mitarbeitern)
Orçun Candan (Full-Stack-Entwickler bei AIMultiple)
Yalçın Börlü (Senior Software Engineer bei einem Gesundheits- und Wellness-Unternehmen)
Yiğit Dinç (Mitgründer eines Legal-Tech-Unternehmens)
Wir danken auch den Entwicklern und Maintainern der in unserem Benchmark enthaltenen Open-Source-Repositories für ihre Arbeit und wertvollen Beiträge zur Community.
Anonymisierung der ursprünglichen Entwickleridentitäten
Um den Benchmark verantwortungsvoll durchzuführen, anonymisierten wir alle ursprünglichen Entwicklernamen und E-Mail-Adressen bei der Wiederholung von Pull Requests aus Upstream-Repositories. Da die Benchmark-Repositories öffentlich sind, könnte die Beibehaltung der ursprünglichen Autoreninformationen unbeabsichtigt personenbezogene Daten offenlegen und das Risiko bergen, Entwickler jedes Mal zu benachrichtigen, wenn ein nachgestellter Pull Request geöffnet oder aktualisiert wird. Obwohl GitHub Autoren normalerweise nicht benachrichtigt, wenn ihre Commits in einem separaten Repository wiederholt werden, hielten wir es für Best Practice, jegliche Möglichkeit unerwünschter Benachrichtigungen, Zuschreibungsprobleme oder Datenschutzbedenken zu vermeiden.
Die Anonymisierung stellt sicher, dass:
- Entwickler nicht durch Tausende automatisierter PR-Ereignisse gestört werden.
- Personenbezogene Daten nicht in einem anderen öffentlichen Repository erneut veröffentlicht werden.
- Benchmarks unvoreingenommen bleiben und verhindern, dass Tools oder LLM-Bewerter durch erkennbare Autorennamen beeinflusst werden.
- Ethische und Datenschutzstandards bei der Arbeit mit Open-Source-Beiträgen eingehalten werden.
Nur Identitätsmetadaten wurden geändert; sämtlicher Code, Diffs, Commit-Reihenfolge und Dateistrukturen wurden exakt beibehalten, um die Authentizität und Reproduzierbarkeit des Benchmarks zu gewährleisten.
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Benchmark für KI-Code-Review-Tools}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Abgerufen am 13. März 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.