İlişkisel Temel Modelleri Karşılaştırın
17 tabular veri setinde, yarı anlamsal-yarı sayısal spektrum, küçük/yüksek anlamsal tablolar, karmaşık iş veri setleri ve büyük düşük anlamsal sayısal veri setleri üzerinde gradient boosting (LightGBM, CatBoost) karşısında SAP-RPT-1-OSS benchmark'ını yaptık.
Amaçımız, ilişkisel bir LLM'in önceden eğitilmiş anlamsal öncüllerinin geleneksel ağaç modellerine göre avantaj sağlayabileceği ve ölçek altında veya düşük anlamsal yapıda zorluklarla karşılaştığı noktaları ölçmektir.
SAP-RPT-1-OSS vs. Gradient Boosting: Benchmark sonuçları
- Başarı Oranı: Ortalama normalize edilmiş puanı (0.0 ile 1.0 arası) temsil eder. Daha yüksek bir çubuk, modelin o kategorideki veri setleri için en olası performansa tutarlı bir şekilde daha yakın olduğunu gösterir.
- 100 – 500 satır (3 Veri Seti):
- Dahil Edilenler: wine (178), sonar (208), vote (435).
- Sonuç: SAP, 3 veri setinden 2'sinde en iyi performansı gösterdi. Wine ve sonar üzerinde en yüksek puanlara ulaştı, bu da LLM öncüllerinin eğitim verisi az olduğunda faydalı olabileceğini düşündürüyor. Ancak, CatBoost, vote veri setinde dar bir zafer elde etti (%0.1 içinde), bu da ağaç modellerinin küçük ölçeklerde bile son derece rekabetçi kaldığını gösteriyor.
- 501 – 1.000 satır (3 Veri Seti):
- Dahil Edilenler: cylinder_bands (540), breast_cancer (569), credit_g (1.000).
- Sonuç: SAP, 3 veri setinde de en iyi performansı gösterdi. cylinder_bands üzerinde, SAP LightGBM'i %5.5'lik bir farkla geride bıraktı; bu durum, sanayi kusurlarının anlamsal açıklamalarının daha iyi işlenmesinden kaynaklanıyor olabilir, ancak bu mekanizmayı doğrulamak için daha fazla ablasyon çalışmasına ihtiyaç duyulacaktır.
- 1.000 – 10.000 satır (5 Veri Seti):
- Dahil Edilenler: titanic (1.3K), car_evaluation (1.7K), spambase (4.6K), compas (5.2K), employee_salaries (9.2K).
- Sonuç: SAP, 5 veri setinden 4'ünde en iyi sonuçları elde etti, özellikle spambase ve titanic gibi metin yoğun görevlerde oldukça iyi performans gösterdi. Ancak, CatBoost, compas üzerinde SAP'yi %10.4 oranında önemli ölçüde geride bıraktı, bu boyut aralığında bile ağaç modellerini tercih eden veri setine özgü özellikleri gösteriyor.
- 10.000+ satır (6 Veri Seti):
- Dahil Edilenler: california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Sonuç: Veri hacmi arttıkça, LLM'in potansiyel "önceki bilgi" avantajı azalıyor. LightGBM ve CatBoost, 6 veri setinden 5'inde en iyi sonuçları elde ederek, hesaplama maliyetinin çok daha düşük bir kısmında daha iyi doğruluk sağlıyor. Tek istisna olan california_housing, SAP için sadece mütevazı bir %1.7'lik avantaj gösteriyor.
1. Benchmark sonuçları veri setleri tablosu
Aşağıda, tüm 17 veri seti boyunca model performansının tam dökümü yer almaktadır.
2. Maliyet & verimlilik analizi
Her model için doğrudan hesaplama maliyetini, RunPod H200 örneği fiyatlandırması olan saatte 3,59 $ baz alarak hesapladık.
SAP-RPT-1-OSS, metin gömme ön işleme için gereken süre ve LLM mimarisinin ağır bellek yükü nedeniyle önemli ölçüde daha yüksek maliyetlere yol açıyor. Buna karşılık, LightGBM ve CatBoost, bu donanımda görevleri neredeyse anında tamamlıyor. Aşağıdaki maliyetler, 3 katlı çapraz doğrulama çalıştırması için toplam duvar saati süresini (ön işleme + eğitim) yansıtmaktadır.
Veri seti başına ortalama maliyet (17 Veri Seti Ort.)
Veri seti boyutuna göre maliyet dökümü
- Küçük Veri Setleri (<1K satır): SAP nispeten ucuzdur (çalışma başına ≈ 0,03 $). Buradaki yüksek kazanma oranı, maliyeti önemsiz hale getiriyor.
- Büyük Veri Setleri (>20K satır): SAP pahalı hale geliyor.
- Örnek: adult_income (48k satır) üzerinde eğitim, 3 kat için toplam ≈12 dakika sürüyor.
- Maliyet: 12 dk X 0,06 $/dk = çalıştırma başına 0,72 $.
- Karşılaştırma: LightGBM, aynı görevi 0,01 $ için tamamlıyor.
Sonuç: Veri seti başına 0,22 $ mutlak anlamda pahalı olmasa da, SAP tabandan 22 kat daha pahalıdır. Bu maliyet farkı, SAP'nin anlamlı doğruluk iyileştirmeleri gösterdiği küçük, zengin anlamsal veri setleri için (örneğin, +%5.5'lik artışla cylinder_bands) haklı çıkarılabilir, ancak ağaç modellerinin maliyetin çok daha düşük bir kısmında eşit veya daha iyi performans gösterdiği büyük veri setleri için haklı çıkarmak daha zor hale gelir.
3. Analiz çerçevesi: Anlamsal Spektrum
Bu sonuçları yorumlamak için veriyi nasıl seçtiğimizi anlamak çok önemlidir. Veri setlerini rastgele seçmedik; Anlamsal-Sayısal Spektrum'u kapsayacak şekilde özel olarak seçilen 17 veri setinden oluşan bir suite hazırladık.
Temel hipotezimiz, SAP'nin (LLM-tabanlı olduğu için) verinin dilsel anlam taşıdığı yerlerde parlayacağı, ağaç modellerinin ise ham sayısal hesaplamada baskın olacağıydı. Veri setlerimizi üç farklı kümeye ayırdık:
Küme A: Yüksek anlamsal veri setleri (6 veri seti)
Özellikler: Özellikler, zengin metin açıklamaları, gerçek dünya anlamına sahip kategorik etiketler (örneğin, "hekim ücret donması") veya alana özgü terminoloji içerir.
- Veri Setleri:
- cylinder_bands: Endüstriyel baskı kusurları.
- titanic: Yolcu isimleri ve unvanları.
- vote: Kongre oylama kayıtları (Politikalara ilişkin Kategorik "Evet/Hayır").
- breast_cancer: Tıbbi tümör açıklamaları.
- spambase: E-posta kelime frekansları.
- wine: Kimyasal kökenler.
Küme B: Karma iş verisi (6 veri seti)
Özellikler: Çoğu kurumsal veritabanında bulunan standart tabular format, sayısal değerlerin (maaş, yaş) ve kategorik dizelerin (unvan, ırk, departman) bir karışımı.
- Veri Setleri:
- employee_salaries: Unvanlar vs. maaş.
- compas: Suç geçmişi ve demografi (Hassas nitelikler).
- adult_income: Nüfus sayımı demografisi.
- credit_g: Alman kredi risk profilleri.
- default_credit: Tayvan kredi temerrüt verisi.
- car_evaluation: Araç satın alma parametreleri.
Küme C: Düşük anlamsal/saf sayısal veri (5 veri seti)
Özellikler: Özellikler soyut ölçümler, sensör okumaları veya fizik koordinatlarıdır. Sütun adları genellikle önemli değildir; sadece matematiksel ilişkiler önemlidir.
- Veri Setleri:
- higgs_100k: Fizik parçacık kinematiği.
- diamonds: Fiziksel boyutlar ve fiyat.
- sonar: Frekans enerji sıçramaları.
- california_housing: Enlem/Boylam koordinatları ve nüfus sayımı istatistikleri.
- house_sales: King County emlak (çoğunlukla sayısal özellikler).
4. Derinlemesine inceleme: SAP nerede kazanır vs. başarısız olur
Analiz çerçevesini sonuçlarımıza uygulamak, dört farklı performans deseni ortaya çıkarıyor. Aşağıdaki tablo, SAP'nin tam olarak nerede başarılı olduğunu ve nerede bozulduğunu özetlemektedir.
İlişkisel temel modellerin kavramsal temelleri
İlişkisel bir temel modelin ana amacı, yapılandırılmış tablolar üzerinde doğru tahminler yapmak ve çeşitli görevleri yerine getirmektir. Bu modellerin, bilginin farklı tablolar arasında nasıl temsil edildiğini, varlıkların ilişkiler aracılığıyla nasıl bağlandığını ve zamansal bilginin sonuçları nasıl etkilediğini anlaması gerekir.
Bu tür modellerin temel yetenekleri şunlardır:
- Sema genelleştirme: Sıfırdan yeniden eğitim yapmadan yeni ilişkisel şemalara uyum sağlama yeteneği.
- Birleştirilmiş girdi temsili: Sayısal, kategorik ve metinsel özellikler gibi farklı sütun türlerini işleme.
- Zamansal ve yapısal bağlamın entegrasyonu: Zaman boyunca ve birincil ve dış anahtarlarla bağlanan varlıklar arasında bağımlılıkları yakalama.
- Transfer edilebilirlik: Önceden eğitim ve sıfır-çekim öğrenme yoluyla yeni veri setlerinde tahmin görevlerini yerine getirme.
Griffin
Griffin, birleştirilmiş bir ilişkisel temel model oluşturma girişimlerinden ilkidir. İlişkisel veriyi, her satırın bir düğüm olduğu ve kenarların dış anahtar ilişkilerine karşılık geldiği zamansal, heterojen bir grafik olarak temsil eder. Temel özellikleri şunlardır:
Birleştirilmiş özellik kodlayıcı
- Kategorik ve metin özellikleri önceden eğitilmiş bir metin kodlayıcı ile kodlanırken, sayısal değerler öğrenilmiş bir float kodlayıcı kullanır.
- İlişkisel şemayı tanımasına yardımcı olmak için tablo adları, sütun adları ve kenar türleri gibi meta veriler gömülür.
- Görev gömüleri, tek bir modelin paylaşılan dekoderlerle regresyon ve sınıflandırma görevlerini yerine getirmesini sağlar.
Mesaj iletimi ve dikkat
Griffin, mesaj iletimi sinir ağlarını çapraz dikkat modülü ile entegre eder. Mesaj iletimi bileşeni, ilişkiler içinde ve arasında bilgiyi birleştirirken, çapraz dikkat her satır içinde ilgili hücrelere odaklanır. Bu tasarım, modelin çeşitli verileri işlemesine ve bağlı varlıklar arasında bağlamı korumasına yardımcı olur.
Önceden eğitim ve ince ayar
Model, tek tablo veri setlerinde maskelenmiş hücre tamamlama görevi aracılığıyla önceden eğitilir ve ardından belirli görevler için ilişkisel veritabanlarında ince ayar yapılır. Büyük ilişkisel benchmark'lar üzerindeki deneyler, Griffin'in hem doğruluk hem de transfer öğrenme verimliliği açısından geleneksel GNN taban çizgilerini ve tek tablo modellerini geride bıraktığını göstermektedir.
Şekil 1: Griffin Model Çerçevesini gösteren grafik.1
İlişkisel transformer
Griffin grafik birleştirmeye odaklanırken, İlişkisel Transformer (RT), transformer mimarilerini doğrudan ilişkisel veritabanlarına uygular. Her hücreyi, değeri, sütun adı ve tablo adı ile zenginleştirilmiş bir token olarak ele alır.
Girdi temsili
Her token şunları birleştirir:
- Veri tipine (sayısal, metin veya tarih-saat) bağlı bir değer gömüsü.
- Tablo ve sütun metninden üretilen bir şema gömüsü.
- Önceden eğitim sırasında değer gizlendiğinde kullanılan bir mask token.
Bu yapı, RT'nin farklı şemalara sahip ilişkisel veritabanlarını tutarlı bir girdi formatını koruyarak işlemesini sağlar.
İlişkisel dikkat
RT, hücre düzeyinde çalışan bir ilişkisel dikkat mekanizması getirir. Şunları içerir:
- Sütun dikkat sütunlar içinde değer dağılımlarını öğrenmek için.
- Özellik dikkat aynı satır veya bağlı üst satırlar içindeki nitelikleri birleştirmek için.
- Komşu dikkat bağlı alt satırlardan bilgiyi birleştirmek için.
Birlikte, bu dikkat katmanları satırlar, sütunlar ve tablolar arasında bağımlılıkları modelleyen bir ilişkisel grafik transformer oluşturur.
Eğitim ve transfer sonuçları
RT, RelBench'ten ilişkisel veritabanlarında önceden eğitilir. Deneylerde, önceden eğitilmiş model, sıfır-çekim ortamlarında tam denetimli modellerin performansının %94'üne kadar ulaştı. İnce ayar sırasında daha hızlı öğrendi ve yüksek doğruluğa ulaşmak için daha az eğitim adımı gerektirdi.2
Bu yaklaşım, ilişkisel veritabanlarının alanlar arasında transfer edilebilir desenler paylaştığını ve hücre düzeyi tokenizasyonun yapılandırılmış veriler üzerinde tahmin görevleri için pratik bir temel sağladığını öne sürmektedir.
RelBench
RelBench, ilişkisel veritabanlarında birden fazla ilgili tabloya dağıtılmış veriden uçtan uca öğrenmeye odaklanan ilişkisel derin öğrenmeyi ilerletmek için tasarlanmıştır.
İlişkisel veritabanları, endüstri ve bilim genelinde baskın veri yönetim sistemi olmaya devam ettiği için, RelBench, manuel özellik düzleştirme yerine doğrudan ilişkisel yapılar üzerinde çalışan modelleri değerlendirmek için standartlaştırılmış ve tekrarlanabilir bir çerçeve sağlar.
RelBench'in önceki sürümleri, sağlık hizmetleri, sosyal ağlar, e-ticaret ve spor gibi alanları kapsayan 11 ilişkisel veri seti ve hem zorlayıcı hem de alana özgü olacak şekilde tasarlanmış 70 tahmin görevi tanıttı.3
Ocak 2026'da RelBench v2 yayımlandı; SALT, RateBeer, arXiv ve MIMIC-IV olmak üzere dört yeni veri seti ve bir ilişkisel veritabanı içindeki mevcut sütunları tahmin etme yeteneğini değerlendiren yeni bir Otomatik Tamamlama görevi sınıfı da dahil olmak üzere 40 ek tahmin görevi eklendi.
Yayın ayrıca, ReDeLEx aracılığıyla 70'ten fazla ilişkisel veri setine erişimi sağlayan CTU entegrasyonu yoluyla veri erişimini genişletti; doğrudan SQL veritabanı bağlantısı ekledi; ve RelBench formatında 4DBInfer deposundan yedi veri setini entegre etti.
Veri setleri ve görevlerin ötesinde, RelBench, grafik oluşturma için PyTorch Geometric ve tabular modelleme için PyTorch Frame kullanarak grafik sinir ağlarına dayalı ilişkisel derin öğrenme için açık kaynaklı bir referans uygulaması sağlar ve ilerlemeyi takip etmek için halka açık bir liderlik tablosu sunar.
v2 sürümü ayrıca, isteğe bağlı zaman-sansürlü etiketler, bağlantı tahmininde NDCG metriği desteği, daha hızlı cümle-gömme oluşturma ve yapılandırılabilir önbellek yönetimi dahil olmak üzere çok sayıda kullanılabilirlik ve performans iyileştirmesi getirdi.4
VIEIRA
VIEIRA, tek bir tahmin motoru oluşturmaktan ziyade temel modellerle programlamaya odaklanarak farklı bir yaklaşım benimser. SCALLOP olasılıklı mantık derleyicisini, büyük dil modelleri, görüntü modelleri ve diğer önceden eğitilmiş bileşenleri yabancı öngörüler olarak entegre eden bir bildirimci dil ile genişletir.5
İlişkisel paradigma
VIEIRA'da, temel modeller, ilişkisel girdilere ve çıktılara sahip durum olmayan işlevler olarak ele alınır. Bu, GPT, CLIP veya SAM gibi modellerin mantıksal kurallara göre birleştirilmesini sağlar. Örneğin:
- Bir program, metinden bilgi çıkarmak ve bunu yapılandırılmış ilişkiler olarak saklamak için GPT kullanabilir.
- CLIP, görüntüleri sınıflandırabilir ve bunları bir tablodaki metinsel etiketlerle bağlayabilir.
Uygulamalar
Çerçeve şunları destekler:
- GPT kullanarak tarih ve matematik akıl yürütme.
- Metin çıkarma ve mantıksal çıkarım kullanarak akrabalık akıl yürütme.
- Getiriyi ve akıl yürütmeyi birleştiren soru-cevap.
- Çok modlu birleştirme yoluyla görsel soru-cevap ve görüntü düzenleme.
Sembolik mantığı ve sinirsel çıkarımı birleştirerek VIEIRA, veri analistlerinin ve geliştiricilerin yapılandırılmış veriler ve görüntüler üzerinde tahmin sorularını yanıtlamak için önceden eğitilmiş temel modelleri kullanan yorumlanabilir sistemler oluşturmasına olanak tanır.
Vaka çalışmaları
SAP Hana Cloud
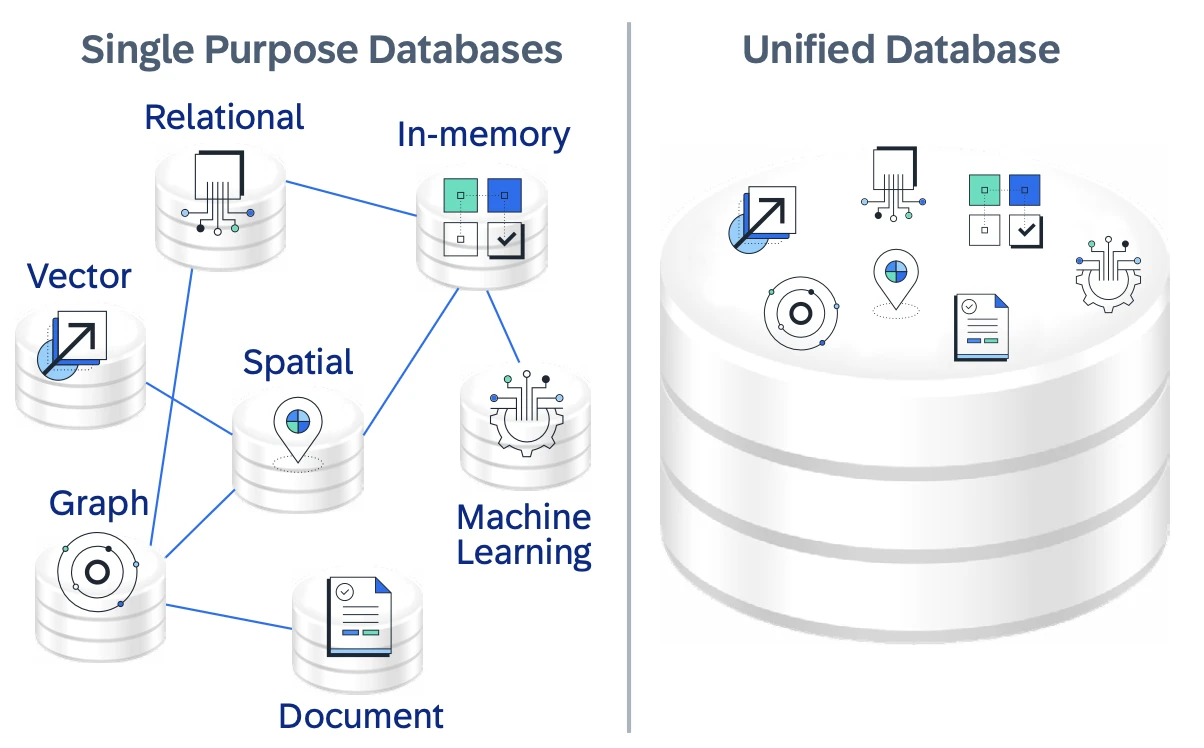
SAP HANA Cloud, işlemleri, analitikleri ve AI'ı birleştiren kurumsal uygulamalar için birleştirilmiş bir veri temeli olarak hareket etmek üzere tasarlanmış, yerel bulut, tam yönetilen bir veritabanı-hizmetidir. Tek amaçlı bir ilişkisel veritabanı olarak hizmet vermek yerine, SAP HANA Cloud, kuruluşların operasyonel iş verilerinin üzerine "akıllı veri uygulamaları" oluşturmasını sağlayan çok modelli bir platform olarak konumlandırılmıştır.
SAP HANA Cloud, farklı performans ve maliyet gereksinimlerini desteklemek için bellek içi işlemi, disk tabanlı depolama ve veri gölü entegrasyonu ile birleştirir. Bu esnek tasarım, gerçek zamanlı iş yüklerini desteklerken veri hacimleri ve kullanım dalgalanmasıyla birlikte dinamik olarak ölçeklenir.
Temel bir ayırt edici özellik, tek bir veritabanı içinde ilişkisel, JSON/belge, grafik, mekansal ve vektör verilerini destekleyen yerel çok modelli motorudur. Bu, uygulamaların veriyi ayrı sistemler arasında taşımadan SQL sorgularını, grafik ilişkilerini ve vektör benzerliği aramasını birleştirmesini sağlayarak mimariyi basitleştirir ve gecikmeyi azaltır.
SAP Business Technology Platform'un bir parçası olarak, SAP HANA Cloud, SAP ve SAP dışı veri kaynaklarıyla doğrudan entegre olur, çoğaltma olmadan canlı erişim sağlar ve varsayılan olarak kurumsal düzeyde güvenlik, kullanılabilirlik ve uyumluluk sağlar.
Genel olarak, SAP HANA Cloud, ilişkisel veritabanının analitik, çok modelli veri ve kurumsal AI uygulamaları için temel katman olarak hizmet verdiği, ilişkisel odaklı, AI-yerel bir veri platformudur.
Şekil 2: Hana'nın birleştirilmiş veritabanını ve
çok modelli veri işleme işlemini gösteren görüntü.6
SAP'nin sap-rpt-1
sap-rpt-1, bağlam içinde öğrenme yoluyla geniş bir yelpazede tahmin görevleri gerçekleştiren tek bir ilişkisel temel model tanıtır. Her kullanım durumu için yeni bir model yeniden eğitmek yerine, kullanıcılar "zamanında ödeme yapan müşteriler" ve "geç ödeme yapan müşteriler" gibi hedef desenlerinin birkaç örneğini sağlar. Model ardından deseni tanır ve yeni veriler için hemen doğru tahminler üretir.
Model, satırlar ve sütunlar arasındaki ilişkileri yakalayan ve aynı zamanda tablo ve sütun adları gibi meta verileri vektör gömülerine gömen iki boyutlu bir dikkat mekanizması ile tasarlanmıştır. Bu tasarım, ilişkisel şemaların anlamlarını ve iş tablolarındaki zamansal bilgileri anlamasını sağlar.
SAP'nin yaklaşımı, veri analistleri ve iş kullanıcıları için birkaç avantaj getirir:
- Çoklu tablolar ve alanlar üzerinde çalışan tek bir model.
- Tekrarlanan ince ayar veya özel geliştirme ihtiyacı yok.
- Haftalar yerine dakikalar içinde tahmin içgörülerine erişim.
- Mevcut veri ambarları ve SAP sistemleriyle entegrasyon.
sap-rpt-1'i SAP ekosistemi içine gömerek, iş uzmanları kendi verileriyle doğrudan etkileşime girebilir ve sezgisel arayüzler aracılığıyla tahminler alabilirler. Sonuç, manuel özellik mühendisliği olmadan yapılandırılmış veriden uygulanabilir kararlara daha hızlı bir yoldur.
Şekil 3: SAP alanları boyunca dar-AI taban çizgilerine karşı sap-rpt-1-large'ın hata azaltma faktörü.
2025'in sonu itibarıyla SAP, SAP-RPT-1'in SAP AI Foundation (SAP AI Core) içindeki üretken AI hub aracılığıyla genel olarak kullanıma hazır olduğunu doğruladı.
Model, iki üretim varyantında sunulur:
- Düşük gecikme ve yüksek iş hacimli tahminler için optimize edilmiş SAP-RPT-1-small,
- Tahmin doğruluğunu önceliklendirmek üzere tasarlanmış SAP-RPT-1-large.
Bu yayın, SAP-RPT-1'in sadece araştırma amaçlı bir yetenek olmaktan ziyade, SAP'nin kurumsal AI yığını içinde dağıtılabilir bir temel model olarak rolünü resmiyetleştirir.
Ayrıca, SAP, kullanıcıların kendi veya SAP tarafından sağlanan örnek verileri kullanarak bağlam içinde öğrenmeyi test edebilecekleri bir kodsuz, web tabanlı ortam olan SAP-RPT Playground'u sunar.
SAP-ABAP-1
SAP-ABAP-1, SAP müşterileri ve ortakları için AI tabanlı geliştirici verimliliği kullanım durumlarını desteklemek üzere tasarlanmış bir temel modeldir.
SAP'nin üretken AI hub aracılığıyla kullanıma sunulur ve 250 milyondan fazla ABAP kodu, 30 milyon satır CDS kodu ve kapsamlı teknik dokümantasyon üzerinde eğitilir. Model, ABAP kodunu anlamak ve açıklamak, en iyi uygulamaları ortaya çıkarmak ve güncel SAP geliştirme bilgisine erişim sağlamak için optimize edilmiştir.
SAP, generatif AI hub üzerinden SAP-ABAP-1'e ücretsiz deneme erişimi sunar ve 2026'da ek yeteneklerin yayımlanması planlanmaktadır.7
Kumo.AI'nin KumoRFM: tahmin analitiği için bir ilişkisel grafik transformer
Stanford profesörü Jure Leskovec tarafından kurulan Kumo.AI, ilişkisel veritabanlarını ve veri ambarlarını analiz etmek için bir ilişkisel grafik transformer kullanan KumoRFM adlı bir ilişkisel temel model oluşturdu. İlişkisel veriyi, her varlığın bir düğüm olduğu ve birincil ve dış anahtarların tablolar arasında kenarlar oluşturduğu zamansal, heterojen bir grafik olarak temsil eder.
Bu grafik tabanlı yaklaşım, KumoRFM'nin aynı anda birden fazla tablodan öğrenmesine ve yeni ilişkisel şemalara uyum sağlamasına olanak tanır. Model, çeşitli veri kaynaklarında önceden eğitilir ve her tahmin görevi için ayrı modeller oluşturmadan yeni veri setlerine genelleştirilebilir.
KumoRFM, kullanıcı uzmanlığına bağlı olarak farklı arayüzler aracılığıyla kullanılabilir:
- PQL (Tahmin Sorgu Dili): Yapılandırılmış veriler üzerinde tahmin sorgularını tanımlamak için özel bir sorgu dili.
- Doğal dil arayüzü: Teknik olmayan kullanıcılar için, doğal dil girdileri otomatik olarak PQL sorgularına çevrilir.
- Python SDK: Geliştiricilerin modeli kurumsal AI pipeline'larına ve uygulamalarına entegre etmesine olanak tanır.
KumoRFM mimarisi, bağlam alt grafikleri ve tahmin alt grafikleri oluşturmak için veritabanını dinamik olarak örneklendirir. Bu alt grafikler, ilişkili varlıklar arasında bağımlılıkları ve zamansal bilgileri yakalayan ilişkisel grafik transformer tarafından işlenir. Bağlam içinde öğrenme yoluyla model, doğru tahminler sağlar ve akıl yürütme sürecini açıklayabilir.
Kumo, kurumsal ortamlara uygun iki dağıtım seçeneği sunar:
- SaaS platformu: Kolay erişim ve ölçeklendirme için Apache Spark üzerine inşa edilmiş bulut tabanlı bir hizmet
- Veri ambarı yerel: Kuruluşların verilerini güvenli ortamlarının dışına taşımadan Snowflake veya Databricks'te kendi verilerini kullanmalarına olanak tanır
Manuel şema tanımı gerektiren geleneksel bilgi grafiklerinin aksine, KumoRFM ilişkisel grafiğini yapılandırılmış kaynaklardan otomatik olarak oluşturur. Bu, ilişkilerin, zamansal desenlerin ve gelişen bağlamın güvenilir tahminler için önemli olduğu e-ticaret, finans ve sağlık hizmetleri için oldukça uygundur.
KumoRFM'nin temel yetenekleri şunlardır:
- Farklı tablolar ve şema yapıları arasında esneklik.
- Çeşitli sütun türleri ve özel tanımlayıcılarla uyumluluk.
- Çıkarım sırasında belirli görevlere uyum.
- Tahmin görevlerinde yüksek doğruluk ve yorumlanabilirlik.
Şekil 4: Görüntü, İlişkisel Temel Modellerin (RFM'lerin) tahmin yapma, açıklamalar sağlama ve sonuçları değerlendirme amacıyla e-ticaret, finans ve sağlık hizmetleri gibi birden fazla alanda nasıl çalıştığını göstermektedir.8
Benchmark metodolojisi
Benchmark kurulumu & ortamı
CPU-bağımlı ağaçlar ile GPU-hızlandırılmış modeller arasında adil karşılaştırmalar sağlamak için, her ikisini de verimli bir şekilde işleyebilen yüksek performanslı bir ortam kullandık.
- Donanım: NVIDIA H200 140GB GPU içeren RunPod örneği.
- Yazılım: Tekrarlanabilirlik için sabitlenmiş kütüphanelerle Python 3.12:
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Kaynak: Resmi GitHub)
- Tekrarlanabilirlik: random_state=42, tüm bölümler, başlatmalar ve modellerde tutarlı bir şekilde kullanıldı.
Veri setleri: Anlamsal spektrum
Modelleri, OpenML ve Scikit-Learn'den temin edilen 17 denetimli öğrenme veri seti üzerinde değerlendirdik. Rastgele seçim yerine, LLM'lerin özelliklerin sadece ham istatistikler değil, dilsel anlam içerdiği yerlerde başarılı olacağı hipotezini test etmek için bu suite'i "Anlamsal-Sayısal Spektrum"u kapsayacak şekilde hazırladık.
Envanter:
- Küçük & anlamsal (<1K satır):
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Orta/karma (1K – 10K satır):
- credit_g (1K), titanic (1.3K), car_evaluation (1.7K), spambase (4.6K), compas (5.2K), employee_salaries (9.2K).
- Büyük/sayısal (10K+ satır):
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (100K'ya örneklendirildi).
Kapsanan görevler:
- 11 İkili Sınıflandırma görevi
- 2 Çok sınıflı Sınıflandırma görevi
- 4 Regresyon görevi
Model yapılandırmaları & ön işleme
Yorucu hiperparametre ayarı yerine güçlü varsayılanları kullanarak gerçekçi bir "uygulayıcı karşılaştırması" hedefledik.
LightGBM & CatBoost
Hesaplama açısından ağır olan SAP modeline karşı adil bir karşılaştırma sağlamak için, sağlam varsayılan tahmin edicileri artırdık.
- LightGBM: n_estimators=500, learning_rate=0.05, num_leaves=31. CPU üzerinde çalışır (n_jobs=-1).
- CatBoost: iterations=500, learning_rate=0.05, depth=6. GPU üzerinde çalışır (task_type="GPU").
- Ön işleme: Kategorikler için basit Label Encoding; sayılar için ölçeklendirme yok; eksik değerler için medyan/mod imputasyonu.
SAP-RPT-1-OSS
Ön yapılandırma deneylerimize dayanarak performansı ve maliyeti dengelemek için SAP'yi yapılandırdık.
- Yapılandırma: max_context_size=4096, bagging=4.
- Not:
- Bağlam: adult_income üzerinde yapılan testler, bağlamın 4096'dan 8192'ye artırılmasının, önemsiz doğruluk kazancı (0.917 vs 0.917 ROC-AUC) için çalışma süresini üç katına çıkardığını (4 dk'dan 12 dk'ya) gösterdi.
- Bagging: Bagging'in 4'ten 8'e (makalede kullanılan SAP'nin varsayılan ayarı9 ) artırılması azalan getiriler sundu.
- Ön işleme: Yok. Ham pandas DataFrame doğrudan iletilir. Model, metin gömüleri (sentence-transformers/all-MiniLM-L6-v2) kullanarak kodlar.
Değerlendirme protokolü
Çapraz doğrulama stratejisi
Karıştırma ile 3-Katlı Çapraz Doğrulama kullandık.
- SAP'nin yavaş çıkarım sürelerine uyum sağlamak için standart 5-katlıyı 3-katlıya düşürdük (%40 zaman tasarrufu) ve istatistiksel geçerliliği koruduk.
- Bölme: Sınıflandırma için StratifiedKFold; regresyon için Standart K-Fold.
Metrikler & teşhisler
Model performansının bütüncül bir görünümünü yakalamak için basit doğrulamanın ötesine geçtik:
- Temel sıralama metrikleri: ROC-AUC (İkili), Dengeli Doğruluk (Çok sınıflı), R² (Regresyon).
- İkincil teşhisler: Kazanımların sınıf dengesizliğinin artefaktları olmadığından emin olmak için Matthews korelasyon katsayısı (MCC) ve log kayıp değerlerini takip ettik ve regresyon hatası kalibrasyonu için MAPE.
- Maliyet hesaplaması: RunPod H200 örneğinde ($3.59/sa) toplam duvar saati süresine (ön işleme + eğitim + çıkarım) dayanır.
İstatistiksel anlamlılık
Performans farklarının istatistiksel olarak anlamlı mı yoksa rastgele gürültü mü olduğunu belirlemek için çiftli model karşılaştırmalarına Wilcoxon işaretli sıra testi (p
Sınırlamalar & iç geçerlilik
Metodolojimizdeki aşağıdaki kısıtlamaları açıkça kabul ediyoruz:
- Standart yapılandırmalar vs ayar: Yoğun hiperparametre optimizasyonu (örneğin, iç içe CV veya Optuna taramaları) yerine tüm modeller için sabit, güçlü varsayılan yapılandırmalar kullandık. Bu tutarlı bir taban çizgisi sağlasa da, Ağaç modellerinin veri setine özgü ayarlamalarla performans kazanımları gördüğünü not etmek önemlidir; bu da "Rekabetçi" kümede marjları daraltabilir.
- Veri ölçeği sınırları: Analizimiz, tipik orta ölçekli kurumsal senaryoları simüle etmek için 100k satırın altındaki veri setlerine odaklandı. Veri hacmi arttıkça LLM'in avantajının azaldığını gözlemledik, ancak çıkarım gecikmesi ve maliyetin muhtemelen birincil kısıtlar haline geleceği milyon satırlık ölçeklere testi genişletmedik.
- Altyapı birliği: Tutarlı bir test ortamı korumak için tüm modelleri aynı NVIDIA H200 donanımında çalıştırdık. LightGBM ve CatBoost, ticari CPU'lar için son derece optimize edilmiştir; bu nedenle, yalnızca Ağaç modellerine adanmış bir üretim ortamında maliyet farkı muhtemelen daha geniş olacaktır.
- Anlamların ötesinde genelleştirme: "Anlamsal Spektrum" hipotezimiz birçok sonucu başarıyla öngördü, ancak LLM'in sonar ve california_housing gibi soyut veri setlerindeki güçlü performansı, dilsel anlamın ötesinde yetenekler öneriyor. Bu, modelin yüksek boyutlu düzenlileştirme desenlerinden de faydalanıyor olabileceğini, bu da bu ilk çalışmanın kapsamının ötesinde daha fazla araştırma gerektiren bir olgu olduğunu göstermektedir.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{İlişkisel Temel Modelleri Karşılaştırın}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Erişim tarihi: 2 Temmuz 2026}
}


 e-ticaret, finans ve sağlık hizmetleri gibi birden fazla alanda nasıl çalıştığını gösteriyor.")
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.