Top 5 Open-Source-Frameworks für agentische KI
Wir haben 4 beliebte Open-Source-Agentic-Frameworks über 2,000 Durchläufe (5 Aufgaben, 100 Durchläufe pro Framework) getestet und dabei die End-to-End-Latenz, den Token-Verbrauch und architektonische Unterschiede gemessen.
Benchmark der agentischen KI-Frameworks
Wir haben untersucht, wie die Frameworks selbst das Agentenverhalten beeinflussen und welche Auswirkungen dies auf Latenz und Token-Verbrauch hat.
LangGraph ist das schnellste Framework mit den niedrigsten Latenzwerten über alle Aufgaben hinweg, während LangChain die höchste Latenz und den höchsten Token-Verbrauch aufweist.
Über 5 Aufgaben und 2,000 Durchläufe hinweg erweist sich LangChain als das token-effizienteste Framework, während AutoGen in der Latenz führend ist; LangGraph und LangChain folgen dicht dahinter. CrewAI weist das insgesamt schwerste Profil auf.
Aufgabe 1: Einfache Aggregation
Zunächst haben wir den Overhead jedes Frameworks gemessen, wenn es ein einzelnes Tool aufruft und das Ergebnis zurückgibt, ohne komplexes Reasoning durchzuführen.
LangChain & LangGraph: Bei einfachen Aufgaben sind sie fast so schnell wie nicht-agentischer Code, beide wurden unter 5 Sekunden mit weniger als 900 Prompt-Tokens fertig. Die Zustandsautomaten-Architektur von LangGraph verursacht bei dieser einfachen Komplexität keine spürbare Latenz im Vergleich zu LangChain; der Overhead der Zustandsverwaltung manifestiert sich erst bei steigender Aufgabenkomplexität.
AutoGen: Liegt leicht über LangChain und LangGraph in Bezug auf Latenz und Token-Verbrauch, was die grundlegenden Kosten der Multi-Agenten-Konversationsschleife widerspiegelt, bei der zwei Agenten selbst für eine Ein-Schritt-Aufgabe Nachrichten austauschen.
CrewAI: Selbst wenn es nur einen einzigen Tool-Aufruf tätigen soll, zeigt es einen sogenannten „Management-Overhead“ und verbraucht fast das Dreifache der Tokens von LangChain und dauert fast dreimal so lange. Der mehrstufige Verifikationsprozess zwischen seinen Planner- und Analyst-Personas bietet einen gründlichen, aber ressourcenintensiven Ansatz, der Vollständigkeit über Geschwindigkeit stellt. Diese Kosten sind strukturell und treten unabhängig von der Aufgabenkomplexität auf.
Aufgabe 2: Vergleichende Umsatzanalyse (Zustandsverwaltung)
In Aufgabe 2 wollten wir die Fähigkeit der Frameworks prüfen, zwei unterschiedliche Filtergruppen im Speicher zu halten (Zustandspersistenz) und zu kombinieren.
CrewAI
Bei unserer Log-Analyse haben wir festgestellt, dass CrewAI unter den Frameworks die höchste Infrastruktur-Transparenz bietet, allerdings auf Kosten des höchsten Ressourcenverbrauchs.
Anstatt abgerufene Daten sofort zurückzugeben, validiert CrewAI wiederholt seine eigenen Prozesse durch einen Selbstüberprüfungsmechanismus. Dieses explorative Verhalten führte dazu, dass es das konfigurierte Limit von max_iter=10 erreichte, sodass einige Durchläufe in einer endlosen Denkschleife stecken blieben, ohne eine JSON-Ausgabe zu produzieren.
Die Ursache für dieses Verhalten ist, dass CrewAI mehrschichtige Anweisungen in den System-Prompt einfügt, jedem Agenten eine Rolle, ein Ziel und einen Hintergrund zuweist und dabei eine ReAct-artige Gedanke → Aktion → Beobachtung-Schleife bei jedem Schritt erzwingt. Selbst bei einfachen Aufgaben kann der LLM diese Zeremonie nicht überspringen und produziert pflichtbewusst ausführliche interne Monologe, was sich in Multi-Agenten-Szenarien weiter verschärft.
CrewAI verbrauchte fast das Doppelte an Tokens der anderen Frameworks und benötigte über dreimal so lange wie LangChain, was es eher für komplexe Zustandsübergänge und multifaktorielle Entscheidungsfindung geeignet macht als für unkomplizierte Datenabrufaufgaben.
LangChain
Das schnellste und kosteneffizienteste Framework. In unseren Logs haben wir beobachtet, dass LangChain die Aufgabe in 5-6 Schritten ohne Umwege erledigt: Laden → Filtern → Berechnen → Filtern → Berechnen → Ausgabe. Da seine Zustandsverwaltung sehr einfach ist, ist der Overhead nahezu null und die Latenz die niedrigste unter allen Frameworks.
AutoGen
Lieferte eine sehr ausgewogene Leistung. In Aufgabe 2 entsprach es LangGraph nahezu exakt sowohl beim Token-Verbrauch als auch bei der Latenz und zeigte, dass der Overhead der Konversationsschleife sich nicht signifikant erhöht, wenn die Aufgabenkette linear bleibt.
Allerdings fügt es gelegentlich einen zusätzlichen Verifikationsschritt hinzu, um Parameter während des Tool-calling-Prozesses zu bestätigen, wodurch es etwas langsamer als LangChain ist. Wenn es auf einen Fehler bei einem Tool-Aufruf stößt oder die Daten nicht wie erwartet zurückkommen, aktualisiert es sofort seine Argumentation im nächsten Schritt und gelangt zum korrekten JSON. Da es Tool-Ausgaben als Konversationsfluss behandelt, ist es eines der widerstandsfähigsten Frameworks gegenüber logischen Fehlern.
LangGraph
In dieser Aufgabe ist LangGraph aufgrund seiner graphbasierten Architektur das stabilste Framework. In seinen Logs beobachteten wir, dass der Zustand während des gesamten Durchlaufs sehr sauber übertragen wird. Das Risiko von Datenkontamination oder dass sich Segmente gegenseitig beeinflussen, ist bei diesem Framework auf dem niedrigsten Niveau. Über alle 100 Durchläufe lieferte es Ergebnisse in nahezu derselben Anzahl von Schritten und innerhalb desselben Latenzbereichs.
Aufgabe 3: Schwellenwert-Parsing (numerische Disziplin)
In dieser Aufgabe wollten wir prüfen, wie genau die Frameworks natürlichsprachliche numerische Bedingungen wie „weniger als 1 Jahr Betriebszugehörigkeit“ und „mehr als $70 monatliche Gebühren“ in präzise Tool-Parameter wie tenure_max=12 und charges_min=70.0 übersetzen.
Der LLM weiß, wie man diese Konvertierung vornimmt; was wir wirklich testen wollten, war, ob das Framework diese Parameter während seiner eigenen Wiederholungsmechanismen, des Re-Prompt-Kontextes und seiner Zustandsverwaltungszyklen beibehalten kann.
LangChain & LangGraph
Beide Frameworks übergaben die Parameter (tenure_max=12, charges_min=70) direkt an das Tool, genau so, wie der LLM sie produzierte, ohne jegliche Änderung oder Re-Prompt-Schleife. Diese Effizienz zeigt sich in den Zahlen: beide Frameworks schlossen Aufgabe 3 in unter 9 Sekunden mit weniger als 1,800 Prompt-Tokens ab, dem niedrigsten Wert in dieser Aufgabe.
Als wir messen wollten, ob numerische Schwellenwerte ohne Eingriff des Frameworks erhalten bleiben, erfüllten diese beiden unsere Erwartungen: Welcher Parameter auch generiert wurde, genau dieser wurde ausgeführt.
AutoGen
AutoGen ist bei der numerischen Korrektheit vollkommen erfolgreich. In einigen Durchläufen wurde beobachtet, dass das Framework einen Verifikationsschritt hinzufügte, bevor es den vom LLM generierten Parameter an das Tool übergab, d.h. das Framework verbrauchte einen zusätzlichen Schritt, während es den Parameter beibehielt. Mit 2,480 Tokens und 8 Sekunden entsprach es der Latenz von LangChain trotz des zusätzlichen Schrittes, was bestätigt, dass der Verifikations-Overhead real, aber gering ist. Es erfüllte unsere Erwartungen hinsichtlich der Parameterintegrität, wobei der Bestätigungsschritt lediglich marginale Token-Kosten verursachte und keine nennenswerte zusätzliche Latenz.
CrewAI
Das auffälligste Verhalten zeigte CrewAI, das Aufgabe 3 in 30 Sekunden mit 4,360 Tokens abschloss, dem höchsten Wert in dieser Aufgabe. Aus der Log-Analyse gingen zwei unterschiedliche Fehlermuster hervor.
In einigen Durchläufen wurde ein Wert, der 68.81% hätte sein sollen, als 0.6878 (Dezimalverhältnis) zurückgegeben. Dies deutet darauf hin, dass die Ausgabeserialisierung des Frameworks den Kontext der LLM-Ausgabe entfernen kann.
Die Logs zeigen, dass der LLM zunächst die korrekten Parameter tenure_max=12 und charges_min=70 produzierte. Sobald CrewAI jedoch in eine „Failed to parse“-Schleife geriet, drängte das Framework den LLM, dies erneut zu überdenken. Im Re-Prompt-Kontext verschob der LLM den Schwellenwert auf tenure_max=14 und deaktivierte den Filter charges_min vollständig, was eine Abwanderungsrate von 46.84% erzeugte, was tatsächlich der Abwanderungsrate aller Kunden mit einer Betriebszugehörigkeit von weniger als 14 entspricht. Dies war genau das Szenario, das wir beobachten wollten: Der Wiederholungsmechanismus des Frameworks kann einen Parameter korrumpieren, den der LLM ursprünglich richtig erfasst hatte.
Aufgabe 4: Fehlerresilienz und Wendefähigkeit
In dieser Aufgabe wollten wir prüfen, wie jedes Framework mit disruptiven Szenarien umgeht, und die Auswirkungen auf Latenz und Token-Verbrauch beobachten. Das Tool wirft nacheinander 3 verschiedene Fehlertypen (Netzwerk, Timeout, Rate Limit) und drängt den Agenten in die Enge. Die ersten beiden Fehler weisen den Agenten an, es erneut zu versuchen, und nachdem er beide erneut versucht hat, teilt der eingehende Rate-Limit-Fehler dem Agenten mit, 10 Sekunden zu warten. Sobald der Agent gewartet und es erneut versucht hat, funktioniert das Tool normal.
LangGraph & AutoGen
Diese beiden Frameworks fanden autonom alternative Lösungen, als sie in dieser Aufgabe mit Tool-Ausfällen konfrontiert wurden.
Als das Tool eine Rate-Limit-Warnung zurückgab, entschieden diese Agenten, anstatt zu pausieren und zu warten, das fehlerhafte Tool ganz aufzugeben und einen alternativen Pfad zu finden. Ihr Ansatz war: „Da dieses Tool nicht funktioniert, filtere ich jede Zahlungsmethode einzeln, berechne die Abwanderungsrate für jede separat und kombiniere die Ergebnisse dann selbst.“
Methode: Anstatt die Aufgabe mit einem einzigen Tool-Aufruf zu erledigen, zerlegten sie, indem sie zwei separate Tools verwendeten – eines zum Filtern und eines zum Berechnen – und jede Zahlungsmethode (Electronic check, Mailed check usw.) einzeln verarbeiteten.
Diese Agenten arbeiten mit zielorientiertem Denken und nicht mit Pfadabhängigkeit. Wenn der kürzeste Pfad nicht verfügbar ist, können sie innerhalb von Sekunden einen alternativen Ausführungsplan konstruieren.
LangGraph erreichte in Aufgabe 4 15,010 Prompt-Tokens, die höchste Token-Anzahl für eine einzelne Aufgabe im gesamten Benchmark, weil seine Zustandsmaschine die wachsende Historie jedes manuellen Tool-Aufrufs bei jedem Schritt wieder in den Kontext einbrachte. AutoGen folgte mit 10,750 Tokens, etwas geringer aufgrund seiner konversationellen Handhabung von Zwischenergebnissen. Trotzdem endeten beide bei etwa 24-27 Sekunden, was bestätigt, dass die zusätzlichen Token-Kosten nicht zu einer nennenswerten Latenz führten, weil der Wechsel selbst schnell erfolgte.
CrewAI
Trotz des höchsten Token-Verbrauchs in den vorherigen Aufgaben wies CrewAI in dieser Aufgabe den niedrigsten Token-Verbrauch, aber die höchsten Latenzwerte auf.
Warum die niedrigste Token-Anzahl?
CrewAI durchlief nicht wie seine Konkurrenten einen 10-15 Schritte umfassenden manuellen Workaround. Als es auf Fehler stieß, pumpte es nicht wiederholt die gesamte Historie und komplexe Zwischendaten bei jedem Schritt zurück in den LLM, sondern baute eine fokussiertere, modulare Denkschleife auf. Durch die Vermeidung unnötiger Ausführlichkeit wurde es in dieser Aufgabe zum kosteneffizientesten Framework.
Warum eine hohe Latenz?
Die Management-orientierte Struktur von CrewAI pausiert und überdenkt den Plan, wenn ein Fehler auftritt. Als es die 10-Sekunden-Warnung erhielt, verbrachte es mehr Zeit in der „Strategieplanungs“-Phase. Anstatt auf ein anderes Tool zum Filtern auszuweichen, entschied es sich hartnäckig dafür, auf die Wiederherstellung des Haupttools zu warten oder es mit dem stabilen Tool zu versuchen, was die Gesamtdauer verlängerte.
LangChain
LangChain durchlief in dieser Aufgabe seine größte Transformation und bewies, warum Resilienz von der richtigen Konfiguration abhängt.
In unserem ersten Durchlauf stürzte LangChain bei jedem einzelnen Versuch mit einem ConnectionError ab.
Der standardmäßige AgentExecutor von LangChain behandelt rohe Python-Ausnahmen, die aus einem Tool geworfen werden, als fatale Fehler und beendet den Prozess. Im Gegensatz zu seinen Konkurrenten wendet es standardmäßig keine „Fehler sind Beobachtungen“-Philosophie an. Da der Agent den Fehler nie sieht, hat er keine Chance, darüber nachzudenken.
Wir haben den Tool-Aufruf in langchain_agent.py mit einem try-except-Block umschlossen. Dadurch wurde der Fehler in eine lesbare Nachricht konvertiert, die der Agent verarbeiten konnte.
Verhalten nach der Korrektur: Nachdem die Korrektur angewendet wurde, beobachteten wir in den Logs von LangChain, dass es genau dieselbe Argumentation wie LangGraph zeigte. Es erhielt 3 Fehler vom Tool, wechselte sofort die Strategie und nutzte zwei separate Tools – eines zum Filtern und eines zum Berechnen –, verarbeitete jede Zahlungsmethode einzeln und kombinierte die Ergebnisse.
LangChain ist tatsächlich genauso fähig und anpassungsfähig wie LangGraph, aber weil die Fehlerbehandlung des Frameworks standardmäßig deaktiviert war, hatte es keine Gelegenheit, diese Fähigkeit zu demonstrieren. Sobald es richtig konfiguriert war, erreichte es das korrekte Ergebnis mit demselben alternativen Pfadansatz.
Warum traten diese Unterschiede auf? (Analyse der Framework-Architektur)
Wenn das Agentenverhalten ausschließlich vom LLM (GPT-5.2) abhinge, hätten sich alle Frameworks ähnlich verhalten sollen. Die deutlichen Unterschiede in diesen Verhältnissen sind jedoch in den eigenen inneren Schleifenmechanismen der Frameworks begründet:
1. LangGraph & AutoGen (90% Schwenk):
LangGraph arbeitet mit einer Zustandsautomaten-Architektur, während AutoGen ein konversationsbasiertes Modell nutzt. In beiden Systemen werden Fehler als Feedback-Schleife verarbeitet. In LangGraph gibt der Zustand, der den Fehler empfängt, an den nächsten Knoten weiter; in AutoGen leitet der Proxy-Agent den Fehler als Chat-Nachricht an den Assistenten weiter. Dieser ständige Anstups-Mechanismus zwingt den Agenten, weiter nach einer Lösung zu suchen. Da der Agent wiederholt mit der Frage „Ich habe einen Fehler erhalten, was soll ich tun?“ konfrontiert wird, steigt die Wahrscheinlichkeit, dass er einen alternativen manuellen Weg einschlägt, auf 90%.
2. LangChain (65% Schwenk / 35% Warten):
LangChain läuft auf einer sequentiellen AgentExecutor-Architektur. Selbst mit vorhandener Fehlerbehandlung hat die Ausführungsschleife eine linearere Struktur und ist primär auf die Erzeugung einer finalen Antwort ausgerichtet. Wenn das Tool für 3-4 Schritte Fehler wirft, zieht es LangChain manchmal vor, auf einen erfolgreichen nächsten Versuch des Tools zu warten oder ein Ergebnis aus dem vorhandenen Kontext zu produzieren, anstatt auf eine alternative Strategie umzuschwenken. Weil die Zustandsverriegelung von LangChain flexibler ist als die von LangGraph, liegt sein Warten/Direktlösungs-Verhältnis bei etwa 35%.
3. CrewAI (0% Schwenk):
CrewAI arbeitet mit einer managementorientierten Prozessarchitektur. Seine Agenten sind in Rollen- und Aufgabendefinitionen eingebettet. Wenn Fehler auftreten, löst seine interne Architektur typischerweise Selbstkorrektur- oder Wiederholungslogik aus. Ein radikaler Strategiewechsel wie „Lass uns den gesamten Plan verwerfen und in 5 Schritten manuell filtern“ steht jedoch im Konflikt mit der managementbasierten Planstruktur von CrewAI. Es arbeitet nach der Disziplin „Ich sollte das mir gegebene Tool reparieren oder die nächstliegende Alternative nutzen“, anstatt seinen Plan vollständig aufzugeben. Dies ist im Kern ein planzentrierter Ansatz im Gegensatz zu einem zielzentrierten.
Aufgabe 5: Orchestrierung unstrukturierter Daten (Routing unstrukturierter Daten)
In Aufgabe 5 beobachteten wir, wie sich die Frameworks verhalten, wenn sie innerhalb einer CSV auf JSON- und Lange-Text-Spalten (LongText) stoßen. Die Agenten mussten zunächst den Datentyp dieser Spalten erkennen und dann die richtigen Verarbeitungstools entweder sequentiell oder parallel auswählen.
In der realen Welt erfordert das Management unstrukturierter Daten, dass ein Agent über standardmäßige tabellarische Daten hinausgeht und mit JSON-Blobs, kostenlos-Text-Abschnitten oder verschachtelten Objekten arbeitet.
Damit ein Framework diese Art von Daten korrekt handhaben kann, muss es zwei Dinge gut beherrschen:
1- eine Erkennungsintelligenz, die versteht, welches Tool zu welchem Datentyp passt
2- einen Orchestrierungsmechanismus, der mehrere unabhängige Tool-Aufrufe koordiniert.
Wir haben Aufgabe 5 speziell darauf ausgelegt, diese beiden Fähigkeiten getrennt zu messen.
AutoGen
AutoGen lieferte in dieser Aufgabe eine starke Leistung und schloss mit 8,170 Prompt-Tokens und einer medianen Latenz von 47 Sekunden ab, dem schnellsten und token-effizientesten Ergebnis in Aufgabe 5.
Die Konversationsschleife im Kern seiner Architektur, das Messaging zwischen AssistantAgent und UserProxyAgent, wird normalerweise als eine Struktur angesehen, die zu Ausführlichkeit führt. In Aufgabe 5 jedoch wurde diese Struktur zu einem Vorteil.
Indem der LLM den Konversationsverlauf betrachtete, erkannte er, dass die Spalten Metadata und SupportNotes unabhängig voneinander waren. Daraufhin sendete er eine einzige TOOL CALLS-Antwort, die 4 Tools gleichzeitig auflistete: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…) und summarize_text_column(…) wurden alle parallel ausgeführt. Dadurch konnte die Aufgabe in 3 LLM-Runden mit den wenigsten Tokens und den wenigsten Schritten abgeschlossen werden.
Der technische Grund für dieses Verhalten ist klar: Die Tool-Ausführungs-Engine von AutoGen verarbeitet die vom LLM zurückgegebene tool_calls-Liste atomar und sammelt die Ergebnisse in einem einzigen Konversationsschritt. Die Philosophie des Frameworks „die Konversation zu managen“ erlaubt es, mehrere parallele Kanäle gleichzeitig zu öffnen, und die Token- und Latenzzahlen bestätigen dies unmittelbar.
LangGraph
LangGraph schloss mit 9,150 Prompt-Tokens und einer medianen Zeit von 70 Sekunden ab, nahe bei AutoGen in Bezug auf Tokens, aber langsamer in der Zeit. Seine Zustandsautomaten-Architektur zeigte in Aufgabe 5 zugleich ihre größte Stärke und ihre auffälligste Schwäche.
In jedem Durchlauf akkumuliert der llm node → tools node → llm node-Loop alle vorherigen Tool-Ausgaben im Zustand und übergibt sie an den LLM. Diese Struktur garantiert, dass der Agent niemals etwas vergisst, was normalerweise ein bedeutender Vorteil ist.
In Aufgabe 5 jedoch wirkte diese Stärke gegen ihn. LangGraph fand die richtigen Tools und baute das richtige Segment. Aber selbst nachdem die Analyse abgeschlossen war, erkannte es Unklarheiten im akkumulierenden Zustand, interpretierte abgeschlossene Schritte als noch ausstehend und löste wiederholt zusätzliche Tool-Aufrufe aus. Obwohl es die notwendigen Daten bereits abgerufen hatte und kurz davor stand, die richtige Antwort zu liefern, sprang das Signal „fehlender Schritt“ der Zustandsmaschine an und der Agent geriet in unnötige Schleifen. Infolgedessen lag die Anzahl der Tool-Aufrufe pro Durchlauf zwischen 6 und 16. Die Stärke des Zustands, „niemals etwas zu vergessen“, ließ manchmal abgeschlossene Schritte als unvollständig erscheinen, zog den Agenten in redundante Zyklen zurück und trieb die Latenz um 23 Sekunden über die von AutoGen, trotz vergleichbarer Token-Anzahl.
CrewAI
CrewAIs Leistung in Aufgabe 5 erzeugte die höchste Varianz im gesamten Benchmark. In einigen Durchläufen folgte es einer makellosen Sequenz mit 5 Tool-Aufrufen, ohne Umwege, und führte wie ein Skript aus. In diesen Läufen funktionierte die durch Rolle und Aufgabe definierte managementbasierte Struktur von CrewAI genau wie beabsichtigt: Wenn der Agent seine Rolle klar verstand, verhielt er sich vorhersehbar und diszipliniert.
In anderen Durchläufen (z.B. Lauf 16: 35 Tool-Aufrufe) hingegen brach vollständiges Chaos aus. Die Ursache war der interne Monolog (Thought), den CrewAI bei jedem Schritt generiert. Nachdem der Agent das Segment mit dem richtigen Filter korrekt aufgebaut hatte, begann sein innerer Monolog zu hinterfragen, ob weitere Filter angewendet werden sollten. Nachdem er das Ergebnis gesehen hatte, zweifelte er, ob das aktuelle Segment gültig sei oder das vorherige Vorrang haben sollte. Dieser Zweifel trieb ihn dazu, die Daten von Grund auf neu zu laden. Dann filterte er erneut, trat in eine weitere Verifikationsschleife ein, zweifelte erneut und wiederholte diese Spirale 8 Mal.
Bei CrewAI erzeugt jeder Gedanke eine unabhängige Bewertung, und diese Bewertungen entkräften gelegentlich zuvor verifizierte Schritte. Der Reflex des Managerial Process zur „kontinuierlichen Verifikation“ trieb den Agenten in manchen Durchläufen dazu, seine eigenen richtigen Entscheidungen erneut in Frage zu stellen.
LangChain
Die AgentExecutor-Struktur von LangChain ist inhärent sequentiell, und Aufgabe 5 war der Punkt, an dem diese Einschränkung am deutlichsten sichtbar wurde. Mit 10,070 Prompt-Tokens und 86 Sekunden Median war es das langsamste Framework in dieser Aufgabe, obwohl es nicht die höchste Token-Anzahl hatte.
Es führt bei jedem Schritt einen einzigen Tool-Aufruf aus, empfängt das Ergebnis und fährt dann fort, was bedeutet, dass 4 unabhängige Tools 4 separate LLM-Runden mit 4 separaten Wartezeiten erforderten. AutoGens 47-Sekunden-Median gegenüber LangChains 86 Sekunden ist eine direkte Messung der Kosten von sequentieller versus paralleler Ausführung.
In Aufgabe 5 pendelte sich die Tool-Anzahl von LangChain bei entweder 9 oder 15 ein. Diese zwei Cluster deuten auf zwei typische Strategien hin: In einigen Durchläufen übersprang es den Inspektionsschritt und ging direkt zum Parsen und Zusammenfassen über (9 Tools), während es in anderen zuerst jede Spalte inspizierte, bevor es die Verarbeitung vornahm (15 Tools). Die Identität des linearen Executors von LangChain wurde hier deutlich: Es zeigte weder die parallele Effizienz von AutoGen noch das Monolog-Chaos von CrewAI.
Management unstrukturierter Daten und Framework-Architektur
Die Ergebnisse dieser Aufgabe zeigen, dass die Effizienz, mit der ein Framework unstrukturierte Daten (JSON, LongText) verwalten kann, direkt mit seinem inneren Schleifenmechanismus zusammenhängt:
Frameworks, die zu parallelen Tool-Aufrufen fähig sind (AutoGen), können unabhängige Datenspalten in einem einzigen Schritt verarbeiten. In realen Szenarien mit großen JSON-Objekten und zahlreichen Textspalten führt dieser Unterschied zu einem massiven Kosten- und Geschwindigkeitsvorteil.
Frameworks mit zustandsgetriebenen Schleifen (LangGraph) brillieren bei der Datenkonsistenz, tragen aber das Risiko, abgeschlossene Schritte, die sich in der Historie angesammelt haben, erneut zu evaluieren.
Monolog-basierte Frameworks (CrewAI) sind tiefgründig in der Lage, Typ und Bedeutung von Daten zu verstehen, doch diese Tiefe schlägt bisweilen in übermäßiges Hinterfragen und Schleifen um.
Linear ausführende Frameworks (LangChain) verarbeiten verschiedene Zweige unstrukturierter Daten getrennt und erzeugen ein Ergebnis, das einen Mittelweg aus beiden Welten darstellt.
GitHub-Sternwachstum agentischer Frameworks
Vergleich agentischer KI-Frameworks
Agentische KI-Frameworks variieren über mehrere Schlüsseldimensionen hinweg, und das Verständnis dieser Unterschiede ist wesentlich, um aussagekräftige Vergleiche anstellen zu können.
Multi-Agenten-Orchestrierung
Multi-Agenten-Orchestrierung koordiniert mehrere spezialisierte KI-Agenten, um komplexe Workflows zu bewältigen, die über die Fähigkeiten einzelner Agenten hinausgehen. Anstatt einen monolithischen Agenten zu bauen, verteilt die Orchestrierung die Arbeit auf Agenten mit unterschiedlichen Rollen, Tools und Fachkenntnissen. Jedes Framework bietet unterschiedliche Ansätze zur Agentenkoordination.
LangGraph
LangGraph ist ein vergleichsweise bekanntes Framework und stellt eine wichtige Option für Entwickler dar, die Agentensysteme bauen.
Explizite Multi-Agenten-Koordination: Sie können mehrere Agenten als einzelne Knoten oder Gruppen modellieren, jeder mit eigener Logik, eigenem Speicher und eigener Rolle im System.
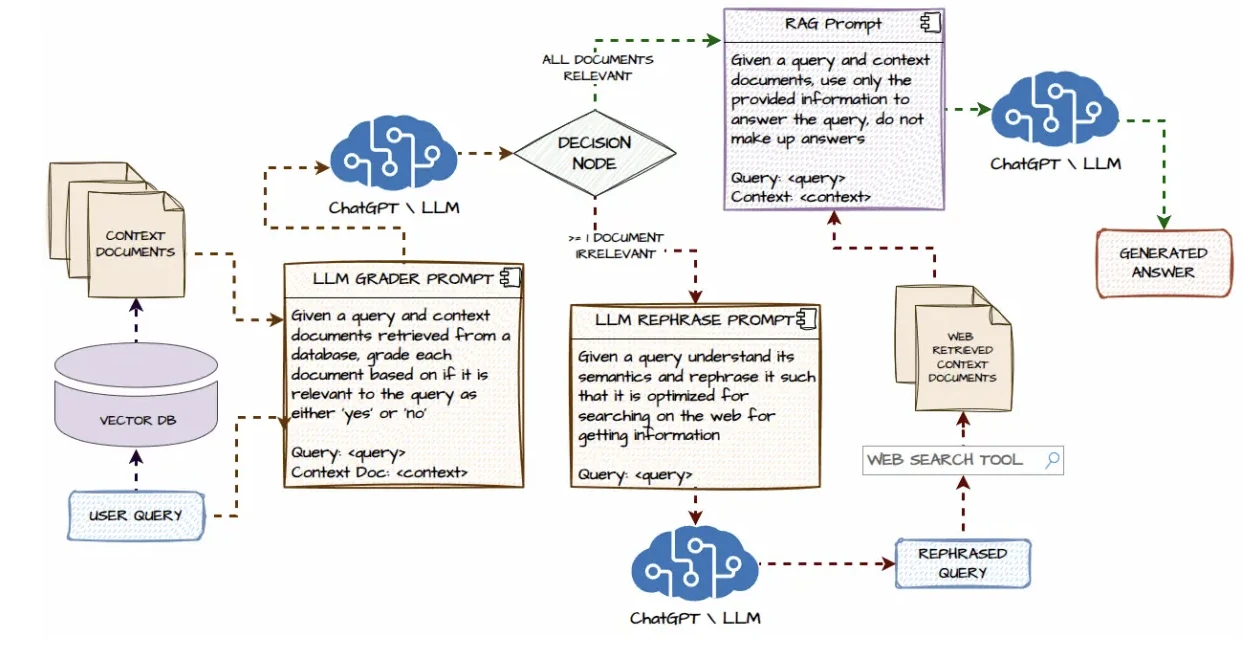
Es erstellt KI-Workflows über APIs und Tools hinweg. Daher eignet es sich gut für RAG und benutzerdefinierte Pipelines.
AutoGen
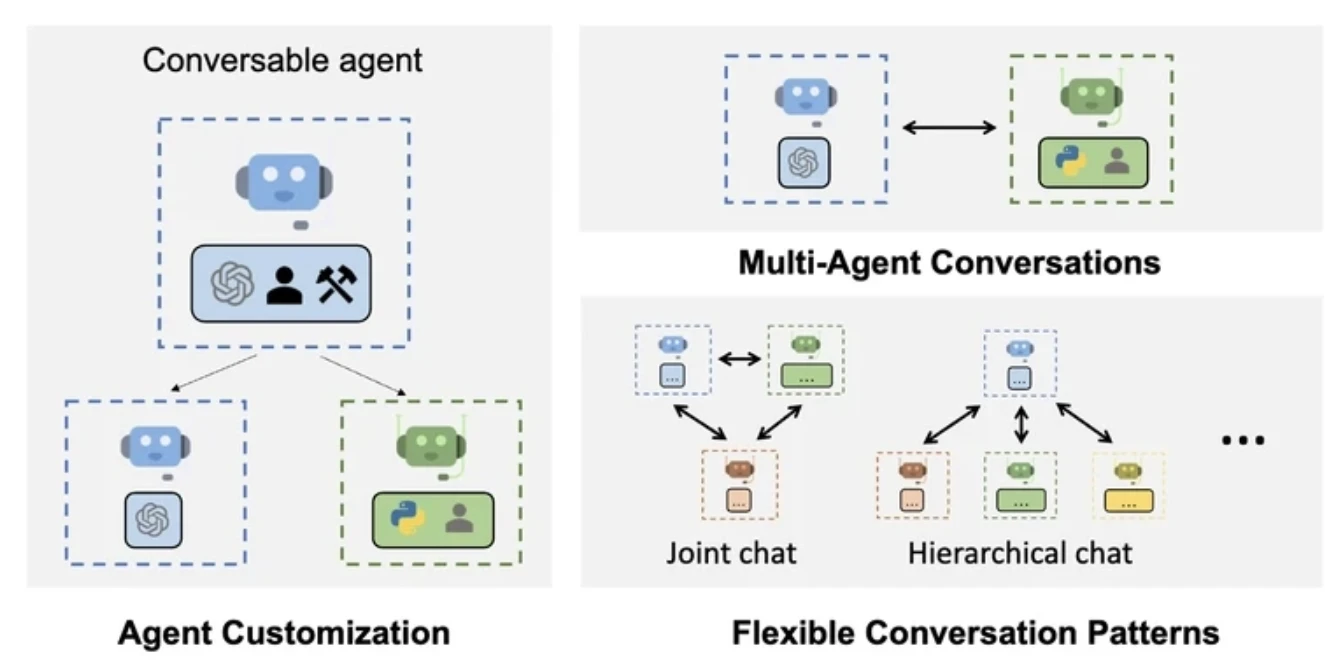
AutoGen ermöglicht es mehreren Agenten, durch den Austausch von Nachrichten in einer Schleife zu kommunizieren. Jeder Agent kann basierend auf seiner internen Logik antworten, reflektieren oder Tools aufrufen.
Es verfügt über asynchrone Agentenzusammenarbeit und eignet sich daher besonders für Forschungs- und Prototyping-Szenarien, in denen das Agentenverhalten experimentiert oder iterativ verfeinert werden muss.
CrewAI
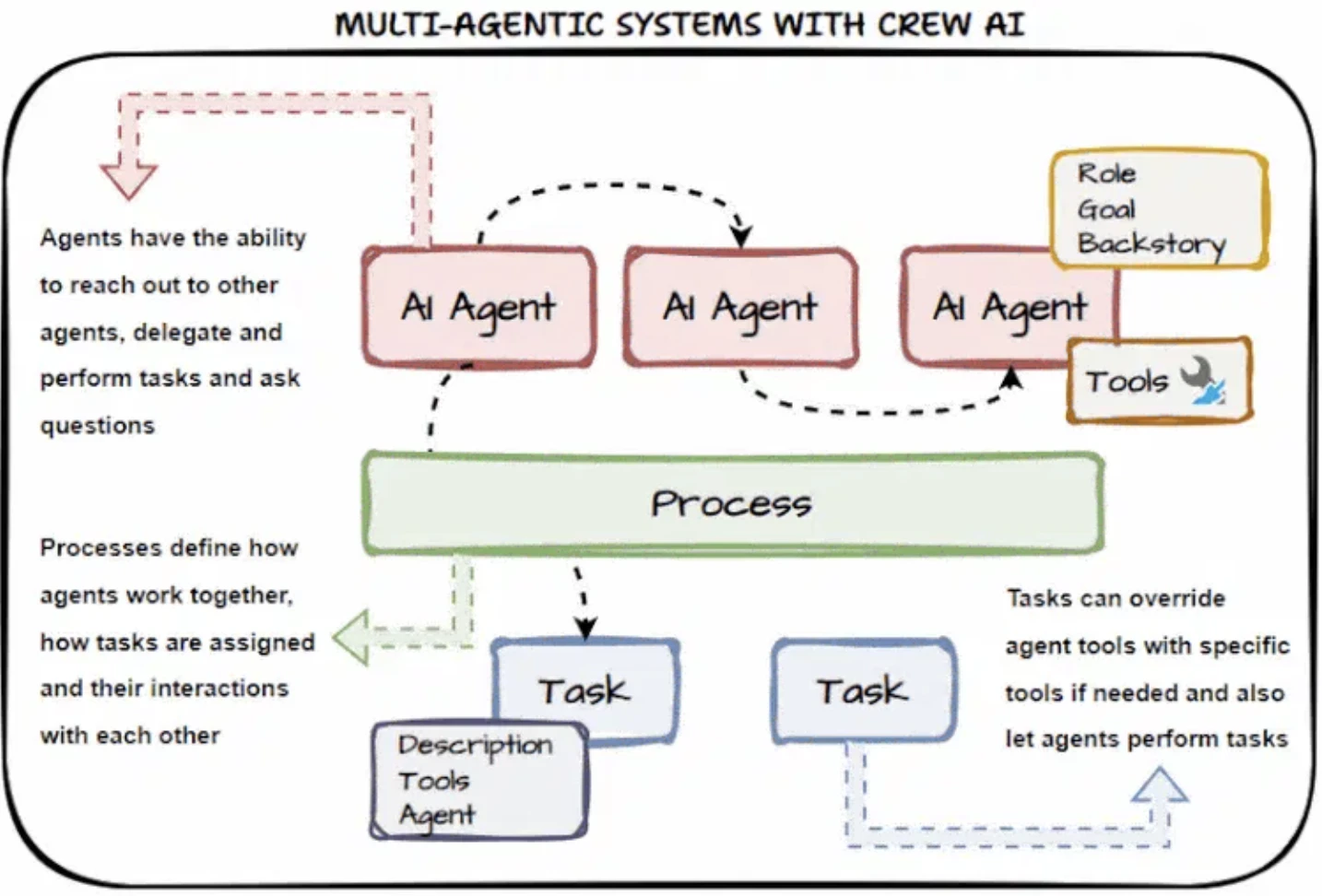
CrewAI übernimmt den größten Teil der Low-Level-Logik für Sie und bietet Multi-Agenten-Orchestrierung:
- Integration mit Monitoring-Tools für Tracing und Debugging
- Integrierte Ausführungskontrolle durch Flows mit bedingter Logik, Schleifen und Zustandsverwaltung
- Unterstützt hierarchische (Manager-Worker) und strukturierte Multi-Agenten-Koordination
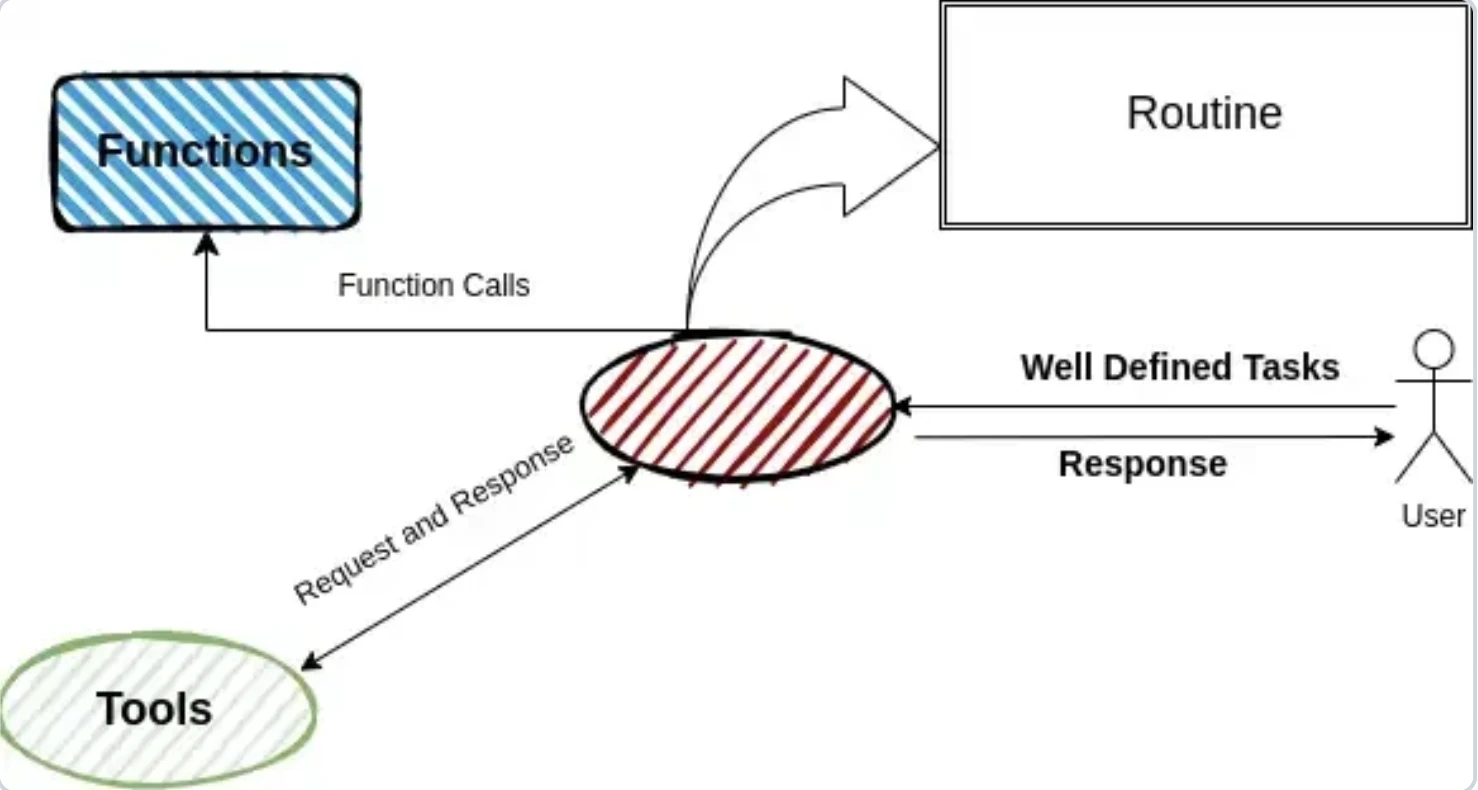
OpenAI Swarm
Swarm ist ein leichtgewichtiges, experimentelles Multi-Agenten-Framework für Prototyping. Agenten arbeiten sequentiell durch Übergaben und übertragen Aufgaben, während sie einen gemeinsamen Kontext beibehalten. Es verwendet Routinen in natürlicher Sprache und Python-Tools für flexible Workflows.
LangChain
LangChain ist ein Framework zum Erstellen von Single-Agent-LLM-Anwendungen mit RAG-Tooling. Es bietet modulare Komponenten einschließlich Chains, Tools, Speicher und Retrieval für Dokumentenverarbeitungs-Workflows.
LangChain arbeitet hauptsächlich mit Single-Agent-Ausführungsmustern, bei denen ein Agent den Workflow verwaltet.
Agenten- und Funktionsdefinition
LangGraph
LangGraph verfolgt einen graphbasierten Ansatz für das Agentendesign, bei dem jeder Agent als Knoten dargestellt wird, der seinen eigenen Zustand hält. Diese Knoten sind durch einen gerichteten Graphen verbunden, was bedingte Logik, Multi-Team-Koordination und hierarchische Steuerung ermöglicht. Dies erlaubt es Ihnen, Multi-Agenten-Graphen mit Supervisor-Knoten für skalierbare Orchestrierung zu bauen und zu visualisieren.
LangGraph verwendet annotierte, strukturierte Funktionen, die Tools an Agenten binden. Sie können Knoten aufbauen, sie mit verschiedenen Supervisoren verbinden und visualisieren, wie verschiedene Teams interagieren. Stellen Sie es sich so vor, als würden Sie jedem Teammitglied eine detaillierte Stellenbeschreibung geben. Dies erleichtert das Erstellen und Testen von Agenten, die zusammenarbeiten.
AutoGen
AutoGen definiert Agenten als adaptive Einheiten, die flexibles Routing und asynchrone Kommunikation ermöglichen. Agenten interagieren miteinander (und optional mit Menschen) durch den Austausch von Nachrichten, was kollaboratives Problemlösen ermöglicht. Wie LangGraph verwendet es annotierte, strukturierte Funktionen.
CrewAI
CrewAI verfolgt einen rollenbasierten Designansatz. Jedem Agenten wird eine Rolle (z.B. Researcher, Developer) und eine Reihe von Fähigkeiten, Funktionen oder Tools zugewiesen, auf die er zugreifen kann. Die Funktionsdefinition erfolgt über strukturierte Annotationen.
OpenAI Swarm
OpenAI Swarm verwendet ein routinenbasiertes Modell, bei dem Agenten durch Prompts und Funktions-Docstrings definiert werden. Es verfügt über keine formale Orchestrierung oder Zustandsmodelle, sondern stützt sich auf manuell strukturierte Workflows. Das Verhalten von Funktionen wird vom LLM durch Docstrings erschlossen (Swarm erkennt, was eine Funktion tut, indem es ihre Beschreibung liest), was dieses Setup flexibel, aber weniger präzise macht.
LangChain
LangChain verwendet eine chain-basierte Architektur, bei der ein einzelner Orchestrator-Agent Aufrufe an Sprachmodelle und verschiedene Tools verwaltet. Es definiert Funktionen über explizite Schnittstellen wie Toolkits und Prompt-Templates.
Während es sich primär auf zentralisierte Workflows konzentriert, unterstützt LangChain Erweiterungen für Multi-Agenten-Setups, bietet jedoch keine integrierte Agent-zu-Agent-Kommunikation.
Speicher
Speicherfähigkeiten:
- Zustandsbehaftet: Ob das Framework persistenten Speicher über Ausführungen hinweg unterstützt.
- Kontextbezogen: Ob es Kurzzeitspeicher über Nachrichtenhistorien oder Kontextweitergabe unterstützt.
Speicherfunktionen sind ein Schlüsselaspekt beim Bau agentischer Systeme, um Kontext zu merken und sich über die Zeit anzupassen:
- Kurzzeitspeicher: Verfolgt kürzliche Interaktionen, sodass Agenten mehrzügige Gespräche oder schrittweise Workflows handhaben können.
- Langzeitspeicher: Speichert persistente Informationen über Sitzungen hinweg, wie Benutzerpräferenzen oder Aufgabenhistorien.
- Entitätsspeicher: Verfolgt und aktualisiert Wissen über spezifische Objekte, Personen oder Konzepte, die in Interaktionen erwähnt wurden (z.B. das Merken eines Firmennamens oder einer Projekt-ID, die früher genannt wurde).
LangGraph
LangGraph verwendet zwei Arten von Speicher: In-Thread-Speicher, der Informationen während einer einzelnen Aufgabe oder Konversation speichert, und Cross-Thread-Speicher, der Daten über Sitzungen hinweg speichert. Entwickler können MemorySaver verwenden, um den Ablauf einer Aufgabe zu speichern und sie mit einem bestimmten thread_id zu verknüpfen. Für die langfristige Speicherung unterstützt LangGraph Tools wie InMemoryStore oder andere Datenbanken. Dies bietet flexible Kontrolle darüber, wie Speicher bereichsbezogen ist und über Ausführungen hinweg erhalten bleibt.
AutoGen
AutoGen verwendet ein kontextbezogenes Speichermodell. Jeder Agent hält kurzfristigen Kontext über ein context_variables-Objekt, das die Interaktionshistorie speichert. Es verfügt über keinen integrierten persistenten Speicher.
CrewAI
CrewAI bietet sofort einsatzbereit einen mehrschichtigen Speicher. Es speichert Kurzzeitspeicher in einem ChromaDB-Vektorspeicher, kürzliche Aufgabenergebnisse in SQLite und Langzeitspeicher in einer separaten SQLite-Tabelle (basierend auf Aufgabenbeschreibungen). Zusätzlich unterstützt es Entitätsspeicher mittels Vektorembeddings. Diese Speichereinrichtung wird automatisch konfiguriert, wenn memory=True aktiviert ist.
OpenAI Swarm
Swarm ist zustandslos und verwaltet Speicher nicht nativ. Entwickler können Kurzzeitspeicher manuell über context_variables übergeben und optional externe Tools oder Drittanbieter-Speicherschichten (z.B. mem0) integrieren, um längerfristigen Kontext zu speichern.
LangChain
LangChain unterstützt sowohl Kurz- als auch Langzeitspeicher über flexible Komponenten. Kurzzeitspeicher wird typischerweise über In-Memory-Puffer verwaltet, die Konversationshistorie innerhalb einer Sitzung verfolgen. Für Langzeitspeicher integriert LangChain externe Vektorspeicher oder Datenbanken, um Embeddings und Retrieval-Daten zu persistieren.
Entwickler können Speicherbereiche und -strategien mithilfe integrierter Speicherklassen anpassen, was ein effizientes Management von kontextbezogenem und entitätsspezifischem Speicher über Interaktionen hinweg ermöglicht.
Human-in-the-loop
LangGraph
LangGraph unterstützt benutzerdefinierte Haltepunkte (interrupt_before), um den Graphen anzuhalten und mitten in der Ausführung auf Benutzereingaben zu warten.
AutoGen
AutoGen unterstützt nativ menschliche Agenten über UserProxyAgent und erlaubt es Menschen, Schritte während der Agentenzusammenarbeit zu überprüfen, zu genehmigen oder zu ändern.
CrewAI:
CrewAI ermöglicht Feedback nach jeder Aufgabe, indem human_input=True gesetzt wird; der Agent pausiert, um natürlichsprachliche Eingaben vom Benutzer zu sammeln.
OpenAI Swarm
OpenAI Swarm bietet kein integriertes HITL.
LangChain
LangChain erlaubt das Einfügen benutzerdefinierter Haltepunkte innerhalb von Chains oder Agenten, um die Ausführung anzuhalten und menschliche Eingaben anzufordern. Dies unterstützt Überprüfung, Feedback oder manuelle Eingriffe an definierten Stellen im Workflow.
Model Context Protocol (MCP)-Integration in agentischen KI-Frameworks
KI-Agenten müssen mit externen Tools wie Datenbanken, APIs, Dateisystemen und Geschäftsanwendungen interagieren. Ohne einen Standard musste jedes Framework für jedes Tool benutzerdefinierte Integrationen erstellen, was ein fragmentiertes Ökosystem zur Folge hatte. MCP löst dies durch ein universelles Protokoll, das es jedem Agenten ermöglicht, über eine einzige Schnittstelle eine Verbindung zu jedem Tool herzustellen.
Wie jedes Framework mit MCP integriert
LangGraph
LangGraph verbindet sich über einen Adapter mit MCP-Servern, der automatisch verfügbare Tools erkennt und sie in ein mit LangChain kompatibles Format konvertiert. Agenten können diese Tools dann nahtlos zusammen mit ihren nativen Fähigkeiten nutzen.
AutoGen
AutoGen bietet integrierte MCP-Integration über sein Erweiterungsmodul. Entwickler können mit nur wenigen Codezeilen eine Verbindung zu MCP-Servern herstellen und alle ihre Tools für AutoGen-Agenten verfügbar machen.
CrewAI
CrewAI-Agenten können direkt in ihrer Konfiguration auf MCP-Server verweisen, unter Verwendung einfacher URLs oder strukturierter Einstellungen. Das Framework übernimmt automatisch das Verbindungslebenszyklus- und Fehlermanagement.
OpenAI Swarm
Swarm profitiert von der nativen MCP-Unterstützung von OpenAI in seinem gesamten Ökosystem. Da OpenAI MCP in ChatGPT und sein Agents SDK integriert hat, kann Swarm diese Infrastruktur direkt nutzen.
LangChain
LangChain bietet MCP-Tool-Calling-Funktionen, bei denen Python-Funktionen als Brücken zu MCP-Servern fungieren. Dies ermöglicht das Abrufen von Tools aus verschiedenen Quellen und deren Integration in Chains, Agenten und andere LangChain-Komponenten ohne benutzerdefinierte Wrapper.
Was agentische KI-Frameworks tatsächlich tun?
Agentische KI-Frameworks unterstützen das Prompt-Engineering und die Verwaltung, wie Daten zu und von LLMs fließen. Auf grundlegender Ebene helfen sie, Prompts zu strukturieren, damit der LLM in einem vorhersagbaren Format antwortet, und leiten Antworten an das richtige Tool, die richtige API oder das richtige Dokument weiter.
Bei einem Scratch-Build würde man den Prompt manuell definieren, das Tool extrahieren, das der LLM verwenden möchte, und den entsprechenden API-Aufruf auslösen. Frameworks rationalisieren dies durch:
- Prompt-Orchestrierung: Aufbau, Verwaltung und Routing komplexer Prompts an LLMs
- Tool-Integration: Agenten ermöglichen, externe APIs, Datenbanken, Codefunktionen usw. aufzurufen
- Speicher: Beibehaltung des Zustands über Runden oder Sitzungen hinweg (kurz- und langfristig)
- RAG-Integration: Ermöglicht Wissensabruf aus externen Quellen
- Multi-Agenten-Koordination: Strukturierung der Zusammenarbeit oder Delegation von Aufgaben zwischen Agenten
Agentische KI-Frameworks: Praxisbeispiele
LangGraph – Multi-Agenten-Reiseplaner
Ein mit LangGraph gebautes Produktionsprojekt demonstriert einen zustandsbehafteten Multi-Agenten-Reiseassistenten, der Flug- und Hoteldaten abruft (unter Verwendung von Google Flights & Hotels APIs) und Reiseempfehlungen generiert.4
CrewAI – Agentischer Content Creator
Das offizielle Beispiel-Repository von CrewAI enthält Flows wie Reiseplanung, Marketingstrategie, Aktienanalyse und Recruiting-Assistenten, bei denen rollenspezifische Agenten (z.B. „Researcher“, „Writer“) an Aufgaben zusammenarbeiten.5
CrewAI verwandelt ein grobes Content-Brief in einen vollständigen Artikel unter Verwendung von Groq.
Kernfunktionen agentischer KI-Frameworks
Modellunterstützung:
- Die meisten sind modellagnostisch und unterstützen mehrere LLM-Anbieter (z.B. OpenAI, Anthropic, Open-Source-Modelle).
- Die System-Prompt-Strukturen variieren jedoch je nach Framework und können mit manchen Modellen besser funktionieren als mit anderen.
- Zugriff auf und Anpassung von System-Prompts ist oft wesentlich für optimale Ergebnisse.
Tooling:
- Alle Frameworks unterstützen Tool-Nutzung, einen Kernbestandteil zur Ermöglichung von Agentenaktionen.
- Bieten einfache Abstraktionen, um benutzerdefinierte Tools zu definieren.
- Die meisten unterstützen Model-Context-Protocol (MCP), entweder nativ oder durch Community-Erweiterungen.
Speicher / Zustand:
- Verwenden Zustandsverfolgung, um Kurzzeitspeicher über Schritte oder LLM-Aufrufe hinweg aufrechtzuerhalten.
- Einige helfen Agenten, vorherige Interaktionen oder Kontext innerhalb einer Sitzung beizubehalten.
RAG (Retrieval-Augmented Generation):
- Die meisten beinhalten einfache Einrichtungsoptionen für RAG und integrieren Vektordatenbanken oder Dokumentenspeicher.
- Dies erlaubt Agenten, während der Ausführung auf externes Wissen zu verweisen.
Weitere gemeinsame Funktionen
- Unterstützung für asynchrone Ausführung, die gleichzeitige Agenten- oder Tool-Aufrufe ermöglicht.
- Integrierte Handhabung von strukturierten Ausgaben (z.B. JSON).
- Unterstützung für Streaming-Ausgaben, bei denen das Modell Ergebnisse inkrementell generiert.
- Grundlegende Observability-Funktionen zur Überwachung und zum Debugging von Agentenläufen.
Benchmark-Methodik
1. Aufgabenstruktur
Aufgabe 1: Misst, ob ein einzelner Tool-Aufruf mit dem korrekten Parameter getätigt werden kann. Der Basisinfrastruktur-Overhead des Frameworks zeigt sich in diesem einfachen Szenario am deutlichsten.
Aufgabe 2: Erfordert, die Ergebnisse zweier separater Filtergruppen im Speicher zu halten und in einer einzigen Ausgabe zu kombinieren. Zustandsverwaltung und die Koordination mehrerer Segmente werden getestet.
Aufgabe 3: Misst, ob numerische Bedingungen in natürlicher Sprache ohne Verzerrung in Tool-Parameter übersetzt werden. Der eigentliche Test ist, ob die Wiederholungs- und Re-Prompt-Mechanismen des Frameworks diese Parameter bewahren können.
Aufgabe 4: Ein Tool wirft nacheinander Netzwerk-, Timeout- und RateLimit-Fehler. Gemessen wird, ob das Framework angesichts dieser Fehler seine Strategie ändert.
Aufgabe 5: Der Agent muss zunächst JSON- und LongText-Spalten entdecken und dann die richtigen Tools mit den korrekten Scope-Parametern aufrufen. Beobachtet wird, ob das Framework unabhängige Tools parallel oder sequentiell ausführt.
Wie eine Aufgabe tatsächlich aussieht
Zur Veranschaulichung des Setups hier Aufgabe 5, die komplexeste Aufgabe im Benchmark der agentischen KI-Frameworks. Jedes Framework erhielt denselben Prompt und denselben Satz an Tools; nur das Framework, das den LLM umhüllte, änderte sich.
Dem Agenten übergebener Prompt:
Analysiere abgewanderte Kunden (Churn=’Ja’), die mehr als 100 an MonthlyCharges zahlen.
- Filtere den Datensatz auf Churn=’Ja’.
- Inspiziere die Spalten ‘Metadata’ und ‘SupportNotes’, um ihre Datentypen zu entdecken.
- Extrahiere die ‘device_type’-Verteilung aus der JSON-Spalte ‘Metadata’.
- Zähle Beschwerde-Schlüsselwörter aus der kostenlos-Text-Spalte ‘SupportNotes’.
Gib das Ergebnis nur als JSON zurück.
Erforderliche JSON-Ausgabe:
Warum diese Aufgabe zwischen Frameworks unterscheidet: Der Agent muss eine Kette von vier Tool-Aufrufen planen, das gefilterte Segment über jeden Aufruf hinweg im Zustand halten und erkennen, dass eine Spalte JSON ist, während die andere kostenlos-Text ist. Ein Framework, das die unabhängigen Spalten parallel ausführt (AutoGen), wird viel schneller fertig als eines, das sie sequentiell ausführt (LangChain). Und ein Framework, das abgeschlossene Schritte erneut evaluiert (LangGraph, CrewAI), gerät unnötig in Schleifen. Das strikte JSON-Schema erlaubt uns, die Korrektheit automatisch zu bewerten.
2. Konfiguration
Alle Frameworks verwendeten dasselbe LLM-Modell (openai/gpt-5.2) und denselben Temperaturwert (0.1). Für alle Aufgaben wurden jedem Agenten dieselben Tools und dieselben Prompts gegeben. Jedes Framework wurde in seiner nativen Struktur eingerichtet: LangChain mit AgentExecutor, LangGraph mit StateGraph, AutoGen mit AssistantAgent + UserProxyAgent und CrewAI mit Agent + Task + Crew.
Der IBM Telco Customer Churn-Datensatz (7,032 Kunden) wurde verwendet. Der Tool-Zustand wurde vor jedem Durchlauf zurückgesetzt. 100 unabhängige Durchläufe wurden für jede Kombination aus Framework und Aufgabe ausgeführt.
Maximale Iterationslimits wurden entsprechend der Aufgabenkomplexität festgelegt: 10 für die Aufgaben 1, 2 und 3; 20 für Aufgabe 4 aufgrund der fehlerhaften Tool-Schleife; und 20 für Aufgabe 5 aufgrund der 4-schrittigen Erkennungskette.
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Top 5 Open-Source-Frameworks für agentische KI}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Abgerufen am 6. Juli 2026}
}

Kommentare 1
Teilen Sie Ihre Gedanken
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.