Graph-Datenbank-Benchmark: Neo4j vs FalkorDB vs Memgraph
Wir haben Neo4j, FalkorDB und Memgraph an einem synthetischen Graphen getestet, der von 120.000 Amazon-Produktbewertungen abgeleitet ist (381K Knoten, 804K Kanten). Wir führten 12 Abfragevorlagen mit jeweils 1.000 Messungen aus, testeten die Ingestion bei 6 Batch-Größen, hielten eine gleichzeitige Last für 60 Sekunden bei bis zu 32 Threads aufrecht und maßen Speicher, Cold Start, gemischte Workloads und den Einfluss von Indizes.
FalkorDB lieferte bei 8 Threads einen höheren Durchsatz als Neo4j und Memgraph.
Ergebnisse des Graph-Datenbank-Benchmarks
Gleichzeitiger Durchsatz
QPS (Queries per Second) misst, wie viele Leseabfragen die Datenbank unter gleichzeitiger Last mit mehreren Threads pro Sekunde beantwortet. Jeder Lauf dauert 60 Sekunden. Höher ist besser.
Abfrage-Latenz (p50)
p50 ist die Median-Latenz: Die Hälfte aller Abfragen ist schneller als dieser Wert abgeschlossen. Niedriger ist besser.
- Punkt-Abfrage: Abrufen eines einzelnen Knotens per ID. FalkorDBs Redis-Hash-Tabellen führen O(1)-Speicherzugriffe durch, etwa 3x schneller.
- Traversal: Weg von einem Knoten zu seinen Nachbarn (1-Hop) oder Nachbarn-von-Nachbarn (2-Hop). FalkorDB erledigt 2-Hop in 2,9x kürzerer Zeit.
- Aggregation: Zählen von Bewertungen pro Marke, Berechnung der durchschnittlichen Sternbewertungen.
- Filter + Scan: Filtern von Bewertungen nach Sternbewertung im gesamten Datensatz.
Ingestion-Durchsatz
Der Ingestion-Durchsatz misst, wie viele Bewertungen pro Sekunde die Datenbank schreiben kann. Jeder Punkt auf dem Diagramm entspricht einer anderen Batch-Größe: Wie viele Bewertungen in einer einzelnen Abfrage gruppiert werden. Höher ist besser.
Bei Batch-Größe 1 führt Memgraph (1.427/s). Mit zunehmender Batch-Größe skaliert FalkorDB steil und kreuzt Memgraph bei etwa Batch 500. Neo4j flacht bei ~10.600/s unabhängig von der Batch-Größe ab. Bei Batch 5.000 erreicht FalkorDB 22.784/s, das 77-fache seiner Batch-1-Leistung.
Sie können mehr über unsere Graph-Datenbank-Benchmark-Methodik lesen.
Wichtige Erkenntnisse
FalkorDB erreicht 6.693 QPS bei 8 Threads, 6,7x Neo4j
Redis' speicherinterne Datenstrukturen und Event-Loop ermöglichen es, latenzarme Abfragen mit hoher Parallelität zu kombinieren. Nach 8 Threads flacht der Durchsatz ab, da der Redis-Kern mit einem Thread die Obergrenze darstellt. Neo4j erreicht bei 16 Threads seinen Höhepunkt (1.010 QPS) und fällt dann bei 32 (927 QPS) ab, was auf Thread-Konkurrenz hindeutet.
FalkorDB startet kalt in 1,1 ms, 82x schneller als Neo4j
Neo4j benötigt 90 ms, um nach einem Neustart die erste Abfrage zu akzeptieren. Die erste Wärmungsabfrage läuft bei 274 ms, dann dauert es etwa 3 Abfragen, bis es sich auf 34 ms einpendelt. FalkorDB ist in 1,1 ms bereit, erste Abfrage bei 0,4 ms. In einer Microservice- oder serverlosen Umgebung, in der Pods hoch- und runterskalieren, macht diese Lücke einen Unterschied.
Indizes: 1.700x Unterschied bei Neo4j, ~1x bei FalkorDB
Ohne Indizes dauerte Neo4js deep_feature_products-Abfrage 293 ms. Mit Indizes 0,17 ms. Das ist ein Unterschied von 1.712x. Memgraph zeigte eine ähnliche Sensitivität (160-898x je nach Abfrage). FalkorDBs Ergebnisse blieben mit oder ohne Indizes etwa gleich, da Redis-Hash-Tabellen bereits als implizite Indizes fungieren.
Speicher: 415 MB vs 2.668 MB für denselben Graphen
- Memgraph: 415 MB
- FalkorDB: 496 MB
- Neo4j: 2.668 MB (JMX-Heap verwendet)
Neo4js JVM alloziert beim Start 4 GB vor, daher ist der speicherverbrauch auf Prozessebene (VmRSS) immer ~5,2 GB, unabhängig von der tatsächlichen Datennutzung. Die JMX-Heap-Metrik ist die aussagekräftige. Der Peak von 2,7 GB ist die Zahl, die für die Kapazitätsplanung verwendet werden sollte.
Neo4j gewann die schwerste Aggregation
FalkorDB hatte bei 11 von 12 Abfragen die niedrigste Latenz. Die Ausnahme war agg_feature_sentiment (Gruppierung nach Sentiment mit Filterung), bei der Neo4js Abfrageoptimierer einen besseren Ausführungsplan lieferte: 131 ms vs FalkorDBs 152 ms.
Gemischter Workload (80 % Lesen, 20 % Schreiben)
8 Threads, 60 Sekunden, null Fehler bei allen drei Datenbanken:
- FalkorDB: 50.223 Ops (837 QPS)
- Neo4j: 44.256 Ops (738 QPS)
- Memgraph: 28.040 Ops (467 QPS)
Schreiboperationen verschlechterten die Leseleistung bei keiner der Datenbanken spürbar.
Architekturen in diesem Benchmark
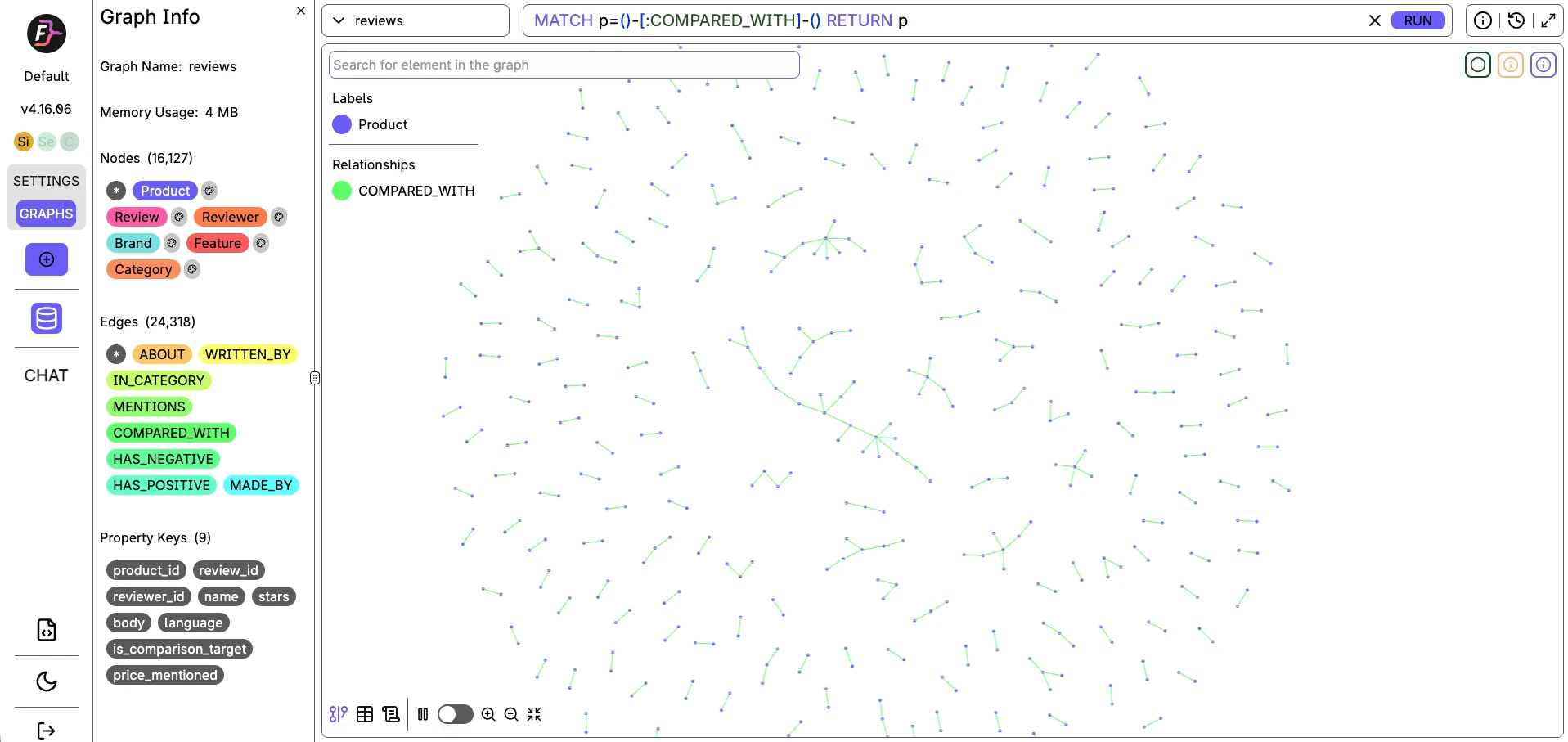
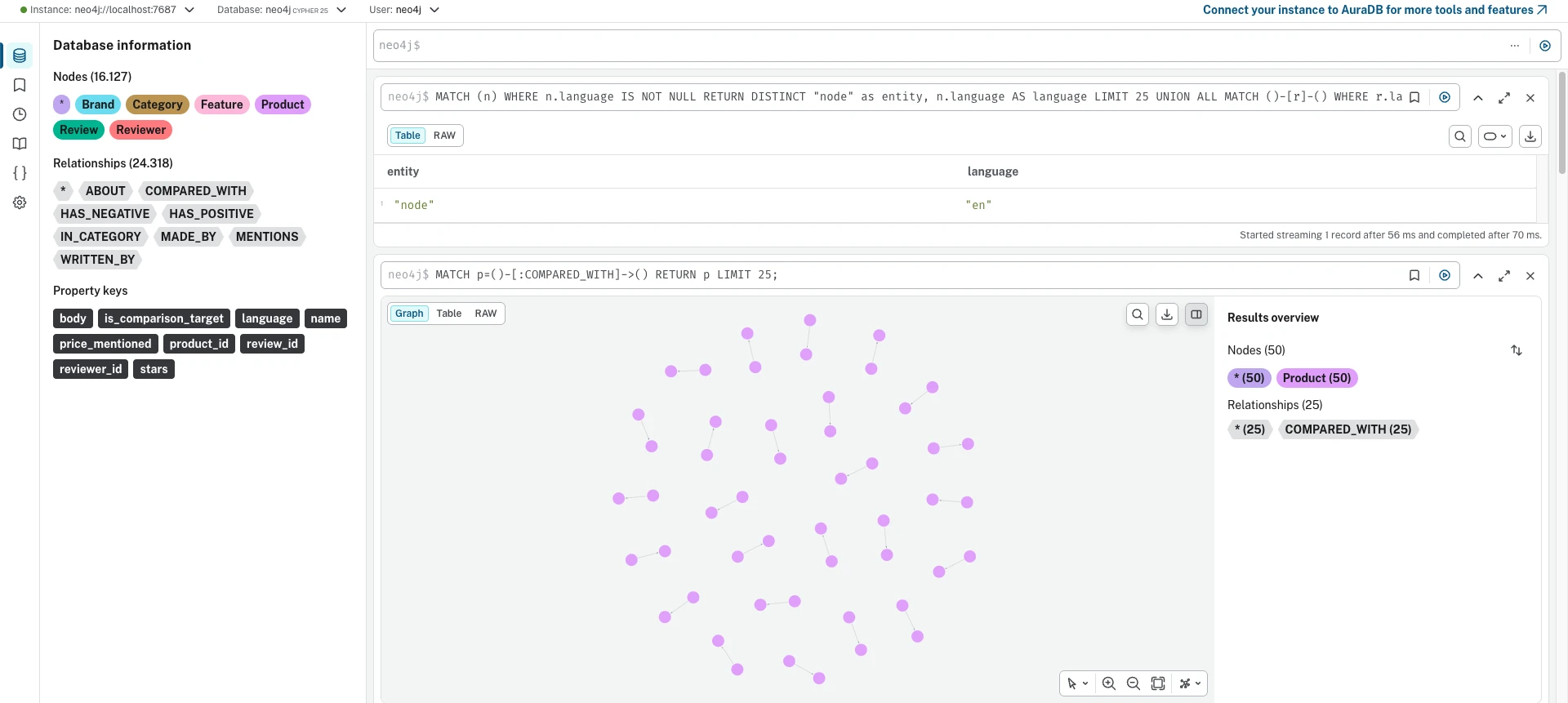
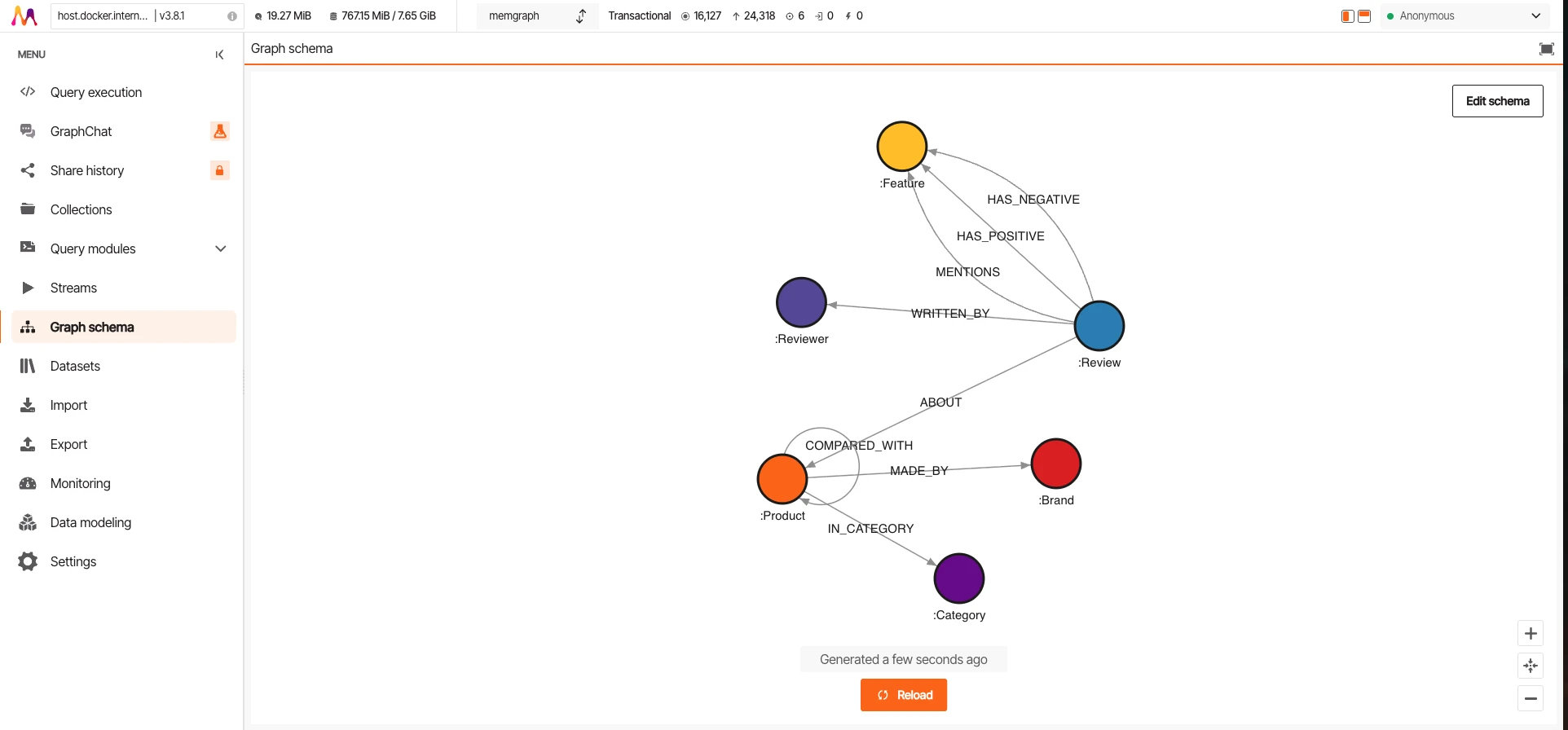
Jede Datenbank liefert ihre eigene Management-UI. Diese Screenshots zeigen denselben Datensatz (16.127 Knoten, 24.318 Kanten), der in alle drei geladen wurde und dieselbe COMPARED_WITH-Traversal-Abfrage ausführt.
FalkorDB
FalkorDB ist ein Graph-Modul, das auf Redis' speicherinternem Key-Value-Speicher aufbaut. Abfragen sind openCypher, aber darunter sind es Redis-Hash-Tabellen. Deshalb landen Punkt-Abfragen bei 0,044-0,048 ms.
Die anderen beiden Datenbanken in diesem Benchmark maßen bei denselben Abfragen 2-3x höher. Der Kompromiss ist, dass Redis' Single-Thread-Kern bedeutet, dass der gleichzeitige Durchsatz nach 8 Threads nicht weiter skaliert.
Neo4j
Neo4j läuft auf der JVM. JIT-Kompilierung bedeutet, dass wiederholte Abfragen im Laufe der Zeit schneller werden (Warmup: 274 ms -> 34 ms). GC-Pausen beeinflussen die Tail-Latenz, werden aber durch IQR-Ausreißerentfernung abgefangen. Der Abfrageoptimierer bewältigt komplexe Aggregationspläne gut, und davon kommt der agg_feature_sentiment-Sieg. Der Preis ist die 4 GB Heap-Vorallokation und GC-Overhead.
Memgraph
Memgraph ist in C++ geschrieben. Kein JVM-Overhead. 415 MB für den gesamten Datensatz, der niedrigste der drei. Am schnellsten bei einzelnen Inserts (1.427/s) dank minimalem Abfrage-Overhead. Aber es hinkt beim gleichzeitigen Durchsatz hinterher (684 QPS Peak). Bolt-kompatibel, funktioniert also mit dem Neo4j-Treiber.
Methodik des Graph-Datenbank-Benchmarks
Umgebung
- RunPod 8 vCPU (AMD EPYC x86_64), 32 GB RAM, Ubuntu 24.04 LTS
- Native Installation, kein Docker. Alle drei Datenbanken auf derselben Maschine, localhost-Verbindungen.
- Python 3.12.3. Persistente Sessions für Single-Thread-Tests, pro-Call-Sessions aus einem Verbindungspool für Multi-Thread-Tests.
Daten
- 120.000 synthetische Bewertungen generiert aus Zipf (Marken, Merkmale) und Poisson (Entitäten, Beziehungen) Verteilungen, fester Seed=42.
- 6 Knotentypen: Bewertung, Produkt, Bewerter, Marke, Merkmal, Kategorie
- 8 Kantentypen: ABOUT, WRITTEN_BY, IN_CATEGORY, MADE_BY, HAS_POSITIVE, HAS_NEGATIVE, MENTIONS, COMPARED_WITH
Abfragen
12 Cypher-Vorlagen in 5 Kategorien: Punkt-Abfrage (3), 1-Hop-Traversal (2), 2-Hop-Traversal (2), Aggregation (3), Filter (1), Full Scan (1). Jede parametrisierte Abfrage wird mit 10 verschiedenen Parameterwerten 100 Mal ausgeführt, für 1.000 Messungen pro Abfrage pro Datenbank.
Parameter werden aus dem gesamten ID-Raum unter Verwendung einer Zipf-gewichteten Auswahl gesampelt, sodass sowohl beliebte als auch seltene Elemente getestet werden.
Drei Beispiele:
Punkt-Abfrage: Abrufen eines einzelnen Knotens per indexierter ID
2-Hop-Traversal: Weg von einer Marke durch ihre Produkte zu ihren Bewertungen
Aggregation: Full-Graph-Scan mit Multi-Hop-Join und Berechnung
Messung
- Timing:
time.perf_counter_ns(), 500 Warmup-Abfragen, mindestens 100 Runs pro Abfrage - Statistik: 10.000 Bootstrap-Samples, 95 % CI, IQR-Ausreißerentfernung (3,0x Faktor). Sowohl Roh- als auch gefilterte Daten werden berichtet.
- Speicher: Neo4j über JMX-Heap verwendet (VmRSS ist bedeutungslos, da JVM voralloziert), FalkorDB über Redis
used_memory_rss, Memgraph über/proc/{pid}/statusVmRSS.
Fairness
- Dieselbe Pool-Größe, Warmup-Anzahl, Cypher-Abfragen, Daten und Maschine bei allen drei Datenbanken.
- Gleichzeitiger Test: 60 Sekunden langanhaltende Last bei 1, 2, 4, 8, 16 und 32 Threads mit einem festen pool_size=32. Abfrage-Mix: 40 % 1-Hop-Traversal, 30 % 2-Hop-Traversal, 20 % Aggregation, 10 % 3-Hop-Traversal.
Getestete Datenbanken
Einschränkungen
Einzelmachine, einzelner Knoten pro Datenbank. Kein verteiltes oder Cluster-Benchmarking. Neo4j Enterprise-Clustering und Memgraph-Replikation liegen außerhalb des Rahmens.
Synthetische Daten mit Verteilungen, die von echten Amazon-Bewertungen abgeleitet sind. Entsprechen möglicherweise nicht spezifischen Produktions-Workload-Mustern.
Nicht gemessen: Festplatten-Persistenz/Wiederherstellung, Volltextsuche, Graph-Algorithmen (PageRank, Community-Erkennung) und schreibintensive Workloads (>50 % Schreibvorgänge).
Unterschiedliche Treiber: Neo4j und Memgraph verwendeten den Neo4j Python-Treiber, FalkorDB seinen eigenen. Der Overhead-Unterschied betrug
Fazit
FalkorDB gewann 11 von 12 Abfragen, erreichte 6.693 QPS und startete kalt in 1,1 ms. Für leseintensive Graph-Workloads ist es die schnellste Option in diesem Benchmark. Memgraph ist die speichereffizienteste Option (415 MB vs 2,7 GB). Neo4j bietet das breiteste Ökosystem: RBAC, Clustering, Monitoring und ein Abfrageoptimierer, der komplexe Aggregationspläne besser bewältigt als jede Alternative.
Die Architektur bestimmt die Obergrenze. Verteilte Cluster, Graphen mit 1 Mio. + Knoten und schreibintensive Workloads sind die Tests, die diese Rankings neu ordnen könnten.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Graph-Datenbank-Benchmark: Neo4j vs FalkorDB vs Memgraph}},
year = {2026},
month = apr,
howpublished = {\url{https://aimultiple.com/graph-databases}},
note = {AIMultiple. Abgerufen am 15. April 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.