Beste 12+ KI-Web-Scraping-Agenten (Kostenlos & Bezahlte)
Manuelle CSS-Selektoren und einfache Skripte funktionieren nicht mehr gut. Da Web-Architekturen dynamischer und KI-gesteuerter werden, werden traditionelle Scraping-Methoden weniger effektiv.
Um Daten zuverlässig zu halten, wendet sich die Industrie an autonome KI-Agenten, visuelles Scraping (VLM) und selbstheilende Scraper. Besuchen Sie die besten KI-Web-Scraping-Tools:
Beste KI-Web-Scraping-Tools
Wie wir diese Liste erstellt haben
Wir haben absichtlich allgemeine Daten-Scraping-Tools und Automatisierungsbibliotheken ausgeschlossen, die keine integrierten KI-Funktionen haben (wie Scrapy oder Playwright), auch wenn sie häufig für Web-Scraping verwendet werden und KI-Tools in hybriden Workflows ergänzen können.
Wir haben diese Liste nach folgenden Kriterien kuratiert:
- Fokus auf KI-gestützte Fähigkeiten: Wir haben Tools aufgenommen, die künstliche Intelligenz verwenden, wie z. B. LLMs und NLP, um die Seitenstruktur ohne fest codierte Regeln oder prompt-gesteuerte Datenextraktion zu verstehen.
- Zugänglichkeit für Benutzer: Wir haben Tools basierend auf dem technischen Niveau kategorisiert, z. B. No-Code- vs. Entwickler-Tools.
Was ist KI-Web-Scraping?
KI-Web-Scraping hat sich zu einer autonomen Datenliquidation entwickelt. Es geht nicht mehr darum, Browserklicks zu automatisieren oder HTML zu parsen; es beinhaltet Vision-Language-Modelle (VLMs), die eine Webseite wie ein Mensch „sehen“, und agentenbasiertes Reasoning, das komplexe Authentifizierung und dynamische Inhalte ohne vordefinierte CSS-Selektoren oder DOM-Mapping navigieren kann.
Typen von KI-Web-Scraping-Tools
1. KI-gestützte Plattformen
Diese Lösungen verwenden LLMs, Computer Vision oder NLP, um Inhalte von Webseiten zu parsen, zu extrahieren oder zu interpretieren. Beispielsweise passt sich das adaptive Scraping von Diffbot dynamisch an DOM-Änderungen oder inkonsistente Markup-Strukturen über Seiten hinweg an. Viele Tools in dieser Kategorie unterstützen entweder schema- (strukturierte) oder prompt-basierte Extraktion.
Sie geben dem Tool eine natürliche Sprachanweisung, zum Beispiel: „Extrahiere alle Jobtitel und Firmennamen von dieser URL.“
2. No-Code-Tools
No-Code-Scraper bieten visuelle Schnittstellen, die es Benutzern ermöglichen, die zu erfassenden Daten mithilfe von Point-and-Click-Funktionalität oder vorgefertigten Vorlagen zu definieren. Sie können Regeln zur Datenextraktion visuell definieren.
Allerdings bieten diese Tools im Vergleich zu KI-gestützten Plattformen, die KI zur Mustererkennung oder intelligenten Feldvorschlägen nutzen, eine begrenzte KI-Nutzung.
3. Open-Source-KI-Tools
Diese Kategorie umfasst Bibliotheken oder Frameworks, die LLMs oder KI-Agenten verwenden, um Daten von Webseiten zu extrahieren. Sie bieten programmatische Kontrolle; Sie müssen Extraktionsschemata oder KI-Prompts definieren.
Techniken und Technologien im KI-gestützten Web-Scraping
Der Ansatz des KI-gestützten Web-Scrapings passt sich automatisch an Website-Neugestaltungen an und extrahiert Daten, die dynamisch über JavaScript geladen werden. Es ist wichtig, diese Methoden unter Berücksichtigung der Nutzungsbedingungen und ethischen Überlegungen der Website einzusetzen.
1. Adaptives Scraping
Traditionelle Web-Scraping-Methoden basieren auf der spezifischen Struktur oder dem Layout einer Webseite. Wenn Websites ihre Designs und Strukturen aktualisieren, können traditionelle Scraper leicht brechen. KI-basierte Datenerfassungsmethoden wie adaptives Scraping ermöglichen es Web-Scraping-Tools, sich an Änderungen auf Websites anzupassen, einschließlich Design und Struktur.
Adaptive Scraper verwenden maschinelles Lernen und KI, um ihr Verhalten dynamisch an die Struktur einer Webseite anzupassen. Sie identifizieren autonom die Struktur der Zielseite, indem sie das Document Object Model (DOM) analysieren oder spezifischen Mustern folgen. Um Muster zu identifizieren oder Änderungen vorherzusagen, kann das Tool mit gescrapten historischen Daten trainiert werden.
Beispielsweise können KI-Modelle wie Convolutional Neural Networks (CNNs) verwendet werden, um visuelle Elemente einer Webseite wie Buttons zu erkennen und zu analysieren. Typischerweise verlassen sich traditionelle Daten-Scraping-Techniken auf den zugrunde liegenden Code einer Webseite, wie z. B. HTML-Elemente, um Daten zu extrahieren.
Zero-Shot-Vision-Extraktion:
Traditionelles adaptives Scraping basiert immer noch auf dem DOM-Baum. Allerdings haben sich Tools wie Firecrawl und Crawl4AI im Jahr 2026 zur „Zero-Shot“-Extraktion entwickelt. Durch die Aufnahme eines visuellen Schnappschusses (VLM) identifiziert die KI Elemente basierend auf visueller Absicht und nicht auf Code. Dies macht Scraper widerstandsfähiger gegen CSS-Klassen-Randomisierung und „Honey-pot“-Code-Fallen.
Gesponsert
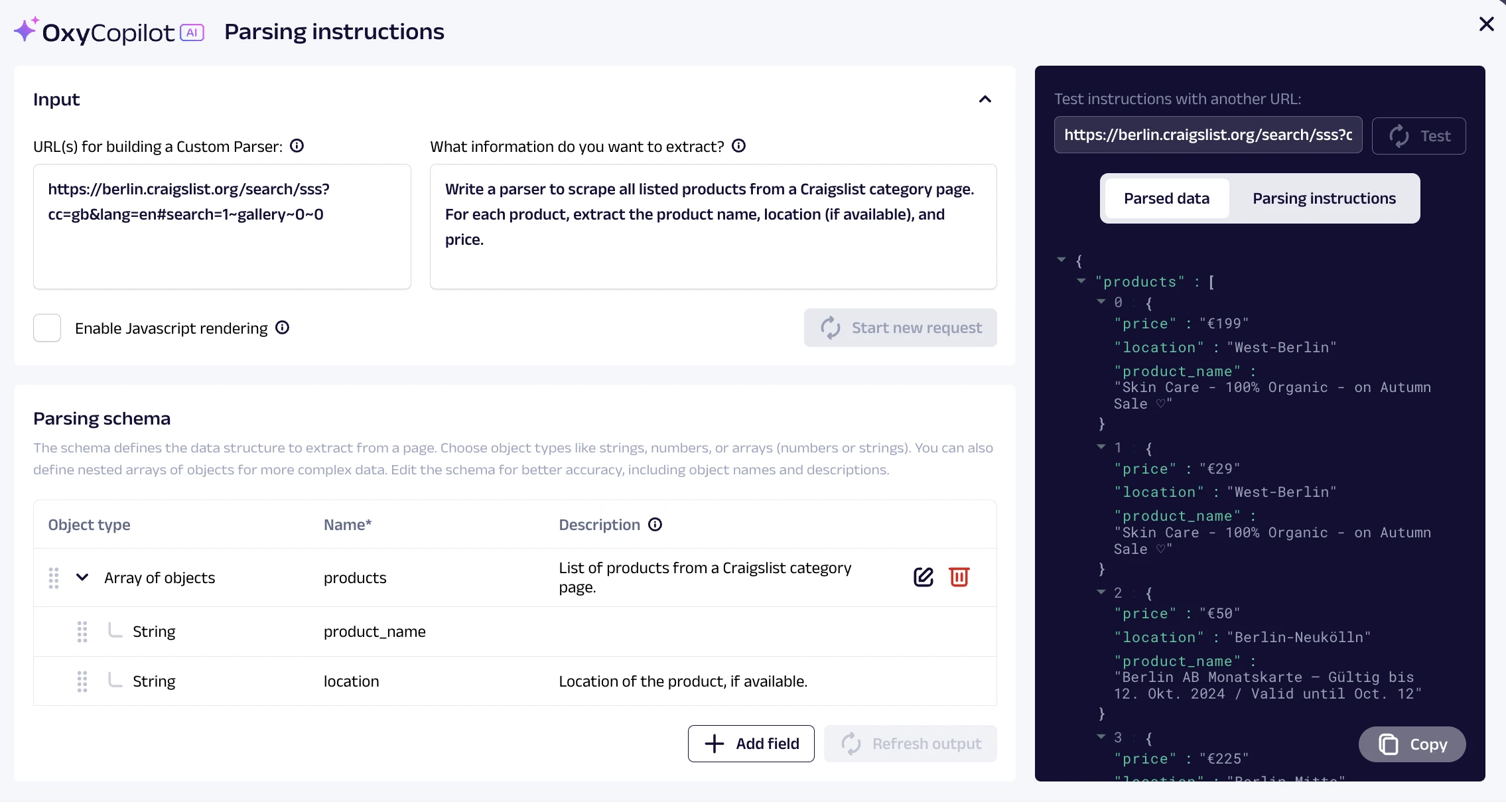
Oxylabs bietet einen ML-basierten benutzerdefinierten Parser-Builder namens OxyCopilot, der die Web Scraper API von Oxylab verbessert und es Benutzern ermöglicht, gesammelte Daten mithilfe von Prompts zu verfeinern und zu organisieren. Dies strafft den Prozess, indem die Notwendigkeit entfällt, irrelevante Datenfelder zu sortieren oder manuelle Datenbereinigung durchzuführen.
2. Generierung menschenähnlicher Surf-Muster
Die meisten Websites setzen Anti-Scraping-Maßnahmen wie CAPTCHAs ein, um Web-Scraper daran zu hindern, auf ihre Inhalte zuzugreifen und sie zu scrapen. KI-gestützte Web-Scraping-Tools können menschenähnliches Verhalten wie Geschwindigkeit, Mausbewegungen und Klickmuster simulieren.
3. Generative KI-Modelle
Im Jahr 2025/2026 haben wir aufgehört, KI zu bitten, BeautifulSoup-Code zu schreiben. Stattdessen verwenden wir Scraping-Agenten (wie Skyvern oder Browser-use).
- Funktionsweise: Sie geben ein Ziel in einfachem Englisch an (z. B. „Finde den günstigsten Laptop auf dieser Seite und exportiere ihn nach JSON“).
- Reason-act (ReAct)-Muster: Der Agent erkundet die Site, löst CAPTCHA, behandelt Paginierung und validiert die Datenqualität in Echtzeit, ohne eine einzige Zeile manuellen Codes.
4. Natural Language Processing (NLP)
NLP, ein Teilbereich des ML, ermöglicht es Ihnen, Aufgaben wie Sentiment-Analyse, Inhaltszusammenfassung und Entitätserkennung durchzuführen. Es ist notwendig, Erkenntnisse aus den gescrapten Daten abzuleiten.
Wenn Sie beispielsweise eine erhebliche Menge an Produktbewertungsdaten extrahiert haben, müssen Sie die emotionale Tonalität hinter jedem Wort bestimmen, z. B. positiv, negativ oder neutral. Die Sentiment-Analyse ermöglicht es Ihnen, die extrahierten Daten als positiv oder negativ zu kategorisieren. Dies hilft Unternehmen, Kundenbedenken anzusprechen und ihre Angebote zu verbessern.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Beste 12+ KI-Web-Scraping-Agenten (Kostenlos & Bezahlte)}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraping}},
note = {AIMultiple. Abgerufen am 5. Juni 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.