Yeniden Sıralayıcı Benchmark: En İyi 8 Model Karşılaştırıldı
Yoğun arama (dense retrieval) aşamasının bir yeniden sıralama evresiyle ne kadar iyileştiğini ölçmek için 8 yeniden sıralayıcı modeli ~145k İngilizce Amazon incelemesi üzerinde test ettik. multilingual-e5-base ile en iyi 100 adayı getirdik, her modelle yeniden sıraladık ve en iyi 10 sonucu, her biri kaynak incelemesinden somut detaylara atıfta bulunan 300 sorguya karşı değerlendirdik. En iyi yeniden sıralayıcı Hit@1'ı %62.67'den %83.00'e (+20.33pp) yükseltti.
Yeniden sıralayıcı benchmark sonuçları
Metrikler açıklandı:
ΔHit@1 / ΔHit@10, baz çizgisine (yeniden sıralayıcı yok) göre iyileşmeyi yüzde puanı (pp) cinsinden gösterir. Örneğin, +20.33pp, yeniden sıralayıcının Hit@1'ı baz çizgisinin %62.67'sine kıyasla 20.33 yüzde puanı iyileştirdiği anlamına gelir.
Hit@K, doğru product_id'ye sahip herhangi bir incelemenin en iyi-K sonuçlarda görünüp görünmediğini ölçer. Gerçek değer (ground truth), sorguyu oluşturan incelemenin product_id'sidir. Aynı ürünün farklı bir incelemesi en iyi-K'ya girerse, bu bir vuruş (hit) olarak sayılır. Hit@1 en katı testtir: en iyi sonuç doğru üründen mi? Hit@10 daha esnektir: doğru ürün ilk 10 sonuç arasında bir yerde var mı?
MRR@10 (Ortalama Ters Sıralama), tüm sorgular üzerinden ilk doğru sonucun 1/sıralama değerinin ortalamasını alır. İlk eşleşen product_id 1. sıradaysa, skor 1.0'dır. 2. sıradaysa 0.5'tir. 10. sıradaysa 0.1'dir. Bu, doğru ürünü mümkün olduğunca yüksek bir sıraya yerleştiren modelleri ödüllendirir.
nDCG@10 (Normalleştirilmiş İndeksli Kümülatif Kazanım), sadece ilk değil, en iyi 10'daki tüm eşleşen incelemelerin konumlarını değerlendirir. Aynı ürünün aday setinde birden fazla incelemesi varsa ve bunlardan birkaçı en iyi 10'a girerse, nDCG her birine konumuna göre puan verir. Pratikte, çoğu ürünün en iyi 100 aday arasında sadece 1-2 incelemesi olduğu için nDCG ve MRR yakın takip eder.
Recall@10, tam aday setinde (en iyi 100) bulunan tüm eşleşen incelemelerden (aynı product_id) en iyi 10'daki eşleşen incelemelerin oranını ölçer. Bir ürünün en iyi 100'de 3 incelemesi varsa ve yeniden sıralayıcı bunlardan 2'sini en iyi 10'a koyarsa, bu sorgu için Recall@10 2/3'tür. Çoğu ürünün aday setinde az sayıda tekrar eden incelemesi olduğu için, bu benchmark'ta Recall@10 ve Hit@10 neredeyse özdeştir.
Gecikme detayları
Yeniden sıralama gecikmesi, her çapraz kodlayıcının 100 aday belgeyi sorguya karşı puanlama süresini ölçer. Vektör arama süresi (~20ms) dahil edilmez çünkü tüm çalışmalarda sabit kalır ve yeniden sıralayıcıdan bağımsızdır.
Gecikme metrikleri açıklandı:
Yeniden Sıralama, çapraz kodlayıcının 100 aday belgeyi sorguya karşı puanlama süresidir. Modeller burada farklılaşır: tek bir ileri geçiş (forward pass) hızlıyken, otoregresif kodlama yavaştır.
P95, 95. yüzdelik toplam gecikmedir. Bazı sorguların daha uzun inceleme metinleri vardır, bu da tokenizasyon ve puanlama süresini artırır. P95, sorguların %95'i için beklemeniz gereken en kötü durumu gösterir.
Temel bulgular
149M'lik bir model 1.2B'lik bir modelle eşleşir
gte-reranker-modernbert-base 149M parametreye sahiptir, nemotron-rerank-1b 1.2B'ye sahiptir. İkisi de İngilizce'de %83.00 Hit@1'e ulaştı. ModernBERT mimarisi 8 kat daha küçüktür ve aynı üst düzey doğruluğu sağlar.
Bu, model boyutunun önemsiz olduğu anlamına gelmez. nemotron, MRR@10 (0.8514'e karşı 0.8483) ve Hit@10 (%88.33'e karşı %88.00) konusunda hafifçe önde gider, yani en iyi 10 genelinde ilgili belgeleri biraz daha iyi sıralar. Ancak ilk sonucun doğru olması gereken çoğu uygulama için 149M'lik model yeterlidir.
En büyük model en iyi değildir
qwen3_reranker_4b 4B parametreye sahiptir ve sorgu başına bir saniyeden fazla sürer. %77.67 Hit@1'e ulaşır ve dördüncü sırada yer alır; nemotron (1.2B), gte_modernbert (149M) ve jina (560M) geride kalır. 5.3 yüzde puan daha az doğruluk için nemotron'un gecikmesinin 4.5 katını ödersiniz.
qwen3'ün mimarisi, evet/hayır logit yaklaşımıyla nedensel dil modellemesi kullanır. Model sorgu-belge çiftini okur ve "evet, bu ilgili" olasılığını çıkarır. Kavramsal olarak temizdir, ancak otoregresif kodlama yükü nedeniyle çıkarım (inference) pahalıdır. SequenceClassification modelleri (gte_modernbert, bge) ve nemotron'un prompt'lar şablonu yaklaşımı, çifti tek bir ileri geçişte işler, bu da temelde daha hızlıdır.
Jina en iyi hız-doğruluk dengesini sunar
jina_reranker_v3, 188ms'de %81.33 Hit@1'e ulaşır. nemotron 243ms'de %83.00'e ulaşır. Sorgu başına 200ms'nin altında toplam gecikme gerekiyorsa, Jina bunu sağlayan üst seviyedeki tek modeldir. 1.67 yüzde puanlık fark, saniyede binlerce istek sunan bir üretim sisteminde ekstra 55ms'yi haklı çıkarmayabilir.
Bir yeniden sıralayıcı sonuçları kötüleştirir
mxbai_rerank_xsmall (70M parametre) %64.67 Hit@1 puanı alır. Herhangi bir yeniden sıralayıcı olmadan baz çizgisi %62.67 puan alır. İyileşme sadece 2 yüzde puandır ve bu 300 sorgu için gürültü sınırları içindedir. 70M parametre ile model, daha uzun veya daha nüanslı metinlerde sorgu-belge ilgiliğini güvenilir bir şekilde yargılamak için yeterli kapasiteye sahip değildir.
Bir yeniden sıralayıcı otomatik olarak faydalı değildir. Dağıtmadan önce gerçek verileriniz üzerinde test edin.
Arama motoru tavanı belirler
Tüm üst düzey yeniden sıralayıcılar %87-88 Hit@10 civarında birleşir. Bu tavan arama motorundan (retriever) gelir. multilingual-e5-base doğru belgeyi en iyi 100 aday arasına koymazsa, hiçbir yeniden sıralayıcı bunu kurtaramaz. Her yeniden sıralayıcının başarısız olduğu kalan %12'lik sorgular, yoğun arama motorunun ilgili belgeyi tamamen kaçırdığı durumları temsil eder.
Bu tavanın ötesine geçmek için daha iyi bir arama motoru, daha büyük bir aday havuzu veya her ikisine ihtiyaç vardır. En iyi 250 adayı test ettik ve en iyi 100'e kıyasla neredeyse hiç iyileşme bulamadık; bu da e5_base'nin yararlı adaylarını 250. sıradan çok önce tükettiği anlamına gelir.
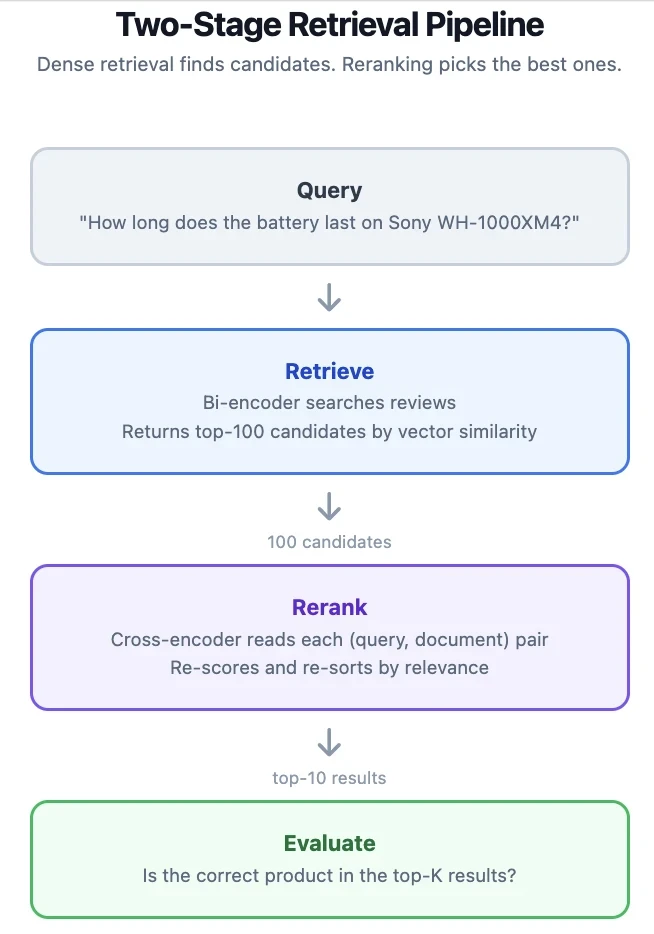
Yeniden sıralayıcılar nasıl çalışır
Bir yoğun arama motoru (bi-encoder), sorguları ve belgeleri bağımsız olarak vektörlere kodlar. Arama, bu vektörler üzerinde en yakın komşu aramasıdır. Bu hızlıdır çünkü sorguyu arama sırasında yalnızca bir kez kodlarsınız, ancak model sorguyu ve belgeyi birlikte görmez, bu nedenle nüanslı ilgili sinyalleri kaçırabilir.
Bir yeniden sıralayıcı (çapraz kodlayıcı), sorgu-belge çiftini tek bir girdi olarak alır. Model her iki metne de ortak olarak dikkat eder, bağımsız kodlamanın kaçırdığı ilişkileri yakalar. Maliyet, modelin her aday için bir kez çalıştırılması gerektiğidir, bu nedenle yalnızca küçük bir havuzu puanlayabilirsiniz.
Bu benchmark'taki mimariler
Dört farklı çapraz kodlayıcı mimarisini test ettik:
SequenceClassification modelleri (bge_base, bge_v2_m3, mxbai_xsmall, gte_modernbert) bir [query, document] çiftini girdi olarak alır ve tek bir logit skoru çıkarır. Bu en basit ve en yaygın yaklaşımdır.
Nemotron, bir prompt'lar şablonu formatı kullanır: "question:{q} passage:{p}". Girdi yapılandırılmış bir çiftten ziyade düz metin gibi görünür, ancak model yine de SequenceClassification aracılığıyla tek bir ilgili skor çıkarır. LLM ön eğitimi (Llama tabanlı), ona güçlü dil anlayışı kazandırır.
Qwen3 yeniden sıralayıcıları nedensel dil modellemesi kullanır. Model çifti okur ve evet/hayır yargısı üretir. Skor log P(evet) / (P(evet) + P(hayır))'dır. Bu, tam otoregresif mekanizmayı gerektirir, bu da daha yüksek gecikmeyi açıklar.
Jina v3, tokenizasyon ve puanlamayı dahili olarak yöneten özel bir API (model.rerank()) kullanır. Temel mimari çapraz dikkat (cross-attention) kullanır, ancak arayüz detayları soyutlar.
Yeniden sıralayıcı benchmark metodolojisi
- GPU: NVIDIA H100 PCIe 80GB via Runpod
- Vektör veritabanı: Qdrant 1.12.0 (yerel ikili), kosinüs mesafesi
- Arama motoru: multilingual-e5-base (768-dim). Sorgu öneki:
"query: ", belge öneki:"passage: " - Yazılım: transformers 5.2.0, PyTorch 2.8.0, CUDA 12.8.1
- Veri seti: Amazon Reviews Multi'nin (Kaggle) İngilizce alt kümesi.1 Minimum 100 karakter için filtreleme sonrası ~145k inceleme. Her incelemenin bir product_id, inceleme metni ve yıldız puanı vardır.
- Sorgu oluşturma: Claude Sonnet 4.6 via OpenRouter. 300 İngilizce sorgu (5 tür: gerçekçi, görüş, kullanım, problem çözme, özellik karşılaştırması). Her sorgu, kaynak incelemesinden belirli detaylara atıfta bulunmalıdır; genel sorular (özgünlük skoru < 4/5) filtrelenir.
- Belge formatı:
"Review Title: {title}\nReview: {body}" - Pipeline: multilingual-e5-base ile en iyi 100 adayı getir, çapraz kodlayıcı ile yeniden sırala, en iyi 10'u döndür. Baz çizgisi yeniden sıralamayı atlar ve arama motorunun en iyi 10'unu doğrudan döndürür.
- Gerçek değer: yalnızca product_id tam eşleşme. Kosinüs benzerliği yedeği yok. Yarı anlamsal olarak benzer ürünler için kısmi puan yok.
- Kontrollü değişken: Deneyler arasında yalnızca yeniden sıralayıcı modeli değişir. Arama motoru, aday sayısı, sorgu seti ve değerlendirme kriterleri tüm çalışmalarda özdeştir.
- İnce ayar yok: Tüm modeller varsayılan HuggingFace ağırlıklarıyla sıfır atış (zero-shot) olarak değerlendirildi.
- Gecikme: Yeniden sıralama (100 adayın çapraz kodlayıcı puanlaması). GPU üzerinde sorgu başına ölçüldü.
Test edilen modeller
Sınırlamalar
Bu benchmark tek bir arama motoru (multilingual-e5-base) kullanır. Farklı bir arama motoru farklı aday setleri üretir ve yeniden sıralayıcı sıralamalarını değiştirebilir. Sonuçlar, her yeniden sıralayıcının bu belirli arama motoruyla ne kadar iyi çalıştığını yansıtır, yalnızca yeniden sıralayıcı kalitesini değil.
Amazon'dan İngilizce ürün incelemeleri üzerinde test ettik. Diğer alanlardaki (bilimsel makaleler, yasal belgeler, kod) veya diğer dillerdeki performans farklı olacaktır.
Aday sayısı 100'de sabittir. Bazı yeniden sıralayıcılar 20 veya 200 adayla farklı sıralayabilir. 250 adayı test ettik ve ihmal edilebilir bir iyileşme bulduk; bu da 100'ün e5_base için yeterli olduğunu gösterir, ancak diğer arama motorları farklı davranabilir.
300 sorgu orta düzeyde bir örneklem boyutudur. En iyi üç model (nemotron, gte_modernbert, jina) 2 yüzde puandan daha az ayrılmıştır. Daha büyük bir sorgu seti ile bu sıralamalar değişebilir. Üst seviye ile alt seviye arasındaki fark (20+ yüzde puan) sağlamdır.
Sonuç
Yeniden sıralayıcılar çalışır. Bu benchmark'taki en iyi model Hit@1'ı %62.67'den %83.00'e (+20.33pp) yükseltir, yani daha önce yanlış belgeyi ilk döndüren her 100 sorgudan 20'si artık doğru olanı döndürür. Bu, 250ms'nin altında gecikme ekleyen bir bileşen için önemli bir kazançtır.
En yararlı bulgu, model boyutunun yeniden sıralayıcı kalitesini belirlemediğidir. 149M parametreli gte-reranker-modernbert-base, Hit@1'de 1.2B'lik nemotron-rerank-1b ile eşleşir. 4B parametreli Qwen3 modeli dördüncü sırada bitirir. Bir üretim sistemi için yeniden sıralayıcı seçiyorsanız, daha küçük modellerle başlayın. Büyük olanlara hiç ihtiyaç duymayabilirsiniz.
Gecikmeye duyarlı uygulamalar için jina-reranker-v3, 200ms altındaki en güçlü seçenektir. Gecikme kısıtlaması olmadan maksimum doğruluk için nemotron-rerank-1b ve gte-reranker-modernbert-base üst sırayı paylaşır. GPU bütçesi olan ekipler için gte-modernbert açık kazandırıcıdır: 1.2B'lik modelle aynı doğruluk, bellek ayak izinin çok daha azı.
Bir desen tüm deneylerde tutarlı oldu: arama motoru tavanı belirler. Hiçbir yeniden sıralayıcı Hit@10'u %88'in üzerine çıkarmadı, çünkü doğru belgelerin kalan %12'si en iyi 100 aday arasında hiç görünmedi. Daha iyi bir arama motoruna yatırım yapmak, muhtemelen en iyi üç yeniden sıralayıcı arasında geçiş yapmaktan daha büyük kazançlar sağlayacaktır.
Daha fazla okuma
Diğer RAG benchmarklarını keşfedin, örneğin:
- Embedding Modelleri: OpenAI vs Gemini vs Cohere
- RAG için En İyi 16 Açık Kaynak Embedding Modeli
- RAG için En İyi Vektör Veritabanı: Qdrant vs Weaviate vs Pinecone
- Agentic RAG benchmark: Çoklu veritabanı yönlendirme ve sorgu oluşturma
- Çok Modlu Embedding Modelleri: Apple vs Meta vs OpenAI
- Hibrit RAG: RAG Doğruluğunu Artırma
- RAG için En İyi 10 Çok Dilli Embedding Modeli
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Yeniden Sıralayıcı Benchmark: En İyi 8 Model Karşılaştırıldı}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/rerankers}},
note = {AIMultiple. Erişim tarihi: 26 Şubat 2026}
}9 veri noktasının sonuçları ve zaman damgaları. Bu makalede kullanılan verileri, bir CSV dosyası ve bir README içeren ZIP dosyası olarak indirin.

Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.