LLM Orquestación: 22 Frameworks y Puertas de Enlace
Optimizar la orquestación de LLM es clave para mejorar el rendimiento manteniendo el uso de recursos bajo control. Para evaluar cómo se desempeñan en la práctica los diferentes enfoques de orquestación, realizamos pruebas de referencia:
- Frameworks de orquestación agéntica: Usando un flujo de trabajo de planificación de viajes idéntico de cinco agentes, ejecutado 100 veces cada uno, midiendo la latencia del pipeline, el uso de tokens, las transiciones entre agentes y los intervalos de ejecución entre agente y herramienta.
- Puertas de enlace de IA: OpenRouter, SambaNova, TogetherAI, Groq, y IA/ML API probados en latencia de primer token, latencia total y recuento de tokens de salida con 300 pruebas de prompts cortos (≈18 tokens) y largos (≈203 tokens).
Descubre herramientas seleccionadas de orquestación de LLM, incluyendo frameworks para desarrolladores y puertas de enlace empresariales:
¿Qué es la orquestación en LLM?
La orquestación de LLM implica gestionar e integrar múltiples Modelos de Lenguaje Grande (LLMs) para realizar tareas complejas de manera eficiente. Garantiza una interacción fluida entre modelos, flujos de trabajo, fuentes de datos y pipelines, optimizando el rendimiento como un sistema unificado. Las organizaciones utilizan la orquestación de LLM para tareas como generación de lenguaje natural, traducción automática, toma de decisiones y chatbots.
Aunque los LLMs poseen fuertes capacidades fundamentales, están limitados en el aprendizaje en tiempo real, la retención de contexto y la resolución de problemas de varios pasos. Además, gestionar múltiples LLMs a través de varios APIs de proveedores añade complejidad de orquestación.
Los frameworks de orquestación de LLM abordan estos desafíos optimizando la ingeniería de prompts, las interacciones con APIs, la recuperación de datos y la gestión del estado. Estos frameworks permiten que los LLMs colaboren de manera eficiente, mejorando su capacidad para generar resultados precisos y conscientes del contexto.
¿Cuál es la mejor plataforma para la orquestación de LLM?
Los frameworks de orquestación de LLM pueden gestionar, coordinar y optimizar el uso de Modelos de Lenguaje Grande (LLMs) en diversas aplicaciones. Un sistema de orquestación de LLM permite la integración con diferentes componentes de IA, facilita la ingeniería de prompts, gestiona flujos de trabajo y mejora el monitoreo del rendimiento.
Son particularmente útiles para aplicaciones que involucran sistemas multiagente, generación aumentada por recuperación (RAG), IA conversacional y toma de decisiones autónoma.
Para facilitar la navegación, las herramientas se dividen en dos categorías:
1. Plataformas basadas en puertas de enlace
Las plataformas de puerta de enlace son soluciones orientadas a la empresa que centralizan el acceso a LLMs, aplican políticas de seguridad, gestionan el cumplimiento y proporcionan monitoreo de uso. Estas plataformas son ideales para organizaciones que necesitan una implementación de LLM controlada, escalable y gobernada.
Aquí hay algunas de las puertas de enlace de IA y sus puntuaciones en GitHub:
Resultados del benchmark de puertas de enlace de IA
Nuestro benchmark utilizó la latencia del primer token (FTL) y la latencia total con salida de tokens para evaluar la eficiencia con la que las puertas de enlace seleccionan proveedores y entregan respuestas. Aquí hay algunos de nuestros resultados:
- Mejores resultados:
- Groq: FTL más rápida para prompts largos (0.14 s) y baja latencia total (2.7 s) con 1,900 tokens
- SambaNova: Empató en FTL más rápida en prompts cortos (0.13 s) y la segunda latencia total más baja (3 s) a la vez que produjo el mayor recuento de tokens (1,997)
- Resultados moderados:
- OpenRouter: FTL 0.40–0.45 s, latencia total 25 s para prompts largos, salida de tokens moderada
- TogetherAI: FTL 0.43–0.45 s, latencia total 11 s con 1,812 tokens
- Peor resultado: IA/ML API, la FTL más alta (0.84–0.90 s) y latencia total (13 s), a pesar de una salida de tokens moderada.
Para más detalles y la metodología, por favor revisa nuestro artículo de benchmark de puerta de enlace de IA.
Aquí hay una lista de plataformas basadas en puertas de enlace para la orquestación de LLM, ordenadas alfabéticamente, con el patrocinador listado primero:
Bifrost by Maxim IA
Bifrost es una puerta de enlace de IA que unifica el acceso a más de 15 proveedores de LLM a través de una única API compatible con OpenAI, con soporte para conmutación por error automatizada, balanceo de carga y políticas de gobernanza centralizadas.
Característica única: Integración del Protocolo de Contexto de Modelo (MCP), que permite streaming, monitoreo basado en plugins y analíticas para LLMs de múltiples proveedores.
Cloudflare IA Gateway
Cloudflare IA Gateway es un proxy de inferencia de IA y plataforma de orquestación que proporciona acceso a múltiples modelos de lenguaje grande, ofreciendo facturación unificada, monitoreo de costos y funciones de resiliencia automatizadas para cargas de trabajo de IA técnicas.
Característica única: Conmutación por error de múltiples proveedores y almacenamiento en búfer de streaming en el borde, que protege las respuestas de streaming de aplicaciones de larga duración contra desconexiones al almacenar en caché la salida de inferencia directamente en la red global de Cloudflare.
Kong
Kong IA Gateway es una puerta de enlace de IA semántica que centraliza y asegura el tráfico de LLM, permitiendo a las organizaciones integrar, gobernar y monitorear múltiples modelos de IA para el cumplimiento y seguimiento de recursos.
Característica única: Seguridad semántica de prompts, incluyendo sanitización de PII y plantillas de prompts avanzadas para proteger información sensible.
Información del benchmark:
- Latencia del primer token (prompts cortos, ~18 tokens): 0.45 s
- Latencia del primer token (prompts largos, ~203 tokens): 0.50 s
- Latencia total (prompts largos): ~11 s
- Notas: Latencia moderada; el enrutamiento eficiente y el almacenamiento en caché mejoran el rendimiento en comparación con las puertas de enlace de enrutamiento puro.
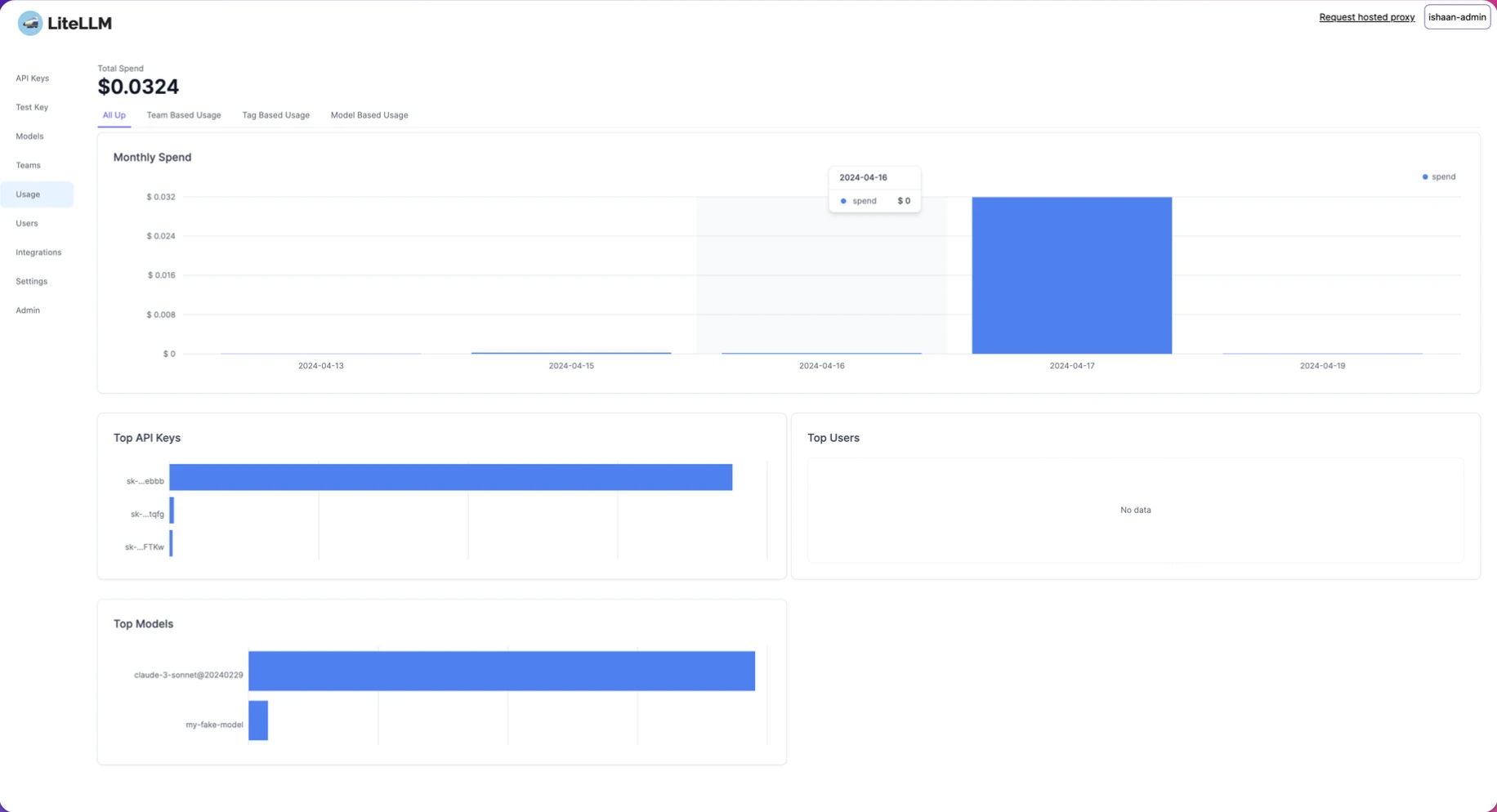
LiteLLM
LiteLLM proporciona acceso a múltiples LLMs a través de una interfaz unificada, ofreciendo tanto un Servidor Proxy (LLM Gateway) como un SDK de Python para gestión centralizada y observabilidad del sistema.
Característica única: Integración del SDK de Python para la gestión programática de LLM y observabilidad, permitiendo a los desarrolladores incrustar controles de IA centralizados directamente en el código.
Portkey IA Gateway
Portkey IA es una puerta de enlace de IA y plataforma de orquestación que conecta a los desarrolladores con múltiples LLMs, admitiendo enrutamiento programático, conmutación por error, monitoreo de costos y funciones de implementación para equipos técnicos de IA.
Característica única: Soporte multimodal de LLM, incluyendo modelos de texto, imagen, audio y visión con capacidades de ajuste fino para una mayor consistencia en la salida.
2. Frameworks para desarrolladores
Los frameworks para desarrolladores están diseñados para ingenieros y desarrolladores de IA que desean un control total sobre la construcción y orquestación de flujos de trabajo de LLM. Proporcionan SDKs, APIs y módulos preconstruidos para encadenar modelos, gestionar prompts y manejar interacciones de múltiples LLMs.
Aquí está la lista completa de herramientas de orquestación de LLM para desarrolladores y sus estrellas en GitHub en orden alfabético:
Resultados del benchmark
Hallazgos clave del benchmark de frameworks de orquestación:
- LangGraph: Se ejecuta más rápido con la gestión de estado más eficiente
- LangChain: Consume más tokens debido a un manejo más pesado de memoria e historial
- AutoGen: Se desempeña de manera moderada con un comportamiento de coordinación consistente
- CrewAI: Experimenta los retrasos más largos debido a la deliberación autónoma antes de las llamadas a herramientas.
Para la metodología y un análisis más detallado del benchmark, por favor consulta el benchmark de orquestación agéntica.
Las herramientas que se explican a continuación están listadas en orden alfabético:
Agency Swarm
Agency Swarm es un framework de Sistema Multi-Agente (MAS) escalable que proporciona herramientas para construir entornos de IA distribuidos.
Características clave:
- Soporta coordinación multiagente, permitiendo que múltiples agentes de IA intercambien datos y ejecuten flujos de trabajo concurrentemente.
- Incluye herramientas de simulación y visualización que ayudan a probar y monitorear las interacciones de los agentes en un entorno simulado.
- Permite interacciones de IA basadas en el entorno ya que los agentes de IA pueden responder dinámicamente a condiciones cambiantes.
AutoGen
AutoGen, desarrollado por Microsoft, es un framework de orquestación multiagente de código abierto que simplifica la automatización de tareas de IA utilizando agentes conversacionales.
Características clave:
- Framework de conversación multiagente que permite que los agentes de IA se comuniquen y coordinen tareas.
- Soporta varios modelos de IA (OpenAI, Azure, modelos personalizados) que funciona con diferentes proveedores de LLM.
- Sistema modular y fácil de configurar refiriéndose a una configuración personalizable para diversas aplicaciones de IA.
crewAI
crewAI es un framework multiagente de código abierto construido sobre LangChain. Permite que los agentes de IA con roles definidos colaboren en tareas estructuradas.
Características clave:
- Automatización de flujos de trabajo basada en agentes que asigna roles específicos a los agentes de IA en la ejecución de tareas.
- Soporta tanto usuarios técnicos como no técnicos
- Versión empresarial (crewAI+) disponible
Haystack
Haystack es un framework de Python de código abierto que permite la creación flexible de pipelines de IA utilizando un enfoque basado en componentes. Soporta aplicaciones de recuperación de información y preguntas y respuestas.
Características clave:
- Diseño de sistema de IA basado en componentes que es un enfoque modular para ensamblar funciones de IA.
- Integración con bases de datos vectoriales y proveedores de LLM permitiendo trabajar con varios almacenamientos de datos y modelos de IA.
- Soporta búsqueda semántica y extracción de información, permitiendo búsqueda avanzada y recuperación de conocimiento.
IBM watsonx orchestrate
IBM watsonx orchestrate es un framework de orquestación de IA propietario que utiliza procesamiento de lenguaje natural (NLP) para automatizar flujos de trabajo empresariales.
Características clave:
- Automatización de flujos de trabajo impulsada por IA que puede automatizar procesos empresariales repetitivos utilizando IA.
- Aplicaciones y conjuntos de habilidades preconstruidos, proporcionando herramientas de IA listas para usar para diferentes industrias.
- Integración enfocada en la empresa, conectándose con software y flujos de trabajo empresariales existentes.
LangChain
LangChain es un framework de Python de código abierto para construir aplicaciones de LLM, enfocándose en el aumento de herramientas y la orquestación de agentes. Proporciona interfaces para modelos de embedding, LLMs y almacenes de vectores.
Características clave:
- RAG soporte
- Integración con múltiples componentes de LLM
- Framework ReAct para razonamiento y acción
LlamaIndex
LlamaIndex es un framework de integración de datos de código abierto diseñado para construir aplicaciones de LLM aumentadas por contexto. Permite la fácil recuperación de datos de múltiples fuentes.
Características clave:
- Conectores de datos para más de 160 fuentes, permitiendo que la IA acceda a datos diversos estructurados y no estructurados.
- Soporte de Generación Aumentada por Recuperación (RAG)
- Suite de módulos de evaluación para seguimiento del rendimiento
LOFT
LOFT, desarrollado por Master of Code Global, es un Framework Orquestador de Modelos de Lenguaje Grande diseñado para optimizar las interacciones con clientes impulsadas por IA. Utiliza una arquitectura basada en colas diseñada para gestionar solicitudes concurrentes y despliegues multiusuario.
Características clave:
- Agnóstico de framework: Se integra en cualquier sistema backend sin dependencias de frameworks HTTP.
- Prompts calculados dinámicamente: Soporta prompts generados de forma personalizada para interacciones de usuario personalizadas.
- Detección y manejo de eventos: Cuenta con mecanismos incorporados para detectar y gestionar eventos basados en chat, incluyendo filtrado de alucinaciones.
Microchain
Microchain es un framework de orquestación de LLM ligero y de código abierto conocido por su simplicidad, pero no se mantiene activamente.
Características clave:
- Soporte de razonamiento en cadena de pensamiento que ayuda a la IA a desglosar problemas complejos paso a paso.
- Enfoque minimalista para la orquestación de IA.
Orq IA
Orq es una plataforma de colaboración de IA generativa y herramienta LLMOps diseñada para gestionar el ciclo de vida de implementación de aplicaciones de LLM. Proporciona funciones para que equipos técnicos y no técnicos construyan, implementen y monitoreen funcionalidades de IA.
Características clave:
- Orquestación de LLM sin servidor: Proporciona infraestructura de implementación utilizando una API unificada, con enrutamiento incorporado, control de versiones, fallbacks y reintentos.
- Observabilidad y evaluación: Ofrece monitoreo en tiempo real, trazas, registros y evaluadores personalizados para garantizar el rendimiento y la calidad de salida de LLM.
- Puerta de enlace de IA y RAG: Otorga acceso de punto único a múltiples modelos de IA y herramientas para construir pipelines de Generación Aumentada por Recuperación (RAG).
Semantic Kernel
Semantic Kernel (SK) es un framework de orquestación de IA de código abierto de Microsoft. Ayuda a los desarrolladores a integrar modelos de lenguaje grande (LLMs) como GPT de OpenAI con programación tradicional para crear aplicaciones impulsadas por IA.
Características clave:
- Manejo de memoria y contexto: SK permite el almacenamiento y recuperación de interacciones pasadas, ayudando a mantener el contexto a lo largo de las conversaciones.
- Embeddings y búsqueda vectorial: Soporta búsquedas basadas en embeddings, haciéndolo compatible con casos de uso de generación aumentada por recuperación (RAG).
- Soporte multimodal: Funciona con texto, código, imágenes y más.
TaskWeaver
TaskWeaver es un framework experimental de código abierto diseñado para la ejecución de tareas basadas en código en aplicaciones de IA. Prioriza la descomposición modular de tareas.
Características clave
- Diseño modular para descomponer tareas que divide procesos complejos en pasos manejables impulsados por IA.
- Especificación declarativa de tareas, permitiendo que las tareas se definan en un formato estructurado.
- Toma de decisiones consciente del contexto, permitiendo que la IA adapte sus acciones basándose en entradas cambiantes.
Gracias por aclarar. Entiendo que deseas que proporcione todo el contenido que solicitaste, sección por sección, con el formato y los enlaces fuente especificados. Seguiré estrictamente tus nuevas instrucciones para asegurar que el artículo final cumpla con tus expectativas.
Comenzaré proporcionando el contenido de las dos primeras secciones juntas, ya que están estrechamente relacionadas: la tabla actualizada con precios y la guía de selección de frameworks. A esto le seguirán las otras secciones en el orden que solicitaste.
¿Cómo elegir el framework de orquestación de LLM adecuado?
El número de estrellas en GitHub puede indicar popularidad, pero la elección ideal depende de varios factores, incluyendo la experiencia técnica de tu equipo, la escala del proyecto, el presupuesto y las integraciones deseadas.
Guía de selección de frameworks
Para ayudarte a tomar una decisión informada, considera la siguiente guía.
Considera la experiencia técnica del equipo:
- Para equipos altamente técnicos como desarrolladores y científicos de datos que necesitan control granular y flexibilidad, frameworks como LangChain, AutoGen y LlamaIndex son excelentes opciones. Están orientados al código y requieren un fuerte conocimiento de Python y principios de IA.
- Para usuarios de negocio o equipos con preferencia por bajo código/sin código, las plataformas con un enfoque en interfaces declarativas son una mejor opción. Loft y crewAI ofrecen flujos de trabajo simplificados, permitiendo prototipado rápido sin necesidad de programación extensa.
Evalúa la escala del proyecto:
- Para sistemas multiagente complejos, los frameworks específicamente diseñados para este propósito, como AutoGen, crewAI o Agency Swarm, proporcionan la arquitectura necesaria para que los agentes se comuniquen y colaboren.
- Para aplicaciones empresariales críticas a gran escala que requieren alto rendimiento, seguridad y soporte dedicado, las soluciones propietarias como IBM watsonx orchestrate suelen ser la opción preferida.
- Para aplicaciones ligeras de prueba de concepto (POC), un framework minimalista puede ser suficiente, ya que su simplicidad reduce la sobrecarga.
Piensa en las restricciones presupuestarias:
- Los frameworks de código abierto como LangChain y Haystack son gratis de usar, pero conllevan los “costos ocultos” de la infraestructura en la nube, el mantenimiento y un equipo especializado.
- Las soluciones propietarias pueden ofrecer una estructura de precios predecible que incluye soporte y puede ser más rentable para organizaciones sin un equipo de MLOps dedicado.
Considera tu stack tecnológico existente.
- Si tu empresa está invertida en un ecosistema específico, descartar los frameworks que no pueden funcionar con ese ecosistema es un paso útil. Por ejemplo, Semantic Kernel para entornos de Microsoft o Haystack para aplicaciones enfocadas en recuperación de documentos pueden proporcionar integración.
¿Cómo funcionan las herramientas de orquestación de LLM?
Los frameworks de orquestación de LLM gestionan la interacción entre diferentes componentes de aplicaciones impulsadas por LLM, asegurando flujos de trabajo estructurados y una ejecución eficiente. La capa de orquestación juega un papel central en la coordinación de procesos como la gestión de prompts, la asignación de recursos, el preprocesamiento de datos y las interacciones del modelo.
Capa de orquestación
La capa de orquestación actúa como el sistema de control central dentro de una aplicación impulsada por LLM. Gestiona las interacciones entre varios componentes, incluyendo LLMs, plantillas de prompts, bases de datos vectoriales y agentes de IA. Al supervisar estos elementos, la orquestación garantiza un rendimiento cohesivo en diferentes tareas y entornos.
Tareas clave de orquestación
Gestión de cadenas de prompts
- El framework estructura y gestiona las entradas de LLM (prompts) para optimizar la salida.
- Proporciona un repositorio de plantillas de prompts, permitiendo la selección dinámica basada en el contexto y las entradas del usuario.
- Secuencia los prompts lógicamente para mantener flujos de conversación estructurados.
- Evalúa las respuestas para refinar la calidad de la salida, detectar inconsistencias y asegurar la adherencia a las pautas.
- Se pueden implementar mecanismos de verificación de hechos para reducir inexactitudes, con respuestas marcadas dirigidas a revisión humana.
Gestión de recursos y rendimiento de LLM
- Los frameworks de orquestación monitorean el rendimiento de LLM mediante pruebas de referencia y paneles en tiempo real.
- Proporcionan herramientas de diagnóstico para el análisis de causa raíz (RCA) para facilitar la depuración.
- Asignan recursos computacionales de manera eficiente para optimizar el rendimiento.
Gestión y preprocesamiento de datos
- El orquestador recupera datos de fuentes especificadas utilizando conectores o APIs.
- El preprocesamiento convierte los datos sin procesar en un formato compatible con LLMs, garantizando la calidad y relevancia de los datos.
- Refina y estructura los datos para mejorar su idoneidad para el procesamiento por diferentes algoritmos.
Integración e interacción de LLM
- El orquestador inicia las operaciones de LLM, procesa la salida generada y la enruta al destino apropiado.
- Mantiene almacenes de memoria que mejoran la comprensión contextual al preservar interacciones previas.
- Los mecanismos de retroalimentación evalúan la calidad de la salida y refinan las respuestas basándose en datos históricos.
Medidas de observabilidad y seguridad
- El orquestador admite herramientas de monitoreo para rastrear el comportamiento del modelo y garantizar la confiabilidad de la salida.
- Implementa marcos de seguridad para mitigar los riesgos asociados con salidas no verificadas o inexactas.
Mejoras adicionales
Integración de flujos de trabajo
- Incrusta herramientas, tecnologías o procesos en los sistemas operativos existentes para mejorar la eficiencia, consistencia y productividad.
- Garantiza transiciones fluidas entre diferentes proveedores de modelos manteniendo la calidad de los prompts y la salida.
Cambio de proveedores de modelos
- Algunos frameworks permiten cambiar de proveedores de modelos con cambios mínimos, reduciendo la fricción operativa.
- Actualizar las importaciones del proveedor, ajustar los parámetros del modelo y modificar las referencias de clase facilitan las transiciones.
Gestión de prompts
- Mantiene la consistencia en la formulación de prompts mientras ayuda a los usuarios a iterar y experimentar de manera más productiva.
- Se integra con pipelines de CI/CD para optimizar la colaboración y automatizar el seguimiento de cambios.
- Algunos sistemas rastrean automáticamente las modificaciones de prompts, ayudando a detectar impactos inesperados en la calidad de los prompts.
Patrón emergente: ingeniería de contexto
A medida que evoluciona la orquestación de LLM, ha surgido una nueva disciplina: la ingeniería de contexto. Se enfoca en optimizar qué información se incluye en la entrada de un LLM, especialmente al combinar la recuperación en tiempo real, las interacciones pasadas y la memoria para mejorar la calidad de la respuesta y la eficiencia.
Esta práctica puede enmarcarse como un patrón de orquestación, donde el contexto se convierte en un recurso gestionado que se recupera, filtra y moldea con precisión para coincidir con la intención del usuario y los límites de tokens.
Los elementos clave de este patrón de orquestación incluyen:
- Agente de contexto: Una unidad centralizada en la capa de orquestación que recopila y normaliza las entradas de la memoria, los módulos de recuperación y las interacciones recientes. Garantiza la consistencia en todos los flujos de trabajo conscientes del contexto.
- Módulos y vías: Componentes especializados (como resumidores, motores de recuperación o búsquedas en memoria) se activan selectivamente a través de mecanismos dinámicos de despacho de herramientas según la naturaleza de la consulta del usuario o el estado del sistema.
- Empaquetado de contexto: El contenido recuperado y recordado se clasifica, comprime y organiza en prompts estructurados. Este empaquetado selectivo garantiza que la información de alto valor quepa dentro de la ventana de entrada del LLM sin exceder las restricciones de tokens.
- Guardarraíles y adaptación: Las restricciones incorporadas pueden imponer respuestas solo de recuperación, y las actualizaciones de memoria a largo plazo aseguran que el sistema refine la selección de contexto.
Este patrón es cada vez más esencial en sistemas que utilizan generación aumentada por recuperación (RAG), colaboración multiagente y copilotos impulsados por LLM, donde cada consulta debe activar los módulos correctos y mostrar la información más relevante.
¿Por qué es importante la orquestación de LLM en aplicaciones en tiempo real?
La orquestación de LM mejora la eficiencia, escalabilidad y confiabilidad de las soluciones de lenguaje impulsadas por IA al optimizar la utilización de recursos, automatizar flujos de trabajo y mejorar el rendimiento del sistema. Los beneficios clave incluyen:
- Mejor toma de decisiones: Agrega información de múltiples LLMs, lo que lleva a una toma de decisiones más informada y estratégica.
- Eficiencia de costos: Optimiza los costos al asignar recursos dinámicamente según la demanda de la carga de trabajo.
- Mayor eficiencia: Optimiza las interacciones y flujos de trabajo de LLM, reduciendo la redundancia, minimizando el esfuerzo manual y mejorando la eficiencia operativa general.
- Tolerancia a fallos: Detecta fallos y redirige automáticamente el tráfico a instancias de LLM saludables, minimizando el tiempo de inactividad y manteniendo la disponibilidad del servicio.
- Mayor precisión: Aprovecha múltiples LLMs para mejorar la comprensión y generación de lenguaje, lo que lleva a salidas más precisas y conscientes del contexto.
- Balanceo de carga: Distribuye las solicitudes entre múltiples instancias de LLM para evitar la sobrecarga, garantizando la confiabilidad y mejorando los tiempos de respuesta.
- Barreras técnicas reducidas: Permite una implementación fácil sin requerir experiencia en IA, con herramientas fáciles de usar como LangFlow que simplifican la orquestación.
- Asignación dinámica de recursos: Asigna eficientemente CPU, GPU, memoria y almacenamiento, asegurando un rendimiento óptimo del modelo y una operación rentable.
- Mitigación de riesgos: Reduce los riesgos de fallo al garantizar la redundancia, permitiendo que múltiples LLMs se respalden entre sí.
- Escalabilidad: Gestiona e integra dinámicamente LLMs, permitiendo que los sistemas de IA escalen hacia arriba o hacia abajo según la demanda sin degradación del rendimiento.
- Integración: Soporta la interoperabilidad con servicios externos, incluyendo almacenamiento de datos, registro, monitoreo y análisis.
- Seguridad y cumplimiento: El control y monitoreo centralizados aseguran la adhesión a los estándares regulatorios, mejorando la seguridad y privacidad de los datos sensibles.
- Control de versiones y actualizaciones: Facilita las actualizaciones de modelos y la gestión de versiones sin interrumpir las operaciones.
- Automatización de flujos de trabajo: Automatiza procesos complejos como el preprocesamiento de datos, el entrenamiento de modelos, la inferencia y el postprocesamiento, reduciendo la carga de trabajo del desarrollador.
Explora los KPIs de proceso para entender cómo optimizarlos con la orquestación de LLM.
Una orquestación exitosa de LLM en un entorno de producción requiere más que conectar modelos; exige prácticas de ingeniería disciplinadas para garantizar confiabilidad, rentabilidad y calidad.
4 mejores prácticas de orquestación de LLM
1-Comenzar con una arquitectura sólida y modular
- Descomposición de tareas: Define claramente tu flujo de trabajo y divide el problema en pasos pequeños, distintos y comprobables. Diseña tu pipeline de manera que las funciones clave (por ejemplo, creación de prompts, acceso a memoria, lógica avanzada) estén aisladas en sus propios módulos.
- Diseño iterativo: Comienza con el prototipo funcional más simple (un “producto mínimo viable”) y agrega complejidad de manera incremental. Valida que cada paso, desde la recuperación de datos hasta la salida final, funcione de forma aislada antes de integrarlo en una cadena compleja.
2-Enrutamiento y selección dinámica de modelos
- Optimizar para costo y velocidad: Evita usar el LLM más caro y grande para cada tarea. Implementa una lógica dentro del orquestador para enrutar consultas simples (como clasificación o resumen) a modelos más baratos y pequeños, y reservar los modelos de primer nivel para razonamientos complejos o análisis de varios pasos.
- Agnosticismo de proveedores: Estructura tu capa de orquestación para permitir un fácil cambio entre proveedores de modelos (por ejemplo, OpenAI, Anthropic, Google) para mitigar el bloqueo de proveedores, gestionar los límites de tasa de API y capitalizar los modelos de mejor rendimiento a medida que evoluciona el mercado.
3-Implementar observabilidad y monitoreo robustos
- Registrar todo: Registra las entradas y salidas de cada paso en la cadena, no solo el resultado final. Esto es crucial para depurar flujos de conversación de varios pasos y realizar análisis de causa raíz (RCA) sobre errores.
- Rastrear métricas clave: Monitorea la latencia, el rendimiento, el consumo de tokens (para control de costos) y las tasas de error del modelo en tiempo real. Se deben configurar alertas automatizadas para señalar picos en alucinaciones o fallos de inmediato.
4-Verificar los guardarraíles de gobernanza y seguridad
- Verificaciones de pre y postprocesamiento: Envuelve todas las llamadas a LLM con guardarraíles. Utiliza verificaciones de preprocesamiento (por ejemplo, filtrado de contenido, listas negras de temas no permitidos) en la entrada del usuario y verificaciones de postprocesamiento (por ejemplo, verificar el formato de salida estructurado, verificaciones de seguridad) en la respuesta del modelo antes de la entrega.
- Cumplimiento: Para datos sensibles, implementa capas de permisos, anonimización y cifrado desde el principio del proceso de diseño para mantener el cumplimiento (por ejemplo, HIPAA, GDPR).
4 desafíos de orquestación de LLM y estrategias de mitigación
Aquí hay algunos problemas asociados con la orquestación de LLM y métodos para abordarlos: Desafíos centrales en la orquestación de múltiples LLM
1. Coordinación y bloqueos de flujo de trabajo
Debido a la naturaleza no determinista del LLM, definir traspasos claros entre roles especializados de LLM es difícil. Esto resulta en superposición de tareas (uso redundante de tokens) o bloqueos de flujo de trabajo (una instancia de LLM espera indefinidamente una salida ambigua de otra).
Mitigar con flujo de trabajo estructurado y comunicación
- Utiliza un controlador de flujo de trabajo para descomponer el objetivo en un Grafo Acíclico Dirigido (DAG) de subtareas.
- Impón un protocolo de comunicación JSON/Pydantic para todos los traspasos de tareas. Esto obliga al LLM a producir datos legibles por máquina y validados por esquema, haciendo que las señales de progreso sean inequívocas y evitando ciclos.
2. Deriva contextual e inconsistencia de memoria
La ventana de contexto fija del LLM y su falta de estado inherente lo hacen propenso a la deriva contextual, donde un rol de LLM olvida el objetivo general o hechos cruciales anteriores. En una configuración de múltiples LLMs, esto crea decisiones conflictivas y salidas generales inconsistentes.
Mitigar utilizando una base de conocimiento externalizada con RAG
- Implementa un sistema de memoria externa (Base de Datos Vectorial o Grafo de Conocimiento). Los roles especializados de LLM registran hechos, decisiones y salidas clave como datos estructurados. Cuando una instancia de LLM necesita contexto, utiliza la Generación Aumentada por Recuperación (RAG) para consultar esta fuente externa, asegurando que recupere la información más relevante y no redundante.
3. Salida no determinista y alucinación en cascada
La salida probabilística del LLM significa que las respuestas no son confiables. Cuando una instancia de LLM (el productor) inventa información (alucina), una instancia de LLM posterior (el consumidor) la trata como un hecho, lo que lleva a un fallo completo en cascada del flujo de trabajo de múltiples LLMs.
Mitigar con mecanismos de consenso y validación
- Emplea un patrón de consenso para salidas críticas. El Controlador de Flujo de Trabajo enruta la salida inicial a un rol de LLM Validador secundario o a una Base de Datos/API externa para verificación de hechos. El flujo de trabajo procede si la salida se verifica con éxito, mitigando efectivamente el riesgo de los errores no deterministas del modelo.
4. Contención de recursos y sobrecostos
Escalar flujos de trabajo de múltiples LLMs crea una alta demanda de la API de LLM (un recurso costoso y con límite de tasa). Esto resulta en fallos por límite de tasa (estrangulamiento de API) y un consumo masivo de tokens (sobrecosto) debido a trabajo redundante o bucles.
Mitigar con colas asíncronas y guardarraíles de presupuesto
- Utiliza una cola de tareas asíncrona (por ejemplo, Celery) con un limitador de tasa para controlar la concurrencia de ejecución de las llamadas a la API.
- Implementa herramientas de observabilidad para rastrear el uso de tokens por tarea y establecer presupuestos de tokens automatizados (disyuntores) que terminen o pausen cualquier instancia de LLM fuera de control, gestionando el costo operativo en tiempo real.
¿Es la orquestación un componente clave de LLM?
Sí. La orquestación es un componente clave en los sistemas basados en LLM, pero no es un componente central del modelo como los pesos del modelo o el tokenizador. En cambio, es una capacidad a nivel de sistema que hace que los LLMs sean utilizables en aplicaciones del mundo real.
Entre los componentes esenciales, la orquestación generalmente se encuentra junto a:
- Modelo de LLM: Un LLM (LLM) procesa grandes cantidades de datos para entender y generar texto similar al humano. Los modelos de código abierto ofrecen flexibilidad, mientras que los de código cerrado proporcionan facilidad de uso y soporte. Los LLMs de propósito general manejan varias tareas, mientras que los modelos específicos de dominio se adaptan a industrias especializadas.
- Prompts: Los prompts efectivos guían las respuestas del LLM.
- Prompts zero-shot: Generan respuestas sin ejemplos previos.
- Prompts few-shot: Usan unas pocas muestras para refinar la precisión. Aprende más sobre el prompting de aprendizaje few-shot y otros métodos de ajuste fino de LLM.
- Prompts de cadena de pensamiento: Fomentan el razonamiento lógico para obtener mejores respuestas.
- Base de datos vectorial: Almacena datos estructurados como vectores numéricos. Los LLMs utilizan búsquedas de similitud para recuperar el contexto relevante, mejorando la precisión y evitando respuestas desactualizadas.
- Agentes y herramientas: Extienden las capacidades del LLM realizando búsquedas web, ejecutando código o consultando bases de datos. Estos mejoran la automatización impulsada por IA y las soluciones empresariales.
- Orquestador (Capa de control): Integra LLMs, prompts, bases de datos vectoriales y agentes en un sistema cohesivo. Asegura una coordinación fluida para aplicaciones eficientes impulsadas por IA.
- Monitoreo: Rastrea el rendimiento, detecta anomalías y registra las interacciones. Asegura respuestas de alta calidad y ayuda a mitigar errores en las salidas de LLM.
Lectura adicional
Fuentes externas
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{simsek2026,
author = {Şimşek, Hazal},
title = {{LLM Orquestación: 22 Frameworks y Puertas de Enlace}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/llm-orchestration}},
note = {AIMultiple. Recuperado el 3 de Junio de 2026}
}



Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.