Beste 20+ Agentic RAG Frameworks
Agentic RAG verbessert traditionelles RAG, indem es die LLM-Leistung steigert und eine stärkere Spezialisierung ermöglicht. Wir haben einen Benchmark durchgeführt, um seine Leistung bei der Weiterleitung zwischen mehreren Datenbanken und der Generierung von Abfragen zu bewerten.
Entdecken Sie agentic RAG Frameworks und Bibliotheken, die wichtigsten Unterschiede zu Standard-RAG, Vorteile und Herausforderungen, um ihr volles Potenzial auszuschöpfen.
Agentic RAG Benchmark: Multi-Datenbank-Routing und Abfragegenerierung
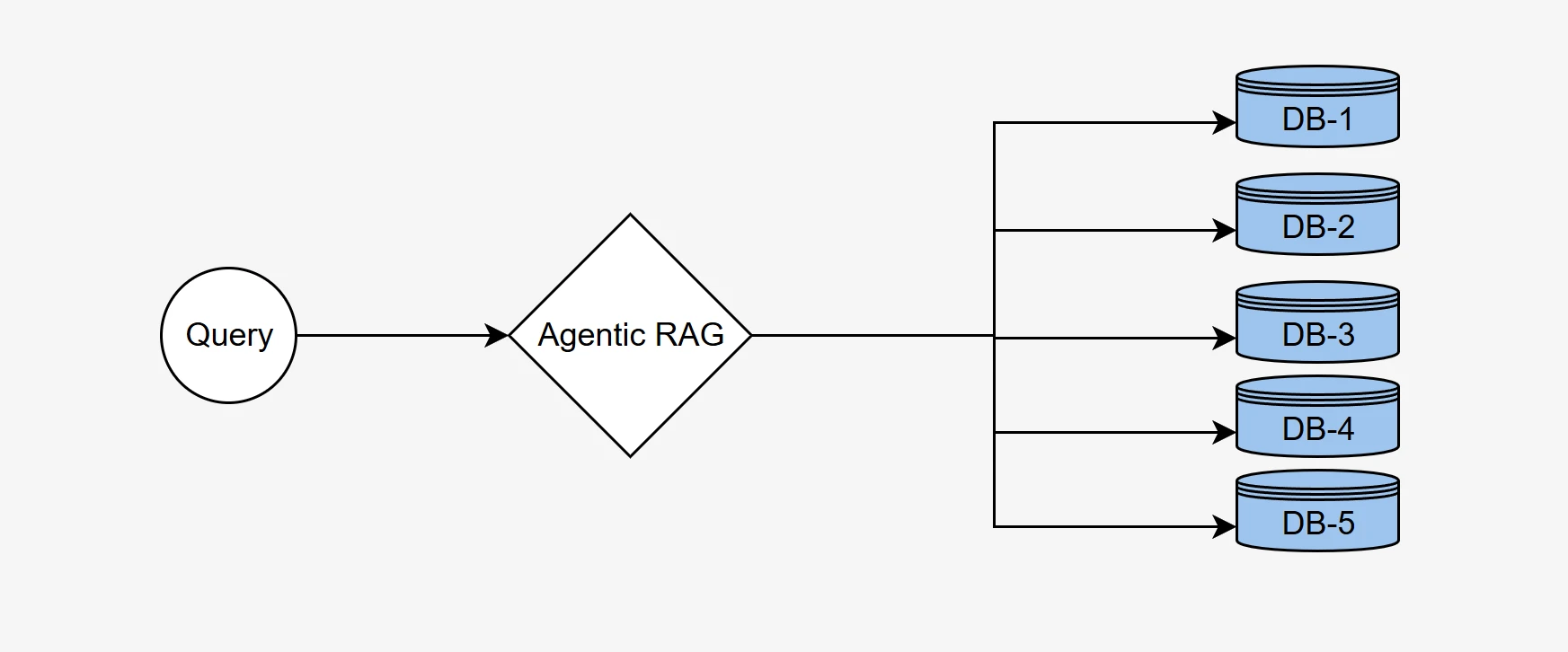
Wir verwendeten unsere agentic RAG Benchmark-Methodik, um die Fähigkeit des Systems zu demonstrieren, die richtige Datenbank aus einer Menge von fünf unterschiedlichen Datenbanken mit jeweils einzigartigen Kontextinformationen auszuwählen und semantisch korrekte SQL-Abfragen zu generieren, um die korrekten Daten abzurufen.
In dem Agentic RAG Benchmark verwendeten wir:
- Agent-Framework: Langchain
- Vektordatenbank: ChromaDB
In vielen realen Unternehmensszenarien sind Daten oft über mehrere Datenbanken verteilt, die jeweils spezialisierte Informationen zu bestimmten Domänen oder Aufgaben enthalten. Zum Beispiel könnte eine Datenbank Finanzdaten speichern, während eine andere Kundendaten oder Bestandsdetails enthält.
Ein effektives Agentic RAG-System muss die Benutzerabfrage intelligent an die relevanteste Datenbank weiterleiten, um genaue Informationen abzurufen. Dieser Prozess umfasst die Analyse der Abfrage, das Verständnis des Kontextes und die Auswahl der geeigneten Datenquelle aus einer Reihe verfügbarer Datenbanken.
Gedankenprozess des Agenten
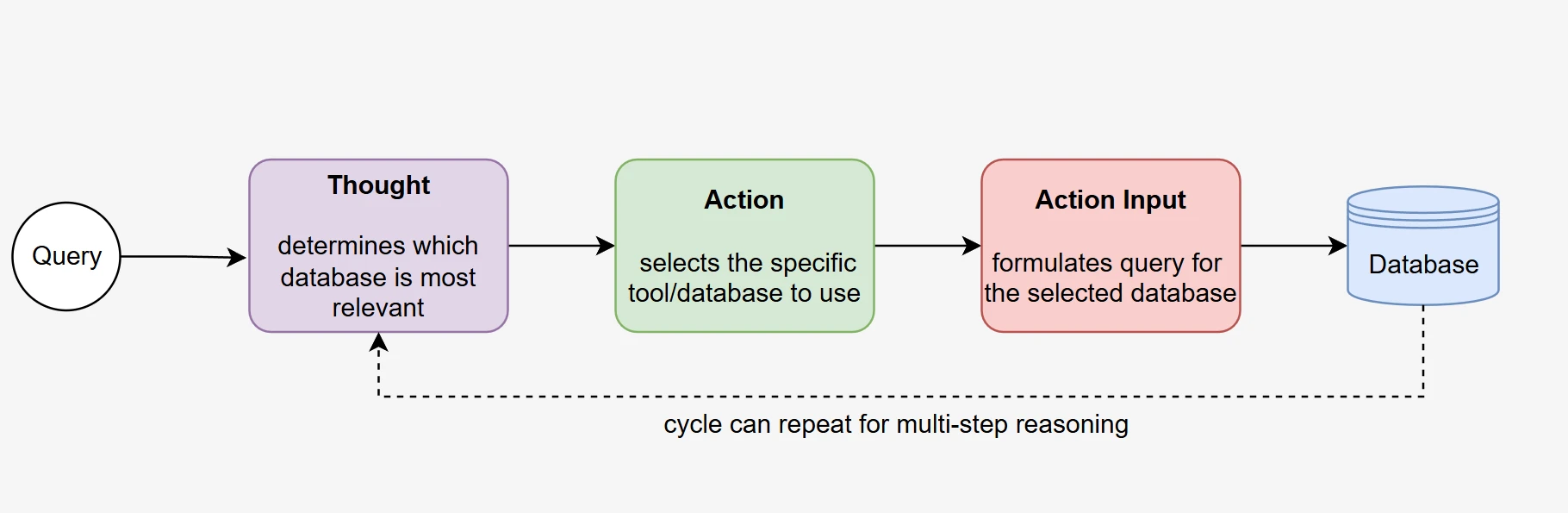
Im Kern eines agentic RAG-Systems liegt die Fähigkeit des LLM, autonom zu denken und zu handeln, um ein Ziel zu erreichen. Unser funktionsaufrufbasierter Ansatz ermöglicht es Modellen, echtes agentisches Verhalten durch selbstgesteuerte Datenbankauswahl und iterative Informationssammlung zu demonstrieren.
Autonome Entscheidungsfindung: Der Agent analysiert die eingehende Benutzerabfrage und bestimmt autonom, welche Datenbankfunktion aufgerufen werden soll, basierend auf dem Abfragekontext und den verfügbaren Funktionsbeschreibungen. Dieser Entscheidungsprozess erfolgt ohne vordefinierte Routing-Regeln und demonstriert echte Denkfähigkeiten.
Mehrstufige Ausführung: Der Agent führt typischerweise mehrere Funktionsaufrufe nacheinander aus, zuerst zur Identifizierung und zum Zugriff auf die relevante Datenbank, dann zur Erfassung detaillierter Schemainformationen und schließlich zur Verfeinerung seines Verständnisses, bevor die SQL-Abfrage generiert wird. Dieser iterative Prozess spiegelt menschliche Problemlösungsansätze wider.
Selbstkorrekturfähigkeit: Wenn erste Funktionsaufrufe nicht genügend Informationen liefern, kann der Agent autonom entscheiden, zusätzliche Aufrufe mit verfeinerten Parametern durchzuführen, und zeigt damit adaptives Verhalten, das über einfache Abrufsysteme hinausgeht.
Zielgerichtetes Verhalten: Während des gesamten Prozesses behält der Agent den Fokus auf die Generierung einer präzisen SQL-Abfrage und nutzt jedes Ergebnis eines Funktionsaufrufs, um nachfolgende Entscheidungen und Aktionen zu informieren.
Dieses autonome, mehrstufige Interaktionsmuster unterscheidet agentic RAG grundlegend von traditionellen RAG-Systemen, die vorbestimmten Pfaden und einmaligen Abrufmechanismen folgen.
Agentic RAG Benchmark-Methodik
Dieser Benchmark bewertet die Fähigkeit von Large Language Models (LLMs), als autonome Agenten innerhalb einer Retrieval-Augmented Generation (RAG)-Pipeline zu fungieren. Konkret misst er zwei Kernkompetenzen:
- Datenbank-Routing: Die Fähigkeit des Agenten, die relevanteste Datenbank aus mehreren Kandidaten anhand einer natürlichsprachlichen Frage korrekt zu identifizieren und auszuwählen.
- SQL-Generierung: Die Fähigkeit des Agenten, eine präzise SQL-Abfrage unter Verwendung des Schemas der ausgewählten Datenbank zu generieren.
Datensatz
Der Benchmark verwendet den BIRD-SQL-Datensatz1 , einen weit verbreiteten akademischen Benchmark für Text-zu-SQL-Aufgaben. BIRD-SQL bietet natürlichsprachliche Fragen, gepaart mit Ground-Truth-Datenbankidentifikatoren und Goldstandard-SQL-Abfragen, und eignet sich daher ideal zur Bewertung sowohl der Routing-Genauigkeit als auch der Qualität der Abfragegenerierung.
Aus dem vollständigen BIRD-SQL-Datensatz haben wir eine Teilmenge von 500 Fragen zusammengestellt, die auf fünf verschiedene Datenbanken verteilt sind und unterschiedliche Domänen abdecken:
Jede Frage hat genau eine korrekte Zieldatenbank. Die Antwort auf jede Frage befindet sich in einer bestimmten Datenbank, was den Agenten zu einer eindeutigen Routing-Entscheidung zwingt.
Herausforderung durch semantische Mehrdeutigkeit
Um die Denkfähigkeiten des Agenten über oberflächliches Keyword-Matching hinaus zu bewerten, haben wir die datenbankübergreifende semantische Ähnlichkeit als bewussten Störfaktor bei der Fragenauswahl eingeführt.
Ablauf der Fragenauswahl:
- Alle Kandidatenfragen aus den fünf Datenbanken wurden mithilfe von Sentence Transformers (
all-MiniLM-L6-v2) in Embeddings umgewandelt. - Datenbankübergreifende Fragepaare wurden berechnet und nach Kosinus-Ähnlichkeit sortiert.
- Fragen mit datenbankübergreifenden Kosinus-Ähnlichkeitswerten über 0.70 wurden bewusst priorisiert, um Szenarien zu schaffen, in denen semantisch ähnliche Fragen zu völlig unterschiedlichen Datenbanken gehören.
Beispiel für semantische Verwirrung:
Frage A (Finanz-DB): „For the client whose loan was approved first on 1993/7/5, what is the increase rate of his/her account balance from 1993/3/22 to 1998/12/27?”
Frage B (Debitkarten-DB): „For the customer who paid 634.8 in 2012/8/25, what was the consumption decrease rate from Year 2012 to 2013?”
Beide Fragen folgen nahezu identischen semantischen Mustern: Sie identifizieren einen bestimmten Kunden über ein Transaktionsereignis und berechnen dann eine Änderungsrate über einen Zeitraum. Dennoch unterscheiden sich die korrekten Datenbanken völlig; eine benötigt Kredit- und Kontodaten, während die andere Transaktions- und Verbrauchsdaten benötigt. Dies zwingt den Agenten, eine tiefere kontextuelle Argumentation über die Datendomäne durchzuführen, anstatt sich auf oberflächliche Finanz-Schlüsselwörter zu verlassen, die auf beide Datenbanken zutreffen würden.
Datenbankumgebung
Das Schema und eine kurze natürlichsprachliche Beschreibung jeder Datenbank wurden in ChromaDB gespeichert, einer Vektordatenbank für effiziente semantische Abfragen. Die Sammlung jeder Datenbank enthält:
- Eine übergeordnete Beschreibung der Domäne und des Zwecks der Datenbank
- Schema-Dokumente pro Tabelle, einschließlich Spaltennamen, Datentypen und Wertebeschreibungen
Dieses Setup ermöglicht es dem Agenten, nach Auswahl einer Zieldatenbank relevante Schema-Informationen durch semantische Suche abzurufen.
Agentenarchitektur
Eine funktionsaufrufbasierte agentische Architektur wurde für alle Modelle verwendet, um einen fairen und standardisierten Vergleich zu gewährleisten. Jede der fünf Datenbanken wurde als separate aufrufbare Funktion (Tool) mit standardisierten Parametern dargestellt. Dieses Design nutzt die nativen Funktionsaufruffähigkeiten jedes Modells und ermöglicht es den Modellen, autonom:
- die eingehende Frage zu analysieren
- die passende Datenbankfunktion auszuwählen und aufzurufen
- Schema-Informationen als Funktionsantwort zu erhalten
- optional zusätzliche Funktionen zur Verfeinerung aufzurufen
- die endgültige SQL-Abfrage zu generieren
Dieser Ansatz gewährleistet eine konsistente Bewertungsmethodik über verschiedene Modellfamilien hinweg, einschließlich traditioneller Modelle und reasoning‑optimierter Modelle.
Agentischer Prozessablauf
Das System implementiert eine echte mehrstufige agentische Schleife und keine starre Pipeline:
- Fragenanalyse: Der Agent erhält die natürlichsprachliche Frage zusammen mit Beschreibungen aller fünf verfügbaren Datenbankfunktionen.
- Datenbankauswahl (Tool-Aufruf): Der Agent wählt autonom die Datenbankfunktion aus, die er als am relevantesten erachtet, und ruft sie auf. Dies ist ein echter Funktionsaufruf; der Agent erhält das Schema als strukturierte Tool-Antwort im selben Konversationskontext.
- Schema-Argumentation: Der Agent beobachtet das zurückgegebene Schema und überlegt, welche Tabellen und Spalten für die Frage relevant sind.
- Optionale Wiederherstellung: Wenn der Agent feststellt, dass die ausgewählte Datenbank die erforderlichen Informationen nicht enthält, kann er eine andere Datenbankfunktion aufrufen, wodurch eine Selbstkorrektur ohne externes Eingreifen möglich ist.
- SQL-Generierung: Basierend auf dem akkumulierten Kontext (Frage + Schema-Beobachtung) erstellt der Agent die endgültige SQL-Abfrage.
Dieser mehrstufige Konversationsfluss unterscheidet den Benchmark von traditionellen Single-Shot-RAG-Ansätzen. Der Agent behält den vollständigen Kontext über mehrere Runden hinweg bei, kann die Ergebnisse seiner Aktionen beobachten und seinen Ansatz iterativ verfeinern – Merkmale echten agentischen Verhaltens.
Wesentliche architektonische Eigenschaften:
- Die Konversation ist kontinuierlich; der Agent sieht seine eigenen vorherigen Überlegungen und Tool-Antworten.
- Es werden keine künstlichen Rundenlimits auferlegt; der Agent entscheidet, wann er genügend Informationen hat.
- Sowohl die Datenbankauswahl als auch die SQL-Generierung erfolgen innerhalb derselben agentischen Sitzung.
- Die Anzahl der Tool-Aufrufe pro Frage wird als zusätzliche Metrik zur Analyse der Agenteneffizienz erfasst.
Bewertungsprozess
Für jede Frage im Benchmark:
Schritt 1: Bewertung des Datenbank-Routings
Der erste Datenbank-Funktionsaufruf des Agenten wird als seine Routing-Entscheidung aufgezeichnet. Diese wird mit der im BIRD-SQL-Datensatz angegebenen Ground-Truth-Datenbank verglichen.
Metrik: Genauigkeit des Datenbank-Routings (% korrekte Auswahlen an allen Fragen)
Schritt 2: SQL-Qualität
Die vom Agenten SQL-Abfrage wird mit einem LLM-als-Judge-Ansatz bewertet. Ein separates Richtermodell (Claude 4 Sonnet) erhält sowohl die vom Agenten generierte SQL-Abfrage als auch die BIRD-SQL Ground-Truth-SQL und vergibt eine semantische Ähnlichkeitsbewertung auf einer Skala von 0–5:
Wichtige Designentscheidung: Die SQL-Qualität wird bewertet, wenn der Agent die richtige Datenbank auswählt. Wenn der Agent zur falschen Datenbank geroutet hat, erhält er automatisch 0 Punkte, da eine SQL-Abfrage gegen das falsche Schema von Natur aus bedeutungslos ist. Dadurch wird sichergestellt, dass die SQL-Qualitätsmetrik ausschließlich die Fähigkeit zur Abfragegenerierung widerspiegelt, ohne durch Routing-Fehler verfälscht zu werden.
Metriken:
- Durchschnittlicher SQL-Qualitätswert (von 5.0), berechnet über korrekt geroutete Fragen
- Perfekte Übereinstimmungsrate: Prozentsatz der korrekt gerouteten Fragen mit 5/5 Bewertung
Kontrollierte Variablen
Um einen fairen Vergleich zwischen den Modellen zu gewährleisten:
- Alle Modelle erhalten identische System-Prompts und Tool-Definitionen.
- Die Temperatur wird für deterministische Ausgaben auf 0 gesetzt.
- Es werden keine modellspezifischen Prompt-Engineering-Maßnahmen oder Few-Shot-Beispiele bereitgestellt (Zero-Shot-Evaluierung).
- Das Evidenz-Feld des BIRD-SQL-Datensatzes (domänenspezifische Hinweise) wird allen Modellen vorenthalten, um ununterstütztes Denken zu messen.
- Alle Modelle greifen auf dieselbe ChromaDB-Instanz mit identischen Schema-Embeddings zu.
Agentic RAG Frameworks & Bibliotheken
Agentic RAG-Frameworks ermöglichen KI-Systemen, Informationen zu finden, zu denken, Entscheidungen zu treffen und Maßnahmen zu ergreifen. Die besten Werkzeuge und Bibliotheken, die Agentic RAG antreiben:
Diese Liste umfasst Werkzeuge, die folgenden Kriterien erfüllen:
- 50+ Sterne auf GitHub.
- Häufige Verwendung in Agentic RAG-Projekten.
Beachte, dass in der Tabelle:
- Tool-Nutzung bezieht sich auf die native Fähigkeit eines Systems, Tools innerhalb seiner Umgebung zu routen und aufzurufen.
- Tool-Typ bezieht sich auf den Hauptverwendungsbereich der Werkzeuge, wie z. B.:
- Agentic RAG-Frameworks sind speziell für den Aufbau, Einsatz oder die Konfiguration von Agentic RAG-Systemen konzipiert.
- Agent-Bibliotheken ermöglichen die Erstellung intelligenter Agenten, die denken, Entscheidungen treffen und mehrstufige Aufgaben ausführen können.
- LLMOps-Frameworks verwalten den Lebenszyklus von LLMs und optimieren den Einsatz und die Nutzung von LLMs innerhalb agentenbasierter Systeme.
- LLMs, die über integrierte Fähigkeiten zum Tool-Aufruf und Routing verfügen, ermöglichen dynamische Entscheidungsfindung. Andere LLMs erfordern möglicherweise externe APIs oder Integrationen, um Agentenfunktionalität zu ermöglichen.
- Verifizierung der Tool-Nutzung und Agententypen erfolgt anhand öffentlicher Quellen.
Was ist agentic RAG?
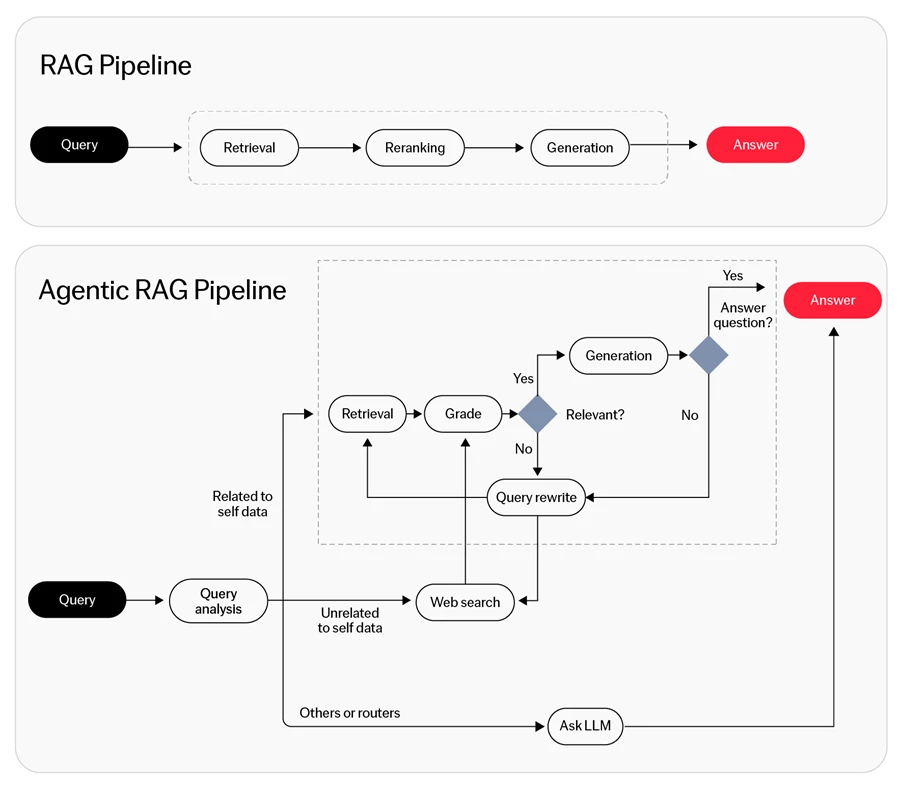
Agentic Retrieval-Augmented Generation (RAG) ist ein KI-Framework, das Abruftechniken mit generativen Modellen kombiniert, um dynamische Entscheidungsfindung und Wissenssynthese zu ermöglichen. Dieser Ansatz integriert die Genauigkeit von traditionellem RAG mit den generativen Fähigkeiten fortschrittlicher KI, um die Effizienz und Effektivität KI-gesteuerter Aufgaben zu steigern.
Einschränkungen traditioneller RAG-Systeme
Agentic RAG zielt darauf ab, die Einschränkungen des Standard-RAG-Systems zu überwinden, wie z. B.:
- Schwierigkeiten bei der Informationspriorisierung: RAG-Systeme haben oft Schwierigkeiten, Daten in großen Datensätzen effizient zu verwalten und zu priorisieren, was die Gesamtleistung beeinträchtigen kann.
- Begrenzte Integration von Expertenwissen: Diese Systeme unterschätzen möglicherweise spezialisierte, hochwertige Inhalte und bevorzugen stattdessen allgemeine Informationen.
- Schwaches kontextuelles Verständnis: Obwohl sie Daten abrufen können, verstehen sie häufig nicht vollständig deren Relevanz oder wie sie mit der spezifischen Abfrage übereinstimmen.
Wie man ein agentic RAG aufbaut
1. Tool-Nutzung
- Router einsetzen: Der erste Schritt besteht darin, Router einzusetzen, die entscheiden, ob Dokumente abgerufen, Berechnungen durchgeführt oder die Abfrage umgeschrieben werden soll. Dieser Ansatz erweitert die Entscheidungsfähigkeiten, um Anfragen an mehrere Werkzeuge weiterzuleiten, und ermöglicht es Large Language Models (LLMs), geeignete Pipelines auszuwählen.
- Tool-Aufruf-Integration: Dies bezieht sich auf die Erstellung einer Schnittstelle, über die Agenten mit ausgewählten Werkzeugen verbunden werden können. Anwender können LLMs mit Tool-Aufruf-Fähigkeiten nutzen oder eigene erstellen, um:
- Eine auszuführende Funktion auszuwählen.
- Die erforderlichen Argumente für diese Funktion abzuleiten.
- Das Abfrageverständnis über traditionelle RAG-Pipelines hinaus zu verbessern und Aufgaben wie Datenbankabfragen oder komplexes Denken zu ermöglichen.
2. Agentenimplementierung
- Single-Call-Agenten: Eine Abfrage löst einen einzigen Aufruf des entsprechenden Werkzeugs aus und gibt die Antwort zurück. Dies ist für einfache Aufgaben effektiv, kann jedoch bei vagen oder komplexen Abfragen scheitern.
- Multi-Call-Agenten: Dieser Ansatz teilt Aufgaben unter spezialisierten Agenten auf, wobei sich jeder Agent auf eine bestimmte Teilaufgabe konzentriert. Zum Beispiel:
- Retriever-Agent: Optimiert den Echtzeit-Abfrageabruf.
- Manager-Agent: Behandelt Aufgabendelegation und Orchestrierung.
3. Mehrstufiges Denken
Für komplexe Arbeitsabläufe verwenden Agenten Denkschleifen, um iteratives, mehrstufiges Denken durchzuführen und dabei den Speicher für Zwischenschritte beizubehalten. Diese Schleifen umfassen:
- Aufrufen mehrerer Werkzeuge.
- Abrufen von Daten und Validieren ihrer Relevanz.
- Bei Bedarf Umschreiben von Abfragen.
Frameworks definieren oft mehrere Agenten, um bestimmte Teilaufgaben zu bearbeiten und eine effiziente Ausführung des Gesamtprozesses zu gewährleisten.
4. Hybride Ansätze: Kombination von Abruf und Ausführung
Ein hybrider Ansatz kombiniert Abruf-Pipelines mit dynamischen Ausführungsstrategien:
- Embedding- und vektorbasierte Abrufstrategien für den Dokumentenzugriff.
- Tool-Aufruf-Fähigkeiten zur dynamischen Abfrageauflösung.
- Multi-Agenten-Zusammenarbeit für spezialisierte Teilaufgaben.
Was ist der Unterschied zwischen RAG und agentic RAG?
Hier sind die Stärken und Schwächen von RAG vs. Agentic RAG basierend auf verschiedenen Aspekten:
- Prompt Engineering
- Traditionelles RAG: Stützt sich stark auf manuelle Optimierung von Prompts.
- Agentic RAG: Passt Prompts dynamisch an Kontext und Ziele an, wodurch der Bedarf an manuellen Eingriffen sinkt.
- Kontextbewusstsein
- Traditionelles RAG: Hat begrenztes Kontextbewusstsein und verlässt sich auf statische Abrufprozesse.
- Agentic RAG: Berücksichtigt den Konversationsverlauf und passt die Abrufstrategien dynamisch an den Kontext an.
- Autonomie
- Traditionelles RAG: Besitzt keine autonomen Aktionen und kann sich nicht an veränderte Situationen anpassen.
- Agentic RAG: Führt Echtzeit-Aktionen durch und passt sich basierend auf Feedback und Echtzeit-Beobachtungen an.
- Denkfähigkeit
- Traditionelles RAG: Benötigt zusätzliche Klassifizierer und Modelle für mehrstufiges Denken und Tool-Nutzung.
- Agentic RAG: Bewältigt mehrstufiges Denken intern und macht externe Modelle überflüssig.
- Datenqualität
- Traditionelles RAG: Verfügt über keinen integrierten Mechanismus zur Bewertung der Datenqualität oder zur Sicherstellung der Genauigkeit.
- Agentic RAG: Bewertet die Datenqualität und führt nach der Generierung Prüfungen durch, um korrekte Ausgaben sicherzustellen.
- Flexibilität
- Traditionelles RAG: Arbeitet mit statischen Regeln, was die Anpassungsfähigkeit einschränkt.
- Agentic RAG: Verwendet dynamische Abrufstrategien und passt seinen Ansatz bei Bedarf an.
- Abrufeffizienz
- Traditionelles RAG: Der Abruf ist statisch und aufgrund von Ineffizienzen oft kostspielig.
- Agentic RAG: Optimiert Abrufe, um unnötige Operationen zu minimieren, senkt die Kosten und verbessert die Effizienz.
- Einfachheit
- Traditionelles RAG: Bietet einen einfachen Aufbau mit geringer Konfigurationskomplexität.
- Agentic RAG: Erfordert komplexere Konfigurationen, um dynamische und kontextbewusste Abläufe zu unterstützen.
- Vorhersagbarkeit
- Traditionelles RAG: Konsistent und regelbasiert, aber starr im Verhalten.
- Agentic RAG: Das Verhalten kann je nach Echtzeit-Kontext und Beobachtungen dynamisch variieren.
- Kosten im Einsatz
- Traditionelles RAG: Günstiger für einfache Setups, kann jedoch langfristig höhere Betriebskosten verursachen.
- Agentic RAG: Erfordert aufgrund fortschrittlicher Funktionen und dynamischer Fähigkeiten eine höhere Anfangsinvestition.
Langkontext-Modelle vs. agentic RAG: Wenn Abruf überflüssig wird
Die Revolution der Kontextfenster 2025‑2026 stellt eine Kernannahme von RAG-Architekturen in Frage. Modelle unterstützen nun 1 bis 2 Millionen Token und werfen die grundlegende Frage auf: Wann übertrifft die direkte Kontextverarbeitung die Leistung komplexer Abrufagenten?
Die sich verändernde Kontextlandschaft
Die Kontextfenster haben sich von 128k Token Anfang 2024 auf über 1M im Jahr 2026 dramatisch erweitert. Jüngste Forschung mit vollständigen Romanen als Testdaten zeigt, dass diese Erweiterung neue architektonische Abwägungen mit sich bringt, die Ingenieure berücksichtigen müssen.4
Die Rechenkosten für die Verarbeitung riesiger Kontexte müssen gegen die technische Komplexität und potenzielle Fehlerquellen von Abrufsystemen abgewogen werden. Die Verarbeitung von 1M Token eliminiert die verlustbehaftete Komprimierung durch Chunking und Indexierung, jedoch zu hohen Kosten pro Abfrage.
Das Problem des Abruf-Engpasses
Die Forschung zu langen Dokumenten identifiziert eine schwerwiegende Einschränkung traditioneller RAG-Ansätze. Der standardmäßige Top‑k-Abruf erzeugt, was Forscher als „Abruf-Engpass” bezeichnen: Wenn der erste Zugriff den relevanten Chunk verfehlt, besitzt das System keinen Wiederherstellungsmechanismus.
Agentic RAG adressiert dies durch iterative Abfrageverfeinerung. Studien zeigen, dass agentische Systeme erfolgreich einen beträchtlichen Teil der Probleme lösen, die beim einmaligen Abruf vollständig scheitern. Die autonome Schleife erlaubt es Agenten, Abfragen umzuformulieren, wenn erste Versuche unzureichende Informationen liefern.5
Wenn die Daten jedoch in die erweiterten Kontextfenster passen, übertrifft die direkte Langkontextverarbeitung selbst ausgefeilte agentische Abrufsysteme. Der Leistungsunterschied besteht, weil das Modell gleichzeitig über das gesamte Dokument hinweg argumentieren kann und die Fragmentierung vermeidet, die dem chunkbasierten Abruf innewohnt.
Verschiedene Arten von agentic RAG-Modellen
Zu den Agenten, die Large Language Models (LLMs) innerhalb von Retrieval-Augmented Generation (RAG)-Frameworks nutzen, gehören:
- Routing-Agent: Verwendet ein Large Language Model (LLM) für agentisches Denken, um die am besten geeignete Retrieval-Augmented Generation (RAG)-Pipeline (z. B. Zusammenfassung oder Fragebeantwortung) für eine gegebene Abfrage auszuwählen. Der Agent bestimmt die beste Passform durch Analyse der Eingabeabfrage.
- One-Shot-Query-Planning-Agent: Zerlegt komplexe Abfragen in kleinere Teilabfragen, führt sie über verschiedene RAG-Pipelines mit unterschiedlichen Datenquellen aus und kombiniert die Ergebnisse zu einer umfassenden Antwort.
- Tool-Use-Agent: Erweitert standardmäßige RAG-Frameworks, indem externe Datenquellen (z. B. APIs, Datenbanken) einbezogen werden, um zusätzlichen Kontext zu liefern. Dies ermöglicht eine angereicherte Verarbeitung von Abfragen mithilfe von LLMs.
- ReAct-Agent: Integriert Denken und Handeln für die Bearbeitung sequenzieller, mehrteiliger Abfragen. Er hält einen Zustand im Speicher vor und ruft iterativ Werkzeuge auf, verarbeitet deren Ausgaben und bestimmt die nächsten Schritte, bis die Abfrage vollständig gelöst ist.
- Agent für dynamische Planung & Ausführung: Dieser Agent ist für komplexere Abfragen konzipiert und trennt die übergeordnete Planung von der Ausführung. Er verwendet ein LLM als Planer, um einen Rechengraphen der zur Beantwortung der Abfrage erforderlichen Schritte zu entwerfen, und einen Executor, um diese Schritte effizient auszuführen. Der Fokus liegt auf Zuverlässigkeit, Beobachtbarkeit, Parallelisierung und Optimierung für Produktionsumgebungen.
Vorteile von agentic RAG
Agentic RAG verbessert LLMs durch:
- Autonomer & zielorientierter Ansatz: Anders als traditionelles RAG handelt agentic RAG wie ein autonomer Agent, trifft Entscheidungen zur Erreichung definierter Ziele und strebt tiefere, aussagekräftigere Interaktionen an.
- Verbessertes Kontextbewusstsein & Sensitivität: Agentic RAG berücksichtigt dynamisch den Gesprächsverlauf, Benutzerpräferenzen, vorherige Interaktionen und den aktuellen Kontext, um relevante, informierte Antworten und Entscheidungen zu liefern.
- Dynamischer Abruf & fortgeschrittenes Denken: Es verwendet intelligente, auf Abfragen zugeschnittene Abrufmethoden und bewertet und verifiziert gleichzeitig die Genauigkeit und Zuverlässigkeit der abgerufenen Daten.
- Multi-Agent-Orchestrierung: Es koordiniert mehrere spezialisierte Agenten, zerlegt Abfragen in handhabbare Aufgaben und sorgt für eine nahtlose Koordination, um genaue Ergebnisse zu liefern.
- Erhöhte Genauigkeit durch Verifikation nach der Generierung: Agentic RAG-Modelle führen Qualitätsprüfungen der generierten Inhalte durch, stellen die bestmögliche Antwort sicher und kombinieren LLMs mit agentenbasierten Systemen für überlegene Leistung.
- Anpassungsfähigkeit & Lernen: Diese Systeme lernen und verbessern sich kontinuierlich, steigern Problemlösungsfähigkeiten, Genauigkeit und Effizienz und passen sich verschiedenen Domänen für spezifische Aufgaben an.
- Flexible Werkzeugnutzung: Agenten können externe Werkzeuge wie Suchmaschinen, Datenbanken oder APIs nutzen, um die Datenerfassung, -verarbeitung und -anpassung für vielfältige Anwendungen zu verbessern.
Herausforderungen von agentic RAG
- Datenqualität: Zuverlässige Ausgaben erfordern qualitativ hochwertige, kuratierte Daten. Herausforderungen ergeben sich bei der Integration und Verarbeitung unterschiedlicher Datensätze, einschließlich textueller und visueller Daten, um die Anforderungen der Benutzerabfragen zu erfüllen. Zudem müssen die Datenabrufprozesse Genauigkeit und Konsistenz gewährleisten.
- Tipp: Implementieren Sie automatisierte Datenbereinigungswerkzeuge und KI-gestützte Datenvalidierungstechniken, um eine konsistente und qualitativ hochwertige Datenintegration über textuelle und visuelle Datensätze hinweg sicherzustellen.
- Skalierbarkeit: Eine effiziente Verwaltung der Systemressourcen und Abrufprozesse ist mit dem Wachstum des Systems entscheidend. Wenn die Anzahl der Benutzerabfragen und das Datenvolumen zunehmen, wird die Handhabung sowohl der Echtzeit- als auch der Stapelverarbeitung für den weiteren Datenabruf zu einer erheblichen Herausforderung.
- Tipp: Nutzen Sie eine skalierbare Cloud-basierte Infrastruktur und verteilte Rechen-Frameworks, um die steigende Datenlast effizient zu bewältigen. Integrieren Sie dynamischen Lastausgleich für die Echtzeit-Abfragebearbeitung.
- Erklärbarkeit: Transparenz bei der Entscheidungsfindung schafft Vertrauen. Klare Einblicke in die Generierung der Antworten auf Benutzerabfragen zu geben, insbesondere bei der Nutzung textueller und visueller Daten, bleibt eine anhaltende Herausforderung.
- Tipp: Verwenden Sie KI-Erklärbarkeitswerkzeuge wie SHAP oder LIME, um Modellvorhersagen interpretierbar zu machen, und integrieren Sie Visualisierungs-Dashboards, die Logik hinter den Antworten verdeutlichen.
- Datenschutz und Sicherheit: Starker Datenschutz und sichere Kommunikationsprotokolle sind unerlässlich. Der Umgang mit sensiblen oder vertraulichen Daten erfordert robuste Verschlüsselungs- und Compliance-Mechanismen während der Speicherung, des weiteren Datenabrufs und der Verarbeitung.
- Tipp: Setzen Sie Ende-zu-Ende-Verschlüsselung und Zugriffsmanagementlösungen ein und stellen Sie die Einhaltung von Datenschutzbestimmungen wie DSGVO oder CCPA sicher. Verwenden Sie sichere API-Gateways für den weiteren Datenabruf.
- Ethische Bedenken: Die Auseinandersetzung mit Voreingenommenheit, Fairness und Missbrauch ist für einen verantwortungsvollen KI-Einsatz entscheidend. Die Sicherstellung unvoreingenommener Antworten auf vielfältige Benutzerabfragen bleibt ein zentraler Aspekt beim ethischen KI-Design.
- Tipp: Setzen Sie verantwortungsvolle KI-Plattformen und KI-Governance-Werkzeuge ein, um KI-Voreingenommenheit zu begegnen und die vier Leitprinzipien der KI einzuhalten.
Zukunftsaussichten
Die neueste Forschung zu agentic RAG umfasst Verbesserungsbereiche wie:
- Wissensgraph-Integration: Verbessert das Denken durch die Nutzung komplexer Datenbeziehungen.
- Aufkommende Technologien: Einbindung von Werkzeugen wie Ontologien und dem semantischen Web, um die Systemfähigkeiten voranzutreiben.
- Kollaboration spezialisierter Agenten: Agenten mit Expertise in unterschiedlichen Bereichen (z. B. Vertrieb, Marketing, Finanzen) arbeiten in einem koordinierten Workflow zusammen, um komplexe Aufgaben zu bewältigen.
- Qualitätsoptimierung: Behebung inkonsistenter Ausgaben, um die Zuverlässigkeit und Präzision von Multi-Agenten-Systemen zu verbessern.
Weiterführende Lektüre
Entdecken Sie weitere RAG-Benchmarks, wie z. B.:
- Top 10 mehrsprachige Embedding-Modelle für RAG
- Embedding-Modelle: OpenAI vs Gemini vs Cohere
- Top 16 Open-Source-Embedding-Modelle für RAG
- Top Vektordatenbank für RAG: Qdrant vs Weaviate vs Pinecone
- Reranker-Benchmark: Top 8 Modelle im Vergleich
- Multimodale Embedding-Modelle: Apple vs Meta vs OpenAI
FAQs
Retrieval-Augmented Generation (RAG) ist eine Technik, die abrufbasierte Methoden mit generativen Modellen kombiniert, um die Informationsbeschaffung und Antwortgenerierung zu verbessern.
Erfahren Sie mehr über die Retrieval-Augmented Generation-Technik und gängige Modelle.
Ein Agent ist ein Computerprogramm, das seine Umgebung beobachtet, Entscheidungen trifft und Aktionen autonom ausführt, um bestimmte Ziele ohne direktes menschliches Eingreifen zu erreichen.
Verwendung in KI-Systemen
Agenten werden verwendet, um Aufgaben zu automatisieren, Prozesse zu optimieren und intelligente Entscheidungen in dynamischen Umgebungen zu treffen. Je nach Komplexität können Agenten von einfachen regelbasierten Systemen bis hin zu fortgeschrittenen Modellen reichen, die Lerntechniken verwenden.
Arten von Agenten
Reaktive Agenten: Handeln basierend auf dem aktuellen Zustand der Umgebung und folgen vordefinierten Regeln, ohne vergangene Erfahrungen zu nutzen.
Kognitive Agenten: Speichern vergangene Erfahrungen und nutzen diese, um Muster zu analysieren und Entscheidungen zu treffen, was das Lernen aus früheren Interaktionen ermöglicht.
Kollaborative Agenten: Interagieren mit anderen Agenten oder Systemen, um gemeinsame Ziele zu erreichen, häufig innerhalb von Multi-Agenten-Systemen, bei denen Koordination und Informationsaustausch entscheidend sind.
Agentic RAG kann für Aufgaben besser sein, die eine dynamischere, kontextbewusstere Entscheidungsfindung und iterative Interaktionen erfordern, aber seine Wirksamkeit hängt vom konkreten Anwendungsfall und den Implementierungsanforderungen ab.
Vanilla-RAG ruft passiv Informationen ab und generiert Antworten auf Basis eines statischen Abfrage-Antwort-Modells, während agentic RAG iterative Prozesse, Entscheidungsfindung und dynamische Interaktionen einbezieht, um Antworten zu verfeinern oder komplexe Aufgaben zu bewältigen.
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{Beste 20+ Agentic RAG Frameworks}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Abgerufen am 17. Juli 2026}
}




Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.