LCM'ler: LLM Tokenizasyonundan Kavram Düzeyinde Gösterime
Meta tarafından “Büyük Kavram Modelleri” üzerine yaptıkları çalışmada tanıtılan büyük kavram modelleri (LCM'ler) , belirteç tabanlı tahminden kavram düzeyinde temsile doğru temel bir geçişi temsil eder. 1
LCM'ler geleneksel LLM'lerden iki temel açıdan farklılık gösterir:
- Yüksek boyutlu gömme alanı: LCM'ler, ayrık belirteç dizileriyle çalışmak yerine, tüm modellemeyi doğrudan yüksek boyutlu gömme alanında gerçekleştirir.
- Kavram düzeyinde soyutlama: Modelleme, belirli bir dil veya yöntem içinde değil, anlamsal ve soyut kavramlar düzeyinde gerçekleştirilir. Bu, LCM'leri doğası gereği dil ve yöntemden bağımsız kılar.
Meta'ün araştırmasına göre, 2 Aşağıdaki ölçütlere dayanarak, LCM'lerin temel bileşenlerini ve bunların anlamsal arama ve akıl yürütmedeki potansiyellerini inceleyeceğiz:
LLM'lerin sınırlamalarını anlamak: Tokenlardan kavramlara
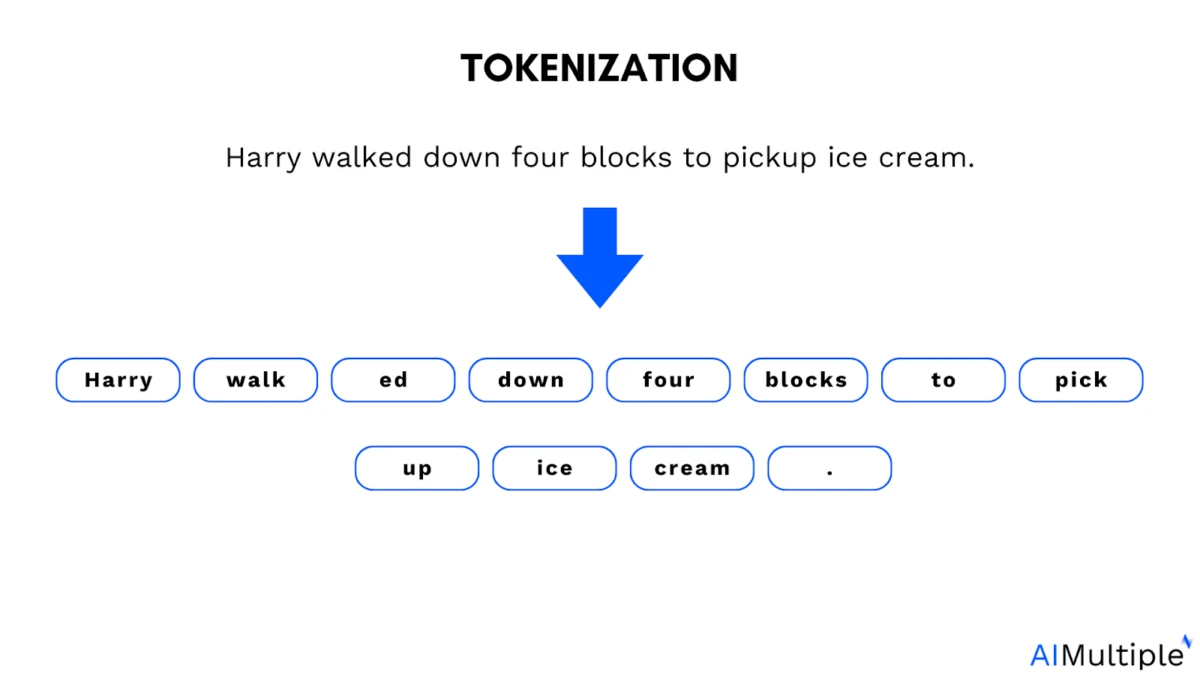
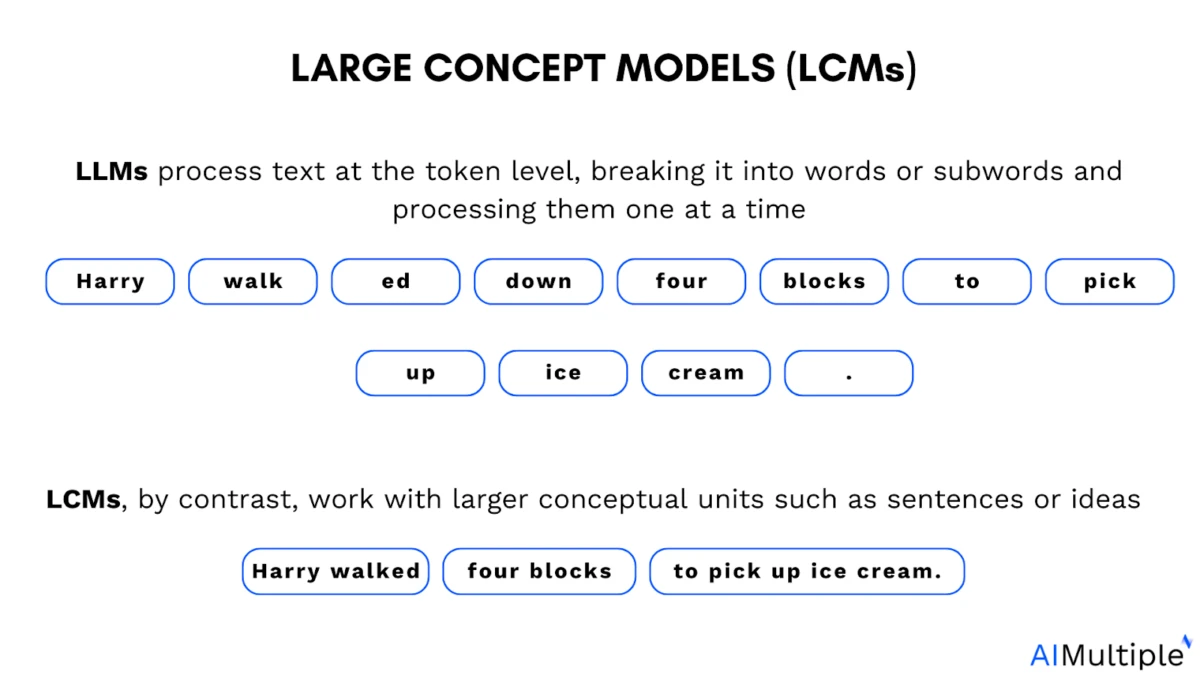
Büyük dil modellerinde ( LLM'lerde) belirteçlemenin rolü: Büyük dil modelleri (LLM'ler) belirteçler üzerinde eğitilir. Belirteçler, metnin küçük bir parçasıdır. Tam bir kelime, kelimenin bir parçası veya modelin bir birim olarak işlediği tek bir karakter olabilir.
Tokenizasyon örneği:
Sorun
Tokenizasyon, modellerin dili yönetilebilir parçalara ayırmasına yardımcı olur, ancak aynı zamanda bir kısıtlama da getirir. Çoğu dil öğrenme modeli, ayrık token dizileri üzerinde çalışır (örneğin, metin alt kelimeleri; kodlayıcılar tarafından üretilen görsel/işitsel tokenler).
LLM'ler birden fazla modaliteyi işleyebilir, ancak temel amaçları ve temsilleri sıralamaya bağlı kalır; bu da kavram düzeyinde anlamı doğrudan modellemeyi zorlaştırır.
Cognition.ai'nin Sonnet 4.5 ile yaptığı bulgular bunu açıkça gösteriyor: model, bağlam penceresinin neredeyse dolduğunu algılıyor, aceleyle sonuçlara varıyor ve hatta kalan belirteçleri (her ne kadar yanlış olsa da) rapor ediyor. 3
Çözüm (Kavramlar)
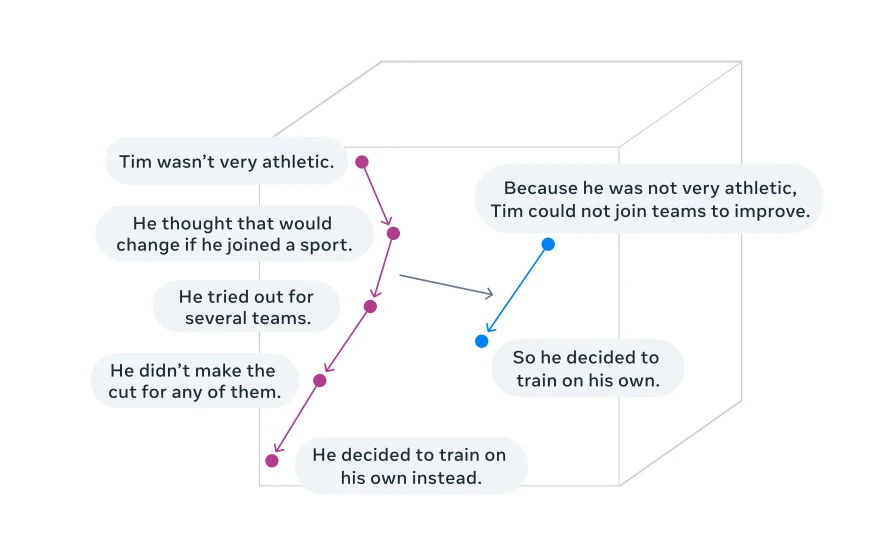
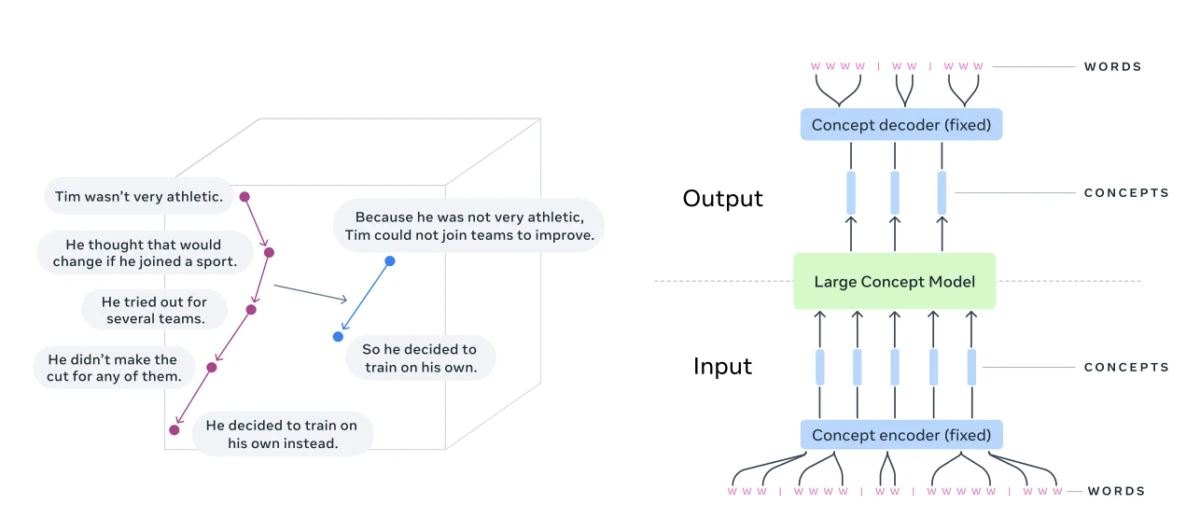
Kavramların yerleştirildiği bir uzayda akıl yürütmenin görselleştirilmesi (özetleme görevi) 4
Kavramlar, anlamın daha üst düzey temsillerini ifade eder. Token'ların aksine, belirli bir dil birimine bağlı değillerdir ve metinden, konuşmadan türetilebilirler, bu nedenle akıl yürütme süreci aynı kalır.
Bu şunları sağlar:
- Parçalı unsurlar yerine bütün fikirler üzerinde akıl yürüterek uzun bağlamların daha iyi ele alınması .
- İşlemler anlam düzeyinde gerçekleştirildiği için daha soyut bir akıl yürütme söz konusudur .
- Çok dilli ve çok modlu görevleri, her girdi türü için ayrı işlem hatlarına ihtiyaç duymadan ele almak için dil ve yöntemden bağımsız bir süreç .
Büyük ölçekli kavram modelleri nelerdir?
Buna karşılık, büyük kavram modelleri (LCM'ler), herhangi bir dile veya modaliteye bağlı olmayan, sürekli bir gömme uzayında anlamsal kavramları temsil etmeyi ve bunlar üzerinde akıl yürütmeyi amaçlar.
Büyük ölçekli bir kavram modelinin (LCM) temel mimarisi:
Kaynak: Meta 5
LCM'lerin temel bileşenleri
1. SONAR kodlaması (metni veya konuşmayı kavram gömülerine dönüştürme)
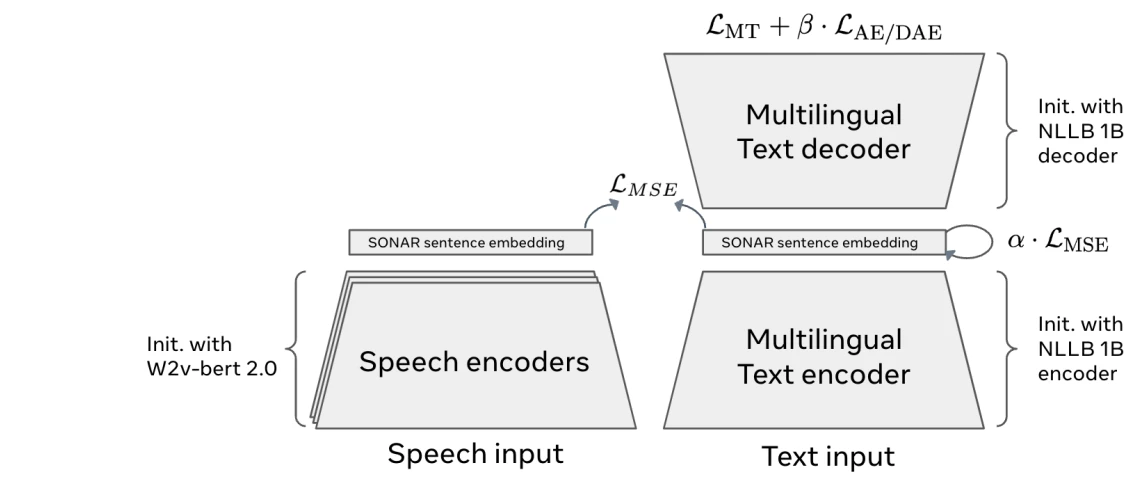
SONAR mimarisi 6
Büyük Kavram Modeli'nin (LCM) ilk aşaması, metni veya konuşmayı paylaşılan bir gömme alanına dönüştüren kavram kodlayıcısıdır . Girişi belirteçlere ayırmak yerine, tüm cümleleri anlamlarını yakalayan matematiksel gömmeler olarak temsil eder.
LCM'ler, 200'den fazla metin dilini ve 76 konuşma dilini destekleyen çok dilli ve çok modlu bir gömme alanı olan SONAR'ı kullanır.
Örneğin, İngilizce'deki "I love you" ve İspanyolca'daki "Te quiero" cümleleri aynı fikri ifade ettikleri için bu alanda birbirine yakın yerleştirilmiştir. Bu kavram düzeyinde çalışarak, LCM'ler belirteç tabanlı modellere kıyasla kapsayıcılık, verimlilik ve ölçeklenebilirlik kazanır.
SONAR neden geleneksel gömme yöntemlerinden daha iyidir?
Geleneksel yöntemler:
- mBERT : Çok dilli gömme vektörleri sağlar, ancak cümle düzeyinde tutarlı bir şekilde hizalanmadıkları için diller arası görevler daha az etkilidir.
SONAR'ın avantajları:
- Dil bağımsız : Metin girişi ve çıkışı için 200'den fazla dil (Meta'ün "Hiçbir Dil Geride Kalmasın " projesine dayanarak). Konuşma girişi için 76 dil ve konuşma çıkışı için İngilizce.
- Diller arası uyum : Aynı anlama gelen cümleler, dilden bağımsız olarak birbirine yakın sıralanır.
- Üst düzey akıl yürütme : Birimler cümleler (veya kavramlar) olduğundan, modeller fikirleri doğrudan manipüle ederek özetleme veya çeviri gibi görevleri yerine getirebilir.
- Sıfır atışlı çeviri : Her bir dil çifti için doğrudan eğitim gerektirmeden diller ve yöntemler arasında çeviri yapabilir.
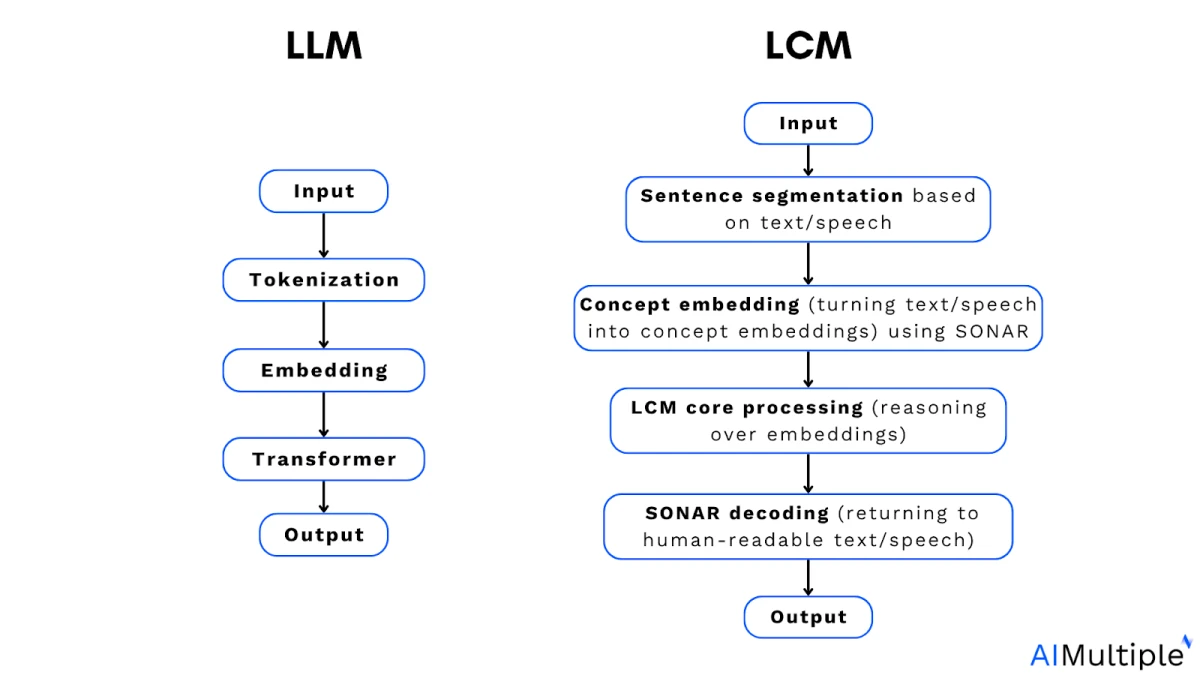
LLM'ler ve LCM'ler
2. LCM çekirdek işleme (gömülü vektörler üzerinden akıl yürütme)
LCM çekirdeği, modelin bağlama dayalı olarak yeni kavramlar ürettiği akıl yürütme aşamasıdır. Tek seferde bir belirteç tahmin eden LLM'lerin aksine, LCM Çekirdeği daha yüksek bir semantik düzeyde çalışarak tüm cümleleri veya kavramları tahmin eder.
Buradaki zorluk, bağlama bağlı olarak sürekli gömme vektörleri üretmektir. LLM'ler ayrık belirteçler üzerinde olasılık dağılımları oluştururken, LCM'ler anlamı yakalayan vektörleri doğrudan üretmelidir.
Bu sorunu çözmek için araştırmacılar çeşitli yaklaşımlar önermişlerdir, bunlar arasında şunlar yer almaktadır:
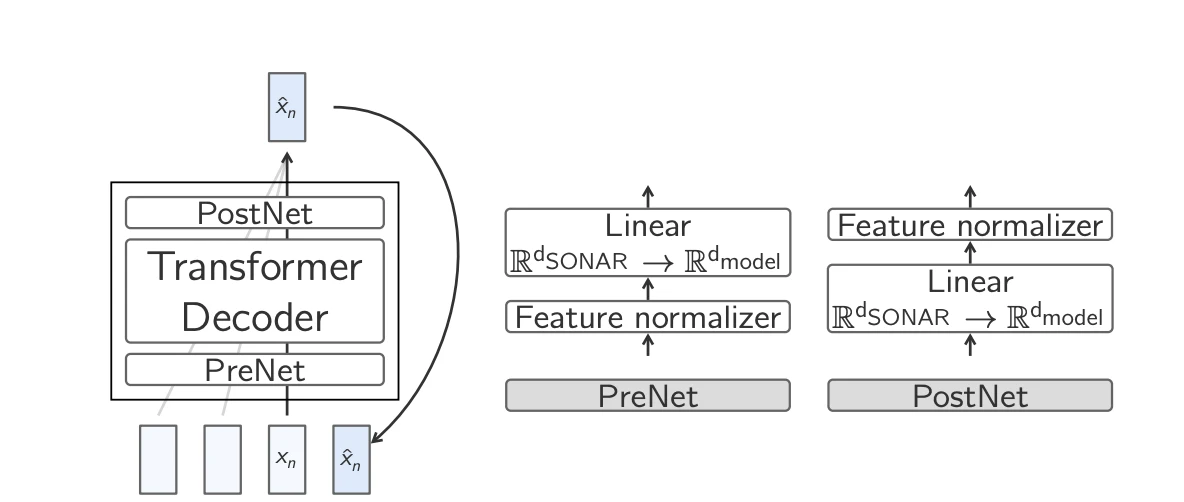
- Temel-LCM: Standart Transformer ile gömme tahmini: En basit yöntem , Ortalama Kare Hata (MSE) kaybını en aza indirerek bir Transformer'ı doğrudan bir sonraki gömmeyi tahmin edecek şekilde eğitmektir. Prensipte etkili olsa da, bu yaklaşım zorluklarla karşı karşıyadır çünkü belirli bir bağlam, birden fazla geçerli, ancak anlamsal olarak farklı devamlılığa yol açabilir.
Temel-LCM 7
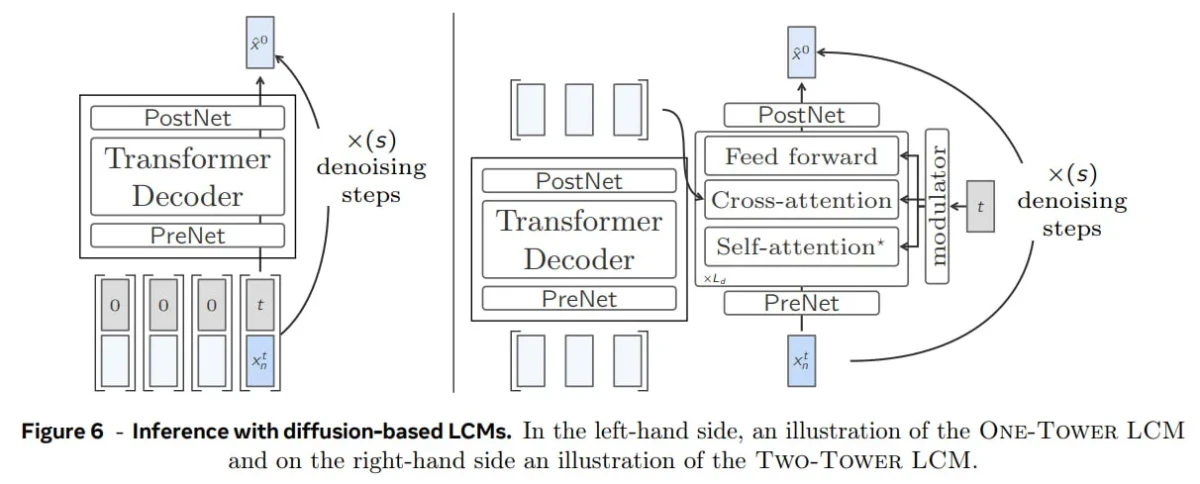
- Difüzyon tabanlı LCM: Bağlamsallaştırma ve gürültü giderme için yapısal varyasyonlar: Görüntü oluşturmadan esinlenen bu varyant, bir difüzyon süreci kullanır. Otoregresif olarak, her seferinde bir kavram üretir ve üretilen her kavram için gürültü giderme adımları gerçekleştirir.
- Tek kule: Tek bir Transformer yığını hem bağlamlandırmayı hem de gürültü gidermeyi ele alarak tasarımı verimli ve kompakt tutar.
- İki kuleli yaklaşım: Süreci iki parçaya ayırır: bağlamı anlamak için bir bağlamlandırıcı ve gömülü temsilleri iyileştirmek için bir gürültü giderici ; bu da karmaşıklık pahasına daha fazla esneklik sunar.
- Nicelleştirilmiş LCM: Ayrıklaştırılmış gömülü temsiller: Başka bir seçenek de gömülü temsilleri daha büyük sembolik birimlere ayırmaktır . Bu, görevi, modelin ayrık öğeler ürettiği LLM'lere daha yakın hale getirir, ancak burada "tokenlar" çok daha büyük, anlamsal olarak daha zengin anlam parçalarını temsil eder.
3. SONAR kod çözme (insan tarafından okunabilir metne veya konuşmaya geri döndürme)
LCM'nin son adımı, soyut gömülü temsilleri doğal metne veya konuşmaya dönüştüren kavram çözücüsüdür .
Kavramlar ortak bir gömme alanında saklandığından, akıl yürütme sürecini yeniden çalıştırmaya gerek kalmadan desteklenen herhangi bir dile veya yönteme çözümlenebilirler.
Bu dilden bağımsız tasarım, bir LCM'nin Almanca girdi alabileceği, kavramlarla akıl yürütebileceği ve Japonca çıktı verebileceği anlamına gelir. Ayrıca kolay ölçeklenebilirlik sağlar: yeni kodlayıcılar veya kod çözücüler (örneğin işaret dili veya konuşmadan metne dönüştürme sistemleri için) tüm modeli yeniden eğitmeye gerek kalmadan eklenebilir.
"Düşünmeyi" ifadeden ayrı tutarak, kod çözücü, LCM'lerin çok dilli ve çok modlu uygulamalar için hem esnek hem de uyarlanabilir kalmasını sağlar.
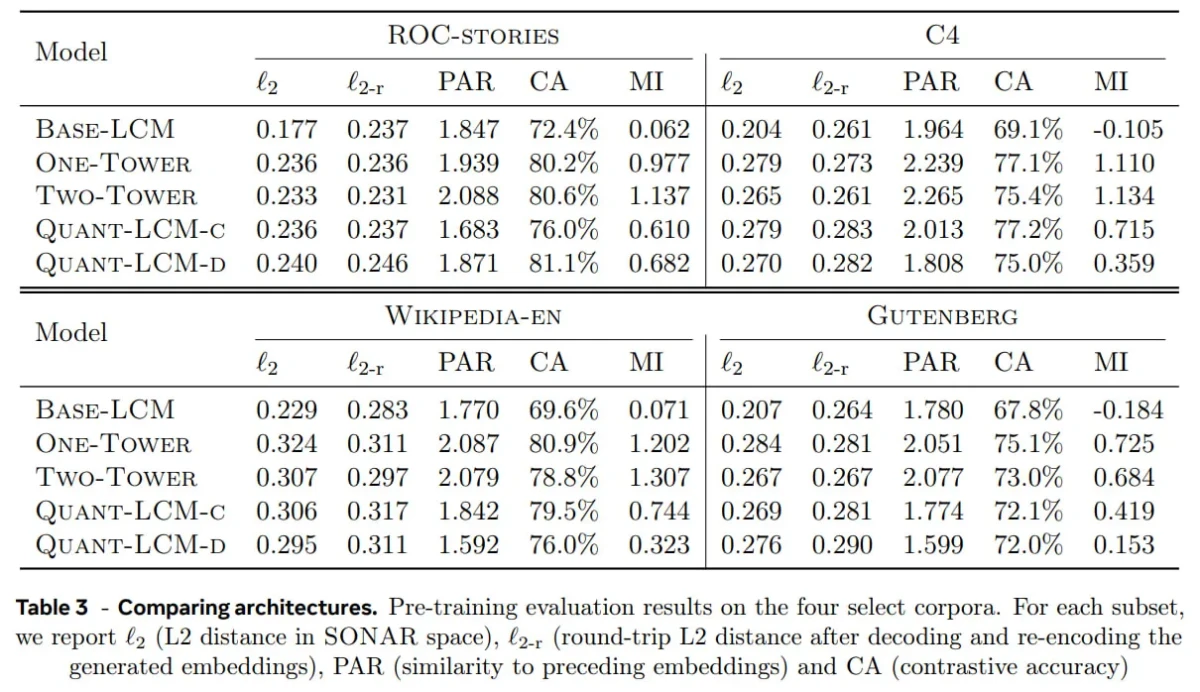
LCM mimarilerinin karşılaştırmalı değerlendirilmesi
Meta numaralı önceden eğitilmiş LCM'ler, FineWeb-Edu veri kümesi (yalnızca İngilizce) üzerinde kullanıldı ve dört kıyaslama ölçütü üzerinden değerlendirildi:
- ROC-Hikayeleri (anlatısal akıl yürütme),
- C4 (web ölçekli metin),
- Vikipedi-en (ansiklopedik bilgi),
- Gutenberg (uzun metin).
Bu veri kümeleri, kısa anlatılardan büyük bilgi tabanlarına ve kapsamlı belgelere kadar çeşitli metin türlerini kapsayacak şekilde seçilmiştir.
Önemli noktalar:
Difüzyon tabanlı LCM'ler (QUANT-LCM-C, QUANT-LCM-D) en güçlü performansı sergileyenlerdir . Yinelemeli gürültü giderme süreçleri, kavram devamlılıklarını modellemede daha etkili olmuş ve daha yüksek anlamsal doğruluk ve tutarlılığa yol açmıştır.
Karşılaştırma verilerinin nasıl yorumlanacağı:
- ℓ₂, ℓ₂-r: Daha düşük değer = daha doğru, tutarlı gömme işlemleri.
- PAR: Orta yol en iyisidir, çökmeden tutarlılık gösterir.
- CA: Daha yüksek değer = daha iyi anlamsal uyum.
- MI: Daha yüksek değer, daha bilgilendirici çıktılar anlamına gelir.
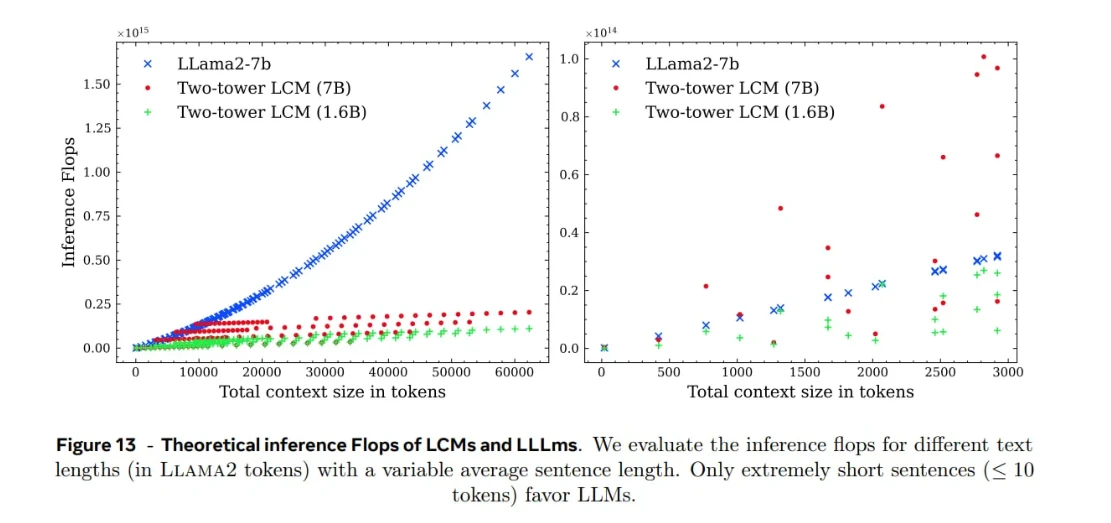
LCM verimliliğinin karşılaştırılması
Meta'ün deneyleri, aynı miktarda metni işlerken LCM'lerin LLM'lere kıyasla bağlam uzunluğuyla daha iyi ölçeklendiğini göstermiştir. Bu avantaj, bir kavramın birden fazla belirteç içeren tam bir cümleye karşılık gelmesinden kaynaklanmaktadır. Belirteçlerden daha az kavram olduğu için, modelin işleyeceği birim sayısı daha azdır ve karesel dikkat daha az zorlayıcı hale gelir.
Önemli noktalar:
Bu verimlilik kazanımlarının metnin cümlelere nasıl bölündüğüne büyük ölçüde bağlı olduğunu belirtmekte fayda var. Paragrafların daha kısa veya daha uzun cümlelere bölünmesi, kavram sayısını ve dolayısıyla hesaplama yükünü etkileyecektir.
Her LCM çıkarımı da üç aşamayı içerir:
- SONAR kodlaması (metin veya konuşma: gömme)
- Transformer-LCM mantığı (gömülü vektörlerin işlenmesi)
- SONAR kod çözme (gömülü veriler: metin veya konuşma)
Bu işlem hattı, özellikle kısa girdiler için ek yük getirir:
Kısa cümleler (~10'dan az kelime içeren) için, kodlama ve kod çözme adımları kavram düzeyindeki işlemlemenin faydalarından daha ağır bastığı için, LLM'ler LCM'lerden daha verimli olabilir .
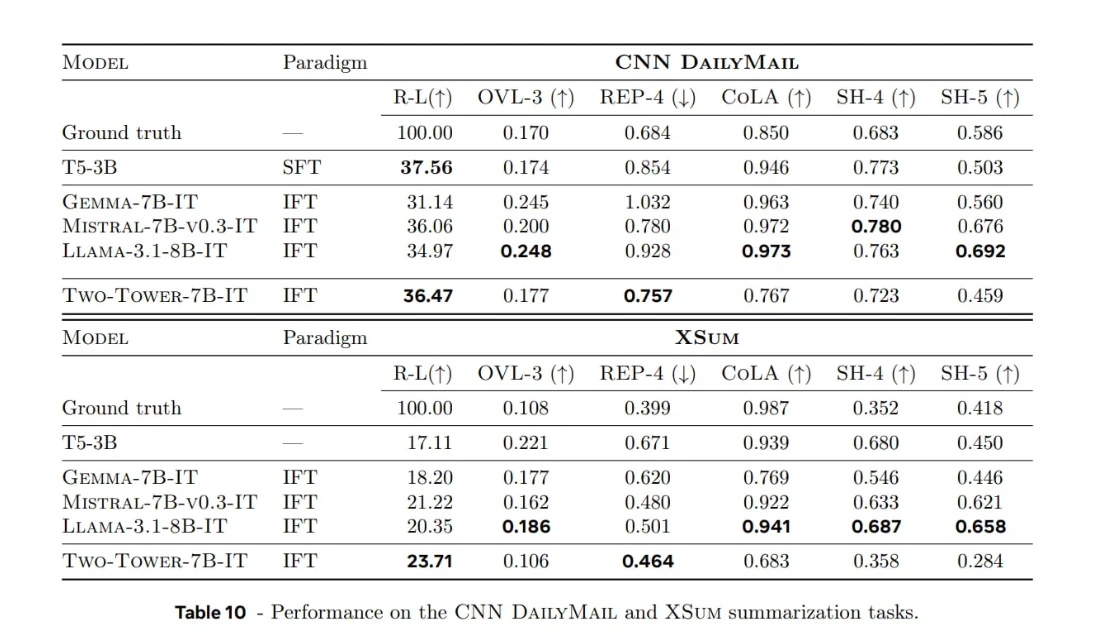
Özetleme görevlerinde LCM ile geleneksel LLM'lerin karşılaştırılması
Meta ayrıca, haber özetleme veri kümeleri (örneğin, CNN/DailyMail, XSum) üzerinde difüzyon tabanlı bir LCM'yi (7B parametre) kıyasladı ve geleneksel LLM'lerle karşılaştırdı.
Paradigma tanımları:
- SFT : Özetleme örnekleri üzerine uzmanlaşmış eğitim.
- IFT : Talimat veri kümeleri üzerinde daha kapsamlı eğitim, böylece model özetlemeyi birçok beceriden biri olarak öğrenir.
Parametre açıklamaları:
- ROUGE-L : Referans özetleriyle örtüşme.
- OVL-3 : Giriş üçlü harf örtüşme oranı, kaynak metinden kaynaklanan fazlalığı ölçer.
- REP-4 : Oluşturulan özetlerdeki tekrar sayısını ölçen, dört gramlık tekrar oranını çıktı olarak verir.
- SEAHORSE Q4 ve Q5 metrikleri : Kalite ve tutarlılık ölçütleri.
- CoLA tabanlı sınıflandırıcı : Oluşturulan cümlelerin dilsel olarak kabul edilebilirliğini değerlendirdi.
Önemli noktalar:
Kuvvet:
- Yayılım tabanlı LCM, özellikle geniş bağlamları işlerken, uzun metin özetlemede güçlü bir tutarlılık ve bağlamsal uyum sergiler.
Dikkat edilmesi gereken noktalar ve hususlar:
- Değerlendirme çoğunlukla MMLU gibi geniş kapsamlı kıyaslama ölçütlerinden ziyade üretken görevleri (özetleme) hedef almaktadır.
- Paragrafların cümlelere nasıl bölündüğü (örneğin "kavramları" nasıl tanımladığınız) performansı büyük ölçüde etkiler.
- Dilsel akıcılık ve kabul edilebilirlik açısından, LLaMA-3.1-8B ve Mistral-7B gibi belirteç tabanlı dil öğrenme modelleri (LLM'ler) hala avantajlı konumda. Dilsel iletişim modelleri (LCM'ler) umut vaat etse de, özellikle akıcılık veya esneklik alanlarında tüm ölçütlerde henüz net kazanımlar sağlamıyorlar.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCM'ler: LLM Tokenizasyonundan Kavram Düzeyinde Gösterime}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Ocak 23, 2026}
}

Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.