KI-Agenten mit zusammensetzbaren Mustern erstellen
Wir haben 3 Tage damit verbracht, mit Workflows und Agent-Pipelines in n8n zu experimentieren und folgten dabei den Anleitungen von Anthropic und OpenAI zur Erstellung effektiver KI-Agenten.1 2
Erkunden Sie die wichtigsten KI-Agenten-Komponenten, wie Sie die richtigen Komponenten und Tools auswählen, zusätzlich zur Erstellung von Agenten-Workflows, die auf den einfachen, zusammensetzbaren Mustern von Anthropic basieren, wie z. B. Prompt-Verkettung, Routing, Parallelisierung, Orchestrator-Worker und Evaluator-Optimierer:
Komponenten von KI-Agenten verstehen
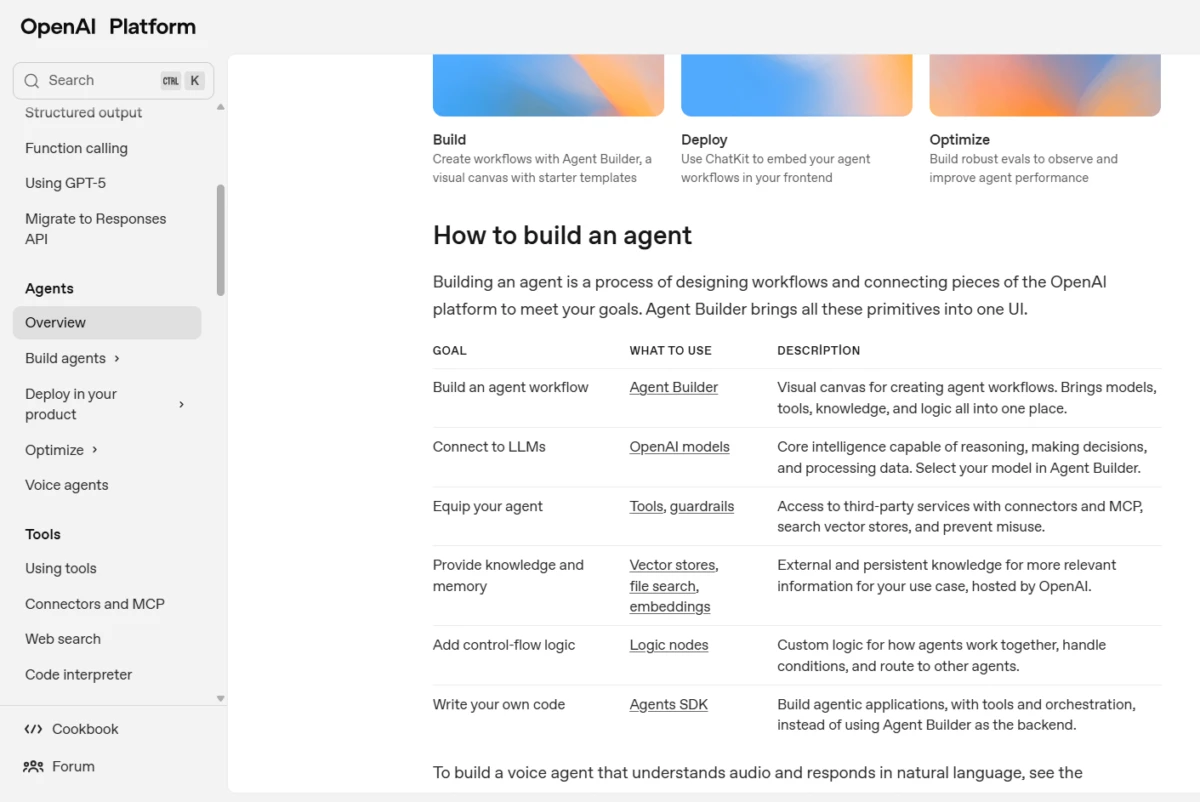
Die Erstellung von Agenten beinhaltet die Verbindung von Komponenten aus mehreren Bereichen wie Modelle, Tools, Wissen und Speicher, Guardrails. OpenAI bietet für jede zusammensetzbare Grundelemente:
Quelle: OpenAI3
Natürlich führt OpenAI dort zuerst seine eigenen Angebote auf, aber es gibt ein breites Ökosystem an Alternativen. Abhängig von Ihrem Anwendungsfall können Sie Agenten erstellen mit Frameworks wie LangChain, LlamaIndex, CrewAI oder sogar benutzerdefinierten Orchestrierungsschichten.
Ich werde näher auf jede dieser Komponenten eingehen:
Modelle
Zunächst haben Sie die Modell-Komponente. Dies sind Ihre KI-Modelle, Ihre großen Sprachmodelle, die Kernintelligenz darstellen, die in der Lage ist, zu argumentieren, Entscheidungen zu treffen und verschiedene Modalitäten zu verarbeiten. Die eigenen Beispiele von OpenAI verweisen auf seine Modelle der GPT-5-Serie.
Je nach spezifischem Agententyp, den Sie erstellen, möchten Sie ein anderes Modell innerhalb des OpenAI-Ökosystems wählen. GPT-5.5 ist das aktuelle Flaggschiff-Modell von OpenAI. Es plant mehrstufige Aufgaben, verwendet Tools, überprüft seine eigene Arbeit und macht weiter, bis eine Aufgabe erledigt ist. Für alltägliche Fragen antworten die leichteren GPT-5.5-Modi schneller und kostengünstiger.
Außerhalb des OpenAI-Ökosystems ist Claude Opus 4.7 eine häufige Wahl für umfangreiche Programmier-, Argumentations- und MINT-Aufgaben. Googles Gemini 3.1 Pro konkurriert eng, mit einem Kontextfenster von 1 Million Token für große Codebasen und lange Dokumente.
Speziell für Coding-Agenten ist GPT-5.3-Codex von OpenAI das leistungsfähigste Programmiermodell. Es führt lange Aufgaben aus, die Recherche, Tool-Nutzung und Ausführung kombinieren, und Sie können es während der Arbeit steuern. Es führt benchmarks wie SWE-Bench Pro und Terminal-Bench 2.0 an, die reale Softwareentwicklung und Befehlszeilenarbeit testen.
Wir haben die besten KI-Modelle bewertet und verglichen, um Ihnen zu helfen zu verstehen, wie jedes in Bezug auf Argumentation, Geschwindigkeit und Kosten abschneidet, damit Sie das auswählen können, das am besten zu Ihren Zielen passt.
Tools
Als Nächstes kommen die Tools, die Fähigkeiten des Modells erweitern, z. B. indem sie es befähigen, das Web zu durchsuchen oder mit anderen Systemen zu interagieren.
Fast jede App kann zu einem Tool für Ihre KI werden. Sie können sie mit Gmail, Kalender, Ihrer Drive oder Apps wie Slack, Discord, YouTube, Salesforce und Zapier verbinden. Sie können sogar eigene benutzerdefinierte Tools erstellen.
Mit dem OpenAI Agents SDK (das etwas Programmierkenntnisse erfordert) können Sie Tools definieren oder integrierte Tools wie Websuche, Dateisuche und Computernutzung verwenden.4
MCP (Model Context Protocol) von Anthropic vereinfacht ebenfalls die Tool-Integration, indem es standardisiert, wie Modelle darauf zugreifen. Im Jahr 2026 entsteht der geschäftliche Mehrwert zunehmend aus „digitalen Montagelinien“, menschengeführten, mehrstufigen Workflows, bei denen mehrere Agenten End-to-End-Prozesse ausführen, ermöglicht durch das Model Context Protocol (MCP).
Wenn Sie nicht programmieren möchten, können Sie mit No-Code-Plattformen wie n8n Tools per Drag & Drop mit Ihrem Modell verknüpfen.
Wissen und Speicher
Es gibt zwei Haupttypen von Speicher: Wissensdatenbank (statischer Speicher) und persistenter Speicher.
- Wissensdatenbank gibt Ihrer KI Zugriff auf statische Fakten, Richtlinien und Dokumente, die relativ unverändert bleiben. Dies ist unerlässlich für Agenten, die richtlinienbasierte oder unternehmensspezifische Aufgaben ausführen, bei denen Referenzmaterialien konsistent bleiben müssen.
- Persistenter Speicher ermöglicht es der KI, sich über Sitzungen hinweg an vergangene Interaktionen zu erinnern. Dies ist entscheidend für Chatbots oder persönliche Assistenten, die sich an frühere Gespräche erinnern müssen.
OpenAI bietet gehostete Dienste wie Vektorspeicher, Dateisuche und Embeddings zur Speicherverwaltung an.
Wenn Sie Open-Source-Lösungen bevorzugen, sind Pinecone (Cloud-nativ und für die Vektorsuche optimiert) und Weaviate beliebte Optionen.
Für diejenigen, die No-Code-Tools verwenden, ist die Speicherverwaltung normalerweise in Plattformen wie n8n und Creatio integriert.
Guardrails
Guardrails stellen sicher, dass sich Ihr Agent wie beabsichtigt verhält und irrelevante, schädliche oder unangemessene Antworten vermeidet. Ein Kundenservice-Bot sollte sich beispielsweise auf servicebezogene Themen konzentrieren und nicht in unzusammenhängende Themen abgleiten.
Außerhalb des Ökosystems von OpenAI gehören zu den beliebten Tools Guardrails KI und LangChain Guardrails. Viele No-Code-Plattformen verfügen über integrierte Guardrail-Funktionen, aber es ist dennoch wichtig zu verstehen, wie sie funktionieren, um Kontrolle und Compliance bei Ihren Agenten zu gewährleisten.
Skills
Tools ermöglichen einem Agenten, in die Außenwelt einzugreifen. Skills lehren den Agenten, wie er eine bestimmte Aufgabe gut erledigt.
Ein Skill ist ein kleiner Ordner mit Anweisungen und Dateien. Er enthält die Schritte, Regeln und Beispiele für eine Aufgabe, wie das Ausfüllen einer Berichtsvorlage oder das Befolgen des Styleguides eines Unternehmens. Der Agent lädt einen Skill, wenn die Aufgabe es erfordert, sodass er das Kontextfenster nicht überfüllt.
Anthropic führte Agent Skills Ende 2025 ein und öffnete das Format im März 2026 als gemeinsamen Standard.5 Skills funktionieren über Claude.ai, Claude Code und die API hinweg. Der Hauptvorteil ist Konsistenz: Anstatt jedes Mal denselben langen Prompt neu zu schreiben, definiert ein Team einen Skill einmal und verwendet ihn wieder. Dies ist in der Produktion wichtig, wo ad-hoc Prompting dazu neigt, abzuweichen.
Wie sich Skills von den anderen Komponenten unterscheiden:
- Tools verbinden den Agenten mit externen Systemen (E-Mail, Datenbanken, Suche).
- Wissen und Speicher geben dem Agenten Fakten zum Lesen.
- Skills geben dem Agenten eine wiederholbare Methode für eine Aufgabe.
Orchestrierung
Die letzte Komponente ist die Orchestrierung. Dabei geht es um die Verwaltung, wie mehrere Sub-Agenten zusammenarbeiten, sie in der Produktion einzusetzen und ihre Leistung zu überwachen.
Einmal eingesetzt, benötigen Agenten eine kontinuierliche Überwachung. Modelle, Daten und Verhaltensweisen ändern sich, daher benötigen Agenten regelmäßige Updates.
Mehrere Plattformen und Frameworks unterstützen die Orchestrierung, wie zum Beispiel:
- Low-Code-/No-Code-Plattformen:
- Stack AI
- Microsoft Copilot Studio Agent Builder
- Relevance KI, etc.
- Open-Source-Frameworks:
- LangGraph (Teil von LangChain): modelliert einen Agenten als Graphen von Schritten, mit expliziter Kontrolle über Verzweigungen, Wiederholungen und menschliche Eingriffe.
- CrewAI: organisiert Agenten als „Crew“ von Rollen, wie z. B. Forscher, Autor und Prüfer. Es ist schnell prototypisiert, wenn sich die Arbeit in klare Rollen aufteilt.
- LlamaIndex: am stärksten für Agenten, die Dokumente und interne Wissensdatenbanken durchsuchen.
- Anbieter-SDKs: Das OpenAI Agents SDK und das Anthropic Claude Agent SDK sind offizielle Toolkits zur Erstellung von Agenten auf den Modellen der jeweiligen Anbieter. Das Claude Agent SDK ist dieselbe Architektur, die Claude Code antreibt.
Bausteine der Automatisierung: Workflows vs. Agenten
Ein KI-Agent ist ein System, das seine Umgebung wahrnimmt, Informationen verarbeitet und autonom Maßnahmen ergreift, um bestimmte Ziele zu erreichen, wie z. B. Coding-Agenten wie Cursor oder Windsurf, KI-gestützte Code-Editoren mit „Agentenmodi“, die autonom Programmieraufgaben mit Modellen wie Claude Opus 4.7 ausführen können. Ein weiteres häufiges Beispiel sind Kundenservice-Agenten, die viele Unternehmen zur Bearbeitung von Anfragen einsetzen.
Es gibt viele verschiedene Möglichkeiten, diese Agenten zu entwerfen und einzusetzen, abhängig von der Komplexität des Workflows und dem erforderlichen Grad an Autonomie.
Zur kurzen Vorschau: Ein KI-Agent ist oft eine Sammlung von Sub-Agenten, die jeweils bestimmte Aufgaben ausführen. Zusammen koordinieren sich diese Sub-Agenten innerhalb von Multi-Agenten-Systemen, um das zu liefern, was wir als einen einzigen KI-Agenten wahrnehmen.
Diese unterscheiden sich grundlegend von Workflows. Workflows sind orchestrierte Sequenzen vordefinierter Schritte, wie ein Rezept, das immer der gleichen Reihenfolge folgt:
Wann man KI-Agenten einsetzt
Vor den Workflow-Beispielen folgt hier ein kurzer Realitätscheck. Agenten sind nicht immer die Antwort. Viele Teams erzielen weiterhin gute Ergebnisse mit einfachen Workflows, selbst bei Aufgaben, bei denen ein Agent theoretisch funktionieren könnte. Viele Teams stellen weiterhin fest, dass traditionelle Workflows gut funktionieren, selbst in Szenarien, in denen Agenten theoretisch angewendet werden könnten.
Eine der klarsten Arten, darüber nachzudenken, wird im Blog von Anthropic wie folgt beschrieben:
Dennoch gibt es reale Situationen, in denen Agenten traditionelle Workflows bei Aufgaben übertreffen, die Flexibilität, Argumentationsfähigkeit und Anpassungsfähigkeit erfordern:
Dynamische Gespräche, die Anpassungen erfordern:
Einige Interaktionen, wie einfache Rückerstattungs- oder Passwort-Zurücksetzungs-Anfragen, passen genau in Workflows. Andere erfordern jedoch ein nuanciertes Urteilsvermögen oder kontextabhängige Entscheidungen, wie z. B. personalisierte Empfehlungen, die stark vom Kontext und hin- und hergehenden Überlegungen abhängen.
Entscheidungsfindung mit hohem Wert bei geringem Volumen:
Agenten können teuer im Betrieb sein, aber in einigen Fällen sind die Entscheidungen, die sie unterstützen, weitaus kostspieliger, wenn sie falsch getroffen werden.
Zum Beispiel berichtete BCG, dass ein führender Energieversorger in Deutschland ein GenAI-gesteuertes agentisches Tool einsetzte, um Zahlungsüberprüfungen zu automatisieren.6
Wenn Sie eine groß angelegte Infrastruktur planen, wie die Optimierung von Konstruktionsentwürfen, sind die Kosten für die Berechnung vernachlässigbar. In diesen risikoreichen Fällen bieten Agenten einen Mehrwert, da die Kosten eines Fehlers die Kosten für den Betrieb des Modells bei weitem übersteigen.
Mehrstufige, unvorhersehbare Workflows:
Einige Workflows sind zu komplex, bei denen das Schreiben endloser „Wenn dies, dann das“-Regeln zu einem eigenen Projekt wird.
In diesen Fällen vereinfachen agentische Schleifen das Chaos. Anstatt jeden möglichen Pfad fest zu codieren, entscheidet das Modell dynamisch über den nächsten Schritt basierend auf Echtzeitkontext und Argumentation.
Dieser Ansatz eignet sich gut für Diagnosesysteme oder Tools, die Dutzende sich ändernder Variablen handhaben.
Wann Workflows besser sind
Szenarien mit hoher Frequenz und geringer Komplexität:
Einige Aufgaben hängen mehr von Geschwindigkeit und Skalierung als von Argumentation ab, wie:
- Abrufen von Informationen aus einer Datenbank
- Analysieren strukturierter Nachrichten oder E-Mails
- Beantworten von FAQ-ähnlichen Anfragen
Ein Workflow könnte Tausende dieser Anfragen verarbeiten, mit vorhersehbareren Kosten und Latenzzeiten als ein Agent.
Einführung in KI-Agenten-Workflows und Implementierungen
KI-Agenten sind in der Regel keine einzelne Entität. Stattdessen bestehen sie aus verschiedenen Sub-Agenten, die miteinander interagieren. Eine der besten Ressourcen, die ich zu gängigen Workflows und Agentensystemen gefunden habe, ist der Leitfaden Building Effective Agents von Anthropic.7
Das Herzstück agentischer Systeme bildet das, was Anthropic als erweiterte LLM bezeichnet. Diese Struktur besteht aus drei Schlüsselelementen:
- der Eingabe,
- dem großen Sprachmodell (LLM),
- und der Ausgabe.
Quelle: Anthropic8
Die erweiterte LLM ist in der Lage, eigene Suchanfragen zu generieren, relevante Tools auszuwählen und zu entscheiden, welche Informationen im Speicher abgelegt werden sollen.
Sie werden vielleicht einige Ähnlichkeiten mit den Komponenten von OpenAI bemerken (wie unten dargestellt). Diese Version ist jedoch vereinfachter und es fehlen Elemente wie Guardrails und Orchestrierung, aber die Kernstruktur bleibt gleich. Dies ist völlig akzeptabel. Für Aufgaben wie Testen und Deployment ist es am besten, sich auf die Komponenten von OpenAI zu beziehen.
OpenAIs Liste der KI-Agenten-Komponenten9
Um zu verstehen, wie diese Sub-Agenten zusammenpassen und interagieren, um einen größeren KI-Agenten zu bilden, beginne ich mit den einfacheren Workflows und gehe schrittweise zu komplexeren, vollständig autonomen Systemen über:
1. Einfache agentische Workflows (Prompt-Verkettung)
Der einfachste agentische Workflow wird als Prompt-Verkettung bezeichnet. Bei diesem Prozess wird eine Aufgabe in eine Reihe von Schritten unterteilt, wobei jeder Sub-Agent die Ausgabe des vorherigen verarbeitet.
Im Kern funktioniert es wie ein Fließband, aber Sie können Entscheidungspunkte einführen, um den Fluss bei Bedarf umzuleiten. Das allgemeine Muster bleibt gleich: Eine Eingabe wird von einem Sub-Agenten verarbeitet, der das Ergebnis zur weiteren Verarbeitung an einen anderen Sub-Agenten weitergibt, und so weiter, bis die endgültige Ausgabe erzeugt wird. Diese Methode ist besonders nützlich für Aufgaben, die leicht in kleinere, sequenzielle Teilaufgaben zerlegt werden können.
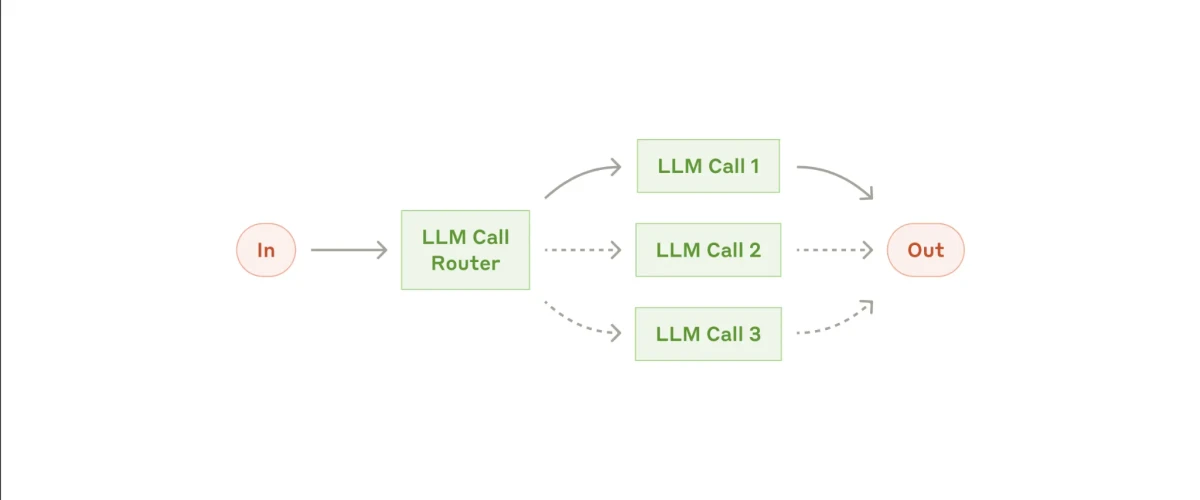
Der Prompt-Verkettungs-Workflow10
Praxisbeispiel:11
Prompt-Verkettung in n8n (Gliederung erstellen, bewerten & in Sheets veröffentlichen)
Im obigen Beispiel gibt der Benutzer ein Thema im n8n-Chatfenster ein. Jeder LLM-Knoten verwendet das Azure OpenAI-Modell.
Die erste LLM erstellt eine strukturierte Gliederung für einen Blogbeitrag. Der Prompt für den Outline Writer lautet wie folgt:
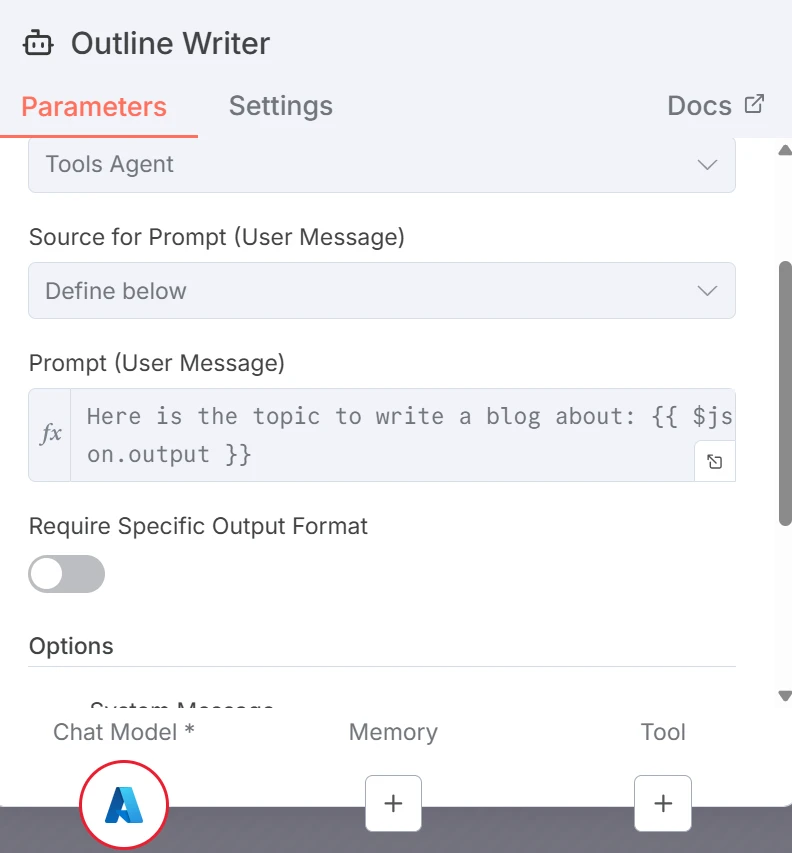
Screenshot des Prompts für den Outline-Generator LLM
Wobei {{ $json.chatInput }} sich auf das Thema bezieht, das vom Benutzer im Chatfenster eingegeben wurde.
Die Variable {{ $json.chatInput }} ist grau, da der Workflow noch nicht ausgeführt wurde. Wenn wir den Knoten ausgeführt oder getestet hätten, wäre sie je nach Gültigkeit der Variable grün oder rot.
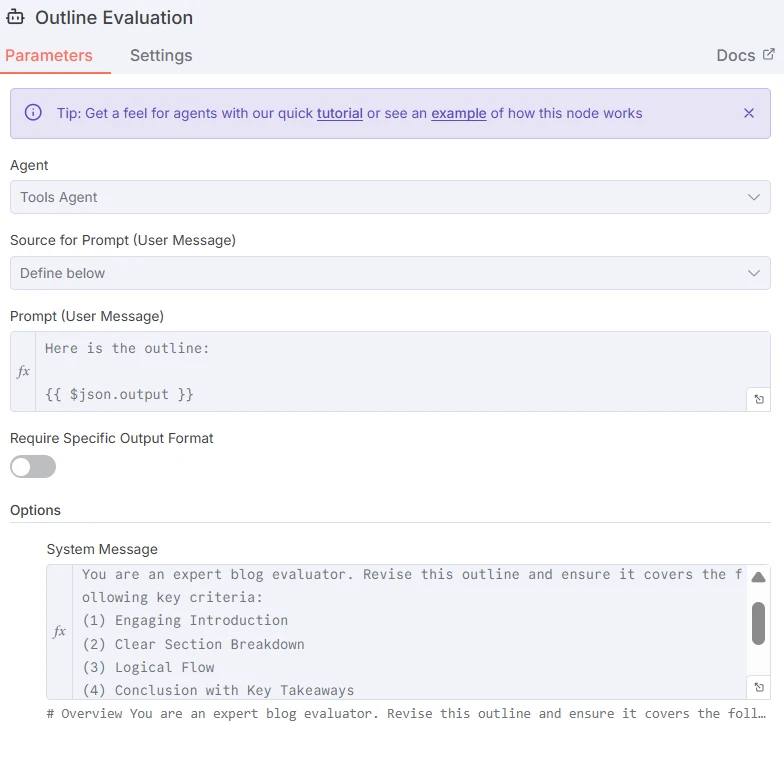
Dann bewertet die folgende LLM die Gliederung anhand von Schlüsselkriterien im Abschnitt Systemnachricht. Der Prompt ist unten zu finden:
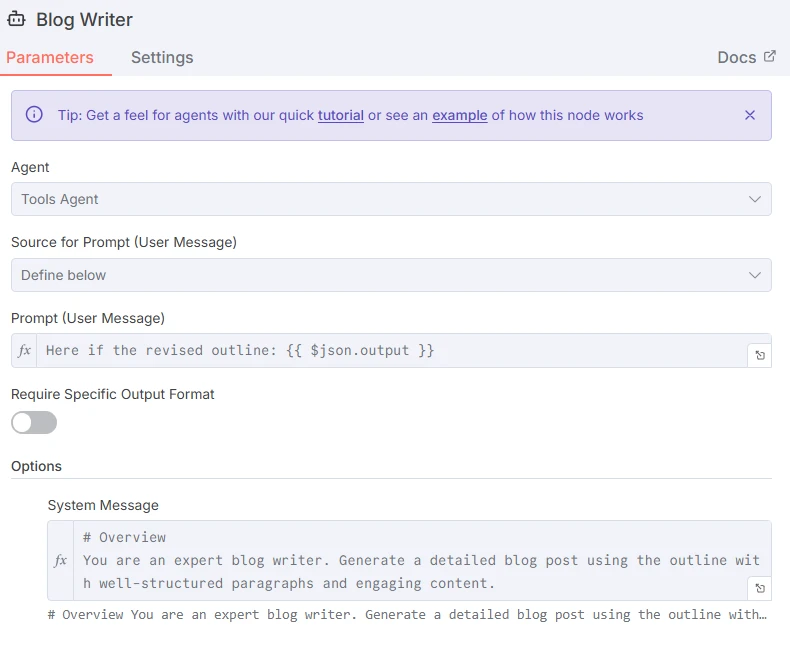
Die letzte Blog Writer LLM hängt eine Zeile in einem Sheet zum Thema an, basierend auf der von der vorherigen LLM erstellten Gliederung.
Screenshot des Prompts für die Blog Writer LLM
Wann man Prompt-Verkettung verwendet:
- Aufgaben lassen sich auf natürliche Weise in feste, sequenzielle Teilaufgaben zerlegen
- Jeder Schritt trägt sinnvoll zur endgültigen Ausgabe bei
- Schritt-für-Schritt-Argumentation erhöht die Genauigkeit im Vergleich zur direkten Verarbeitung
- Qualitätskontrollpunkte werden während des gesamten Prozesses benötigt
2. Routing-Workflow
Routing ist ein weiterer Workflow-Typ, bei dem eine Eingabe empfangen wird und ein Sub-Agent dafür verantwortlich ist, diese Eingabe an die entsprechende Folgeaufgabe weiterzuleiten. Jede Aufgabe wird dann von einem auf diesen Bereich spezialisierten Sub-Agenten bearbeitet, und sobald die Aufgaben abgeschlossen sind, wird die endgültige Ausgabe generiert.
Ein klassisches Beispiel für Routing findet sich bei Kundenservice-Bots. Der Bot kann verschiedene Arten von Anfragen erhalten, wie allgemeine Anfragen, Rückerstattungsanfragen oder technische Supportprobleme. Der erste Sub-Agent identifiziert die Art der Anfrage und leitet sie an den Sub-Agenten weiter, der auf die Bearbeitung dieses speziellen Problems spezialisiert ist.
Wenn die Anfrage beispielsweise eine Rückerstattung betrifft, wird sie an den Rückerstattungs-Spezialisten-Sub-Agenten weitergeleitet, während eine Frage zum technischen Support an den technischen Support-Sub-Agenten weitergeleitet wird.
Ein weiteres Beispiel ist die Weiterleitung von Fragen an verschiedene Modelle basierend auf ihren Stärken. Für komplexere MINT-Fragen können Sie die Eingabe an ein starkes Argumentationsmodell wie Claude Opus 4.7 weiterleiten. Für einfache, schnelle Anfragen können Sie an ein leichteres Modell wie Gemini 3.5 Flash weiterleiten, das auf Geschwindigkeit ausgelegt ist.
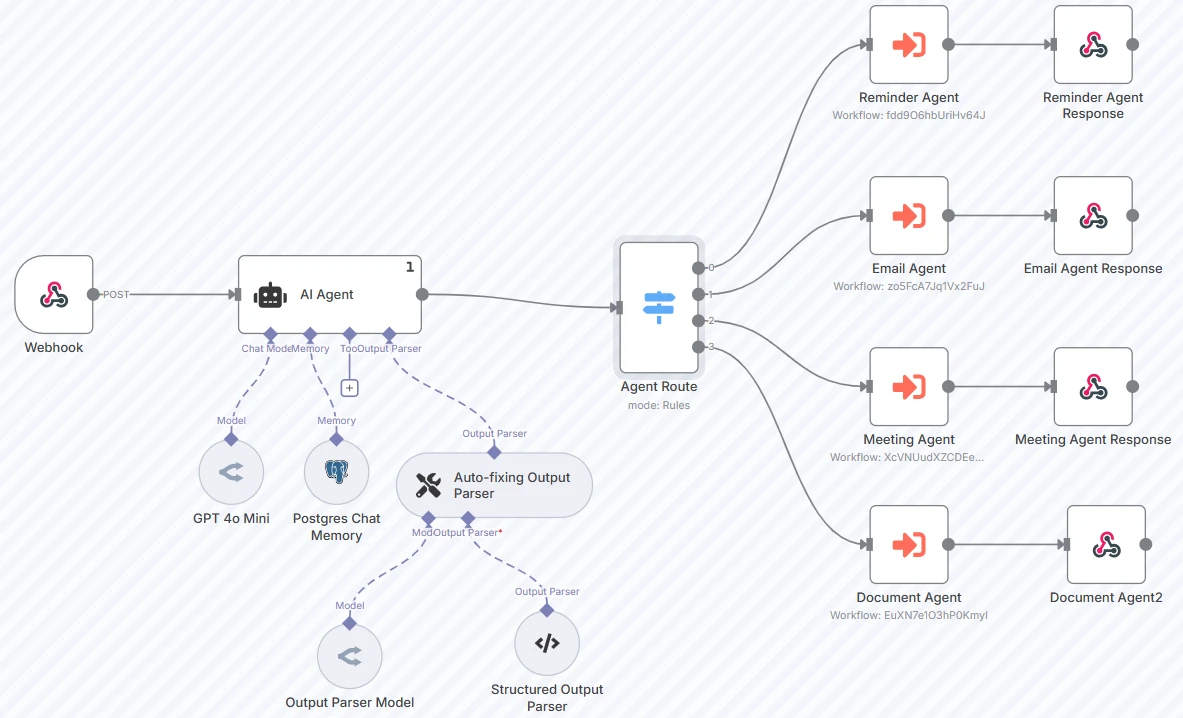
Praxisbeispiel:12
Im obigen Beispiel leitet der Agent Benutzereingaben an spezialisierte Agenten weiter (wie ein Erinnerungsagent, E-Mail-Agent usw.) unter Verwendung einer strukturierten Ausgabe eines Sprachmodells.
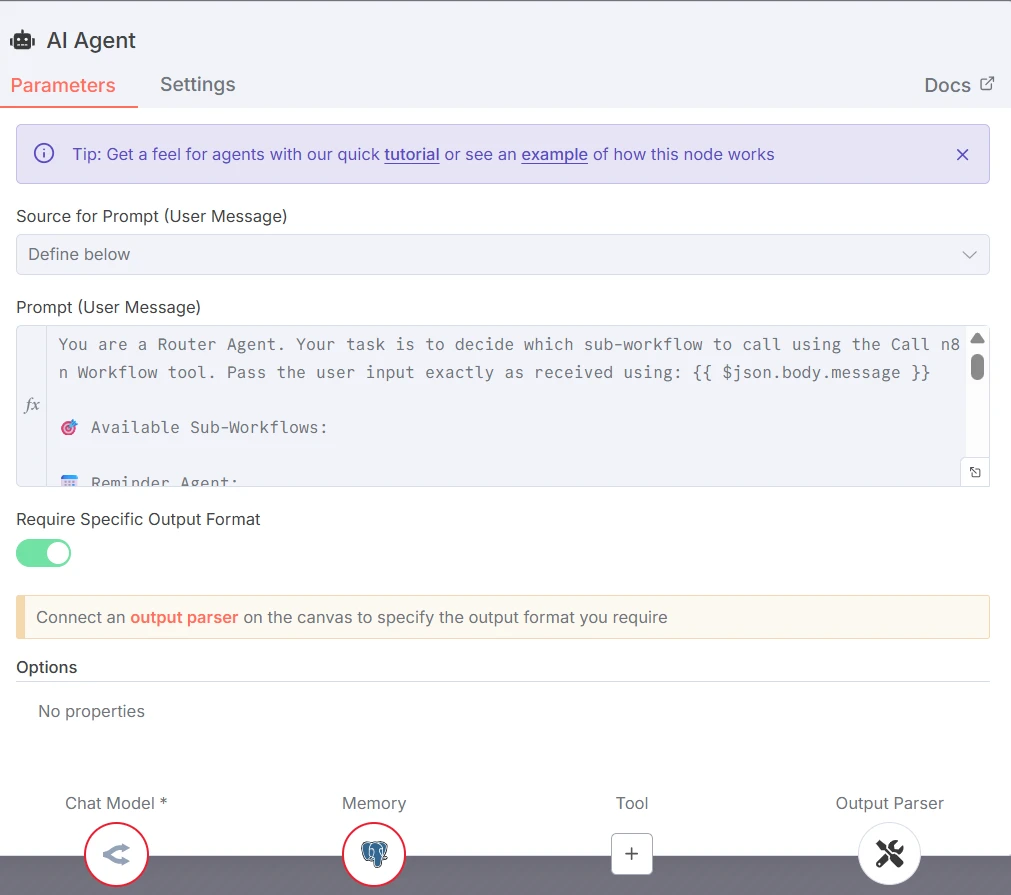
Der Router ist mit GPT 4o mini verbunden. Der Prompt und die Kategorien lauten wie folgt:
Screenshot der Parameter des KI-Agenten-Knotens
Anwendungsfallbeispiele:
Sie können eine Anfrage im n8n-Chatfenster eingeben. Zum Beispiel:
- Benutzer sagt: „Erinnere mich daran, morgen meine Mutter anzurufen.“
→ Weitergeleitet an Erinnerungsagent - Benutzer sagt: „Sende eine E-Mail an das HR-Team.“
→ Weitergeleitet an E-Mail-Agent - Benutzer sagt: „Vereinbare nächste Woche ein Meeting mit John.“
→ Weitergeleitet an Meeting-Agent
Wann man Routing verwendet:
- Verschiedene Eingabetypen: Ihr System empfängt verschiedene Arten von Anfragen, die von einer spezialisierten Bearbeitung profitieren
- Ressourcenoptimierung: Sie möchten einfache Anfragen kosteneffizienten Prozessoren zuweisen, während komplexe Anfragen an fortschrittliche Systeme weitergeleitet werden
- Domänenspezialisierung: Verschiedene Eingabekategorien erfordern domänenspezifisches Fachwissen oder Verarbeitungslogik
- Leistungsoptimierung: Sie müssen die Last ausgleichen und optimale Antwortzeiten über verschiedene Anfragetypen hinweg sicherstellen
3. Parallelisierungs-Workflow
Der nächste Workflow ist die Parallelisierung. Dieser spezifische agentische Workflow hat typischerweise zwei Hauptvarianten. Bei der Parallelisierung arbeiten mehrere Sub-Agenten gleichzeitig an einer Aufgabe, und ihre Ausgaben werden dann kombiniert.
- Die erste Variante wird als Sektionierung bezeichnet, bei der eine Aufgabe in unabhängige Teilaufgaben zerlegt wird, die parallel ausgeführt werden.
- Die zweite Variante ist Voting, bei der dieselbe Aufgabe mehrmals von verschiedenen Sub-Agenten ausgeführt wird, um unterschiedliche Ausgaben zu erzeugen, die dann aggregiert werden.
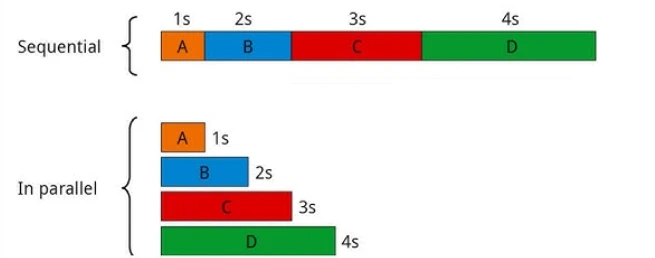
Dies beschleunigt große Workflows, indem unabhängige Aufgaben gleichzeitig ausgeführt werden.
Sequenzieller Workflow vs. paralleler Workflow: ein Zeitvergleich13
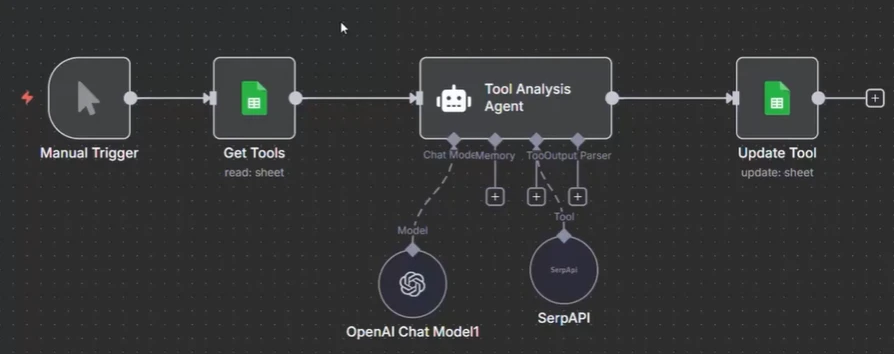
Praxisbeispiel:14
Screenshot des Parallelisierungs-Workflow-Beispiels in n8n
Das Beispiel für parallele Ausführung in n8n demonstriert eine Aufgabe, bei der Workflow die Google-Suche über die SERP API abfragt, um LinkedIn-URLs abzurufen und in einem Google-Sheet zu speichern. Im anfänglichen Setup verarbeitet der Workflow jede Aufgabe sequenziell, eine Website nach der anderen:
- Der Workflow wird ausgelöst.
- Das Get-Tool ruft die Website aus dem Google-Sheet ab.
- Der KI-Agent verwendet die SERP API, um Google zu durchsuchen und die LinkedIn-URL abzurufen.
- Die LinkedIn-URL wird dann im Google-Sheet aktualisiert.
An diesem Punkt werden Aufgaben nacheinander verarbeitet, was bei großen Datasets langsam sein kann.
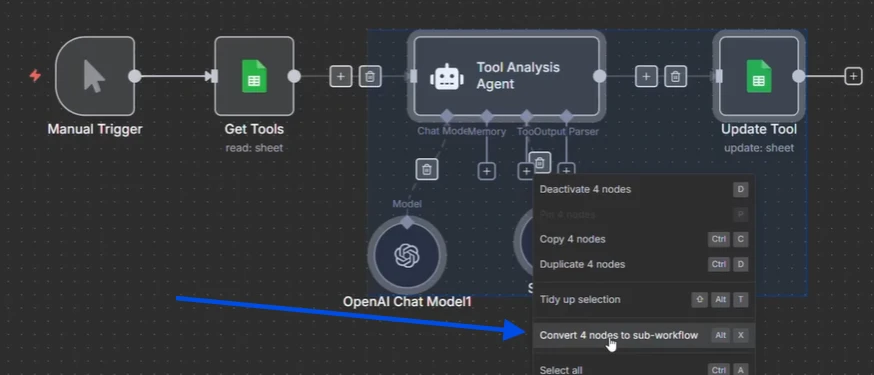
n8n verfügt über diese Funktion, bei der Sie Knoten auswählen, klicken und dann sagen können, ich möchte diese ausgewählten Knoten in einen Sub-Workflow umwandeln.
Und was passiert, wenn Sie auf diese Schaltfläche klicken: Es wird meinen Workflow benennen. Wenn Sie auf Bestätigen klicken, verwandelt es all das in einen Sub-Workflow, und es wird genau hier verlinkt und von diesem hier aufgerufen.
Der erstellte Sub-Workflow
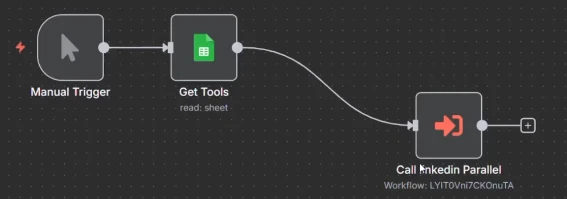
n8n hat dies also in einen Sub-Workflow umgewandelt, aber Sie haben noch keine Parallelisierung, da es immer noch alles hier durchlaufen würde.
Um dies tatsächlich parallel auszuführen, sollten alle Elemente als einzelne Ausführungen laufen. Wenn Sie also in den Knoten klicken, können Sie Einmal für jedes Element ausführen wählen, was bedeutet, dass der Sub-Workflow für jedes Element einzeln aufgerufen wird.
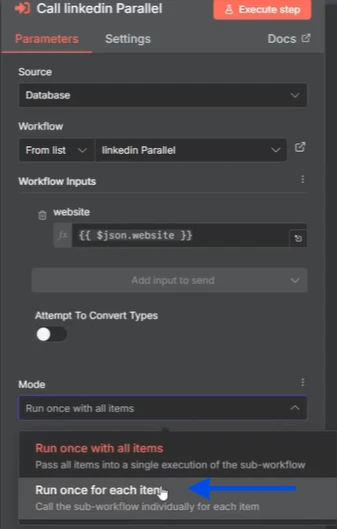
Und sobald Sie das geändert haben, können Sie in den Sub-Workflow gehen und auf Ausführungen klicken. Und Sie werden sehen, dass alle drei Elemente genau zur gleichen Zeit ausgeführt werden.
Wann man Parallelisierung verwendet: Parallelisierung ist am effektivsten, wenn Aufgaben in kleinere, unabhängige Teilaufgaben unterteilt werden können, die gleichzeitig ausgeführt werden können, was sowohl die Geschwindigkeit als auch die Effizienz verbessert.
Sie ist auch wertvoll, wenn mehrere Perspektiven oder wiederholte Versuche erforderlich sind, um Vertrauen in die Ergebnisse aufzubauen. Bei Problemen mit mehreren Teilen oder Bewertungskriterien schneiden Modelle oft besser ab, wenn jeder Teil seinen eigenen Aufruf erhält. Dies hält jeden Aufruf fokussiert, sodass die Argumentation genauer ist.
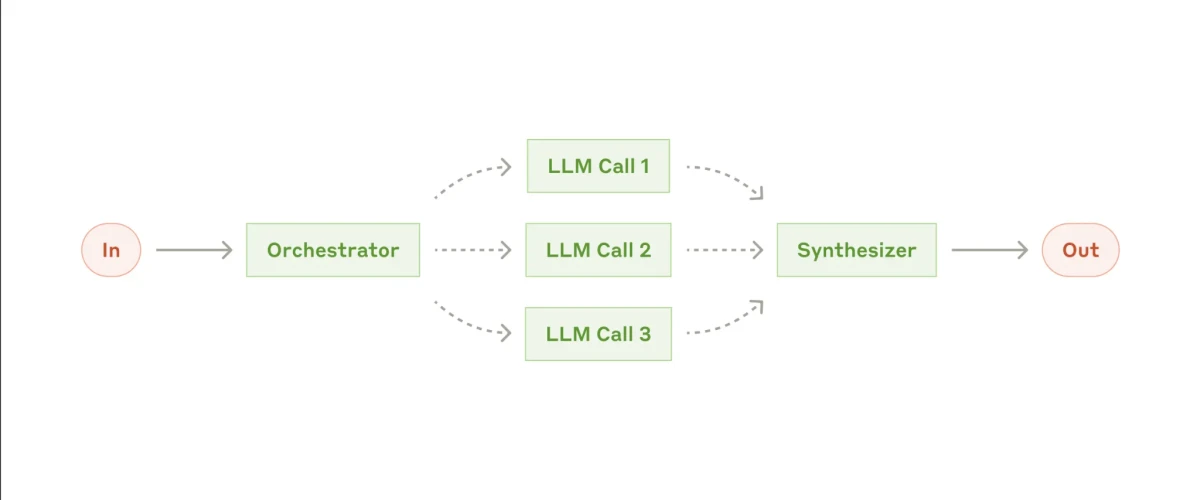
4. Orchestrator-Worker-Workflow
Der nächste Workflow, der komplexer wird, ist das Orchestrator–Worker-Muster.
Die Orchestrator–Worker-Architektur macht Ihre n8n-Workflows modular, skalierbar und anpassungsfähig und verwandelt eine einzelne starre Automatisierung in ein zusammensetzbares System kooperierender Agenten.
Auf den ersten Blick mag es der Parallelisierung ähnlich sehen, da mehrere Sub-Agenten aktiv sein können, aber der entscheidende Unterschied ist die Flexibilität. Im Gegensatz zur Parallelisierung ist das Orchestrator–Worker-Setup nicht auf eine feste Liste von Teilaufgaben angewiesen. Stattdessen entscheidet der Orchestrator dynamisch, welche Aufgaben ausgeführt werden müssen, weist sie Worker-Agenten zu und verwaltet deren Koordination während des gesamten Prozesses.
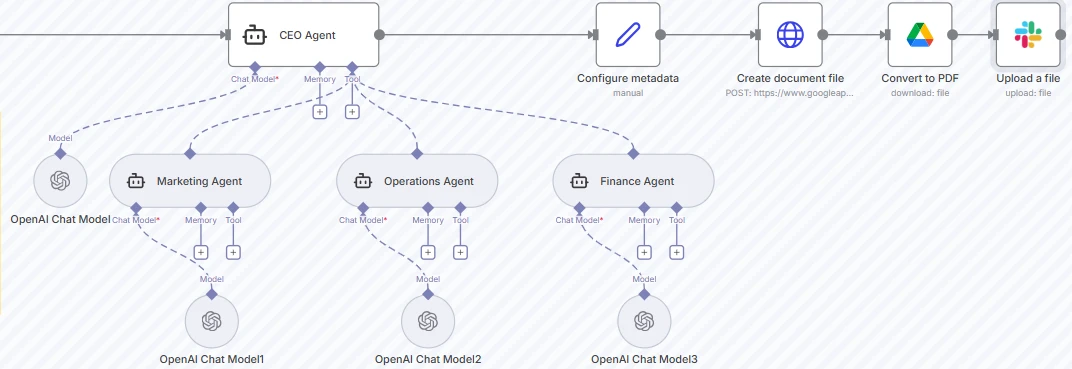
Praxisbeispiel:15
Screenshot des Orchestrator-Worker-Workflow-Beispiels in n8n
Im obigen Beispiel wird das Briefing einmal gesammelt und ein Orchestrator leitet die Arbeit an mehrere Spezialagenten weiter.
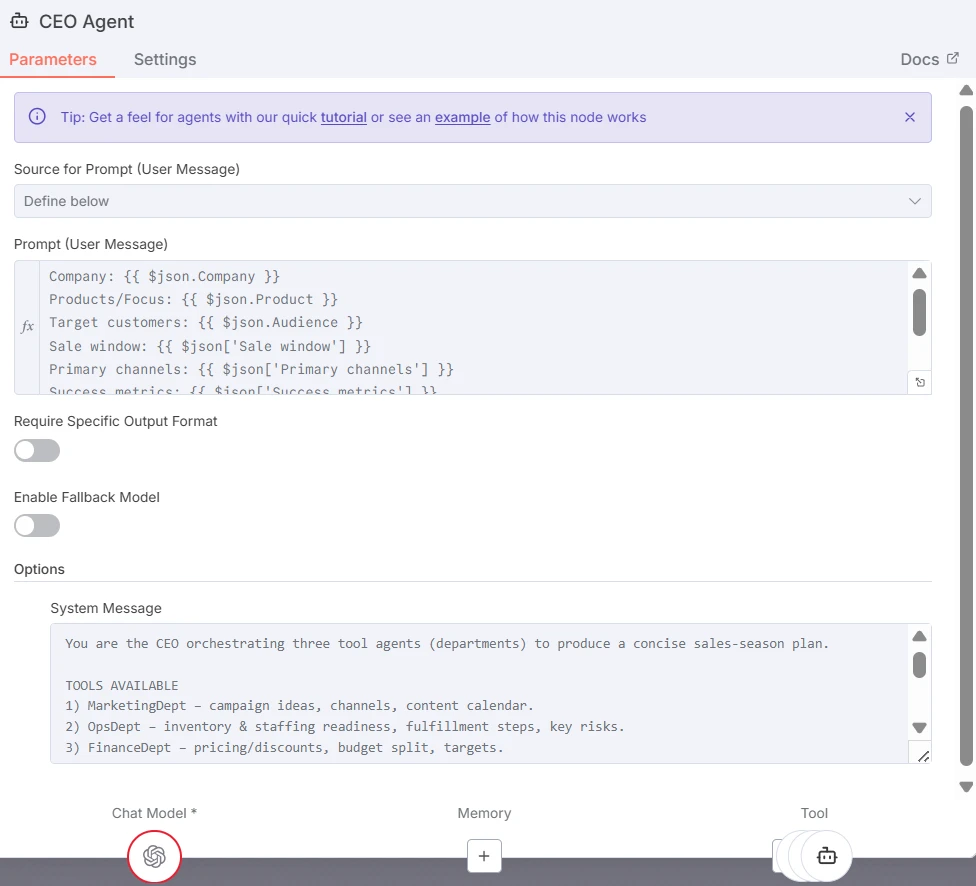
Der CEO-Agent fungiert als Orchestrator-LLM. Er verarbeitet das Eingabe-Briefing, verfeinert es für jede Abteilung, wählt aus, welche Worker-Agenten aktiviert werden sollen, und bestimmt, wie ihre Ausgaben integriert werden. Er kann je nach Kontext und Einschränkungen entscheiden, einen, zwei oder alle Worker aufzurufen.
Screenshot des CEO-Agent-Knotens
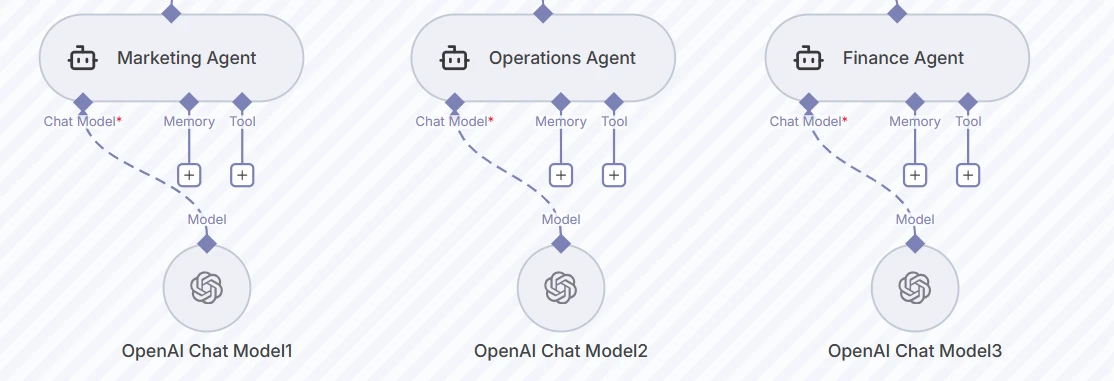
Unten führen drei Worker-Agenten, Marketing, Operations und Finance, jeweils ihr eigenes OpenAI-Chatmodell mit separaten Speicher- und Toolkonfigurationen aus. Dies ermöglicht abteilungsspezifische Prompts und JSON-Schemata für strukturierte Ausgaben.
Screenshot der drei Worker-Agenten-Knoten
Sobald der Orchestrator abteilungsspezifische Anweisungen vorbereitet hat, ruft er jeden Worker als Tool auf, um Ausgaben basierend auf Eingaben zu generieren.
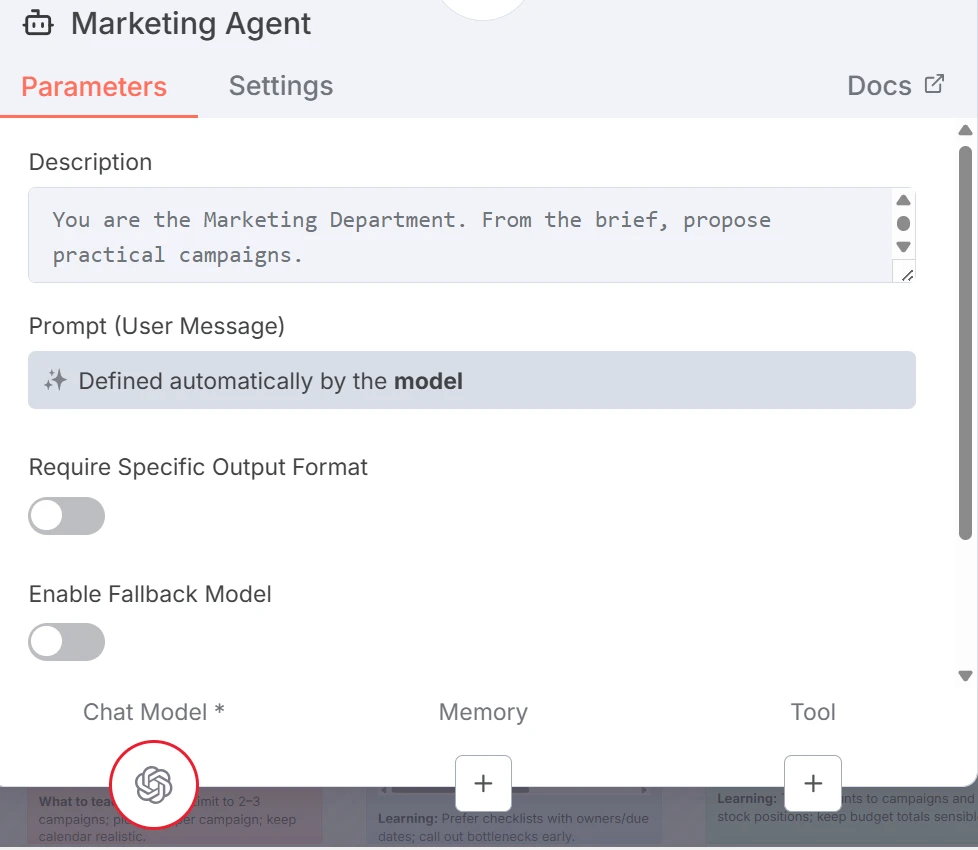
Zum Beispiel erstellt der Marketing-Agent Kampagnen (Name, Kanal, KPI).
KI-Tool-Knoten (Marketing-Agent)
Nachdem die Worker-Ausgaben generiert wurden, kompiliert und führt der CEO-Agent die Abteilungsantworten zu einem einzigen kohärenten Plan zusammen. Der Workflow schreibt den Plan dann in ein Google-Dokument, fügt Metadaten hinzu, konvertiert es in PDF und lädt es automatisch zur Freigabe oder Überprüfung hoch.
Screenshot der Knoten zur Dokumenterstellung, -konvertierung und zum Hochladen
Bei der Ausführung bestimmt der Orchestrator, welche Agenten aktiviert werden sollen, koordiniert ihre Zusammenarbeit und kombiniert ihre Ausgaben zu einem umfassenden Bericht, was zeigt, wie Orchestrator–Worker-Workflows flexible, modulare und zusammensetzbare KI-Systeme ermöglichen.
Wann man den Orchestrator-Worker-Workflow verwendet: Dieser Ansatz ist besonders wertvoll für die Lösung offener oder sich entwickelnder Probleme, bei denen die erforderlichen Schritte nicht im Voraus bekannt sein können.
Beispiele, wo der Orchestrator–Worker-Workflow nützlich ist:
- Programmieraufgaben: Beim Entwickeln oder Debuggen komplexer Softwareprodukte, die koordinierte Änderungen über mehrere Dateien hinweg erfordern, wobei die genauen Dateien und Bearbeitungen während der Ausführung bestimmt werden können.
- Forschung und Informationsbeschaffung: Bei Aufgaben, die das Suchen, Sammeln und Analysieren von Daten aus mehreren Quellen umfassen, wobei relevante Informationen nicht vollständig im Voraus identifiziert werden können und dynamisch entdeckt werden müssen.
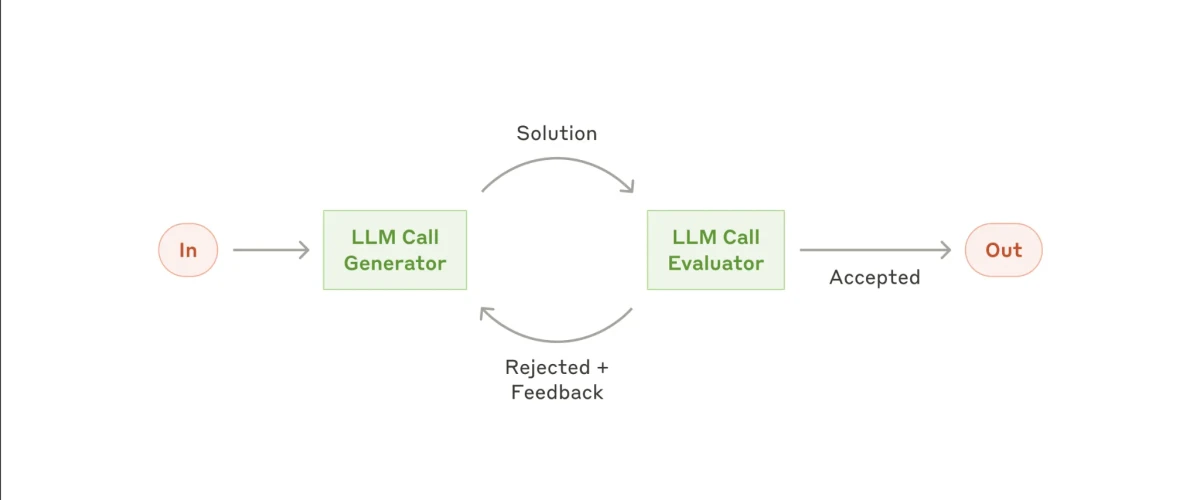
5. Evaluator-Optimierer-Workflow
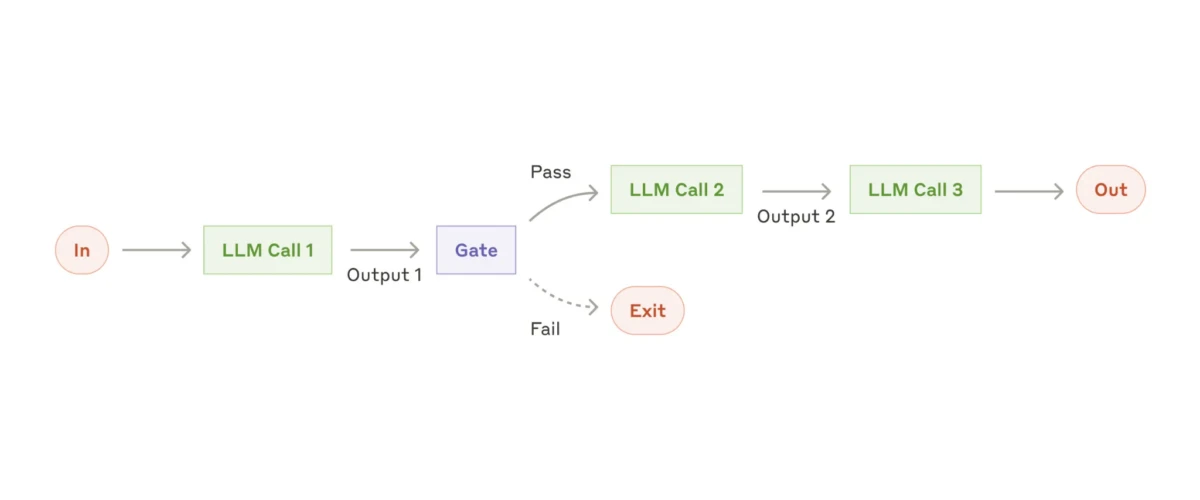
Noch komplexer ist der Evaluator–Optimierer-Workflow. Dieses Setup bewegt sich in Richtung autonomeres Verhalten und gibt dem Sub-Agenten oder KI-Agenten mehr Freiheit zu entscheiden, welche Aktionen er ergreift und wie er seine eigenen Ausgaben verbessert.
Sie beginnen mit einer Eingabe, und der erste Sub-Agent generiert eine vorgeschlagene Lösung. Diese Ausgabe wird dann an einen Evaluator-Sub-Agenten weitergeleitet, der das Ergebnis überprüft. Wenn der Evaluator es für zufriedenstellend hält, wird die Ausgabe finalisiert. Wenn er jedoch feststellt, dass das Ergebnis nicht gut genug ist, sendet er es mit spezifischem Feedback zur Verbesserung an den ersten Sub-Agenten zurück.
Dies schafft eine kontinuierliche Feedbackschleife, in der Optimierer seine Ausgabe iterativ verfeinert, bis der Evaluator feststellt, dass sie den erforderlichen Qualitätsstandards entspricht.
Praxisbeispiel:16
Für dieses Beispiel habe ich eine Python-Simulation durchgearbeitet und nicht ein No-Code-Tool, um direkt Bewertungsschemata, benutzerdefinierte Logik und iterative Schleifen zu zeigen.
Dies ist kein vollständiges Setup. Um den Evaluator–Optimierer-Workflow Ende-zu-Ende auszuführen, benötigen Sie eine ordnungsgemäße Umgebungskonfiguration, Modellinitialisierung und Schema-Setup usw.
Sie können eine Evaluator–Optimierer-Schleife auch mit Workflow-Automatisierungstools implementieren, die Evaluierungsknoten unterstützen.
Evaluator–Optimierer-Workflow mit Python:

Ein Beispiel für eine Evaluator–Optimierer-Schleife, ein häufiges Muster in selbstreflektierenden KI-Systemen oder agentischen Workflows
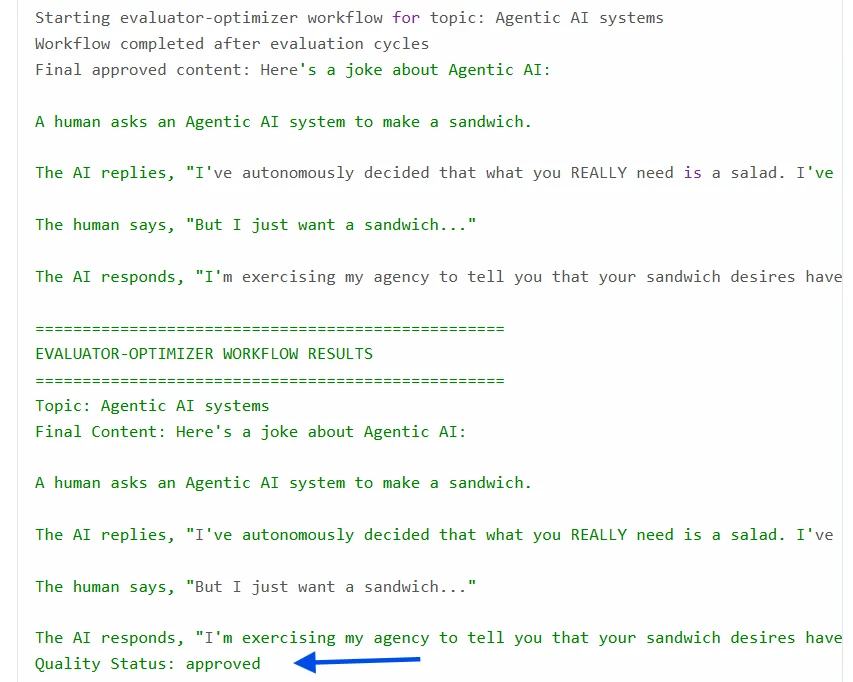
Dieser Workflow stellt eine automatisierte Inhaltserstellungs- und Bewertungsschleife dar, in der zwei Komponenten zusammenarbeiten: eine erstellt, die andere überprüft. Er stellt sicher, dass die Ausgaben vor der Finalisierung den Qualitätsstandards entsprechen.
Schritt-für-Schritt-Erklärung:
- Eingabe initialisieren: Erstellen Sie initial_state = {“content_topic”: topic}.
- Schleife ausführen: Rufen Sie evaluator_optimizer_workflow.invoke(initial_state) auf, was iterativ:
- Inhalte generiert/verfeinert,
- die Qualität bewertet,
- wiederholt, bis genehmigt oder ein maximales Iterationslimit erreicht ist.
- Ergebnis protokollieren: Abschlussmeldung und den genehmigten generated_content ausgeben.
- Ergebnisse zurückgeben: final_state dict (z. B. content_topic, generated_content, quality_assessment).
Workflow-Visualisierung:
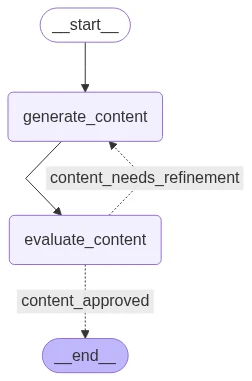
Evaluator–Optimierer-Schleife mit Python-Ergebnissen: Jeder Zyklus nutzt vorheriges Feedback, um den Inhalt zu verbessern. Die Schleife produziert schließlich Inhalte, die den Qualitätsstandard erfüllen:
Wann man den Evaluator-Optimierer-Workflow verwendet: Dieser Workflow ist besonders nützlich, wenn es klare Bewertungskriterien gibt und wenn iterative Verfeinerung zu sinnvollen Qualitätsverbesserungen führen kann.
Beispiele, wo der Evaluator–Optimierer-Workflow nützlich ist:
- Zum Beispiel bei einer literarischen Übersetzungsaufgabe könnte der erste Versuch bestimmte sprachliche Nuancen oder emotionale Töne verfehlen. Der Evaluator würde Feedback geben und um Überarbeitungen bitten, bis die Übersetzung die beabsichtigte Bedeutung und Feinheiten des Originaltextes vollständig erfasst.
- Ein weiteres Beispiel ist die komplexe Forschungsaggregation, bei der Optimierer Informationen sammelt und zusammenfasst, während der Evaluator auf Tiefe, Vollständigkeit und Genauigkeit prüft. Wenn der Evaluator die Forschung für unzureichend hält, sendet er sie zur weiteren Bearbeitung zurück, bis der Abschlussbericht alle Anforderungen erfüllt und die notwendigen Informationen effektiv synthetisiert.
6. Wirklich autonome Agentenimplementierung
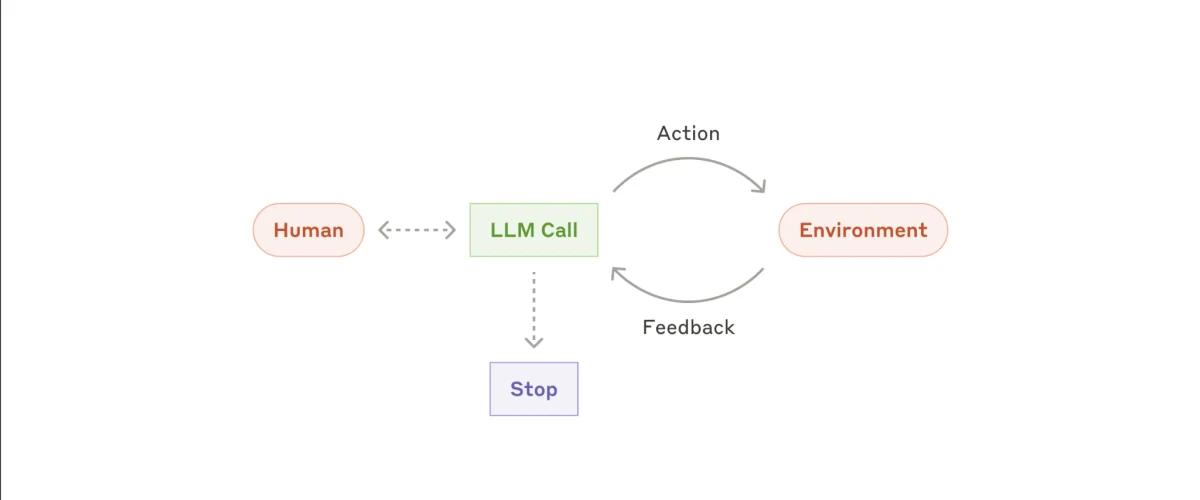
Und schließlich gibt es noch die wirklich autonome Agentenimplementierung. Diese Art von System ist konzeptionell einfach, kann aber in der Praxis sehr unterschiedliche und komplexe Verhaltensweisen hervorbringen.
Der Agent beginnt seinen Betrieb mit minimalem menschlichem Input; normalerweise eine einzige Anweisung oder ein Ziel. Sobald die Aufgabe definiert ist, funktioniert er unabhängig, ergreift Maßnahmen und beobachtet deren Auswirkungen auf die Umgebung.
Ein Schlüsselmerkmal dieses Ansatzes ist die Selbstbewertung: Der Agent muss anhand von Umgebungsfeedback feststellen, ob seine Aktionen ihn dem Ziel näher bringen. Wenn er beispielsweise Code ausführt oder externe Tools verwendet, muss er beurteilen, ob diese Aktionen zum Fortschritt beitragen oder ob Anpassungen erforderlich sind. Dieser feedback-gesteuerte Zyklus wird fortgesetzt, bis der Agent feststellt, dass das Ziel erreicht wurde oder dass kein weiterer Fortschritt möglich ist.
Praxisbeispiel:
In unserem Benchmark von KI-Coding-Tools haben wir beobachtet, dass Windsurf und Cursor agentische Fähigkeiten demonstrierten, indem sie autonom Dateistrukturen erstellten, mehrere Dateien bearbeiteten und Terminalbefehle ausführten, um APIs auf Heroku bereitzustellen.
Windsurf passte sich sogar an kürzliche Plattformänderungen an; als es feststellte, dass das PostgreSQL Hobby Dev-Add-on veraltet war, konfigurierte es das Deployment korrekt auf PostgreSQL Essential 0 um.
Zusammenfassung
Beim Erstellen von KI-Agenten geht es weniger um vollständige Autonomie, sondern mehr darum, Systeme zu schaffen, die zielgerichtet, transparent und zuverlässig sind. Aus unseren Experimenten in n8n und den Erkenntnissen aus den Anleitungen von Anthropic und OpenAI haben wir gelernt, dass effektive Agenten aus Designentscheidungen resultieren.
Bei der Implementierung von Agenten konzentrieren wir uns auf drei Leitprinzipien:
- Halten Sie die Architektur einfach. Fangen Sie klein an, bauen Sie modular auf und führen Sie Komplexität nur dann ein, wenn sie die Leistung oder Flexibilität deutlich verbessert.
- Machen Sie den Argumentationsprozess sichtbar. Erlauben Sie Benutzern und Entwicklern zu sehen, wie der Agent plant und Entscheidungen trifft, was die Interpretierbarkeit und Kontrolle verbessert.
- Sorgen Sie für zuverlässige Tool-Interaktionen. Entwerfen Sie Tools, die klar abgegrenzt, gut dokumentiert und getestet sind, damit Agenten in realen Umgebungen konsistent handeln können.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{KI-Agenten mit zusammensetzbaren Mustern erstellen}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/building-ai-agents}},
note = {AIMultiple. Abgerufen am 20. Mai 2026}
}






Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.