Top 3 Synthetische Dokumentengeneratoren im Benchmark verglichen
Synthetische Dokumentengeneratoren erstellen annotierte, realistische Dokumentenbilder, die beim Trainieren und Evaluieren von Machine-Learning-Modellen helfen, ohne auf große, manuell gekennzeichnete Datensätze angewiesen zu sein.
Wir benchmarken 3 synthetische Dokumentengeneratoren, Genalog, DocCreator und Tonic Textual, indem wir mehr als 2.500 synthetische Dokumente erstellen und deren Effektivität bei realistischen Layouts, genauen numerischen Daten und Trainingsdatensätzen für Dokumentenanalyseaufgaben vergleichen.
Ergebnisse des Dokumentengenerierungs-Benchmarks
Die Ergebnisse zeigen, dass
- Genalog und DocCreator in Bezug auf Nutzen und Genauigkeit starke Leistungen erbringen, wobei Genalog bei der numerischen Genauigkeit leicht besser abschneidet.
- Tonic Textual bei der Realitätsnähe des visuellen Layouts glänzt, aber in anderen Bereichen zurückbleibt, was es für Aufgaben geeigneter macht, die realistische Dokumente erfordern.
Für weitere Informationen zu den Metriken lesen Sie die Benchmark-Methodik.
- Nutzen misst, wie gut Modelle, die auf synthetischen Daten trainiert wurden, bei echten Dokumenten abschneiden.
- Layout-Genauigkeit misst, wie gut die räumliche Anordnung der Elemente in synthetischen Dokumenten mit den realen übereinstimmt.
- Numerische Genauigkeit prüft, ob numerische Werte in synthetischen Dokumenten den realen Daten ähneln.
Kommentar zu den Ergebnissen: Um die Leistungsunterschiede besser zu verstehen, wurde der Benchmark auch mit dem Trainingsdatensatz anstelle des separaten Testdatensatzes durchgeführt. Diese sekundäre Evaluation zielte darauf ab, festzustellen, ob die Bereitstellung von Trainingsmaterial für die Modelle deren Fähigkeit verbessert, strukturierte und numerisch genaue Ausgaben zu reproduzieren.
Die Ergebnisse zeigen, dass die Modelle, selbst wenn sie auf Trainingsdaten evaluiert wurden, leicht höhere Scores erzielten. Dies deutet darauf hin, dass die Ergebnisse widerspiegeln, wie gut die Tools die Aufgabe selbst bewältigen. Die moderaten Ergebnisse werden wahrscheinlich durch Einschränkungen bei der OCR-Qualität und die Kapazität des trainierten Modells beeinflusst, eher als durch das Benchmark-Verfahren selbst.
Genalog
Genalog schnitt insgesamt am stärksten ab. Seine synthetischen Dokumente waren sehr effektiv für das Modelltraining und wiesen eine gute Balance zwischen realistischen Layout-Elementen und numerischer Genauigkeit auf. Die generierten Dokumente spiegelten die Struktur und den Abstand echter Formulare und Rechnungen eng wider, was sie für eine Vielzahl von Dokumentenanalyseaufgaben geeignet macht.
DocCreator
DocCreator produzierte ebenfalls hochwertige Ausgaben. Die Dokumente dieses Dokumentengenerators waren für das Training fast so nützlich wie die von Genalog. Die Layouts waren realistisch, und die synthetischen Dokumente bewahrten die statistischen Eigenschaften der Zahlen. Die Stärke von DocCreator liegt in der Kombination vielfältiger Layout-Generierung mit seinen Degradationsmodellen, was die Ausgaben visuell echten gescannten Dokumenten ähnelt.
Tonic Textual
Tonic Textual zeigte gemischte Ergebnisse. Obwohl dieser synthetische Dokumentengenerator sehr saubere und konsistente Layouts produzierte, waren die Dokumente für das Training von Modellen weniger effektiv. Darüber hinaus waren die synthetischen Zahlen nicht immer statistisch ähnlich wie echte Daten. Dies deutet darauf hin, dass Tonic Textual am besten für Aufgaben geeignet ist, die sich auf das Erscheinungsbild von Dokumenten oder den ersetzenden Datenschutz bei PII konzentrieren, und weniger für das Training in großem Maßstab für Layout-Struktur- und Informationsentnahmeaufgaben.
Im März 2026 wechselte Tonic Textual seine Entity-Linking-Komponente von einem LLM-basierten Modell zu einem BERT-basierten Modell, um den Durchsatz zu verbessern.1 Das gleiche Release (v391) fügte auch verbesserte Filter- und Sortierfunktionen auf der Seite „Datasets“ hinzu.2
Gesamteinschätzung
Genalog ist das am besten ausgewogene Tool und bietet sowohl realistische Layouts als auch genaue Zahlen.
DocCreator ist stark bei komplexen und vielfältigen Layouts und Dokumentendegradation, mit geringfügigen numerischen Ungenauigkeiten.
Tonic Textual ist ideal für layoutfokussierte Aufgaben, aber nicht für Aufgaben, die präzise numerische Daten erfordern.
Methodik-Übersicht
Evaluierungsmetriken
Jeder generierte Datensatz wurde anhand der folgenden Metriken gegen die Originaldaten bewertet:
Nutzen-Score
(KIE F1 Score): Ein Score zwischen 0 und 1, wobei höher besser ist. Er wird durch den F1-Score des auf den synthetischen Daten trainierten LayoutLMv3-Modells definiert, wenn es auf dem realen Testdatensatz evaluiert wird. Ein hoher Score zeigt an, dass die synthetischen Daten ein hochwirksamer Ersatz für echte Daten sind.
Genauigkeits-Scores
Diese Metriken messen, wie stark die synthetischen Dokumente den realen ähneln.
- Layout-Genauigkeit (EMD-Score): Die Earth Mover's Distance (dEMD) misst den Unterschied zwischen der Verteilung der Bounding-Box-Mittelpunkte in den realen versus synthetischen Dokumenten. Es ist ein Wert von 0 bis 1, wobei niedriger besser ist. Ein niedriger Score bedeutet, dass die räumlichen Layout-Elemente gut erhalten sind.
- Numerische Genauigkeit (K-S-Distanz): Die Kolmogorov-Smirnov-Distanz (DKS) misst die maximale Differenz zwischen den kumulativen Verteilungsfunktionen (CDFs) numerischer Werte (z. B. Preise, Mengen) in den realen und synthetischen Daten. Sie reicht von 0 bis 1, wobei niedriger besser ist. Ein niedriger Score bedeutet, dass der Generator die statistischen Eigenschaften der Zahlen genau reproduziert.
Alle Metriken wurden während der Berechnung normalisiert.
Datensätze
FUNSD: Eine Sammlung von 199 gescannten Formularen, die durch verrauschten Text, komplexe und vielfältige Layouts sowie handschriftliche Anmerkungen gekennzeichnet sind. Es wurde im letzten Monat mehr als 1.500 Mal heruntergeladen. Dies testet die Fähigkeit eines Generators, unstrukturierte und unvollkommene Daten zu verarbeiten. 3
- Wir teilen die Stichprobe in zwei Teile auf: 80 % der Daten werden zum Trainieren des Modells verwendet, während die verbleibenden 20 % nach dem Training für Tests reserviert sind.
- Jedes Tool produzierte zwischen drei und sechs synthetische Dokumente für jedes Original, was insgesamt mehr als 2.500 synthetische Dokumente ergibt.
Aufgabenbewertung
Um den Nutzen zu messen, wurde ein beliebtes LayoutLMv3-Modell mit 22K GitHub-Sternen und über 750K Downloads auf den von jedem synthetischen Dokumentengenerator-Tool generierten synthetischen Daten trainiert. 4
Die Leistung dieses Modells wurde dann auf einem zurückgehaltenen Testdatensatz von echten Dokumenten aus den Originaldatensätzen evaluiert. Dies misst direkt, wie nützlich die synthetischen Daten für eine reale Aufgabe sind.
Synthetische Generierungstools
Genalog
Eine Open-Source-Python-Bibliothek von Microsoft zur Generierung synthetischer Dokumentenbilder mit synthetischem Rauschen. Sie funktioniert, indem sie Text- und Layout-Vorlagen (geschrieben in HTML + CSS) nimmt und sie über WeasyPrint rendert, gefolgt von der Anwendung von Degradationseffekten (Unschärfe, Durchbluten, Salz-und-Pfeffer-Rauschen, morphologische Operationen).5
DocCreator
Ein plattformübergreifendes Open-Source-Tool zur Generierung synthetischer Dokumentenbilder mit zugehörigen Ground-Truth-Daten. Es wurde in der Forschung zur Dokumentenbildanalyse und -erkennung (DIAR) weit verbreitet eingesetzt.6 ,7
Tonic Textual
Eine Lösung für Redaktion und Synthese in realen Dokumentenformaten (PDF, Word). Es behauptet, unstrukturierte Dokumente zu scannen, benannte Entitäten (z. B. PII) zu identifizieren, sie zu redigieren oder durch synthetische Werte zu ersetzen und de-identifizierte Dokumente in ähnlichen Formaten auszugeben.
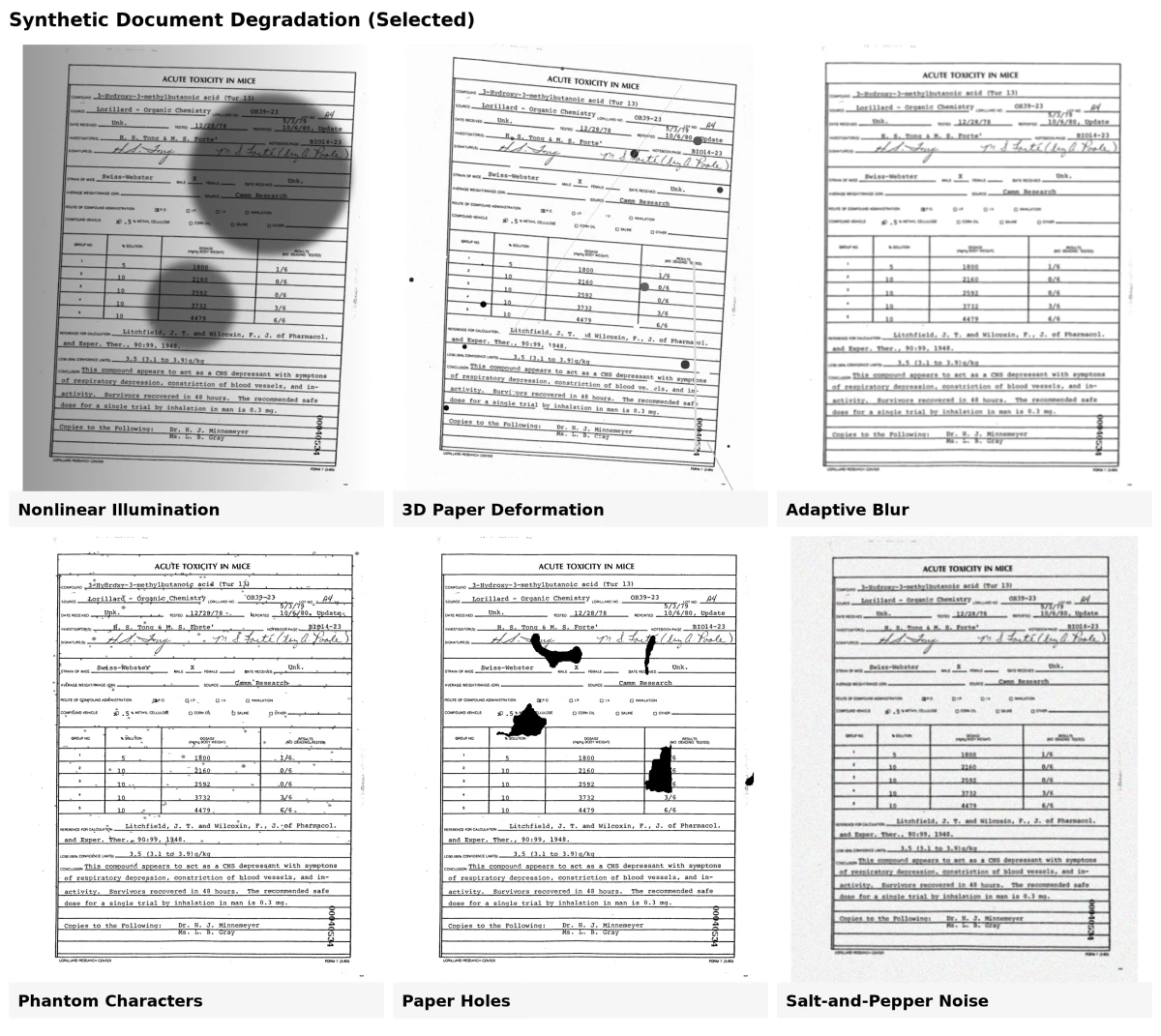
8 Methoden zur Degradation synthetischer Dokumente
Die Generierung synthetischer Dokumente umfasst oft das Hinzufügen realistischer Defekte, um künstliche Daten echten Dokumenten ähnlicher zu machen. Diese Defekte oder Degradationsmodelle helfen dabei, Modelle zu trainieren, die bei verrauschten, gealterten oder gescannten Dokumenten besser abschneiden. Diese Tools wenden mehrere physikalische und visuelle Transformationen an, um gängige Dokumentenunvollkommenheiten zu simulieren.8
1. Tintendegradation
Dieses Modell simuliert Verblassen, Flecken oder Streifen, die durch Alterung oder minderwertigen Druck verursacht werden. Es fügt kleine Tintenflecken hinzu oder entfernt Teile von Buchstaben, um echten Tintenverfall nachzuahmen.
2. Phantomzeichen
Alte Druckwerkzeuge hinterließen oft schwache Umrisse oder „Geister“-Markierungen um Buchstaben. Das Phantomzeichen-Modell rekonstruiert diese, indem es extrahierte Defekte aus echten Scans zwischen gedruckten Zeichen einfügt.
3. Papierlöcher
Löcher unterschiedlicher Formen und Größen werden zufällig zu Dokumenten hinzugefügt, um Risse oder Lochungen in abgenutztem Papier zu replizieren.
4. Durchbluten
Dieser Effekt imitiert Tinte, die von der anderen Seite der Seite durchdringt. Er verwendet sowohl Vorder- als auch Rückseitenbilder eines Dokuments, um nachzuahmen, wie die Tinte teilweise durch das Papier übergeht.
5. Adaptive Unschärfe
Das Scannen oder Fotografieren von Dokumenten erzeugt oft eine leichte Unschärfe. Dieses Modell vergleicht echte unscharfe Beispiele und wendet eine ähnliche Unschärfe mit Gauß-Filtern an, wobei das Ergebnis subtil und realistisch bleibt.
6. 3D-Papierverformung
Dokumente können sich beim Scannen oder Fotografieren biegen, falten oder krümmen. Mit 3D-Meshes von echtem Papier rekonstruiert dieses Modell diese Formen und Lichteffekte, um Modelle für die kamera-basierte Dokumentenanalyse zu trainieren.
7. Nichtlineare Beleuchtung
Ungleichmäßige Beleuchtung beim Scannen kann eine Seite eines Dokuments dunkler erscheinen lassen. Dieses Modell passt die Helligkeit basierend auf simulierten Lichtwinkeln und Papierkrümmung an und reproduziert den Effekt schlechter Beleuchtung.
8. Salz-und-Pfeffer-Rauschen
Fügt zufällige schwarze und weiße Pixel hinzu, um Staub, Papierstruktur oder Sensorrauschen beim Scannen zu simulieren. Dieser „Salz-und-Pfeffer“-Effekt hilft, das körnige Aussehen gealterter oder minderwertiger digitaler Scans zu erzeugen.
Synthetische Dokumentengenerierung als Lösung für Herausforderungen der Layoutanalyse
Die Herausforderung der Layoutanalyse
Das Verständnis der Struktur von Dokumenten ist schwieriger als das Lesen des Textes. OCR-Tools können Wörter extrahieren, erklären aber nicht die Rolle jedes Blocks, wie Titel, Tabellen oder Abbildungen.
Um diese Herausforderung zu bewältigen, wurden Methoden entwickelt:
Frühe Methoden für die Layoutanalyse waren regelbasiert. Sie verließen sich auf geometrische Regeln und Texturanalyse, um Seiten in Blöcke zu unterteilen. Obwohl nützlich, erforderten diese Ansätze eine aufwändige manuelle Abstimmung und generalisierten nicht gut.
Machine-Learning-Ansätze wie Support Vector Machines (SVMs) und Gaussian Mixture Models (GMMs) verbesserten dies durch Lernen aus Daten.9 Allerdings waren sie immer noch von handgefertigten Merkmalen abhängig und hatten Schwierigkeiten mit der Vielfalt realer Dokumente.
Deep Learning hat das Feld transformiert. Convolutional Neural Networks (CNNs) machten es möglich, Layouterkennung wie Objekterkennung zu behandeln und Tabellen, Abbildungen oder Formeln auf die gleiche Weise zu identifizieren, wie Modelle Objekte in natürlichen Bildern erkennen.10 Einige Modelle kombinieren auch Text- und Bildmerkmale für genauere Ergebnisse.
Die Herausforderung des Deep Learning: Erfordert große, gekennzeichnete Datensätze zum Trainieren.
Synthetische Daten als Lösung: Der Prozess der synthetischen Dokumentengenerierung bietet eine skalierbare Möglichkeit, annotierte Trainingsdaten ohne die Kosten manueller Kennzeichnung zu erstellen.
Generative Modelle bringen jetzt fortschrittlichere Möglichkeiten. Variational Autoencoders (VAEs), aufmerksamkeitsbasierte Modelle und GANs können strukturelle Muster von Dokumenten lernen und realistische neue Layouts produzieren.11
Hauptunterschiede zwischen synthetischen Dokumentengeneratoren
Die drei im Benchmark verglichenen synthetischen Dokumentengeneratoren unterscheiden sich in Fokus, Ausgabequalität und Benutzerfreundlichkeit:
- Genalog: Am besten ausgewogen für realistische Layouts und numerische Genauigkeit. Sein Python-basierter Workflow mit HTML/CSS-Vorlagen und Degradationsmodellen macht es ideal für das Training von Machine-Learning-Modellen bei verschiedenen Dokumentenanalyseaufgaben.
- DocCreator: Stark bei der Generierung visuell komplexer und degradierter Dokumente unter Bewahrung der Layoutvielfalt. Numerisch etwas weniger genau als Genalog, aber effektiv für Aufgaben, die eine realistische Simulation gescannter Dokumente erfordern.
- Tonic Textual: Glänzt bei sauberen, visuell konsistenten Layouts und datenschutzfreundlicher Datensynthese. Weniger geeignet für numerische Genauigkeit oder vollständige Trainingsdatensätze, was es besser für layoutfokussierte Aufgaben oder PII-Ersatz macht.
Diese Unterschiede spiegeln ihre primären Ansätze wider: Genalog balanciert Realismus und Datengenauigkeit, DocCreator betont Layoutvielfalt und Dokumentendegradation, und Tonic Textual priorisiert Erscheinungsbild und Datenschutz. Dies hilft Benutzern, das richtige Tool basierend darauf auszuwählen, ob die Priorität auf Trainingseffektivität, Layoutrealismus oder Daten-De-Identifizierung liegt.
Andere häufig verwendete synthetische Dokumentengeneratoren
YData SDK: Bietet einen synthetischen Dokumentengenerator, der hochwertige synthetische Dokumente in PDF-, DOCX- oder HTML-Formaten produzieren kann, die oft verwendet werden, um Datenschutz-Compliance-Hürden zu umgehen.12
DoGe: Ein Open-Source-Tool, das speziell entwickelt wurde, um realistische Dokumentenscans mit sinnvollem Text, Überschriften und Tabellen für das Training von Document KI zu synthetisieren.13
DocXPand: Spezialisiert auf die Generierung von Ausweisdokumenten (Pässe, Personalausweise) basierend auf ISO-Standards, das Füllen von Vorlagen mit falschen Informationen und KI-generierten Gesichtern.14
Weitere Lesungen
- Synthetische Datengenerierung: Benchmark & Best Practices
- Top 25 Anwendungsfälle für synthetische Daten
- Synthetische Benutzer erklärt: Top 7 KI-Tools für die Nutzerforschung
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{Top 3 Synthetische Dokumentengeneratoren im Benchmark verglichen}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Abgerufen am 18. März 2026}
}



Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.