En İyi 3 Sentetik Belge Üreticisi Karşılaştırmalı Test Edildi
Sentetik belge üreticileri, büyük, elle etiketlenmiş veri setlerine güvenmeden makine öğrenimi modellerini eğitmek ve değerlendirmek için işaretleme yapılmış, gerçekçi belge görüntüleri oluşturur.
Genalog, DocCreator ve Tonic Textual olmak üzere 3 sentetik belge üreticisini, 2.500'den fazla sentetik belge oluşturarak, gerçekçi düzenlerde, doğru sayısal verilerde ve belge analizi görevleri için eğitim veri setlerindeki etkinliklerini karşılaştırarak test ediyoruz.
Belge oluşturma karşılaştırmalı test sonuçları
Sonuçlar şunları gösteriyor:
- Genalog ve DocCreator, fayda ve sadelik açısından güçlü performans gösterir; Genalog sayısal doğruluk açısından biraz daha iyidir.
- Tonic Textual, görsel düzen gerçekçiliğinde üstündür ancak diğer alanlarda geride kalır, bu da onu gerçekçi belge gerektiren görevler için daha uygun hale getirir.
Metrikler hakkında daha fazla bilgi için karşılaştırmalı test metodolojisini okuyun.
- Fayda, sentetik veri ile eğitilen modellerin gerçek belgeler üzerinde ne kadar iyi performans gösterdiğini ölçer.
- Düzen sadeliği, sentetik belgelerdeki öğelerin mekansal düzeninin gerçeklerle ne kadar iyi eşleştiğini ölçer.
- Sayısal sadelik, sentetik belgelerdeki sayısal değerlerin gerçek verilere benzer olup olmadığını kontrol eder.
Sonuçlar üzerine yorum: Performans farklarını daha iyi anlamak için karşılaştırmalı test, ayrı test seti yerine eğitim seti kullanılarak da gerçekleştirildi. Bu ikincil değerlendirme, modellere eğitim materyali sağlamanın yapılandırılmış ve sayısal olarak doğru çıktılar üretme yeteneklerini iyileştirip iyileştirmeyeceğini belirlemeyi amaçladı.
Sonuçlar, eğitim verisi üzerinde değerlendirildiğinde bile modellerin biraz daha yüksek puanlar aldığını gösteriyor. Bu, sonuçların araçların görevi ne kadar iyi ele aldığını yansıttığını göstermektedir. Orta düzeydeki sonuçlar, muhtemelen OCR kalitesindeki sınırlamalar ve eğitilmiş modelin kapasitesi tarafından etkilenmiştir, karşılaştırmalı test prosedürü tarafından değil.
Genalog
Genalog genel olarak en güçlü performansı gösterdi. Sentetik belgeleri model eğitimi için çok etkiliydi ve gerçekçi düzen öğeleri ile sayısal doğruluk arasında iyi bir denge sağladı. Oluşturulan belgeler, gerçek formların ve fişlerin yapısını ve aralığını yakından yansıttı, bu da onları çeşitli belge analizi görevleri için uygun hale getirdi.
DocCreator
DocCreator da yüksek kaliteli çıktılar üretti. Bu belge üreticisinin belgeleri, Genalog'unkiler kadar eğitim için neredeyse aynı derecede yararlıydı. Düzenler gerçekçiydi ve sentetik belgeler sayıların istatistiksel özelliklerini korudu. DocCreator'ın gücü, çeşitli düzen oluşturma ile bozulma modellerini birleştirmesinde yatar, bu da çıktıları taranmış gerçek dünya belgelerine görsel olarak benzer hale getirir.
Tonic Textual
Tonic Textual'ın sonuçları karışıktı. Bu sentetik belge üreticisi çok temiz ve tutarlı düzenler üretse de, belgeler modelleri eğitmek için daha az etkiliydi. Ayrıca, sentetik sayılar her zaman gerçek verilere istatistiksel olarak benzer değildi. Bu, Tonic Textual'ın, düzen yapısı ve bilgi çıkarma görevleri için tam ölçekli eğitimden ziyade belge görünümüne veya gizliliği koruyan PII değiştirme odaklı görevler için en uygun olduğunu göstermektedir.
March 2026'da Tonic Textual, verimliliği artırmak için varlık bağlantı bileşenini bir LLM-tabanlı modelden BERT-tabanlı bir modele geçirdi.1 Aynı sürüm (v391), Veri Setleri sayfasında gelişmiş filtreleme ve sıralama da ekledi.2
Genel Bakış
Genalog, hem gerçekçi düzenler hem de doğru sayılar sağlayan en iyi dengeli araçtır.
DocCreator, karmaşık ve çeşitli düzenler ve belge bozulması için güçlüdür, küçük sayısal hatalarla.
Tonic Textual, düzen odaklı görevler için idealdir ancak hassas sayısal veri gerektiren görevler için uygun değildir.
Metodoloji Özeti
Değerlendirme metrikleri
Oluşturulan her veri seti, aşağıdaki metrikler kullanılarak orijinal veriye göre puanlandı:
Fayda puanı
(KIE F1 Puanı): 0 ile 1 arasında bir puan, burada daha yüksek daha iyidir. Gerçek test setinde değerlendirildiğinde sentetik veri üzerinde eğitilen LayoutLMv3 modelinin F1 puanı ile tanımlanır. Yüksek bir puan, sentetik verinin gerçek veri için son derece etkili bir alternatif olduğunu gösterir.
Sadelik puanları
Bu metrikler, sentetik belgelerin gerçeklere ne kadar yakın benzediğini ölçer.
- Düzen Sadeliği (EMD Puanı): Toprak Taşıyıcı Mesafesi (dEMD), gerçek ve sentetik belgelerdeki sınırlayıcı kutu merkez noktalarının dağılımı arasındaki farkı ölçer. 0 ile 1 arasında bir değerdir, burada düşük daha iyidir. Düşük bir puan, mekansal düzen öğelerinin iyi korunduğunu gösterir.
- Sayısal Sadelik (K-S Mesafesi): Kolmogorov-Smirnov Mesafesi (DKS), gerçek ve sentetik verilerdeki sayısal değerlerin (örneğin fiyatlar, miktarlar) kümülatif dağılım fonksiyonları (CDF'ler) arasındaki maksimum farkı ölçer. 0 ile 1 arasında değişir, burada düşük daha iyidir. Düşük bir puan, üreticinin sayıların istatistiksel özelliklerini doğru bir şekilde yeniden ürettiği anlamına gelir.
Tüm metrikler hesaplama sırasında normalize edildi.
Veri Setleri
FUNSD: Gürültülü metin, karmaşık ve çeşitli düzenler ve el yazısı notlarla karakterize edilen 199 taranmış formdan oluşan bir koleksiyon. Geçen ay 1.500'den fazla kez indirildi. Bu, bir üreticinin yapılandırılmamış ve kusurlu verileri işleme yeteneğini test eder. 3
- Örneği ikiye böldük: verinin %80'i modeli eğitmek için kullanılırken, kalan %20'si eğitimden sonra test için ayrılmıştır.
- Her araç, her orijinal belge için üç ile altı sentetik belge üretti, bu da toplamda 2.500'den fazla sentetik belge sonucunu verdi.
Görev değerlendirmesi
Faydayı ölçmek için, 22K GitHub yıldızı ve 750K'dan fazla indirmeye sahip popüler bir LayoutLMv3 modeli, her sentetik belge üretici aracı tarafından oluşturulan sentetik veri üzerinde eğitildi. 4
Bu modelin performansı, ardından orijinal veri setlerinden gerçek belgelerin tutulan bir test setinde değerlendirildi. Bu, sentetik verinin gerçek dünya bir görevi için ne kadar yararlı olduğunu doğrudan ölçer.
Sentetik oluşturma araçları
Genalog
Sentetik gürültü ile sentetik belge görüntüleri oluşturmak için Microsoft tarafından geliştirilmiş açık kaynaklı bir Python kütüphanesi. HTML + CSS ile yazılmış metin + düzen şablonlarını alıp WeasyPrint aracılığıyla render ederek ve ardından bozulma efektleri (bulanıklık, kanama, tuz-biber gürültüsü, morfolojik işlemler) uygulayarak çalışır.5
DocCreator
İlişkili gerçek veri ile sentetik belge görüntüleri oluşturmak için çok platformlu, açık kaynaklı bir araç. Belge Görüntü Analizi ve Tanıma (DIAR) araştırmalarında yaygın olarak kullanılmıştır.6 ,7
Tonic Textual
Gerçek dünya belge formatlarında (PDF, Word) sansürleme ve sentezleme için bir çözüm. Yapılandırılmamış belgeleri taradığını, adlandırılmış varlıkları (örneğin PII) tanımladığını, bunları sentetik değerlerle sansürlediğini veya değiştirdiğini ve benzer formatlarda kimliği belirsizleştirilmiş belgeleri çıkardığını iddia eder.
8 Sentetik belge bozulma yöntemleri
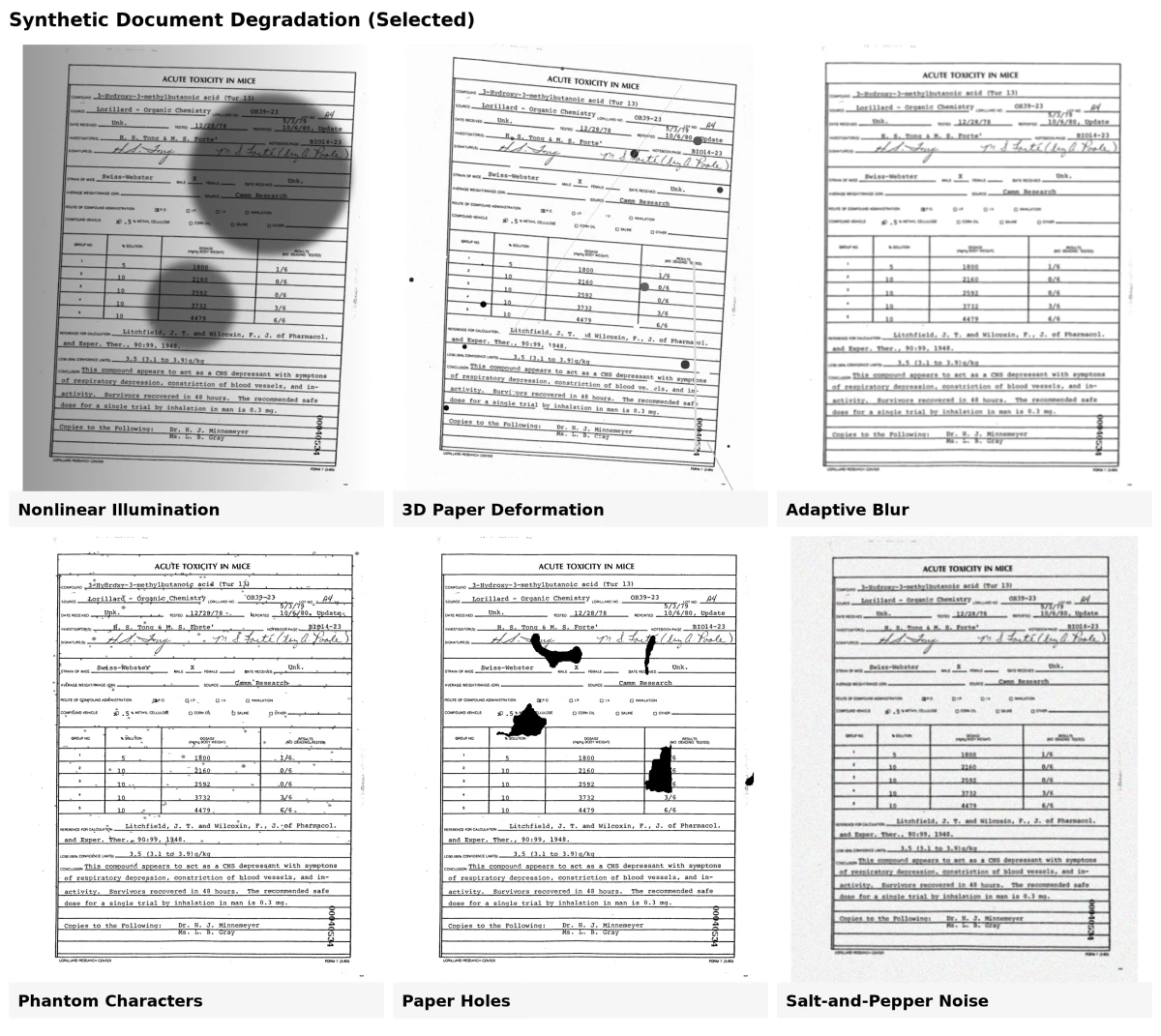
Sentetik belge oluşturma, yapay verilerin gerçek dünya belgelerine benzemesini sağlamak için genellikle gerçekçi kusurlar eklemeyi içerir. Bu kusurlar veya bozulma modelleri, gürültülü, yaşlanmış veya taranmış belgelerde daha iyi performans gösteren modelleri eğitmeye yardımcı olur. Bu araçlar, yaygın belge kusurlarını simüle etmek için birkaç fiziksel ve görsel dönüşüm uygular.8
1. Mürekkep bozulması
Bu model, yaşlanma veya düşük kaliteli baskı nedeniyle oluşan solma, leke veya çizgileri simüle eder. Gerçek mürekkep çürümesini taklit etmek için küçük mürekkep lekeleri ekler veya harflerin kısımlarını kaldırır.
2. Hayalet karakterler
Eski baskı araçları genellikle harflerin etrafında hafif konturlar veya "hayalet" işaretler bırakırdı. Hayalet karakter modeli, bunları basılı karakterler arasına gerçek taramalardan çıkarılan kusurlar ekleyerek yeniden oluşturur.
3. Kağıt delikleri
Farklı şekil ve boyutlardaki delikler, yıpranmış kağıtlarda görülen yırtıkları veya delme işaretlerini taklit ederek belgelere rastgele eklenir.
4. Kanama
Bu etki, mürekkebin sayfanın diğer tarafından sızmasını taklit eder. Mürekkebin kağıt üzerinden kısmen nasıl transfer olduğunu yeniden oluşturmak için bir belgenin ön ve arka görüntülerini kullanır.
5. Uyarlanabilir bulanıklık
Belgeleri taramak veya fotoğraflamak genellikle hafif bulanıklık oluşturur. Bu model, gerçek bulanık örnekleri karşılaştırır ve Gauss filtreleri kullanarak benzer bir bulanıklık uygular, sonucu ince ve gerçekçi tutar.
6. 3D kağıt deformasyonu
Belgeler tarandığında veya fotoğraflandığında bükülebilir, katlanabilir veya kıvrılabilir. Gerçek kağıtlardan 3D ağlar kullanarak bu model, bu şekilleri ve aydınlatma efektlerini yeniden oluşturur, kamera tabanlı belge analizi için modelleri eğitmeye yardımcı olur.
7. Doğrusal olmayan aydınlatma
Tarama sırasında eşitsiz aydınlatma, bir belgenin bir tarafının daha koyu görünmesine neden olabilir. Bu model, simüle edilmiş ışık açılarına ve sayfa eğriliğine göre parlaklığı ayarlayarak kötü aydınlatmanın etkisini yeniden üretir.
8. Tuz-biber gürültüsü
Toz, kağıt dokusu veya tarama sensör gürültüsünü simüle etmek için rastgele siyah ve beyaz pikseller ekler. Bu "tuz-biber" efekti, yaşlanmış veya düşük kaliteli dijital taramaların taneli görünümünü oluşturmaya yardımcı olur.
Düzen analizi zorlukları için çözüm olarak sentetik belge oluşturma
Düzen analizi zorluğu
Belgelerin yapısını anlamak, metni okumaktan daha zordur. OCR araçları kelimeleri çıkarabilir, ancak başlıklar, tablolar veya figürler gibi her bloğun rolünü açıklamazlar.
Bu zorlukla başa çıkmak için yöntemler geliştirilmiştir:
Düzen analizi için Erken yöntemler kural tabanlıydı. Sayfaları bloklara ayırmak için geometrik kurallara ve doku analizine güvendiler. Yararlı olsalar da, bu yaklaşımlar ağır manuel ayar gerektiriyordu ve iyi genelleştirilemiyordu.
Veriden öğrenerek bunu iyileştiren Destek Vektör Makineleri (SVM'ler) ve Gauss Karışım Modelleri (GMM'ler) gibi Makine öğrenimi yaklaşımları.9 Ancak, hala el yapımı özelliklere bağımlıydılar ve gerçek dünya belgelerinin çeşitliliğiyle mücadele ettiler.
Derin öğrenme alanı dönüştürdü. Evrişimli sinir ağları (CNN'ler), düzen tanımayı nesne tespiti gibi işlemeyi mümkün kıldı; tabloları, figürleri veya formülleri doğal görüntülerdeki nesneleri tespit eden modellerle aynı şekilde tanımladı.10 Bazı modeller daha doğru sonuçlar için hem metin hem de görüntü özelliklerini birleştirir.
Derin öğrenme zorluğu: eğitmek için büyük, etiketlenmiş veri setleri gerektirir.
Çözüm olarak sentetik veri: Sentetik belge oluşturma süreci, manuel etiketleme maliyeti olmadan işaretleme yapılmış eğitim verisi oluşturmak için ölçeklenebilir bir yol sunar.
Üretken modeller şimdi daha gelişmiş olasılıklar getiriyor. Varyasyonel otomatik kodlayıcılar (VAE'ler), dikkat tabanlı modeller ve GAN'lar, belgelerin yapısal kalıplarını öğrenebilir ve gerçekçi yeni düzenler üretebilir.11
Sentetik Belge Üreticileri Arasındaki Temel Farklar
Karşılaştırmalı test edilen üç sentetik belge üreticisi, odak, çıktı kalitesi ve kullanılabilirlik açısından farklılık gösterir:
- Genalog: Hem gerçekçi düzenler hem de sayısal doğruluk için en iyi dengelenmiş. HTML/CSS şablonları ve bozulma modelleri ile Python tabanlı iş akışı, onu çeşitli belge analizi görevlerinde makine öğrenimi modellerini eğitmek için ideal hale getirir.
- DocCreator: Görsel olarak karmaşık ve bozulmuş belgeler oluşturmada güçlü, düzen çeşitliliğini korur. Sayısal olarak Genalog'dan biraz daha az doğru ancak gerçekçi taranmış belge simülasyonu gerektiren görevler için etkilidir.
- Tonic Textual: Temiz, görsel olarak tutarlı düzenler ve gizliliği koruyan veri sentezinde üstündür. Sayısal doğruluk veya tam eğitim veri setleri için daha az uygun, bu da onu düzen odaklı görevler veya PII değiştirme için daha iyi hale getirir.
Bu farklılıklar, temel yaklaşımlarını yansıtır: Genalog gerçekçilik ve veri sadeliğini dengeler, DocCreator düzen çeşitliliği ve belge bozulmasına vurgu yapar ve Tonic Textual görünüm ve gizliliği önceliklendirir. Bu, kullanıcıların önceliğin eğitim etkinliği, düzen gerçekçiliği veya veri kimliği belirsizleştirme olup olmadığına göre doğru aracı seçmesine yardımcı olur.
Diğer yaygın olarak kullanılan sentetik belge üreticileri
YData SDK: PDF, DOCX veya HTML formatlarında yüksek kaliteli sentetik belgeler üretebilen sentetik bir belge Üreticisi sunar, genellikle gizlilik uyumluluk engellerini aşmak için kullanılır.12
DoGe: Belge AI eğitimi için anlamlı metin, başlıklar ve tablolar içeren gerçekçi belge taramalarını sentezlemek için özel olarak tasarlanmış açık kaynaklı bir araç.13
DocXPand: ISO standartlarına dayalı kimlik belgeleri (pasaportlar, kimlik kartları) oluşturmak için özelleşmiştir, şablonları sahte bilgilerle ve AI tarafından oluşturulan yüzlerle doldurur.14
Daha fazla okuma
- Sentetik Veri Oluşturma Karşılaştırmalı Testi ve En İyi Uygulamalar
- En İyi 25 Sentetik Veri Kullanım Alanı
- Sentetik Kullanıcılar Açıklandı: En İyi 7 AI Kullanıcı Araştırması Aracı
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{En İyi 3 Sentetik Belge Üreticisi Karşılaştırmalı Test Edildi}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Erişim tarihi: 18 Mart 2026}
}



Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.