Top-Bilderkennungstools im Vergleich
Wir haben die Standard-API-Konfigurationen von Amazon Rekognition, Google Cloud Vision und Microsoft Azure KI Vision anhand von 100 Bildern über 5 Objektklassen hinweg einem Benchmark unterzogen und ihre Preisgestaltung sowie ihren Funktionsumfang verglichen.
Benchmark-Ergebnisse der Bilderkennungstools
Leistungsübersicht bei IoU=0.5
Die Leistungskennzahlen für drei Bilderkennungsplattformen wurden bei einem Intersection-over-Union-Schwellenwert (IoU) von 0.5 bewertet, wobei mAP, F1-Score, Recall und Precision verglichen wurden.
Der mAP ist die primäre Bewertungsmetrik, die bei Objekterkennungsaufgaben berücksichtigt werden sollte, da er ein umfassendes Maß für die Erkennungsqualität über verschiedene Konfidenzschwellen und Objektklassen hinweg liefert.
Sie können mehr über unsere Benchmark-Methodik erfahren.
Durchschnittliche Precision pro Klasse (AP) bei IoU=0.5
Alle drei Dienste erkennen Personen zuverlässig, verlieren jedoch an Precision bei Schutzausrüstung, wobei Helme den stärksten Abfall zeigen.
Während Amazon und Google eine niedrige Precision bei der Handschuh- und Huterkennung zeigen, erreicht Microsoft Azure KI Vision 0% Precision für beide Kategorien. Azure KI Vision erkennt keine Objekte, die klein sind (weniger als 5% des Bildes) oder eng beieinander angeordnet sind, was zu der beobachteten niedrigen Precision bei der Erkennung von Handschuhen und Hüten beitragen könnte.1
Keiner der Dienste kann Masken erfolgreich erkennen (0% Precision), was eine kritische Lücke in ihren Objekterkennungsfähigkeiten aufzeigt, wenn sie mit Standardeinstellungen ohne benutzerdefinierte Kennzeichnung verwendet werden.
Sie können mehr über die Grenzen der Bilderkennung erfahren.
mAP bei verschiedenen IoU-Schwellenwerten [0.5:0.05:0.95]
Wenn die IoU-Schwellenwerte von 0.5 auf 0.95 strenger werden, sinkt der mAP bei allen drei Diensten, jedoch unterschiedlich stark. Amazon Rekognition hält sich über den gesamten Bereich am besten, was auf eine präzisere Bounding-Box-Ausrichtung als bei den anderen beiden Diensten hindeutet.
Mögliche Faktoren, die Leistungsunterschiede beeinflussen würden
Fokus des Modelltrainings und Produktumfang
- Amazon Rekognition umfasst dedizierte PSA-bezogene Funktionen, die wahrscheinlich zu einer besseren Trainingsabdeckung und Merkmalsrepräsentationen für Objekte wie Helme und Handschuhe führen.
- Google Cloud Vision und Azure KI Vision priorisieren allgemeine Bildverständnisaufgaben (z. B. OCR, Sehenswürdigkeiten, Marken, Web-Erkennung), wodurch PSA und ähnliche Objekte in ihren Trainingszielen sekundär sind.
Standardmäßige API-Konfiguration und Precision-Recall-Kompromisse
- Alle Dienste wurden mit Standardeinstellungen bewertet, die typischerweise eine hohe Precision priorisieren, um False Positives zu minimieren.
- Diese Designentscheidung führt zu starken Precision-Werten bei allen Anbietern, jedoch zu einem deutlich niedrigeren Recall, insbesondere bei weniger prominenten Objekten.
Einschränkungen bei der Erkennung kleiner Objekte
- Objekte wie Handschuhe, Hüte und Helme nehmen oft einen kleinen Bruchteil des Bildes ein, was ihre zuverlässige Erkennung erschwert.
- Azure KI Vision, das dokumentiert bei kleinen oder eng beieinander liegenden Objekten unterdurchschnittlich abschneidet, zeigt die stärkste Verschlechterung in diesen Kategorien.
Label-Taxonomie und Bewertungszuordnung
- Anbieterspezifische Labels mussten auf eine einheitliche Ground-Truth-Taxonomie abgebildet werden.
- Gültige Erkennungen mit nicht übereinstimmenden oder granulareren Labels wurden möglicherweise von der Bewertung ausgeschlossen.
Fehlen von Maskenerkennung
- Keiner der bewerteten Dienste stellt maskenbezogene Objekt-Labels in seinen Standard-APIs zur Verfügung.
- Alle drei lieferten daher 0% Precision für Masken.
IoU-Empfindlichkeit und Lokalisierungsqualität
- Die Leistungsunterschiede nehmen bei höheren IoU-Schwellenwerten zu, bei denen eine strengere Bounding-Box-Ausrichtung erforderlich ist.
- Amazon Rekognition behält bei diesen Schwellenwerten einen relativ höheren mAP bei, was auf eine stärkere Lokalisierungsgenauigkeit hindeutet.
Benchmark-Methodik der Bilderkennungstools
Wir haben die standardmäßige (d. h. ohne benutzerdefinierte Kennzeichnung) Leistung dieser Anbieter in realen Fällen getestet.
Wir verwendeten 100 Bilder. Wir skalierten die Bilder auf 512×512 Pixel, wobei die wesentlichen Bereiche mit Instanzen erhalten blieben, da der ursprüngliche Datensatz unterschiedliche Abmessungen umfasste.
Wir möchten diesen Test erneut durchführen, ohne dass die Anbieter ihre Lösungen auf den Datensatz trainieren. Daher geben wir den Datensatz, den wir für diesen Benchmark verwendet haben, nicht preis.
Wir haben die Antworten der APIs der Dienstanbieter wie folgt verarbeitet:
- Abbildung der Labels der Dienstanbieter auf die in der obigen Tabelle definierten Ground-Truth-Kategorien. Labels der Dienstanbieter, die nicht mit diesen Ground-Truth-Labels übereinstimmten, wurden von der Bewertung ausgeschlossen.
- Normalisierung der Bounding-Box-Formate verschiedener Anbieter
- Berechnung des IoU zwischen vorhergesagten und Ground-Truth-Boxen
- Zuordnung der Vorhersagen zur Ground Truth basierend auf dem IoU-Schwellenwert
- Berechnung der Metriken: Precision, Recall, F1 und AP pro Kategorie
- Berechnung des COCO-artigen mAP unter Verwendung der Schwellenwerte 0.5-0.95
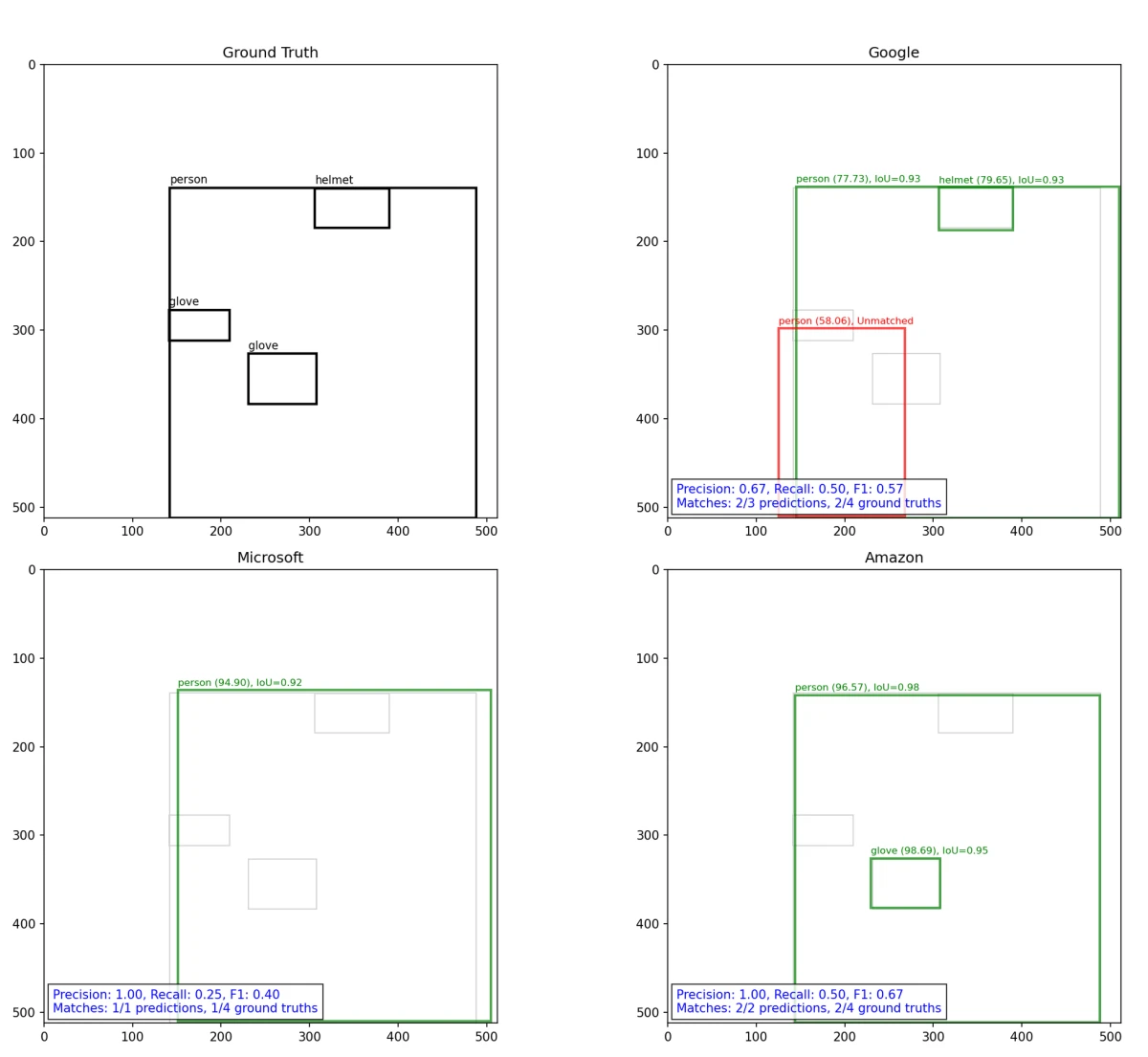
Eine Beispielberechnung von IoU, Precision, Recall und F1 ist in der folgenden Abbildung dargestellt:
Benchmarking-Metriken
Precision
Precision misst die Genauigkeit der vom Modell getroffenen positiven Vorhersagen. In der Bilderkennung beantwortet sie für eine bestimmte Klasse (z. B. „Person“) die Frage: „Von allen Bildern, die das Modell als eine Person enthaltend gekennzeichnet hat, wie viele tun dies tatsächlich?“. Dies ist in Szenarien entscheidend, in denen False Positives (fälschliche Kennzeichnung eines Bildes als positiv) kostspielig sind.
Recall
Recall misst die Vollständigkeit positiver Vorhersagen und beantwortet: „Von allen Bildern, die Klasse tatsächlich enthalten, wie viele hat das Modell korrekt identifiziert?“. Dies ist entscheidend, wenn das Übersehen einer positiven Instanz (False Negative) kritisch ist.
F1-Score
Der F1-Score ist das harmonische Mittel aus Precision und Recall und liefert ein ausgewogenes Maß, das besonders nützlich ist, wenn eine ungleiche Klassenverteilung vorliegt (z. B. wenige Helm-Bilder im Vergleich zu Nicht-Helm-Bildern). Es handelt sich um eine einzelne Metrik, die sowohl False Positives als auch False Negatives erfasst.
mAP
mAP, oder mean Average Precision, ist eine Metrik, die hauptsächlich bei Objekterkennungsaufgaben innerhalb der Bilderkennung verwendet wird. Sie bewertet die Genauigkeit des Modells über verschiedene Klassen hinweg, indem sie die Average Precision (AP) jeder Klasse mittelt. AP selbst ist die Fläche unter der Precision-Recall-Kurve, die durch Variieren des Konfidenzschwellenwerts für Erkennungen erzeugt wird.
Dieses interaktive Tool ermöglicht es Ihnen, Erkennungsergebnisse verschiedener Anbieter anhand von Beispielbildern aus dem Datensatz zu vergleichen. Verwenden Sie die oberen Schaltflächen, um Amazon, Google, Microsoft oder alle Anbieter auszuwählen. Schalten Sie die Ground Truth mit dem Kontrollkästchen um. Navigieren Sie mit den nummerierten Schaltflächen auf der linken Seite zwischen den Testbildern. Farbcodierte Boxen zeigen jede Erkennung mit Konfidenzwerten.
Beste Bilderkennungs-APIs
Amazon Rekognition
Amazon Rekognition umfasst dedizierte PSA-Erkennungs-APIs neben allgemeiner Objekt- und Gesichtserkennung, was ihm eine breitere Label-Abdeckung bei Klassen wie Helmen und Handschuhen verleiht als die beiden anderen Dienste. Dieser Produktumfang stimmt mit den AP-Ergebnissen pro Klasse im Benchmark überein.
Die Bild-APIs sind in zwei Gruppen unterteilt:
- Gruppe 1 (Gesichtsidentifikation): CompareFaces, IndexFaces, SearchFaces, verwendet zur Identitätsüberprüfung und Gesichtssuche in Bildsammlungen.
- Gruppe 2 (Inhaltsanalyse): DetectLabels (allgemeine Objekterkennung), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
Es integriert sich mit dem Rest von AWS (S3 für Speicherung, Lambda für ereignisgesteuerte Verarbeitung, SageMaker für benutzerdefiniertes Modelltraining).
Google Cloud Vision
Google Cloud Vision übertraf 89% Precision bei IoU=0.5, die gleiche Precision-Untergrenze wie die beiden anderen Dienste, erzielte jedoch einen niedrigeren Recall bei kleinen Objekten und Schutzausrüstung. Sein Produktumfang tendiert eher zu allgemeinem Bildverständnis als zu industrieller Erkennung: OCR, Sehenswürdigkeitenerkennung, Logo- und Markenidentifikation sowie Web-Erkennung (Abgleich eines Bildes mit öffentlich indizierten Bildern).
Kernfähigkeiten:
- Objektlokalisierung und Label-Erkennung
- OCR für gedruckten und handschriftlichen Text in mehreren Sprachen
- Sehenswürdigkeiten-, Logo- und Prominentenerkennung
- Web-Erkennung für die umgekehrte Bildersuche
- Benutzerdefiniertes Modelltraining über Vertex KI
Es integriert sich mit Cloud Storage, BigQuery und Google Workspace und akzeptiert eine breitere Palette an Dateiformaten als Rekognition (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure KI Vision
Microsoft Azure KI Vision bietet Bildanalyse, OCR, Bildbeschriftung und einen separaten Dienst zur Hintergrundentfernung. Die Dokumentation weist darauf hin, dass der Objektdetektor kleine oder eng beieinander liegende Objekte nicht zuverlässig verarbeitet, sodass er sich eher auf allgemeines Bildverständnis und Textlesen als auf feinkörnige Objekterkennung positioniert.
Die Kernfähigkeiten sind in zwei Gruppen unterteilt:
- Gruppe 1 (Erkennung visueller Elemente): Tagging, Gesichtserkennung, Objekterkennung, Marken- und Sehenswürdigkeitenerkennung, intelligentes Zuschneiden, OCR.
- Gruppe 2 (sprachbewusste Ausgabe): Bildbeschreibung, dichte Bildunterschriften, vollständiges Lesen (Dokumenten-OCR).
Unterscheidungsmerkmale der Dienstanbieter
API-Preisübersicht
Erstellung benutzerdefinierter Vision-Modelle
Gehostete APIs wie Amazon Rekognition, Google Cloud Vision und Microsoft Azure KI Vision liefern Vorhersagen aus einem festen, vom Anbieter definierten Labelsatz. Wenn eine erforderliche Objektklasse in diesem Satz fehlt oder wenn die Genauigkeit in einer bestimmten Domäne zu gering ist, besteht die Alternative darin, ein benutzerdefiniertes Modell zu trainieren. Roboflow ist ein Beispiel, das diesen Workflow abdeckt.
Roboflow
Roboflow ist eine Computer-Vision-Plattform, die Datenannotation, Modelltraining und Deployment abdeckt. Es funktioniert nach einem anderen Modell als die oben genannten gehosteten Erkennungs-APIs: Benutzer trainieren Modelle auf ihren eigenen gekennzeichneten Datensätzen und führen die Inferenz auf ihrer eigenen Hardware aus, anstatt einen verwalteten Endpunkt aufzurufen. Dies ist der Weg, den Teams einschlagen, wenn Standard-Cloud-APIs keine Labels für eine bestimmte Objektklasse bereitstellen, wie z. B. die Masken, die bei allen drei getesteten Diensten eine Precision von 0% erzielten.
Roboflow umfasst drei Hauptkomponenten:
- RF-DETR: ein Echtzeit-Transformer-basiertes Modell zur Objekterkennung und Segmentierung, das für Live-Kamera- und Videoeingaben vorgesehen ist.2
- AutoDistill: ein Tool, das große Basismodelle verwendet, um Bilddatensätze automatisch ohne manuelle Annotation zu kennzeichnen.3
- Inference: ein Deployment-Paket, das mehrere Backends (ONNX, TensorRT, PyTorch) unterstützt, mit Ausführung auf GPUs, CPUs oder Edge-Geräten wie NVIDIA Jetson über einen Docker-basierten Dienst.4
Edge Computing in der Bilderkennung
Cloud-basierte Bilderkennung sendet jedes Bild zur Analyse an ein entferntes Rechenzentrum. Edge-Computing führt das Modell auf dem Gerät aus, das Bild aufgenommen hat, sodass das Ergebnis (ein Label, eine Warnung, eine Markierung) das Gerät verlässt.
Wie Edge Computing funktioniert
In einem Cloud-Setup fungieren Kameras als Datensammler und streamen Rohbilder nach oben; das Modell befindet sich im Rechenzentrum. In einem Edge-Setup führt das Gerät das neuronale Netzwerk lokal aus und überträgt die relevante Ausgabe: „Person erkannt“, „Bestand niedrig“, „Defekt gefunden“.
Warum dies für die Bilderkennung wichtig ist
- Latenz: lokale Inferenz eliminiert die Cloud-Rundreise, was für autonome Fahrzeuge, Fertigungsroboter und jedes System, das innerhalb von Millisekunden auf die Vorhersage reagieren muss, von Bedeutung ist.
- Datenschutz: Bilder verlassen das Gerät nicht, was nützlich ist, wenn Datenresidenz- oder DSGVO-Anforderungen gelten (medizinische Bildgebung, Videoüberwachung im Einzelhandel).
- Bandbreite und Kosten: die Metadaten werden hochgeladen, nicht das vollständige Video, was die Netzwerk- und Cloud-API-Kosten für großvolumige Bereitstellungen reduziert.
- Offline-Betrieb: Edge-Geräte funktionieren weiter, wenn das Netzwerk ausfällt, was für Sicherheitssysteme und abgelegene Industriestandorte erforderlich ist.
Praxisbeispiele für Edge-KI in der Bilderkennung
Captur On-Device-SDK
Die geräteinterne Verarbeitung ist die häufigste Form von Edge-KI in mobilen Kontexten. Captur bietet ein geräteinternes Bildverifizierungs-SDK, das Computer-Vision-Modelle lokal auf mobilen Geräten in ~30ms ausführt, selbst offline.5 Der Logistikanbieter GoBolt integrierte das SDK von Captur in seine Fahrer-App zur Zustellnachweisverifizierung und meldete einen Rückgang der „Lieferung nicht erhalten“-Meldungen um 30% in der ersten Woche.6
Ultralytics YOLO26
Ultralytics' YOLO26 ist ein quelloffenes Computer-Vision-Modell, das für Edge- und stromsparende Geräte entwickelt wurde. Seine vollständig End-to-End-, NMS-freie Architektur entfernt Nachbearbeitungsschritte wie Non-Maximum Suppression, reduziert die Latenz und verbessert die Exportierbarkeit auf Edge-Hardware, während es Objekterkennung, Segmentierung, Klassifizierung und Posenschätzung innerhalb einer einzigen Modellfamilie unterstützt.7
Vision Transformers in der Bilderkennung
Die hier getesteten Bilderkennungs-APIs verwenden CNN-basierte Detektoren. Vision Transformers (ViTs) sind eine alternative Architektur, die das Bild in Patches fester Größe (typischerweise 16×16 Pixel) aufteilt und alle Patches parallel verarbeitet, wodurch das Modell entfernte Bildbereiche bereits ab der ersten Schicht in Beziehung setzen kann, anstatt diesen Kontext schrittweise durch gestapelte Faltungen aufzubauen.
Für die Objekterkennung ist dies von Bedeutung, wenn die Identität eines Objekts von der umgebenden Szene abhängt (ein Hut auf einer Person im Vergleich zu einem Hut auf einem Regal). CNNs erfassen dies durch gestapelte Faltungen; ViTs erfassen es durch Aufmerksamkeit über alle Patches auf einmal.
Die drei Cloud-Dienste in diesem Benchmark betreiben alle CNN-basierte Modelle in der Produktion. Hybride CNN-Transformer-Architekturen tauchen in neueren quelloffenen Modellen auf (zum Beispiel verwendet Roboflows RF-DETR ein DINOv2-Transformer-Backbone), aber die Produktions-Cloud-APIs sind noch nicht migriert.
Vision-Transformer-Modelle für die Bilderkennung
- Google ViT: der ursprüngliche Vision Transformer, trainiert auf ImageNet für die Bildklassifizierung. Verfügbar auf Hugging Face mit vortrainierten Gewichten.
- Swin Transformer: verwendet einen Shifted-Window-Mechanismus, um sowohl globale als auch lokale Details zu erfassen, verwendet für Erkennung und Segmentierung.
- DINOv2 (Meta): selbstüberwachtes Modell, das ohne manuelle Labels trainiert wurde und allgemeine Bild-Embeddings erzeugt.
- Segment Anything Model (SAM): ViT-basierter Segmentierer, der Objekte isolieren kann, auf die er nicht trainiert wurde.
Anwendungsfälle von Bilderkennungssoftware
In der heutigen digitalen Landschaft haben Computer Vision und Bildverarbeitungstechnologien die Art und Weise verändert, wie Unternehmen visuelle Daten nutzen. Fortschrittliche Bildklassifizierungsalgorithmen ermöglichen hochentwickelte Bilderkennungstools, die Abläufe in allen Branchen neu gestalten.
Diese Bilderkennungstechnologien kombinieren leistungsstarke Modelltrainingsansätze mit intuitiven Schnittstellen, die es Benutzern ermöglichen, komplexe visuelle Aufgaben zu automatisieren. Von benutzerdefinierten Vision-Lösungen für spezifische Geschäftsanforderungen bis hin zu Gesichtserkennungssystemen für die Sicherheit können diese Tools Muster, Objekte und Merkmale in Bildern identifizieren.
Visuelle Inspektion
Bilderkennung ermöglicht die automatisierte visuelle Inspektion in mehreren Branchen. Diese Systeme identifizieren Objekte, erkennen Merkmale und überprüfen die Kompatibilität durch die Analyse visueller Daten.
Zum Beispiel implementierte die Chamberlain Group Amazon Rekognition in ihrer myQ-App, sodass Benutzer automatisch Bilder ihres Garagentoröffners erfassen können, um die Kompatibilität zu überprüfen. Diese optimierte Lösung ersetzte einen komplexen manuellen Prozess und erhöhte die Benutzerverbindungsraten erheblich.8
Dokumentenverarbeitung
OCR-Technologie extrahiert Text aus Bildern und Dokumenten und automatisiert die Dateneingabe in mehreren Sprachen. Moderne Systeme können handschriftlichen Text und komplexe Layouts verarbeiten, papierbasierte Arbeitsabläufe transformieren und Dokumente durchsuchbar machen.
Zum Beispiel verwendet die französische Versicherungsgruppe LSA Courtage die Google Cloud Vision API, um Text von Führerscheinen und Zulassungspapieren zu erkennen. Diese OCR-Implementierung reduzierte die Dokumentenverarbeitungszeit um 45% pro Seite und steigerte die Produktivität der Underwriter um 20%, wodurch sie täglich 1.500 Dokumente verarbeiten können.9
Sie können unseren OCR-Benchmark überprüfen, um die Genauigkeit der verschiedenen OCR-Tools für verschiedene Dokumenttypen zu sehen.
Landwirtschaftsüberwachung
Landwirte nutzen Drohnenbilder mit Bilderkennung, um die Pflanzengesundheit zu überwachen, Krankheiten zu erkennen und die Bewässerung zu optimieren. Durch die Identifizierung von Bereichen mit Pflanzenstress, bevor sichtbare Symptome auftreten, können Landwirte frühzeitig eingreifen und den Ressourcenverbrauch reduzieren.
Zum Beispiel verwendet Microsofts Project FarmBeats (jetzt Azure Data Manager for Agriculture) Sensoren, Drohnen und maschinelles Lernen, um datengesteuerte Landwirtschaft in Umgebungen mit begrenzter Strom- und Internetverbindung zu ermöglichen. Das System hilft, die landwirtschaftliche Produktivität zu steigern und Kosten zu senken, indem es visuelle Daten mit dem Wissen der Landwirte über ihr Land kombiniert.10
Sicherheit und Überwachung
Sicherheitssysteme nutzen Gesichtserkennung und Objekterkennung, um Aktivitäten zu identifizieren, den Zugang zu kontrollieren und Personen zu lokalisieren. Diese Systeme überwachen Videostreams und alarmieren das Personal bei Bedrohungen. Zum Beispiel verwendet Sun Finance Amazon Rekognition, um die Kundenidentität durch den Vergleich von Selfies mit Ausweisdokumenten zu überprüfen, was die Verifizierung beschleunigt und Betrug verhindert, während die finanzielle Inklusion erweitert wird.11
Inhaltsmoderation
Social-Media-Plattformen nutzen Bilderkennung, um unangemessene Inhalte wie Nacktheit, Gewalt oder grafische Darstellungen aus Benutzer-Uploads zu filtern. Die Bildunterschriftengenerierung kann eine zweite Ebene hinzufügen, indem sie den Bildkontext beschreibt, den pixelbasierte Klassifizierer übersehen, zum Beispiel die Erkennung von Hasssymbolen im Hintergrund eines ansonsten harmlosen Fotos. Laut AWS reduziert die maschinelle Filterung typischerweise das Volumen, das menschliche Moderatoren überprüfen müssen, auf 1–5% der Gesamtmenge.12
Zum Beispiel verwendet die CoStar Group Amazon Rekognition für die Inhaltsmoderation und Videoanalyse von etwa 150.000 täglichen Bild- und Video-Uploads auf ihrer gewerblichen Immobilienplattform. Diese Inhaltsmoderationslösung scannt Bilder, klassifiziert Inhalte, erkennt unerwünschtes Material und nutzt Bildunterschriftentechnologie, um den Kontext zu verstehen, was Zeit spart und gleichzeitig Compliance und hochwertige Daten gewährleistet.13
Sie können mehr über die Anwendungen der Bilderkennung erfahren.
Grenzen der Bilderkennungstechnologie
Detailverlust bei kleinen Objekten
Wenn Objekte in Bildern klein erscheinen, enthalten sie weniger Pixel, was zu begrenzten visuellen Daten führt. Darüber hinaus neigen CNNs dazu, wichtige feine Details während der Verarbeitung durch Downsampling-Schichten zu verlieren, was die Erkennungsfähigkeiten erheblich beeinträchtigt.
Verpasste Erkennungen
Bilderkennungssysteme bevorzugen typischerweise größere Objekte sowohl während der Trainings- als auch der Analysephase, was zu einer höheren Häufigkeit von übersehenen kleinen Objekten oder False Negatives führt.
Hintergrundinterferenz
Kleinere Objekte sind anfälliger dafür, durch visuelles Rauschen, Hintergrundunordnung oder überlappende Elemente verdeckt zu werden, was ihre genaue Identifizierung erschwert. Selbst eine teilweise Verdeckung kann kleine Objekte unverhältnismäßig stark beeinträchtigen, da sie von vornherein eine geringere unterscheidbare Fläche aufweisen.
Skalenvariabilität
Objekte, die in unterschiedlichen Entfernungen oder Größenordnungen erscheinen, stellen Modelle vor Schwierigkeiten, die nicht speziell für die Erkennung feiner Details über verschiedene Objektgrößen hinweg entwickelt wurden.
Rechenanforderungen
Techniken zur Verbesserung der Erkennung kleiner Objekte, wie mehrskalige Merkmalsextraktion oder Eingaben mit höherer Auflösung, erfordern mehr Rechenleistung, was die Echtzeitanwendbarkeit einschränkt.
Trainings-Bias
Datensätze repräsentieren kleine Objekte oft unzureichend oder enthalten nicht genügend Annotationen für sie, was die Generalisierungsfähigkeit des Modells auf solche Fälle in realen Szenarien verringert.
FAQs
Bilderkennungssoftware ist eine Art von Computer-Vision-Technologie, die maschinelle Lernalgorithmen verwendet, um unstrukturierte Daten wie digitale Bilder und Videodaten zu analysieren. Sie geht über die Identifizierung spezifischer Objekte hinaus; fortschrittliche Systeme zielen auf Szenenverständnis ab, indem sie den Kontext und die Beziehungen innerhalb eines Bildes interpretieren, um eine vollständigere Analyse zu liefern. Dies ermöglicht es Computern, visuelle Informationen effektiv zu sehen und zu klassifizieren.
Keine einzelne Bilderkennungssoftware oder Computer-Vision-Software ist universell die beste. Die ideale Wahl unter den Bilderkennungstechnologien hängt von Ihren spezifischen Anforderungen ab. Berücksichtigen Sie Faktoren wie die erforderliche Genauigkeit, die Art der Aufgaben, die Sie ausführen müssen (wie Objekterkennung oder OCR, und berücksichtigen Sie sogar, ob Sie mit natürlicher Sprachverarbeitung für Aufgaben integrieren müssen, die Bildverständnis mit Textanalyse kombinieren), Benutzerfreundlichkeit, Skalierbarkeit, Budget, Anpassungsoptionen und die technische Expertise Ihres Teams. Das Ausprobieren verschiedener Optionen ist der beste Weg, um die Bilderkennungstechnologien zu finden, die von Ihnen benötigten Computer-Vision-Fähigkeiten für Ihre Anwendung am besten bereitstellen.
Obwohl sich die Bilderkennung erheblich verbessert hat, ist Genauigkeit nicht garantiert. Zu den Faktoren, die Leistung beeinflussen, gehören die Bildqualität (Beleuchtung, Auflösung), die Komplexität der Szene, Variationen im Erscheinungsbild von Objekten und die Qualität der Trainingsdaten, die für die Deep-Learning-Algorithmen verwendet werden. Ein robustes Szenenverständnis zu erreichen und bestimmte Objekte genau zu erkennen, kann in komplexen oder verrauschten visuellen Daten eine Herausforderung darstellen.
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Top-Bilderkennungstools im Vergleich}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Abgerufen am 17. Juni 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.