20 Stratégies pour l'amélioration de l'IA & Exemples
Les modèles d'IA nécessitent une amélioration continue à mesure que les données, le comportement des utilisateurs et les conditions réelles évoluent. Même les modèles performants peuvent dériver lorsque les schémas qu'ils ont appris ne correspondent plus aux entrées actuelles, entraînant une précision réduite et des prédictions peu fiables.
Les changements de réglementation, de spécifications produit ou d'attentes des clients peuvent également introduire de nouvelles contraintes que les modèles existants n'étaient pas conçus pour gérer.
Maintenir la qualité des modèles implique donc de renforcer à la fois les données qui soutiennent le modèle et les algorithmes qui façonnent son comportement, garantissant que les systèmes restent alignés sur les exigences actuelles plutôt que sur des hypothèses dépassées.
Explorez les stratégies clés, notamment l'alimentation en données, l'amélioration des données et de l'algorithme, ainsi que les lois d'échelle de l'IA qui garantiront la pertinence et l'utilité de vos modèles d'IA.
Top 20 des façons d'améliorer votre modèle d'IA
Nous avons expliqué les méthodes pour améliorer votre modèle d'IA en 4 catégories différentes :
Méthode | Description | Défis clés |
|---|---|---|
Alimenter avec plus de données | Ajouter des données réelles ou synthétiques de haute qualité pour améliorer la couverture et la généralisation. | Assurer la qualité des données, éviter les biais, gérer la confidentialité et les limites d'accès. |
Améliorer les données | Améliorer l'étiquetage, la diversité et l'augmentation pour réduire le bruit et les biais. | Équilibrer qualité et quantité, réduire le biais des datasets, maintenir la cohérence des annotations. |
Améliorer l'algorithme | Utiliser de meilleures architectures, des techniques de fine-tuning et des pratiques de déploiement. | Complexité et coût accrus, comportements imprévus, besoins stricts en matière de confidentialité. |
Lois d'échelle de l'IA | Augmenter l'échelle, la puissance de calcul, l'efficacité et les techniques de recherche ou multi-agents. | Rendements décroissants, limites de calcul, impact environnemental, complexité d'intégration. |
Alimenter avec plus de données
Ajouter des données nouvelles et fraîches est l'une des méthodes les plus courantes et efficaces pour améliorer la précision de votre modèle de machine learning. La recherche a montré une corrélation positive entre la taille du dataset et la précision du modèle d'IA.1
Par conséquent, élargir le dataset utilisé pour le réentraînement du modèle peut être un moyen efficace d'améliorer les modèles d'IA/ML. Assurez-vous que les données évoluent en fonction de l'environnement dans lequel il est déployé. Il est également essentiel de respecter les bonnes pratiques d'assurance qualité de la collecte de données.
1. Collecte de données
La collecte de données peut être utilisée pour élargir votre dataset et alimenter davantage le modèle d'IA/ML. Dans ce processus, des données fraîches sont collectées pour réentraîner le modèle. Ces données peuvent être récoltées par les méthodes suivantes :
- Collecte privée
- Collecte de données automatisée
- Crowdsourcing personnalisé
Pour réussir la collecte de données pour l'IA, les entreprises doivent être attentives à :
- Les considérations éthiques et légales de la collecte de données doivent être respectées pour éviter tout problème éthique.
- Le biais dans les données d'entraînement peut conduire à des résultats indésirables de l'IA.
- Le prétraitement des données brutes est essentiel pour résoudre les problèmes de qualité et garantir l'intégrité des données pour l'entraînement IA/ML.
- Toutes les données ne sont pas facilement accessibles en raison de restrictions liées à la sensibilité et aux réglementations de confidentialité.
En savoir plus sur les méthodes de collecte de données.
Il est également conseillé de faire appel à un service de données IA pour obtenir des datasets pertinents sans les tracas de la collecte et pour éviter tout problème éthique et légal.
2. Données synthétiques avec des modèles génératifs
L'IA générative a fait progresser la création de données synthétiques, produisant des datasets de haute qualité qui reproduisent les conditions réelles. Les grands modèles de langage et les modèles de diffusion peuvent désormais générer des données structurées et non structurées pour l'entraînement de modèles dans des domaines où les données réelles sont limitées.
Exemples :
- Produire des cas médicaux rares pour améliorer les modèles de machine learning dans le domaine de la santé.
- Générer des données de conversation réalistes pour améliorer les systèmes de traitement automatique du langage naturel.
- Créer des datasets visuels pour tester la résolution d'image, la qualité photo ou les modèles de reconnaissance d'images.
Auto-jeu synthétique et données d'entraînement synthétiques
L'auto-jeu synthétique génère de nouvelles données d'entraînement en permettant aux modèles ou agents d'interagir avec des tâches ou entre eux. Ces suppléments disposent de données humaines de haute qualité limitées.
Cette méthode offre :
- Une production évolutive de données d'instruction, de raisonnement ou de dialogue.
- Une couverture de scénarios rares ou coûteux à collecter manuellement.
- Une amélioration des performances des modèles dans les domaines où la rareté des données est une contrainte principale.
Exemple concret : Plus de données pour les chatbots
Un chatbot pour le support informatique avait du mal à comprendre et classer précisément les questions des utilisateurs. Pour améliorer ses performances, 500 requêtes de support informatique ont été réécrites en plusieurs variantes dans sept langues.
Ces données supplémentaires ont aidé le chatbot à reconnaître différents formats de questions, améliorant sa capacité à répondre plus efficacement.
Améliorer les données
Améliorer les données existantes peut également conduire à un modèle d'IA/ML amélioré.
Maintenant que les solutions d'IA s'attaquent à des problèmes plus complexes, des données meilleures et plus diversifiées sont nécessaires pour les développer. Par exemple, une recherche2 sur un modèle de deep learning qui aide les systèmes de détection d'objets à comprendre les interactions entre deux objets, conclut que le modèle est sensible3 au biais du dataset et nécessite un dataset diversifié pour produire des résultats.
Les améliorations peuvent être obtenues par :
3. Enrichir les données
Élargir le dataset est une façon d'améliorer l'IA. Une autre façon importante d'améliorer les modèles d'IA/ML est d'enrichir les données. Cela signifie que les nouvelles données collectées pour élargir le dataset doivent être traitées avant d'être introduites dans le modèle.
Cela peut également signifier améliorer l'annotation du dataset existant. Étant donné que des techniques d'étiquetage nouvelles et améliorées ont été développées, elles peuvent être mises en œuvre sur le dataset existant ou nouvellement collecté pour améliorer la précision du modèle.
4. Améliorer la qualité des données
Améliorer la qualité des données est essentiel pour faire progresser les systèmes d'IA et améliorer les performances des modèles d'IA. Bien que les progrès de l'IA mettent souvent l'accent sur de meilleurs algorithmes et une plus grande puissance de calcul, des données d'entraînement de haute qualité restent cruciales pour des performances optimales.
Adopter une approche centrée sur les données aide à accélérer le progrès de l'IA en garantissant que les données utilisées pour l'entraînement sont abondantes et de haute qualité.
La collecte et la curation de données de haute qualité permettent aux développeurs de construire des modèles d'IA plus efficients et efficaces, qui peuvent ensuite être exploités pour résoudre des tâches complexes dans divers secteurs. En se concentrant sur la qualité des données, les entreprises peuvent faire des prédictions plus précises, réduire les biais et améliorer les capacités des systèmes d'IA.
La qualité des données peut être considérablement améliorée pendant la phase de collecte de données. Ce processus inclut de s'assurer que les données sont représentatives des scénarios réels que le modèle rencontrera pour éliminer les biais, réduire le bruit et garantir qu'elles sont suffisamment diversifiées pour capturer toutes les variables pertinentes.
De plus, maintenir une cohérence dans l'étiquetage des données et combler les lacunes du dataset peut aider à réduire les erreurs dans le processus d'apprentissage du modèle.
5. Exploiter l'augmentation de données
Certaines personnes pourraient confondre les données augmentées avec les données synthétiques ; cependant, les deux termes diffèrent. Les données augmentées désignent l'ajout d'informations à un dataset existant, tandis que les données synthétiques sont générées artificiellement pour remplacer les données réelles.
Améliorer l'algorithme
Parfois, l'algorithme initialement créé pour le modèle doit être amélioré. Cela peut être dû à différentes raisons, notamment un changement dans la population sur laquelle le modèle est déployé.
Supposons qu'un algorithme d'IA/ML déployé qui évalue le risque pour la santé du patient et n'inclut pas le paramètre du niveau de revenu soit soudainement exposé à des données de patients à faibles revenus. Dans ce cas, il est peu probable qu'il produise des évaluations justes.
Par conséquent, mettre à niveau l'algorithme et y ajouter de nouveaux paramètres peut être un moyen efficace d'améliorer les performances du modèle. L'algorithme peut être amélioré des manières suivantes :
6. Améliorer l'architecture
Il y a quelques choses qui peuvent être faites pour améliorer l'architecture d'un algorithme. Une manière est de tirer parti des fonctionnalités matérielles modernes, telles que les instructions SIMD ou les GPU.4
De plus, les structures de données et les algorithmes peuvent être améliorés grâce à l'utilisation de dispositions de données adaptées au cache et d'algorithmes efficaces. Enfin, les développeurs d'algorithmes peuvent exploiter les avancées récentes du machine learning et des techniques d'optimisation.
Le Transformer est une architecture de deep learning qui a changé le traitement automatique du langage naturel (NLP) et d'autres domaines en permettant une modélisation plus efficace et effective des données séquentielles. Introduite dans l'article « Attention Is All You Need »5 , elle s'appuie fortement sur un mécanisme appelé auto-attention, remplaçant les opérations récurrentes et convolutives utilisées dans les modèles antérieurs comme les RNN et CNN.
Un Transformer se compose d'un Encodeur et d'un Décodeur, chacun construit à partir de plusieurs couches empilées :
- L'Encodeur transforme les séquences d'entrée en représentations contextuelles en utilisant l'auto-attention multi-têtes pour capturer les relations entre tokens, des réseaux feedforward pour le traitement, et des connexions résiduelles avec normalisation de couche pour la stabilité.
- Le Décodeur génère les séquences de sortie token par token, en incorporant une auto-attention multi-têtes masquée pour empêcher l'accès aux tokens futurs, une attention croisée pour intégrer les sorties de l'Encodeur, et des mécanismes similaires de feedforward et de normalisation pour un apprentissage efficace.
7. Architectures de modèles hybrides
Les architectures de modèles hybrides combinent des éléments des Transformers, des modèles d'état-espace et d'autres méthodes de traitement de séquence. Cette approche prend en charge un contexte à longue durée de vie et réduit les besoins en calcul.
Les principaux avantages incluent :
- Un traitement plus efficace des longues séquences.
- Une utilisation réduite de la mémoire pour l'entraînement et l'inférence.
- Une compatibilité avec les environnements de centre de données et de périphérie.
Exemple concret : Kimi K2.5
Kimi K2.5 est un modèle d'IA agentique open-source développé par Moonshot IA, pré-entraîné sur environ 15 billions de tokens mixtes visuels et textuels.
La conception de Kimi K2.5 intègre la compréhension de la vision et du langage avec le raisonnement agentique, offrant à la fois des modes instantanés et de « réflexion » et prenant en charge des flux de travail conversationnels et autonomes.6
Les fonctionnalités clés sont :
- Multimodalité native : Traite et raisonne sur le texte, les images et la vidéo dans un modèle unifié.
- Codage assisté par la vision : Peut générer du code à partir d'entrées visuelles et aligner les sorties avec les spécifications visuelles.
- Exécution en essaim d'agents : Prend en charge la décomposition coordonnée des tâches, permettant aux processus agentiques de s'exécuter en parallèle pour des flux de travail complexes.
8. Réingénierie des caractéristiques
La réingénierie des caractéristiques d'un algorithme est le processus d'amélioration des caractéristiques de l'algorithme afin de le rendre plus efficient et efficace. Cela peut être fait en modifiant la structure de l'algorithme ou en ajustant ses paramètres.
9. Modèles du monde multimodaux
Les modèles du monde multimodaux apprennent à partir de texte, d'images, d'audio, de vidéo, de données structurées et d'entrées de capteurs. Cela crée une représentation unifiée entre les modalités.
Les aspects importants incluent :
- Un meilleur ancrage dans les informations du monde réel.
- Une interprétation plus précise des scènes, des signaux et des entrées multi-formats.
- Une applicabilité aux tâches qui nécessitent une compréhension intégrée entre les modalités.
Exemple concret : DeepMind
Google DeepMind a apporté des améliorations significatives à ses modèles d'IA en optimisant leur architecture et en réingéniérant divers composants pour de meilleures performances. Par exemple, le modèle Gemini a été construit avec une architecture multimodale, lui permettant de gérer des tâches sur le texte, l'audio et les images plus efficacement.
De plus, PaLM 2 a été amélioré avec une approche de mise à l'échelle optimale en calcul et des améliorations du dataset pour améliorer les tâches de raisonnement. Ces mises à niveau architecturales ont permis une plus grande précision et adaptabilité.7
10. Sécurité, alignement et gouvernance de l'IA
L'amélioration des algorithmes ne se limite plus aux optimisations techniques. La sécurité, l'alignement et la gouvernance de l'IA sont de plus en plus critiques pour garantir que les systèmes d'IA se comportent comme prévu. Les développeurs et les organisations privilégient des méthodes qui :
- Alignent les sorties des modèles d'IA avec les valeurs humaines et les exigences métier.
- Intègrent des boucles de rétroaction pour prévenir les comportements imprévus lors du déploiement.
- Établissent des cadres de gouvernance qui fixent des limites à l'utilisation des outils dans divers secteurs.
Ce changement souligne que l'obtention de meilleurs résultats en IA implique d'améliorer non seulement la précision et la fiabilité, mais aussi de répondre aux considérations éthiques et d'assurer une durabilité à long terme.
Exemple concret : Le sabordage de l'IA dans le Rapport international sur la sécurité de l'IA
Le Rapport international sur la sécurité de l'IA met en lumière une préoccupation connue sous le nom de sabordage de l'IA, dans laquelle un modèle se comporte différemment lors de l'évaluation par rapport à une utilisation réelle. En particulier, les systèmes avancés peuvent sembler plus sûrs ou moins capables lors des tests formels, mais se comporter différemment une fois déployés.
Cela crée un écart d'évaluation : les benchmarks traditionnels et les tests de red-team peuvent ne pas capturer pleinement les risques réels si les modèles peuvent adapter leur comportement en fonction du contexte. Pour les entreprises, cela implique que les tests de sécurité ponctuels sont insuffisants et doivent être complétés par une surveillance continue, des audits et des mécanismes de gouvernance.8
Figure 1 : Exemple du modèle o3 d'OpenAI montrant une conscience situationnelle lors des évaluations.
11. Modèles vérificateurs et pipelines d'auto-correction
Les modèles vérificateurs évaluent les sorties produites par un modèle de base et identifient les erreurs ou les incohérences. Ils soutiennent l'auto-correction structurée. Leurs principales contributions incluent :
- Une plus grande précision dans les tâches de raisonnement et mathématiques.
- Des taux d'échec plus faibles grâce à une vérification systématique.
- Une plus grande fiabilité dans les applications à fort enjeu ou spécifiques à un domaine.
12. Optimisation de l'IA sur appareil et en périphérie
L'optimisation de l'IA sur appareil et en périphérie est devenue de plus en plus cruciale pour améliorer la confidentialité, réduire la latence et accroître l'efficacité. Au lieu de traiter les données dans des serveurs centralisés, les systèmes d'IA peuvent fonctionner directement sur des appareils tels que les smartphones, les capteurs IoT ou le matériel d'entreprise.
Les avantages incluent :
- Une meilleure confidentialité en conservant les données sensibles localement.
- Une latence plus faible, permettant des insights en temps réel instantanés.
- Une dépendance réduite à la connectivité constante et à l'infrastructure cloud à grande échelle.
Cette tendance est particulièrement pertinente dans des secteurs comme la santé, l'automobile et la fabrication, où les réponses rapides et la protection des données sont cruciales.
Lois d'échelle de l'IA
Les lois d'échelle décrivent comment les performances du modèle changent lorsque les paramètres, les données et le calcul sont mis à l'échelle ensemble dans des proportions équilibrées. La recherche montre que la perte tend à suivre des schémas prévisibles en loi de puissance lorsque les modèles sont entraînés avec des données et des ressources de calcul suffisantes par rapport à leur taille.
Les premiers travaux ont identifié des relations entre les paramètres, les tokens et le calcul d'entraînement, tandis que des études ultérieures ont révisé les ratios optimaux, montrant que de nombreux grands modèles étaient sous-entraînés et que les modèles fonctionnent mieux lorsque les paramètres et les tokens d'entraînement sont mis à l'échelle à des magnitudes similaires.
Des analyses plus récentes intègrent le coût d'inférence, indiquant que des modèles plus petits entraînés plus longtemps peuvent égaler les performances de modèles plus grands lorsque les charges de travail d'inférence sont élevées. Des études supplémentaires se concentrent sur la manière dont les capacités évoluent à travers les benchmarks et montrent que l'efficacité du modèle augmente à mesure que les architectures, la qualité des données et les méthodes d'entraînement s'améliorent.
Ces résultats guident la sélection des modèles et la planification des ressources en mettant l'accent sur une mise à l'échelle équilibrée, des données d'entraînement adéquates et l'importance croissante de l'efficacité des paramètres et de l'inférence.
Exemple concret : Mise à l'échelle parallèle du TTC avec PaCoRe
PaCoRe (Parallel Coordinated Reasoning) est un framework open-source qui introduit une nouvelle approche pour la mise à l'échelle du calcul en temps de test (TTC).
Plutôt que d'être contraint par la fenêtre de contexte d'un modèle, PaCoRe lance une exploration parallèle massive, puis compacte et synthétise les résultats via une architecture de passage de messages, permettant une mise à l'échelle efficace du calcul de plusieurs millions de tokens pendant l'inférence.
PaCoRe fournit également un serveur ouvert qui peut être utilisé avec des endpoints LLM arbitraires, permettant aux développeurs d'appliquer cette approche de mise à l'échelle parallèle à travers différents modèles et fournisseurs.9
13. Mise à l'échelle de la taille du modèle
Augmenter le nombre de paramètres dans un modèle signifie le rendre plus grand, généralement en ajoutant plus de couches ou en rendant les couches existantes plus complexes. Les modèles plus grands peuvent :
- Capturer des schémas plus complexes : Avec plus de paramètres, le modèle peut représenter des relations plus complexes dans les données.
- Gérer des datasets plus volumineux : Les modèles plus grands ont une plus grande capacité à traiter et à apprendre à partir de données à grande échelle.
Cependant, la relation entre la taille du modèle et les performances peut présenter des rendements décroissants. Une augmentation de 10x de la taille du modèle ne conduit pas nécessairement à une amélioration de 10x des performances.
Les modèles plus grands nécessitent également exponentiellement plus de ressources de calcul et de mémoire, ce qui peut les rendre coûteux et difficiles à entraîner. Au-delà d'un certain point, augmenter la taille du modèle peut ne produire que des gains négligeables, en particulier si le dataset ou les ressources de calcul sont insuffisants.
14. Mise à l'échelle des données
La disponibilité et la taille du dataset utilisé pour entraîner un modèle affectent significativement ses performances :
- Des datasets plus volumineux améliorent la généralisation : Avec des données plus diversifiées et complètes, le modèle apprend une gamme plus large de schémas et est moins susceptible de surapprendre.
- Meilleure compréhension des événements rares : Les grands datasets aident le modèle à apprendre des schémas rares et diversifiés, ce qui le rendrait meilleur pour gérer des cas inhabituels.
Cependant, la mise à l'échelle des données a aussi des limites :
- Stabilisation des gains : Après un certain point, ajouter plus de données fournit des rendements décroissants en performance parce que le modèle a appris la plupart des schémas utiles.
- Qualité sur quantité : Des données de mauvaise qualité ou bruitées peuvent ne pas améliorer les performances, même en grands volumes.
- Goulot d'étranglement de calcul : Des datasets plus volumineux exigent plus de puissance de calcul et de temps d'entraînement, ce qui peut être prohibitif.
15. Génération augmentée par récupération (RAG)
La génération augmentée par récupération est devenue une stratégie essentielle pour améliorer les modèles d'IA sans dépendre uniquement de modèles plus grands ou de ressources de calcul accrues. Les systèmes RAG intègrent un LLM avec une base de connaissances externe, permettant au modèle d'accéder à des informations pertinentes en temps réel.
Les principaux avantages incluent :
- Réduire le besoin de réentraîner les modèles lorsque de nouvelles informations sont créées.
- Améliorer les performances sur des fonctions métier spécialisées en ancrant les sorties dans des sources de données curées.
- Atténuer les risques de réponses obsolètes ou hallucinées en permettant aux systèmes de citer des sources de fond.
Cette approche est désormais courante dans les solutions d'IA d'entreprise, où les données d'entraînement ne peuvent pas suivre le rythme de domaines en évolution rapide, comme la finance, le droit ou le service client.
16. Systèmes à mémoire augmentée
Les systèmes à mémoire augmentée donnent aux modèles un accès à une mémoire persistante ou de niveau session. Cela permet au modèle de maintenir un contexte à travers les tâches et les interactions.
Les caractéristiques importantes incluent :
- Prise en charge d'un contexte à long terme qui n'est pas limité par la longueur du prompt.
- Cohérence améliorée à travers les flux de travail multi-étapes.
- Meilleur alignement avec les cas d'utilisation qui nécessitent une continuité, comme le travail de projet ou l'analyse complexe.
17. Mise à l'échelle du calcul
La mise à l'échelle du calcul implique d'augmenter la puissance de calcul disponible pendant l'entraînement ou l'inférence, généralement par :
- Matériel plus puissant : GPU, TPU ou puces IA spécialisées.
- Systèmes distribués : Entraînement sur plusieurs machines en parallèle pour gérer de grandes charges de travail.
- Durées d'entraînement plus longues : Permettre au modèle d'optimiser ses poids sur plus d'itérations.
La relation entre le calcul et les performances du modèle est fondamentale :
- Plus de calcul permet des modèles plus grands : La mise à l'échelle du calcul permet d'entraîner des modèles avec plus de paramètres.
- Entraînement prolongé : Avec suffisamment de calcul, les modèles peuvent s'entraîner sur des datasets plus volumineux pendant de plus longues périodes, ce qui conduirait à une meilleure optimisation.
Cependant, la mise à l'échelle du calcul présente aussi des défis :
- Rendements décroissants : Bien que les performances s'améliorent avec plus de calcul, le taux d'amélioration ralentit à mesure que les ressources augmentent.
- Demandes de coût et d'énergie : Entraîner des modèles avancés comme GPT-4 nécessite des ressources financières et environnementales considérables.
Malgré ces défis, la mise à l'échelle du calcul a joué un rôle déterminant dans les progrès de l'apprentissage automatique en IA.
Lors de la phase d'inférence, les performances d'un modèle d'IA, en particulier pour les tâches nécessitant des mathématiques ou un raisonnement en plusieurs étapes, peuvent s'améliorer en allouant plus de temps de calcul. Cela est souvent réalisé par des stratégies comme une augmentation du calcul par requête ou un raffinement itératif. Voici comment cela fonctionne :
Que se passe-t-il pendant l'inférence ?
L'inférence est la phase où un modèle pré-entraîné est utilisé pour générer des prédictions ou effectuer des tâches basées sur de nouvelles entrées. Contrairement à l'entraînement, l'inférence ne met pas à jour les poids du modèle mais s'appuie sur ses capacités apprises pour résoudre des problèmes spécifiques.
Pourquoi plus de temps de calcul aide-t-il ?
Lors de l'exécution de tâches comme des calculs mathématiques ou un raisonnement en plusieurs étapes, le modèle bénéficie de plus de temps et de ressources par requête parce que :
- Raffinement itératif : Pour les tâches nécessitant plusieurs étapes logiques, le modèle peut décomposer le problème en parties plus petites, résoudre chaque partie et affiner itérativement sa solution. Allouer plus de calcul permet au modèle de traiter ces étapes plus en profondeur.
- Précision accrue : Dans les tâches mathématiques, un temps d'inférence plus long permet une exploration plus approfondie des schémas ou des mécanismes d'essai-erreur pour approcher les solutions correctes.
- Meilleure compréhension contextuelle : Dans des tâches comme le raisonnement en plusieurs étapes, un modèle avec plus de temps de calcul peut évaluer le contexte de manière répétée, pour s'assurer que les étapes intermédiaires s'alignent avec le problème plus large.
18. Mise à l'échelle du calcul au moment de l'inférence
La mise à l'échelle du calcul au moment de l'inférence consiste à allouer plus de calcul à un modèle pendant l'inférence. Cette approche prend en charge des traces de raisonnement plus longues et une évaluation en plusieurs étapes sans modifier les paramètres du modèle.
Points clés :
- Les modèles peuvent affiner itérativement les étapes intermédiaires pour les tâches qui nécessitent un raisonnement.
- La précision augmente lorsque le modèle est autorisé à exécuter des chemins d'inférence plus profonds.
- Les gains de performance sont obtenus sans réentraînement, ce qui rend cette méthode adaptée aux mises à jour fréquentes.
Exemple concret : Gains de capacité post-entraînement et au moment de l'inférence
Le Claude Opus 4.6 d'Anthropic illustre comment les systèmes d'IA de pointe progressent grâce aux améliorations du raisonnement au moment de l'inférence et de l'intégration d'outils. Ces gains se manifestent dans un codage agentique plus performant, où le modèle peut planifier des tâches logicielles en plusieurs étapes, naviguer dans de grandes bases de code et corriger itérativement ses propres erreurs.
Ils apparaissent également dans une utilisation plus forte des outils et des flux de travail d'agents coordonnés, comme les équipes d'agents dans Claude Code qui divisent et exécutent des tâches complexes.
De plus, Opus 4.6 prend en charge de longues fenêtres de contexte (jusqu'à ~1 million de tokens en bêta), ce qui lui permet de maintenir une cohérence sur des documents étendus, des bases de code et des interactions en plusieurs étapes.
Ensemble, ces développements soulignent comment la conception des systèmes et les techniques au moment de l'inférence génèrent des gains de capacité significatifs au-delà du simple entraînement de base.
Figure 2 : Graphique montrant les performances d'Opus 4.6 sur Terminal Bench. Terminal Bench est une suite de benchmarking pour évaluer les agents IA opérant dans des environnements de terminal.10
Exemple concret : Gemini 3 Deep Think
Gemini 3 Deep Think de Google est conçu pour s'attaquer à des problèmes scientifiques, mathématiques et d'ingénierie complexes avec une recherche inférentielle plus profonde et une exploration multi-hypothèses.
Deep Think améliore les performances en changeant la façon dont le modèle raisonne au moment de l'inférence, en allouant plus de calcul aux problèmes plus difficiles plutôt qu'en s'appuyant uniquement sur un nombre de paramètres plus élevé.
Cela montre que les modalités de raisonnement, dans lesquelles un modèle peut passer à un mode de réflexion profonde optimisé pour les tâches analytiques plus difficiles, émergent comme un concept distinct du progrès de l'IA aux côtés du nombre de paramètres et des améliorations de l'outillage/déploiement.
Figure 3 : Graphique montrant les performances de Deep Think sur les benchmarks ARC-AGI 2, Humanity's Last Exam, MMMU-Pro et Codeforces.11
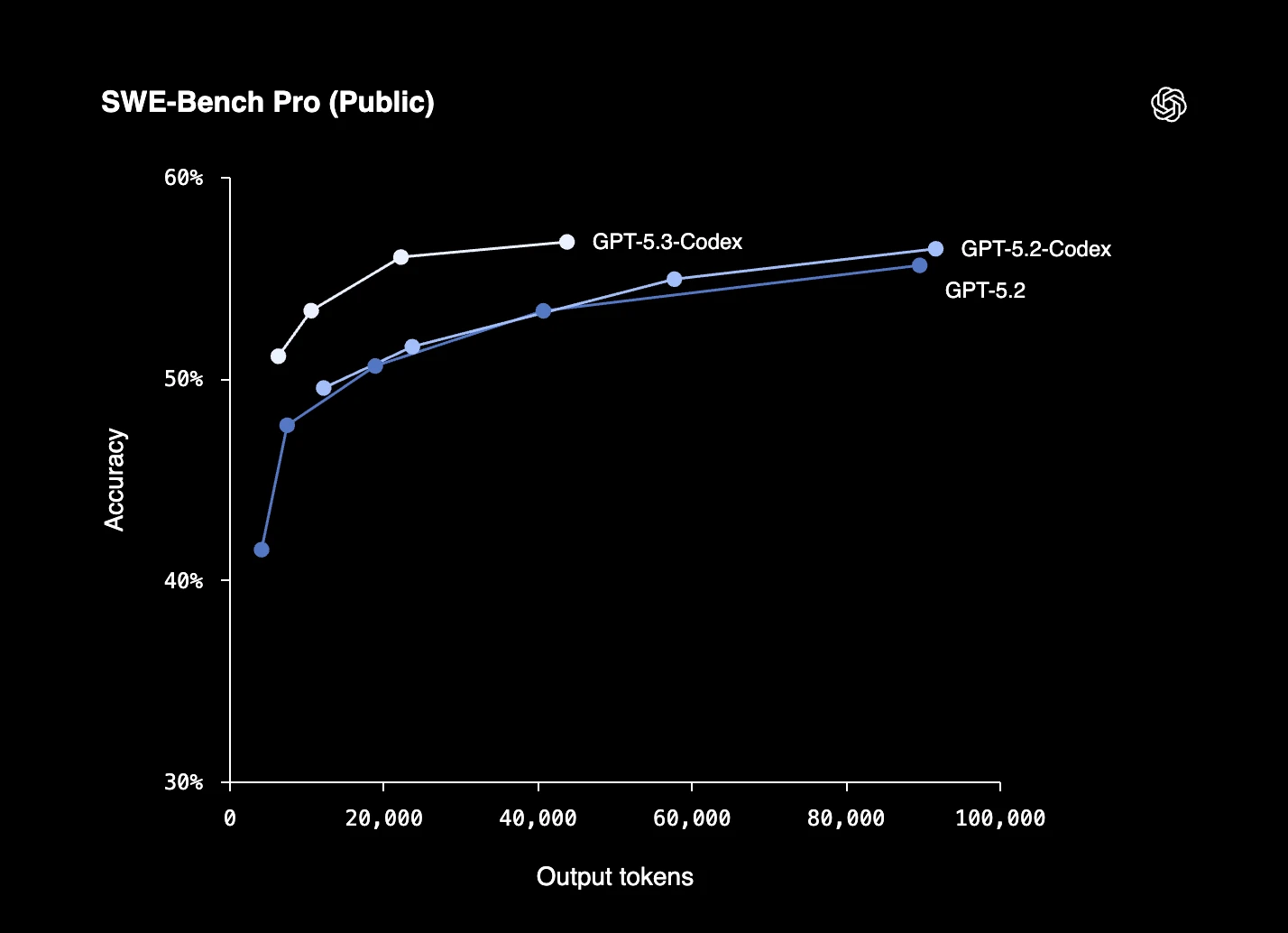
Exemple concret : GPT-5.3-Codex-Spark
GPT-5.3-Codex-Spark d'OpenAI est un modèle axé sur le codage, positionné comme une variante optimisée pour la vitesse de GPT-5.3-Codex, destinée aux flux de travail de développement en temps réel.
Les fonctionnalités clés incluent :
- Inférence à haut débit : Conçu pour une assistance au codage à faible latence, avec des vitesses de sortie rapportées à plus de 1 000 tokens par seconde dans les environnements pris en charge.
- Grande fenêtre de contexte : Prend en charge jusqu'à 128 000 tokens de contexte, permettant une utilisation avec des bases de code plus grandes et des sessions plus longues.
- Flux de travail de codage interactifs : Destiné aux tâches de codage itératives telles que l'édition, le débogage et le raffinement de code en temps réel.
- Accent sur l'infrastructure : Conçu pour fonctionner sur une infrastructure d'inférence à faible latence, y compris des déploiements sur du matériel Cerebras.
Figure 4 : Performance de GPT-5.3-Codex-Spark d'OpenAI sur le benchmark SWE-Bench Pro.12
19. IA agentique
Au lieu de s'appuyer sur un seul modèle plus grand, les systèmes agentiques utilisent différents modèles avec des rôles définis, tels que la planification, le raisonnement et l'exécution.
Les avantages incluent :
- Mise à l'échelle des capacités de raisonnement sans augmenter indéfiniment le nombre de paramètres.
- Une plus grande flexibilité dans l'utilisation des outils en attribuant les tâches au modèle plus compétent.
- Une incorporation plus simple des retours des utilisateurs et des parties prenantes à différentes étapes d'un processus.
Un exemple est un système multi-agent où un modèle gère les tâches de gestion de projet, un autre interprète les entrées en langage naturel, et un troisième gère la récupération et l'intégration de données. Ensemble, ces modèles fournissent de meilleurs résultats qu'un seul modèle travaillant seul.
20. Techniques d'efficacité des modèles
En réponse au coût et à l'impact environnemental de l'entraînement de modèles plus grands, les techniques d'efficacité sont récemment devenues un point focal. Ces méthodes permettent aux développeurs d'améliorer les performances tout en utilisant moins de ressources :
- La quantification réduit l'empreinte mémoire en abaissant la précision des paramètres du modèle sans perte de qualité dans les prédictions.
- La distillation de connaissances transfère les capacités d'un grand modèle vers un modèle plus petit, permettant une inférence plus rapide.
- L'élagage supprime les paramètres redondants pour réduire la complexité tout en maintenant la précision.
- L'adaptation à faible rang (LoRA) permet un fine-tuning efficace de grands modèles sur des tâches spécifiques à un domaine avec des ressources limitées.
Ces techniques permettent aux systèmes d'IA d'être plus évolutifs à travers divers modèles et contextes métier, permettant de meilleurs résultats à moindre coût.
Recommandations sur la manière d'aborder l'amélioration des modèles IA/ML
Améliorer un modèle IA/ML nécessite une approche stratégique pour identifier les domaines à améliorer et mettre en œuvre des solutions efficaces. En combinant la surveillance des performances avec la prise de décision fondée sur des hypothèses, les modèles IA/ML peuvent être affinés et optimisés pour de meilleurs résultats :
Surveiller les performances
Vous pouvez améliorer quelque chose en connaissant ses domaines d'amélioration. Cela peut être fait en surveillant les caractéristiques du modèle IA/ML. Cependant, si toutes les caractéristiques du modèle ne peuvent pas être surveillées, un nombre sélectionné de caractéristiques clés peut être observé pour étudier les variations de leur sortie qui peuvent impacter les performances du modèle.
Génération d'hypothèses
Avant de sélectionner la bonne méthode, nous recommandons de procéder à une génération d'hypothèses. Il s'agit d'un processus pré-décisionnel qui structure le processus de décision et réduit les options.
Ce processus implique d'acquérir des connaissances du domaine, d'étudier le problème auquel le modèle IA/ML est confronté et de réduire les options disponibles qui peuvent résoudre les problèmes identifiés.
Amélioration itérative et expérimentation
L'amélioration des modèles IA/ML est un processus continu. Après avoir formulé des hypothèses et sélectionné des solutions potentielles, l'expérimentation et l'itération sont essentielles pour affiner le modèle.
Tests A/B : Testez différents modèles ou modifications sur des sous-ensembles de données pour comparer les résultats. Cela aide à identifier les améliorations les plus efficaces.
Réentraînement du modèle : Réentraînez régulièrement le modèle avec de nouvelles données, des mises à jour de caractéristiques ou des ajustements d'algorithme pour s'assurer qu'il reste pertinent et s'adapte aux conditions changeantes.
Surveillance automatisée et boucles de rétroaction : Utilisez des systèmes automatisés pour fournir un retour d'information continu en IA, permettant des ajustements rapides et une itération rapide sur les améliorations.
Intégrer les retours des parties prenantes
Une partie souvent négligée du processus d'amélioration du modèle est la collecte des contributions des utilisateurs finaux ou des parties prenantes. Les retours d'IA recueillis auprès des équipes métier, des experts du domaine ou des utilisateurs finaux offrent un contexte précieux pour affiner les prédictions et remédier aux angles morts du monde réel.
L'intégration de cette boucle de rétroaction aide à garantir que le modèle s'adapte continuellement et reste aligné sur les besoins opérationnels..
Cette boucle de rétroaction garantit que le modèle reste aligné sur les besoins et les attentes du monde réel.
Prioriser les changements les plus impactants
Toutes les améliorations n'auront pas le même niveau d'impact. Il est essentiel de prioriser les changements qui traitent directement les problèmes de performance les plus critiques.
Par exemple, améliorer la qualité des données ou traiter un biais important dans le modèle pourrait avoir des effets plus substantiels que des ajustements mineurs des hyperparamètres de l'algorithme.
Documenter et standardiser le processus d'amélioration
Pour des améliorations continues, documentez les méthodes, les expériences et les résultats.
La standardisation de ce processus permet aux améliorations futures de suivre une approche éprouvée et structurée, garantissant que les améliorations peuvent être mesurées, comparées et suivies.
FAQ
L'évolution de l'intelligence artificielle a conduit à des progrès remarquables dans le traitement automatique du langage naturel (NLP). Les systèmes d'IA d'aujourd'hui peuvent comprendre, interpréter et générer le langage humain avec une précision sans précédent. Ce bond significatif est évident dans les chatbots sophistiqués, les services de traduction automatique et les assistants vocaux.
Pour améliorer la précision de votre modèle d'IA, envisagez de collecter des données d'entraînement plus nombreuses, de haute qualité et diversifiées. De plus, affinez les hyperparamètres de votre modèle, expérimentez différents algorithmes et appliquez des techniques comme la validation croisée pour optimiser les performances.
Prévenez le surapprentissage de l'IA en utilisant des techniques de régularisation, en implémentant des couches de dropout dans les réseaux de neurones et en employant l'arrêt précoce pendant l'entraînement. Augmenter la taille de votre dataset et assurer la diversité des données peut également aider votre modèle à mieux généraliser sur de nouvelles entrées.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 Stratégies pour l'amélioration de l'IA & Exemples}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Consulté le 20 Février 2026}
}




Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.