Büyük Dil Modellerinin Geleceği
Büyük dil modellerinin geleceğini büyük dil modellerine bakarak, kendi kendine eğitim, olgu kontrolü ve seyrek uzmanlık gibi umut verici yaklaşımları inceleyerek LLM'lerin sınırlamalarını gidermeyi hedefleyin.
LLM'lerin başarı oranı karşılaştırması
Claude Sonnet 4.6, 0.748 genel puanla karşılaştırmada birinci oldu; temel ve düşünme varyantları üç ondalık basamağa kadar birbirine eşit. Claude Opus 4.8 (0.702), Opus 4.6 temel (0.706) ve Opus 4.6 düşünme (0.729) onu takip ederek Anthropic'e ilk beş sırayı kazandırdı. Anthropic dışındaki ilk model, 0.625 puanla düşünen Gemini 3.5 Flash oldu. GPT varyantları 0.57 ile 0.60 arasında kümelendi; daha güçlü arka uç puanları ön uç istikrarsızlığıyla dengelendi. Karşılaştırma makalemizde daha fazlasını görün.
LLM Karşılaştırma Metodolojisi
Önde gelen büyük dil modellerini 10 yazılım geliştirme görevinde, ajan tabanlı bir CLI koşum takımı kullanarak karşılaştırdık. Her model görev başına 3 kez çalıştırıldı (model başına 30 örnek, iterasyon başına 270 doğrulama hücresi) ve puanların dengelenmesi ile hücre başına varyansın ölçülmesi amaçlandı. Tüm modellere aynı koşullarda, aynı koşum takımı, aynı görev talimatları ve aynı donanım ortamıyla OpenRouter üzerinden erişildi.
Test edilen modeller
Karşılaştırma, Haziran 2026 itibarıyla API aracılığıyla kullanılabilen modelleri kapsamaktadır. Aşağıda listelenen tüm varyantlar bağımsız olarak test edilmiştir:
- Claude Sonnet 4.6 (temel ve düşünme)
- Claude Opus 4.8
- Claude Opus 4.6 (temel ve düşünme)
- Claude Opus 4.7
- Gemini 3.5 Flash (temel ve düşünme)
- GPT 5.5 (düşünme)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (temel ve düşünme)
- GLM 5.1 (temel ve düşünme)
- Deepseek V4 Pro (temel ve düşünme)
Test ortamı
Her ajan ve görev temiz bir ortamda başlar. Görev talimatları bir TASK.md dosyası olarak sağlanır. 20 dakikalık bir kalp atışı izleyicisi her çalışmayı denetler. Çıkış kodları, yürütme süresi, arka uç ve ön uç dosya oluşturma ve girdi, çıktı ve önbellek kategorilerinde gerçek zamanlı token kullanımı kaydedilir.
Görevler, rezervasyon sistemlerinden etkileşimli gösterge panellerine kadar çeşitlilik gösterir. Tümü, çok dosyalı proje yönetimi ve işlevsel bir tam yığın teslimi gerektirir.
Puanlama
Arka uç doğrulaması: Oluşturulan projeler izole ortamlarda dağıtılır ve mutlu yol senaryolarını, hata işlemeyi (400/403/409) ve veri tutarlılığını kapsayan kanonik bir YAML sözleşmesine göre test edilir. İki mod kullanılır:
- Uyarlamalı mod, rota adları belirtimden farklı olduğunda bile işlevselliği doğrular
- Katı mod, tam sözleşme uyumluluğu (rotalar, durum kodları, yanıt alanları) gerektirir
Hücre başına arka uç puanı: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
Kullanıcı arayüzü doğrulaması: Tarayıcı otomasyonu, ön kontrol, görüntüleme, giriş gönderimi ve giriş sonrası davranış dahil gerçek kullanıcı akışlarını simüle eder. Sekiz adım iki gruba ayrılır:
- Altyapı adımları (arka uç ön kontrolü, ön uç görüntüleme, giriş formu görünürlüğü, giriş gönderimi, giriş 2xx, çalışma zamanı hatası yok)
- Davranış adımları (giriş sonrası yetkilendirme sinyali, giriş sonrası davranış sinyali)
Hücre başına kullanıcı arayüzü puanı: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
Engellenen davranış adımları, davranış paydasından çıkarılır, böylece uygulama yüklenemediğinde hücre çifte cezalandırılmaz.
Nihai puan: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
Arka uç daha yüksek ağırlıklandırılmıştır, çünkü API düzeyindeki mantık hataları genellikle ön uç başarısını geçersiz kılar.
Maliyet ölçümü
Hücre başına maliyet, LLM API yanıtından çıkarılan token kullanımı üzerinden hesaplanır. Toplam girdi token'larından önbelleğe alınan girdi token'ları çıkarılarak etkin girdi (yalnızca yeni işlenen token'lar) elde edilir. Çıktı token'ları hiçbir zaman önbelleğe alınmaz ve değişmeden kalır. Token başına fiyatlar, test sırasında geçerli olan LLM Fiyatlandırması kaynağından alınır.
Sınırlamalar
- Görev kapsamı: Tüm 10 görev, tam yığın web uygulaması oluşturma üzerinedir. Karşılaştırma, salt muhakeme görevlerini, bilimsel problem çözmeyi, özetlemeyi veya alana özgü iş yüklerini (hukuk, tıp, finans) kapsamaz. Puanlar, özellikle ajanik kodlama yeteneğini yansıtır.
- API erişimi yalnızca: Tüm modeller API üzerinden test edilmiştir. Aynı modellerin yerel veya kurum içi dağıtımları, niceleme, donanım ve çıkarım yapılandırmasına bağlı olarak farklı sonuçlar üretebilir.
- Zamanın anlık görüntüsü: Model sürümleri değişir. Sonuçlar, test sırasında etkin olan API sürümünü yansıtır. Sağlayıcıdan bildirimsiz bir güncelleme, puanları her iki yönde değiştirebilir.
- Araç çağrı stili: Modeller, dosya yazma ve düzenlemeyi nasıl yapılandırdıklarına göre farklılık gösterir (örneğin, OpenAI’ın
apply_patchtüm dosya farkını tek bir çağrıda birleştirir; Anthropic modelleri birden çok çağrıda yazıp yeniden düzenler). Araç çağrı sayısı, kalite için doğrudan bir gösterge değildir. - Tek koşum takımı: Tüm testler, ajan koşum takımı olarak Opencode kullanılarak yapılmıştır. Farklı bir koşum takımı, özellikle varsayılan davranışı belirli araç kullanım kalıplarına göre ayarlanmış modeller için farklı göreceli sıralamalar üretebilir.
Büyük dil modellerinin gelecekteki eğilimleri
1- Canlı Veri ile Gerçek Zamanlı Olgu Kontrolü
LLM'ler, yalnızca eğitim verilerine güvenmek yerine konuşmalar sırasında harici kaynaklara erişir. Model, harici veritabanlarını sorgular, güncel bilgileri alır ve atıflar sağlar.
Sınırlama: Hâlâ hata yapar. Atıflar doğruluğu garanti etmez; modeller bazen kaynakları yanlış gösterir veya atıf yapılan içeriği yanlış yorumlar.
Microsoft Copilot: GPT-5.4 Düşünme ile canlı internet verilerini entegre ederek, farklı görev türleri için uyarlanmış “Hızlı Yanıt” ve “Daha Derin Düşün” modlarını sunar.1 Araştırmacı ajan, ilk araştırma için GPT'yi, teslimden önce doğruluk ve atıf kalitesi için çıktıları inceleyen Anthropic’in Claude modelini birleştirerek bağımsız sistemlere kıyasla DRACO derin araştırma karşılaştırmasında %13,8 iyileştirme sağlar.2
- ChatGPT: Son olaylar sorulduğunda web'de arama yapar. Yanıtlarda kaynakları belirtir.
- Perplexity: Özellikle atıflı arama içinşa edilmiştir. Her cevaba kaynak bağlantıları ekler.
2- Sentetik eğitim verisi
Modeller, insan tarafından etiketlenmiş verilere ihtiyaç duymak yerine kendi eğitim veri kümelerini oluşturur.
Google’ın kendini geliştiren modeli (2023 araştırması):
- Model sorular oluşturur
- Yanıtları düzenler
- Oluşturulan veri üzerinde kendini ince ayarlar
Performans iyileşti: GSM8K matematik problemlerinde %74,2’den %82,1’e, DROP okuduğunu anlama testinde %78,2’den %83,0’a yükseldi.
OpenAI, Anthropic ve Google artık insan etiketli veri kümelerini tamamlamak için sentetik veri kullanıyor. Bu, veri etiketleme maliyetlerini düşürür ancak yeni önyargı riskleri getirir; modeller kendi hatalarını güçlendirebilir.
Kaynak: “Large Language Models Can Self-Improve”
Mart 2026 anketi, yapay zeka araştırmacılarının %76’sının hesaplama ve veri ölçeklendirmeden elde edilen kazanımların durgunlaştığını, büyük laboratuvarların devasa yatırımlara rağmen azalan geri dönüşler bildirdiğini ortaya koydu. Bulgu, LLM yeteneğindeki bir sonraki sıçramanın, mevcut yaklaşımları daha fazla ölçeklendirmekten ziyade, gelişmiş eğitim verimliliği, seyrek mimariler veya akıl yürütme iyileştirmeleri gibi mimari yeniliklerden gelme olasılığının daha yüksek olduğunu göstermektedir.3
3- Seyrek Uzman Modeller (Uzman Karması)
Her girdi için tüm sinir ağını etkinleştirmek yerine, göreve bağlı olarak parametrelerin yalnızca ilgili bir alt kümesi etkinleştirilir. Model, girdiyi ağ içindeki uzmanlaşmış “uzmanlara” yönlendirir. Sorguyu yalnızca etkinleştirilen uzmanlar işler.
Gerçek hayattan örnekler:
- Llama 4 Scout: Toplam 109B parametre, token başına 17B etkin. Uzman Karması (MoE) mimarisi, tek bir H100 GPU üzerinde 10M token bağlam penceresi sunar.
- Mistral Devstral 2: Yazılım mühendisliği görevleri için özel olarak üretilmiştir. 123B parametre, 256K token bağlam penceresi. SWE-bench Verified'da %72,2 elde ederek onu lider açık ağırlıklı kodlama modeli haline getirmiştir. Daha küçük bir varyant olan Devstral Small 2 (24B parametre), Apache 2.0 lisansı altında tüketici donanımında yerel olarak çalışır.4
- A-CODE-LLM Bench karşılaştırmamızda, DeepSeek V4 Pro’nun hem temel hem de düşünme varyantları genel olarak 0.45’in altında puan aldı; tamamlanma süreleri görev başına 1.700 saniyeyi aştı. Modelin ajanik kodlama yeteneği, güçlü tekil sorgu karşılaştırma performansının gerisinde kalıyor ve bu büyük olasılıkla bu aşamadaki öncü Anthropic ve Google modellerine göre daha düşük araç kullanım olgunluğunu yansıtıyor.
4- Kurumsal İş Akışı Entegrasyonu
LLM'ler, bağımsız araçlar olarak kullanılmak yerine doğrudan iş süreçlerine gömülür.
Gerçek hayattan örnekler:
- Salesforce Agentforce (eski adıyla Einstein Copilot): LLM'leri CRM operasyonlarına entegre eder. Kuruluşun CRM verileri ve metadata'sına dayanarak, Einstein Güven Katmanı aracılığıyla müşteri sorgularını yanıtlar, içerik üretir ve Salesforce içinde eylemler gerçekleştirir.5
- Microsoft 365 Copilot: Word, Excel, PowerPoint ve Outlook'a gömülüdür. Belgeleri taslaklar, elektronik tabloları analiz eder, sunular üretir ve e-posta zincirlerini özetler; kuruluş bağlamında yanıtları temellendirmek için Microsoft Graph üzerinden şirket verilerine başvurur.6 Araştırmacı ajan, ilk araştırmayı GPT'nin yaptığı ve teslimden önce çıktıları Claude’un incelediği çoklu model mimarisi kullanır; bu, tek bir kurumsal üründe rakip yapay zeka sağlayıcılarının ticari olarak doğrulanmış ilk dağıtımıdır.
- Anthropic Claude for Enterprise: Proje tabanlı bellek ayrımı, ekipler arasında iş bağlamlarını ayrı tutar. Claude Opus 4.6, birden çok Claude ajanının daha büyük görevleri paralel iş akışlarına bölmesine, her birinin bir segmenti sahiplenip diğerleriyle eşzamanlı olarak koordine olmasına olanak tanıyan ekip çalışmasını getirdi. Aynı sürüm, Claude’u doğrudan PowerPoint'e yerel bir yan panel (araştırma önizlemesi) olarak entegre etti; bu sayede sunular dosya aktarımı olmadan uygulama içinde oluşturulup düzenlenebilir.7
5- Çok Modlu Yeteneklere Sahip Hibrit LLM'ler
Büyük çok modlu modeller; metin, görüntü ve ses gibi birden çok veri biçimini entegre ederek farklı medya türlerinde içerik anlamalarını ve üretmelerini sağlar.
- A-CODE-LLM Bench karşılaştırmamızda, GPT 5.5 düşünme, 276 saniyelik ortalama tamamlanma süresiyle 0.597 puan aldı ve bu, 0.50 üzerindeki en hızlı model oldu. Mini varyantlar için hücre başına API maliyeti $0.41–$0.45 olup, benzer puan aralığındaki Claude Sonnet 4.6’nın maliyetinin yaklaşık üçte biridir.
- Gemini 2.5 Pro: Bir 1M token bağlam penceresi içinde metin, ses, görüntü, video ve tüm kod depolarını doğal olarak işler. Google AI Studio, Vertex AI ve NotebookLM üzerinden kullanılabilir. API aracılığıyla milyon girdi token'ı başına $1.25 ve milyon çıktı token'ı başına $10 fiyatlandırılır.8
- Llama 4 Scout ve Maverick: Meta’nın açık ağırlıklı modelleri, ayrı modüller olarak eklenmek yerine baştan itibaren birlikte eğitilmiş erken-fusion çok modlu metin ve görüntü token’larını kullanır. Modeller, 200 dilde ön eğitimden geçirilmiş ve aralarında Arapça, İspanyolca, Almanca ve Hintçe’nin de bulunduğu 12 dil için özel ince ayar desteği sağlanmıştır.9
Çok modlu yetenek, öncü modeller arasında standart hale gelmiştir. Geriye kalan zorluk tutarlılıktır: modeller, yaygın görüntü-metin bileşimlerinde iyi performans gösterirken, nadir görsel bağlamlarda, düşük çözünürlüklü girdilerde ve görsel ile metinsel kanıtları birleştirmeyi gerektiren çapraz modlu muhakemede bozulur.
6- Akıl yürütme modelleri
Hemen yanıt üretmek yerine sorunlar üzerinde adım adım düşünen modeller.
Tahminden akıl yürütmeye bu geçiş, aşağıdakileri mümkün kılmak için kritiktir:
- Modellerin görevleri otonom olarak planladığı, yürüttüğü ve uyarladığı ajanik davranış.
- Çıktıların yalnızca makul değil, aynı zamanda adım adım ve mantıksal olarak sağlam olduğu yorumlanabilir yapay zeka.
- Claude Sonnet 4.6: Anthropic’in ajanik kodlama karşılaştırmalarındaki mevcut üretim lideri; AIMultiple’ın A-CODE-LLM Bench karşılaştırmasında 0.748 puan alarak tüm Opus varyantlarının üzerinde yer aldı. Modelin, görev karmaşıklığına göre muhakeme derinliğini manuel mod değiştirme gerektirmeden dinamik olarak belirlediği uyarlanabilir düşünmeyi kullanır. Fiyatlandırma: milyon token başına $3/$15. SWE-bench Verified'da Sonnet 4.6, maliyetinin beşte biri karşılığında Opus 4.7’nin %80,8’ine bir puan yakın olan %79,6’ya ulaşır.
- Claude Opus 4.7: Anthropic’in karmaşık çok adımlı muhakeme ve görme alanındaki amiral gemisi (XBOW görsel keskinlik karşılaştırmasında %98,5, önceki neslin %54,5’ine kıyasla). Fiyatlandırma: milyon token başına $5/$25. AIMultiple karşılaştırmasında Opus 4.7, 0.61 puan alarak Sonnet 4.6 (0.748) ve Opus 4.8’in (0.702) gerisinde kaldı; bunun başlıca nedeni, daha yüksek gecikme süresinin (1.562 saniye/görev ort.) kullanıcı arayüzü puanlarını düşürmesidir. Sonnet ile arasındaki fark, ARC-AGI-2 gibi soyut muhakeme görevlerinde açılır.
- Claude Opus 4.8: Opus 4.7’den sonra yayınlanarak ajanik kodlamadaki 4.7 gerilemesini telafi etti. A-CODE-LLM Bench karşılaştırmasında 0.702 puanla beşinci sırada yer aldı. Temel görevi 34 saniyede tamamlayarak bu görevdeki en hızlı model oldu; yalnızca 6 araç çağrısı kullandı. Fiyatlandırma: karşılaştırma koşullarında hücre başına $2.92 (milyon token başına $15/$75).
7- Alana Özgü İnce Ayar Yapılmış Modeller
Genel amaçlı eğitim yerine belirli sektörler için özel veriler üzerinde eğitilmiş modeller.
Google, Microsoft ve Meta, genel amaçlı tekliflerine ek olarak kurumsal kullanım durumlarını hedefleyen büyük özel alana özgü ve ince ayarlı modeller yayımladı.
Bu özelleşmiş LLM'ler, alana özgü ön eğitim, model hizalama ve denetimli ince ayardan yararlanarak daha az halüsinasyon ve daha yüksek doğruluk sağlayabilir.
Kodlama
GitHub Copilot: Kod depoları üzerinde ince ayar yapılmıştır. Temmuz 2025 itibarıyla 20 milyon geliştirici GitHub Copilot kullanıyor; bu yıllık %400 artış demek ve Fortune 100 şirketlerinin %90’ı bunu kullanıyor. Copilot, kod tamamlar, fonksiyonlar üretir ve hata düzeltmeleri önerir.10
Finans
BloombergGPT: 50 milyar parametreli LLM; Bloomberg finans belgelerinden oluşan 363 milyar token’lık veri kümesi üzerinde eğitilmiş; duygu analizi, adlandırılmış varlık tanıma ve soru yanıtlama dahil finansal NLP karşılaştırmalarında benzer büyüklükteki modellerden daha iyi performans göstermektedir.11
Sağlık hizmeti
Google’ın Med-PaLM 2: Tıbbi veri kümeleri üzerinde ince ayar yapılmış, ABD Tıp Lisanslama Sınavı (USMLE) tarzı sorularda %85+ doğruluğa ulaşmış ve bu karşılaştırmada uzman düzeyinde performans gösteren ilk LLM olmuştur. Google Cloud’un sağlık temel modelleri ailesi MedLM’e güç verir.12
Hukuk
ChatLAW: Özellikle Çin hukuku alanındaki veri kümeleri üzerinde eğitilmiş açık kaynaklı bir dil modeli.13
8- Etik Yapay Zeka ve Önyargı Azaltma
Şirketler, büyük dil modellerinin geliştirilmesi ve dağıtımında etik yapay zeka ve önyargı azaltma konularına giderek daha fazla odaklanmaktadır.
- Anthropic ve OpenAI 2025 ortalarında, birbirlerinin genel modellerini dalkavukluk, ihbarcılık eğilimleri ve kendini koruma davranışları açısından test eden karşılıklı bir hizalama değerlendirmesi gerçekleştirdi. Çalışma, modellerin hezeyanlı inançlar sergileyen simüle kullanıcılardan gelen zararlı kararları onayladığı durumlar da dahil olmak üzere, test edilen tüm modellerde dalkavukluk tespit etti. Anthropic daha sonra bu davranışı yeni modellerde ölçmek için Bloom test çerçevesini geliştirdi.
- Anthropic ayrıca, yalnızca davetiye ile sınırlı bir model olan Claude Mythos Preview'ü (Project Glasswing) yayımladı; bu model, özellikle büyük işletim sistemleri ve web tarayıcılarındaki siber güvenlik açıklarını bulmak ve düzeltmek üzere küçük bir kuruluş grubuna sunuldu. Anthropic, bu modeli genel kullanıma sunmayı planlamadığını belirtti. Bu kontrollü erişim yaklaşımı, risk profilinin kısıtlı dağıtım gerektirdiği yüksek yetenekli özel modellerin dağıtımı için yeni bir çerçeveyi temsil eder.14
- Google DeepMind: “The Ethics of Advanced AI Assistants” başlıklı yayını, yapay zeka ajanlarının gündeme getirdiği etik ve toplumsal soruların ilk sistematik incelemesini sunarak değer hizalaması, manipülasyon riskleri, antropomorfizm, gizlilik ve eşitlik konularını ele aldı. Şirketin Responsible AI değerlendirmesi, 350’den fazla çekişmeli kırmızı takım egzersizini içerdi ve zararlı manipülasyon için yeni bir Kritik Yetenek Seviyesi getirerek bunu siber saldırılar ve KBRN tehditleriyle aynı seviyede sınır düzeyinde bir risk olarak ele aldı.
Büyük dil modellerinin (LLM'ler) sınırlamaları
1- Halüsinasyonlar
Modeller, kulağa makul gelen ancak yanlış bilgiler üretir.
Vectara halüsinasyon sıralaması, sektördeki en yaygın referans alınan temellendirilmiş özetleme karşılaştırmasıdır. Orijinal Vectara veri kümesinde, Google’ın Gemini modelleri sürekli olarak en üst sıralarda yer alır; Gemini Flash varyantları %1’in altında halüsinasyon oranlarına ulaşır. OpenAI’ın GPT ailesi %0,8 ile %2,0 arasında kümelenir.
Vectara, 2025 sonlarında önemli ölçüde daha zor bir karşılaştırma başlattı: 7.700 makale (1.000 yerine), 32K token’a varan daha uzun belgeler ve hukuk, tıp, finans ile teknolojiyi kapsayan içerikler. Yeni veri kümesindeki bulgular, tersine bir örüntüyü ortaya koyuyor: karmaşık görevlerde üstün başarı gösteren muhakeme ve düşünme modelleri, temellendirilmiş özetlemede genellikle daha küçük ve hızlı modellerden daha fazla halüsinasyon üretiyor. Çoğu düşünme sınıfı model, daha zor veri kümesinde %10’un üzerinde halüsinasyon oranı gösterirken, Gemini Flash varyantları gibi daha hafif modeller daha düşük oranları korur.15
Not: Hiçbir tek karşılaştırma, bir model için kesin bir “halüsinasyon oranı” vermez. Sorumlu bir değerlendirme, biri temellendirilmiş bir görevi (Vectara), diğeri açık uçlu bir bilgi görevini ölçen az iki karşılaştırmayı çapraz referans alır ve tam model sürümü ile çağrı koşullarını belirtir.
Tüm modeller halüsinasyon görür. Sıklık, 2021’de yaklaşık %21 iken standart karşılaştırmalarda en iyi performans gösterenler için %5’in altına önemli ölçüde düşmüştür, ancak ortadan kalkmamıştır. Kritik uygulamalar hâlâ insan doğrulaması gerektirir.
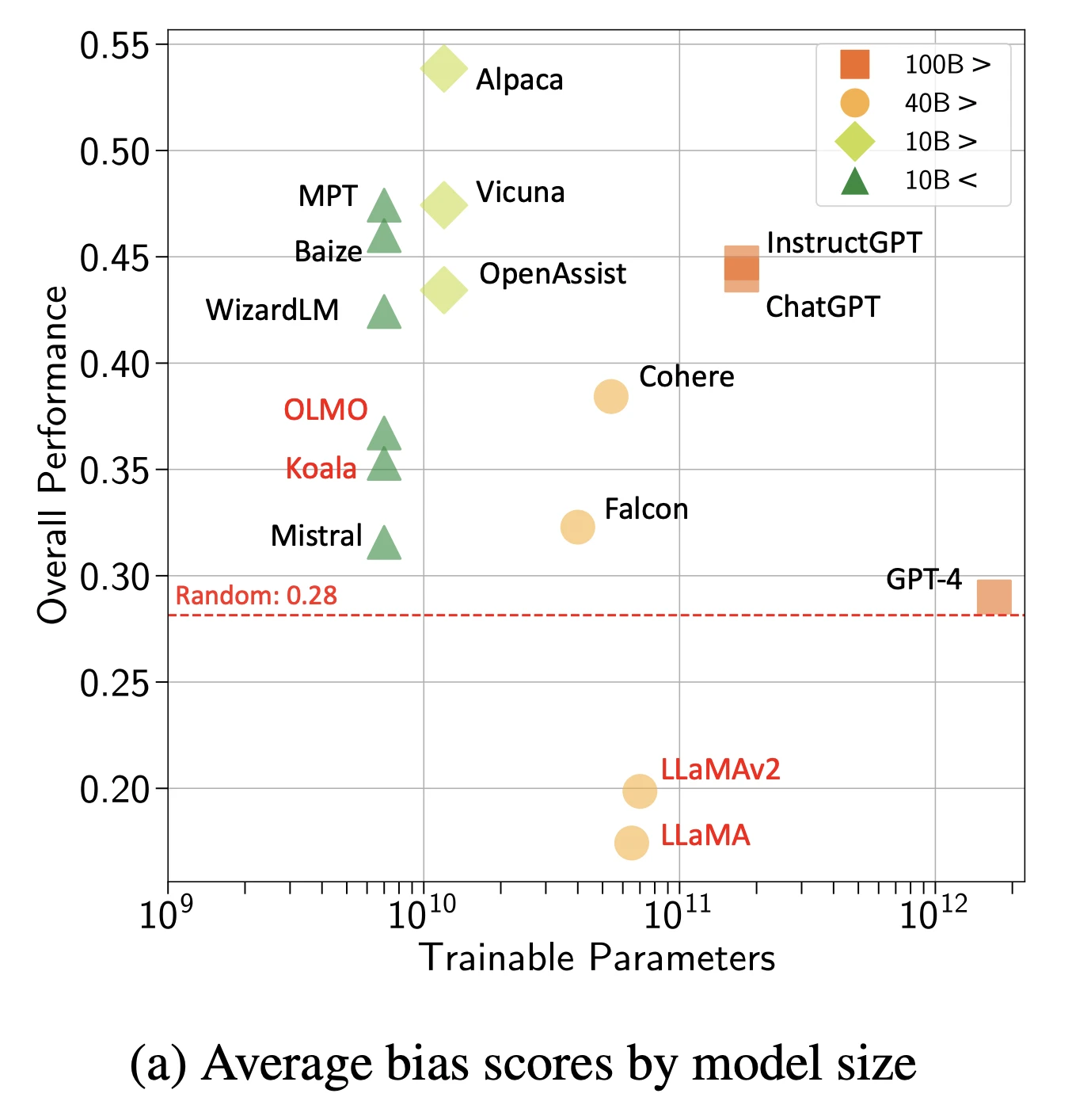
2- Önyargı
Modeller, eğitim verilerindeki toplumsal önyargıları emer ve güçlendirir.
Şekil: Modellere ve boyuta göre genel önyargı puanları
Kaynak: Arxiv16
Gözlemlenen önyargı türleri:
- Meslek önerilerinde cinsiyet önyargısı
- Özgeçmiş tarama simülasyonlarında ırksal önyargı
- Sağlık hizmeti önerilerinde yaş önyargısı
- Eğitim içeriğinde sosyoekonomik önyargı
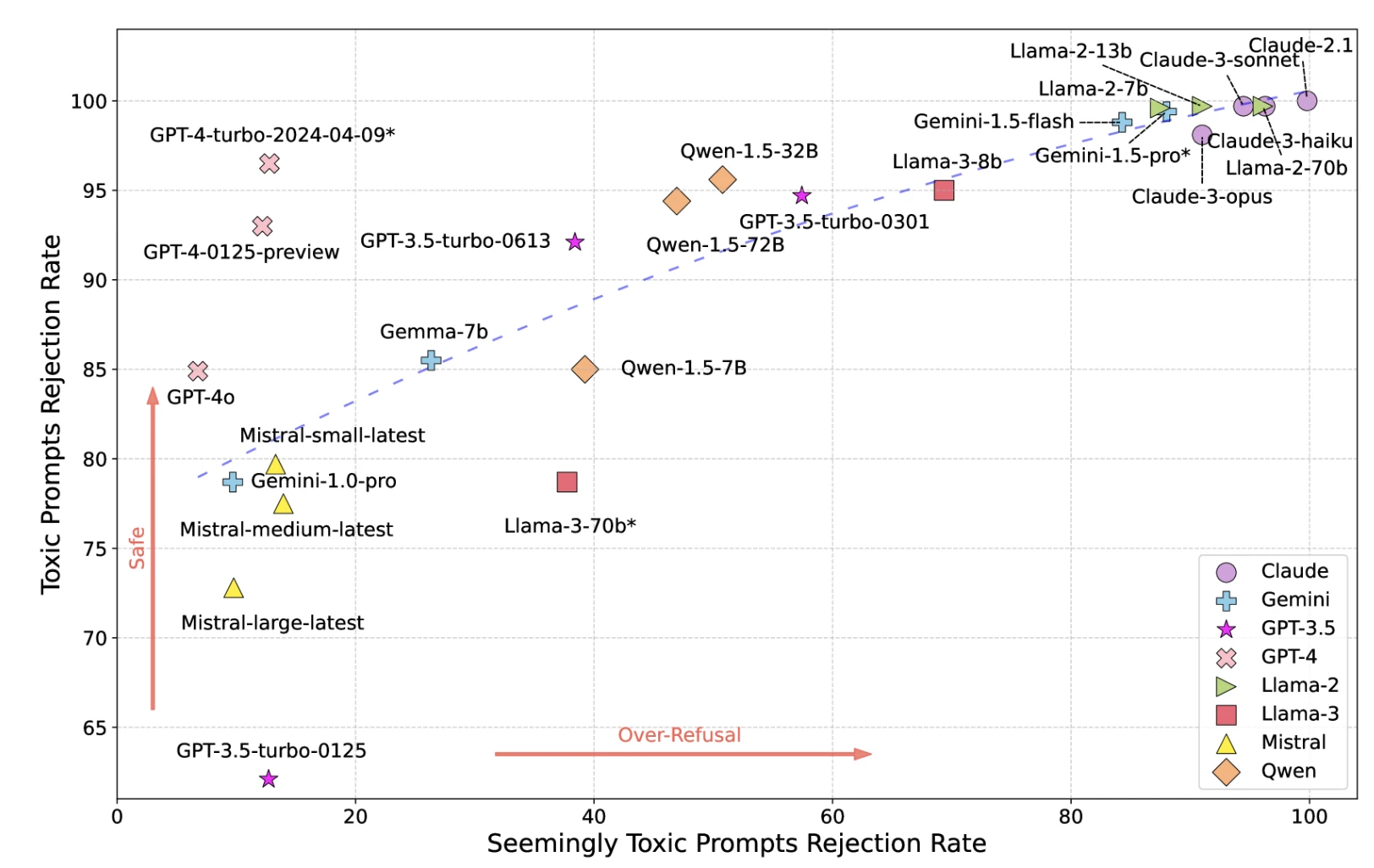
3- Toksisite
Modeller, güvenlik önlemlerine rağmen zararlı, saldırgan veya toksik içerik üretebilir.
Şekil: LLM'lerin toksisite haritası
Kaynak: UCLA, UC Berkeley Araştırmacıları17
*GPT-4-turbo-2024-04-09*, Llama-3-70b* ve Gemini-1.5-pro*, moderatör olarak kullanılmıştır; sonuçlar bu 3 modele göre yanlı olabilir.
Sıkı güvenlik önlemleri toksisiteyi azaltır ancak yanlış pozitifleri (zararsız istekleri reddetme) artırır. Gevşek önlemler toksisitenin geçmesine izin verir.
4- Bağlam Penceresi Sınırlamaları
Her modelin sabit bir bellek kapasitesi vardır — tek bir oturumda işleyebileceği token sayısı. Bu sınır aşıldığında, model ya daha önceki içeriği keser ya da isteği reddeder. Modeller arasındaki pratik fark, gerçek iş yükleri için önem taşıyacak kadar geniştir.
En güncel bağlam pencereleri:
- Llama 4 Scout (Meta): 10M token (~7,5M kelime) — önde gelen modeller arasında üretimde doğrulanmış en büyük bağlam penceresi.18 Pratikte bu, tüm kod tabanlarını, hukuk arşivlerini veya çok günlük konuşma geçmişlerini parçalama olmaksızın yüklemek anlamına gelir.
- Gemini 2.5 Pro: 1.048.576 token (~780.000 kelime), aynı pencere içinde metin, ses, görüntü ve video boyunca yerel çok modlu girdi ile. Hatırlama, 530.000 token’a kadar %100 ve tam 1 milyon token sınırında %99,7 düzeyindedir.
- Claude Sonnet 4.6: 1M token (~750.000 kelime), standart fiyatlandırmayla, beta başlıkları veya özel yapılandırma olmadan kullanılabilir.19
- GPT-5.5: 1M token bağlam penceresi API düzeyinde mevcuttur.20
Büyük bir bağlam penceresi, otomatik olarak pencere boyunca daha iyi performans anlamına gelmez. Çoğu modelde çok uzun bağlamların ortasında hatırlama bozulur ve maliyet girdi uzunluğuyla ölçeklenir — 1M token işlemek, aynı modelde 10K token işlemekten önemli ölçüde daha pahalıdır. Çoğu üretim iş yükü için pratik soru, hangi modelin en büyük pencereye sahip olduğu değil, hangi modelin kullanım durumunuzun gerçekten gerektirdiği bağlam uzunluklarında güvenilir şekilde bilgi çektiğidir.
5- Statik Bilgi Kesme Tarihi
Modeller, belirli bir kesme tarihine sahip önceden eğitilmiş bilgilere dayanır. Harici kaynaklara bağlanmadıkça eğitim sonrası bilgilere erişemezler.
Sorunlar:
- Güncel olaylar hakkında güncel olmayan bilgiler
- Yeni gelişmelerle başa çıkamama
- Dinamik alanlarda (teknoloji, finans, tıp) daha az ilgililik
Çözüm: Web araması entegrasyonu. ChatGPT, Claude ve Perplexity artık gerçek zamanlı arama sunar. Ancak arama, halüsinasyonları ortadan kaldırmaz; modeller bazen arama sonuçlarını yanlış yorumlar.
Başlıca LLM Platformları
GPT-5.5
OpenAI’ın mevcut amiral gemisi, 23 Nisan 2026’da piyasaya sürüldü. Yapılandırılabilir muhakeme çabası etrafında inşa edilmiştir; geliştiriciler istek başına düşünme derinliğini belirler (hiçten xtreme’e kadar), böylece basit sorgular zor problemler için ayrılmış hesaplamayı yakmaz. Model, geniş sistemler üzerinde bağlamı tutması ve yürütme sırasında kendi çalışmasını kontrol etmesi gereken ajanik kodlama, bilgisayar kullanımı ve uzun vadeli görevlerde üstün başarı gösterir.21
Kimler kullanıyor: Geliştiriciler, kuruluşlar ve içerik oluşturucular. LLM'ler arasındaki en büyük kullanıcı tabanı.
Sınırlamalar: Milyon token başına $5/$30 — bu listedeki en yüksek taban fiyat. Hâlâ halüsinasyon görür. Eğitim kesme tarihinden sonraki her şey için web araması entegrasyonu gerektirir.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6, AIMultiple’ın A-CODE-LLM Bench karşılaştırmasında 0.748 genel puanla liderdir; maliyeti hücre başına $1.26–$1.33 aralığında olup test edilen tüm Opus varyantlarının üzerindedir. Claude Opus 4.8, Opus 4.7’nin gerilemesinden (0.61) $2.92 hücre maliyetiyle toparlanarak 0.702 ile onu takip eder. Opus 4.7, karmaşık çok adımlı muhakeme ve görme görevlerinde en iyi performansı sergilemeye devam eder (XBOW görsel keskinlik karşılaştırmasında %98,5), ancak ajanik iş akışlarındaki 1.562 saniyelik ortalama tamamlanma süresi toplam maliyeti hücre başına $3.08’e çıkararak karşılaştırmadaki en pahalı model olmasına yol açar.
Hem Sonnet 4.6 hem de Opus varyantları uyarlanabilir düşünmeyi kullanır: model, manuel mod değişimi gerektirmeden görev karmaşıklığına göre muhakeme derinliğini belirler. Sonnet 4.6, Anthropic modelleri arasında görev başına en az araç çağrısını yaparak (51 temel, 48 düşünme), Opus varyantlarından (56–70 araç çağrısı) daha az iterasyonla en yüksek karşılaştırma puanına ulaştı. Anthropic’in üretim hattında mevcut olan ajan ekipleri, birden çok Claude örneğinin bir görevi gerçek zamanlı olarak koordine edilen paralel iş akışlarına bölmesine olanak tanır.
Kimler kullanıyor: Ajanik kodlama, araştırma iş akışları veya çoklu ajan boru hatları çalıştıran geliştiriciler ve kuruluşlar. Maliyet verimliliğini önceliklendiren ekipler Sonnet 4.6’yı; görme yoğunluklu veya karmaşık muhakeme iş yükleri olan ekipler Opus 4.7’yi kullanır.
Sınırlamalar: Genişletilmiş düşünme daha yavaş ve token başına daha pahalıdır. Sonnet ile arasındaki performans farkı soyut muhakeme görevlerinde (ARC-AGI-2) açılır. Opus 4.8, milyon token başına $15/$75 olarak fiyatlandırılır.
Gemini 3.5 Flash
Gemini 3.5 Flash düşünme, 0.625 puanla Anthropic dışındaki en yüksek sonucu elde etti; maliyeti hücre başına $1.30 ve ortalama tamamlanma süresi 390 saniyedir. Temel varyant, daha yüksek bir maliyetle ($0.56/temel hücre) düşünmeden daha düşük puan aldı; bu, referans çözümü ~50 satır olan bir görev için 131 satırın üzerine yazılmasından kaynaklandı.
Llama 4 Scout
Meta’nın açık ağırlıklı MoE modeli. 109B toplam parametre, token başına 17B etkin; int4 niceleme ile tek bir NVIDIA H100 GPU üzerinde çalışır. Pratik sonucu, 10M token bağlam penceresine bir veri merkezi sözleşmesi olmadan erişilebilmesidir.22 Erken-fusion çok modluluk, metin ve görselin çıktı aşamasında birleştirilmek yerine ilk katmandan itibaren ortaklaşa işlenmesi anlamına gelir. Meta’nın Llama 4 Topluluk Lisansı altında sunulur.
Kimler kullanıyor: Araştırmacılar, yerinde dağıtıma ihtiyaç duyan kuruluşlar, satıcı bağlılığından kaçınan geliştiriciler ve ölçekte maliyetin API fiyatlandırmasını sürdürülemez kıldığı ekipler.
Sınırlamalar: Performans, barındırma yapılandırmasına ve niceleme seçimlerine büyük ölçüde bağlıdır. Altyapı yatırımı ve makine öğrenimi operasyonları kapasitesi gerektirir. Ticari modellere kıyasla daha az üretim cilasına sahiptir.
DeepSeek V4
DeepSeek’in dördüncü nesil modeli önizleme olarak sunulmaktadır. V3’ten kabaca %50 daha büyük, 1 trilyon parametreli MoE mimarisi ve metin, görüntü ile video boyunca çok modlu yetenekler kullanır. Araç Kullanımında Düşünme, modelin harici araçları çağırmadan önce dahili olarak muhakeme yapmasına ve araç çıktılarını kendi mantığına göre doğrulamasına olanak tanır; bu, ajanik iş akışları için temel farklılaştırıcıdır. API girdi fiyatlandırması, milyon token başına $0.27 (önbellek ıskası) ile başlar; bu, GPT-5.5’ten kabaca 18 kat daha ucuzdur.23
SSS'ler
Büyük dil modeli, büyük miktarda veriyi analiz ederek insan benzeri metin üretmek ve anlamak için tasarlanmış bir yapay zeka modelidir.
Bu temel modeller, derin öğrenme tekniklerine dayanır ve genellikle birçok katmana ve çok sayıda parametreye sahip sinir ağları içerir; bu sayede eğitildikleri verilerdeki karmaşık örüntüleri yakalayabilirler.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Büyük Dil Modellerinin Geleceği}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Erişim tarihi: 25 Haziran 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.