En İyi Görüntü Tanıma Araçları Karşılaştırması
Amazon Rekognition, Google Cloud Vision ve Microsoft Azure AI Vision varsayılan API yapılandırmalarını 100 görüntü üzerinde 5 nesne sınıfında karşılaştırdık ve fiyatlandırma ile özellik kapsamlarını kıyasladık.
Görüntü tanıma araçları kıyaslama sonuçları
IoU=0.5 için performans genel görünümü
Üç görüntü tanıma platformu için performans metrikleri, 0.5 Kesme Oranı (IoU) eşiğinde değerlendirildi ve mAP, F1 skoru, geri çağırma ve hassasiyet değerleri karşılaştırıldı.
mAP, nesne tespit görevleri için dikkate alınması gereken birincil değerlendirme metriğidir, çünkü farklı güven eşikleri ve nesne sınıfları arasında tespit kalitesinin kapsamlı bir ölçüsünü sunar.
Kıyaslama metodolojimiz hakkında daha fazla bilgi edinebilirsiniz.
IoU=0.5 için Sınıf Başına Ortalama Hassasiyet (AP)
Her üç hizmet de kişileri güvenilir şekilde tespit ederken, koruyucu ekipmanlarda hassasiyet kaybı yaşar ve en keskin düşüş baretlerde görülür.
Amazon ve Google eldiven ve şapka tespitinde düşük hassasiyet gösterirken, Microsoft Azure AI Vision her iki kategoride de %0 hassasiyete ulaşır. Azure AI Vision, küçük (görüntünün %5'inden az) veya birbirine yakın düzenlenmiş nesneleri tespit etmez; bu durum, eldiven ve şapka tespitindeki gözlenen düşük hassasiyete katkıda bulunabilir.1
Hiçbir hizmet maskeleri başarıyla tespit edemez (%0 hassasiyet), bu da özel etiketleme olmaksızın varsayılan ayarlarda kullanıldıklarında nesne tanıma yeteneklerinde kritik bir boşluğa işaret eder.
Görüntü tanımanın sınırlamaları hakkında daha fazla bilgi edinebilirsiniz.
Farklı IoU eşiklerinde mAP [0.5:0.05:0.95]
IoU eşikleri 0.5'ten 0.95'e sıkılaştıkça, mAP her üç hizmet için de düşer, ancak farklı oranlarda. Amazon Rekognition aralık boyunca en iyi performansı korur ve diğer iki hizmete göre daha sıkı sınırlayıcı kutu hizalamasına sahip olduğunu düşündürür.
Performans farklılıklarını etkileyebilecek potansiyel faktörler
Model eğitim odağı ve ürün kapsamı
- Amazon Rekognition, KKD ile ilgili özel yetenekler içerir; bu da baret ve eldiven gibi nesneler için daha iyi eğitim kapsamı ve özellik temsilleri sağlar.
- Google Cloud Vision ve Azure AI Vision, genel görüntü anlama görevlerine (ör. OCR, simgesel yapılar, markalar, web algılama) öncelik verir; bu da KKD ve benzeri nesneleri eğitim hedeflerinde ikincil hale getirir.
Varsayılan API yapılandırması ve hassasiyet-geri çağırma ödünleşimleri
- Tüm hizmetler varsayılan ayarlarla değerlendirildi; bu ayarlar genellikle yanlış pozitifleri en aza indirmek için yüksek hassasiyete öncelik verir.
- Bu tasarım seçimi, sağlayıcılar genelinde güçlü hassasiyet puanlarına ancak özellikle daha az belirgin nesneler için belirgin şekilde daha düşük geri çağırmaya yol açar.
Küçük nesne tespit sınırlamaları
- Eldiven, şapka ve baret gibi nesneler genellikle görüntünün küçük bir bölümünü kaplar ve güvenilir şekilde tespit edilmeleri zordur.
- Küçük veya birbirine yakın nesnelerde düşük performans sergilediği belgelenen Azure AI Vision, bu kategorilerde en belirgin bozulmayı gösterir.
Etiket taksonomisi ve değerlendirme eşlemesi
- Sağlayıcıya özgü etiketler, birleşik bir temel gerçek taksonomisine eşlenmek zorundaydı.
- Eşleşmeyen veya daha ayrıntılı etiketler kullanan geçerli tespitler değerlendirmeden hariç tutulmuş olabilir.
Maske tespitinin olmaması
- Değerlendirilen hizmetlerin hiçbiri varsayılan API'lerinde maskeyle ilgili nesne etiketleri sunmaz.
- Bu nedenle her üçü de maskeler için %0 hassasiyet döndürmüştür.
IoU duyarlılığı ve konumlandırma kalitesi
- Performans farkları, daha sıkı sınırlayıcı kutu hizalamasının gerektiği daha yüksek IoU eşiklerinde artar.
- Amazon Rekognition bu eşiklerde nispeten daha yüksek mAP korur ve daha güçlü konumlandırma doğruluğuna işaret eder.
Görüntü tanıma araçları kıyaslama metodolojisi
Bu sağlayıcıların hazır (yani özel etiketleme olmaksızın) performansını gerçek hayat senaryolarında test ettik.
100 görüntü kullandık. Orijinal veri kümesi farklı boyutlardan oluştuğu için, örnekleri içeren temel bölgeleri koruyarak görüntüleri 512×512 piksele ölçeklendirdik.
Satıcıların çözümlerini bu veri kümesi üzerinde eğitmediği bir testi tekrar çalıştırmak istiyoruz. Bu nedenle, bu kıyaslama için kullandığımız veri kümesini açıklamıyoruz.
Hizmet sağlayıcıların API'lerinden gelen yanıtları aşağıdaki şekilde işledik:
- servis sağlayıcı etiketleri, yukarıdaki tabloda tanımlanan temel gerçek kategorilerine eşlendi. Bu temel gerçek etiketleriyle eşleşmeyen servis sağlayıcı etiketleri değerlendirme dışı bırakıldı.
- farklı sağlayıcılardan gelen sınırlayıcı kutu formatları normalleştirildi
- tahmin ve temel gerçek kutuları arasındaki IoU hesaplandı
- tahminler IoU eşiğine göre temel gerçekle eşleştirildi
- metrikler hesaplandı: hassasiyet, geri çağırma, F1 ve kategori başına AP
- 0.5-0.95 eşikleri kullanılarak COCO tarzı mAP hesaplandı
IoU, hassasiyet, geri çağırma ve F1 için örnek bir hesaplama aşağıdaki şekilde verilmiştir:
Kıyaslama metrikleri
Hassasiyet
Hassasiyet, modelin yaptığı pozitif tahminlerin doğruluğunu ölçer. Görüntü tanımada, belirli bir sınıf için (ör. “kişi”), şu soruyu yanıtlar: “Modelin kişi içerdiğini etiketlediği tüm görüntülerin ne kadarı gerçekten kişi içerir?”. Yanlış pozitiflerin (bir görüntüyü pozitif olarak yanlış etiketleme) maliyetli olduğu senaryolarda bu önemlidir.
Geri Çağırma
Geri çağırma, pozitif tahminlerin kapsamlılığını ölçer ve şu soruyu yanıtlar: “Sınıfı gerçekten içeren tüm görüntülerin ne kadarını model doğru şekilde tanımladı?”. Pozitif (yanlış negatif) bir örneğin kaçırılmasının kritik olduğu durumlarda bu hayati önem taşır.
F1 Skoru
F1 Skoru, hassasiyet ve geri çağırmanın harmonik ortalamasıdır ve özellikle sınıf dağılımı dengesiz olduğunda (ör. az sayıda kask görüntüsüne karşılık kask olmayan görüntüler) yararlı olan dengeli bir ölçü sağlar. Hem yanlış pozitifleri hem de yanlış negatifleri yakalayan tek bir metriktir.
mAP
mAP veya ortalama Hassasiyet, esas olarak görüntü tanıma içindeki nesne tespit görevlerinde kullanılan bir metriktir. Her sınıfın Ortalama Hassasiyetini (AP) ortalamasını alarak modelin doğruluğunu farklı sınıflar arasında değerlendirir. AP'nin kendisi, tespitler için güven eşiği değiştirilerek oluşturulan hassasiyet-geri çağırma eğrisinin altındaki alandır.
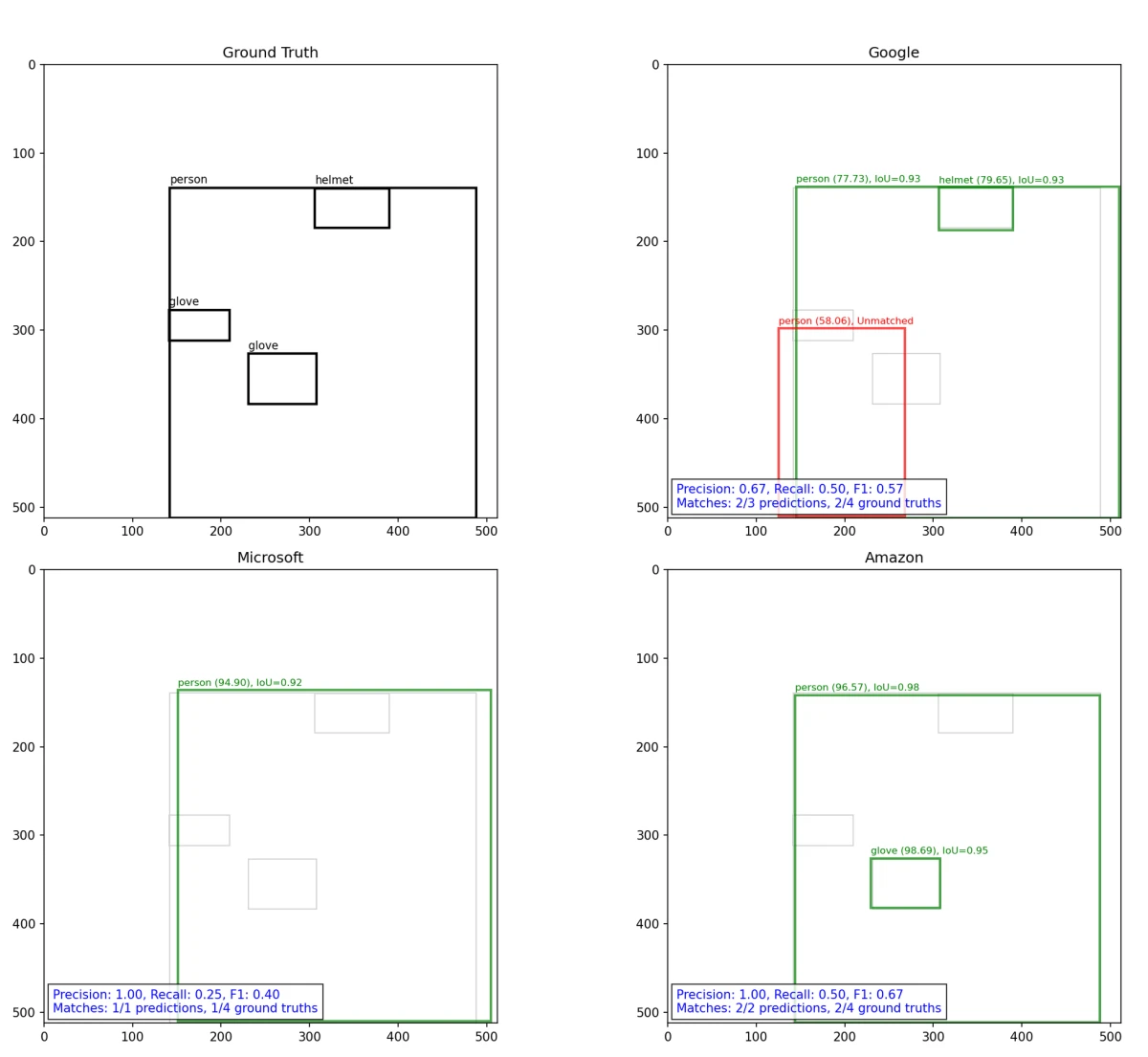
Bu etkileşimli araç, veri kümesindeki örnek görüntüleri kullanarak sağlayıcılar arasında tespit sonuçlarını karşılaştırmanızı sağlar. Amazon, Google, Microsoft veya tüm sağlayıcıları seçmek için üstteki düğmeleri kullanın. Onay kutusuyla temel gerçeği açıp kapatın. Soldaki numaralı düğmeleri kullanarak test görüntüleri arasında gezinin. Renkli kutular, güven puanlarıyla birlikte her tespiti gösterir.
En İyi Görüntü Tanıma API'leri
Amazon Rekognition
Amazon Rekognition, genel nesne ve yüz algılamanın yanı sıra özel KKD tespit API'leri içerir; bu da diğer iki hizmete kıyasla baret ve eldiven gibi sınıflarda daha geniş etiket kapsamı sağlar. Bu ürün kapsamı, kıyaslamadaki sınıf başına AP sonuçlarıyla tutarlıdır.
Görüntü API'leri iki gruba ayrılır:
- Grup 1 (yüz tanımlama): CompareFaces, IndexFaces, SearchFaces; kimlik doğrulama ve görüntü koleksiyonlarında yüz arama için kullanılır.
- Grup 2 (içerik analizi): DetectLabels (genel nesne tespiti), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
AWS'nin geri kalanıyla entegre olur (depolama için S3, olay odaklı işleme için Lambda, özel model eğitimi için SageMaker).
Google Cloud Vision
Google Cloud Vision, diğer iki hizmetle aynı hassasiyet tabanı olan IoU=0.5'te %89'u aşan hassasiyet elde etti, ancak küçük nesneler ve koruyucu ekipmanlarda daha düşük geri çağırma sağladı. Ürün kapsamı, endüstriyel tespit yerine genel amaçlı görüntü anlamaya yöneliktir: OCR, simgesel yapı tanıma, logo ve marka tanımlama ve Web Algılama (bir görüntüyü genel olarak indekslenmiş görüntülerle eşleştirme).
Temel yetenekler:
- Nesne konumlandırma ve etiket tespiti
- Çoklu dilde basılı ve el yazısı metin için OCR
- Simgesel yapı, logo ve ünlü tespiti
- Tersine görüntü arama için Web Algılama
- Vertex AI aracılığıyla özel model eğitimi
Cloud Storage, BigQuery ve Google Workspace ile entegre olur ve Rekognition'dan daha geniş bir dosya formatı yelpazesini kabul eder (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure AI Vision
Microsoft Azure AI Vision görüntü analizi, OCR, görüntü açıklama ve ayrı bir arka plan kaldırma hizmeti sunar. Belgeleri, nesne algılayıcısının küçük veya birbirine yakın nesneleri güvenilir şekilde işleyemediğini belirtir; bu nedenle kendini ince taneli nesne tespitinden çok genel görüntü anlamaya ve metin okumaya konumlandırır.
Temel yetenekler iki gruba ayrılır:
- Grup 1 (görsel öğe tespiti): etiketleme, yüz, nesne algılama, marka ve simgesel yapı algılama, akıllı kırpma, OCR.
- Grup 2 (dil farkındalıklı çıktı): görüntü açıklama, yoğun açıklamalar, tam okuma (belge OCR'si).
Hizmet sağlayıcıların farklılaştırıcı özellikleri
API fiyatlandırma genel görünümü
Özel görüntü modelleri oluşturma
Amazon Rekognition, Google Cloud Vision ve Microsoft Azure AI Vision gibi barındırılan API'ler, sağlayıcı tarafından tanımlanan sabit bir etiket kümesinden tahmin döndürür. Gerekli bir nesne sınıfı bu kümede eksik olduğunda veya belirli bir alanda doğruluk çok düşük olduğunda, alternatif özel bir model eğitmektir. Roboflow bu iş akışını kapsayan bir örnektir.
Roboflow
Roboflow, veri etiketleme, model eğitimi ve dağıtımı kapsayan bir bilgisayarlı görü platformudur. Yukarıdaki barındırılan tespit API'lerinden farklı bir model üzerinde çalışır: kullanıcılar kendi etiketlenmiş veri kümelerinde modeller eğitir ve yönetilen bir uç noktayı çağırmak yerine çıkarımı kendi donanımlarında çalıştırır. Varsayılan bulut API'leri, kıyaslanan üç hizmette de %0 hassasiyet döndüren maskeler gibi belirli bir nesne sınıfı için etiket sunmadığında ekipler bu yolu izler.
Roboflow üç ana bileşenden oluşur:
- RF-DETR: canlı kamera ve video girişleri için tasarlanmış, nesne tespiti ve bölütleme için gerçek zamanlı transformer tabanlı bir model.2
- AutoDistill: manuel etiketleme olmadan görüntü veri kümelerini otomatik olarak etiketlemek için büyük temel modeller kullanan bir araç.3
- Inference: birden çok arka ucu (ONNX, TensorRT, PyTorch) destekleyen, GPU'lar, CPU'lar veya Docker tabanlı bir hizmet aracılığıyla NVIDIA Jetson gibi uç cihazlarda yürütülen bir dağıtım paketidir.4
Görüntü tanımada uç bilişim
Bulut tabanlı görüntü tanıma, her kareyi analiz için uzak bir veri merkezine gönderir. Uç bilişim, modeli o kareyi yakalayan cihaz üzerinde çalıştırır, böylece sonuç (bir etiket, bir uyarı, bir işaret) cihazdan ayrılır.
Uç bilişim nasıl çalışır?
Bir bulut kurulumunda, kameralar veri toplayıcı görevi görür ve ham kareleri yukarı akışa aktarır; model veri merkezinde bulunur. Bir uç kurulumunda, cihaz sinir ağını yerel olarak çalıştırır ve ilgili çıktıyı iletir: “kişi algılandı”, “envanter düşük”, “kusur bulundu”.
Görüntü tanıma için neden önemlidir?
- Gecikme: yerel çıkarım bulut gidiş-dönüşünü ortadan kaldırır; bu, otonom araçlar, üretim robotları ve tahmine milisaniyeler içinde tepki vermesi gereken tüm sistemler için önemlidir.
- Gizlilik: görüntüler cihazdan ayrılmaz; bu, veri yerleşikliği veya GDPR kısıtlamalarının geçerli olduğu durumlarda (tıbbi görüntüleme, mağaza içi CCTV) yararlıdır.
- Bant genişliği ve maliyet: videonun tamamı değil meta veri yüklenir, bu da yüksek hacimli dağıtımlar için ağ ve bulut-API maliyetlerini azaltır.
- Çevrimdışı çalışma: uç cihazlar ağ arızasında çalışmaya devam eder; bu, güvenlik sistemleri ve uzak endüstriyel tesisler için gereklidir.
Görüntü tanımada uç AI'nın gerçek dünyadan örnekleri
Captur cihaz üstü SDK
Cihaz üstü işleme, mobil bağlamlarda uç AI'nın en yaygın biçimidir. Captur, çevrimdışıyken bile bilgisayarlı görü modellerini mobil cihazlarda ~30ms içinde yerel olarak çalıştıran bir cihaz üstü görüntü doğrulama SDK'sı sunar.5 Lojistik sağlayıcısı GoBolt, teslimat kanıtı doğrulaması için Captur SDK'sını sürücü uygulamasına entegre etti ve ilk haftada teslimat alınmadı bildirimlerinde %30 düşüş bildirdi.6
Ultralytics YOLO26
Ultralytics YOLO26, uç ve düşük güçlü cihazlar için tasarlanmış açık kaynaklı bir bilgisayarlı görü modelidir. Tamamen uçtan uca, NMS-ücretsiz mimarisi, maksimum olmayan bastırma gibi işlem sonrası adımları ortadan kaldırarak gecikmeyi azaltır ve uç donanıma aktarılabilirliği artırır; aynı zamanda tek bir model ailesi içinde nesne tespiti, bölütleme, sınıflandırma ve poz tahminini destekler.7
Görüntü tanımada görü transformatörleri
Burada kıyaslanan görüntü tanıma API'leri CNN tabanlı algılayıcılar kullanır. Görü transformatörleri (ViT'ler), görüntüyü sabit boyutlu yamalara (tipik olarak 16×16 piksel) bölen ve tüm yamaları paralel olarak işleyen alternatif bir mimaridir; bu, modelin istiflenmiş evrişimlerle kademeli olarak oluşturmak yerine ilk katmandan itibaren görüntünün uzak bölgelerini ilişkilendirmesine olanak tanır.
Nesne tespiti için, bir nesnenin kimliği çevredeki sahneye bağlı olduğunda (bir kişinin üzerindeki şapka ile raftaki şapka) bu önemlidir. CNN'ler bunu istiflenmiş evrişimlerle yakalar; ViT'ler ise dikkat mekanizmasıyla tüm yamalar arasında aynı anda yakalar.
Bu kıyaslamadaki üç bulut hizmeti de üretimde CNN tabanlı modeller çalıştırır. Hibrit CNN-Transformer mimarileri daha yeni açık kaynak modellerde (örneğin, Roboflow'un RF-DETR'si bir DINOv2 transformer omurgası kullanır) ortaya çıkıyor, ancak üretim bulut API'leri henüz geçiş yapmadı.
Görüntü tanıma için görü transformatör modelleri
- Google ViT: ImageNet üzerinde görüntü sınıflandırması için eğitilmiş orijinal Görü Transformatörü. Hugging Face üzerinde önceden eğitilmiş ağırlıklarla mevcuttur.
- Swin Transformer: hem genel hem de yerel ayrıntıyı yakalamak için kaydırılmış pencere mekanizması kullanır; tespit ve bölütleme için kullanılır.
- DINOv2 (Meta): manuel etiketler olmadan eğitilen kendinden denetimli model; genel amaçlı görüntü yerleştirmeleri üretir.
- Segment Anything Model (SAM): eğitilmediği nesneleri yalıtabilen ViT tabanlı bölütleyici.
Görüntü tanıma yazılımının kullanım alanları
Günümüzün dijital ortamında, bilgisayarlı görü ve görüntü işleme teknolojileri işletmelerin görsel verilerden yararlanma şeklini dönüştürdü. Gelişmiş görüntü sınıflandırma algoritmaları, sektörler genelinde operasyonları yeniden şekillendiren sofistike görüntü tanıma araçlarını mümkün kılıyor.
Bu görüntü tanıma teknolojileri, kullanıcıların karmaşık görsel görevleri otomatikleştirmesini sağlayan sezgisel arayüzlerle güçlü model eğitimi yaklaşımlarını birleştirir. Belirli iş ihtiyaçları için özel görü çözümlerinden güvenlik için yüz tanıma sistemlerine kadar bu araçlar, görüntüler içindeki desenleri, nesneleri ve özellikleri tanımlayabilir.
Görsel denetim
Görüntü tanıma, birden çok sektörde otomatik görsel denetimi mümkün kılar. Bu sistemler görsel verileri analiz ederek nesneleri tanımlar, özellikleri tespit eder ve uyumluluğu doğrular.
Örneğin, Chamberlain Group, myQ uygulamasında Amazon Rekognition'ı uygulayarak kullanıcıların uyumluluğu kontrol etmek için garaj kapısı açıcılarının görüntülerini otomatik olarak yakalamasını sağladı. Bu kolaylaştırılmış çözüm, karmaşık bir manuel sürecin yerini aldı ve kullanıcı bağlantı oranlarını önemli ölçüde artırdı.8
Belge işleme
OCR teknolojisi, görüntülerden ve belgelerden metin çıkararak birden çok dilde veri girişini otomatikleştirir. Modern sistemler el yazısı metinleri ve karmaşık mizanpajları işleyerek kâğıt tabanlı iş akışlarını dönüştürebilir ve belgeleri aranabilir hale getirebilir.
Örneğin, Fransız sigorta grubu LSA Courtage, ehliyet ve ruhsat belgelerindeki metni tanımak için Google Cloud Vision API'yi kullanır. Bu OCR uygulaması, belge işleme süresini sayfa başına %45 azalttı ve sigortacı verimliliğini %20 artırarak günde 1.500 belge işlemelerini sağladı.9
Farklı belge türleri için çeşitli OCR araçlarının doğruluğunu görmek üzere OCR kıyaslamamıza göz atabilirsiniz.
Tarım izleme
Çiftçiler, ürün sağlığını izlemek, hastalıkları tespit etmek ve sulamayı optimize etmek için görüntü tanıma ile drone görüntülerinden yararlanır. Görünür belirtiler ortaya çıkmadan önce ürün stresi alanlarını belirleyerek çiftçiler erken müdahale edebilir ve kaynak kullanımını azaltabilir.
Örneğin, Microsoft'un Project FarmBeats'i (şimdi Azure Tarım için Veri Yöneticisi), sınırlı güç ve internet bağlantısı olan ortamlarda veri odaklı tarımı mümkün kılmak için sensörler, drone'lar ve makine öğrenimini kullanır. Sistem, görsel verileri çiftçilerin arazileri hakkındaki bilgileriyle birleştirerek çiftlik verimliliğini artırmaya ve maliyetleri düşürmeye yardımcı olur.10
Güvenlik ve gözetim
Güvenlik sistemleri, etkinlikleri tanımlamak, erişimi kontrol etmek ve kişileri bulmak için yüz tanıma ve nesne tespiti kullanır. Bu sistemler video akışlarını izler ve personeli tehditlere karşı uyarır. Örneğin, Sun Finance, selfie'leri kimlik belgeleriyle karşılaştırarak müşteri kimliğini doğrulamak için Amazon Rekognition'ı kullanır; bu da doğrulamayı hızlandırır ve dolandırıcılığı önlerken finansal kapsayıcılığı genişletir.11
İçerik denetleme
Sosyal medya platformları, kullanıcı yüklemelerinden çıplaklık, şiddet veya grafik görüntüler gibi uygunsuz içerikleri filtrelemek için görüntü tanımayı kullanır. Açıklama oluşturma, piksel düzeyinde sınıflandırıcıların kaçırdığı görüntü bağlamını tanımlayarak ikinci bir katman ekleyebilir; örneğin, başka türlü zararsız bir fotoğrafın arka planındaki nefret sembollerini tespit etme. AWS'ye göre, makine filtreleme tipik olarak insan moderatörlerin incelemesi gereken hacmi toplamın %1–5'ine düşürür.12
Örneğin, CoStar Group, ticari emlak platformlarına günlük yaklaşık 150.000 görüntü ve video yüklemesinin içerik denetimi ve video analizi için Amazon13
Görüntü tanımanın uygulamaları hakkında daha fazla bilgi edinebilirsiniz.
Görüntü tanıma teknolojisinin sınırlamaları
Küçük nesnelerde ayrıntı kaybı
Nesneler görüntülerde küçük göründüğünde, daha az piksel içerirler ve bu da sınırlı görsel veriyle sonuçlanır. Ayrıca, CNN'ler alt örnekleme katmanları aracılığıyla işleme sırasında önemli ince ayrıntıları kaybetme eğilimindedir; bu da tespit yeteneklerini önemli ölçüde engeller.
Kaçırılan tespitler
Görüntü tanıma sistemleri hem eğitim hem de analiz aşamalarında genellikle daha büyük nesneleri tercih eder; bu da küçük nesnelerin kaçırılma veya yanlış negatif sıklığının artmasına neden olur.
Arka plan girişimi
Daha küçük nesneler, görsel gürültü, arka plan karmaşası veya örtüşen öğeler tarafından gizlenmeye daha yatkındır; bu da onları doğru şekilde tanımlamayı zorlaştırır. Kısmi örtme bile, başlangıçta ayırt edilebilir alanları daha az olduğu için küçük nesneleri orantısız şekilde etkileyebilir.
Ölçek değişkenliği
Farklı mesafelerde veya ölçeklerde görünen nesneler, değişen nesne boyutları arasında ince ayrıntıları tespit etmek için özel olarak tasarlanmamış modeller için zorluk oluşturur.
Hesaplama talepleri
Çok ölçekli özellik çıkarma veya daha yüksek çözünürlüklü girdiler gibi küçük nesne tespitini iyileştirme teknikleri daha fazla işlem gücü gerektirir ve gerçek zamanlı uygulanabilirliği sınırlar.
Eğitim önyargısı
Veri kümeleri genellikle küçük nesneleri yetersiz temsil eder veya onlar için yeterli etiketleme içermez; bu da gerçek dünya senaryolarında bu tür durumlara model genellemesini azaltır.
SSS'ler
Görüntü tanıma yazılımı, dijital görüntüler ve video verileri gibi yapılandırılmamış verileri analiz etmek için makine öğrenimi algoritmalarını kullanan bir bilgisayarlı görü teknolojisi türüdür. Belirli nesneleri tanımlamanın ötesine geçer; gelişmiş sistemler, daha eksiksiz bir analiz sağlamak için bir görüntü içindeki bağlamı ve ilişkileri yorumlayarak sahne anlamayı hedefler. Bu, bilgisayarların görsel bilgileri etkili bir şekilde görmesini ve sınıflandırmasını sağlar.
Evrensel olarak en iyi tek bir görüntü tanıma veya bilgisayarlı görü yazılımı yoktur. Görüntü tanıma teknolojileri arasında ideal seçim, özel ihtiyaçlarınıza bağlıdır. Gerekli doğruluk, gerçekleştirmeniz gereken görev türleri (nesne tespiti veya OCR gibi ve hatta görüntü anlamayı metin analiziyle birleştiren görevler için doğal dil işleme ile entegrasyon gerekip gerekmediğini bile düşünerek), kullanım kolaylığı, ölçeklenebilirlik, bütçe, özelleştirme seçenekleri ve ekibinizin teknik uzmanlığı gibi faktörleri göz önünde bulundurun. Uygulamanız için ihtiyaç duyduğunuz bilgisayarlı görü yeteneklerini en iyi sağlayan görüntü tanıma teknolojilerini bulmanın en iyi yolu farklı seçenekleri denemektir.
Görüntü tanıma önemli ölçüde gelişmiş olsa da doğruluk garanti edilmez. Performansı etkileyen faktörler arasında görüntü kalitesi (aydınlatma, çözünürlük), sahnenin karmaşıklığı, nesne görünümü değişiklikleri ve derin öğrenme algoritmaları için kullanılan eğitim verilerinin kalitesi bulunur. Sağlam bir sahne anlayışı elde etmek ve belirli nesneleri doğru şekilde tespit etmek, karmaşık veya gürültülü görsel verilerde zor olabilir.
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{En İyi Görüntü Tanıma Araçları Karşılaştırması}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Erişim tarihi: 17 Haziran 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.