15 KI-Agenten-Observability-Tools: AgentOps & Langfuse
KI-Agenten-Observability-Tools, wie etwa Langfuse und Arize, helfen dabei, detaillierte Traces (eine Aufzeichnung der Ausführung eines Programms oder einer Transaktion) zu sammeln und Dashboards zur Echtzeitverfolgung von Metriken bereitzustellen.
Viele Agent-Frameworks, wie LangChain, verwenden den OpenTelemetry-Standard, um Metadaten mit agentischem Monitoring zu teilen. Darüber hinaus bieten viele Observability-Tools benutzerdefinierte Instrumentierung für größere Flexibilität.
Wir haben 15 Observability-Plattformen für LLM-Anwendungen und KI-Agenten getestet. Jede Plattform wurde praktisch implementiert, indem Workflows eingerichtet, Integrationen konfiguriert und Testszenarien ausgeführt wurden. Wir haben 4 Observability-Tools einem Benchmark unterzogen, um zu messen, ob sie Overhead in Produktions-Pipelines verursachen. Wir haben außerdem ein LangChain-Observability-Tutorial mit Langfuse demonstriert.
Benchmark zum Overhead agentischer Monitoring-Tools
Wir haben jede Observability-Plattform in unser Multi-Agenten-Reiseplanungssystem integriert und 100 identische Anfragen ausgeführt, um ihren Performance-Overhead im Vergleich zu einer Baseline ohne Instrumentierung zu messen. Lesen Sie unsere Benchmark-Methodik.
- LangSmith zeigte außergewöhnliche Effizienz mit praktisch keinem messbaren Overhead und ist damit ideal für leistungskritische Produktionsumgebungen.
- Laminar verursachte minimalen Overhead von 5% und ist damit hervorragend für Produktionsumgebungen geeignet, in denen Leistung entscheidend ist.
- AgentOps und Langfuse zeigten moderaten Overhead von 12% bzw. 15%, was einen angemessenen Kompromiss zwischen Observability-Funktionen und Performance-Auswirkungen darstellt. Diese Plattformen bieten weiterhin akzeptable Latenz für die meisten Produktionsanwendungen.
Mögliche Gründe für Leistungsunterschiede
Unser Benchmark zeigt, dass Latenzunterschiede durch die Instrumentierungstiefe und die Beteiligung am Ausführungspfad bedingt sind, insbesondere in Multi-Agenten-Workflows. Tools mit tieferer Observability auf Schritt-Ebene wiesen höheren Overhead auf, während leichtere Tracing-Ansätze näher an der Baseline blieben.
1. Instrumentierungstiefe im Ausführungspfad
Observability-Tools fügen dem Ausführungsfluss des Agenten Logik hinzu, um Traces und Metadaten zu erfassen. Wenn diese Logik synchron während der Anfragebearbeitung läuft, erhöht sie direkt die End-to-End-Latenz, da der Agent diese zusätzliche Arbeit abschließen muss, bevor er eine Antwort zurückgibt.
Zum Beispiel:
- LangSmith verursachte praktisch keinen messbaren Overhead (~0%), was auf wenig synchrone Arbeit hindeutet,
- Langfuses tiefere Instrumentierung auf Schritt-Ebene trug zu einem höheren Overhead bei (~15%).
2. Ereignisverstärkung über mehrstufige Pipelines hinweg
In Multi-Agenten-Systemen löst eine einzelne Benutzeranfrage mehrere Agentenaktionen aus. Wenn ein Tool bei jedem Schritt detaillierte Daten aufzeichnet, wächst die Gesamtzahl der Ereignisse schnell an, was den Verarbeitungs- und Trace-Handling-Overhead erhöht, je tiefer der Workflow wird.
In den Benchmark-Ergebnissen:
- Langfuse und AgentOps erzeugten deutlich höheren Overhead (15% und 12%) in unserem mehrstufigen Reiseplanungs-Workflow
- LangSmith und Laminar emittierten weniger Ereignisse pro Agentenschritt.
3. Inline-Evaluierungs- und Validierungs-Overhead
Einige Plattformen führen zusätzliche Prüfungen oder Überwachungen durch, während der Agent läuft. Obwohl jede Prüfung leichtgewichtig ist, summiert sich die wiederholte Anwendung über alle Agentenschritte hinweg zu messbarer Latenz.
Zum Beispiel:
- AgentOps' Lifecycle-Überwachung ging mit einem Overhead von 12% einher
- Laminar zeigte keine Anzeichen von Inline-Evaluierung, die Ausführung beeinflusste, und blieb bei ~5%.
4. Serialisierungs- und Persistenzhäufigkeit
Die Erfassung detaillierter Observability-Daten erfordert die Serialisierung von Traces und deren Speicherung in Storage oder externen Backends. Höhere Trace-Details erhöhen die Häufigkeit dieses Vorgangs und fügen jeder Anfrage I/O-Overhead hinzu.
In unserem Benchmark:
- Langfuses detailliertes Prompt-, Output- und Token-Tracing führte zum höchsten Overhead (~15%)
- LangSmiths leichtere Trace-Artefakte blieben nahe der Baseline.
5. Integrationstiefe mit dem Agenten-Framework
Wie eng ein Tool mit dem Agenten-Framework integriert ist, beeinflusst die Leistung. Engere Integrationen reduzieren Übersetzungs- und Orchestrierungsschritte, während generischere SDKs zusätzliche Verarbeitungsschichten hinzufügen.
Zum Beispiel:
- LangSmiths enge Ausrichtung an der Agentenausführung korrelierte mit ~0% Overhead
- AgentOps und Langfuse zeigten höhere Latenzauswirkungen, was mit stärker entkoppelten Integrationspfaden übereinstimmt.
KI-Agenten-Observability-Plattformen
Stufe 1: Feingranulare LLM- & Prompt-/Output-Observability
* Die in diesen Spalten aufgeführten Fähigkeiten sind illustrative Beispiele dafür, was jedes Tool überwachen kann, wenn es durch Integrationen oder Anpassung erweitert wird. Diese sind nicht exklusiv für eine einzelne Plattform.
Stufe 2: Workflow-, Modell- & Evaluierungs-Observability
Stufe 3: Agenten-Lifecycle- & Betriebs-Observability
Stufe 4: System- & Infrastruktur-Monitoring (nicht agenten-nativ)
Datadog (mit seinem LLM-Observability-Modul) und Prometheus (via Exporter) werden zunehmend neben Langfuse/LangSmith eingesetzt.
Agentenentwicklungs- & Orchestrierungsplattformen:
- Tools wie Flowise, Langflow, SuperAGI und CrewAI ermöglichen das Erstellen, Orchestrieren und Optimieren von Agenten-Workflows mit No-Code-/Low-Code-Schnittstellen
Bereitstellungs-kostenlos-Editionen & Preise
Die kostenlos-Editionen variieren je nach Nutzungslimits (z. B. Beobachtungen, Traces, Tokens oder Arbeitseinheiten). Die Einstiegspreise gelten in der Regel für einen Basisplan, der Einschränkungen bei Funktionen, Nutzern oder Nutzungslimits aufweisen kann.
Weights & Biases (W&B Weave)
Anwendungsfall: Debugging von Fehlern in Multi-Agenten-Systemen durch Nachverfolgung, wie sich Fehler über Agentenaufrufe hinweg ausbreiten.
Weights & Biases Weave zeichnet strukturierte Ausführungs-Traces für Multi-Agenten-Systeme auf und bewahrt die Eltern-Kind-Beziehungen zwischen Agentenaufrufen. Eingaben, Ausgaben, Zwischenzustände, Latenz und Token-Nutzung werden pro Agent und pro Trace erfasst.
Weave-Monitoring-Funktionen
- Hierarchisches Agenten-Tracing statt flacher Anfrageprotokolle
- Kosten- und Latenzzuordnung auf Agenten-Ebene
- Native Unterstützung für Evaluierungs-Scorer, die direkt auf Traces angewendet werden.
Evaluierungsfunktionen
Weave bietet außerdem integrierte Scorer für die Evaluierung, darunter:
- HallucinationFreeScorer zur Erkennung von Halluzinationen,
- SummarizationScorer zur Bewertung der Zusammenfassungsqualität,
- EmbeddingSimilarityScorer für semantische Ähnlichkeit,
- ValidJSONScorer und ValidXMLScorer für Formatvalidierung,
- PydanticScorer für Schema-Compliance,
- OpenAIModerationScorer für Inhaltssicherheit,
- RAGAS-Scorer wie ContextEntityRecallScorer,
- ContextRelevancyScorer für RAG-Systemevaluierung.
Am besten geeignet für: Teams, die mehrstufige oder Multi-Agenten-Workflows betreiben und eine Ursachenanalyse auf Trace-Ebene statt oberflächlicher Metriken benötigen.
Langfuse
Anwendungsfälle: Verfolgen Sie LLM-Interaktionen, verwalten Sie Prompt-Versionen und überwachen Sie die Modellleistung mit Benutzersitzungen.
Langfuse bietet tiefe Einblicke in die Prompt-Ebene und erfasst Prompts, Antworten, Kosten und Ausführungs-Traces, um beim Debuggen, Überwachen und Optimieren von LLM-Anwendungen zu helfen.
Allerdings ist Langfuse möglicherweise nicht für Teams geeignet, die Git-basierte Workflows für Code- und Prompt-Management bevorzugen, da sein externes Prompt-Management-System möglicherweise nicht das gleiche Maß an Versionskontrolle und Zusammenarbeit bietet.
Langfuse-Monitoring-Funktionen
- Einblick in Prompt-Entwicklung und Nutzungsmuster
- Sitzungsbasierte Analyse, geeignet für benutzerorientierte Anwendungen
- Praktisches Metadaten- und Tagging-Modell für Filterung und Überprüfung
Enterprise-Funktionen:
Zu diesen Funktionen gehören:
- Protokollstufen: Passen Sie die Ausführlichkeit der Protokolle für granularere Einblicke an.
- Multi-Modalität: Unterstützt Text, Bilder, Audio und andere Formate für multimodale LLM-Anwendungen.
- Releases & Versionierung: Verfolgen Sie den Versionsverlauf und sehen Sie, wie sich neue Releases auf die Leistung des Modells auswirken.
- Trace-URLs: Greifen Sie über eindeutige URLs auf detaillierte Traces zur weiteren Inspektion und zum Debugging zu.
- Agenten-Graphen: Visualisieren Sie Agenteninteraktionen und -abhängigkeiten für ein besseres Verständnis des Agentenverhaltens.
- Sampling: Sammeln Sie repräsentative Daten aus Interaktionen zur Analyse, ohne das System zu überlasten.
- Token- & Kostenverfolgung: Verfolgen Sie Token-Nutzung und Kosten für jeden Modellaufruf und gewährleisten Sie so ein effizientes Ressourcenmanagement.
- Maskierung: Schützen Sie sensible Daten durch Maskierung in Traces und gewährleisten Sie so Datenschutz und Compliance.
Am besten geeignet für: Teams, die an Prompts iterieren und die Nutzung in der Produktion überwachen, insbesondere wenn Benutzersitzungen wichtig sind.
Galileo
Anwendungsfälle: Überwachen Sie Kosten/Latenz, bewerten Sie die Output-Qualität, blockieren Sie unsichere Antworten und bieten Sie umsetzbare Korrekturen.
Galileo verfolgt Kosten-, Latenz- und Output-Qualitätsmetriken und wendet gleichzeitig Echtzeit-Sicherheits- und Compliance-Prüfungen an.
Die Plattform kombiniert traditionelle Observability (Latenz, Kosten, Leistung) mit KI-gestütztem Debugging und Evaluierung (Halluzinationserkennung, faktische Korrektheit, Kohärenz, Kontexttreue).
Galileo-Monitoring-Funktionen
- Identifizierung von Fehlermodi über oberflächliche Fehler hinaus (z. B. Halluzinationen, die zu ungültigen Tool-Eingaben führen)
- Präskriptives Feedback wie vorgeschlagene Prompt-Änderungen oder Few-Shot-Ergänzungen
- Enge Kopplung zwischen Evaluierungsergebnissen und empfohlenen Korrekturen.
Am besten geeignet für: Organisationen, die Output-Qualität, Sicherheit und schnelle Iterationszyklen mit geführter Behebung priorisieren.
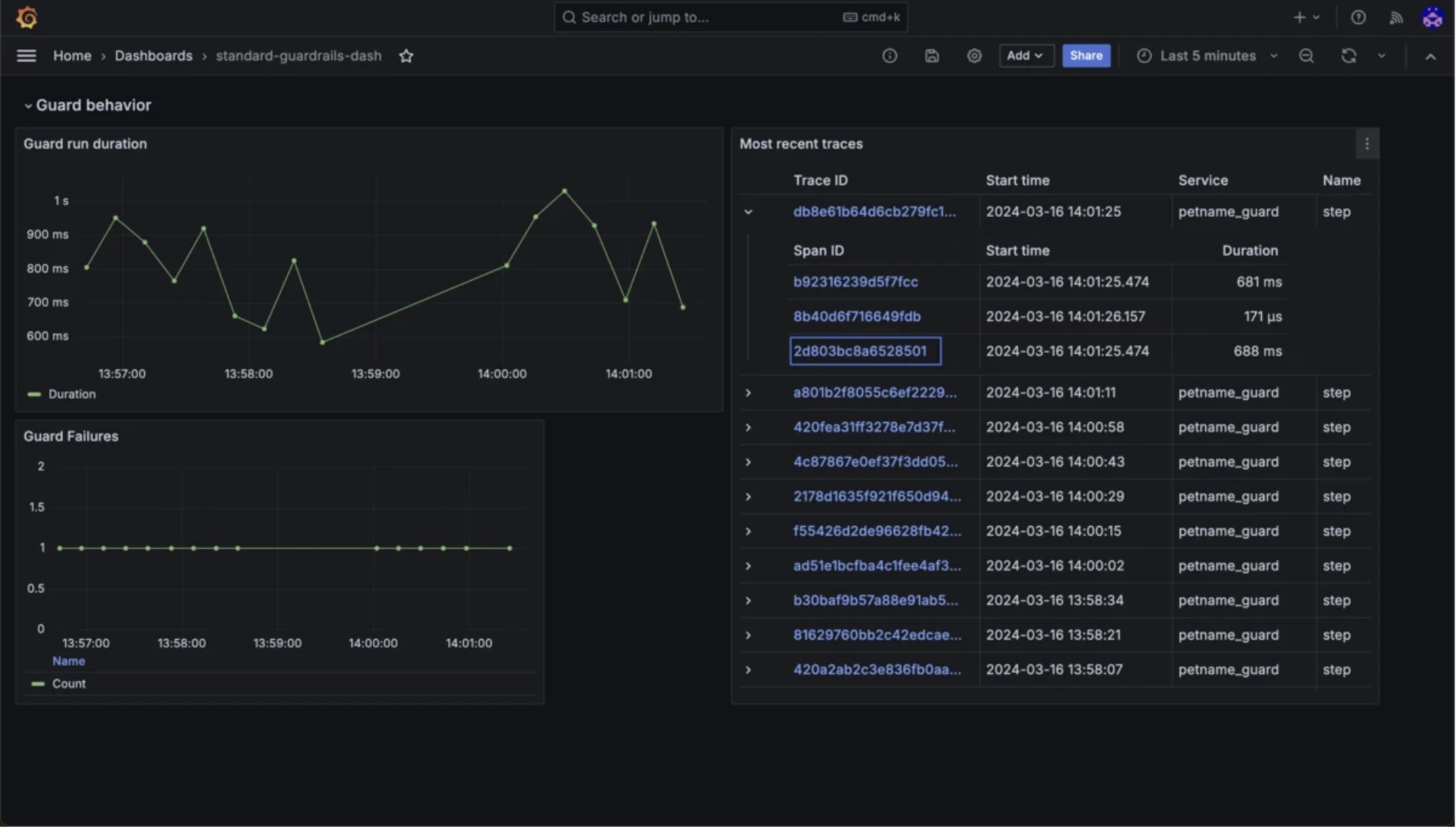
Guardrails KI
Anwendungsfälle: Verhindern Sie schädliche Ausgaben, validieren Sie LLM-Antworten und stellen Sie die Einhaltung von Sicherheitsrichtlinien sicher
Guardrails validiert LLM-Eingaben und -Ausgaben anhand konfigurierbarer Regeln, einschließlich Toxizität, Bias, PII-Offenlegung, Kennzeichnung von Halluzinationen und Format-Compliance.
Guardrails KI-Monitoring-Funktionen
- Deterministische Validierung via RAIL-Spezifikationen
- Eingabe-Guards für Prompt-Injection und Jailbreak-Erkennung
- Automatische Wiederholungen bei Validierungsfehlern.
Am besten geeignet für
Teams, die strenge Sicherheits-, Compliance- oder Formatierungsgarantien durchsetzen müssen, bevor Antworten zurückgegeben werden.
LangSmith
Anwendungsfälle: Agenten-Reasoning und Tool-Call-Debugging (LangChain-zentriert)
LangSmith erfasst vollständige Reasoning-Traces für LangChain-basierte Agenten, einschließlich Prompts, abgerufenem Kontext, Tool-Auswahllogik, Tool-Eingaben/-Ausgaben, Fehlern und Ausnahmen.
LangSmith-Monitoring-Funktionen
- Schritt-für-Schritt-Inspektion der Entscheidungspfade von Agenten
- Run-Wiedergabe und direkter Vergleich über Prompts, Modelle oder Tools hinweg
- Enge Integration mit LangChain via Callbacks.
Am besten geeignet für
Teams, die mit LangChain entwickeln und fehlerhaftes Reasoning oder Tool-Aufrufe im Detail debuggen müssen.
Langtrace KI
Anwendungsfälle: Identifizierung von Kosten- und Latenzengpässen in LLM-Apps
Langtrace verfolgt Token-Anzahlen, Ausführungsdauer, API-Kosten und Anfrageparameter über LLM-Pipelines hinweg unter Verwendung von OpenTelemetry-kompatiblen Traces.
Langtrace KI-Monitoring-Funktionen
- OpenTelemetry-Ausrichtung für Integration mit bestehenden Backends
- Einblick in Kosten- und Latenztreiber pro Schritt
- Leichtgewichtige Prompt-Versionierung und Test-Playground.
Am besten geeignet für: Teams, die Leistung und Kosten über LLM-Workflows hinweg optimieren, anstatt die Output-Qualität zu bewerten.
Arize (Phoenix)
Anwendungsfälle: Überwachen Sie Modell-Drift, erkennen Sie Bias und bewerten Sie LLM-Outputs mit umfassenden Scoring-Systemen
Phoenix konzentriert sich auf Verhaltensdrift, Bias-Erkennung und LLM-als-Richter-Scoring für Relevanz, Toxizität und Genauigkeit.
Allerdings hat es einen höheren Integrations-Overhead im Vergleich zu leichtgewichtigen Proxys und verwaltet die Prompt-Versionierung nicht so sauber wie dedizierte Tools.
Phoenix-Monitoring-Funktionen
- Open-Source-Kern mit optionalen Enterprise-Erweiterungen
- Interaktiver Prompt-Playground für die Entwicklung
- Drift-Erkennung zur Verfolgung von Verhaltensänderungen im Zeitverlauf
- Bias-Prüfungen zur Identifizierung von Antwortverzerrungen,
- LLM-als-Richter-Scoring für Genauigkeit, Toxizität und Relevanz.
Am besten geeignet für: Teams, die langfristiges Modellverhalten und Regressionsrisiken überwachen, anstatt an Prompts zu iterieren.
Agenta
Anwendungsfälle: Herausfinden, welcher Prompt bei welchem Modell am besten funktioniert
Agenta vergleicht Modellantworten hinsichtlich Kosten, Latenz und Output-Qualität unter Verwendung gemeinsamer Eingaben und kontrollierten Kontexts.
Agenta-Monitoring-Funktionen
- Direkter Modellvergleich
- Entscheidungsunterstützung vor der Produktion.
Am besten geeignet für: Frühphasen-Evaluierung und Modellauswahl.
AgentOps.ai
Anwendungsfälle: Agenten-Reasoning überwachen, Kosten verfolgen und Sitzungen in der Produktion debuggen
AgentOps erfasst Reasoning-Traces, Tool-/API-Aufrufe, Sitzungszustand, Caching-Verhalten und Kostenmetriken für eingesetzte Agenten.
AgentOps-Monitoring-Funktionen
- Sitzungswiedergabe für Produktions-Debugging
- Fokus auf Live-Agentenverhalten statt Offline-Evaluierung.
Am besten geeignet für: Teams, die Agenten in der Produktion betreiben und betriebliche Transparenz benötigen.
Braintrust
Anwendungsfälle: Herausfinden, welcher Prompt, Datensatz oder welches Modell mit detaillierter Evaluierung und Fehleranalyse besser abschneidet
Braintrust bewertet Prompts, Datasets und Modelle anhand erwarteter Ausgaben und verfolgt Latenz, Kosten, Tool-Fehler und Ausführungsmetriken.
Braintrust-Monitoring-Funktionen
- Bewerten Sie Test-Datasets mit Eingaben und erwarteten Ausgaben und vergleichen Sie dann Prompts oder Modelle direkt unter Verwendung von Variablen wie
{{input}},{{expected}}und{{metadata}}. - Metrikaufschlüsselungen einschließlich Tool-Ausführungsqualität
Am besten geeignet für: Teams, die Modelle und Prompts vor der Einführung einem Benchmark unterziehen.
AgentNeo
Anwendungsfälle: Debugging von Multi-Agenten-Interaktionen, Nachverfolgung der Tool-Nutzung und Bewertung von Koordinations-Workflows
AgentNeo verfolgt Agentenkommunikation, Tool-Nutzung, Ausführungsgraphen sowie Kosten und Latenz pro Agent über ein Python-SDK.
AgentNeo-Monitoring-Funktionen
- Open-Source und lokal ausführbar
- Interaktives lokales Dashboard (
localhost:3000) für Echtzeit-Monitoring von Multi-Agenten-Workflows. - Integration mittels Decorators (z. B.
@tracer.trace_agent,@tracer.trace_tool)
Am besten geeignet für: Entwicklungsteams, die mit Multi-Agenten-Systemen experimentieren.
Laminar
Anwendungsfall: Verfolgen Sie die Leistung über verschiedene LLM-Frameworks und Modelle hinweg.
Laminar verfolgt Ausführungs-Spans, Kosten, Token-Nutzung und Latenzperzentile über LLM-Frameworks und Modelle hinweg.
Laminar-Monitoring-Funktionen
- Framework-unabhängige Leistungsanalyse
- Feingranulare Span-Inspektion.
Am besten geeignet für: Vergleichende Leistungsanalyse über heterogene Stacks hinweg.
Helicone
Anwendungsfälle: Verfolgen Sie mehrstufige Agenten-Workflows und analysieren Sie Benutzersitzungsmuster.
Helicone erfasst Anfragevolumen, Kosten, Fehler, Latenztrends und Agenten-Workflows auf Sitzungsebene.
Helicone-Monitoring-Funktionen
- Einblick in User Journeys
- Historische Trendanalyse.
Am besten geeignet für: Produktteams, die Nutzungsmuster und Benutzerverhalten überwachen.
Coval
Anwendungsfälle: Simulieren Sie Tausende von Agentenkonversationen, testen Sie Voice-/Chat-Interaktionen und validieren Sie das Verhalten vor der Bereitstellung.
Coval simuliert Tausende von Konversationen, um Aufgabenerfüllung, Korrektheit und Tool-Call-Effektivität zu messen.
Coval-Monitoring-Funktionen
- Simulationsbasiertes Agententesten
- Automatische Regressionserkennung
- Unterstützung für Voice- und Text-Agenten.
Am besten geeignet für: Validierung vor der Bereitstellung und Regressionserkennung.
Datadog
Anwendungsfälle: Infrastruktur- und Anwendungs-Observability mit LLM-Signalkorrelation.
Datadog sammelt Infrastrukturmetriken (CPU, Speicher, Netzwerk), Anwendungsleistungsdaten (Latenz, Fehlerraten, Durchsatz) und Protokolle. Für LLM-Anwendungen kann es Token-Nutzung, Kosten pro Anfrage, Modell-Latenz und sicherheitsrelevante Signale wie Prompt-Injection-Versuche erfassen.
Datadog-Monitoring-Funktionen
- Breite, systemweite Observability über Infrastruktur, Anwendungen und KI-Workloads hinweg
- Großes Integrations-Ökosystem (900+ Integrationen), das die Korrelation zwischen KI-Verhalten und Infrastrukturzustand ermöglicht
Am besten geeignet für: Organisationen, die das Verhalten von LLMs mit der zugrunde liegenden Infrastruktur und Anwendungsleistung korrelieren möchten, anstatt Agenten-Reasoning oder Prompts zu inspizieren
Prometheus
Anwendungsfälle: Überwachen Sie die Systemleistung, verfolgen Sie Anwendungsmetriken und richten Sie Alarmierungen für Infrastrukturprobleme ein.
Prometheus ist ein Open-Source-Überwachungssystem, das Zeitreihenmetriken von HTTP-Endpunkten in regelmäßigen Abständen abruft, um Infrastruktur-, Anwendungs-, Datenbank-, Container- und benutzerdefinierte Geschäftsmetriken zu verfolgen.
Prometheus-Monitoring-Funktionen
- Zeitreihen-Metriksammlung via Pull-basiertes Scraping
- PromQL für Abfragen, Aggregation und Alarmbedingungen
- Exporter-Ökosystem (z. B. Node Exporter) für breite Systemabdeckung
Am besten geeignet für: Infrastruktur- und Anwendungs-Monitoring mit regelbasierter Alarmierung.
Grafana
Anwendungsfälle: Visualisieren Sie Metriken, erstellen Sie Dashboards und leiten Sie Warnmeldungen über LLM-, Agenten- und Infrastrukturdaten hinweg weiter.
Grafana ist eine Open-Source-Visualisierungs- und Analyseplattform, die sich mit Datenquellen wie Prometheus, OpenTelemetry und Datadog integriert, um einheitliche Observability-Dashboards bereitzustellen.
Grafana-Monitoring-Funktionen
- Dashboards für Metriken, Protokolle und Traces
- Systemübergreifende Korrelation für LLM-, Agenten- und Infrastruktursignale
- Alarmierungs-Routing und Benachrichtigungsmanagement.
Am besten geeignet für: Zentrale Observability-Visualisierung und Incident-Response.
Tutorial: LangChain-Observability mit Langfuse
Wir haben eine mehrstufige LangChain-Pipeline mit drei Stufen aufgebaut:
- Fragenanalyse
- Antwortgenerierung
- Antwortverifizierung
Nach dem Einrichten der Pipeline haben wir sie mit Langfuse verbunden, um die Ausführung in Echtzeit zu überwachen und zu verfolgen. Dadurch konnten wir erkunden, wie Langfuse uns hilft, detaillierte Einblicke in die Leistung, Kosten und das Verhalten von KI-Anwendungen zu gewinnen.
Folgendes haben wir durch Langfuse beobachtet:
Dashboard-Übersicht
Langfuse stellte uns mehrere Dashboards zur Verfügung, die uns Einblicke in verschiedene Aspekte der Pipeline-Leistung geben:
- Kosten-Dashboard: Dieses verfolgt die Ausgaben über alle API-Aufrufe hinweg, mit detaillierten Aufschlüsselungen nach Modell und Zeitraum.
- Nutzungsmanagement: Es überwacht Ausführungsmetriken wie Beobachtungszahlen und Ressourcenzuweisung und hilft uns, die Ressourcennutzung während der Ausführung zu verfolgen.
- Latenz-Dashboard: Dieses Dashboard half uns, Antwortzeiten zu analysieren, Engpässe zu erkennen und Leistungstrends zu visualisieren.
Nutzungsmetriken
Das Nutzungsmetriken-Dashboard gab uns folgende Einblicke in die Systemleistung:
- Gesamt-Trace-Anzahl: Wir verfolgten acht Traces, von denen jeder einen vollständigen Frage-Antwort-Zyklus in der Pipeline darstellt.
- Gesamt-Beobachtungszahl: Im Durchschnitt hatte jeder Trace 16 Beobachtungen, was den mehrstufigen Charakter des Prozesses widerspiegelt.
Darüber hinaus ermöglicht uns Langfuse, Nutzungsmuster, Ressourcenzuweisung und Spitzenzeiten über die letzten 7 Tage zu verfolgen, was uns hilft zu verstehen, wann das System am aktivsten ist und wie Ressourcen über die Zeit verteilt werden.
Trace-Inspektion
Beim Drilldown in einen einzelnen Trace konnten wir detaillierte Ausführungsinformationen sehen:
- Trace-Zeilen: Jede Zeile repräsentiert eine vollständige Pipeline-Ausführung mit einer eindeutigen Trace-ID.
- Latenzmetriken: Die Ausführungszeit variierte und reichte von 0.00s bis 34.08s.
- Token-Anzahlen: Das Dashboard verfolgte die Eingabe-/Ausgabe-Token-Nutzung, was beim Kosten- und Effizienzmanagement hilft.
- Umgebungsfilterung: Wir konnten Traces basierend auf Bereitstellungsumgebungen filtern (z. B. Entwicklung, Produktion).
Individuelle Trace-Details
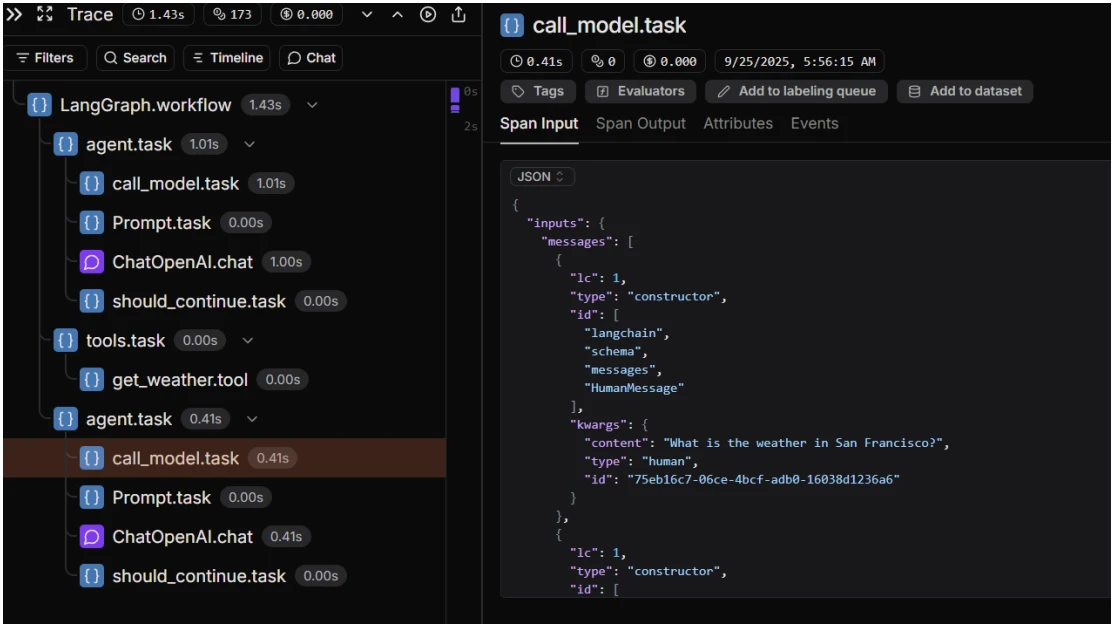
Wir haben den Trace weiter im Detail untersucht, um die Ausführungsaufschlüsselung zu verstehen:
- Sequenzielle Kettenarchitektur: Der Trace zeigte einen visuellen Ablauf, der jeden Schritt darstellt, beginnend mit SequentialChain → LLMChain → ChatOpenAI, mit hierarchischer Struktur.
- Eingabe-/Ausgabe-Verfolgung: Die ursprüngliche Frage „What are the benefits of using Langfuse for KI agent observability?“ wurde in jeder Phase zusammen mit den jeweiligen Ausgaben, die KI in jedem Schritt produzierte, verfolgt.
- Token-Analyse: Wir beobachteten, dass 1.203 Tokens für die Eingabe und 1.516 Tokens für die Ausgabe verwendet wurden, was Kostenauswirkungen im Zusammenhang mit der Token-Nutzung hat und zur Optimierung des Ressourcenmanagements beiträgt.
- Zeitmessungsdaten: Die Gesamtlatenz für den vollständigen Trace betrug 34.08s, aufgeschlüsselt über jede Komponente:
- SequentialChain → 14.02s
- LLMChain → 10.25s
- ChatOpenAI → 9.81s
- Modellinformationen: Langfuse bestätigte die Verwendung des Modells Anthropic Claude-Sonnet-4, mit Details zu den spezifischen Einstellungen, einschließlich der Temperaturkonfiguration.
- Formatierte Ausgabe: Sowohl die Vorschau- als auch die JSON-Ansicht wurden für das Debugging bereitgestellt und gaben Einblicke in die Antwort des Modells in menschenlesbarer Form und maschinenlesbarem Format.
Automatisierte Analyse
Langfuse lieferte auch automatisierte Bewertungen unserer Antworten:
- Qualitätsbewertung: Das System bewertete die Struktur, Kohärenz und Vollständigkeit der Antworten und hob gut organisierte Abschnitte hervor, wies jedoch darauf hin, dass die Antworten prägnanter sein könnten.
- Verbesserungsvorschläge: Es identifizierte Abschnitte mit Redundanz und schlug vor, wo Formulierungen verbessert werden könnten, und kombinierte verwandte Punkte, um die Antwort transparenter und effizienter zu gestalten.
- Leistungseinblicke: Das System gab Feedback zur Token-Nutzung und Antwortrelevanz und half uns, die Effizienz zu optimieren, während die Ausgabe hilfreich und themenbezogen bleibt.
- Strukturiertes Feedback: Das Feedback war in Kategorien gegliedert, sodass wir bestimmte Verbesserungsbereiche gezielt angehen konnten.
Benutzeranalysen
Langfuse verfolgt detaillierte Interaktionen zwischen Benutzern und dem KI-Agenten:
- Benutzeraktivitätszeitachse: Zeigt die erste und letzte Interaktion für jeden Benutzer an und hilft, aktive von inaktiven Benutzern zu unterscheiden. Wir können sehen, wann Benutzer zum ersten und letzten Mal mit dem System interagiert haben.
- Ereignisvolumen-Verfolgung: Verfolgt die Anzahl der Ereignisse, die jeder Benutzer ausgelöst hat. Einige Benutzer generierten beispielsweise über 2.000 Ereignisse, was ihr Engagement-Niveau mit dem System zeigt.
- Token-Verbrauchsanalyse: Überwacht die Gesamtzahl der von jedem Benutzer verbrauchten Tokens. Die Token-Nutzung reichte von 6.59K bis 357K Tokens und lieferte Einblicke in die Ressourcennutzung.
- Kostenzuordnung: Schlüsselt die mit jedem Benutzer verbundenen Kosten auf und erleichtert so die Verfolgung von Ausgaben und die Optimierung der Budgetzuweisung für die Ressourcennutzung.
- Benutzeridentifikation: Verwendet anonymisierte Benutzer-IDs, um die Privatsphäre zu wahren und gleichzeitig individuelle Benutzerinteraktionen zu verfolgen, was bei der Nutzungsanalyse hilft, ohne die Vertraulichkeit der Benutzer zu gefährden.
Die Sitzungsansicht ermöglicht es uns, granulare Details von Benutzerinteraktionen zu verfolgen:
- Vollständiger Konversationsablauf: Zeigt die vollständige Frage-Antwort-Interaktion und erleichtert es, die gesamte Konversation von Anfang bis Ende zu verfolgen.
- Implementierungstransparenz: Zeigt den tatsächlich während der Sitzung verwendeten Python-Code an und bietet Einblick in die technische Implementierung.
- Eingabe-/Ausgabe-Korrelation: Verknüpft Benutzerfragen mit den entsprechenden Systemantworten und hilft uns, Probleme zu beheben und zu identifizieren, wo in der Konversation Probleme aufgetreten sein könnten.
- Sitzungsmetadaten: Enthält technische Details wie Zeitmessung, Benutzerkontext und spezifische Implementierungsdaten und bietet einen umfassenden Überblick über die Ausführung der Sitzung.
Wann man keine Observability-Tools verwenden sollte
- Frühphasenentwicklung: Wenn Sie noch den Product-Market-Fit validieren oder Ihre ersten Agenten-Workflows aufbauen, sollte der Fokus auf der Kernfunktionalität liegen und nicht auf umfassender Observability.
- API-Engpässe: Wenn Ihre Hauptprobleme API-Kosten, Latenz oder Caching sind, sollte die unmittelbare Priorität die Optimierung dieser Bereiche sein, nicht die Verfolgung von Metriken auf Systemebene.
- Modelloptimierung: Wenn Verbesserungen hauptsächlich durch Modellauswahl, Fine-Tuning oder Prompt Engineering erzielt werden, sind Observability-Tools für Drift und Bias möglicherweise noch nicht erforderlich.
Wann man Observability-Tools verwenden sollte
- Produktion im großen Maßstab: Wenn Sie über mehrere Modelle, Agenten oder Ketten hinweg arbeiten, sind Observability-Tools unerlässlich, um die Leistung zu überwachen und die Systemgesundheit sicherzustellen.
- Enterprise- oder kundenorientierte Anwendungen: Für Anwendungen, bei denen Zuverlässigkeit, Sicherheit und Compliance unverhandelbar sind, bieten Observability-Tools die erforderliche Transparenz und Kontrolle.
- Kontinuierliche Überwachung: Wenn Sie Drift, Bias, Leistung und Sicherheitsprobleme im Laufe der Zeit überwachen müssen, die mit einfachen Skripten oder manuellen Prüfungen nicht leicht erfasst werden können, sind Observability-Tools entscheidend.
- Hochrisiko-Szenarien: In Umgebungen, in denen die Kosten eines Fehlers (z. B. Halluzinationen, unsichere Ausgaben) erheblich sind, stellt Observability sicher, dass Risiken minimiert und Probleme frühzeitig erkannt werden.
Benchmark-Methodik
Um den Performance-Overhead von Observability-Plattformen in produktiven LLM-Anwendungen zu bewerten, haben wir einen systematischen Benchmarking-Ansatz unter Verwendung eines realen agentischen Workflows entwickelt.
Testanwendung
Wir haben ein sequenzielles Multi-Agenten-Reiseplanungssystem mit LangChain aufgebaut, das natürliche Sprachanfragen für Reisen in fünf Stufen verarbeitet:
- Parser-Agent: Extrahiert strukturierte Daten (Herkunft, Ziel, Daten, Dauer) aus Benutzereingaben
- Flugfinder-Agent: Ruft verfügbare Flüge über die Amadeus-API ab
- Wetterreporter-Agent: Ruft Wettervorhersagen für das Ziel mit WeatherAPI ab
- Aktivitätsempfehlungs-Agent: Schlägt Aktivitäten basierend auf den Wetterbedingungen vor
- Reiseplaner-Agent: Synthetisiert alle Ausgaben zu einer umfassenden Reiseroute
Das System verwendet Claude 4 Haiku über OpenRouter für alle LLM-Aufrufe und integriert externe APIs für Echtzeitdaten.
Benchmark-Design
Baseline-Etablierung: Wir haben zunächst die Leistung der Anwendung ohne jegliche Observability-Instrumentierung gemessen und 100 identische Anfragen ausgeführt, um eine Baseline für den Vergleich zu etablieren.
Plattformintegration: Anschließend haben wir fünf führende Observability-Plattformen (LangSmith, Laminar, AgentOps, Langfuse) nacheinander integriert und aus Konsistenzgründen dieselben Tracing-Punkte auf allen Plattformen instrumentiert.
Sequenzielle Ausführung: Jede Plattform wurde unabhängig getestet, indem alle 100 Anfragen nacheinander ausgeführt wurden, bevor zur nächsten Plattform übergegangen wurde. Dieser Ansatz minimiert die Variabilität durch externe Faktoren wie Netzwerkbedingungen oder API-Ratenlimits.
Kontrollierte Umgebung: Alle Tests wurden auf derselben Serverinfrastruktur mit identischen Anfragesätzen ausgeführt, um einen fairen Vergleich zu gewährleisten. Um den Overhead von LLM-bedingten Latenzschwankungen zu isolieren, haben wir das Modell mit Temperatur=0 und strukturierten Prompts konfiguriert, um die Antwortvariabilität zwischen den Durchläufen zu minimieren.
Erfasste Metriken
Für jede Plattform haben wir die durchschnittliche Latenz gemessen und den Overhead als die zusätzlich eingeführte Latenz im Vergleich zur Baseline berechnet: ((Platform Latency - Base Latency) / Base Latency) × 100
FAQs
Observability ist die Fähigkeit, das Innenleben eines KI-Agenten zu verstehen, indem externe Signale wie Protokolle, Metriken und Traces untersucht werden.
Für KI-Agenten umfasst dies die Überwachung von Aktionen, Tool-Nutzung, Modellinteraktionen und Antworten, um die Leistung zu beheben und zu verbessern.
Agenten-Observability ist entscheidend für die Verfolgung und Verbesserung der KI-Leistung, indem sie Folgendes ermöglicht:
Verständnis von Kompromissen: Sie hilft, Schlüsselmetriken wie Genauigkeit und Kosten zu messen und erleichtert es, ein Gleichgewicht zwischen Leistung und Ressourcennutzung zu finden.
Latenzmessung: Echtzeit-Latenzverfolgung bietet Einblicke in Antwortzeiten und hilft, die Agentenleistung zu optimieren.
Erkennung bösartiger Eingaben: Observability hilft, schädliche Sprache und Prompt-Injections zu identifizieren und ermöglicht rechtzeitige Interventionen, um Probleme zu verhindern.
Überwachung von Benutzerfeedback: Durch die Beobachtung von Benutzerinteraktionen und Feedback liefert Observability wertvolle Daten für kontinuierliche Verbesserung und Fine-Tuning von Agenten.
Zu den Schlüsselkomponenten gehören:
– Verfolgung von Aktionen: Überwachung jedes vom Agenten ausgeführten Schritts.
– Tool-Nutzung: Beobachtung der vom Agenten verwendeten Tools und Ressourcen.
– Latenzmessung: Überwachung der Antwortzeiten zur Leistungsoptimierung.
– Evaluierungen: Bewertung des Agentenverhaltens und der Modellleistung.
– Erkennung bösartiger Eingaben: Identifizierung schädlicher Prompts oder Angriffe.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{15 KI-Agenten-Observability-Tools: AgentOps & Langfuse}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-monitoring}},
note = {AIMultiple. Abgerufen am 2. Juli 2026}
}














.")





Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.