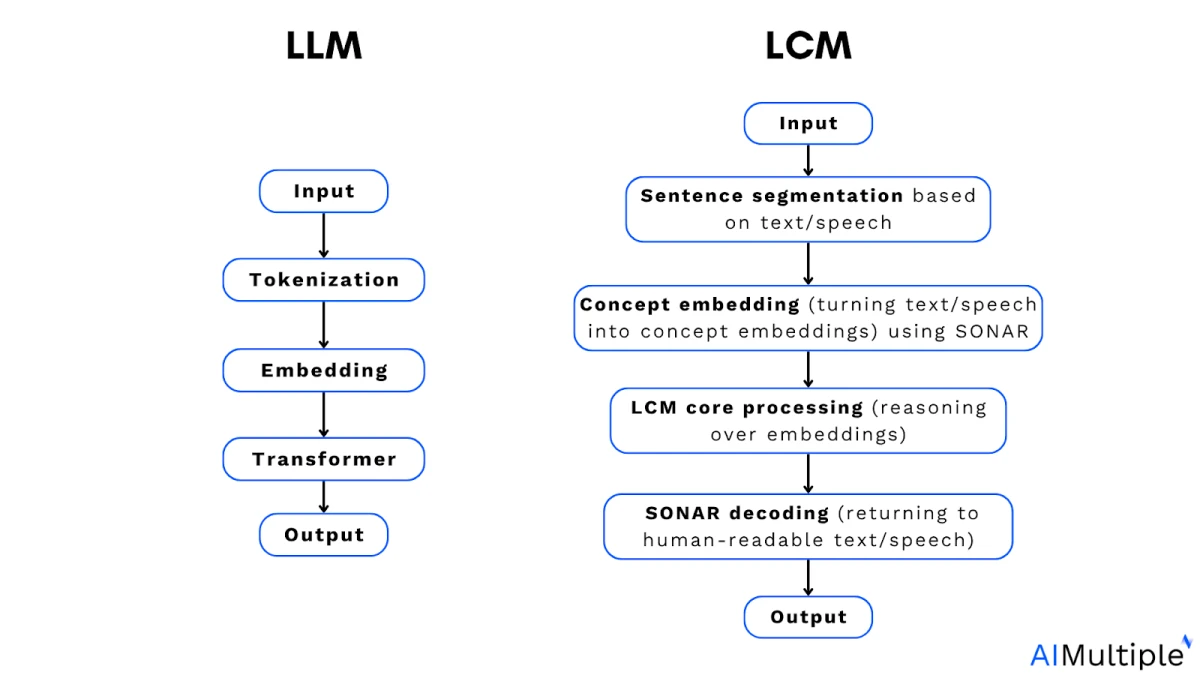
LCMs: Von der Tokenisierung auf LLM-Ebene zur Repräsentation auf Konzeptebene
Große Konzeptmodelle (LCMs) , wie sie von Meta in ihrer Arbeit über „Große Konzeptmodelle“ eingeführt wurden, stellen einen grundlegenden Wandel von der tokenbasierten Vorhersage hin zur Repräsentation auf Konzeptebene dar. 1
LCMs unterscheiden sich von traditionellen LLMs in zwei wesentlichen Punkten:
- Hochdimensionaler Einbettungsraum: Anstatt mit diskreten Tokensequenzen zu arbeiten, führen LCMs die gesamte Modellierung direkt im hochdimensionalen Einbettungsraum durch.
- Abstraktion auf Konzeptebene: Die Modellierung erfolgt auf der Ebene semantischer und abstrakter Konzepte, nicht innerhalb einer bestimmten Sprache oder Modalität. Dadurch sind LCMs von Natur aus sprach- und modalitätsunabhängig.
Aus den Recherchen von Meta, 2 Wir werden die Kernkomponenten von LCMs und ihr Potenzial für semantische Suche und Schlussfolgerung anhand der folgenden Benchmarks untersuchen:
Die Grenzen von LLMs verstehen: Von Token zu Konzepten
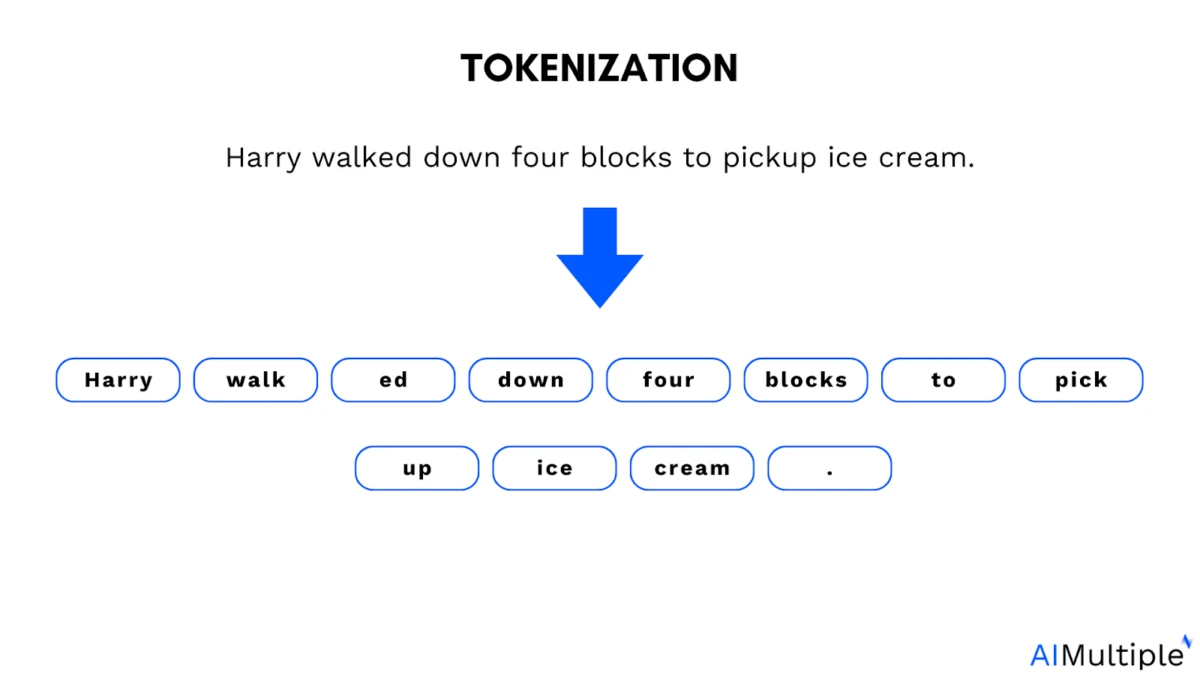
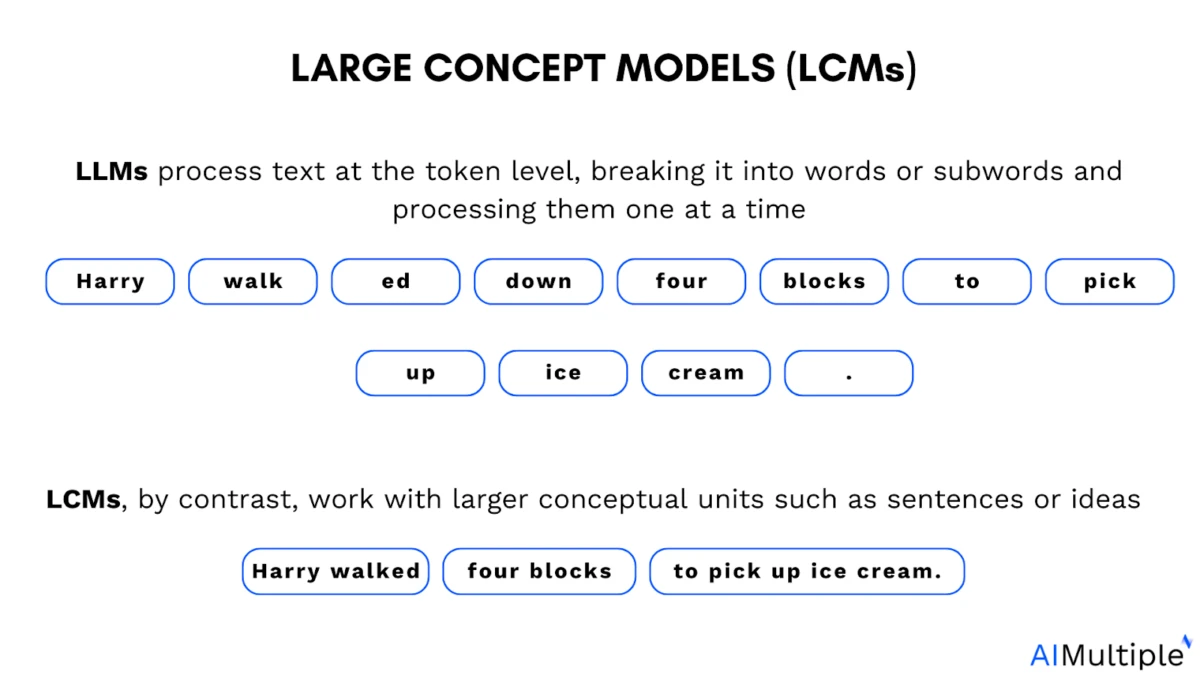
Die Rolle der Tokenisierung in großen Sprachmodellen: Große Sprachmodelle (LLMs) werden mit Tokens trainiert. Tokens sind kleine Textabschnitte. Es kann sich um ein ganzes Wort, einen Wortteil oder sogar ein einzelnes Zeichen handeln, das vom Modell als Einheit verarbeitet wird.
Beispiel für Tokenisierung:
Das Problem
Die Tokenisierung hilft Modellen dabei, Sprache in handhabbare Einheiten zu zerlegen, bringt aber auch eine Einschränkung mit sich. Die meisten Sprachverarbeitungsmodelle arbeiten mit Sequenzen diskreter Token (z. B. Textteilwörter; visuelle/auditive Token, die von Kodierern erzeugt werden).
LLMs können mehrere Modalitäten aufnehmen, doch ihr Kernziel und ihre Repräsentation bleiben sequenzgebunden , was es schwieriger macht, Bedeutung direkt auf Konzeptebene zu modellieren.
Die Ergebnisse von Cognition.ai mit Sonnet 4.5 zeigen dies deutlich: Das Modell erkennt, wenn sein Kontextfenster fast voll ist, zieht voreilige Schlüsse und meldet sogar verbleibende Token, allerdings ungenau. 3
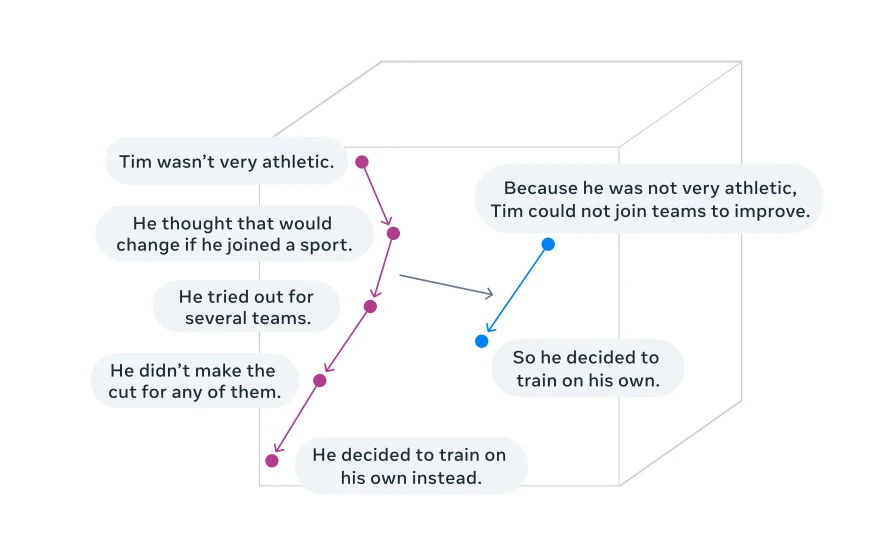
Die Lösung (Konzepte)
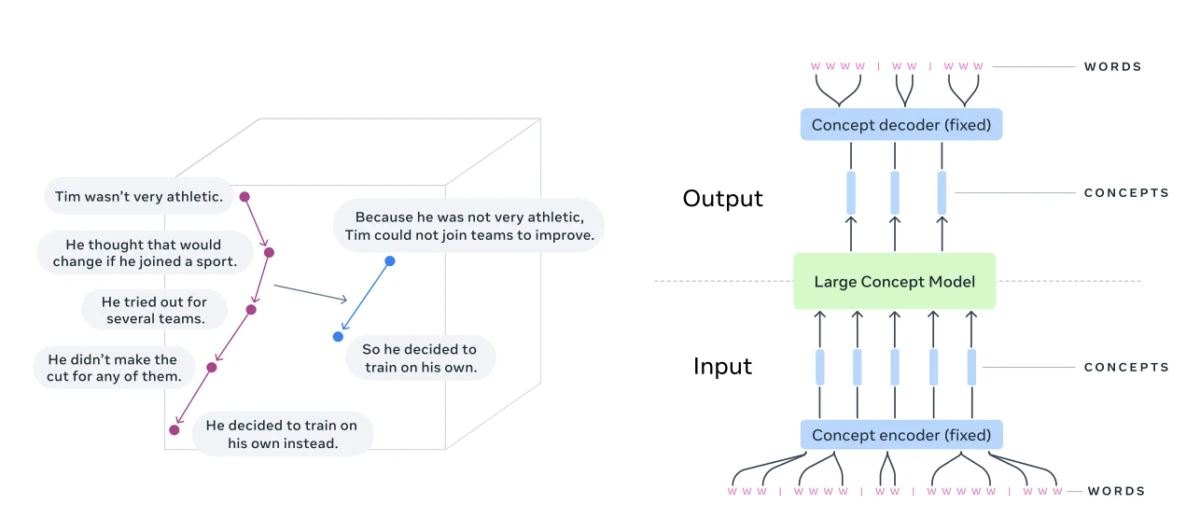
Visualisierung von Schlussfolgerungen in einem Einbettungsraum von Konzepten (Aufgabe der Zusammenfassung) 4
Konzepte bezeichnen übergeordnete Bedeutungsrepräsentationen . Im Gegensatz zu Tokens sind sie nicht an eine bestimmte sprachliche Einheit gebunden und können aus Texten und gesprochener Sprache abgeleitet werden, sodass der Denkprozess derselbe bleibt.
Dies ermöglicht Folgendes:
- Bessere Verarbeitung längerer Kontexte durch das Betrachten ganzer Ideen anstatt fragmentierter Einheiten.
- Abstrakteres Denken, da die Operationen auf der Ebene der Bedeutung durchgeführt werden.
- Ein sprach- und modalitätsunabhängiger Prozess zur Bearbeitung mehrsprachiger und multimodaler Aufgaben, ohne dass separate Verarbeitungspipelines für jede Art von Eingabe erforderlich sind.
Was sind große Konzeptmodelle?
Im Gegensatz dazu zielen große Konzeptmodelle (LCMs) darauf ab, semantische Konzepte in einem kontinuierlichen Einbettungsraum darzustellen und darüber zu argumentieren, der nicht an eine bestimmte Sprache oder Modalität gebunden ist.
Grundlegende Architektur eines großen Konzeptmodells (LCM):
Quelle: Meta 5
Kernkomponenten von LCMs
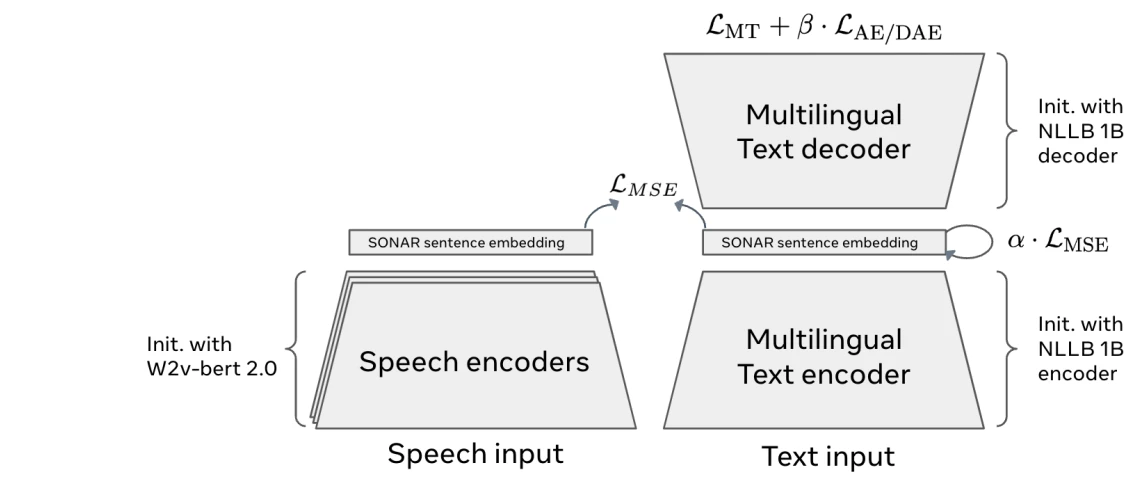
1. SONAR-Kodierung (Umwandlung von Text oder Sprache in Konzept-Einbettungen)
SONAR-Architektur 6
Die erste Stufe eines Large Concept Model (LCM) ist der Konzept-Encoder , der Text oder Sprache in einen gemeinsamen Einbettungsraum umwandelt. Anstatt die Eingabe in Tokens zu zerlegen, repräsentiert er ganze Sätze als mathematische Einbettungen , die deren Bedeutung erfassen.
LCMs verwenden SONAR , einen mehrsprachigen und multimodalen Einbettungsraum, der über 200 Textsprachen und 76 Sprachsprachen unterstützt.
Beispielsweise stehen die Sätze „I love you“ (Englisch) und „Te quiero“ (Spanisch) in diesem Bereich nahe beieinander, weil sie dieselbe Idee ausdrücken. Durch die Arbeit auf dieser konzeptionellen Ebene gewinnen LCMs im Vergleich zu tokenbasierten Modellen an Inklusivität, Effizienz und Skalierbarkeit.
Warum ist SONAR besser als herkömmliche Einbettungen?
Traditionelle Methoden:
- mBERT : Bietet mehrsprachige Einbettungen, diese sind jedoch nicht konsistent auf Satzebene ausgerichtet , was die Effektivität sprachübergreifender Aufgaben verringert.
SONAR-Vorteile:
- Sprachunabhängig : Über 200 Sprachen für Texteingabe und -ausgabe (aufbauend auf dem Projekt „No Language Left Behind “ von Meta). 76 Sprachen für Spracheingabe und Englisch für Sprachausgabe.
- Sprachübergreifende Ausrichtung : Sätze mit gleicher Bedeutung erscheinen unabhängig von der Sprache nahe beieinander.
- Höheres Denkvermögen : Da die Einheiten Sätze (oder Konzepte) sind, können Modelle Aufgaben wie Zusammenfassen oder Übersetzen durchführen, indem sie Ideen direkt manipulieren.
- Zero-Shot-Übersetzung : Kann zwischen Sprachen und Modalitäten übersetzen , ohne für jedes Paar ein direktes Training durchzuführen .
LLMs vs LCMs
2. LCM-Kernverarbeitung (Schlussfolgerungen über Einbettungen)
Der Kern des LCM ist die Schlussfolgerungsphase, in der das Modell kontextbasiert neue Konzepte generiert. Im Gegensatz zu LLMs, die jeweils nur ein Token vorhersagen, sagt der LCM-Kern ganze Sätze oder Konzepte voraus und operiert somit auf einer höheren semantischen Ebene.
Die Herausforderung besteht darin, kontinuierliche Einbettungen zu erzeugen, die vom Kontext abhängen. LLMs generieren Wahrscheinlichkeitsverteilungen über diskrete Token, LCMs hingegen müssen direkt Vektoren generieren, die die Bedeutung erfassen.
Um diesem Problem zu begegnen, haben Forscher verschiedene Ansätze vorgeschlagen, darunter:
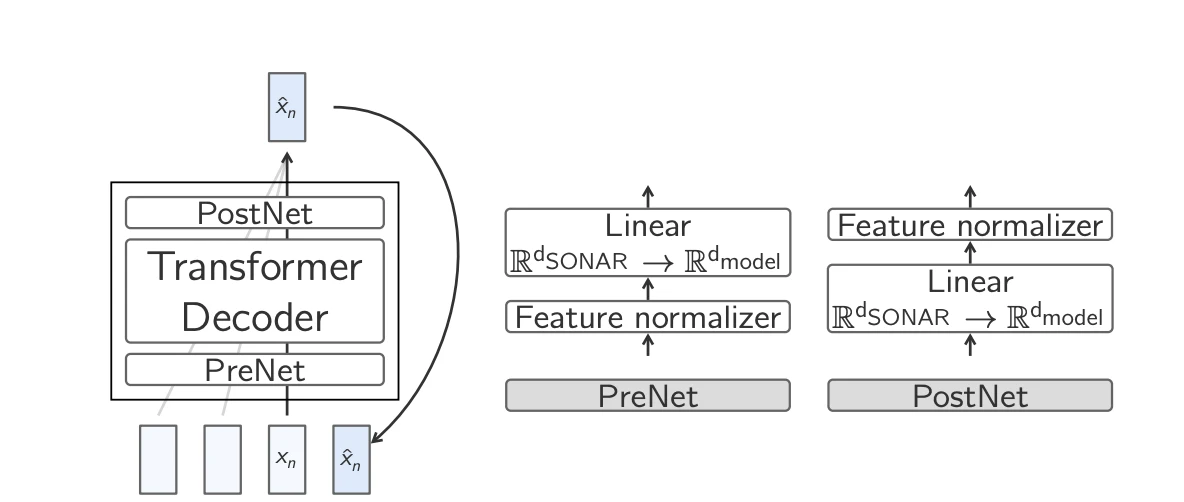
- Base-LCM: Standard-Transformer zur Vorhersage von Einbettungen: Die einfachste Methode besteht darin, einen Transformer so zu trainieren, dass er die nächste Einbettung direkt vorhersagt und dabei den mittleren quadratischen Fehler (MSE) minimiert. Obwohl dieser Ansatz prinzipiell effektiv ist, stößt er auf Herausforderungen, da ein gegebener Kontext zu mehreren gültigen, aber semantisch unterschiedlichen Fortsetzungen führen kann.
Basis-LCM 7
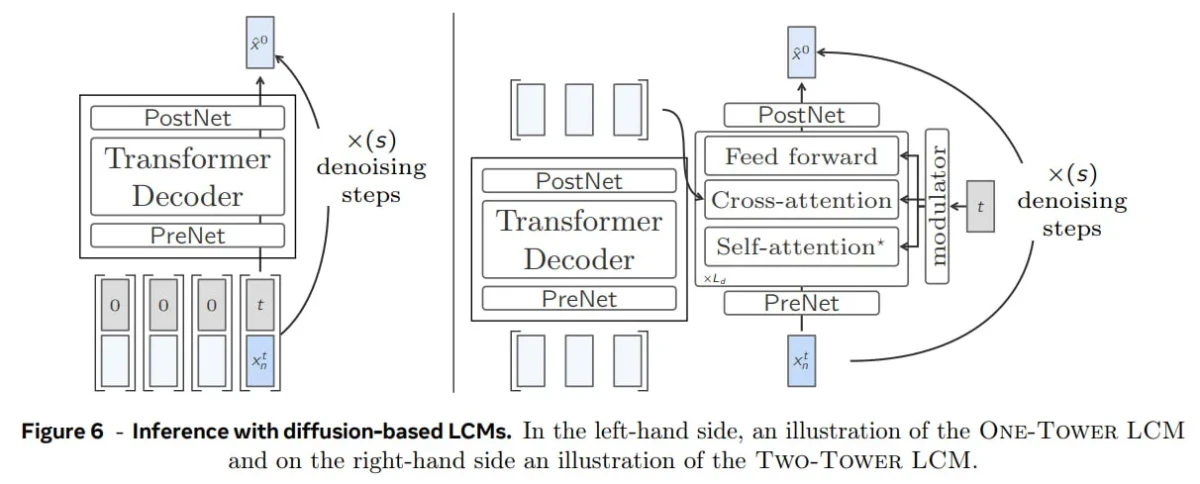
- Diffusionsbasierte LCM: Strukturelle Variationen zur Kontextualisierung und Rauschunterdrückung: Inspiriert von der Bildgenerierung nutzt diese Variante einen Diffusionsprozess . Sie generiert autoregressiv Konzepte, eines nach dem anderen, und führt für jedes generierte Konzept Rauschunterdrückungsschritte durch.
- Ein-Turm-Lösung: Ein einziger Transformer-Stack übernimmt sowohl die Kontextualisierung als auch die Rauschunterdrückung und sorgt so für ein effizientes und kompaktes Design.
- Zwei-Turm-Modell: Teilt den Prozess in zwei Teile auf: einen Kontextualisierer zum Verständnis des Kontextes und einen Entrauscher zur Verfeinerung der Einbettungen. Dies bietet mehr Flexibilität auf Kosten der Komplexität.
- Quantisiertes LCM: Diskretisierte Einbettungen: Eine weitere Möglichkeit besteht darin, Einbettungen in größere symbolische Einheiten zu diskretisieren . Dadurch ähnelt die Aufgabe eher der von LLMs, bei denen das Modell diskrete Elemente generiert, aber hier repräsentieren die „Token“ viel größere, semantisch reichhaltigere Bedeutungseinheiten.
3. SONAR-Dekodierung (Rückführung in für Menschen lesbaren Text oder Sprache)
Der letzte Schritt eines LCM ist der Konzeptdecoder , der abstrakte Einbettungen wieder in natürlichen Text oder Sprache umwandelt.
Da Konzepte in einem gemeinsamen Einbettungsraum gespeichert sind, können sie in jede unterstützte Sprache oder Modalität dekodiert werden, ohne den Schlussfolgerungsprozess erneut auszuführen.
Dieses sprachunabhängige Design ermöglicht es einem LCM, Eingaben in Deutsch zu verarbeiten, Konzepte zu erkennen und Ergebnisse in Japanisch auszugeben. Es ermöglicht zudem eine einfache Skalierbarkeit: Neue Encoder oder Decoder (z. B. für Gebärdensprache oder Spracherkennungssysteme) können hinzugefügt werden, ohne dass das gesamte Modell neu trainiert werden muss.
Indem der Decoder das „Denken“ vom Ausdruck trennt, stellt er sicher, dass LCMs sowohl flexibel als auch anpassungsfähig für mehrsprachige und multimodale Anwendungen bleiben.
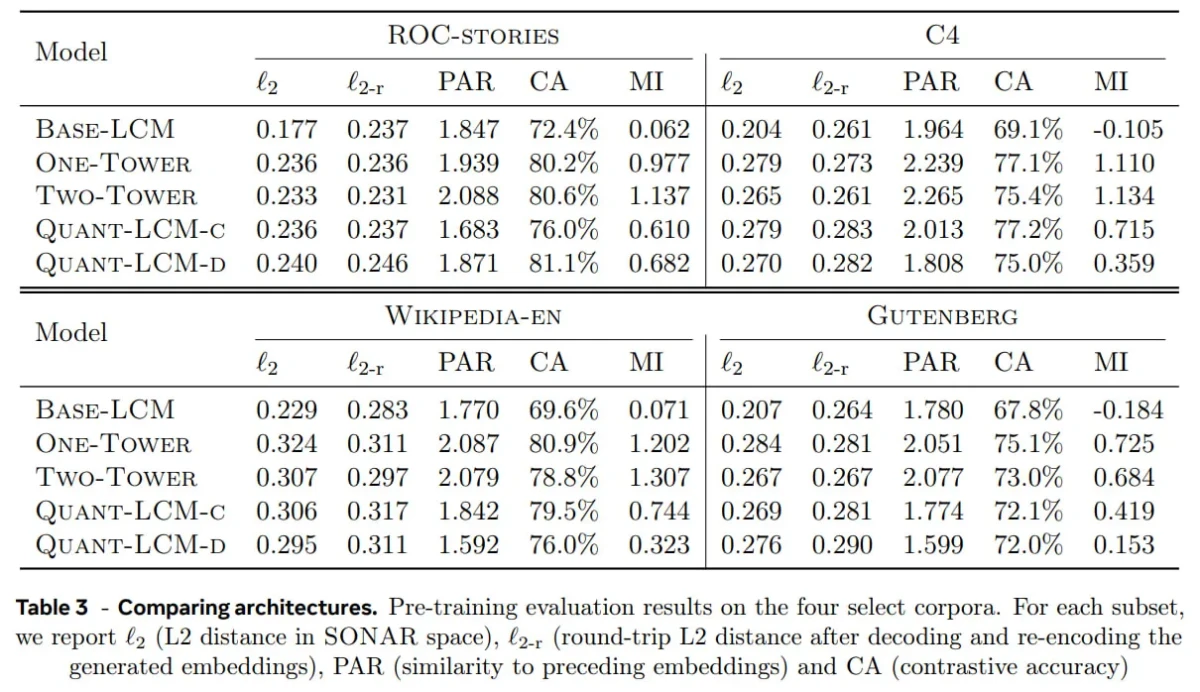
Benchmarking von LCM-Architekturen
Meta wurden auf dem FineWeb-Edu-Datensatz (nur Englisch) vortrainierte LCMs erstellt und anhand von vier Benchmarks evaluiert:
- ROC-Stories (narratives Denken),
- C4 (Web-Scale-Text),
- Wikipedia-en (enzyklopädisches Wissen),
- Gutenberg (Langform des Textes).
Diese Datensätze wurden ausgewählt, um verschiedene Textarten zu erfassen, von kurzen Erzählungen bis hin zu großen Wissensdatenbanken und ausführlichen Dokumenten.
Wichtigste Erkenntnisse:
Diffusionsbasierte LCMs (QUANT-LCM-C, QUANT-LCM-D) erzielen die besten Ergebnisse . Ihr iterativer Entrauschungsprozess erwies sich als effektiver bei der Modellierung von Konzeptfortsetzungen, was zu einer höheren semantischen Genauigkeit und Kohärenz führte.
Wie man die Vergleichsdaten interpretiert:
- ℓ₂, ℓ₂-r: Niedrigere Werte bedeuten genauere und konsistentere Einbettungen.
- PAR: Der Mittelweg ist am besten, er zeigt Kohärenz ohne Zusammenbruch.
- CA: Höher = bessere semantische Übereinstimmung.
- MI: Höherer Wert = informativere Ergebnisse.
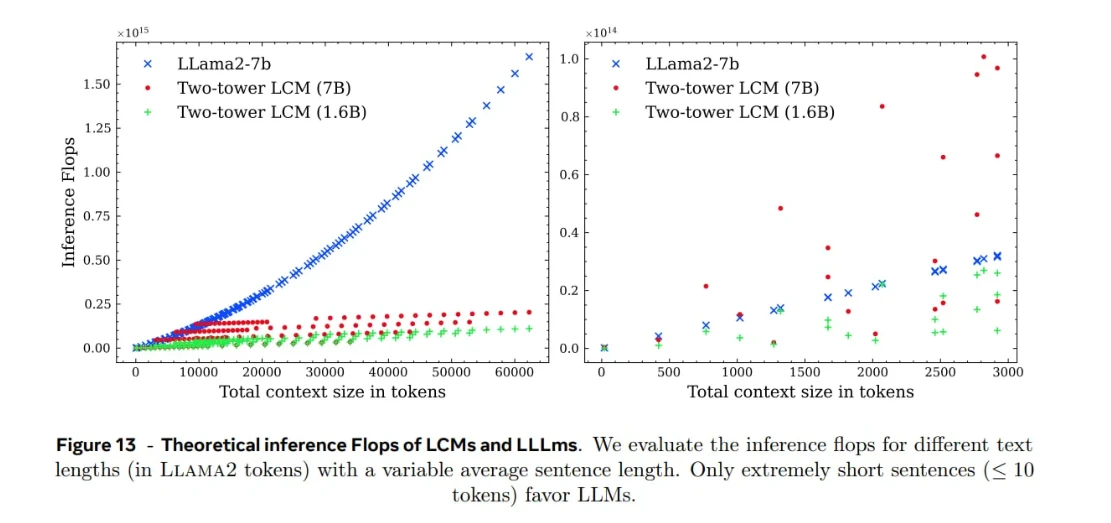
Benchmarking der LCM-Effizienz
Die Experimente von Meta zeigten, dass LCMs im Vergleich zu LLMs bei gleicher Textmenge gut mit der Kontextlänge skalieren . Dieser Vorteil beruht darauf, dass ein Konzept einem vollständigen Satz entspricht , der mehrere Token enthält. Da es weniger Konzepte als Token gibt, muss das Modell weniger Einheiten verarbeiten, und die quadratische Aufmerksamkeit wird weniger aufwendig.
Wichtigste Erkenntnisse:
Es ist wichtig zu beachten, dass diese Effizienzgewinne stark davon abhängen, wie der Text in Sätze segmentiert wird . Absätze, die in kürzere oder längere Sätze unterteilt werden, beeinflussen die Anzahl der Konzepte und somit die Rechenlast.
Jede LCM-Berechnung umfasst drei Phasen:
- SONAR-Kodierung (Text oder Sprache: Einbettungen)
- Transformer-LCM-Schlussfolgerung (Verarbeitung von Einbettungen)
- SONAR-Dekodierung (Einbettungen: Text oder Sprache)
Diese Pipeline verursacht zusätzlichen Aufwand, insbesondere bei kurzen Eingaben:
Bei kurzen Sätzen (weniger als ~10 Token) können LLMs effizienter sein als LCMs, da die Kodierungs- und Dekodierungsschritte die Vorteile der Verarbeitung auf Konzeptebene überwiegen.
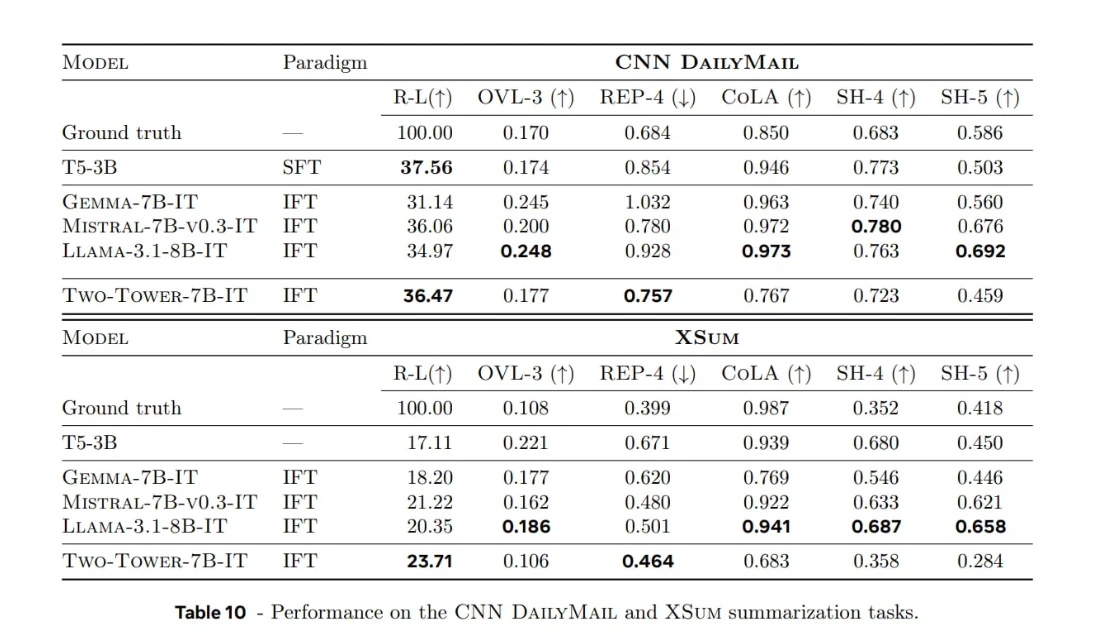
LCM vs. traditionelle LLMs bei Zusammenfassungsaufgaben
Meta führte außerdem eine Benchmark-Analyse eines diffusionsbasierten LCM (7B Parameter) anhand von Nachrichten-Zusammenfassungsdatensätzen (z. B. CNN/DailyMail, XSum) durch und verglich es mit traditionellen LLMs.
Paradigmenbeschreibungen:
- SFT : Spezialisiertes Training zu Beispielen für Zusammenfassungen.
- IFT : Umfassenderes Training mit Unterrichtsdatensätzen, damit das Modell die Zusammenfassung als eine von vielen Fähigkeiten erlernt.
Parameterbeschreibungen:
- ROUGE-L : Überschneidung mit Referenzzusammenfassungen.
- OVL-3 : Input-Trigramm-Überlappungsverhältnis, das die Redundanz aus dem Quelltext misst.
- REP-4 : Ausgabe des Vier-Gramm-Wiederholungsverhältnisses, das die Wiederholung in generierten Zusammenfassungen misst.
- SEAHORSE-Kennzahlen für das 4. und 5. Quartal : Qualitäts- und Kohärenzmaße.
- CoLA-basierter Klassifikator : Bewertung der sprachlichen Akzeptabilität generierter Sätze.
Wichtigste Erkenntnisse:
Stärke:
- Das Diffusions-LCM weist eine starke Kohärenz und kontextuelle Ausrichtung bei der Zusammenfassung längerer Texte auf, insbesondere bei der Verarbeitung großer Kontexte.
Vorbehalte und Überlegungen:
- Die Evaluierung konzentriert sich hauptsächlich auf generative Aufgaben (Zusammenfassung) und weniger auf umfassende Benchmarks wie MMLU.
- Die Art und Weise, wie Absätze in Sätze unterteilt werden (z. B. wie man „Konzepte“ definiert), hat einen starken Einfluss auf die Leistung.
- Hinsichtlich sprachlicher Flüssigkeit und Akzeptabilität haben tokenbasierte Sprachlernsysteme wie LLaMA-3.1-8B und Mistral-7B weiterhin einen Vorteil. Sprachlernsysteme zeigen zwar vielversprechende Ansätze, erzielen aber noch keine eindeutigen Verbesserungen in allen Bereichen, insbesondere nicht in Bezug auf Flüssigkeit oder Flexibilität.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCMs: Von der Tokenisierung auf LLM-Ebene zur Repräsentation auf Konzeptebene}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Januar 23, 2026}
}

Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.