Reranker-Benchmark: Top 8 Modelle verglichen
Wir haben 8 Reranker-Modelle an ~145k englischen Amazon-Bewertungen getestet, um zu messen, wie stark eine Reranking-Phase die dichte Suche verbessert. Wir haben die Top-100-Kandidaten mit multilingual-e5-base abgerufen, sie mit jedem Modell neu sortiert und die Top-10-Ergebnisse an 300 Abfragen evaluiert, die sich jeweils auf konkrete Details aus ihrer Quellbewertung bezogen. Der beste Reranker hob Hit@1 von 62,67 % auf 83,00 % (+20,33 pp).
Ergebnisse des Reranker-Benchmarks
Erklärung der Metriken:
ΔHit@1 / ΔHit@10 zeigt die Verbesserung gegenüber der Baseline (kein Reranker) in Prozentpunkten (pp). Zum Beispiel bedeutet +20,33 pp, dass der Reranker Hit@1 im Vergleich zur Baseline von 62,67 % um 20,33 Prozentpunkte verbessert hat.
Hit@K misst, ob eine Bewertung mit der korrekten product_id in den Top-K-Ergebnissen erscheint. Die Ground Truth ist die product_id der Bewertung, die Abfrage generiert hat. Wenn eine andere Bewertung desselben Produkts in den Top-K landet, zählt dies als Treffer. Hit@1 ist der strengste Test: Stammt das Top-Ergebnis vom richtigen Produkt? Hit@10 ist großzügiger: Ist das richtige Produkt irgendwo in den ersten 10 Ergebnissen?
MRR@10 (Mean Reciprocal Rank) mittelt 1/Rang des ersten korrekten Ergebnisses über alle Abfragen. Wenn das erste übereinstimmende product_id auf Rang 1 liegt, beträgt der Score 1,0. Auf Rang 2 ist es 0,5. Auf Rang 10 ist es 0,1. Dies belohnt Modelle, die das korrekte Produkt so hoch wie möglich platzieren.
nDCG@10 (Normalized Discounted Cumulative Gain) bewertet die Positionen aller übereinstimmenden Bewertungen in den Top-10, nicht nur die erste. Wenn dasselbe Produkt mehrere Bewertungen im Kandidatensatz hat und mehrere in den Top-10 landen, schreibt nDCG jede basierend auf ihrer Position gut. In der Praxis haben die meisten Produkte nur 1-2 Bewertungen in den Top-100-Kandidaten, daher verlaufen nDCG und MRR eng beieinander.
Recall@10 misst den Anteil der übereinstimmenden Bewertungen (gleiche product_id) in den Top-10 aller übereinstimmenden Bewertungen im gesamten Kandidatensatz (Top-100). Wenn ein Produkt 3 Bewertungen in den Top-100 hat und der Reranker 2 davon in die Top-10 setzt, beträgt Recall@10 für diese Abfrage 2/3. Da die meisten Produkte nur wenige doppelte Bewertungen im Kandidatensatz haben, sind Recall@10 und Hit@10 in diesem Benchmark nahezu identisch.
Aufschlüsselung der Latenz
Die Reranking-Latenz misst die Zeit, die jeder Cross-Encoder benötigt, um 100 Kandidatendokumente gegen die Abfrage zu bewerten. Die Vektorsuchzeit (~20 ms) ist ausgeschlossen, da sie über alle Durchläufe konstant bleibt und unabhängig vom Reranker ist.
Erklärung der Latenzmetriken:
Rerank ist die Zeit, die der Cross-Encoder benötigt, um alle 100 Kandidatendokumente gegen die Abfrage zu bewerten. Hier unterscheiden sich die Modelle: Ein einzelner Forward-Pass ist schnell, während die autoregressive Dekodierung langsam ist.
P95 ist die 95. Perzentil-Gesamtlatenz. Einige Abfragen haben längere Bewertungstexte, was die Tokenisierung und Bewertungszeit erhöht. P95 zeigt den Worst-Case, den Sie bei 95 % der Abfragen erwarten sollten.
Wichtige Erkenntnisse
Ein 149M-Modell entspricht einem 1,2B-Modell
gte-reranker-modernbert-base hat 149M Parameter, nemotron-rerank-1b hat 1,2B. Beide erreichen 83,00 % Hit@1 auf Englisch. Die ModernBERT-Architektur ist 8x kleiner und liefert identische Top-Line-Genauigkeit.
Dies bedeutet nicht, dass die Modellgröße irrelevant ist. Nemotron liegt bei MRR@10 (0,8514 vs. 0,8483) und Hit@10 (88,33 % vs. 88,00 %) knapp vorn, was bedeutet, dass es relevante Dokumente über die gesamten Top-10 hinweg etwas besser rankt. Aber für die meisten Anwendungen, bei denen es darauf ankommt, das erste Ergebnis richtig zu bekommen, reicht das 149M-Modell aus.
Das größte Modell ist nicht das beste
qwen3_reranker_4b hat 4B Parameter und benötigt über eine Sekunde pro Abfrage. Es erreicht 77,67 % Hit@1 und liegt hinter nemotron (1,2B), gte_modernbert (149M) und jina (560M) auf Platz vier. Sie zahlen 4,5x die Latenz von nemotron für 5,3 Prozentpunkte weniger Genauigkeit.
Die Architektur von qwen3 verwendet causales Sprachmodellieren mit einem Ja/Nein-Logit-Ansatz. Das Modell liest das Abfrage-Dokument-Paar und gibt die Wahrscheinlichkeit von „Ja, dies ist relevant“ aus. Dies ist konzeptionell sauber, aber die Inferenz ist aufgrund des Overheads der autoregressiven Dekodierung teuer. Die SequenceClassification-Modelle (gte_modernbert, bge) und nemotrons Prompt-Template-Ansatz verarbeiten das Paar in einem einzigen Forward-Pass, was grundlegend schneller ist.
Jina bietet den besten Speed-Accuracy-Tradeoff
jina_reranker_v3 erreicht 81,33 % Hit@1 bei 188 ms. Nemotron erreicht 83,00 % bei 243 ms. Wenn Sie eine Gesamtlatenz von unter 200 ms pro Abfrage benötigen, ist Jina das einzige Modell der oberen Liga, das dies liefert. Die Lücke von 1,67 Prozentpunkten mag in einem Produktionssystem, das Tausende von Anfragen pro Sekunde bedient, die zusätzlichen 55 ms nicht rechtfertigen.
Ein Reranker verschlechtert die Ergebnisse
mxbai_rerank_xsmall (70M Parameter) erzielt 64,67 % Hit@1. Die Baseline ohne Reranker erzielt 62,67 %. Die Verbesserung beträgt nur 2 Prozentpunkte, was bei 300 Abfragen innerhalb des Rauschens liegt. Bei 70M Parametern fehlt dem Modell die Kapazität, die Relevanz von Abfrage-Dokumenten bei längeren oder nuancierteren Texten zuverlässig zu beurteilen.
Ein Reranker ist nicht automatisch vorteilhaft. Testen Sie ihn vor dem Einsatz auf Ihren tatsächlichen Daten.
Der Retriever setzt die Obergrenze
Alle Top-Reranker konvergieren bei etwa 87-88 % Hit@10. Diese Obergrenze stammt vom Retriever. Wenn multilingual-e5-base das richtige Dokument nicht in die Top-100-Kandidaten platziert, kann kein Reranker es wiederherstellen. Die verbleibenden 12 % der Abfragen, bei denen jeder Reranker versagt, repräsentieren Fälle, in denen der dichte Retriever das relevante Dokument einfach vollständig verpasst hat.
Um über diese Obergrenze hinauszukommen, ist ein besserer Retriever, ein größerer Kandidatenpool oder beides erforderlich. Wir haben Top-250-Kandidaten getestet und fast keine Verbesserung gegenüber Top-100 festgestellt, was bedeutet, dass e5_base seine nützlichen Kandidaten weit vor Rang 250 erschöpft.
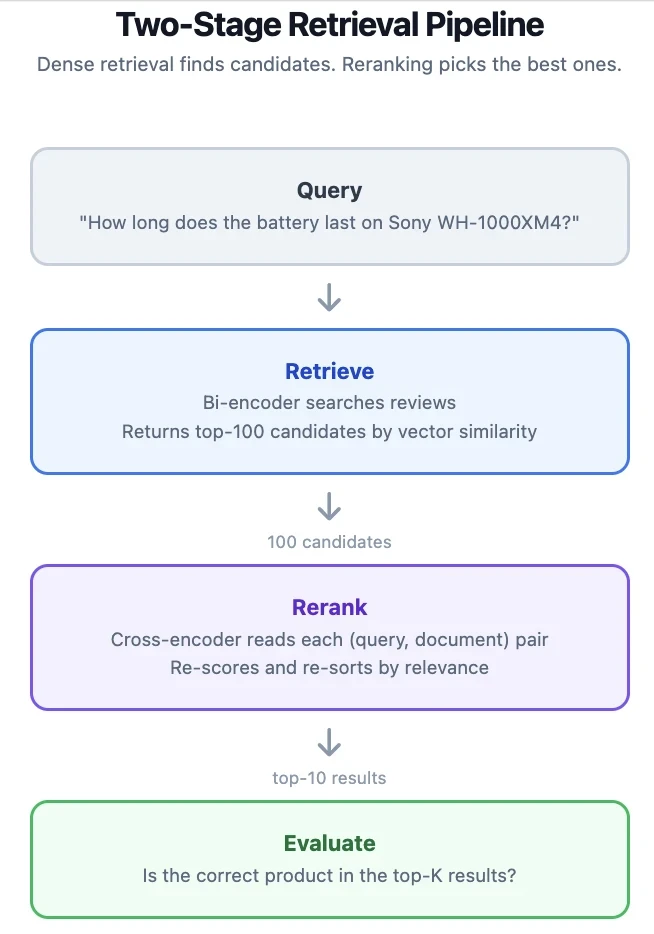
Wie Reranker funktionieren
Ein dichter Retriever (Bi-Encoder) kodiert Abfragen und Dokumente unabhängig voneinander in Vektoren. Die Suche ist eine Nachbarsuchsuche über diese Vektoren. Dies ist schnell, da Sie die Abfrage nur zur Suchzeit kodieren, aber das Modell sieht Abfrage und Dokument nie zusammen, sodass es nuancierte Relevanzsignale verpassen kann.
Ein Reranker (Cross-Encoder) nimmt ein Abfrage-Dokument-Paar als einzelne Eingabe. Das Modell achtet auf beide Texte gemeinsam und erkennt Beziehungen, die eine unabhängige Kodierung verpasst. Der Preis ist, dass Sie das Modell einmal pro Kandidat ausführen müssen, sodass Sie sich nur eine kleine Pool bewerten können.
Architekturen in diesem Benchmark
Wir haben vier verschiedene Cross-Encoder-Architekturen getestet:
SequenceClassification-Modelle (bge_base, bge_v2_m3, mxbai_xsmall, gte_modernbert) nehmen ein [query, document] Paar als Eingabe und geben einen einzelnen Logit-Score aus. Dies ist der einfachste und häufigste Ansatz.
Nemotron verwendet ein Prompt-Template-Format: „question:{q} passage:{p}“. Die Eingabe sieht aus wie reiner Text statt eines strukturierten Paares, aber das Modell gibt immer noch einen einzelnen Relevanzscore über SequenceClassification aus. Das LLM-Pretraining (basierend auf Llama) verleiht ihm ein starkes Sprachverständnis.
Qwen3-Reranker verwenden causales Sprachmodellieren. Das Modell liest das Paar und generiert eine Ja/Nein-Entscheidung. Der Score ist log P(Ja) / (P(Ja) + P(Nein)). Dies erfordert die gesamte autoregressive Maschinerie, was die höhere Latenz erklärt.
Jina v3 verwendet eine benutzerdefinierte API (model.rerank()), die Tokenisierung und Bewertung intern handhabt. Die zugrunde liegende Architektur verwendet Cross-Attention, aber die Schnittstelle abstrahiert die Details.
Methodik des Reranker-Benchmarks
- GPU: NVIDIA H100 PCIe 80GB über Runpod
- Vektordatenbank: Qdrant 1.12.0 (lokale Binärdatei), Cosine-Distanz
- Retriever: multilingual-e5-base (768-dim). Abfrage-Präfix:
"query: ", Dokumenten-Präfix:"passage: " - Software: transformers 5.2.0, PyTorch 2.8.0, CUDA 12.8.1
- Datensatz: Englischer Teil von Amazon Reviews Multi (Kaggle).1 ~145k Bewertungen nach Filterung auf mindestens 100 Zeichen. Jede Bewertung hat eine product_id, Bewertungstext und Sternebewertung.
- Abfragegenerierung: Claude Sonnet 4.6 über OpenRouter. 300 englische Abfragen (5 Typen: faktisch, Meinung, Nutzung, Problemlösung, Feature-Vergleich). Jede Abfrage muss sich auf spezifische Details aus ihrer Quellbewertung beziehen; generische Fragen (Spezifitätsscore < 4/5) werden herausgefiltert.
- Dokumentenformat:
"Review Title: {title}\nReview: {body}" - Pipeline: Top-100-Kandidaten mit multilingual-e5-base abrufen, mit Cross-Encoder neu sortieren, Top-10 zurückgeben. Die Baseline überspringt das Reranking und gibt die Top-10 des Retrievers direkt zurück.
- Ground Truth: Nur exakte Übereinstimmung der product_id. Kein Cosine-Ähnlichkeits-Fallback. Keine Teilgutschrift für semantisch ähnliche Produkte.
- Gesteuerte Variable: Nur das Reranker-Modell ändert sich zwischen den Experimenten. Retriever, Kandidatenanzahl, Abfragesatz und Bewertungskriterien sind über alle Durchläufe identisch.
- Kein Fine-Tuning: Alle Modelle wurden zero-shot mit Standard-HuggingFace-Gewichten evaluiert.
- Latenz: Reranking (Cross-Encoder-Bewertung von 100 Kandidaten). Gemessen pro Abfrage auf GPU.
Getestete Modelle
Einschränkungen
Dieser Benchmark verwendet einen einzigen Retriever (multilingual-e5-base). Ein anderer Retriever würde andere Kandidatensätze produzieren und die Reranker-Rankings ändern können. Die Ergebnisse spiegeln wider, wie gut jeder Reranker mit diesem spezifischen Retriever funktioniert, nicht die Reranker-Qualität isoliert.
Wir haben an englischen Produktbewertungen von Amazon getestet. Die Leistung in anderen Bereichen (wissenschaftliche Artikel, juristische Dokumente, Code) oder anderen Sprachen wird abweichen.
Die Anzahl der Kandidaten ist auf 100 festgelegt. Einige Reranker könnten bei 20 oder 200 Kandidaten anders ranken. Wir haben 250 Kandidaten getestet und eine vernachlässigbare Verbesserung festgestellt, was darauf hindeutet, dass 100 für e5_base ausreicht, aber andere Retriever sich anders verhalten können.
300 Abfragen sind eine moderate Stichprobengröße. Die Top-3-Modelle (nemotron, gte_modernbert, jina) unterscheiden sich um weniger als 2 Prozentpunkte. Bei einem größeren Abfragesatz könnten sich diese Rankings verschieben. Die Lücke zwischen der oberen und der unteren Liga (20+ Prozentpunkte) ist robust.
Fazit
Reranker funktionieren. Das beste Modell in diesem Benchmark hebt Hit@1 von 62,67 % auf 83,00 % (+20,33 pp), was bedeutet, dass 20 von jeweils 100 Abfragen, die zuvor das falsche Dokument zuerst zurückgegeben haben, nun das richtige zurückgeben. Das ist ein signifikanter Gewinn für eine Komponente, die weniger als 250 ms Latenz hinzufügt.
Die nützlichste Erkenntnis ist, dass die Modellgröße die Reranker-Qualität nicht bestimmt. gte-reranker-modernbert-base mit 149M Parametern entspricht nemotron-rerank-1b mit 1,2B bei Hit@1. Das 4B-Parameter-Qwen3-Modell landet auf Platz vier. Wenn Sie einen Reranker für ein Produktionssystem auswählen, beginnen Sie mit den kleineren Modellen. Sie werden die größeren möglicherweise nie benötigen.
Für latenzsensitive Anwendungen ist jina-reranker-v3 die stärkste Option unter 200 ms. Für maximale Genauigkeit ohne Latenzbeschränkung teilen sich nemotron-rerank-1b und gte-reranker-modernbert-base den ersten Platz. Für Teams mit GPU-Budget ist gte-modernbert der klare Gewinner: gleiche Genauigkeit wie das 1,2B-Modell bei einem Bruchteil des Speicherverbrauchs.
Ein Muster hielt sich über alle Experimente hinweg: Der Retriever setzt die Obergrenze. Kein Reranker hat Hit@10 über 88 % gedrückt, da die verbleibenden 12 % der korrekten Dokumente nie in den Top-100-Kandidaten erschienen. Die Investition in einen besseren Retriever wird wahrscheinlich größere Gewinne bringen als der Wechsel zwischen den Top-3-Rerankern.
Weiterführende Literatur
Entdecken Sie andere RAG-Benchmarks, wie zum Beispiel:
- Embedding-Modelle: OpenAI vs Gemini vs Cohere
- Top 16 Open-Source-Embedding-Modelle für RAG
- Top-Vektordatenbank für RAG: Qdrant vs Weaviate vs Pinecone
- Agentic-RAG-Benchmark: Multi-Datenbank-Routing und Abfragegenerierung
- Multimodale Embedding-Modelle: Apple vs Meta vs OpenAI
- Hybrid-RAG: Steigerung der RAG-Genauigkeit
- Top 10 mehrsprachige Embedding-Modelle für RAG
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Reranker-Benchmark: Top 8 Modelle verglichen}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/rerankers}},
note = {AIMultiple. Abgerufen am 26. Februar 2026}
}Ergebnisse und Zeitstempel von 9 Datenpunkten. Laden Sie die in diesem Artikel verwendeten Daten als ZIP-Datei herunter, die eine CSV-Datei und eine README enthält.

Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.