Rechnungs OCR Benchmark: Extraktionsgenauigkeit von LLMs vs OCRs
Die Rechnungsverarbeitung ist ein kritischer, aber arbeitsintensiver Geschäftsprozess, der traditionell eine manuelle Datenextraktion und -eingabe in Buchhaltungssysteme erfordert. Dieser manuelle Ansatz ist zeitaufwendig und anfällig für menschliche Fehler. Um automatisierte Alternativen zu bewerten, haben wir eine vergleichende Analyse führender Lösungen zur Dokumentenverarbeitung und LLMs durchgeführt:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document KI
- Microsoft Azure Document Intelligence
- Rossum
Unsere Studie bewertete die Fähigkeiten dieser Tools, Daten aus verschiedenen Rechnungsformaten und -qualitäten genau zu extrahieren, mit dem Ziel, ihre Wirksamkeit als Alternativen zur manuellen Verarbeitung zu quantifizieren.
Benchmark-Ergebnisse
Wir haben die Leistung der Rechnungsverarbeitung bei Rechnungen unterschiedlicher Qualität und Kontraststufen bewertet. Während alle Tools bei hochwertigen Bildern eine starke Leistung zeigten, nahm ihre Genauigkeit bei der Verarbeitung von Dokumenten geringerer Qualität deutlich ab. Unter den getesteten Tools wies Claude Sonnet 3.5 die höchste Gesamtgenauigkeit und Robustheit über das gesamte Spektrum der Dokumentenqualität auf.
Methodik
Messung: Unsere Bewertungsmethodik konzentrierte sich auf die Genauigkeit der Extraktion von Schlüssel-Wert-Paaren. Jedes extrahierte Feld wurde mittels binärer Klassifikation bewertet: korrekte Extraktion oder inkorrekte/fehlende Extraktion. Die Genauigkeitsmetrik wurde mit der folgenden Formel berechnet:
Genauigkeit = (Anzahl der korrekt extrahierten Schlüssel-Wert-Paare) / (Gesamtzahl der Schlüssel-Wert-Paare)
Diese Methodik ermöglicht einen objektiven Vergleich der Extraktionsleistung über verschiedene Tools und Dokumenttypen hinweg.
Stichprobengröße: Das Auffinden von Rechnungsdaten ist schwierig, da sie persönliche Informationen wie E-Mails und Namen enthalten. Wir verwendeten mehr als 400 Schlüssel-Wert-Paare aus 20 öffentlich verfügbaren Rechnungsmustern.
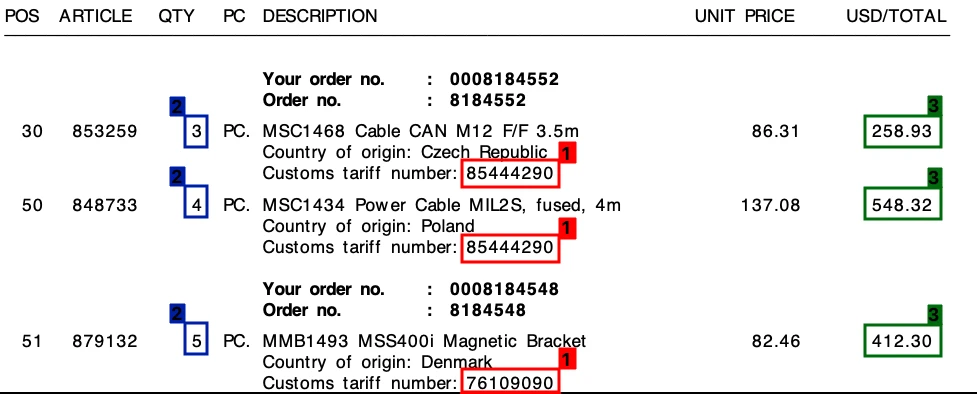
Proben: Während alle Lösungen hochwertige Bilder korrekt verarbeiteten, nahm die Extraktionsqualität bei Bildern wie diesen ab:
Fine-tuning: Obwohl die von uns getesteten Produkte bei der Ermittlung der Gesamtbeträge erfolgreich waren, hatten sie Probleme bei der Extraktion von Preisdetails. Es ist möglich, durch Fine-tuning einiger Produkte bessere Ergebnisse zu erzielen. Bei einigen Produkten können Benutzer auf einen Wert im Bild klicken, um die Modellausgabe zu korrigieren.
Um allen Anbietern gerecht zu werden, haben wir kein Fine-tuning durchgeführt. Mit Fine-tuning sollten alle Anbieter in der Lage sein, beim zweiten Mal, wenn sie diese Dokumente verarbeiten, höhere Erfolgsquoten zu erzielen. Unser Schwerpunkt in diesem Benchmark liegt jedoch auf autonomen Abläufen, die von Modellen verlangen, korrekte und zuverlässige Ergebnisse aus Dokumenten zu liefern, die sie zuvor nicht gesehen haben.
Zeitplan: Alle Tests wurden im Dezember 2024 abgeschlossen.
Nächste Schritte
Teilnehmerzahl erhöhen: Da diese Studie Einblicke in die aktuellen Fähigkeiten der Rechnungsverarbeitung über LLM (LLMs), OCR-Technologien und spezialisierte Rechnungsverarbeitungstools bietet, planen wir, unsere Analyse durch die Einbeziehung weiterer modernster LLMs zu erweitern, um einen umfassenderen Benchmark automatisierter Rechnungsverarbeitungslösungen zu liefern.
Erhöhung der Stichprobengröße und Vielfalt.
Was ist Rechnungs-OCR?
Rechnungsparsing verwendet automatisierte Tools wie NLP, NLU, OCR und andere Datenextraktionstechnologien, um Daten aus Rechnungen in verschiedenen Formaten wie PDFs und Bildern zu extrahieren.
Ein Rechnungsparser ist ein Softwareprogramm, das Informationen wie
Lieferantenname
Rechnungsnummer
Fälliger Betrag
extrahiert und in ein maschinenlesbares Format einfügt. Diese Daten können für verschiedene Funktionen genutzt werden, wie die Automatisierung der Kreditorenbuchhaltung, den Abschluss von Monatsabschlüssen und die Verwaltung von Rechnungen.
Die Parser-Software ist in der Regel in ein Rechnungsverarbeitungssystem integriert, das den gesamten Prozess vom Eingang einer Rechnung bis zur Zahlung automatisiert.
Wie funktionieren Rechnungs-OCR-Tools?
Dokumente, die in einer bestimmten Auszeichnungssprache verfasst sind, werden von Parsern gelesen und verarbeitet. Sie zerlegen das Dokument in kleinere Teile, Token genannt, und untersuchen jeden Token, um seine Bedeutung und seine Position innerhalb der Dokumentstruktur zu bestimmen.
Dazu müssen Parser viel über die Grammatik der betreffenden Auszeichnungssprache wissen. Dies ermöglicht ihnen, jeden Token zu erkennen und die genauen Beziehungen zwischen ihnen zu bestimmen.
Der Prozess umfasst 5 Schritte:
1. Eingabe
Rechnungen können in einer Vielzahl von Formaten eingehen, darunter Papier, E-Mail oder elektronische Formate wie PDF oder XML. Die Rechnungsparser-Software akzeptiert diese Rechnungen in der Regel als Eingabe.
2. Optische Zeichenerkennung (OCR)
Wenn die Rechnung in einem gescannten Papier- oder Bildformat vorliegt, verwendet der Parser OCR-Technologie, um Text aus dem Bild zu extrahieren. Dadurch kann der Parser auf die in der Rechnung enthaltenen Daten zugreifen.
Einige Rechnungsparsing-Lösungen verwenden KI-gestützte OCR-Tools oder LLMs, die automatisch Informationen aus PDFs, Fotos und gescannten Dokumenten extrahieren, ohne dass neue Regeln oder Vorlagen erforderlich sind. Dies liegt daran, dass die KI halbstrukturierte und unbekannte Dokumente verarbeiten und sich im Laufe der Zeit verbessern kann. Die extrahierten Informationen können so angepasst werden, dass nur bestimmte Tabellen oder Dateneinträge enthalten sind.
3. Datenextraktion
Der Parser extrahiert dann spezifische Informationen aus der Rechnung, wie Lieferantenname, Rechnungsnummer, Datum und Positionen. Dies geschieht in der Regel durch eine Kombination aus Mustererkennung und maschinellen Lernalgorithmen.
Einige Rechnungsparsing-Softwares sind in der Lage, Schlüsselinformationen wie Rechnungsdatum, Nummer, Steueridentifikationsnummern und verschiedene Summen mithilfe vordefinierter Filter zu extrahieren:
Einige Parser-Tools bieten die Möglichkeit, Positionen aus Rechnungen mit einem konsistenten Format zu extrahieren, indem für jedes spezifische Layout eines Lieferanten oder Handelspartners ein eigener Dokumentparser erstellt wird:
4. Datenvalidierung
Sobald die Daten extrahiert wurden, validiert der Parser die Informationen, um sicherzustellen, dass sie genau und vollständig sind. Dies kann die Überprüfung umfassen, ob das Datum im richtigen Format vorliegt, der Lieferantenname mit einer vordefinierten Liste von Lieferanten übereinstimmt oder die Positionsdetails dem erwarteten Format entsprechen.
5. Datenausgabe
Die extrahierten und validierten Daten werden dann in einem Format ausgegeben, das einfach in das Buchhaltungs- oder ERP-System des Benutzers importiert werden kann. Dies kann in Form einer CSV-Datei, eines Datenbankeintrags oder direkt in eine Buchhaltungssoftware erfolgen.
Herausforderungen bei der manuellen Rechnungsdatenextraktion
Die manuelle Extraktion von Daten aus Rechnungen und deren Eingabe in ein System kann für Unternehmen eine Herausforderung darstellen, da es mehrere Komplexitäten gibt:
Menschliche Fehler
Rechnungen können eine große Datenmenge enthalten, und die manuelle Eingabe erhöht das Risiko von Fehlern, wie Tippfehlern, Zahlenvertauschungen und falscher Dateneingabe. Ungenauigkeiten bei der Dateneingabe sind für geschätzte $600 Milliarden jährliche Verluste verantwortlich.1 Prozesse wie die Kreditorenbuchhaltung benötigen einen korrekten Datenexport aus Finanzdokumenten.
Zeitaufwendig
Im Durchschnitt dauert es 17 Tage oder etwa 75% eines Monats, um eine einzelne Rechnung manuell zu verarbeiten.2
Viele wichtige Informationen sind in Rechnungen enthalten und werden alle im Schlüssel-Wert-Stil präsentiert, wobei jedes Element sowohl als Schlüssel als auch als Wert dient. Die manuelle Extraktion dieser Paare ist zeitaufwendig und erfordert mehrfache Prüfungen, um die Genauigkeit sicherzustellen. Sogar einige OCR-Algorithmen haben Schwierigkeiten, extrahierte Werte ohne Kontext zu erkennen. Automatisierte Rechnungsverarbeitung kann Mitarbeitern helfen, sich auf komplexere Aufgaben zu konzentrieren.
Mangelnde Standardisierung
Rechnungen verschiedener Lieferanten können unterschiedliche Formate aufweisen. Jede Rechnung wird mit einem einzigartigen Format erstellt, das bei der Verarbeitung und Interpretation dieser Muster Schwierigkeiten bereiten kann. Die Dokumente, wie E-Mails, Papier und PDFs, können viele digitale und physische Aufzeichnungen durchlaufen, bevor sie zur Zahlung freigegeben werden, was die manuelle Extraktion von Daten erschwert und fehleranfällig macht.
Prozessineffizienz
Die manuelle Bearbeitung von Rechnungen, die durchschnittliche Kosten von fast $23 pro Rechnung verursacht3 , kann sowohl zeitaufwendig als auch teuer sein und zu einem ineffizienten und sich wiederholenden Prozess führen.
Potenzial für Datenverlust
Es besteht das Risiko, Daten zu verlieren, wenn Rechnungen verloren gehen oder beschädigt werden oder wenn Daten nicht korrekt in das System eingegeben werden.
OCR-Software hat oft Schwierigkeiten, Positionen aus Rechnungen zu extrahieren. Dies liegt daran, dass Transaktionstabellen möglicherweise keine horizontalen oder vertikalen Linien aufweisen, was es für ocr invoice processing schwierig macht, einen Kontext für die extrahierten Elemente herzustellen. Gesammelte digitale Rechnungen oder Rechnungsbilder können in diesem Prozess verwendet werden.
Wie wählen Sie Ihren Anbieter für die Rechnungsverarbeitung aus?
1. Liefert eine Lösung, die mit den Datenschutzrichtlinien Ihres Unternehmens übereinstimmt.
Die Datenschutzrichtlinie Ihres Unternehmens kann ein Hindernis für die Nutzung externer APIs wie Amazon AWS Textract sein. Die meisten Anbieter bieten Vor-Ort-Lösungen an, sodass Datenschutzrichtlinien Ihr Unternehmen nicht unbedingt daran hindern, eine Lösung zur Rechnungserfassung zu nutzen. Der Workflow der Kreditorenbuchhaltung muss mit besonderer Sorgfalt behandelt werden, da er häufig vertrauliche Geschäfts- und Finanzinformationen umfasst.
2. Eine konsistente Datenstruktur unabhängig vom Text auf den Dokumenten bereitstellen.
Es gibt zwei Wege, wie Deep-Learning-basierte Rechnungserfassungsunternehmen arbeiten. Unternehmen wie Textract geben Schlüssel-Wert-Paare zurück. Wenn also zum Beispiel eine Rechnung den Gesamtbetrag "Gross amount" nennt, eine andere "Total amount" und eine deutsche Rechnung "Summe", liefert Textract Ihnen die Daten in drei verschiedenen Strukturen für diese drei Dokumente.
In einem Fall haben Sie ein Schlüssel-Wert-Paar mit dem Schlüssel "Gross amount", in einem anderen "Total amount" und in der deutschen erhalten Sie "Summe". Andere Anbieter haben konsistente Datenstrukturen entworfen, die für alle Rechnungen funktionieren. In allen drei Szenarien erhalten Sie "Total amount", was der Schlüssel ist, den sie in ihrer Ausgabedatei verwenden. Dies vereinfacht Analysen und die Verarbeitung, da Sie sich nicht mit vielen unterschiedlichen strukturierten Datenformaten befassen müssen.
3. Fragen Sie nach den Raten für falsch positive und manuelle Datenextraktion
Führen Sie dann ein Proof of Concept (PoC)-Projekt durch, um die tatsächlichen Raten bei den von Ihrem Unternehmen erhaltenen Rechnungen zu sehen.
Falsch positive sind Rechnungen, die automatisch-verarbeitet werden, aber Fehler in der Datenextraktion aufweisen. Diese sind schwer zu identifizieren und können den Betrieb stören. Beispielsweise wäre eine falsche Extraktion von Zahlungsbeträgen problematisch. Dies zu minimieren sollte oberste Priorität haben.
Manuelle Datenextraktion ist erforderlich, wenn das automatisierte Datenextraktionssystem wenig Vertrauen in sein Ergebnis hat. Dies kann auf ein anderes Rechnungsformat, eine schlechte Bildqualität oder einen Druckfehler des Lieferanten zurückzuführen sein. Dies zu minimieren ist ebenfalls wichtig, aber es gibt einen Zielkonflikt zwischen falsch positiven und manueller Datenextraktion. Mehr manuelle Datenextraktion kann vorzuziehen sein, als falsch positive zu haben.
Dies ist das erste quantitative Benchmarking, das wir in diesem Bereich gesehen haben, und wir werden eine ähnliche Methodik anwenden, um unser eigenes Benchmarking vorzubereiten.
4. Nutzen Sie einen PoC, um die potenzielle Automatisierungsrate zu messen
Dies hängt von der Anzahl der Felder ab, die Sie aus den Dokumenten erfassen möchten. Ein typischer Satz von ~10 Feldern, einschließlich Bestellnummer, Lieferantenname usw., kann die Dateneingabe in ERP und Zahlungen ermöglichen.
Bewährte Anbieter erreichen ~80% STP, indem sie alle diese ~10 Felder in etwa 80% der Fälle nahezu fehlerfrei extrahieren. Auch wenn gelegentlich Fehler auftreten können, kann die manuelle Überprüfung der größten Zahlungen sicherstellen, dass keine signifikante Fehlzahlung durch das Netz schlüpft.
5. Fragen Sie nach den erweiterten Verarbeitungsoptionen, die der Anbieter anbietet
Die Extraktion ist der erste Schritt der Datenerfassung; in den meisten Fällen muss sie von einer Datenverarbeitung gefolgt werden. Beispielsweise müssen Rechnungen auf Umsatzsteuerkonformität überprüft werden (z. B. müssen inländische Rechnungen ohne Umsatzsteuer erklären, warum die Umsatzsteuer ausgeschlossen ist), und ein Versäumnis könnte je nach Land zu erheblichen Geldbußen für das Unternehmen führen.
6. Fragen Sie, wie die Lösung über neue Rechnungen lernt
Die besten Lösungen verfügen über eine Schnittstelle, die es Ihrem Team ermöglicht, die Lösung zu unterstützen. Wenn ein Mitarbeiter Ihres Unternehmens die Schlüssel-Wert-Paare auswählt, merkt sich die Rechnungserfassungslösung dies, sodass sie beim nächsten Mal bei einer ähnlichen Rechnung sicherer sein kann.
7. Bewerten Sie die Benutzerfreundlichkeit ihrer manuellen Dateneingabelösung
Sie wird von den Back-Office-Mitarbeitern Ihres Unternehmens verwendet, wenn sie Rechnungen manuell bearbeiten, die nicht mit ausreichender Sicherheit automatisch verarbeitet werden können.
Darüber hinaus sind bewährte Beschaffungsfragen sinnvoll. Zum Beispiel:
- Wie weit verbreitet ist ihre Lösung? Haben sie Fortune-500-Kunden?
- Sind ihre Kunden mit ihrer Lösung und dem Support zufrieden? Es könnte gut sein, einen Bekannten aus einem Unternehmen zu fragen, das ihre Lösung bereits nutzt. Da die Rechnungsautomatisierung keine Lösung ist, die das Marketing oder den Vertrieb eines Unternehmens verbessern würde, könnten sogar Wettbewerber ihre Ansichten zu Rechnungsautomatisierungslösungen miteinander teilen.
- Welche Optionen gibt es, um die Lösung in die Systeme Ihres Unternehmens (z. B. ERP) zu integrieren? Ist die IT-Abteilung mit dem Integrationsansatz einverstanden?
- Wie hoch sind die Gesamtkosten (Total Cost of Ownership, TCO)? Verschiedene Lösungen verwenden unterschiedliche Preiseinheiten (z. B. Preis pro Seite oder Preis pro Dokument), was diesen Vergleich erschwert. Anhand einer Stichprobe aus Ihrem Archiv könnten Sie jedoch eine Kostenschätzung erhalten.
Weiterführende Informationen
Zitieren Sie diesen Benchmark
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Rechnungs OCR Benchmark: Extraktionsgenauigkeit von LLMs vs OCRs}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Abgerufen am 22. Januar 2026}
}

Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.