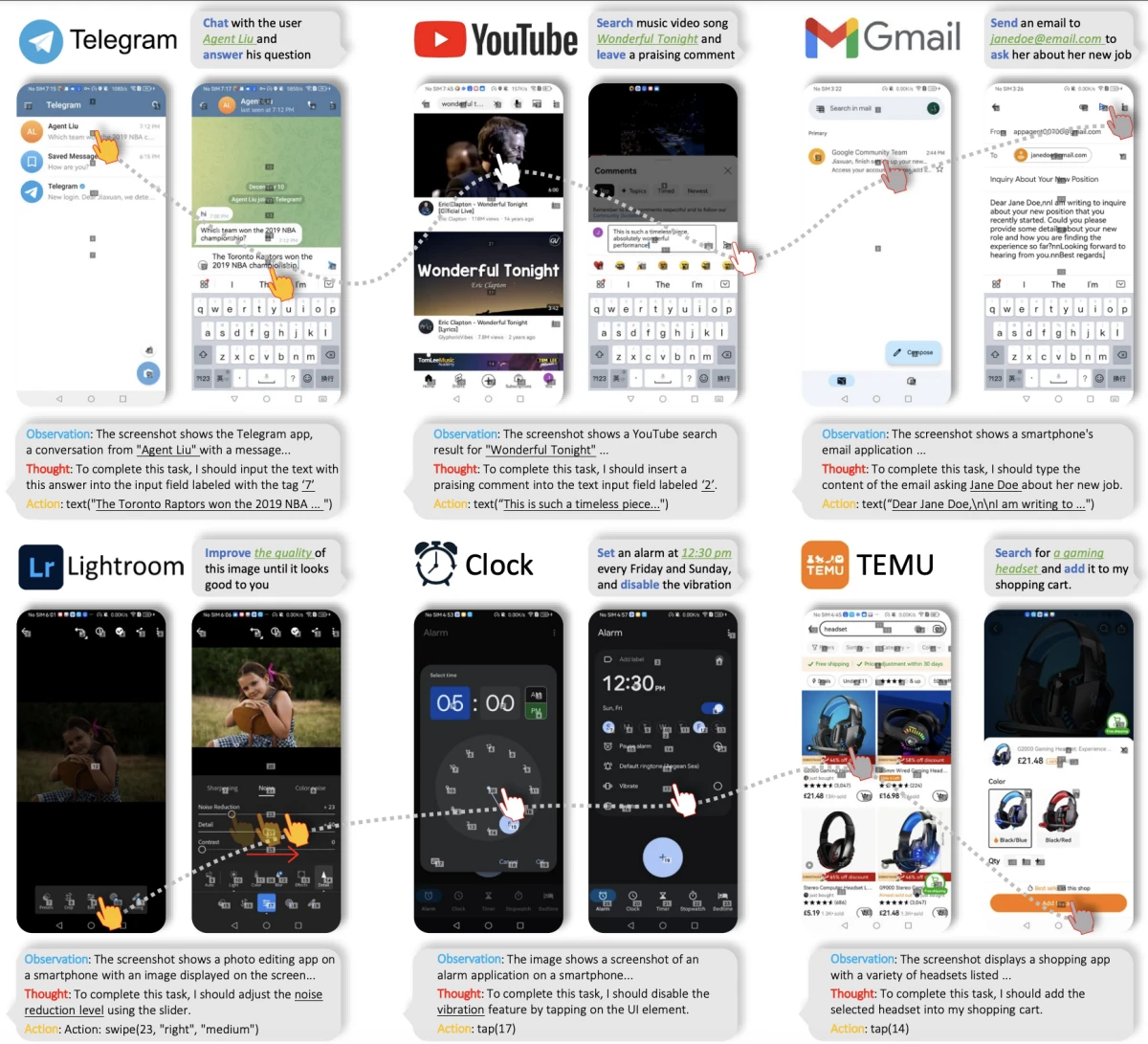
Mobile AI Agents auf 65 realen Aufgaben getestet
Wir haben 3 Tage damit verbracht, vier mobile AI Agents (DroidRun, Mobile-Agent, AutoDroid und AppAgent) auf 65 realen Aufgaben zu benchmarken, wobei wir einen Android-Emulator mit Anwendungen wie Kalenderverwaltung, Kontakterstellung, Fotoaufnahme, Audiorekordierung und Dateivorgaben verwendeten.
Sehen Sie sich die Benchmark-Ergebnisse einschließlich realer Leistungsvergleiche, Kosten und Ausführungszeiten an:
Leistungsvergleich mobiler AI Agents
DroidRun
Höchste Erfolgsquote (43 %) bei hohen Kosten pro erfolgreicher Aufgabe (0,075 $, ~3.225 Tokens)
DroidRun zeigte die beste Leistung mit einer Erfolgsquote von 43 % über die 65 Aufgaben hinweg. Bei der Betrachtung nur der Aufgaben, die alle Agents erfolgreich abschlossen, verbrauchte DroidRun durchschnittlich 3.225 Tokens zu einem Preis von 0,075 $ pro Aufgabe.
Dieser erhebliche Ressourcenverbrauch spiegelt die mehrstufige Schlussfolgerungsarchitektur von DroidRun wider, bei der der Agent ein detailliertes Zustands-Tracking durchführt, explizite Aktionspläne erstellt und Erklärungen für jede Entscheidung liefert. Obwohl teuer, liefert dieser umfassende Ansatz die höchste Erfolgsquote im Benchmark.
Mobile-Agent
Starke Leistung (29 %) und kosteneffizient (0,025 $, ~1.130 Tokens)
Mobile-Agent erreichte die zweithöchste Erfolgsquote von 29 %, während er eine angemessene Kosteneffizienz beibehielt. Bei häufig erfolgreichen Aufgaben über alle Agents hinweg durchschnittete Mobile-Agent 0,025 $ und 1.130 Tokens pro Aufgabe.
Das entspricht etwa einem Drittel der Kosten pro Aufgabe von DroidRun bei gleichzeitig etwa zwei Dritteln seiner Erfolgsquote, was Mobile-Agent zu einer attraktiven Option für Bereitstellungen macht, bei denen Budgetbeschränkungen wichtig sind.
Die 14-Prozentpunkte-Lücke in der Erfolgsquote deutet jedoch darauf hin, dass die zusätzlichen Schlussfolgerungsfähigkeiten von DroidRun einen bedeutenden Wert für missionkritische Anwendungen bieten.
AutoDroid
Beste Kosteneffizienz (14 % Erfolg, 0,017 $, ~765 Tokens), aber begrenzte Wirksamkeit
AutoDroid zeigte die niedrigsten Kosten bei häufig erfolgreichen Aufgaben mit nur 0,017 $ und 765 Tokens pro Aufgabe, was es zur wirtschaftlichsten Option im Benchmark macht.
Seine Erfolgsquote von 14 %, weniger als die Hälfte der Leistung von Mobile-Agent und etwa ein Drittel von DroidRun, zeigt jedoch, dass dieser Kostenvorteil mit erheblichen Kompromissen bei der Zuverlässigkeit einhergeht.
Trotz der Verwendung eines auf Aktionen basierenden Ansatzes ähnlich wie DroidRun führt der minimale Schlussfolgerungsaufwand von AutoDroid zu erheblichen Kosteneinsparungen, aber einer begrenzten Fähigkeit zur Aufgabenabschluss.
AppAgent
Schlechteste Leistung (7 % Erfolg) bei höchsten Kosten (0,90 $, ~2.346 Tokens)
AppAgent verzeichnete sowohl die niedrigste Erfolgsquote von 7 % als auch die höchsten Kosten bei häufig erfolgreichen Aufgaben mit 0,90 $ und 2.346 Tokens pro Aufgabe. Zwölfmal teurer als DroidRun und über fünfzigmal kostspieliger als AutoDroid.
Dieses schlechte Kosten-Leistungs-Verhältnis rührt von AppAgents visuell basiertem Ansatz her, der beschriftete Screenshots durch multimodale LLMs für jede Interaktion verarbeitet. Jeder an den multimodalen LLM gesendete Screenshot verbraucht erhebliche Eingabe-Tokens für die Bildverarbeitung, während die tatsächlichen Textantworten (Completion-Tokens) relativ bescheiden bleiben.
Dies erzeugt eine stark unausgewogene Token-Verteilung, bei der der Overhead der Bildverarbeitung die Kosten dominiert, ohne entsprechende Verbesserungen beim Aufgabenabschluss, da der Agent bei Koordinatenberechnungen und der Identifizierung von UI-Elementen auf mobilen Schnittstellen Schwierigkeiten hat.
Vergleich der Ausführungszeiten mobiler AI Agents
Bei der einzigen Aufgabe, die alle Agents erfolgreich abschlossen, war AutoDroid mit 57 Sekunden am schnellsten, gefolgt von Mobile-Agent mit 66 Sekunden. DroidRun schloss die Aufgabe in 78 Sekunden ab und zeigte, dass seine mehrstufige Schlussfolgerungsarchitektur trotz höheren Token-Verbrauchs eine effiziente Ausführung ermöglicht.
AppAgent wies mit 180 Sekunden eine signifikant höhere Latenz auf, bedingt durch seinen visuell basierten Ansatz, der eine umfangreiche Screenshot-Verarbeitung durch multimodale LLMs für jede Interaktion erfordert.
Sie können unsere Benchmark-Methodik hier einsehen.
Übersicht mobiler AI Agents
GitHub-Star-Anzahlen ändern sich schnell, und wir werden die Tabelle entsprechend aktualisieren.
DroidRun
DroidRun ist ein Open-Source-Framework, das mobile-native AI Agents erstellt, die mobile Apps und Telefone autonom steuern können. Es ist ein grundlegendes Framework, das Benutzeroberflächen in strukturierte Daten umwandelt, mit denen große Sprachmodelle interagieren können, und ermöglicht komplexe Automatisierung direkt auf mobilen Geräten.
DroidRun gewann schnell an Fahrt: Über 900 Entwickler meldeten sich innerhalb von 24 Stunden an, und das Projekt stieg auf 3,8 k Stars auf GitHub, was es zu einem der am schnellsten wachsenden Frameworks für mobile AI Agents macht.
Sehen Sie es in Aktion:
AutoDroid
AutoDroid ist ein System zur Automatisierung mobiler Aufgaben, das entwickelt wurde, um beliebige Aufgaben in jeder Android-App ohne manuelle Einrichtung auszuführen. Es nutzt das gesunden Menschenverstand basierte Schlussfolgern großer Sprachmodelle wie GPT‑4 und Vicuna, kombiniert mit automatischer app-spezifischer Analyse.
AutoDroid führt eine funktionalitätsorientierte UI-Darstellung ein, um App-Schnittstellen mit LLMs zu verbinden, verwendet explorationsbasierte Memory-Injektion, um dem Modell app-spezifisches Verhalten beizubringen, und beinhaltet Abfrageoptimierung zur Reduzierung der Inferenzkosten. Evaluiert auf einem Benchmark von 158 Aufgaben erreichte es 90,9 % Aktionsgenauigkeit und 71,3 % Aufgabenerfolg und übertraf GPT‑4-only-Baselines.1
Mobile-Agent
Das GitHub-Repo X-PLUG/MobileAgent ist die offizielle Implementierung von Mobile-Agent, einem AI-Agent-Framework, das entwickelt wurde, um mobile Anwendungen autonom zu steuern, indem es deren visuelle UI-Darstellungen wahrnimmt und darauf schließt.
Dieses Projekt stammt von der X-PLUG-Gruppe der Tsinghua-Universität und wurde auf ICLR 2024 vorgestellt, mit dem Ziel, die Grenzen mobiler Agents durch den Einsatz multimodalen Lernens, insbesondere visueller Wahrnehmung und Befehlsbefolgung, zu erweitern. Sehen Sie sich das Video an, um es in Aktion zu sehen.
AppAgent
Das GitHub-Repository TencentQQGYLab/AppAgent ist ein Open-Source-Forschungsprojekt von Tencent’s QQG Y-Lab. Es stellt AppAgent vor, ein Framework für mobile AI Agents, das entwickelt wurde, um Android-Apps autonom zu bedienen und durch sie hindurch zu schließen, ohne dass für jede einzelne App menschlich geschriebener Code erforderlich ist.
Quelle: AppAgent2
Funktionen mobiler AI Agents
Zielorientierte Befehlsverarbeitung
Der Agent bestimmt, welche Apps zu öffnen sind, welche Aktionen zu ergreifen sind und wie sie zu sequenzieren sind. Zum Beispiel geben Benutzer an, was erledigt werden soll (z. B. „Buche eine Fahrt zum Flughafen“), nicht die einzelnen Schritte.
LLM-gestützte Schlussfolgerung
Angetrieben von großen Sprachmodellen (z. B. GPT-4, Claude, Gemini), können diese Agents:
- Benutzerabsicht und Bildschirminhalt identifizieren
- Logische, schrittweise Aktionspläne erstellen
- Sich an dynamische UI-Änderungen über verschiedene App-Zustände hinweg anpassen
Strukturierte, native App-Steuerung
Anstatt sich auf Screen-Scraping zu verlassen:
- Agents extrahieren strukturierte UI-Hierarchien (z. B. XML-basierte Bäume von Buttons und Feldern)
- Sie interagieren direkt mit UI-Elementen und behandeln sie als erstklassige APIs.
- Beispiel: DroidRun verwendet Android Accessibility APIs, um echte UI-Elemente zu lesen und darauf zu agieren.
Ausführung von App-übergreifenden Workflows
Agents arbeiten über mehrere Apps und mehrstufige Workflows hinweg. Sie können neu planen, wenn ein Zwischenschritt fehlschlägt. Zum Beispiel: „Eine Datei aus der E-Mail herunterladen → in Google Drive hochladen → eine Bestätigung senden.“
Cloud- und On-Device-Ausführung für mobile AI Agents
Mobile AI Agents können in der Cloud, auf dem Gerät oder mit einem hybriden Ansatz ausgeführt werden.
Cloud-basierte Agents verbinden sich über API-Aufrufe mit Modellen wie GPT-4, Claude oder Gemini. Dies ermöglicht ausgefeilte Schlussfolgerungen und mehrstufige Aufgabenabschlüsse. Dies erfordert jedoch die Übertragung von Bildschirmdaten und Benutzerkontext an externe Server, was Datenschutzbedenken aufwirft, insbesondere für sensible Anwendungen. Die Leistung hängt auch von einer stabilen Netzwerkverbindung ab.
On-Device-Agents führen Modelle direkt auf mobiler Hardware aus und halten alle Daten lokal. Dies eliminiert Übertragungsrisiken und ermöglicht Offline-Funktionalität. Der Kompromiss ist eine begrenzte Modellkapazität: Aktuelle mobile NPUs und GPUs begrenzen die Modellgröße, was die Genauigkeit bei komplexen Schlussfolgerungsaufgaben verringern kann.
Hybride Architekturen kombinieren beide Ansätze. Leichte On-Device-Modelle bearbeiten Routineaufgaben und die initiale Intent-Klassifizierung, während komplexe Operationen an Cloud-LLMs weitergeleitet werden. Apple Intelligence und Gemini Nano folgen diesem Muster und verarbeiten einfache Anfragen lokal und eskalieren bei Bedarf. Das optimale Gleichgewicht zwischen lokaler und Cloud-Verarbeitung entwickelt sich weiter, da Edge-AI-Hardware verbessert wird.
Sicherheits- und Datenschutzrisiken bei mobilen AI Agents
Mobile AI Agents lesen Bildschirminhalt, navigieren durch Apps und führen Aktionen aus und erhalten so tiefen Zugriff auf sensible Benutzerdaten. Dies wirft mehrere Bedenken auf:
- Offenlegung von Bildschirminhalten: Agents können Passwörter, Nachrichten und Finanzdaten an Cloud-LLMs zur Verarbeitung übertragen
- Leckage von Anmeldeinformationen: Auto-Login-Workflows können gespeicherte Passwörter und Authentifizierungstokens unbeabsichtigt offenlegen
- Unklare Datenspeicherung: Oft ist unklar, wie Agent-Protokolle und erfasste Screenshots gespeichert oder geteilt werden
- Risiko der Prompt-Injektion: Bösartige App-Inhalte könnten das Agent-Verhalten durch gefälschten UI-Text manipulieren
Die Bewältigung dieser Risiken erfordert einen mehrschichtigen Ansatz:
- On-Device-Verarbeitung: Das lokale Ausführen von Modellen reduziert die Notwendigkeit, sensible Daten an externe Server zu übertragen
- PII-Maskierung: Das automatische Erkennen und Redigieren persönlicher Informationen vor API-Aufrufen begrenzt die Exposition
- Berechtigungsbeschränkungen: Die Beschränkung des Agent-Zugriffs auf sensible App-Kategorien (Banking, Gesundheit, Messaging) verhindert unbeabsichtigten Datenzugriff
- Transparente API-Richtlinien: Die Auswahl von Anbietern mit klaren Datenverwaltungs- und Aufbewahrungsrichtlinien hilft bei der Einhaltung
Benchmark-Methodik
Wir haben eine Benchmark-Evaluierung durchgeführt, um die Leistung von AI-Mobile-Agents zu bewerten, die auf dem Android-Betriebssystem bei realen Aufgaben operieren. Wir verwendeten das AndroidWorld-Framework und testeten alle Agents auf denselben Standardaufgaben.
AndroidWorld-Framework
AndroidWorld ist eine Open-Source-Benchmark-Plattform, die speziell von Google Research für die Evaluierung mobiler Agents entwickelt wurde. Diese Plattform zielt darauf ab, die Leistung von Agents zu messen, die in realen Android-Anwendungen durch standardisierte Aufgaben arbeiten.
Das wichtigste Merkmal von AndroidWorld ist, dass es echte Android-Anwendungen anstelle von künstlichen Testumgebungen verwendet und die Leistung von Agents automatisch bewerten kann. Wir haben in dieser Studie 65 Aufgaben verwendet. Diese Aufgaben decken alltägliche Szenarien der mobilen Gerätenutzung ab, wie Kalenderverwaltung, Kontakthinzufügung, Sprachaufzeichnung, Fotoaufnahme und Dateivorgaben.
Umgebungseinrichtung
Systemkonfiguration: Um die Benchmark-Umgebung einzurichten, installierten wir zunächst Android Studio auf dem Windows 11-Betriebssystem und konfigurierten Google’s offiziellen Android-Emulator.
Einrichtung des virtuellen Geräts: Wir erstellten ein virtuelles Gerät, das ein Pixel 6-Gerät simuliert. Die Spezifikationen dieses virtuellen Geräts wurden als Android 13 (API Level 33) Betriebssystem, 1080×2400 Auflösung, 8 GB RAM und 20 GB Speicherplatz festgelegt.
Emulator-Konfiguration: Um den Emulator in AndroidWorld zu integrieren, konfigurierten wir den gRPC-Port als 8554, da AndroidWorld über diesen Port mit dem Emulator kommuniziert.
Python-Umgebungseinrichtung: Um die Python-Umgebung vorzubereiten, erstellten wir eine neue Conda-Umgebung mit Python 3.11 unter Verwendung von Miniconda. Nach dem Klonen des AndroidWorld-Repositorys von GitHub installierten wir alle Abhängigkeiten mit pip. Einer der kritischsten Schritte von AndroidWorld ist der Emulator-Einrichtungsprozess.
Der Einrichtungsbefehl dauerte ungefähr 45-60 Minuten. Während dieses Prozesses installierte AndroidWorld automatisch alle zu testenden Android-Anwendungen auf dem Emulator.
Erstellung von Initialzustandsdaten: Es erstellte Initialzustandsdaten für jede Anwendung, zum Beispiel fügte es einige Ereignisse zur Kalenderanwendung hinzu, fügte Kontakte zur Kontaktanwendung hinzu und fügte einen Podcast namens „banana“ zur Podcast-Anwendung hinzu. Es speicherte auch Snapshots für jede Aufgabe, sodass jede Aufgabe von einem sauberen Initialzustand starten kann.
Agent-Integrationen
AutoDroid
AutoDroid-Integration: Um AutoDroid zu integrieren, klonten wir zunächst das Repository von GitHub und installierten die erforderlichen Python-Pakete. Das Hauptmerkmal von AutoDroid ist das Identifizieren von UI-Elementen durch Parsing von XML und das Abschließen von Aufgaben mit einem auf Aktionen basierenden Ansatz.
Der Agent weist jedem anklickbaren oder fokussierbaren Element auf dem Bildschirm eine Indexnummer zu und erhält Befehle vom LLM wie „tap(5)“ oder „text('hello')“.
AutoDroid-Wrapper: Für die Integration mit AndroidWorld erstellten wir eine Wrapper-Klasse namens autodroid_agent.py. Dieser Wrapper führt die notwendigen Konfigurationen in der Initialisierungsmethode von AutoDroid durch, wandelt das von AndroidWorld kommende Aufgabenziel in ein Prompt-Format um, das AutoDroid verarbeiten kann, und wandelt die von AutoDroid generierten Aktionen in echte ADB-Befehle unter Verwendung der execute_adb_call-Funktionen von AndroidWorld um.
Ausführungsablauf: In der step-Methode von AutoDroid macht der Agent zunächst einen Screenshot und einen XML-Dump des Bildschirms, parst UI-Elemente, sendet diese Informationen an das LLM und führt Tap-, Swipe- oder Texteingabeaktionen gemäß der erhaltenen Antwort durch.
DroidRun
DroidRun-Integration: Wir folgten einem ähnlichen Integrationsprozess für DroidRun. Nach dem Klonen des DroidRun-Repositorys von GitHub installierten wir die Abhängigkeiten in requirements.txt.
Die Architekturstruktur von DroidRun ist komplexer, da sie über ein mehrstufiges Schlussfolgerungs- und Zustands-Tracking-System verfügt. DroidRun kann nicht nur erklären, was es in jedem Schritt tun wird, sondern auch warum, und kann die Ergebnisse vorheriger Schritte im nächsten Schritt verwenden.
DroidRun-Wrapper: Wir erstellten den droidrun_agent.py-Wrapper für die AndroidWorld-Integration. Der wichtigste Teil in diesem Wrapper bestand darin, die eigene CodeActAgent-Klasse von DroidRun mit der Basisschnittstelle des Agents von AndroidWorld kompatibel zu machen.
Ausführungsprozess: Als wir die execute_task-Methode von DroidRun aufriefen, durchlief der Agent eine Aufgabenplanungsphase, führte dann jeden Schritt aus und bewertete die Ergebnisse. Wir passten diesen Prozess an das schrittweise Ausführungsmodell von AndroidWorld an. Wir implementierten auch die von DroidRun verwendeten Tools (tap_by_index, start_app, list_packages, etc.) mit den ADB-Befehlen von AndroidWorld.
AppAgent
AppAgent-Integration: Die Integration von AppAgent war anders als bei den anderen, da sie einen visuell basierten Ansatz verwendet. Nach dem Klonen des AppAgent-Repositorys integrierten wir die Python-Dateien im Skriptordner in AndroidWorld.
Visuell basierter Ansatz: Das Funktionsprinzip von AppAgent ist wie folgt: Es macht zunächst einen Screenshot des Bildschirms, berechnet dann die Begrenzungsboxen der UI-Elemente, zeichnet diese Boxen auf den Screenshot, weist jeder eine Nummer zu und sendet diesen beschrifteten Screenshot an einen multimodalen LLM. Der LLM bestimmt visuell, welches Element geklickt werden soll.
Wrapper-Konfiguration: Der wichtigste Schritt bei der Integration von AppAgent bestand darin, den Teil, der mit dem Android-Gerät unter Verwendung des and_controller.py-Moduls von AppAgent kommuniziert, auf den Emulator von AndroidWorld umzuleiten. Im appagent_agent.py-Wrapper reimplementierten wir die get_screenshot- und get_xml-Methoden von AppAgent, um mit den APIs von AndroidWorld zu arbeiten. Wir machten auch die model.py-Datei von AppAgent, die das OpenAI API-Format verwendet, kompatibel mit der OpenRouter API.
Mobile-Agent (M3A)
Mobile-Agent (M3A) Integration: Die Integration von M3A war der umfassendste Prozess, da sie vollständig visuell basiert und über ein sehr detailliertes UI-Analysesystem verfügt. Nach dem Klonen des M3A-Repositorys installierten wir auch das Mobile-Env-Android-Interaktionsframework, da M3A von diesem Framework abhängt.
Mehrstufige Analyse: Das Funktionsprinzip von M3A basiert auf der Aufteilung des Bildschirms in Gitter, der separaten Analyse jedes Gitters und der mehrstufigen Planung. Beim Erstellen des m3a_agent.py-Wrappers mussten wir das eigene Umgebungssystem von M3A mit der Umgebung von AndroidWorld integrieren. M3A verwendet normalerweise sein eigenes Mobile-Env, aber wir leiteten es auf die env von AndroidWorld um.
Mehrfache LLM-Aufrufe: Wir beobachteten, dass M3A bei jedem Schritt mehrere LLM-Aufrufe tätigt (wie Planung, Aktionsauswahl, Verifizierung) und machte sie mit den Schrittgrenzen von AndroidWorld kompatibel.
Testverfahren und Datensammlung
Testablauf: Der Testablauf für jeden Agent funktionierte wie folgt: Zuerst starteten wir den Emulator mit einem sauberen Snapshot. Nachdem der Emulator vollständig geöffnet war, führten wir run.py von AndroidWorld aus. Wir führten 65 Aufgaben sequenziell für jeden Agent aus und verwendeten Claude 4.5 Sonnet für alle Agents.
Aufgabenausführung: AndroidWorld führte automatisch die folgenden Schritte für jede Aufgabe durch: Laden des Anfangszustands der Aufgabe, Starten des Agents, Senden des Aufgabenziels an den Agent, Verfolgen der Schritte des Agents, Stoppen, wenn die maximale Anzahl von Schritten erreicht ist oder wenn der Agent „Aufgabe abgeschlossen“ sagt, und Überprüfen, ob die Aufgabe erfolgreich war.
Erfolgskriterien: Das Aufgabenauswertungssystem von AndroidWorld enthält vordefinierte Erfolgskriterien. Zum Beispiel fragt AndroidWorld für die Aufgabe „Kontakt namens John Doe hinzufügen“ die Kontakt-Datenbank ab, um zu bestätigen, dass der Kontakt hinzugefügt wurde.
Bei Kalenderaufgaben prüft es anhand der Datenbank, ob das Ereignis mit dem richtigen Datum, der richtigen Zeit, dem richtigen Titel und der richtigen Beschreibung erstellt wurde. Am Ende jeder Aufgabenausführung lieferte uns AndroidWorld Ausführungszeit und Erfolgsstatus (True/False). Diese Daten wurden automatisch aufgezeichnet und für die Analyse verwendet.
Datensammlung: Nach Abschluss des gesamten Benchmarks identifizierten wir die Aufgabe, die alle Agents erfolgreich abschlossen. Jede dieser Aufgaben wurde dann 10-mal von jedem Agent ausgeführt, und die durchschnittliche Ausführungszeit, die Kosten und der Token-Verbrauch wurden für zuverlässigere Leistungsmetriken berechnet.
Mögliche Gründe für die Leistungsunterschiede bei mobilen AI Agents
Die beobachteten Unterschiede ergeben sich hauptsächlich aus architektonischen Entscheidungen und Interaktionsmethoden.
DroidRun priorisiert Zuverlässigkeit durch mehrstufige Schlussfolgerung, explizite Planung und Zustands-Tracking. Dies verbessert den Aufgabenerfolg, erhöht jedoch den Token-Verbrauch und die Kosten.
Mobile-Agent balanciert Leistung und Effizienz. Seine leichtere Schlussfolgerung und das visuelle Verständnis reduzieren die Kosten bei gleichzeitiger Aufrechterhaltung moderater Erfolgsquoten, was es für budgetempfindliche Anwendungsfälle geeignet macht.
AutoDroid konzentriert sich auf eine auf Aktionen basierte Ausführung mit minimalem Schlussfolgerungsaufwand. Dies führt zu den niedrigsten Kosten und den schnellsten Ausführungszeiten, begrenzt aber auch seine Fähigkeit, komplexe oder mehrdeutige Aufgaben zu bewältigen.
AppAgent verlässt sich stark auf visuell basierte Interaktion unter Verwendung multimodaler LLMs. Häufige Screenshot-Verarbeitung treibt Latenz und Kosten in die Höhe, während UI-Koordinatenherausforderungen den Aufgabenerfolg verringern.
FAQs
Mobile AI Agents sind Softwaresysteme, die autonom mit Benutzern und mobilen Anwendungen interagieren, indem sie natürliche Spracheingaben und zielgerichtetes Schlussfolgern verwenden, um Aufgaben im Namen der Benutzer zu erledigen. Im Gegensatz zu traditionellen Automatisierungstools oder frühen persönlichen Assistenten werden diese Agents von KI angetrieben. Einige seiner Anwendungsfälle sind:
Mobile QA-Automatisierung ohne Testskripts
Automatisierung mobiler Workflows wie das Hochladen von ID-Dokumenten oder das Ändern von Profileinstellungen
AI-Assistenten, die Apps für Sehbehinderte, ältere Menschen oder andere bedienen.
Allgemeine tägliche Aufgaben wie das Erstellen von Ereignissen im Kalender oder sogar das Abschließen von Duolingo-Lektionen.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Mobile AI Agents auf 65 realen Aufgaben getestet}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/mobile-ai-agent}},
note = {AIMultiple. Abgerufen am 9. Juni 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.