Fatura OCR Kıyaslaması: LLM'ler ve OCR'ların Çıkarma Doğruluğu
Fatura işleme, geleneksel olarak manuel veri çıkarma ve muhasebe sistemlerine giriş gerektiren, kritik ancak emek yoğun bir iş operasyonudur. Bu manuel yaklaşım zaman alıcıdır ve insan hatasına açıktır. Otomatik alternatifleri değerlendirmek amacıyla, önde gelen belge işleme çözümlerinin ve LLM'lerin karşılaştırmalı bir analizini gerçekleştirdik:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document AI
- Microsoft Azure Document Intelligence
- Rossum
Çalışmamız, bu araçların çeşitli fatura formatlarından ve kalitelerinden veri çıkarma yeteneklerini değerlendirerek, manuel işlemeye alternatif olarak etkinliklerini nicelendirmeyi amaçladı.
Kıyaslama sonuçları
Fatura işleme performansını farklı kalite ve kontrast seviyelerindeki faturalar üzerinde değerlendirdik. Tüm araçlar yüksek kaliteli görüntülerle güçlü performans sergilerken, düşük kaliteli belgeler işlenirken doğrulukları önemli ölçüde düştü. Test edilen araçlar arasında Claude Sonnet 3.5, tüm belge kaliteleri yelpazesinde en yüksek genel doğruluk ve dayanıklılığı gösterdi.
Metodoloji
Ölçüm: Değerlendirme metodolojimiz, anahtar-değer çifti çıkarma doğruluğuna odaklandı. Çıkarılan her alan, ikili sınıflandırma kullanılarak değerlendirildi: doğru çıkarma veya yanlış/eksik çıkarma. Doğruluk metriği aşağıdaki formül kullanılarak hesaplandı:
Doğruluk = (Doğru Çıkarılan Anahtar-Değer Çiftlerinin Sayısı) / (Toplam Anahtar-Değer Çifti Sayısı)
Bu metodoloji, farklı araçlar ve belge türleri arasında çıkarma performansının objektif olarak karşılaştırılmasını sağladı.
Örneklem büyüklüğü: Fatura verisi bulmak, kişisel bilgiler (e-posta ve isimler) içerdiğinden zorludur. 20 halka açık fatura örneğinden alınan 400'den fazla anahtar-değer çifti kullandık.
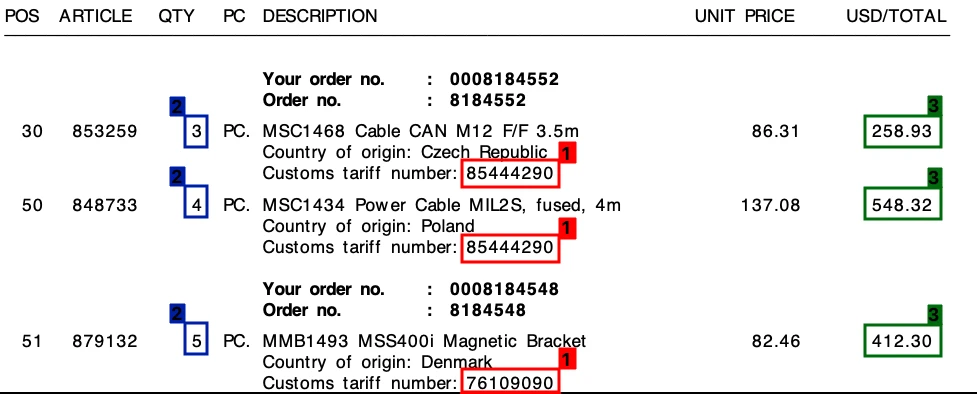
Örnekler: Tüm çözümler yüksek kaliteli görüntüleri doğru şekilde işlerken, çıkarma kalitesi aşağıdaki gibi görüntülerde düştü:
Fine-tuning: Denediğimiz ürünler toplam tutarları bulmada başarılı olsalar da, fiyatlandırma ayrıntılarını çıkarmada sorun yaşadılar. Bazı ürünlerde ince ayar (fine-tuning) yaparak daha iyi sonuçlar elde etmek mümkündür. Birkaç üründe, kullanıcılar model çıktısını düzeltmek için görüntüdeki bir değere tıklayabilirler.
Tüm sağlayıcılar için adil olmak adına hiçbir ince ayar yapmadık. İnce ayar ile, tüm sağlayıcılar bu belgeleri ikinci kez işlediklerinde daha yüksek başarı oranlarına ulaşabilmelidir. Ancak bu kıyaslamadaki odağımız, modellerin daha önce görmedikleri belgelerden doğru, güvenilir sonuçlar üretmesini gerektiren otonom operasyonlardır.
Zaman çizelgesi: Tüm testler Aralık 2024'te tamamlandı.
Sonraki adımlar
Katılımcı sayısını artırma: Bu çalışma, Büyük Dil Modelleri (LLM'ler), OCR teknolojileri ve uzmanlaşmış fatura işleme araçları arasındaki mevcut fatura işleme yeteneklerine dair içgörüler sağladığından, otomatik fatura işleme çözümlerine yönelik daha kapsamlı bir kıyaslama sunmak için ek son teknoloji LLM'ler dahil ederek analizimizi genişletmeyi planlıyoruz.
Örneklem büyüklüğünü ve çeşitliliğini artırma.
Fatura OCR nedir?
Fatura ayrıştırma, PDF'ler ve görüntüler gibi çeşitli formatlardaki faturalardan veri çıkarmak için NLP, NLU, OCR ve diğer veri çıkarma teknolojileri gibi otomatik araçları kullanır.
Bir fatura ayrıştırıcı, aşağıdaki gibi bilgileri çıkaran bir yazılım programıdır:
Satıcı adı
Fatura numarası
Ödenecek tutar
ve bunları makine tarafından okunabilir bir formatta girer. Bu veriler, borç hesaplarını otomatikleştirme, ay sonu muhasebe kapanışlarını tamamlama ve fatura yönetimi gibi çeşitli işlevler için kullanılabilir.
Ayrıştırıcı yazılım genellikle, bir faturanın alınmasından ödemeye kadar tüm süreci otomatikleştiren bir fatura işleme sistemine entegre edilir.
Fatura OCR araçları nasıl çalışır?
Belirli bir işaretleme dilinde yazılmış belgeler, ayrıştırıcılar tarafından okunur ve işlenir. Belgeyi token adı verilen daha küçük parçalara ayırır ve her bir token'ı, belgenin yapısında ne anlama geldiğini ve nereye uyduğunu belirlemek için inceler.
Bunu yapmak için, ayrıştırıcıların ilgili işaretleme dilinin dilbilgisi hakkında çok şey bilmesi gerekir. Bu, her bir token'ı tanımalarını ve aralarındaki kesin bağlantıları belirlemelerini sağlar.
Süreç 5 adımdan oluşur:
1. Girdi
Faturalar, kağıt, e-posta veya PDF ya da XML gibi elektronik formatlar dahil olmak üzere çeşitli formatlarda alınabilir. Fatura ayrıştırma yazılımı tipik olarak bu faturaları girdi olarak kabul eder.
2. Optik Karakter Tanıma (OCR)
Fatura taranmış kağıt veya görüntü formatındaysa, ayrıştırıcı görüntüden metin çıkarmak için OCR teknolojisini kullanır. Bu, ayrıştırıcının fatura içindeki verilere erişmesini sağlar.
Bazı fatura ayrıştırma çözümleri, yeni kurallara veya şablonlara ihtiyaç duymadan PDF'lerden, fotoğraflardan ve taranmış belgelerden bilgileri otomatik olarak çıkaran yapay zeka destekli OCR araçları veya LLM'ler kullanır. Bunun nedeni, yapay zekanın yarı yapılandırılmış ve alışılmadık belgeleri işleyebilmesi ve zamanla iyileşebilmesidir. Çıkarılan bilgiler, yalnızca belirli tabloları veya veri girişlerini içerecek şekilde özelleştirilebilir.
3. Veri çıkarma
Ayrıştırıcı daha sonra faturadan satıcı adı, fatura numarası, tarih ve ürün detayları gibi belirli bilgileri çıkarır. Bu genellikle örüntü tanıma ve makine öğrenimi algoritmalarının bir kombinasyonu kullanılarak gerçekleştirilir.
Bazı fatura ayrıştırma yazılımları, önceden tanımlanmış filtreler kullanarak fatura tarihi, numarası, vergi kimlik numaraları ve çeşitli toplamlar gibi kilit bilgileri çıkarma yeteneğine sahiptir:
Bazı ayrıştırıcı araçlar, her bir satıcı veya ticari ortak düzeni için ayrı bir belge ayrıştırıcı oluşturarak, tutarlı formata sahip faturalardan satır kalemi bilgilerini çıkarma imkanı sunar:
4. Veri doğrulama
Veriler çıkarıldıktan sonra, ayrıştırıcı bilgilerin doğru ve eksiksiz olduğundan emin olmak için doğrular. Bu, tarihin doğru formatta olup olmadığını, satıcı adının önceden tanımlanmış bir satıcı listesiyle eşleşip eşleşmediğini veya ürün detaylarının beklenen formata uyup uymadığını kontrol etmeyi içerebilir.
5. Veri çıktısı
Çıkarılan ve doğrulanan veriler daha sonra kullanıcının muhasebe veya ERP sistemine kolayca aktarılabilecek bir formatta çıktı olarak verilir. Bu, bir CSV dosyası, veritabanı kaydı veya doğrudan bir muhasebe yazılımına olabilir.
Manuel fatura veri çıkarmanın zorlukları
Faturalardan verileri manuel olarak çıkarmak ve bir sisteme girmek, şirketler için çeşitli zorluklar barındırır:
İnsan hatası
Faturalar büyük miktarda veri içerebilir ve manuel giriş, yazım hataları, rakamların yer değiştirmesi ve yanlış veri girişi gibi hata riskini artırır. Veri girişindeki yanlışlıklar, yıllık tahmini 600 milyar dolarlık kayba neden olmaktadır.1 Borç hesapları gibi süreçler, finansal belgelerden doğru veri aktarımına ihtiyaç duyar.
Zaman alıcı
Ortalama olarak, tek bir faturayı manuel olarak işlemek 17 gün veya bir ayın yaklaşık %75'ini alır.2
Faturalar birçok önemli bilgiyi içerir ve her parça, anahtar-değer tarzında sunulur; burada her öğe hem anahtar hem değer olarak işlev görür. Bu çiftleri manuel olarak çıkarma işlemi zaman alıcıdır ve doğruluğu sağlamak için birden fazla kontrol gerektirir. Hatta bazı OCR algoritmaları bile bağlam olmadan çıkarılan değerleri tespit etmekte zorlanır. Otomatik fatura işleme, çalışanların daha karmaşık görevlere odaklanmasına yardımcı olabilir.
Standardizasyon eksikliği
Farklı tedarikçilerden gelen faturalar farklı formatlarda olabilir. Her fatura benzersiz bir formatta oluşturulur ve bu desenlerin işlenmesi ve yorumlanması sırasında zorluk çıkarabilir. E-postalar, kağıt ve PDF'ler gibi belgeler, ödeme için onaylanmadan önce birçok dijital ve kağıt kaydından geçebilir; bu da manuel veri çıkarmayı zorlaştırır ve hataya açık hale getirir.
Süreç verimsizliği
Fatura başına ortalama yaklaşık 23$ maliyete yol açan manuel fatura işleme,3 hem zaman alıcı hem de pahalı olabilir ve verimsiz, tekrarlayan bir sürece yol açar.
Veri kaybı potansiyeli
Faturaların kaybolması veya hasar görmesi ya da verilerin sisteme doğru girilmemesi durumunda veri kaybı riski vardır.
OCR yazılımları da çoğu zaman faturalardan satır kalemlerini çıkarmada zorluk yaşar. Bunun nedeni, işlem tablolarının yatay veya dikey çizgiler içermemesi olabilir; bu da fatura OCR işlemenin, çıkarılan öğeler için bağlam oluşturmasını zorlaştırır. Toplanan dijital fatura veya fatura görüntüleri bu süreçte kullanılabilir.
Fatura işleme tedarikçinizi nasıl seçersiniz?
1. Şirketinizin veri gizliliği politikalarıyla uyumlu bir çözüm sunar.
Şirketinizin veri gizliliği politikası, Amazon AWS Textract gibi harici API'leri kullanmaya engel teşkil edebilir. Çoğu sağlayıcı, şirket içi çözümler sunar, böylece veri gizliliği politikaları şirketinizin fatura yakalama çözümünü kullanmasını mutlaka engellemez. Borç hesapları iş akışı, sıklıkla gizli iş ve finansal bilgileri içerdiğinden dikkatle ele alınmalıdır.
2. Belgelerdeki metinden bağımsız olarak tutarlı bir veri yapısı sağlar.
Derin öğrenme tabanlı fatura yakalama şirketlerinin çalışma şekli iki türlüdür. Textract gibi şirketler anahtar-değer çiftleri döndürür. Örneğin, bir fatura toplam tutara "Brüt tutar", bir diğeri "Toplam tutar" ve bir Alman faturası "Summe" derse, Textract size bu 3 belge için 3 farklı yapıda veri verir.
Birinde "Brüt tutar" anahtarlı, diğerinde "Toplam tutar" anahtarlı, Alman olanda ise "Summe" anahtarlı bir anahtar-değer çifti alırsınız. Diğer sağlayıcılar, tüm faturalar için çalışan tutarlı veri yapıları tasarlamıştır. Her 3 senaryoda da, çıktı dosyasında kullandıkları anahtar olan "Toplam tutar"ı alırsınız. Bu, birçok farklı yapılandırılmış veri formatıyla uğraşmanız gerekmediği için analitiği ve işlemeyi kolaylaştırır.
3. Yanlış pozitif ve manuel veri çıkarma oranlarını sorun
Ardından, şirketinizin aldığı faturalardaki gerçek oranları görmek için bir Kavram Kanıtlama (PoC) projesi yürütün.
Yanlış pozitifler, otomatik-işlenen ancak veri çıkarmada hatalar olan faturalardır. Bunların tespiti zordur ve operasyonları aksatabilir. Örneğin, ödeme tutarlarının yanlış çıkarılması sorunlu olur. Bunu en aza indirmek mutlak odak noktası olmalıdır.
Manuel veri çıkarma, otomatik veri çıkarma sisteminin sonucuna güveninin sınırlı olduğu durumlarda gereklidir. Bu, farklı bir fatura formatı, düşük görüntü kalitesi veya tedarikçi kaynaklı bir baskı hatasından kaynaklanabilir. Bunu da en aza indirmek önemlidir, ancak yanlış pozitifler ile manuel veri çıkarma arasında bir denge vardır. Daha fazla manuel veri çıkarmaya sahip olmak, yanlış pozitiflere sahip olmaya tercih edilebilir.
Bu alanda gördüğümüz ilk niceliksel kıyaslama budur ve kendi kıyaslamamızı hazırlamak için benzer bir metodolojiyi izleyeceğiz.
4. Potansiyel otomasyon oranını ölçmek için bir PoC'den yararlanın
Bu, belgelerden yakalamayı beklediğiniz alan sayısına bağlıdır. Satınalma siparişi kimliği, satıcı adı vb. gibi kalemleri içeren tipik bir ~10 alan seti, ERP'ye veri girişi ve ödemeleri mümkün kılabilir.
En iyi uygulama sağlayıcıları, bu ~10 alanın tamamını neredeyse hatasız bir şekilde, zamanın ~%80'inde çıkararak ~%80 STP (doğrudan işleme) elde ederler. Zaman hatalar olsa da, en büyük ödemeleri manuel olarak kontrol etmek, önemli yanlış ödemelerin ağdan sızmasını önleyebilir.
5. Tedarikçi tarafından sunulan gelişmiş işleme seçeneklerini sorun
Çıkarma, veri toplamanın ilk adımıdır; çoğu durumda veri işleme ile takip edilmelidir. Örneğin, faturaların KDV uyumluluğu açısından kontrol edilmesi gerekir (örneğin, KDV'siz yurt içi faturaların KDV'nin neden hariç tutulduğunu açıklaması gerekir) ve bunun yapılmaması, ülkeye bağlı olarak şirket için önemli para cezalarına yol açabilir.
6. Çözümün yeni faturaları nasıl öğrendiğini sorun
En iyi çözümler, ekibinizin çözüme rehberlik etmesine olanak tanıyan bir arayüze sahiptir. Şirket çalışanınız anahtar-değer çiftlerini seçerken, fatura yakalama çözümü bunu not eder ve böylece bir sonraki benzer fatura hakkında daha emin olabilir.
7. Manuel veri giriş çözümlerinin kullanım kolaylığını değerlendirin
Bu çözüm, şirketinizin arka ofis personeli tarafından, otomatik olarak güvenle işlenemeyen faturaları manuel olarak işlerken kullanılacaktır.
Bunun ötesinde, en iyi satın alma uygulaması soruları anlamlıdır. Örneğin:
- Çözümleri ne kadar yaygın olarak benimsenmiştir? Fortune 500 müşterileri var mı?
- Müşterileri çözümlerinden ve desteklerinden memnun mu? Halihazırda çözümlerini kullanan bir şirketten bir tanıdığa sormak iyi olabilir. Fatura otomasyonu, bir şirketin pazarlamasını veya satışını iyileştirecek bir çözüm olmadığından, rakipler bile birbirleriyle fatura otomasyonu çözümleri hakkındaki görüşlerini paylaşabilirler.
- Çözümü şirketinizin sistemlerine (örneğin, ERP) entegre etme seçenekleri nelerdir? BT departmanı entegrasyon yaklaşımını onaylıyor mu?
- Toplam Sahip Olma Maliyetleri (TCO) nedir? Farklı çözümler farklı fiyatlandırma birimleri kullanır (örneğin, sayfa başına fiyat veya belge başına fiyat), bu da karşılaştırmayı zorlaştırır. Ancak, arşivinizden bir örnek kullanarak maliyet hakkında bir tahminde bulunabilirsiniz.
Daha fazla okuma
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Fatura OCR Kıyaslaması: LLM'ler ve OCR'ların Çıkarma Doğruluğu}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Erişim tarihi: 22 Ocak 2026}
}

Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.