RAG-Frameworks: LangChain vs LangGraph vs LlamaIndex
Wir haben 5 RAG-Frameworks einem Benchmark unterzogen: LangChain, LangGraph, LlamaIndex, Haystack und DSPy, indem wir denselben agentischen RAG-Workflow mit standardisierten Komponenten aufgebaut haben: identische Modelle (GPT-4.1-mini), Embeddings (BGE-small), Retriever (Qdrant) und Tools (Tavily-Websuche). Dies isoliert den tatsächlichen Overhead und die Token-Effizienz jedes Frameworks.
Benchmark-Ergebnisse der RAG-Frameworks
Der Benchmark bestand aus 100 Abfragen, wobei jedes Framework den vollständigen Satz 100 Mal durchlief, um stabile Durchschnittswerte zu liefern.
- Durchschn. Tokens: Gesamtzahl der über alle LLM-Aufrufe hinweg verbrauchten Tokens (Router, Document Grader, Answer Grader und Generator), umfasst sowohl Prompts (mit abgerufenem Kontext) als auch Completions. Niedriger = geringere API-Kosten.
- Framework-Overhead: Reine Orchestrierungszeit (ms), die interne Verarbeitung des Frameworks (Routing-Logik, State-Management usw.), ohne LLM-API- und Tool-Aufrufe. Niedriger = schlankeres Framework.
Alle Implementierungen erreichten eine Genauigkeit von 100% im Testdatensatz. Es wurden dieselben Modelle, Temperaturen, Retrieval-Anbieter, Websuch-Tools und ein gemeinsames Kontext-Token-Limit verwendet.
Wichtigste Erkenntnisse
- Wir konzentrieren uns darauf, das Kontrollierbare zu kontrollieren: Gleiche Modellfamilie und Temperaturen, max_tokens auf Knotenebene, Retriever (Qdrant + BGE-small, k=5, Normalisierung aktiviert), Webanbieter (nur Tavily), Router-Richtlinie (heuristisch + Modell), vorzeitige Rückgabe des Rechners, gemeinsames Kontext-Token-Limit, identischer Bewertungsmaßstab, einheitliche Instrumentierung. Dies reduziert wesentliche Störfaktoren in unseren Messungen erheblich.
- Framework-Overhead ist messbar, aber gering: Wir beobachteten ~3–14 ms pro Abfrage durch Orchestrierungslogik. Diese Unterschiede sind real, aber nicht die Hauptursache für Latenzlücken von >1 s; die meiste Zeit wird für I/O mit externen Modellen/Tools aufgewendet.
- Die Leistung folgt den Tokens (unter diesen Bedingungen): DSPy zeigt den niedrigsten Framework-Overhead (~3,53 ms). Haystack (~5,9 ms) und LlamaIndex (~6 ms) folgen, während LangChain (~10 ms) und LangGraph (~14 ms) höher liegen. Der Token-Verbrauch ist am niedrigsten bei Haystack (~1,57k), dann LlamaIndex (~1,60k); DSPy und LangGraph liegen bei ~2,03k, und LangChain bei ~2,40k.
- Routing/Tool-Pfad ist entscheidend: Leichte Verschiebungen im initialen Routing (Retriever vs. Web vs. Rechner) und im Fallback-Verhalten beeinflussen sowohl Tokens als auch Zeit, selbst wenn Prompts und Budgets aufeinander abgestimmt sind.
Warum bleiben Unterschiede bestehen? Die „Framework-DNA“
Trotz Standardisierung bleiben geringe Abweichungen bei Token-Anzahl und Latenz bestehen. Diese sind auf die inhärenten, grundlegenden Verhaltensweisen jedes Frameworks zurückzuführen – seine „DNA.“
- Prompt- & Nachrichten-Serialisierung: Jedes Framework verpackt denselben logischen Inhalt mit leicht unterschiedlicher Formatierung, bevor es ihn an das LLM sendet, was zu kleinen, aber konsistenten Token-Deltas führt.
- Kontext-Zusammenstellung: Die genaue Reihenfolge und Einbeziehung von Metadaten innerhalb des verketteten Kontexts kann je nach Framework leicht variieren und die endgültige Token-Anzahl beeinflussen.
- Routing-Entscheidungen bei Gleichstand: In Grenzfällen können subtile Unterschiede darin, wie ein Framework die JSON-Ausgabe des Routers analysiert, zu einer anderen anfänglichen Tool-Wahl führen.
In diesem Setup scheint der Token-Fußabdruck der primäre Treiber zu sein, mehr als die Ausführungszeit des Frameworks.
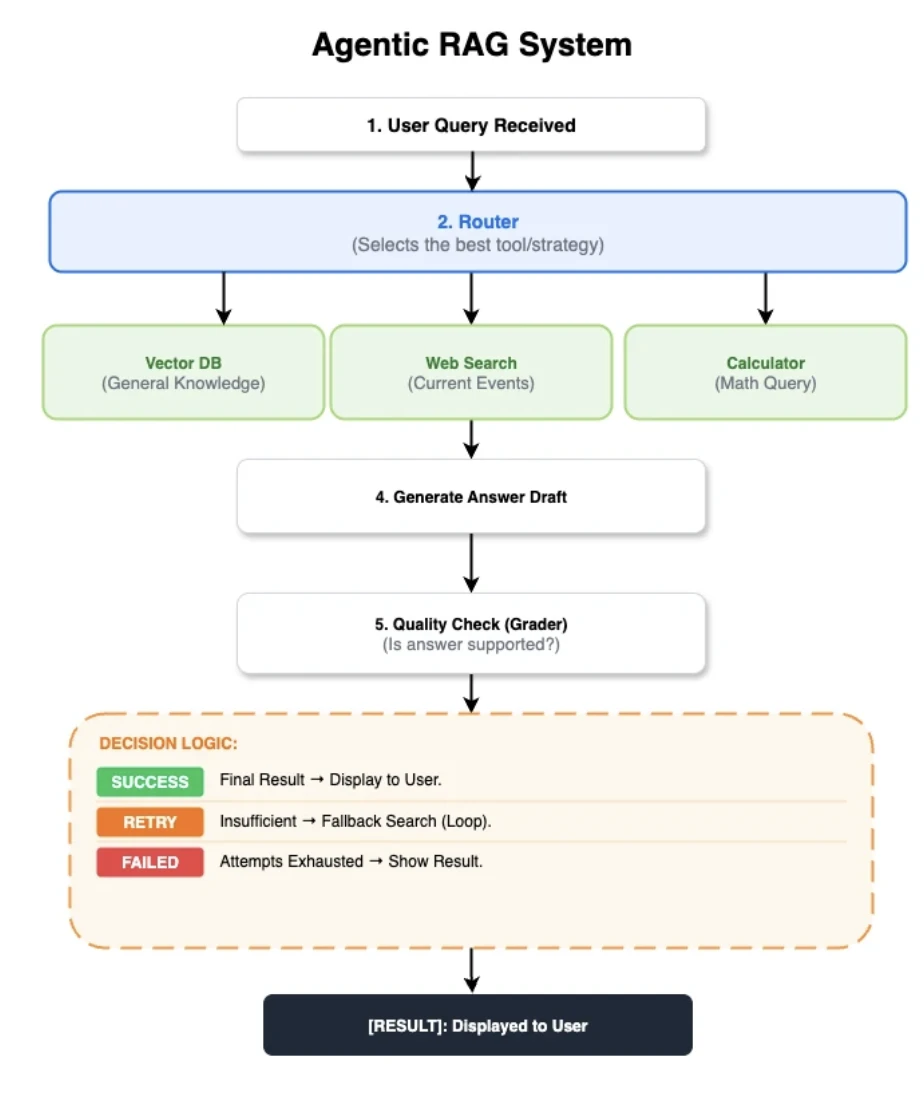
Die gemeinsame agentische RAG-Architektur
Um einen fairen Vergleich zu erreichen, wurden alle fünf Implementierungen auf demselben Kontrollfluss aufgebaut:
- Router: Ein hybrider Modell-und-Heuristik-Knoten, der zwischen Retriever, web_search oder calculator wählt.
- Dokumente abrufen: Ruft die Top-5-Dokumente von Qdrant unter Verwendung normalisierter BGE-small-Embeddings ab.
- Dokumente bewerten: Ein LLM-Prüfer bewertet die Dokumentenrelevanz. Bei Irrelevanz wird ein Websuche-Fallback ausgelöst.
- Antwort generieren: Verwendet ein LLM mit temperature=0,0 und einem gemeinsamen Kontext-Token-Limit, um eine Antwort zu generieren.
- Antwort bewerten: Ein zweiter LLM-Prüfer bewertet den Entwurf auf Fundiertheit, Widersprüche (Halluzinationen) und Vollständigkeit.
- Fallback & vorzeitige Rückgabe: Eine Websuche wird ausgelöst, wenn die Antwortbewertung unzureichend ist. Rechnerergebnisse werden jedoch direkt zurückgegeben, wobei die Generierungs- und Bewertungsschritte übersprungen werden.
Workflow-Beispiele
Szenario A — Direkter Treffer aus der Datenbank:
Szenario B — Aktuelles Ereignis löst Web-Tool aus:
Szenario C — Rechner liefert eine vorzeitige Rückgabe:
Szenario D — Vektordatenbank unzureichend, greift auf Websuche zurück:
Methodik der RAG-Frameworks
Alle fünf Implementierungen erreichten eine Genauigkeit von 100% in unserem Testdatensatz mit 100 Abfragen und stimmten mit den Ground-Truth-Antworten überein. Dies war die grundlegende Anforderung, die sicherstellte, dass jedes Framework denselben agentischen RAG-Workflow erfolgreich ausführen konnte, bevor Leistungsunterschiede gemessen wurden.
1. Kernkomponenten & Konfiguration
Die grundlegenden Tools wurden standardisiert, um Leistungsvariablen an der Quelle zu eliminieren.
- LLMs:
- Modell: Alle Knoten (Router, Generator, Grader) verwendeten das Modell openai/gpt-4.1-mini über die OpenRouter-API.
- Determinismus: Die Temperatur wurde für alle LLM-Aufrufe auf 0,0 gesetzt, um maximale Konsistenz bei Routing, Generierung und Bewertung zu gewährleisten.
- Token-Limits: Strenge max_tokens-Limits wurden durchgesetzt: 256 für den Router und die Grader sowie 512 für den Generator. Dies verhindert Latenzunterschiede, die durch übermäßig lange Antworten eines Frameworks verursacht werden.
- Embedding-Modell & Retrieval:
- Modell: Alle Frameworks verwendeten BAAI/bge-small-en-v1.5 von HuggingFace.
- Normalisierung: Ein entscheidender Schritt für die Leistung: normalize_embeddings wurde in allen fünf Frameworks auf True gesetzt. (LangChain/LangGraph über encode_kwargs; LlamaIndex über normalize=True; Haystack über normalize_embeddings; DSPy-Retriever normalisiert.)
- Retrieval: Der Qdrant-Vektorspeicher wurde in allen Implementierungen mit k=5 (Top-5-Dokumente) abgefragt.
- Tooling:
- Websuche: Der Benchmark wurde auf nur Tavily beschränkt (max_results=3).
- Rechner: Alle fünf Implementierungen verwendeten die sympy-Bibliothek für die Analyse und Auswertung mathematischer Ausdrücke, um identische Fähigkeiten sicherzustellen.
2. RAG-Kontrollfluss & Richtlinie
Der „Entscheidungsfindungs“-Prozess des Agenten wurde explizit in allen Frameworks gespiegelt.
- Routing-Logik: Eine hybride Routing-Strategie wurde in allen fünf Skripten implementiert, um Modellintelligenz mit deterministischen Regeln auszubalancieren:
- Eine regex-basierte heuristic_route prüft zunächst auf offensichtliche Rechner- oder Websuche-Muster (z. B. mathematische Symbole, Jahreszahlen wie „2024“).
- Ein LLM-router_node trifft dann seine eigene Entscheidung.
- Die endgültige Entscheidung priorisiert die Heuristik für Rechner, ansonsten wird die Wahl des LLM übernommen.
- Kontext-Budgetierung: Dies ist eine der wichtigsten Standardisierungen. Bevor der generate_answer-Knoten aufgerufen wird, werden alle abgerufenen Dokumentkontexte und Websuchergebnisse verkettet und dann auf ein gemeinsames Limit von 2000 Tokens gekürzt, unter Verwendung einer gemeinsamen truncate_to_token_budget-Hilfsfunktion. Dies stellt sicher, dass das Generator-LLM in jedem Framework eine Eingabe exakt derselben Größe erhält, wodurch verhindert wird, dass ein einzelnes Framework durch die Ausführlichkeit seines abgerufenen Kontexts bevor- oder benachteiligt wird.
- Antwortbewertungs-Richtlinie:
- Nachsichtiger Maßstab: Der grade_answer-Knoten verwendet einen identischen, nachsichtigen Prompt in allen Frameworks, der den LLM-Prüfer anweist, semantisch ähnliche und hinreichend vollständige Antworten zu akzeptieren.
- Fehlerbehandlung: Die Logik zur Behandlung eines fehlgeschlagenen JSON-Parsings durch den Grader wurde standardisiert. Wenn die Ausgabe des Graders kein gültiges JSON ist, verwendet das System standardmäßig eine permissive Bewertung (grounded=True, complete=True), was einem realen Szenario entspricht, in dem ein fehleranfälliger Parser eine ansonsten gute Antwort nicht durchfallen lassen sollte. DSPy gibt strukturierte Felder zurück (kein JSON-Parsing), dies wird als Robustheitsunterschied protokolliert, nicht als Leistungsvorteil.
- Vorzeitige Rückgabe des Rechners: Wie im Code zu sehen, setzt ein erfolgreicher Aufruf des calculator_node direkt die final_answer und beendet den Workflow vorzeitig. Dies ist eine bedeutende Optimierung, die konsistent angewendet wird und verhindert, dass der Rechner-Pfad unnötig die generate- und grade_answer-LLMs aufruft.
- DSPy-Abgleich. Um Fairness mit Nicht-CoT-Baselines zu wahren, verwendet DSPy.Predict (kein CoT) für Router und AnswerGenerator. Signaturen spiegeln die Knotenverträge anderer Frameworks wider; wo verfügbar, verwenden Token-Anzahlen die vom Modell gemeldete Nutzung, ansonsten tiktoken-Fallback.
3. Instrumentierung und Metriken
Der Messprozess war identisch und verwendete gemeinsame Hilfsfunktionen und Prinzipien.
- Latenz: Hochpräzises time.perf_counter() wurde für alle Zeitmessungen verwendet. Der Framework-Overhead wird konsistent berechnet als Gesamtlatenz – Latenz externer Aufrufe.
- Tokenisierung: Alle Token-Anzahlen für Prompts und Completions wurden mit tiktoken berechnet, der cl100k_base-Kodierung, um eine einzige Quelle der Wahrheit für Token-Metriken sicherzustellen. Die in den Ergebnissen angegebene Metrik „Durchschn. Tokens“ stellt die kumulative Summe aller Eingabe- (Prompt) und Ausgabe-Tokens (Completion) für jeden LLM-Aufruf (z. B. Router, Grader, Generator) innerhalb eines einzelnen Abfrage-Workflows dar.
- State-Management: Während die Implementierungssyntax variiert (LangGraphs TypedDict, LlamaIndex' Klasse, LangChains Dictionary), ist die State-Struktur funktional identisch. Jedes Framework übergibt denselben Satz von Schlüsseln (question, documents, web_results usw.) zwischen den Knoten, wodurch sichergestellt wird, dass die Kontrollflusslogik mit denselben Informationen arbeitet.
Durch die Durchsetzung dieser strengen Standardisierungen auf Code-Ebene zielt dieser Benchmark darauf ab, über oberflächliche Vergleiche hinauszugehen und eine replizierbare Analyse der Framework-Leistung unter einer festgelegten RAG-Richtlinie zu bieten.
Interpretation der Ergebnisse:
- Sie können folgern: In diesem spezifischen, stark kontrollierten Setup ist der Orchestrierungs-Overhead tendenziell gering; Unterschiede werden hauptsächlich durch Token-Anzahlen und Tool-Pfade verursacht.
- In diesem spezifischen, stark kontrollierten Setup ist der Framework-Overhead vernachlässigbar.
- Leistungsunterschiede wurden durch Token-Anzahl und Tool-Pfad-Variationen verursacht.
- Sie können nicht verallgemeinern: Die Ergebnisse sind spezifisch für diese Architektur, Modelle, Prompts, Retriever und Webanbieter; Änderungen daran können die Rangfolge verändern.
Entwicklererfahrung: Ein qualitativer Vergleich
Leistung ist nicht der einzige Faktor; wie sich ein Framework beim Entwickeln anfühlt, ist ebenso wichtig.
- LangGraph: Der deklarative Graph
Verwendet ein Graph-First-Paradigma. Sie definieren Knoten und verdrahten sie mit Kanten (einschließlich add_conditional_edges), sodass der Kontrollfluss Teil der Architektur ist. Der State wird über ein TypedDict mit Reducer-artigen Aktualisierungen typisiert (Annotated[…, add]).- Wählen Sie LangGraph für: komplexe Workflows mit mehreren Verzweigungen, Wiederholungen und Zyklen; seine Struktur skaliert in Robustheit und Wartbarkeit, wenn Agenten wachsen.
- LlamaIndex: Imperative Orchestrierung
Ein prozedurales Skript, bei dem der Kontrollfluss aus Standard-Python-if/else besteht; der „Graph“ lebt in Ihrem Code. Der State ist eine dedizierte PipelineState-Klasse, und das Framework bietet saubere Retrieval-Primitive (VectorStoreIndex → .as_retriever(k=5)).- Wählen Sie LlamaIndex für: lesbare, ein-dateiige Workflows, bei denen Sie klare prozedurale Logik und einfaches Debugging schätzen.
- LangChain: Imperativ mit deklarativen Komponenten
Die Orchestrierung bleibt ein Python-Skript, aber einzelne Aufgaben sind kleine, zusammensetzbare Chains mit dem |-Operator (z. B. prompt | llm | parser). Der State ist ein flexibles, untypisiertes Python-Dict.- Wählen Sie LangChain für: schnelles Prototyping oder Teams, die bereits im LangChain-Ökosystem arbeiten und es bevorzugen, kleine deklarative Einheiten innerhalb eines größeren imperativen Treibers zu komponieren.
- Haystack: Komponentenbasiert, manuelle Orchestrierung Typisierte, wiederverwendbare Komponenten (@component) mit expliziten I/O, während der Kontrollfluss reines Python (if/else) bleibt. Einfacher Austausch von LLM/Retriever/Web-Backends, plus erstklassige Instrumentierung pro Schritt (externe vs. Framework-Zeit).
- Wählen Sie Haystack für: produktionsreife, testbare Pipelines mit klaren Verträgen und feingranularer Kontrolle.
- DSPy: Signature-First-Programme (weniger Codezeilen)
Definieren Sie eine Aufgabe über eine Signatur (Eingaben/Ausgaben + Absicht) und implementieren Sie dann mit Modulen, die Prompting und LLM-Aufrufe kapseln. Zentralisiert Prompt-/Nutzungsverwaltung und entfernt Glue-Code; das Austauschen von Interna (z. B. Predict ↔ CoT) ändert den Vertrag nicht.- Wählen Sie DSPy für: minimalen Boilerplate, lesbare ein-dateiige Abläufe, vertragsgetriebene Entwicklung (mit optionalen Optimierern).
Optimale Leistung gegen Vergleichbarkeit eintauschen
- LangGraph könnte mit seinen nativen Graph-Optimierungen glänzen, wenn parallele Ausführung, State-Caching und sein Conditional-Edge-System für komplexe Verzweigungslogik genutzt werden dürfen.
- DSPy könnte dramatisch andere Ergebnisse zeigen, wenn seine Signatur-Optimierer (wie MIPROv2) und Chain-of-Thought-Prompting verwendet werden, was die Antwortqualität erheblich verbessern kann.
- Haystack könnte sein produktionsreifes Caching, Batching-Funktionen und Optimierungen auf Komponentenebene nutzen, die wir aus Fairnessgründen deaktiviert haben.
- LlamaIndex könnte von seinen fortgeschrittenen Indexierungsstrategien, Query-Engines und multimodalen Fähigkeiten profitieren, die in diesem Benchmark nicht getestet wurden.
- LangChain könnte mit seinem umfangreichen Tool-Ökosystem und LCEL (LangChain Expression Language)-Optimierungen glänzen, wenn es nicht auf unseren standardisierten Tool-Satz beschränkt wäre.
Das „beste“ Framework hängt davon ab, ob Sie optimieren für: Entwicklungsgeschwindigkeit, Wartbarkeit, Leistung oder spezifische architektonische Muster.
Fazit
In einer eng abgestimmten agentischen RAG-Pipeline ist der Orchestrierungs-Overhead normalerweise ein kleiner Anteil. Was den Ausschlag gibt, ist, wie viele Tokens Sie verarbeiten und welche Tools Sie aufrufen – beides geprägt von Prompts, Retrieval und Routing. Das „richtige“ Framework hängt letztlich vom bevorzugten Orchestrierungsstil Ihres Teams ab: deklarative Graphen (LangGraph), imperative Skripte (LlamaIndex), zusammensetzbare Chains (LangChain), modulare Komponenten (Haystack) oder Signature-First-Programme (DSPy), die Boilerplate minimieren.
Weiterführende Literatur
Entdecken Sie weitere RAG-Benchmarks, wie zum Beispiel:
- Embedding-Modelle: OpenAI vs Gemini vs Cohere
- Top-Vektordatenbank für RAG: Qdrant vs Weaviate vs Pinecone
- Agentischer RAG-Benchmark: Multi-Datenbank-Routing und Abfragegenerierung
- Hybrides RAG: Steigerung der RAG-Genauigkeit
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG-Frameworks: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Abgerufen am 3. Juni 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.