Comparar Modelos Fundacionales Relacionales
Hemos realizado benchmarks de SAP-RPT-1-OSS frente al gradiente impulsado (LightGBM, CatBoost) en 17 conjuntos de datos tabulares que abarcan el espectro semántico-numérico, tablas pequeñas/de alta semántica, conjuntos de datos empresariales mixtos y grandes conjuntos de datos numéricos de baja semántica.
Nuestro objetivo es medir dónde los priores semánticos preentrenados de un LLM relacional pueden proporcionar ventajas sobre los modelos de árboles tradicionales y dónde enfrentan desafíos bajo escala o estructura de baja semántica.
SAP-RPT-1-OSS vs. Gradiente impulsado: Resultados del benchmark
- Tasa de éxito: Representa la puntuación normalizada promedio (0.0 a 1.0). Una barra más alta indica que el modelo está consistentemente más cerca del mejor rendimiento posible para los conjuntos de datos en esa categoría.
- 100 – 500 filas (3 Conjuntos de datos):
- Incluidos: wine (178), sonar (208), vote (435).
- Resultado: SAP tiene el mejor rendimiento en 2 de 3 conjuntos de datos. Logra las puntuaciones más altas en wine y sonar, lo que sugiere que los priores de LLM pueden ser beneficiosos cuando los datos de entrenamiento son escasos. Sin embargo, CatBoost obtuvo una estrecha victoria en el conjunto de datos vote (dentro del 0.1%), lo que indica que los modelos de árboles siguen siendo altamente competitivos incluso a pequeña escala.
- 501 – 1,000 filas (3 Conjuntos de datos):
- Incluidos: cylinder_bands (540), breast_cancer (569), credit_g (1,000).
- Resultado: SAP tiene el mejor rendimiento en los 3 conjuntos de datos. En cylinder_bands, SAP superó a LightGBM por un margen del 5.5%, posiblemente debido a un mejor manejo de las descripciones semánticas de defectos industriales, aunque se necesitarían más estudios de ablación para confirmar este mecanismo.
- 1,000 – 10,000 filas (5 Conjuntos de datos):
- Incluidos: titanic (1.3K), car_evaluation (1.7K), spambase (4.6K), compas (5.2K), employee_salaries (9.2K).
- Resultado: SAP logra los mejores resultados en 4 de 5 conjuntos de datos, desempeñándose particularmente bien en tareas con mucho texto como spambase y titanic. Sin embargo, CatBoost supera significativamente a SAP en compas por un 10.4%, lo que indica características específicas del conjunto de datos que favorecen a los modelos de árboles incluso en este rango de tamaño.
- 10,000+ filas (6 Conjuntos de datos):
- Incluidos: california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Resultado: A medida que crece el volumen de datos, la ventaja potencial de "conocimiento previo" del LLM disminuye. LightGBM y CatBoost logran los mejores resultados en 5 de 6 conjuntos de datos, ofreciendo mejor precisión a una fracción del costo computacional. La única excepción, california_housing, muestra solo una modesta ventaja del 1.7% para SAP.
1. Tabla de conjuntos de datos de resultados del benchmark
A continuación se presenta el desglose completo del rendimiento del modelo en los 17 conjuntos de datos.
2. Análisis de costo y eficiencia
Calculamos el costo computacional directo para cada modelo basándonos en los precios de la instancia H200 de RunPod de $3.59/hora.
SAP-RPT-1-OSS incurre en costos significativamente más altos debido al tiempo requerido para el preprocesamiento de incrustaciones de texto y la gran sobrecarga de memoria de la arquitectura del LLM. En contraste, LightGBM y CatBoost completan las tareas casi instantáneamente en este hardware. Los costos a continuación reflejan el tiempo total de reloj (preprocesamiento + entrenamiento) para una ejecución de validación cruzada de 3 pliegues.
Costo promedio por conjunto de datos (Promedio de 17 conjuntos de datos)
Desglose de costos por tamaño del conjunto de datos
- Conjuntos de datos pequeños (<1K filas): SAP es relativamente barato (≈ $0.03 por ejecución). La alta tasa de victorias aquí hace que el costo sea insignificante.
- Conjuntos de datos grandes (>20K filas): SAP se vuelve costoso.
- Ejemplo: El entrenamiento en adult_income (48k filas) toma ≈$12 minutos en total para 3 pliegues.
- Costo: 12 min X $0.06/min = $0.72 por experimento.
- Comparación: LightGBM termina la misma tarea por $0.01.
Conclusión: Aunque $0.22 por conjunto de datos no es costoso en términos absolutos, SAP es 22 veces más caro que la línea base. Esta diferencia de costos puede justificarse para conjuntos de datos pequeños y ricos en semántica donde SAP muestra mejoras significativas en precisión (por ejemplo, cylinder_bands con un aumento del +5.5%), pero se vuelve más difícil de justificar para conjuntos de datos grandes donde los modelos de árboles logran un rendimiento igual o mejor a una fracción del costo.
3. Marco de análisis: El espectro semántico
Para interpretar estos resultados, es crucial entender cómo seleccionamos los datos. No elegimos conjuntos de datos al azar; curamos una suite de 17 conjuntos de datos seleccionados específicamente para abarcar el Espectro Semántico-Numerical.
Nuestra hipótesis central era que SAP (siendo basado en LLM) sobresaldría donde los datos tienen significado lingüístico, mientras que los modelos de árboles dominarían en el cálculo numérico puro. Clasificamos nuestros conjuntos de datos en tres grupos distintos:
Grupo A: Conjuntos de datos de alta semántica (6 conjuntos de datos)
Características: Las características contienen descripciones de texto ricas, etiquetas categóricas con significado del mundo real (por ejemplo, "congelación de honorarios médicos") o terminología específica del dominio.
- Conjuntos de datos:
- cylinder_bands: Defectos de impresión industrial.
- titanic: Nombres y títulos de pasajeros.
- vote: Registros de votación del Congreso (Categorías "Sí/No" sobre políticas).
- breast_cancer: Descripciones de tumores médicos.
- spambase: Frecuencias de palabras de correo electrónico.
- wine: Orígenes químicos.
Grupo B: Datos empresariales mixtos (6 conjuntos de datos)
Características: El formato tabular estándar que se encuentra en la mayoría de las bases de datos empresariales, una mezcla de valores numéricos (salario, edad) y cadenas categóricas (título del trabajo, raza, departamento).
- Conjuntos de datos:
- employee_salaries: Títulos de trabajo vs. salario.
- compas: Historial criminal y demografía (Atributos sensibles).
- adult_income: Demografía del censo.
- credit_g: Perfiles de riesgo crediticio alemán.
- default_credit: Datos de incumplimiento crediticio de Taiwán.
- car_evaluation: Parámetros de compra de vehículos.
Grupo C: Datos de baja semántica/puros numéricos (5 conjuntos de datos)
Características: Las características son mediciones abstractas, lecturas de sensores o coordenadas físicas. A menudo los nombres de las columnas no importan; solo importan las relaciones matemáticas.
- Conjuntos de datos:
- higgs_100k: Cinemática de partículas físicas.
- diamonds: Dimensiones físicas y precio.
- sonar: Rebotes de energía de frecuencia.
- california_housing: Coordenadas Lat/Long y estadísticas del censo.
- house_sales: Bienes raíces del condado de King (principalmente características numéricas).
4. Análisis profundo: Dónde gana SAP vs. falla
Aplicar el marco de análisis a nuestros resultados revela cuatro patrones de rendimiento distintos. La tabla a continuación resume exactamente dónde sobresale SAP y dónde falla.
Fundamentos conceptuales de los modelos fundacionales relacionales
El objetivo principal de un modelo fundacional relacional es hacer predicciones precisas y realizar diversas tareas sobre tablas estructuradas. Estos modelos deben entender cómo se representa la información a través de diferentes tablas, cómo se vinculan las entidades a través de relaciones y cómo la información temporal influye en los resultados.
Las capacidades clave de tales modelos incluyen:
- Generalización de esquema: La capacidad de adaptarse a nuevos esquemas relacionales sin reentrenar desde cero.
- Representación unificada de entrada: Manejar diferentes tipos de columnas como características numéricas, categóricas y de texto.
- Integración de contexto temporal y estructural: Capturar dependencias a través del tiempo y entre entidades vinculadas por claves primarias y foráneas.
- Transferibilidad: Realizar tareas predictivas en nuevos conjuntos de datos a través de preentrenamiento y aprendizaje de cero disparos.
Griffin
Griffin es uno de los primeros intentos a gran escala de construir un modelo fundacional relacional unificado. Representa los datos relacionales como un grafo temporal heterogéneo, donde cada fila se convierte en un nodo y las aristas corresponden a relaciones de clave foránea. Las características clave incluyen:
Codificador de características unificado
- Las características categóricas y de texto se codifican con un codificador de texto preentrenado, mientras que los valores numéricos utilizan un codificador de flotante aprendido.
- Los metadatos como nombres de tablas, nombres de columnas y tipos de aristas se incrustan para ayudar al modelo a reconocer el esquema relacional.
- Las incrustaciones de tareas permiten que un solo modelo realice tareas de regresión y clasificación con decodificadores compartidos.
Paso de mensajes y atención
Griffin integra redes neuronales de paso de mensajes con un módulo de atención cruzada. El componente de paso de mensajes agrega información dentro y entre relaciones, mientras que la atención cruzada se centra en las celdas relevantes dentro de cada fila. Este diseño ayuda al modelo a manejar datos diversos y mantener el contexto entre entidades conectadas.
Preentrenamiento y ajuste fino
El modelo se preentrena en conjuntos de datos de una sola tabla mediante una tarea de completado de celda enmascarada y luego se ajusta fino en bases de datos relacionales para tareas específicas. Los experimentos en grandes benchmarks relacionales muestran que Griffin supera a las líneas base tradicionales de GNN y a los modelos de una sola tabla tanto en precisión como en eficiencia de aprendizaje por transferencia.
Figura 1: Gráfico que muestra el marco del modelo Griffin.1
Transformador relacional
Mientras que Griffin se centra en la agregación de grafos, el Transformador Relacional (RT) aplica arquitecturas de transformadores directamente a bases de datos relacionales. Trata cada celda como un token enriquecido con su valor, nombre de columna y nombre de tabla.
Representación de entrada
Cada token combina:
- Una incrustación de valor que depende de su tipo de dato (numérico, texto o fecha y hora).
- Una incrustación de esquema se genera a partir del texto de la tabla y la columna.
- Un token de máscara se utiliza cuando el valor está oculto durante el preentrenamiento.
Esta estructura permite que RT procese bases de datos relacionales con diferentes esquemas mientras mantiene un formato de entrada consistente.
Atención relacional
RT introduce un mecanismo de atención relacional que opera a nivel de celda. Incluye:
- Atención de columna para aprender distribuciones de valores dentro de las columnas.
- Atención de características para combinar atributos dentro de la misma fila o filas parentales vinculadas.
- Atención de vecino para agregar información de filas hijas conectadas.
Juntas, estas capas de atención forman un transformador de grafo relacional que modela dependencias a través de filas, columnas y tablas.
Resultados de entrenamiento y transferencia
RT se preentrena en bases de datos relacionales de RelBench. En experimentos, el modelo preentrenado logró hasta el 94% del rendimiento de los modelos totalmente supervisados en configuraciones de cero disparos. También aprendió más rápido durante el ajuste fino, requiriendo menos pasos de entrenamiento para alcanzar una alta precisión.2
Este enfoque sugiere que las bases de datos relacionales comparten patrones transferibles entre dominios y que la tokenización a nivel de celda proporciona una base práctica para tareas predictivas en datos estructurados.
RelBench
RelBench está diseñado para avanzar en el aprendizaje profundo relacional, que se centra en el aprendizaje de extremo a extremo a partir de datos distribuidos en múltiples tablas relacionadas en bases de datos relacionales.
Dado que las bases de datos relacionales siguen siendo el sistema de gestión de datos dominante en la industria y la ciencia, RelBench proporciona un marco estandarizado y reproducible para evaluar modelos que operan directamente sobre estructuras relacionales en lugar de depender del aplanamiento manual de características.
Las versiones anteriores de RelBench introdujeron 11 bases de datos relacionales que abarcan dominios como atención médica, redes sociales, comercio electrónico y deportes, con 70 tareas predictivas diseñadas para ser desafiantes y relevantes para el dominio.3
En enero de 2026, se lanzó RelBench v2, agregando cuatro nuevas bases de datos (SALT, RateBeer, arXiv y MIMIC-IV) y 40 tareas predictivas adicionales, incluida una nueva clase de tareas de autocompletado que evalúan la capacidad de un modelo para predecir columnas existentes dentro de una base de datos relacional.
El lanzamiento también amplió el acceso a datos a través de la integración de CTU, permitiendo el acceso a más de 70 conjuntos de datos relacionales a través de ReDeLEx; agregó conectividad directa a bases de datos SQL; e incorporó siete conjuntos de datos del repositorio 4DBInfer en formato RelBench.
Más allá de los conjuntos de datos y las tareas, RelBench proporciona una implementación de referencia de código abierto para el aprendizaje profundo relacional basada en redes neuronales de grafos, utilizando PyTorch Geometric para la construcción de grafos y PyTorch Frame para modelado tabular, junto con una tabla de clasificación pública para rastrear el progreso.
El lanzamiento de v2 también introdujo múltiples mejoras de usabilidad y rendimiento, incluidas etiquetas con censura de tiempo opcionales, soporte para la métrica NDCG en la predicción de enlaces, generación más rápida de incrustaciones de oraciones y gestión de caché configurable.4
VIEIRA
VIEIRA adopta un enfoque diferente al centrarse en la programación con modelos fundacionales en lugar de construir un solo motor predictivo. Extiende el compilador de lógica probabilística SCALLOP con un lenguaje declarativo que integra modelos de lenguaje grandes, modelos de visión y otros componentes preentrenados como predicados extranjeros.5
Paradigma relacional
En VIEIRA, los modelos fundacionales se tratan como funciones sin estado con entradas y salidas relacionales. Esto permite componer modelos como GPT, CLIP o SAM según reglas lógicas. Por ejemplo:
- Un programa puede usar GPT para extraer conocimiento del texto y almacenarlo como relaciones estructuradas.
- CLIP puede clasificar imágenes y vincularlas a etiquetas de texto en una tabla.
Aplicaciones
El marco soporta:
- Razonamiento de fechas y matemáticas usando GPT.
- Razonamiento de parentesco usando extracción de texto e inferencia lógica.
- Respuesta a preguntas que combina recuperación y razonamiento.
- Respuesta a preguntas visuales y edición de imágenes a través de composición multimodal.
Al unificar la lógica simbólica y la inferencia neuronal, VIEIRA permite a los analistas de datos y desarrolladores construir sistemas interpretables que utilizan modelos fundacionales preentrenados para responder consultas predictivas sobre datos estructurados e imágenes.
Estudios de caso
SAP Hana Cloud
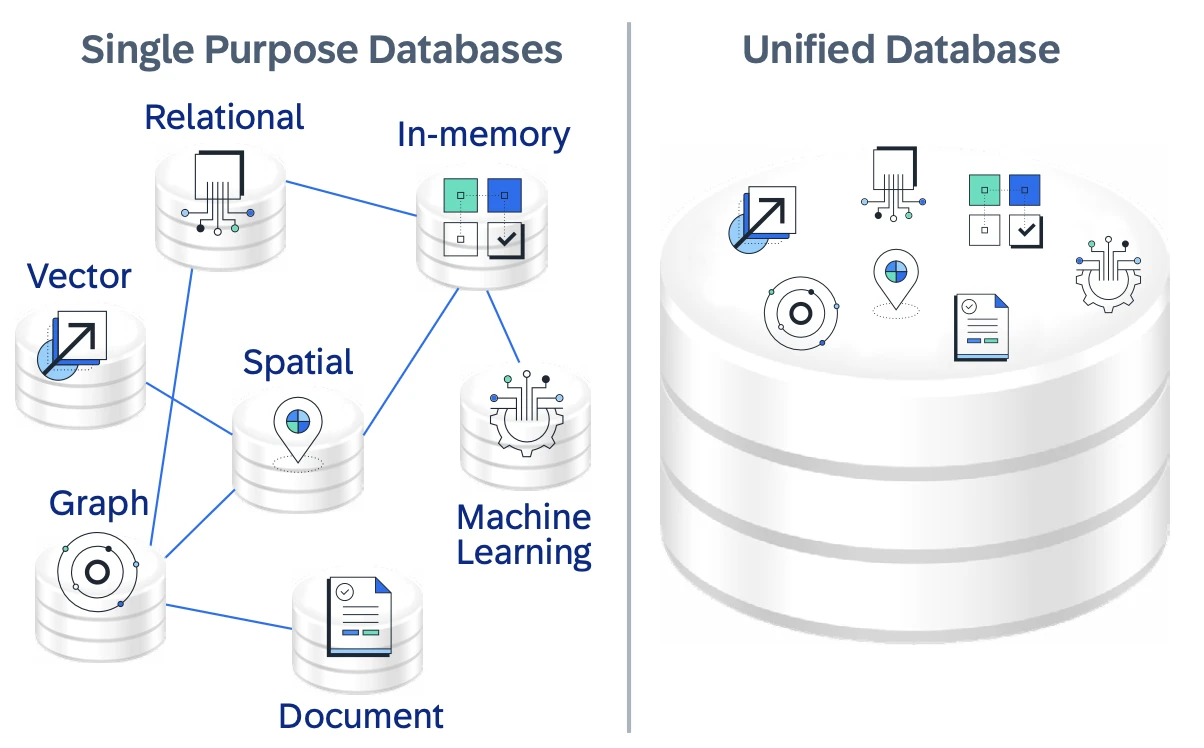
SAP HANA Cloud es una base de datos como servicio nativa de la nube y totalmente administrada diseñada para actuar como una base de datos unificada para aplicaciones empresariales que combinan transacciones, análisis e IA. En lugar de servir como una base de datos relacional de un solo propósito, SAP HANA Cloud se posiciona como una plataforma multimodelo que permite a las organizaciones construir "aplicaciones de datos inteligentes" sobre datos empresariales operativos.
SAP HANA Cloud combina el procesamiento en memoria con almacenamiento basado en disco e integración de lago de datos para soportar diferentes requisitos de rendimiento y costo. Este diseño flexible soporta cargas de trabajo en tiempo real mientras escala dinámicamente a medida que fluctúan los volúmenes de datos y el uso.
Un diferenciador clave es su motor multimodelo nativo, que soporta datos relacionales, JSON/documento, grafo, espacial y vectorial dentro de una sola base de datos. Esto permite que las aplicaciones combinen consultas SQL, relaciones de grafos y búsqueda de similitud vectorial sin mover datos entre sistemas separados, simplificando así la arquitectura y reduciendo la latencia.
Como parte de la Plataforma de Tecnología Empresarial de SAP, SAP HANA Cloud se integra directamente con fuentes de datos de SAP y no SAP, incluido el acceso en vivo sin replicación, y proporciona seguridad, disponibilidad y cumplimiento de nivel empresarial por defecto.
En general, SAP HANA Cloud es una plataforma de datos nativa de IA centrada en lo relacional, en la que la base de datos relacional sirve como la capa fundamental para análisis, datos multimodelo y aplicaciones empresariales de IA.
Figura 2: Imagen que muestra la base de datos unificada de Hana y
el procesamiento de datos multimodelo.6
sap-rpt-1 de SAP
sap-rpt-1 introduce un único modelo fundacional relacional que realiza una amplia gama de tareas predictivas a través del aprendizaje en contexto. En lugar de reentrenar un nuevo modelo para cada caso de uso, los usuarios proporcionan algunos ejemplos de su patrón objetivo, como "clientes que pagaron a tiempo" y "clientes que pagaron tarde". El modelo luego reconoce el patrón y produce inmediatamente predicciones precisas para nuevos datos.
El modelo está diseñado con un mecanismo de atención bidimensional que captura relaciones a través de filas y columnas, mientras que también incrusta metadatos, como nombres de tablas y columnas, en incrustaciones vectoriales. Este diseño le permite entender la semántica de los esquemas relacionales y la información temporal dentro de las tablas empresariales.
El enfoque de SAP trae varias ventajas para los analistas de datos y usuarios empresariales:
- Un solo modelo que funciona en múltiples tablas y dominios.
- No se necesita ajuste fino repetido ni desarrollo personalizado.
- Acceso a información predictiva en minutos en lugar de semanas.
- Integración con almacenes de datos existentes y sistemas SAP.
Al incrustar sap-rpt-1 dentro del ecosistema de SAP, los expertos empresariales pueden interactuar directamente con sus propios datos y recibir predicciones a través de interfaces intuitivas. El resultado es un camino más rápido desde los datos estructurados hasta decisiones accionables sin ingeniería de características manual.
Figura 3: Factor de reducción de errores de sap-rpt-1-large versus líneas base de IA estrecha en dominios de SAP.
A finales de 2025, SAP confirmó que SAP-RPT-1 está disponible generalmente a través del hub de IA generativa en SAP IA Foundation (SAP IA Core).
El modelo se ofrece en dos variantes de producción:
- SAP-RPT-1-small, optimizado para predicciones de baja latencia y alto rendimiento,
- SAP-RPT-1-large, diseñado para priorizar la precisión predictiva.
Este lanzamiento formaliza el papel de SAP-RPT-1 como un modelo fundacional desplegable dentro de la pila de IA empresarial de SAP, en lugar de una capacidad solo de investigación.
Además, SAP ofrece SAP-RPT Playground, un entorno sin código basado en la web donde los usuarios pueden probar el aprendizaje en contexto usando sus propios datos o datos de muestra proporcionados por SAP.
SAP-ABAP-1
SAP-ABAP-1 es un modelo fundacional diseñado para apoyar casos de uso de productividad de desarrolladores basados en IA para clientes y socios de SAP.
Está disponible a través del hub de IA generativa de SAP y está entrenado en más de 250 millones de líneas de código ABAP, 30 millones de líneas de código CDS y documentación técnica extensa. El modelo está optimizado para entender y explicar código ABAP, resaltar las mejores prácticas y proporcionar acceso a conocimiento de desarrollo de SAP actualizado.
SAP ofrece acceso de prueba gratuito a SAP-ABAP-1 a través del hub de IA generativa, con capacidades adicionales planificadas para lanzamiento en 2026.7
KumoRFM de Kumo.IA: un transformador de grafo relacional para análisis predictivo
Kumo.IA, fundada por el profesor de Stanford Jure Leskovec, creó KumoRFM, un modelo fundacional relacional que utiliza un transformador de grafo relacional para analizar bases de datos relacionales y almacenes de datos. Representa los datos relacionales como un grafo temporal heterogéneo, donde cada entidad es un nodo y las claves primarias y foráneas forman aristas entre tablas.
Este enfoque basado en grafos permite que KumoRFM aprenda de múltiples tablas simultáneamente y se adapte a nuevos esquemas relacionales. El modelo se preentrena en diversas fuentes de datos y puede generalizarse a nuevos conjuntos de datos sin construir modelos separados para cada tarea predictiva.
KumoRFM se puede usar a través de diferentes interfaces dependiendo de la experiencia del usuario:
- PQL (Lenguaje de consulta predictiva): Un lenguaje de consulta especializado para definir consultas predictivas en datos estructurados.
- Interfaz de lenguaje natural: Para usuarios no técnicos, las entradas de lenguaje natural se traducen automáticamente a consultas PQL.
- SDK de Python: Permite a los desarrolladores integrar el modelo en pipelines y aplicaciones de IA empresarial.
La arquitectura de KumoRFM muestrea dinámicamente la base de datos para crear subgrafos de contexto y subgrafos de predicción. Estos subgrafos son procesados por el transformador de grafo relacional, que captura dependencias e información temporal entre entidades relacionadas. A través del aprendizaje en contexto, el modelo proporciona predicciones precisas y puede explicar su proceso de razonamiento.
Kumo ofrece dos opciones de implementación adecuadas para entornos empresariales:
- Plataforma SaaS: Un servicio basado en la nube construido sobre Apache Spark para fácil acceso y escalado
- Nativo de almacén de datos: Permite a las organizaciones usar sus propios datos en Snowflake o Databricks sin moverlos fuera de su entorno seguro
A diferencia de los grafos de conocimiento tradicionales que requieren definición manual de esquemas, KumoRFM construye automáticamente su grafo relacional a partir de fuentes estructuradas. Esto lo hace adecuado para comercio electrónico, finanzas y atención médica, donde las relaciones, los patrones temporales y el contexto en evolución son esenciales para predicciones confiables.
Las capacidades clave de KumoRFM incluyen:
- Flexibilidad a través de diferentes tablas y estructuras de esquema.
- Compatibilidad con una variedad de tipos de columnas e identificadores personalizados.
- Adaptación a tareas específicas durante el tiempo de inferencia.
- Alta precisión e interpretabilidad en tareas predictivas.
Figura 4: La imagen muestra cómo funcionan los Modelos Fundacionales Relacionales (RFMs) en múltiples dominios, como comercio electrónico, finanzas y atención médica, para hacer predicciones, proporcionar explicaciones y evaluar resultados.8
Metodología del benchmark
Configuración y entorno del benchmark
Para garantizar comparaciones justas entre árboles limitados por CPU y modelos acelerados por GPU, utilizamos un entorno de alto rendimiento capaz de manejar ambos eficientemente.
- Hardware: Instancia RunPod con una NVIDIA H200 140GB GPU.
- Software: Python 3.12 con bibliotecas fijadas para reproducibilidad:
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Fuente: GitHub oficial)
- Reproducibilidad: random_state=42 se utilizó consistentemente en todos los divisiones, inicializaciones y modelos.
Conjuntos de datos: El espectro semántico
Evaluamos los modelos en 17 conjuntos de datos de aprendizaje supervisado obtenidos de OpenML y Scikit-Learn. En lugar de selección aleatoria, curamos esta suite para abarcar el "Espectro Semántico-Numerical" probando la hipótesis de que los LLM sobresalen donde las características contienen significado lingüístico en lugar de solo estadísticas puras.
El inventario:
- Pequeños y semánticos (<1K filas):
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Medios/mixtos (1K – 10K filas):
- credit_g (1K), titanic (1.3K), car_evaluation (1.7K), spambase (4.6K), compas (5.2K), employee_salaries (9.2K).
- Grandes/numéricos (10K+ filas):
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (muestreado a 100K).
Tareas cubiertas:
- 11 tareas de clasificación binaria
- 2 tareas de clasificación multiclase
- 4 tareas de regresión
Configuraciones de modelos y preprocesamiento
Buscamos una "comparación práctica" realista, utilizando valores predeterminados sólidos en lugar de un ajuste exhaustivo de hiperparámetros.
LightGBM & CatBoost
Para garantizar una comparación justa contra el modelo SAP computacionalmente pesado, aumentamos los estimadores robustos predeterminados.
- LightGBM: n_estimators=500, learning_rate=0.05, num_leaves=31. Se ejecuta en CPU (n_jobs=-1).
- CatBoost: iterations=500, learning_rate=0.05, depth=6. Se ejecuta en GPU (task_type="GPU").
- Preprocesamiento: Codificación de etiquetas simple para categóricos; sin escalado para numéricos; imputación de mediana/moda para valores faltantes.
SAP-RPT-1-OSS
Configuramos SAP para equilibrar el rendimiento y el costo basándonos en nuestros experimentos de configuración preliminares.
- Configuración: max_context_size=4096, bagging=4.
- Nota:
- Contexto: Las pruebas en adult_income mostraron que aumentar el contexto de 4096 a 8192 triplicó el tiempo de ejecución (4 min a 12 min) para una ganancia de precisión insignificante (0.917 vs 0.917 ROC-AUC).
- Bagging: Aumentar bagging de 4 a 8 (la configuración predeterminada de SAP utilizada en el artículo9 ) ofreció rendimientos decrecientes.
- Preprocesamiento: Ninguno. El DataFrame de pandas sin procesar se pasa directamente. El modelo codifica usando incrustaciones de texto (sentence-transformers/all-MiniLM-L6-v2).
Protocolo de evaluación
Estrategia de validación cruzada
Utilizamos Validación Cruzada de 3 Pliegues con mezcla.
- Reducimos los 5 pliegues estándar a 3 pliegues para acomodar los tiempos de inferencia lentos de SAP (ahorro de tiempo del 40%) mientras mantenemos la validez estadística.
- División: StratifiedKFold para clasificación; K-Fold estándar para regresión.
Métricas y diagnósticos
Avanzamos más allá de la simple precisión para capturar una visión holística del rendimiento del modelo:
- Métricas de clasificación principales: ROC-AUC (Binario), Precisión equilibrada (Multiclase), R² (Regresión).
- Diagnósticos secundarios: Rastreamos el coeficiente de correlación de Matthews (MCC) y la pérdida logarítmica para asegurar que las victorias no fueran artefactos de desequilibrio de clases, y MAPE para la calibración del error de regresión.
- Cálculo de costos: Basado en el tiempo total de reloj (preprocesamiento + entrenamiento + inferencia) en la instancia RunPod H200 ($3.59/h).
Significancia estadística
Aplicamos una prueba de rangos con signo de Wilcoxon (p<0.05) a comparaciones de modelos por pares para determinar si las diferencias de rendimiento eran estadísticamente significativas o ruido aleatorio.
Limitaciones y validez interna
Acknowledgemos explícitamente las siguientes restricciones en nuestra metodología:
- Configuraciones estandarizadas vs ajuste: Utilizamos configuraciones predeterminadas fijas y sólidas para todos los modelos en lugar de realizar una optimización exhaustiva de hiperparámetros (por ejemplo, CV anidado o barridos de Optuna). Si bien esto asegura una línea base consistente, vale la pena señalar que los modelos de árboles a menudo ven ganancias de rendimiento con un ajuste específico del conjunto de datos, lo que podría reducir los márgenes en el grupo "Competitivo".
- Límites de escala de datos: Nuestro análisis se centró en conjuntos de datos de menos de 100k filas para simular escenarios típicos de empresas de tamaño mediano. Observamos que la ventaja del LLM disminuía a medida que crecía el volumen de datos, pero no extendimos las pruebas a escalas de millones de filas donde la latencia de inferencia y el costo probablemente se convertirían en las principales restricciones.
- Uniformidad de infraestructura: Para mantener un entorno de prueba consistente, ejecutamos todos los modelos en el mismo hardware NVIDIA H200. LightGBM y CatBoost están altamente optimizados para CPU de consumo; por lo tanto, en un entorno de producción dedicado exclusivamente a modelos de árboles, la diferencia de costos probablemente sería mayor.
- Generalización más allá de la semántica: Nuestra hipótesis de "Espectro Semántico" predijo con éxito muchos resultados, pero el fuerte rendimiento del LLM en conjuntos de datos abstractos como sonar y california_housing sugiere capacidades más allá de la comprensión lingüística. Esto indica que el modelo también puede estar aprovechando patrones de regularización de alta dimensión, un fenómeno que merece una investigación más allá del alcance de este estudio inicial.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{Comparar Modelos Fundacionales Relacionales}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Recuperado el 2 de Julio de 2026}
}


 en múltiples dominios.")
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.