Les défis de scraping web les plus courants
Le scraping web est devenu plus difficile ces dernières années. Depuis 2025, le scraping lié à l'IA a soulevé d'importantes préoccupations juridiques. Les plateformes et les fournisseurs d'infrastructure ont adopté de nouvelles méthodes pour contrôler les robots d'exploration IA et gérer la collecte de données.
Quels sont les principaux défis du scraping web ?
Il existe de nombreux défis techniques auxquels les scrapers web sont confrontés en raison des barrières mises en place par les propriétaires de données ou de sites web pour distinguer les humains des bots et limiter l'accès non humain à leurs informations. Les défis du scraping web peuvent être divisés en ces catégories distinctes :
Les défis découlant des sites web cibles :
- Barrière de score de confiance (détection invisible des bots)
- La pollution des données par le contenu généré par l'IA
- Contenu dynamique
- Changements de structure du site web
- Techniques anti-scraping (bloqueurs CAPTCHA, Robots.txt, bloqueurs d'IP, leurres et empreinte numérique du navigateur)
Les défis inhérents aux outils de scraping web :
- Évolutivité
- Problèmes juridiques et éthiques
- Maintenance de l'infrastructure
Risques juridiques et de conformité
Les plateformes continuent de faire face à de nouvelles réclamations basées sur le contrat, la concurrence déloyale, la vie privée et la mauvaise utilisation des données. En 2025, Reddit a poursuivi Anthropic, alléguant que Anthropic a scrapé les commentaires d'utilisateurs de Reddit pour entraîner Claude sans permission. Le procès s'est concentré sur les questions de conditions d'utilisation et de concurrence déloyale plutôt que sur le droit d'auteur.
Barrière de score de confiance (détection invisible des bots)
Le blocage statique (IP/User-Agent) a été remplacé par une évaluation continue de la confiance comportementale. Les fournisseurs modernes de protection anti-bot (Cloudflare, Akamai) suivent les tremblements de la souris et la vitesse de défilement avant un clic.
Les scrapers qui sautent vers un bouton ou cliquent avec une précision mathématique sont signalés avec un faible score de confiance, entraînant des blocages doux où les données ne se chargent pas sans message d'erreur.
Solution :
Les outils standard basés sur WebDriver/CDP sont facilement détectés par les sites web. Utilisez des bibliothèques modernes comme Nodriver, qui communique directement avec Chrome pour ne laisser aucune marque d'automatisation, ou Camoufox, une version durcie de Firefox conçue spécifiquement pour la discrétion.1
Pollution par le contenu généré par l'IA
Alors que les scrapers ingèrent des données pour l'entraînement, ils rencontrent de plus en plus l'effondrement des modèles, scrapant accidentellement des hallucinations générées par l'IA qui dégradent la qualité de leur propre sortie. Cela rend l'authenticité des données un défi technique plutôt qu'un contrôle de qualité.
Solution :
Implémentez une couche de validation pré-stockage qui calcule la perplexité du texte scrapé. Le contenu généré par l'IA a souvent une perplexité anormalement faible. Jetez les données qui tombent en dessous d'un certain seuil d'unicité.
Contenu web dynamique
Le contenu web dynamique pose un défi significatif pour les scrapers web, car il modifie fondamentalement la façon dont les informations sont livrées et affichées sur une page web.
Contrairement aux sites statiques, où tout le contenu est dans le fichier HTML initial, les sites dynamiques construisent la page à la volée, souvent en réponse au comportement de l'utilisateur. Des technologies comme AJAX (Asynchronous JavaScript and XML) sont au cœur des sites web dynamiques.
Le problème principal est que les outils de scraping standard ne sont pas des navigateurs web. Ils voient le shell HTML initial, qui peut contenir des espaces réservés, des animations de chargement et des balises <script>, mais manque souvent des données réelles que vous souhaitez extraire. Ces outils simples n'exécutent pas JavaScript.
Solution :
Pour surmonter ces défis, les scrapers web doivent évoluer de simples analyseurs HTML vers des outils capables de rendre complètement une page web comme le navigateur d'un humain.
Un navigateur sans tête est un navigateur web sans interface graphique (GUI). Il s'exécute en arrière-plan mais possède toutes les capacités d'un navigateur standard, y compris un moteur JavaScript puissant.
Des outils comme Selenium, Puppeteer et Playwright vous permettent de contrôler programmatiquement les navigateurs (tels que Chrome, Firefox ou WebKit). En utilisant ces outils avancés, vous pouvez créer des scrapers web capables d'interagir avec des sites web complexes et dynamiques et d'accéder à du contenu qui serait complètement invisible pour des méthodes de scraping web plus simples.
Navigateurs distants
Une autre solution consiste à utiliser des navigateurs de scraping, également appelés navigateurs distants. Ce sont des navigateurs gérés par des entreprises de données web. Ils permettent également aux scrapers web d'interagir avec JavaScript.
Changements de structure du site web
Les sites web sont continuellement améliorés. Ces altérations peuvent affecter la mise en page, le design ou le code sous-jacent d'un site. L'impact d'un changement mineur :
- Par exemple, si un développeur décide de changer la classe de l'élément prix de price à current-price pour plus de clarté, les instructions du scraper échoueront :
- Le scraper ne sera plus en mesure de trouver le prix. Il pourrait retourner une erreur, une valeur vide, ou pire, il pourrait accidentellement saisir la mauvaise donnée qui se trouve dans un endroit similaire.
- Comme ces changements peuvent survenir à tout moment et sans avertissement, le code du scraper a constamment besoin d'ajustements potentiels.
Solution
Au lieu de s'appuyer sur des sélecteurs hautement spécifiques et fragiles, les développeurs peuvent en écrire de plus intelligents. Par exemple, au lieu de chercher un <span> avec la classe exacte price, un analyseur adaptable pourrait chercher un <span> situé à côté du texte « Prix : » ou celui qui contient un signe dollar ($).
Des vérifications automatisées peuvent être exécutées périodiquement pour valider les données scrapées. Supposons que le champ prix commence soudainement à retourner des valeurs vides pour tous les produits. Dans ce cas, le système peut alerter automatiquement le développeur que la structure du site web a probablement changé et que l'analyseur doit être mis à jour.
LLMs
Les modèles d'IA peuvent être utilisés pour identifier les éléments à scraper ou pour collecter des données à partir de pages web. Bien qu'ils ajoutent de la latence et des coûts au scraping, ils augmentent l'adaptabilité des scrapers web.
Techniques anti-scraping
De nombreux sites web utilisent des technologies anti-scraping pour empêcher ou entraver les activités de scraping web. Les points suivants fournissent un aperçu de certaines des mesures anti-bot les plus courantes rencontrées dans le processus de scraping web :
Bloqueurs CAPTCHA
Les sites web utilisent CAPTCHA lorsqu'ils soupçonnent qu'un visiteur pourrait être un bot. Cela est courant sur les pages web pour l'inscription des utilisateurs, les formulaires de connexion, les sections de commentaires et pendant les processus de paiement pour les articles très demandés.
Des implémentations de CAPTCHA trop agressives peuvent bloquer les « bons bots », tels que le bot Google qui explore le web pour indexer les pages pour les résultats de recherche. Si le robot d'exploration de Google est bloqué, les pages d'un site web peuvent ne pas être correctement indexées, ce qui peut avoir un impact négatif sur ses pratiques de SEO et son classement dans les moteurs de recherche.
Solution :
Pour contourner cet obstacle, les scrapers doivent être équipés d'un mécanisme pour résoudre ces défis. Bien qu'efficace, l'utilisation d'un service de résolution de CAPTCHA ajoute une autre couche de complexité et de coût financier au projet de scraping web, car ces services facturent généralement par CAPTCHA résolu.
Robots.txt
Depuis 2025, la gouvernance des robots d'exploration s'est étendue au-delà du classique robots.txt. Cloudflare a introduit des contrôles pour les robots d'exploration IA, des fonctionnalités de robots.txt gérées, une politique de signaux de contenu et des outils Pay Per Crawl qui permettent aux éditeurs de bloquer, autoriser ou facturer l'accès aux robots d'exploration.2
Solution :
La bonne approche consiste à trouver un moyen officiellement autorisé d'obtenir les données web. La meilleure alternative est de voir si le site web offre une API pour l'accès aux données. Si aucune API publique n'est disponible, la prochaine étape est la communication directe. Vous pouvez contacter le propriétaire du site web ou le propriétaire des données, en expliquant qui vous êtes et ce que vous intendez faire avec les données.
Blocage d'IP
Le blocage d'IP (également connu sous le nom de bannissement d'IP) est l'une des mesures anti-scraping les plus courantes et fondamentales utilisées par les sites web. Lorsqu'un serveur de site web détecte un trafic anormalement élevé provenant d'une seule adresse IP, il le signale comme suspect. Une fois votre IP bloquée, toutes les demandes ultérieures de votre scraper seront rejetées.
Solution :
Un proxy est un serveur intermédiaire qui se situe entre votre scraper et le site web cible. Lorsque vous envoyez une demande via un proxy, le site web voit la demande provenir de l'adresse IP du proxy, et non de votre propre adresse IP. Deux types puissants de proxies à cette fin :
- Proxies rotatifs : Votre outil de scraping web est configuré pour utiliser ce pool, et avec chaque nouvelle demande (ou après un nombre défini de demandes), il change automatiquement vers une adresse IP différente. Cela distribue vos demandes sur plusieurs adresses IP, de sorte qu'aucune seule ne dépasse les limites de taux du site web.
- Proxies résidentiels : Les adresses IP dans un pool de proxy résidentiel appartiennent à de vraies connexions internet de niveau consommateur fournies par les fournisseurs de services Internet (FAI) aux propriétaires de maisons. Comme le trafic provient d'une adresse IP résidentielle légitime, il est presque impossible pour un site web de distinguer la demande d'un scraper de celle d'un véritable utilisateur humain.
Pièges leurres
Les leurres sont des systèmes informatiques conçus pour attirer les pirates et les empêcher d'accéder aux sites web. Un piège leurre apparaît généralement comme une partie légitime du site web et contient des données qu'un attaquant pourrait cibler.
Si un bot d'exploration tente d'extraire le contenu d'un piège leurre, il entrera dans une boucle infinie de demandes et échouera à extraire toute donnée supplémentaire.
Pourquoi les bots tombent dedans
Un utilisateur humain interagit avec la version rendue et visuelle d'un site web et ne verrait jamais ni ne cliquerait sur ce lien caché. Cependant, de nombreux scrapers simples ne rendent pas la page visuellement.
Ils fonctionnent en analysant le code source HTML brut et en extrayant programmatiquement tous les liens (balises <a href="…">) qu'ils trouvent. Comme le lien leurre existe dans le HTML, le bot naïf le verra et le suivra, comme n'importe quel autre lien légitime.
Solution
Au lieu d'analyser le HTML brut, utilisez un navigateur sans tête, tel que Selenium, Puppeteer ou Playwright. De plus, en définissant des emplacements spécifiques et prévisibles pour les liens que vous souhaitez suivre, vous pouvez réduire la chance que votre scraper tombe sur un lien leurre qui a été intentionnellement placé dans une partie obscure du HTML.
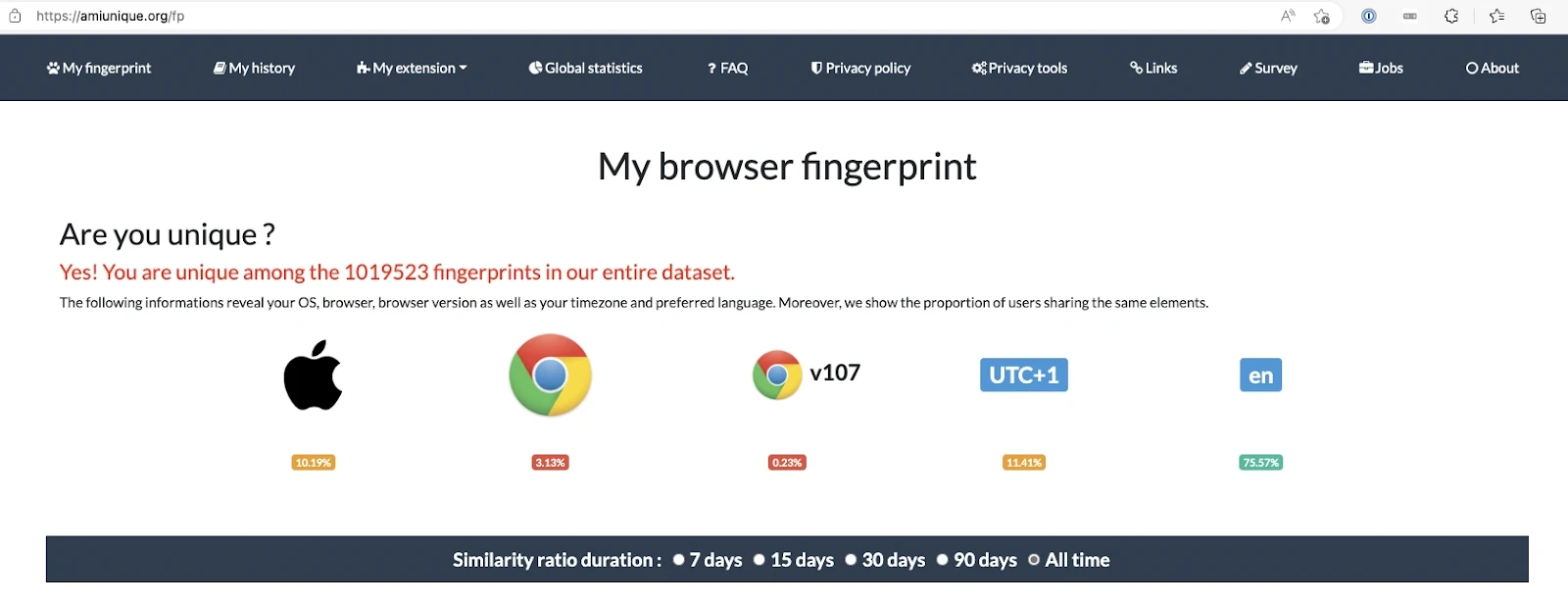
Empreinte numérique du navigateur
L'empreinte numérique du navigateur est une méthode utilisée par les sites web pour collecter des informations sur leurs visiteurs via leurs adresses IP. Chaque fois que vous accédez à un site web, votre appareil émet une demande de connexion au site pour charger son contenu. Cela permet au site web de récupérer et de stocker les données transmises par votre navigateur concernant votre appareil.
Les sites web peuvent accumuler des détails étendus sur l'appareil d'un utilisateur, leur permettant de personnaliser les suggestions pour leurs visiteurs en utilisant l'empreinte numérique du navigateur. Par exemple, le site web cible peut extraire des données sur vos agents utilisateurs, l'en-tête HTTP, les paramètres de langue et les plugins installés.
Source : AmIUnique
Le défi pour les scrapers
L'empreinte numérique du navigateur pose un défi significatif car les scrapers, par défaut, ont des empreintes numériques étranges et incohérentes.
- Empreintes génériques : Un scraper de base utilisant une bibliothèque simple enverra un ensemble minimal d'en-têtes et n'aura aucun plugin, résolution d'écran ou autres attributs « humains ».
- Empreintes incohérentes : Un scraper peut utiliser des proxies rotatifs, faisant en sorte que son adresse IP apparaisse depuis l'Allemagne sur une demande et le Japon sur la suivante.
Solution
Utilisez des navigateurs sans tête tels que Selenium, Puppeteer ou Playwright. Ce sont de vrais moteurs de navigateur qui génèrent une empreinte numérique plus complète et crédible dès la sortie de l'usine par rapport aux simples bibliothèques HTTP.
Vous pouvez également maintenir une liste de chaînes User-Agent standard et réelles et les faire tourner pour différentes sessions. Assurez-vous que les en-têtes HTTP envoyés sont également cohérents avec ceux d'un vrai navigateur.
Évolutivité
Vous pourriez avoir besoin de scraper une grande quantité de données web à partir de plusieurs sites web pour obtenir des informations sur l'intelligence des prix, la recherche de marché et les préférences des clients. À mesure que la quantité de données à scraper augmente, vous avez besoin d'un scraper web hautement évolutif pour effectuer plusieurs demandes en parallèle.
Solution :
Vous devez utiliser un scraper web conçu pour gérer des demandes asynchrones afin d'améliorer la vitesse et de rassembler de grandes quantités de données plus rapidement.
Le scraping de données asynchrone est une technique qui permet à un scraper d'envoyer plusieurs demandes à différents sites web sans attendre que chacune réponde avant d'envoyer la suivante.
Par exemple, si un site web met du temps à répondre, un scraper asynchrone peut continuer à envoyer et traiter des demandes vers d'autres sites web plus rapides dans l'intervalle.
Maintenance de l'infrastructure
Pour maintenir des performances optimales du serveur, il est essentiel de mettre régulièrement à niveau ou d'étendre les ressources telles que le stockage pour accommoder les volumes de données croissants et les complexités du scraping web. Vous devez mettre continuellement à jour votre infrastructure de scraping web pour suivre la demande évolutive.
La construction et la gestion d'une infrastructure de scraping nécessitent un large éventail de compétences techniques. Cela inclut l'administration de serveurs, la gestion de réseau, l'optimisation de base de données et les connaissances spécialisées nécessaires pour contourner les mécanismes anti-bot.
Solution :
Lorsque vous externalisez vos besoins en scraping web, assurez-vous que le fournisseur de services offre des fonctionnalités intégrées telles qu'un rotateur de proxy et un analyseur de données. De plus, le fournisseur doit offrir des options évolutives et mettre régulièrement à jour son infrastructure pour répondre aux besoins changeants.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Les défis de scraping web les plus courants}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/web-scraping-challenges}},
note = {AIMultiple. Consulté le 13 Mai 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.