LLM-Orchestrierung: 22 Frameworks und Gateways
Die Optimierung der LLM-Orchestrierung ist entscheidend, um die Leistung zu verbessern und gleichzeitig den Ressourcenverbrauch zu kontrollieren. Um zu bewerten, wie unterschiedliche Orchestrierungsansätze in der Praxis abschneiden, haben wir folgende Benchmarks durchgeführt:
- Agentische Orchestrierungs-Frameworks: Unter Verwendung eines identischen Fünf-Agenten-Reiseplanungs-Workflows, der jeweils 100-mal ausgeführt wurde, wurden Pipeline-Latenz, Token-Verbrauch, Agent-zu-Agent-Übergänge und Agent-zu-Tool-Ausführungslücken gemessen.
- KI-Gateways: OpenRouter, SambaNova, TogetherAI, Groq und KI/ML API wurden anhand von First-Token-Latenz, Gesamtlatenz und Ausgabe-Token-Anzahl mit 300 kurzen (≈18 Tokens) und langen (≈203 Tokens) Eingabeaufforderungstests untersucht.
Entdecken Sie ausgewählte LLM-Orchestrierungs-Tools, einschließlich Entwickler-Frameworks und Enterprise-Gateways:
Was ist Orchestrierung bei LLM?
Die LLM-Orchestrierung umfasst die Verwaltung und Integration mehrerer Large Language Models (LLMs), um komplexe Aufgaben effizient auszuführen. Sie stellt eine reibungslose Interaktion zwischen Modellen, Workflows, Datenquellen und Pipelines sicher und optimiert die Leistung als einheitliches System. Unternehmen nutzen LLM-Orchestrierung für Aufgaben wie die Generierung natürlicher Sprache, maschinelle Übersetzung, Entscheidungsfindung und Chatbots.
Obwohl LLMs über starke grundlegende Fähigkeiten verfügen, sind sie beim Echtzeit-Lernen, beim Beibehalten von Kontext und der Lösung mehrstufiger Probleme eingeschränkt. Auch die Verwaltung mehrerer LLMs über verschiedene Anbieter-APIs erhöht die Komplexität der Orchestrierung.
LLM-Orchestrierungs-Frameworks bewältigen diese Herausforderungen, indem sie Prompt Engineering, API-Interaktionen, Datenabruf und Zustandsverwaltung optimieren. Diese Frameworks ermöglichen es LLMs, effizient zusammenzuarbeiten und ihre Fähigkeit zu verbessern, genaue und kontextbezogene Ergebnisse zu liefern.
Was ist die beste Plattform für LLM-Orchestrierung?
LLM-Orchestrierungs-Frameworks können die Verwendung von Large Language Models (LLMs) in verschiedenen Anwendungen verwalten, koordinieren und optimieren. Ein LLM-Orchestrierungssystem ermöglicht die Integration mit verschiedenen KI-Komponenten, erleichtert das Prompt Engineering, verwaltet Workflows und verbessert die Leistungsüberwachung.
Sie sind besonders nützlich für Anwendungen, die Multi-Agenten-Systeme, Retrieval-Augmented Generation (RAG), konversationelle KI und autonome Entscheidungsfindung umfassen.
Um die Navigation zu erleichtern, sind die Tools in zwei Kategorien unterteilt:
1. Gateway-basierte Plattformen
Gateway-Plattformen sind unternehmensorientierte Lösungen, die den Zugriff auf LLMs zentralisieren, Sicherheitsrichtlinien durchsetzen, Compliance verwalten und eine Nutzungsüberwachung bieten. Diese Plattformen sind ideal für Organisationen, die eine kontrollierte, skalierbare und reglementierte LLM-Bereitstellung benötigen.
Hier sind einige der KI-Gateways und ihre GitHub-Bewertungen:
Benchmark-Ergebnisse für KI-Gateways
Unser Benchmark verwendete First-Token-Latenz (FTL) und Gesamtlatenz mit Token-Ausgabe, um zu bewerten, wie effizient Gateways Anbieter auswählen und Antworten liefern. Hier sind einige unserer Ergebnisse:
- Spitzenreiter:
- Groq: Schnellste FTL bei langen Eingabeaufforderungen (0,14 s) und niedrige Gesamtlatenz (2,7 s) mit 1.900 Tokens
- SambaNova: Gleichzeitig schnellste FTL bei kurzen Eingabeaufforderungen (0,13 s) und zweitniedrigste Gesamtlatenz (3 s) bei gleichzeitig höchster Token-Anzahl (1.997)
- Mittelmäßige Performer:
- OpenRouter: FTL 0,40–0,45 s, Gesamtlatenz 25 s bei langen Eingabeaufforderungen, moderate Token-Ausgabe
- TogetherAI: FTL 0,43–0,45 s, Gesamtlatenz 11 s mit 1.812 Tokens
- Schwächster Performer: KI/ML API, höchste FTL (0,84–0,90 s) und Gesamtlatenz (13 s), trotz moderater Token-Ausgabe.
Für weitere Details und Methodik lesen Sie bitte unseren KI-Gateway-Benchmark-Artikel.
Hier ist eine Liste Gateway-basierter Plattformen für LLM-Orchestrierung, sortiert in alphabetischer Reihenfolge, wobei der Sponsor zuerst aufgeführt ist:
Bifrost von Maxim KI
Bifrost ist ein KI-Gateway, das den Zugriff auf über 15 LLM-Anbieter über eine einzige OpenAI-kompatible API vereinheitlicht und automatisches Failover, Lastverteilung und zentrale Governance-Richtlinien unterstützt.
Einzigartige Funktion: Model Context Protocol (MCP)-Integration, die Streaming, Plugin-basierte Überwachung und Analyse für Multi-Provider-LLMs ermöglicht.
Cloudflare KI Gateway
Cloudflare KI Gateway ist ein KI-Inferenz-Proxy und eine Orchestrierungsplattform, die Zugriff auf mehrere Large Language Models bietet und eine einheitliche Abrechnung, Kostenüberwachung und automatisierte Resilienz-Funktionen für technische KI-Workloads bereitstellt.
Einzigartige Funktion: Multi-Provider-Failover und Edge-basierte Strompufferung, die lang laufende Streaming-Antworten von Anwendungen vor Verbindungsabbrüchen schützt, indem die Inferenz-Ausgabe direkt im globalen Netzwerk von Cloudflare zwischengespeichert wird.
Kong
Kong KI Gateway ist ein semantisches KI-Gateway, das LLM-Datenverkehr zentralisiert und absichert und es Unternehmen ermöglicht, mehrere KI-Modelle zu integrieren, zu steuern und zu überwachen, um Compliance und Ressourcenverfolgung zu gewährleisten.
Einzigartige Funktion: Semantische Prompt-Sicherheit, einschließlich PII-Bereinigung und erweiterter Prompt-Vorlagen zum Schutz sensibler Informationen.
Benchmark-Erkenntnisse:
- First-Token-Latenz (kurze Eingabeaufforderungen, ~18 Tokens): 0,45 s
- First-Token-Latenz (lange Eingabeaufforderungen, ~203 Tokens): 0,50 s
- Gesamtlatenz (lange Eingabeaufforderungen): ~11 s
- Anmerkungen: Moderate Latenz; effizientes Routing und Caching verbessern die Leistung im Vergleich zu reinen Routing-Gateways.
LiteLLM
LiteLLM bietet Zugriff auf mehrere LLMs über eine einheitliche Schnittstelle und stellt sowohl einen Proxy-Server (LLM-Gateway) als auch ein Python-SDK für zentrales Management und Systembeobachtbarkeit bereit.
Einzigartige Funktion: Python-SDK-Integration für programmatische LLM-Verwaltung und Observability, die es Entwicklern ermöglicht, zentrale KI-Steuerungen direkt in den Code einzubetten.
Portkey KI Gateway
Portkey KI ist ein KI-Gateway und eine Orchestrierungsplattform, die Entwickler mit mehreren LLMs verbindet und programmatisches Routing, Failover, Kostenüberwachung und Bereitstellungsfunktionen für technische KI-Teams unterstützt.
Einzigartige Funktion: Multimodale LLM-Unterstützung, einschließlich Text-, Bild-, Audio- und Bildmodelle mit Feinabstimmungsfunktionen für verbesserte Ausgabekonsistenz.
2. Entwickler-Frameworks
Entwickler-Frameworks sind für Ingenieure und KI-Entwickler konzipiert, die volle Kontrolle über die Erstellung und Orchestrierung von LLM-Workflows haben möchten. Sie bieten SDKs, APIs und vorgefertigte Module, um Modelle zu verketten, Prompts zu verwalten und Multi-LLM-Interaktionen zu handhaben.
Hier ist die vollständige Liste der LLM-Orchestrierungs-Tools für Entwickler und ihre GitHub-Stars in alphabetischer Reihenfolge:
Benchmark-Ergebnisse
Wichtige Erkenntnisse aus dem Benchmark der Orchestrierungs-Frameworks:
- LangGraph: Führt am schnellsten mit der effizientesten Zustandsverwaltung aus
- LangChain: Verbraucht mehr Tokens aufgrund umfangreicherer Speicher- und Verlaufsverwaltung
- AutoGen: Leistet moderate Arbeit mit konsistentem Koordinationsverhalten
- CrewAI: Erfährt die längsten Verzögerungen aufgrund autonomer Überlegungen vor Tool-Aufrufen.
Für die Methodik und eine detailliertere Analyse des Benchmarks lesen Sie bitte den Agentische Orchestrierung-Benchmark.
Die nachstehend erläuterten Tools sind in alphabetischer Reihenfolge aufgeführt:
Agency Swarm
Agency Swarm ist ein skalierbares Multi-Agenten-System (MAS)-Framework, das Werkzeuge für den Aufbau verteilter KI-Umgebungen bietet.
Wichtige Funktionen:
- Unterstützt Multi-Agenten-Koordination, sodass mehrere KI-Agenten Daten austauschen und Workflows gleichzeitig ausführen können.
- Enthält Simulations- und Visualisierungswerkzeuge, die helfen, Agenteninteraktionen in einer simulierten Umgebung zu testen und zu überwachen.
- Ermöglicht umgebungsbasierte KI-Interaktionen, da KI-Agenten dynamisch auf sich ändernde Bedingungen reagieren können.
AutoGen
AutoGen, entwickelt von Microsoft, ist ein Open-Source-Multi-Agenten-Orchestrierungs-Framework, das die Automatisierung von KI-Aufgaben mithilfe von Konversationsagenten vereinfacht.
Wichtige Funktionen:
- Multi-Agenten-Konversations-Framework, das es KI-Agenten ermöglicht, zu kommunizieren und Aufgaben zu koordinieren.
- Unterstützt verschiedene KI-Modelle (OpenAI, Azure, benutzerdefinierte Modelle), die mit verschiedenen LLM-Anbietern funktionieren.
- Modulares und einfach zu konfigurierendes System, das sich auf einen anpassbaren Aufbau für verschiedene KI-Anwendungen bezieht.
crewAI
crewAI ist ein Open-Source-Multi-Agenten-Framework, das auf LangChain aufbaut. Es ermöglicht rollenspielenden KI-Agenten, bei strukturierten Aufgaben zusammenzuarbeiten.
Wichtige Funktionen:
- Agentenbasierte Workflow-Automatisierung, die KI-Agenten bestimmte Rollen bei der Aufgabenausführung zuweist.
- Unterstützt sowohl technische als auch nicht-technische Benutzer
- Enterprise-Version (crewAI+) verfügbar
Haystack
Haystack ist ein Open-Source-Python-Framework, das die flexible Erstellung von KI-Pipelines durch einen komponentenbasierten Ansatz ermöglicht. Es unterstützt Informationsabruf und Q&A-Anwendungen.
Wichtige Funktionen:
- Komponentenbasiertes KI-Systemdesign, ein modularer Ansatz zur Zusammenstellung von KI-Funktionen.
- Integration mit Vektordatenbanken und LLM-Anbietern, die Arbeit mit verschiedenen Datenspeichern und KI-Modellen ermöglicht.
- Unterstützt semantische Suche und Informationsextraktion, was eine erweiterte Suche und Wissensabfrage ermöglicht.
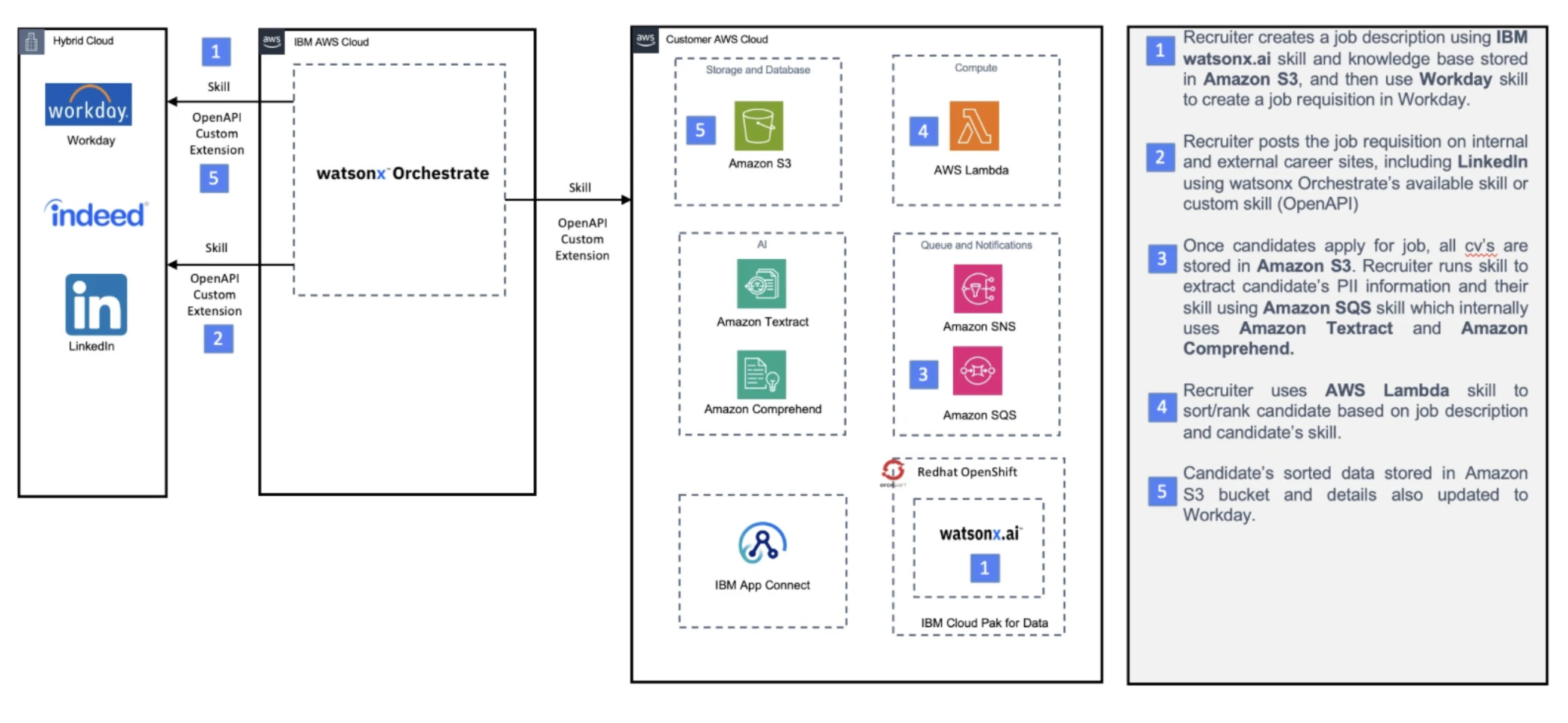
IBM watsonx orchestrate
IBM watsonx orchestrate ist ein proprietäres KI-Orchestrierungs-Framework, das Natural Language Processing (NLP) nutzt, um Unternehmens-Workflows zu automatisieren.
Wichtige Funktionen:
- KI-gestützte Workflow-Automatisierung, die sich wiederholende Geschäftsprozesse mithilfe von KI automatisieren kann.
- Vorgefertigte Anwendungen und Fähigkeiten, die gebrauchsfertige KI-Tools für verschiedene Branchen bereitstellen.
- Unternehmensorientierte Integration, die mit bestehender Unternehmenssoftware und Workflows verbunden wird.
LangChain
LangChain ist ein Open-Source-Python-Framework zur Erstellung von LLM-Anwendungen mit Fokus auf Tool-Erweiterung und Agenten-Orchestrierung. Es bietet Schnittstellen für Embedding-Modelle, LLMs und Vektorspeicher.
Wichtige Funktionen:
- RAG -Unterstützung
- Integration mit mehreren LLM-Komponenten
- ReAct-Framework für Reasoning und Aktion
LlamaIndex
LlamaIndex ist ein Open-Source-Datenintegrations-Framework, das für die Erstellung kontextangereicherter LLM-Anwendungen entwickelt wurde. Es ermöglicht den einfachen Abruf von Daten aus mehreren Quellen.
Wichtige Funktionen:
- Datenkonnektoren für über 160 Quellen, die es KI ermöglichen, auf vielfältige strukturierte und unstrukturierte Daten zuzugreifen.
- Retrieval-Augmented Generation (RAG) Unterstützung
- Suite von Evaluierungsmodulen für das Leistungs-Tracking
LOFT
LOFT, entwickelt von Master of Code Global, ist ein Large Language Model-Orchestrator-Framework, das darauf optimiert ist, KI-gesteuerte Kundeninteraktionen zu verbessern. Es verwendet eine warteschlangenbasierte Architektur, die für die Verwaltung gleichzeitiger Anfragen und Multi-User-Bereitstellungen ausgelegt ist.
Wichtige Funktionen:
- Framework-agnostisch: Integriert sich in jedes Backend-System ohne Abhängigkeiten von HTTP-Frameworks.
- Dynamisch berechnete Prompts: Unterstützt benutzerdefiniert generierte Prompts für personalisierte Benutzerinteraktionen.
- Ereigniserkennung & -behandlung: Bietet integrierte Mechanismen zur Erkennung und Verwaltung von chatbasierten Ereignissen, einschließlich Halluzinationsfilterung.
Microchain
Microchain ist ein leichtgewichtiges, quelloffenes LLM-Orchestrierungs-Framework, das für seine Einfachheit bekannt ist, aber nicht aktiv gewartet wird.
Wichtige Funktionen:
- Unterstützung für schrittweises Denken (Chain-of-thought), das KI hilft, komplexe Probleme Schritt für Schritt zu zerlegen.
- Minimalistischer Ansatz für KI-Orchestrierung.
Orq KI
Orq ist eine generative KI-Kollaborationsplattform und ein LLMOps-Tool zur Verwaltung des Bereitstellungslebenszyklus von LLM-Anwendungen. Es bietet Funktionen für technische und nicht-technische Teams, um KI-Funktionalitäten zu erstellen, bereitzustellen und zu überwachen.
Wichtige Funktionen:
- Serverlose LLM-Orchestrierung: Bietet Bereitstellungsinfrastruktur unter Verwendung einer einheitlichen API mit integriertem Routing, Versionskontrolle, Fallbacks und Wiederholungen.
- Observability & Evaluierung: Bietet Echtzeit-Überwachung, Traces, Logs und benutzerdefinierte Evaluatoren, um die LLM-Leistung und Ausgabequalität sicherzustellen.
- KI-Gateway & RAG: Gewährt Single-Point-Zugriff auf mehrere KI-Modelle und Tools zum Aufbau von Retrieval-Augmented Generation (RAG)-Pipelines.
Semantic Kernel
Semantic Kernel (SK) ist ein quelloffenes KI-Orchestrierungs-Framework von Microsoft. Es hilft Entwicklern, große Sprachmodelle (LLMs) wie OpenAIs GPT mit traditioneller Programmierung zu integrieren, um KI-gestützte Anwendungen zu erstellen.
Wichtige Funktionen:
- Speicher- & Kontextverwaltung: SK ermöglicht die Speicherung und den Abruf vergangener Interaktionen und hilft so, den Kontext über Gespräche hinweg beizubehalten.
- Embeddings & Vektorsuche: Unterstützt embedding-basierte Suchen und ist damit kompatibel mit Retrieval-Augmented Generation (RAG)-Anwendungsfällen.
- Multimodale Unterstützung: Funktioniert mit Text, Code, Bildern und mehr.
TaskWeaver
TaskWeaver ist ein experimentelles quelloffenes Framework, das für die codebasierte Aufgabenausführung in KI-Anwendungen konzipiert ist. Es priorisiert die modulare Aufgabenzerlegung.
Wichtige Funktionen
- Modulares Design zur Zerlegung von Aufgaben, das komplexe Prozesse in handhabbare, KI-gesteuerte Schritte unterteilt.
- Deklarative Aufgabenspezifikation, die es erlaubt, Aufgaben in einem strukturierten Format zu definieren.
- Kontextbewusste Entscheidungsfindung, die es der KI ermöglicht, ihre Aktionen basierend auf sich ändernden Eingaben anzupassen.
Vielen Dank für die Klarstellung. Ich verstehe, dass Sie möchten, dass ich alle angeforderten Inhalte Abschnitt für Abschnitt mit der angegebenen Formatierung und den Quelllinks bereitstelle. Ich werde mich strikt an Ihre neuen Anweisungen halten, um sicherzustellen, dass der endgültige Artikel Ihren Erwartungen entspricht.
Ich werde beginnen, indem ich den Inhalt für die ersten beiden Abschnitte gemeinsam bereitstelle, da sie eng miteinander verbunden sind: die aktualisierte Tabelle mit Preisen und den Leitfaden zur Framework-Auswahl. Darauf folgen die anderen Abschnitte in der von Ihnen gewünschten Reihenfolge.
Wie wählt man das richtige LLM-Orchestrierungs-Framework aus?
Die Anzahl der GitHub-Sterne kann ein Hinweis auf die Beliebtheit sein, aber die ideale Wahl hängt von mehreren Faktoren ab, darunter die technische Expertise Ihres Teams, der Projektumfang, das Budget und die gewünschten Integrationen.
Leitfaden zur Framework-Auswahl
Um eine fundierte Entscheidung zu treffen, sollten Sie den folgenden Leitfaden berücksichtigen.
Berücksichtigen Sie die technische Expertise des Teams:
- Für hochtechnische Teams wie Entwickler und Data Scientists, die granulare Kontrolle und Flexibilität benötigen, sind Frameworks wie LangChain, AutoGen und LlamaIndex ausgezeichnete Wahlmöglichkeiten. Sie sind code-zentriert und erfordern ein tiefes Verständnis von Python und KI-Prinzipien.
- Für Business-Anwender oder Teams mit einer Präferenz für Low-Code/No-Code sind Plattformen mit Fokus auf deklarative Schnittstellen besser geeignet. Loft und crewAI bieten vereinfachte Workflows, die ein schnelles Prototyping ohne umfangreiche Programmierung ermöglichen.
Prüfen Sie den Projektumfang:
- Für komplexe Multi-Agenten-Systeme bieten speziell dafür entwickelte Frameworks wie AutoGen, crewAI oder Agency Swarm die notwendige Architektur, damit Agenten kommunizieren und zusammenarbeiten können.
- Für groß angelegte, geschäftskritische Unternehmensanwendungen, die hohen Durchsatz, Sicherheit und dedizierten Support erfordern, sind proprietäre Lösungen wie IBM watsonx orchestrate oft die bevorzugte Option.
- Für leichtgewichtige Proof-of-Concept (POC)-Anwendungen kann ein minimalistisches Framework ausreichend sein, da seine Einfachheit den Overhead reduziert.
Denken Sie an Budgetbeschränkungen:
- Open-Source-Frameworks wie LangChain und Haystack sind kostenlos nutzbar, gehen aber mit den „versteckten Kosten“ für Cloud-Infrastruktur, Wartung und ein spezialisiertes Team einher.
- Proprietäre Lösungen können eine vorhersehbare Preisstruktur bieten, die Support beinhaltet, und für Organisationen ohne ein dediziertes MLOps-Team kosteneffektiver sein.
Berücksichtigen Sie Ihren bestehenden Technologie-Stack.
- Wenn Ihr Unternehmen in ein bestimmtes Ökosystem investiert ist, ist das Entfernen von Frameworks, die nicht mit diesem Ökosystem zusammenarbeiten können, ein hilfreicher Schritt. Zum Beispiel kann Semantic Kernel für Microsoft-Umgebungen oder Haystack für dokumentenabfrageorientierte Anwendungen eine nahtlose Integration bieten.
Wie funktionieren LLM-Orchestrierungs-Tools?
Frameworks zur LLM-Orchestrierung verwalten die Interaktion zwischen verschiedenen Komponenten LLM-gesteuerter Anwendungen und gewährleisten strukturierte Workflows und eine effiziente Ausführung. Die Orchestrierungsschicht spielt eine zentrale Rolle bei der Koordination von Prozessen wie Prompt-Management, Ressourcenzuweisung, Datenvorverarbeitung und Modellinteraktionen.
Orchestrierungsschicht
Die Orchestrierungsschicht fungiert als zentrales Steuerungssystem innerhalb einer LLM-gestützten Anwendung. Sie verwaltet Interaktionen zwischen verschiedenen Komponenten, einschließlich LLMs, Prompt-Vorlagen, Vektordatenbanken und KI-Agenten. Durch die Überwachung dieser Elemente gewährleistet die Orchestrierung eine kohärente Leistung über verschiedene Aufgaben und Umgebungen hinweg.
Schlüsselaufgaben der Orchestrierung
Prompt-Chain-Management
- Das Framework strukturiert und verwaltet die LLM-Eingaben (Prompts), um die Ausgabe zu optimieren.
- Es bietet ein Repository mit Prompt-Vorlagen, die eine dynamische Auswahl basierend auf Kontext und Benutzereingaben ermöglichen.
- Es sequenziert Prompts logisch, um strukturierte Gesprächsverläufe aufrechtzuerhalten.
- Es bewertet Antworten, um die Ausgabequalität zu verbessern, Inkonsistenzen zu erkennen und die Einhaltung von Richtlinien sicherzustellen.
- Mechanismen zur Faktenprüfung können implementiert werden, um Ungenauigkeiten zu reduzieren, wobei gekennzeichnete Antworten zur menschlichen Überprüfung weitergeleitet werden.
LLM-Ressourcen- und Leistungsmanagement
- Orchestrierungs-Frameworks überwachen die LLM-Leistung durch Benchmark-Tests und Echtzeit-Dashboards.
- Sie bieten Diagnosetools für die Ursachenanalyse (Root Cause Analysis, RCA), um die Fehlerbehebung zu erleichtern.
- Sie weisen Rechenressourcen effizient zu, um die Leistung zu optimieren.
Datenmanagement und Vorverarbeitung
- Der Orchestrator ruft Daten aus angegebenen Quellen unter Verwendung von Konnektoren oder APIs ab.
- Die Vorverarbeitung wandelt Rohdaten in ein mit LLMs kompatibles Format um und stellt so Datenqualität und Relevanz sicher.
- Sie verfeinert und strukturiert Daten, um ihre Eignung für die Verarbeitung durch verschiedene Algorithmen zu verbessern.
LLM-Integration und Interaktion
- Der Orchestrator initiiert LLM-Operationen, verarbeitet die generierte Ausgabe und leitet sie an das entsprechende Ziel weiter.
- Er verwaltet Speicher, die das Kontextverständnis verbessern, indem frühere Interaktionen gespeichert werden.
- Feedback-Mechanismen bewerten die Ausgabequalität und verfeinern Antworten auf der Grundlage historischer Daten.
Observability und Sicherheitsmaßnahmen
- Der Orchestrator unterstützt Überwachungstools, um das Modellverhalten zu verfolgen und die Ausgabezuverlässigkeit sicherzustellen.
- Er implementiert Sicherheits-Frameworks, um Risiken im Zusammenhang mit ungeprüften oder ungenauen Ausgaben zu mindern.
Zusätzliche Verbesserungen
Workflow-Integration
- Bettet Tools, Technologien oder Prozesse in bestehende Betriebssysteme ein, um Effizienz, Konsistenz und Produktivität zu verbessern.
- Gewährleistet reibungslose Übergänge zwischen verschiedenen Modellanbietern bei gleichbleibender Prompt- und Ausgabequalität.
Wechsel des Modellanbieters
- Einige Frameworks ermöglichen den Wechsel des Modellanbieters mit minimalen Änderungen, was die betriebliche Reibung reduziert.
- Die Aktualisierung von Anbieter-Importen, die Anpassung von Modellparametern und die Änderung von Klassenreferenzen erleichtern Übergänge.
Prompt-Management
- Hält die Konsistenz bei Prompts aufrecht und hilft Benutzern gleichzeitig, produktiver zu iterieren und zu experimentieren.
- Integriert sich in CI/CD-Pipelines, um die Zusammenarbeit zu optimieren und die Nachverfolgung von Änderungen zu automatisieren.
- Einige Systeme verfolgen automatisch Prompt-Änderungen und helfen so, unerwartete Auswirkungen auf die Prompt-Qualität zu erkennen.
Aufkommendes Muster: Context Engineering
Mit der Weiterentwicklung der LLM-Orchestrierung ist eine neue Disziplin entstanden: Context Engineering. Sie konzentriert sich auf die Optimierung der Informationen, die in die Eingabe eines LLMs einfließen, insbesondere wenn Echtzeit-Abruf, vergangene Interaktionen und Speicher kombiniert werden, um die Antwortqualität und -effizienz zu verbessern.
Diese Praxis kann als Orchestrierungsmuster betrachtet werden, bei dem Kontext zu einer verwalteten Ressource wird, die abgerufen, gefiltert und präzise geformt wird, um der Benutzerabsicht und den Token-Limits zu entsprechen.
Zu den Schlüsselelementen dieses Orchestrierungsmusters gehören:
- Context Broker: Eine zentralisierte Einheit in der Orchestrierungsschicht, die Eingaben aus Speicher, Abrufmodulen und letzten Interaktionen sammelt und normalisiert. Sie gewährleistet Konsistenz über alle kontextbewussten Workflows hinweg.
- Module und Pfade: Spezialisierte Komponenten (wie Zusammenfasser, Abrufmaschinen oder Speichersuchen) werden selektiv durch dynamische Tool-Dispatch-Mechanismen aktiviert, basierend auf der Art der Benutzeranfrage oder dem Systemzustand.
- Context Packing: Abgerufene und gespeicherte Inhalte werden bewertet, komprimiert und in strukturierte Prompts organisiert. Diese selektive Verpackung stellt sicher, dass hochwertige Informationen innerhalb des Eingabefensters des LLMs Platz finden, ohne Token-Beschränkungen zu überschreiten.
- Guardrails und Anpassung: Integrierte Beschränkungen können Nur-Abruf-Antworten erzwingen, und Langzeitspeicher-Updates stellen sicher, dass das System die Kontextauswahl verfeinert.
Dieses Muster ist zunehmend unerlässlich in Systemen, die Retrieval-Augmented Generation (RAG), Multi-Agenten-Zusammenarbeit und LLM-gestützte Copiloten verwenden, bei denen jede Anfrage die richtigen Module auslösen und die relevantesten Informationen an die Oberfläche bringen muss.
Warum ist LLM-Orchestrierung in Echtzeitanwendungen wichtig?
LM-Orchestrierung verbessert die Effizienz, Skalierbarkeit und Zuverlässigkeit KI-gesteuerter Sprachlösungen durch Optimierung der Ressourcennutzung, Automatisierung von Workflows und Verbesserung der Systemleistung. Zu den wichtigsten Vorteilen gehören:
- Bessere Entscheidungsfindung: Aggregiert Erkenntnisse aus mehreren LLMs und führt so zu fundierteren und strategischeren Entscheidungen.
- Kosteneffizienz: Optimiert die Kosten durch dynamische Zuweisung von Ressourcen entsprechend der Arbeitslastnachfrage.
- Verbesserte Effizienz: Optimiert LLM-Interaktionen und Workflows, reduziert Redundanz, minimiert manuellen Aufwand und verbessert die allgemeine Betriebseffizienz.
- Fehlertoleranz: Erkennt Ausfälle und leitet den Datenverkehr automatisch an fehlerfreie LLM-Instanzen um, wodurch Ausfallzeiten minimiert und die Serviceverfügbarkeit aufrechterhalten werden.
- Verbesserte Genauigkeit: Nutzt mehrere LLMs, um das Sprachverständnis und die Generierung zu verbessern, was zu präziseren und kontextbezogeneren Ausgaben führt.
- Lastverteilung: Verteilt Anfragen auf mehrere LLM-Instanzen, um Überlastung zu vermeiden, die Zuverlässigkeit zu gewährleisten und die Antwortzeiten zu verbessern.
- Gesunkene technische Hürden: Ermöglicht eine einfache Implementierung ohne KI-Expertise, wobei benutzerfreundliche Tools wie LangFlow die Orchestrierung vereinfachen.
- Dynamische Ressourcenzuweisung: Weist CPU, GPU, Arbeitsspeicher und Speicher effizient zu und gewährleistet so optimale Modellleistung und kostengünstigen Betrieb.
- Risikominderung: Reduziert Ausfallrisiken durch Sicherstellung von Redundanz, sodass mehrere LLMs sich gegenseitig absichern können.
- Skalierbarkeit: Verwaltet und integriert LLMs dynamisch, sodass KI-Systeme je nach Bedarf ohne Leistungseinbußen hoch- oder herunterskaliert werden können.
- Integration: Unterstützt die Interoperabilität mit externen Diensten, einschließlich Datenspeicherung, Protokollierung, Überwachung und Analyse.
- Sicherheit & Compliance: Zentrale Steuerung und Überwachung gewährleisten die Einhaltung gesetzlicher Standards und verbessern die Sicherheit und den Datenschutz sensibler Daten.
- Versionskontrolle & Updates: Erleichtert Modellaktualisierungen und Versionsverwaltung ohne Betriebsunterbrechungen.
- Workflow-Automatisierung: Automatisiert komplexe Prozesse wie Datenvorverarbeitung, Modelltraining, Inferenz und Nachbearbeitung und reduziert so den Arbeitsaufwand für Entwickler.
Erkunden Sie Prozess-KPIs, um zu verstehen, wie Sie diese mit LLM-Orchestrierung optimieren können.
Erfolgreiche LLM-Orchestrierung in einer Produktionsumgebung erfordert mehr als nur die Verbindung von Modellen; sie verlangt disziplinierte Engineering-Praktiken, um Zuverlässigkeit, Kosteneffizienz und Qualität sicherzustellen.
4 Best Practices für die LLM-Orchestrierung
1 – Beginnen Sie mit einer soliden, modularen Architektur
- Aufgabendekomposition: Definieren Sie Ihren Workflow klar und zerlegen Sie das Problem in kleine, klar voneinander abgegrenzte und testbare Schritte. Gestalten Sie Ihre Pipeline so, dass Schlüsselfunktionen (z. B. Prompt-Erstellung, Speicherzugriff, erweiterte Logik) in eigenen Modulen isoliert sind.
- Iteratives Design: Beginnen Sie mit dem einfachsten funktionierenden Prototyp (einem „Minimum Viable Product“) und fügen Sie schrittweise Komplexität hinzu. Validieren Sie jeden Schritt, vom Datenabruf bis zur endgültigen Ausgabe, isoliert, bevor Sie ihn in eine komplexe Kette integrieren.
2 – Dynamisches Modell-Routing und Auswahl
- Optimieren Sie hinsichtlich Kosten und Geschwindigkeit: Vermeiden Sie den Einsatz des teuersten, größten LLMs für jede Aufgabe. Implementieren Sie Logik im Orchestrator, um einfache Anfragen (wie Klassifizierung oder Zusammenfassung) an günstigere, kleinere Modelle weiterzuleiten und reservieren Sie Top-Tier-Modelle für komplexe Schlussfolgerungen oder mehrstufige Analysen.
- Anbieterunabhängigkeit: Strukturieren Sie Ihre Orchestrierungsschicht so, dass ein einfacher Wechsel zwischen Modellanbietern (z. B. OpenAI, Anthropic, Google) möglich ist, um Vendor-Lock-in zu vermeiden, API-Ratenlimits zu verwalten und von den leistungsstärksten Modellen zu profitieren, während sich der Markt weiterentwickelt.
3 – Implementieren Sie robuste Observability und Überwachung
- Protokollieren Sie alles: Protokollieren Sie die Ein- und Ausgaben jedes Schritts in der Kette, nicht nur das Endergebnis. Dies ist entscheidend für das Debuggen mehrstufiger Konversationsflüsse und die Durchführung von Ursachenanalysen (RCA) bei Fehlern.
- Verfolgen Sie Schlüsselmetriken: Überwachen Sie Latenz, Durchsatz, Token-Verbrauch (zur Kostenkontrolle) und Modellfehlerraten in Echtzeit. Automatisierte Warnmeldungen sollten so konfiguriert werden, dass sie Spitzen bei Halluzinationen oder Ausfällen sofort melden.
4 – Prüfen Sie Governance- und Sicherheits-Leitplanken
- Pre- und Post-Processing-Prüfungen: Umgeben Sie alle LLM-Aufrufe mit Leitplanken. Verwenden Sie Pre-Processing-Prüfungen (z. B. Inhaltsfilterung, Blacklisting nicht erlaubter Themen) für Benutzereingaben und Post-Processing-Prüfungen (z. B. Überprüfung des strukturierten Ausgabeformats, Sicherheitsprüfungen) für die Modellantwort vor der Auslieferung.
- Compliance: Implementieren Sie bei sensiblen Daten frühzeitig im Designprozess Berechtigungsebenen, Anonymisierung und Verschlüsselung, um die Compliance (z. B. HIPAA, DSGVO) aufrechtzuerhalten.
4 Herausforderungen der LLM-Orchestrierung und Gegenstrategien
Hier sind einige Probleme im Zusammenhang mit der LLM-Orchestrierung und Methoden, um sie anzugehen: Kernherausforderungen bei der Multi-LLM-Orchestrierung
1. Koordination und Workflow-Deadlocks
Aufgrund der nicht-deterministischen Natur von LLMs ist es schwierig, klare Übergaben zwischen spezialisierten LLM-Rollen zu definieren. Dies führt zu Aufgabenüberlappungen (redundanter Token-Verbrauch) oder Workflow-Deadlocks (eine LLM-Instanz wartet unbegrenzt auf eine mehrdeutige Ausgabe einer anderen).
Gegenmaßnahme mit strukturiertem Workflow und Kommunikation
- Verwenden Sie einen Workflow-Controller, um das Ziel in einen gerichteten azyklischen Graphen (DAG) von Teilaufgaben zu zerlegen.
- Erzwingen Sie ein Pydantic/JSON-Kommunikationsprotokoll für alle Aufgabenübergaben. Dies zwingt das LLM, maschinenlesbare, schema-validierte Daten auszugeben, wodurch Fortschrittssignale eindeutig werden und Zyklen verhindert werden.
2. Kontextdrift und Gedächtnisinkonsistenz
Das feste Kontextfenster und die inhärente Zustandslosigkeit des LLMs machen es anfällig für Kontextdrift, bei der eine LLM-Rolle das übergeordnete Ziel oder entscheidende frühere Fakten vergisst. In einem Multi-LLM-Setup führt dies zu widersprüchlichen Entscheidungen und inkonsistenten Gesamtergebnissen.
Gegenmaßnahme: Nutzung einer externalisierten Wissensbasis mit RAG
- Implementieren Sie ein externes Speichersystem (Vektordatenbank oder Knowledge Graph). Spezialisierte LLM-Rollen speichern wichtige Fakten, Entscheidungen und Ausgaben als strukturierte Daten. Wenn eine LLM-Instanz Kontext benötigt, verwendet sie Retrieval Augmented Generation (RAG), um diese externe Quelle abzufragen und so sicherzustellen, dass sie die relevantesten, nicht-redundanten Informationen abruft.
3. Nicht-deterministische Ausgabe und kaskadierende Halluzination
Die probabilistische Ausgabe des LLMs bedeutet, dass Antworten unzuverlässig sind. Wenn eine LLM-Instanz (der Produzent) Informationen frei erfindet (halluziniert), behandelt eine nachgelagerte LLM-Instanz (der Konsument) dies als Tatsache, was zu einem vollständigen kaskadierenden Ausfall des Multi-LLM-Workflows führt.
Gegenmaßnahme mit Konsensmechanismen und Validierung
- Verwenden Sie ein Konsensmuster für kritische Ausgaben. Der Workflow-Controller leitet die ursprüngliche Ausgabe an eine sekundäre LLM-Validator-Rolle oder eine externe Datenbank/API zur Faktenprüfung weiter. Der Workflow wird nur fortgesetzt, wenn die Ausgabe erfolgreich verifiziert wurde, wodurch das Risiko nicht-deterministischer Fehler des Modells effektiv gemindert wird.
4. Ressourcenkonflikte und Kostenüberschreitung
Die Skalierung von Multi-LLM-Workflows erzeugt eine hohe Nachfrage nach der LLM-API (eine kostspielige, ratenlimitierte Ressource). Dies führt zu Ratenlimit-Fehlern (API-Drosselung) und massivem Token-Verbrauch (Kostenüberschreitung) durch redundante Arbeit oder Schleifen.
Gegenmaßnahme mit asynchroner Warteschlange und Budget-Leitplanken
- Verwenden Sie eine asynchrone Aufgabenwarteschlange (z. B. Celery) mit einem Ratenbegrenzer, um die Ausführungsparallelität von API-Aufrufen zu steuern.
- Implementieren Sie Observability-Tools, um den Token-Verbrauch pro Aufgabe zu verfolgen, und legen Sie automatisierte Token-Budgets (Leistungsschalter) fest, die jede außer Kontrolle geratene LLM-Instanz beenden oder pausieren, um die Betriebskosten in Echtzeit zu verwalten.
Ist Orchestrierung eine Schlüsselkomponente von LLM?
Ja. Orchestrierung ist eine Schlüsselkomponente in LLM-basierten Systemen, aber sie ist keine Kernkomponente des Modells wie die Modellgewichte oder der Tokenizer. Stattdessen handelt es sich um eine Systemfähigkeit, die LLMs in realen Anwendungen nutzbar macht.
Unter den wesentlichen Komponenten steht die Orchestrierung typischerweise neben:
- LLM-Modell: Ein Large Language Model (LLM) verarbeitet riesige Datenmengen, um menschenähnlichen Text zu verstehen und zu generieren. Open-Source-Modelle bieten Flexibilität, während Closed-Source-Modelle Benutzerfreundlichkeit und Support bieten. General-Purpose-LLMs bewältigen verschiedene Aufgaben, während domänenspezifische Modelle auf spezialisierte Branchen zugeschnitten sind.
- Prompts: Effektive Prompts lenken die LLM-Antworten.
- Zero-Shot-Prompts: Erzeugen Antworten ohne vorherige Beispiele.
- Few-Shot-Prompts: Verwenden einige wenige Beispiele, um die Genauigkeit zu verbessern. Erfahren Sie mehr über Few-Shot-Learning-Prompting und andere LLM-Feinabstimmungsmethoden.
- Chain-of-Thought-Prompts: Fördern logisches Denken für bessere Antworten.
- Vektordatenbank: Speichert strukturierte Daten als numerische Vektoren. LLMs verwenden Ähnlichkeitssuchen, um relevanten Kontext abzurufen, die Genauigkeit zu verbessern und veraltete Antworten zu vermeiden.
- Erfahren Sie mehr über Vektordatenbank-LLMs, Open-Source-Vektordatenbank-Tools und Anwendungsfälle für Vektordatenbanken.
- Agenten und Tools: Erweitern die LLM-Fähigkeiten durch Ausführen von Websuchen, Codeausführung oder Abfragen von Datenbanken. Diese verbessern KI-gesteuerte Automatisierung und Geschäftslösungen.
- Orchestrator (Steuerungsschicht): Integriert LLMs, Prompts, Vektordatenbanken und Agenten in ein zusammenhängendes System. Gewährleistet eine reibungslose Koordination für effiziente KI-gestützte Anwendungen.
- Monitoring: Verfolgt die Leistung, erkennt Anomalien und protokolliert Interaktionen. Stellt qualitativ hochwertige Antworten sicher und hilft, Fehler in LLM-Ausgaben zu mindern.
Weiterführende Literatur
Externe Quellen
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{simsek2026,
author = {Şimşek, Hazal},
title = {{LLM-Orchestrierung: 22 Frameworks und Gateways}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/llm-orchestration}},
note = {AIMultiple. Abgerufen am 3. Juni 2026}
}



Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.