Die besten 50+ Open-Source-KI-Agenten im Überblick
Jeder baut KI-Agenten, daher haben wir nach praktischen Tests mit beliebten KI-Codierungsagenten, KI-Agenten-Entwicklertools und Werkzeugnutzungs-Benchmarks, um deren reale Fähigkeiten zu bewerten, eine sorgfältig zusammengestellte Liste der bester 50+ Open-Source-KI-Agenten erstellt. Klicken Sie auf die Kategorieüberschriften, um direkt zu unseren Top-Auswahlen zu gelangen:
Agenten-Entwicklung und Infrastruktur
Branchenspezifische Agentenanwendungen
- Web-Automatisierung und Navigationsagenten
- Codierungs- und Entwicklungstools
- Cybersicherheitstools
- KI-Videokreationstools
- Finanzassistenten
- Gesundheitsassistenten
- Forschungsagenten
- Datenanalyse-Assistenten
- Persönliche Assistenten
Wie man über KI-Agenten denkt
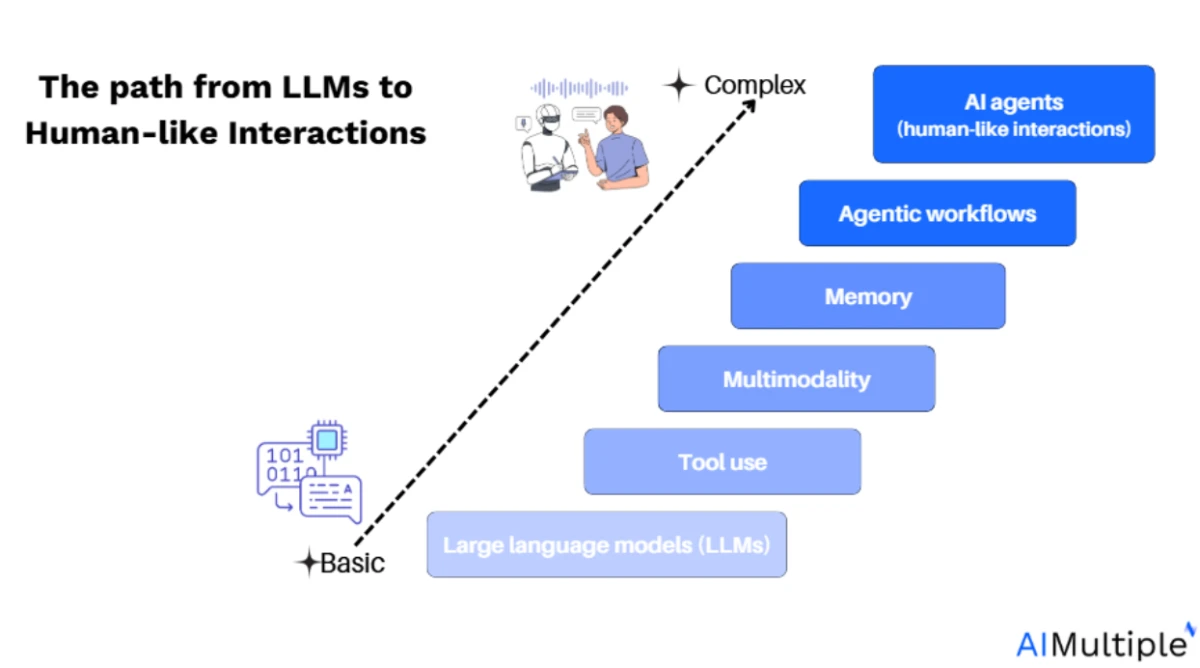
Ein KI-Agent ist mehr als nur ein LLM mit einem Prompt. Technisch gesehen handelt es sich um ein komponierbares System, das Planung, Speicher, Werkzeugnutzung und iterative Ausführung kombiniert. Es bildet eine strukturierte Schleife um einen LLM, der Entscheidungen treffen, Aktionen ausführen und sich an neue Informationen anpassen kann.
So sollte man darüber nachdenken:
- Autonomie und Workflows: KI-Agenten reichen von einfacher Aufgabenautomatisierung basierend auf vordefinierten Workflows bis hin zu vollständig autonomen Systemen, die in der Lage sind, Ziele zu zerlegen, Speicher zu nutzen und mit Werkzeugen zu interagieren. Die zentrale technische Herausforderung besteht darin, den Kontext über mehrere Schritte hinweg beizubehalten und mehrstufige Operationen zu koordinieren.
- Kontext und Kontrolle: Die eigentliche Herausforderung bei KI-Agenten besteht darin, sicherzustellen, dass der LLM in jedem Schritt über den richtigen Kontext verfügt. Dazu gehört die Verwaltung der in den LLM eingespeisten Inhalte und die Gewährleistung, dass der Agent relevante Aufgaben basierend auf aktuellem Kontext ausführt.
- Integration von Werkzeugen: Die Entwicklung effektiver Agenten erfordert eine nahtlose Integration mit externen Werkzeugen, APIs und Datenschnittstellen. Frameworks wie LangChain können dabei helfen, diese externen Ressourcen zu integrieren, aber die Kontrolle über den Workflow ist entscheidend, um das Verhalten des Agenten an neue Eingaben anzupassen.
- Vorteile von Agenten-Frameworks: Alle agentischen Systeme, ob einfache Workflows oder komplexe autonome Agenten, können von Kernfunktionen agentischer Frameworks profitieren. Diese Funktionen können von Grund auf neu erstellt oder von einer bestehenden Open-Source-Plattform übernommen werden, je nach Bedarf.
Neue Standards
- Model Context Protocol (MCP): Der Branchenstandard dafür, wie Agenten mit externen Datenschnittstellen kommunizieren. LangGraph integriert MCP, um Agenten zu ermöglichen, Datenbanken und lokale Werkzeuge „plug-and-play“ anzuschließen, ohne benutzerdefinierte Wrapper.
- Stripe Agentic Commerce Protocol (ACP): Dies ist der erste lebende Branchenstandard, der KI-Agenten erlaubt, Zahlungen, Lagerbestände und Versand sicher zu verwalten. Er ermöglicht „Agentic Checkout“, bei dem der Agent einen Kauf für den Benutzer innerhalb einer Chat-Oberfläche abschließen kann.
Was genau ist ein KI-Agent?
Es gibt keine allgemein anerkannte Definition dafür, was einen „KI-Agenten“ ausmacht.
- Traditionelle KI definiert Agenten als Systeme, die mit ihrer Umgebung interagieren.
- Simon Willisons Umfrage unter Praktikern präsentiert eine Vielzahl von Arbeitsdefinitionen aus der Branche.2
- Anthropics Definition beschreibt Gestaltungsprinzipien für den Aufbau effektiver und ausgerichteter KI-Agenten.3
- Große Beratungsunternehmen betonen die Rolle von Agenten bei der Automatisierung von Geschäftsworkflows und Entscheidungsprozessen.4 .
Viele dieser Definitionen schließen ausdrücklich Workflows und Autonomie am Ende eines Spektrums ein.
Wir stimmen diesen Ansichten zu, daher geben wir keine strikte Definition ab. Stattdessen listen wir die Faktoren auf, die ein KI-System dazu bringen, als agenter angesehen zu werden:
- Umfeld und Ziele:
- KI-Systeme in komplexen Umgebungen, wie solchen mit mehreren Aufgaben und unerwarteten Änderungen, sind agentisch.
- KI-Systeme, die Ziele verfolgen, ohne angewiesen zu werden, sind agentisch.
- Benutzeroberfläche und Überwachung: KI-Systeme, die natürliche Sprachen erlernen und Systeme, die weniger Benutzerüberwachung benötigen, sind agentisch.
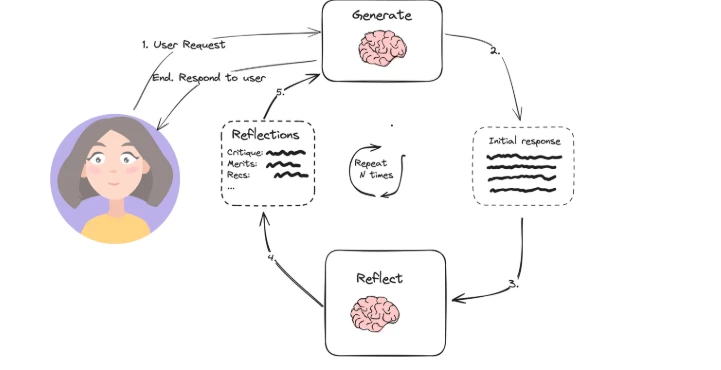
- Systemdesign: Systeme, die Gestaltungsmuster wie Werkzeugnutzung (z. B. Websuche, Programmierung) oder Planung (z. B. Reflexion, Unteraufgabenzerlegung) verwenden, sind agentisch.
Für eine detailliertere Erklärung haben wir diese Faktoren bereits aufgelistet und diskutiert, wie sie agentische KI-Systeme definieren.
Sind diese Agenten vollständig autonom?
Noch nicht. Die meisten Open-Source-KI-Agenten erhöhen die Autonomie von LLMs, indem sie Werkzeugnutzung, Entscheidungsfindung und Problemlösung ermöglichen, benötigen aber weiterhin strukturierte Eingaben und einen Menschen in der Schleife.
Beispiele wie Devon und PR-Agent folgen vordefinierten Logik- oder RL-Workflows, anstatt volles agentisches Verhalten zu zeigen. Andere KI-Agenten fehlen immer noch an (Autonomes Lernen + Generalisierung) Fähigkeiten.
Wann (und wann nicht) KI-Agenten einsetzen
Nicht jede LLM-Anwendung erfordert agentische Komplexität. Viele Anwendungsfälle werden besser durch leichte Retrieval-Augmented Generation (RAG) bedient.
Agentische Systeme bringen architektonischen Overhead mit sich: Speicherverwaltung, Werkzeug-Orchestrierung, Fehlerbehandlung und Kontrollschleifen, die Latenz und Kosten erhöhen. Zum Beispiel haben wir in unseren Benchmarks beobachtet, dass die Erfolgsraten von KI-Agenten nach 35 Minuten menschlicher Interaktion abnehmen.
Um diese Risiken zu mindern, ist es wichtig, agentische Systeme in kontrollierten Umgebungen zu testen und robuste Sicherheitsvorkehrungen vor der Bereitstellung einzurichten.
Agenten sind am wertvollsten, wenn die Schritte nicht leicht vorhersehbar oder hartcodiert sind. Sie eignen sich besonders für Situationen, in denen:
- Aufgaben dynamisch und mehrstufig sind, mit verzweigter Logik oder unklaren Teilzielen.
- Die Werkzeugnutzung bedingt oder adaptiv ist und das System entscheiden muss, welches Werkzeug basierend auf Eingabe oder vorherigem Zustand aufgerufen wird.
- Langzeitgedächtnis oder Kontext erforderlich ist, über Sitzungen oder Ausführungsphasen hinweg.
- Die Ausführung auf Umgebungsfeedback reagieren muss, wie API-Ergebnisse, Suchausgaben oder fehlgeschlagene Aktionen.
- Mensch-in-der-Schleife-Zusammenarbeit erforderlich ist, bei der Autonomie und Überwachung kombiniert werden müssen (z. B. KI-Copiloten).
Andererseits sind Workflows oder zustandslose LLM-Aufrufe vorzuziehen, wenn:
- Die Aufgabenlogik statisch oder vorhersehbar ist, wie Formularausfüllung oder Inhaltskonvertierung.
- Niedrige Latenz kritisch ist, wie bei benutzerorientierten Interaktionen.
- Die Kosten minimiert werden müssen, insbesondere durch Vermeidung rekursiver LLM-Aufrufe und komplexer Orchestrierung.
Weiterlesen
Hier sind unsere neuesten Benchmarks zur Infrastruktur, die häufig von agentischen Systemen verwendet wird:
- Remote-Browser: Wie Browser-Infrastruktur Agenten ermöglicht, sicher mit dem Web zu interagieren.
- Browser MCP Benchmark: Die besten MCP-Server für Werkzeugnutzung und Webzugriff.
Beispiele für Open-Source-KI-Agenten
Einige Tools, die als „KI-Agenten“ bezeichnet werden, sind nicht wirklich besonders agentisch; diese Systeme (z. B. Devon PR-agent) sind größtenteils RL-basierte KI-Workflows, bei denen LLMs durch vordefinierte Codepfade organisiert sind.
1. Agenten-Frameworks (Build-Your-Own)
Modulare Bibliotheken und SDKs für Entwickler, um Agenten mit Kontrolle über Logik, Speicher, Werkzeuge und Orchestrierung zu bauen.
✳️ Einige Agenten wie SmolAgents und Agno passen sowohl in die Kategorie Agenten-Frameworks als auch in Workflow-Automatisierung.
Allgemeine Agenten-Frameworks
Frameworks, die sich auf das Bauen von Agenten konzentrieren und flexible, anpassbare Werkzeuge für die Orchestrierung von Workflows, Multi-Agenten-Setups und allgemeinen Anwendungsfällen bieten.
- LangGraph – Graphbasierte LLM-Workflow-Orchestrierung – LangGraph ist proprietäre Software, bietet aber eine Open-Source-Bibliothek für die Agentenentwicklung. Ideal für RAG-Pipelines, Agenten-Speicher/Zustandshandling und Multi-Agenten-Setups.
- AutoGen – Asynchrone Multi-Agenten-Zusammenarbeit – Entwickelt für die Koordination von werkzeugnutzenden Agenten über chatähnliche APIs. Ideal zur Automatisierung komplexer Workflows, insbesondere bei autonomer Codegenerierung.
- CrewAI – No-Code-/Low-Code-Multi-Agenten-Framework – Eines der einfachsten Werkzeuge zum Einstieg, bietet vorgefertigte Agentenvorlagen (z. B. Meetingvorbereitungs-Agent).
Spezialisierte Agenten-Frameworks
Frameworks mit einem speziellen Fokus auf bestimmte Arten von Agentenverhalten oder Agentenintegrationen.
- Camel – Rollenbasierte Agentensimulation – Optimiert für kooperative, rollenspielende Agenten mit strukturiertem Denken. Ideal für Workflow-Automatisierung und synthetische Datengenerierung.
- Mastra – Frontend-integrierte Agentenentwicklung – JavaScript-basiert, ideal zum Einbetten von Agenten in benutzerorientierte Anwendungen.
- PydanticAI – Typsichere, minimale Agentensteuerung – Bietet enge Validierung und transparente Logikpfade mit Pydantic.
- Cybersecurity KI (CAI) – KI-gestütztes Cybersicherheits-Agenten-Framework – Bietet Penetrationstests, Schwachstellenentdeckung und Red-Teaming mit Mensch-in-der-Schleife-Funktionen, unter Nutzung großer Sprachmodelle und Integrationen mit Werkzeugen wie Nmap.
- Atomic Agents – Schemaerstes, granulares, benutzerdefiniertes Agentenbauwerkzeug – Entwickelt für granulare Agentenstruktur und komponierbare Logik.
- SmolAgents – Leichtgewichtiges Agenten-SDK für Entwickler – Minimale Abstraktion, leitet Logik über Python statt über JSON.
Agenten-Laufzeiten (vorgefertigte autonome Agenten)
Vorgefertigte, eigenständige Agenten, die sofort ausgeführt werden können (wie eine App). Unterstützen typischerweise die autonome Ausführung von Aufgaben aus natürlichsprachlichen Zielen.
Vollständig autonom:
- Automatisch-GPT – Zerlegung von Zielen und autonome Ausführung – Zerlegt Ziele in Unteraufgaben und führt sie mit Werkzeugen, Speicher und Denken aus. Bietet vorgefertigte Agenten und eine Low-Code-Oberfläche.
- AIlice – Lokale, allgemeine Aufgabenausführung – Führt komplexe Aufgaben direkt auf dem Gerät aus, unterstützt lokale Werkzeuge und Dateibearbeitung. Ziel ist es, einen KI-Assistenten zu schaffen, ähnlich wie JARVIS, basierend auf dem Open-Source-LLM.
- Manus KI – Allgemeine, sandboxed Operationen. Führt Werkzeuge und Workflows in einer sicheren Sandbox aus und ist in der Lage, mehrdomänen-, mehrstufige Operationen autonom zu handhaben. Wurde von Meta übernommen und in Metas „Persönliches Ambient Intelligence“-Ökosystem integriert.5
Teilweise autonom:
- BabyAGI – Iterativer Aufgaben-Schleifen-Executor – Erstellt, priorisiert und führt Aufgabenlisten in einer Feedbackschleife aus. Ideal für Experimente zur Aufgabengenerierung.
Browser-/Oberflächenbasiert:
- AgentGPT – Auf dem Browser bereitgestellter autonomer Agent – Ermöglicht Benutzern, Aufgabenagenten über eine Web-Oberfläche zu erstellen und auszuführen. Leichtgewichtig, ideal zum Experimentieren.
- OpenManus – Persistenter Browser-Agent – Für Workflows über mehrere Sitzungen in Browserumgebungen konzipiert. Nutzt Werkzeuge wie Playwright, um Webinteraktionen zu automatisieren. Gut geeignet für die Nutzung innerhalb bestehender Automatisierungspipelines. Die Einrichtung ist mit Conda schnell erledigt.
2. Workflow-Automatisierung und Orchestrierung
Werkzeuge, die Workflows automatisieren und mehrere Plattformen oder Dienste integrieren, oft mit der Fähigkeit, KI-Agenten einzubinden.
Allgemeine Workflow-Automatisierung und Integration
Plattformen, die APIs verbinden, Ereignisse auslösen und Aufgaben automatisieren, wodurch die Erstellung und Integration von Workflows über verschiedene Systeme hinweg vereinfacht wird.
- n8n – Visuelle Workflow-Automatisierung und API-Integration – Verbindet Apps, Trigger und Datenflüsse über einen Knoteneditor. Kombiniert visuelles No-Code-Bauen mit benutzerdefiniertem JavaScript/Python und unterstützt über 400 Integrationen. Sie können es selbst hosten und KI-Agenten-Workflows mit LangChain ausführen. Ideal für technisch versierte Personen.
- PlanExe – LLM-zu-Gantt/WBS-Planungswerkzeug – KI-Planer, ähnlich wie OpenAIs Deep Research. Wandelt natürlichsprachliche Ziele in strukturierte Zeitpläne mit LlamaIndex um.
- Agno ✳️ – Entwicklerfreundliches Workflow- und Agentenbauwerkzeug – Passt sowohl als Workflow-Automatisierungswerkzeug (hilft bei der Automatisierung von Aufgaben und Workflows) als auch als Agenten-Builder.
- SmolAgents ✳️ – Leichtgewichtiges Agenten-SDK für Entwickler – SmolAgents ist flexibel genug, um sowohl als leichtes Agenten-SDK (für Agenten-Frameworks) als auch als Workflow-Werkzeug (da es mit Hugging Face-Modellen integriert ist) zu fungieren.
- Windmill – Open-Source-Entwicklerplattform und Workflow-Engine – Wandelt Skripte in Benutzeroberflächen, APIs und Cron-Jobs um; unterstützt Python, TypeScript, Go und andere Sprachen.
- Activepieces – Open-Source-Automatisierungsplattform – Selbstgehosteter visueller Workflow-Builder zur Automatisierung von Aufgaben und Integration von Apps mit minimalem Codieren. Unterstützt 280+ MCP-Server, um verteilte KI-Aufgaben und Agentenkettungen im großen Maßstab auszuführen.
- Huginn – Web-Automatisierung und Agentenverwaltung – Erstellt Agenten zur Automatisierung webbasierter Aufgaben und Überwachung.
- Node-RED – Flussbasierte Entwicklung für IoT und Echtzeitdaten – Integriert Dienste und automatisiert Aufgaben mit einem browserbasierten Flusseditor.
Multi-Agenten-Workflow-Orchestrierung
Frameworks, die darauf ausgelegt sind, interagierende Agenten über strukturierte Workflows hinweg zu koordinieren und Multi-Agenten-Systeme zu integrieren.
- HyperAgent – Vollständige Software-Lebenszyklus-Agenten-Orchestrierung – Agenten arbeiten zusammen, um Engineering-Aufgaben zu planen, zu codieren und zu verifizieren.
- Supercog – agentic – Modulare Orchestrierung mit wiederverwendbaren Logikblöcken – Entwickelt für skalierbare, strukturierte, teambasierte Automatisierung.
3. Web-Automatisierung und Navigation
Agenten navigieren autonom durch Websites und führen mehrstufige Aufgaben aus, wie Formularausfüllung, Datenauswertung und Web-Browsing-Automatisierung.
Autonome Web-Agenten und Copiloten
Allgemeine autonome Agenten (webfähig):
- AgenticSeek – Vollständig autonomer Web-Browsing-Agent – Vollständig lokaler Manus KI. Spezialisiert auf Datenauswertung und Formularausfüllung, automatisiert webbasierte Aufgaben.
- Agent-E – DOM-orientierte Browser-Automatisierungs-Agent – Konzentriert sich auf die Interaktion mit Webseiten durch Parsen des (Document Object Model) DOM, ideal zum Klicken von Schaltflächen und Ausfüllen von Formularen.
- AutoWebGLM – LLM-basierter Web-Agent – Nutzt Verstärkendes Lernen und HTML-Vereinfachung für eine bessere Navigation durch komplexe Websites.
Bildbasierte Web-Navigationsagenten (multimodal):
- Autogen-Erweiterung WebSurfer – Multimodaler Web-Agent – Kombiniert Text- und visuelle Eingaben (Bildschirmfotos), um die Webinteraktion zu verbessern.
- Skyvern – KI-Agent mit Computer Vision – Automatisiert Workflows mit LLMs und Computer Vision und verarbeitet sowohl Text- als auch visuelle Elemente.
- WebVoyager – Seh-fähiger Web-Agent – Nutzt Text und Bildschirmfotos, um die Navigation auf bildlastigen Websites zu verbessern.
Weitere Informationen zu Open-Source-Web-Automatisierung und -Navigation finden Sie in dieser strukturierten Übersicht einiger der besten Tools und Agenten:
Web-Automatisierung & Scraping-Toolkits
LLM-gestützte Web-RPA und Browser-Erweiterungen
4. Codierung und Entwicklung
KI-Agenten, die bei Codierungsaufgaben unterstützen und Entwicklern in Echtzeit Unterstützung durch Codevorschläge, Fehlerbehebung und Aufgabenautomatisierung bieten.
CLI-basierte Codierungsagenten
- Codex CLI – Mehrfachmodus-Interaktionstool (vorschlagen, bearbeiten, ausführen) – Verbessert Entwickler-Workflows über die Kommandozeile durch Codevorschläge und -bearbeitungen.
- OpenDevin – Open-Source-KI-Codierungsassistent – Unterstützt bei Programmieraufgaben und bietet Codevorschläge für verschiedene Sprachen. Hinweis: OpenDevin wurde kürzlich in OpenHands umbenannt, um seine breitere Mission „All Hands KI“ widerzuspiegeln.6
- Aider – KI-Pair-Programming-Assistent – In Ihre Konsole integriert, um Codierungsunterstützung zu bieten, mit Unterstützung für Autovervollständigung, Fehlerbehebung und Aufgabenautomatisierung.
KI-Code-Editoren
- Neovim – KI-integrierter Code-Editor – KI-gestützte Plugins, die Codevervollständigungen und Refactoring bieten.
- Visual Studio Code (VS Code) – KI-gestütztes Codevervollständigungs- und Debugging-Tool – Bietet Codevorschläge und Autovervollständigung über GitHub Copilot, integriert in IDE-Umgebungen für Entwickler.
- Cursor – KI-integrierter Code-Editor – Mit Echtzeit-KI-Codevervollständigung gebaut.
Prompt-zu-App-Bauwerkzeuge (Vibe-Coding)
Open-Source-Alternativen zu v0 / lovable / Bolt:
- Dyad – Open-Source-KI-App-Bauwerkzeug – Lokal-first, No-Code-Werkzeug zum Erstellen KI-gestützter Anwendungen mit natürlichsprachlichen Befehlen.
- vx.dev – Open-Source-KI-App-Bauwerkzeug – Ein lokal-first, Low-Code-Werkzeug, das darauf abzielt, natürlichsprachliche Prompts in Apps umzuwandeln.
5. Cybersicherheit
KI-Agenten, die Cybersicherheitsoperationen verbessern, einschließlich Aufgaben wie Penetrationstests, Schwachstellenentdeckung, Red-Teaming und autonome Bedrohungserkennung.
- YAWNING TITAN – Abstrakte, graphbasierte Cybersicherheitssimulation – Unterstützt das Training von Agenten für autonome Cyberoperationen mit Fokus auf graphbasierte Umgebungen.
- bumpgen – Paketverwaltungs-Agent – Aktualisiert npm-Pakete (Node.js-Paketmanager) automatisch.
- Cyber-Security LLM Agents – LLM-gestützte Cybersicherheitsaufgaben – Aufgebaut auf AutoGen. Wird in verschiedenen Forschungsanwendungen verwendet, um ChatGPT-EDR-Automatisierung und automatisiertes CI/CD für Detection Engineering zu demonstrieren.
6. KI-Videokreation
KI-Agenten, die bei der Erstellung, Bearbeitung und Verbesserung von visuellen und multimedialen Inhalten helfen, einschließlich Kunst, Bildern und Videos.
- Mochi – Text-zu-Video-Generierung – Wandelt Text-Prompts in Videos um, mit Fokus auf Kurzformvideos. Gut geeignet, um schnell Videos aus textlichen Beschreibungen zu generieren.
- CogVideo – Text-zu-Video-Generierung – Wandelt Text-Prompts in Videos mit hoher Genauigkeit um und ermöglicht die Erstellung von Bild-zu-Video. Ein fortgeschritteneres Werkzeug für hochwertige Videoerstellung aus Text oder Bildern.
- Allegro – Text-zu-Video-Generierung – Wandelt Text-Prompts in Videos mit Fokus auf kreative Inhalte. Dieses Werkzeug betont die kreative Videosynthese aus Text, um einzigartige visuelle Erzählungen zu erzeugen.
- DALL·E (Open-Source-Versionen) – Text-zu-Video-Generierung – Generiert Bilder aus Textbeschreibungen und verwandelt schriftliche Prompts in detaillierte und kreative visuelle Inhalte.
7. Finanzen
KI-Agenten, die automatisierte Verstärkungslernverbesserung oder Echtzeitanalyse finanzieller Daten liefern.
- FinRL – Automatisiertes Verstärkungslernen für den Handel – Lernt und führt Handelsstrategien autonom basierend auf Marktdaten aus und passt sich dynamischen Finanzumgebungen an.
- OpenBB Terminal – Finanzdatenanalyse – Bietet autonome Finanzeinblicke für den Echtzeit-Handel und ermöglicht es Investmentexperten, fundierte Handelsentscheidungen zu treffen.
8. Gesundheitswesen
KI-Agenten, die bei medizinischer Diagnostik, Krankheitsüberwachung und Gesundheitseinsichten helfen, indem sie Patientendaten und medizinische Berichte analysieren.
- HIA (Health Insights Agent) – Medizinische Berichtsanalyse – Analysiert medizinische Berichte und liefert Gesundheitseinsichten.
- KI-HealthCare-Assistant – Krankheitsdiagnose und -überwachung – Diagnostiziert und überwacht Krankheiten anhand von Patientendaten.
9. Forschung
KI-Agenten, die bei Datensammlung, Literaturrecherche und Hypothesentests helfen und den Forschungsprozess beschleunigen.
- ChemCrow – Autonomer Chemieforschungs-Agent – Integriert LLMs mit Chemiewerkzeugen, um komplexe experimentelle und rechnerische Aufgaben in der chemischen Analyse zu planen und auszuführen.
- GPT Researcher – Autonomer allgemeiner Forschungsassistent – Führt strukturierte Online-Suchen durch, analysiert Inhalte und erstellt detaillierte Forschungsberichte mit minimalem Benutzereingriff.
10. Datenanalyse
KI-Agenten, die Daten verarbeiten, analysieren und interpretieren, um umsetzbare Erkenntnisse zu liefern und die Entscheidungsfindung zu unterstützen.
Finanzen
- FinRobot – Finanzdatenanalyse-Agent – Automatisiert die Interpretation und Berichterstattung von Finanzdaten unter Verwendung großer Sprachmodelle.
Business Intelligence und Abfragen
- Wren KI – Text-zu-SQL-Business-Erkenntnis-Agent – Wandelt natürlichsprachliche Fragen in SQL-Abfragen für Business-Reporting um.
- Entaoai – GenAI-unterstütztes Datenengineering-Tool – Bietet eine Chat-Oberfläche für Datenabfragen und -transformation.
- Vanna KI – Natürlichsprache zu SQL-Agent – Generiert SQL-Abfragen basierend auf Benutzer-Prompts, um strukturierte Datensätze zu erkunden.
Soziale Medien
- Twitter Personality Agent – Social-Media-Analyse-Agent – Analysiert Tweet-Verlauf, um Verhaltens- und Persönlichkeitsmerkmale abzuleiten.
11. Persönliche Assistenz
KI-Agenten, die bei Aufgabenmanagement, Terminplanung und persönlicher Organisation helfen und so Produktivität und Zeitmanagement verbessern.
- VacAIgent (vorab gebauter CrewAI-Agent) – Reiseplanungsassistent – Generiert autonom vollständige Reisepläne mit Streamlit und LLMs.
- Inbox Zero – E-Mail-Assistent – Priorisiert, klassifiziert und fasst Nachrichten mit natürlicher Sprachverarbeitung und Gmail-Integration zusammen.
- Cal – Kalenderplanungs-Agent – Automatisiert Erstellung, Umscheduling und Zusammenfassung von Meetings über LLM-basierte Interaktion.
Aufbau von KI-Agentensystemen
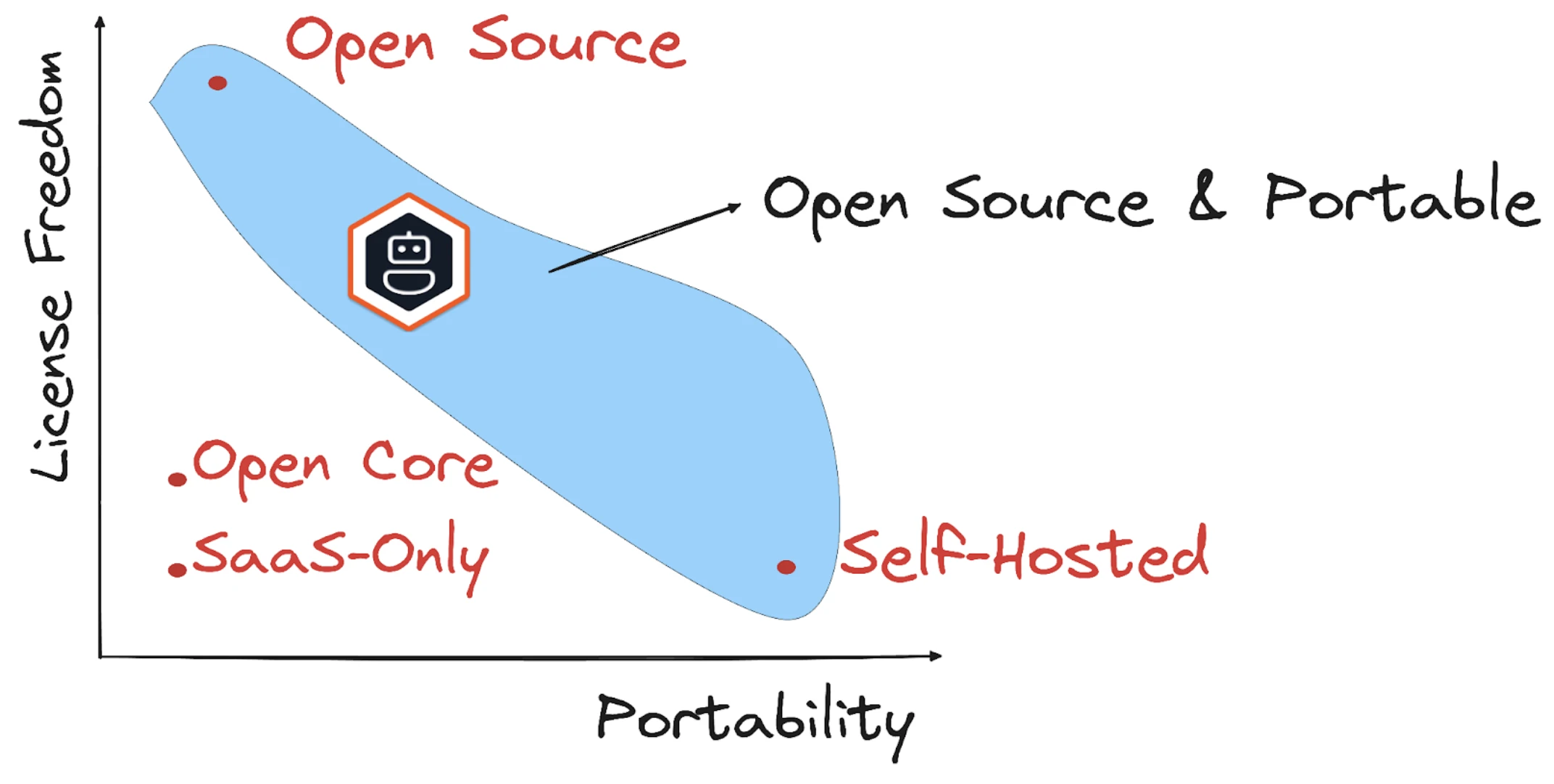
Viele KI-Frameworks werden von einem einzelnen Anbieter oder öffentlichen Repositories kontrolliert, aber streng geregelt.
Diese Projekte bewegen sich oft in Richtung Open-Core-Modelle: Der Basiscode bleibt kostenlos, aber Multi-Agenten-Orchestrierung, Beobachtbarkeit oder feingranulare Kontrolle können hinter kommerziellen Lizenzen verborgen sein. Bei einigen „offenen“ Ökosystemen erfordert die Produktivnutzung oft den Kauf einer geschlossenen Backend-Lösung.
Quelle7
Reale KI-Agenten-Projekte
Aus unserer Erfahrung einige KI-Agenten-Anwendungen:
- API-Entwicklung
- App-Erstellung
- KI-Website-Generierung
- Screenshot-zu-Code-Ausführung
- Lieferungen bestellen
- Restaurantreservierung vornehmen
- Ein Zimmer gestalten
Weitere standalone KI-Agenten-Projekte:
Weitere frameworkbasierte KI-Agenten-Projekte:
Weiterführende Lektüre
- Vergleichen Sie 20 LLM-Sicherheitstools und Open-Source-Frameworks
- Was sind die Top 10 LLM-Sicherheitsrisiken
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Die besten 50+ Open-Source-KI-Agenten im Überblick}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Abgerufen am 14. Mai 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.