Web Crawler Benchmark zum Füttern von Websites mit KI
Wir haben vier Crawl APIs in drei Bereichen mit unterschiedlicher Schwierigkeit auf drei maximalen Tiefenstufen (5, 10, 20) mit einem Limit von 1.000 Seiten getestet und dabei die Crawl-Abdeckung, Ausführungszeit, Linkentdeckung, Markdown-Linkqualität und die Genauigkeit der Titelaus extraction gemessen.
Wenn Sie Folgendes anstreben:
- Webseiten in strukturierte Daten umwandeln, lesen Sie unseren Leitfaden zu Web-Scraping.
- Ganze Websites crawlen, lesen Sie weiter.
Web Crawler Benchmark
Sie können unsere Benchmark-Methodik lesen.
Durchschnittlich gecrawlte Seiten im Vergleich zu den Kosten pro 1.000 Seiten
Gecrawlte Seiten in verschiedenen Domains nach maximaler Tiefe
Firecrawl hat auf theregister.com unabhängig von der maximalen Tiefe konsequent etwa 100 Seiten, auf entrepreneur.com über alle Tiefenstufen hinweg etwa 90 Seiten und auf amazon.com nur etwa 30 Seiten gecrawlt, wahrscheinlich aufgrund von Amazons aggressivem Bot-Schutz. Bemerkenswerterweise hatte die Erhöhung der maximalen Tiefe praktisch keine Auswirkungen auf die Anzahl der Seiten, die Firecrawl in jeder Domain crawlen konnte.
Apify zeigte die konsistenteste Leistung und erreichte auf jeder Domain und auf jeder Tiefenstufe ohne ersichtliche Schwierigkeiten das maximale Crawl-Limit von 1.000 Seiten, selbst auf stark geschützten Seiten wie Amazon.
Cloudflare zeigte in den Tests ein inkonsistentes Verhalten:
- Auf theregister.com bei maximaler Tiefe 5 wurden nur 100 Seiten gecrawlt, bei maximaler Tiefe 20 jedoch fast 1.000 Seiten.
- Wie wir in früheren Tests beobachtet haben, crawlt Cloudflare gelegentlich nur 1 Seite und beendet dann den gesamten Job. Wir haben bestätigt, dass dies kein Caching-Problem ist (Caching war deaktiviert), und haben Wartezeiten zwischen den Läufen von bis zu 1 Minute getestet, aber das Verhalten blieb bestehen. Bei maximaler Tiefe 10 auf theregister.com trat genau dieses Problem auf: Cloudflare crawlte nur 1 Seite, bevor es stoppte.
- Auf entrepreneur.com crawlte Cloudflare bei Tiefe 5 780 Seiten, erhöhte sich auf 885 bei Tiefe 10, fiel dann aber stark auf nur 172 Seiten bei Tiefe 20. Dieser Rückgang könnte damit zusammenhängen, dass der Cloudflare-Crawl-Planer tiefere Linkketten zurückstuft oder abläuft, oder es könnte ein internes Parallelitätslimit widerspiegeln, das dazu führt, dass der Job vorzeitig beendet wird, wenn die Crawl-Front bei höheren Tiefen zu groß wird.
- Auf amazon.com crawlte Cloudflare bei Tiefe 5 905 Seiten, aber die Anzahl ging mit zunehmender maximaler Tiefe stetig zurück und fiel auf 809 bei Tiefe 10 und 795 bei Tiefe 20, was darauf hindeutet, dass tiefere Crawl-Konfigurationen dazu führen können, dass Cloudflare mehr Zeit für den Overhead der Linkentdeckung statt für den tatsächlichen Abruf von Seiten verwendet.
Nimble erreichte oder näherte sich auf theregister.com über alle Tiefenstufen hinweg dem Limit von 1.000 Seiten (1.000 / 1.000 / 999). Auf entrepreneur.com crawlte es bei Tiefe 5 1.000 Seiten, zeigte aber bei höheren Tiefen leichte Rückgänge (896 bei Tiefe 10, 983 bei Tiefe 20), möglicherweise weil sein 7-Stunden-Timeout erreicht wurde, bevor der vollständige Crawl auf tieferen Ebenen abgeschlossen war; alle Nimble-Läufe endeten mit einem Timeout-Status. Amazon erwies sich als schwieriger:
- Bei Tiefe 5 schaffte es nur 319 Seiten, bei Tiefe 10 sprang es auf 988 Seiten und fiel dann bei Tiefe 20 auf 906.
- Diese Inkonsistenz spiegelt wahrscheinlich die Kombination aus Amazons Bot-Schutzmechanismen und den Timeout-Einschränkungen von Nimble wider, wobei tiefere Crawler länger dauern, um jede Seite zu verarbeiten, und unterwegs auf mehr Anti-Bot-Herausforderungen stoßen können.
Ausführungszeit in verschiedenen Domains nach maximaler Tiefe
Firecrawl war der schnellste Anbieter in allen Domains und schloss Crawler in unter 5 Minuten ab, typischerweise zwischen 75 und 265 Sekunden. Diese Geschwindigkeit geht zu Lasten der Abdeckung, da Firecrawl auch die wenigsten Seiten crawlte. Im Wesentlichen schließt es schnell ab, weil es früh stoppt.
Apify benötigte auf theregister.com unabhängig von der Tiefe etwa 2.200-2.400 Sekunden (~40 Minuten). Auf entrepreneur.com und amazon.com waren die Ausführungszeiten mit 8.300-15.900 Sekunden (2-4 Stunden) deutlich länger, was die größeren und komplexeren Seitenstrukturen widerspiegelt. Trotz der längeren Zeiten erreichte Apify konsequent das Limit von 1.000 Seiten und war damit in Bezug auf das Verhältnis von Abdeckung zu Zeit am zuverlässigsten.
Cloudflare zeigte eine Zeitmessung, die seinen inkonsistenten Crawl-Zahlen entspricht:
- Auf theregister.com bei Tiefe 10 wurde es in nur 1 Sekunde abgeschlossen, da es nur 1 Seite crawlte, bevor es stoppte.
- Auf entrepreneur.com bei Tiefe 20 wurde es nach dem Crawl von nur 172 Seiten in 10 Sekunden abgeschlossen.
- Wenn Cloudflare einen vollständigen Crawl abschließt, liegen die Zeiten zwischen 3.500 und 25.200 Sekunden.
- Wenn die maximale Tiefe zunimmt, scheint Cloudflare die Erreichung tieferer Seiten gegenüber der Breite zu priorisieren, weniger Seiten zu crawlen, aber schneller abzuschließen. Auf amazon.com sank die Ausführungszeit von 25.200 Sekunden (Timeout) bei Tiefe 5 auf nur 5.660 Sekunden bei Tiefe 20, während die gecrawlten Seiten ebenfalls von 905 auf 795 zurückgingen. Dies deutet darauf hin, dass der Cloudflare-Crawler bei höheren Tiefen seine Strategie ändert und weniger Zeit für die breite Entdeckung und mehr für die tiefe Durchquerung verwendet.
Nimble erreichte bei jedem einzelnen Lauf in allen Domains und Tiefenstufen das 7-Stunden-Timeout (25.200 Sekunden). Dies ist bemerkenswert, da Nimble in unseren früheren Schnelltests mit maximaler Tiefe 1 ohne Timeout abgeschlossen wurde. Beim vollständigen Benchmark mit Tiefen von 5-20 und einem Limit von 1.000 Seiten lief es konsequent bis zum Erreichen des Timeouts. Trotz dessen schaffte Nimble in den meisten Fällen immer noch, eine hohe Anzahl von Seiten zu crawlen (~900-1.000 auf theregister.com und entrepreneur.com), was bedeutet, dass es während der 7 Stunden aktiv crawlt, aber einfach nie die Fertigstellung signalisiert.
Link-Text-Füllrate bei Anbietern nach maximaler Tiefe
Um die Qualität der Markdown-Ausgabe zu bewerten, haben wir gemessen, wie viel Prozent der Links im Markdown jedes Anbieters Anker-Text enthalten, den anklickbaren Textteil eines Links. Fehlender Anker-Text (z. B. [](/about) statt [About Us](/about)) bedeutet, dass der Crawler die Beschriftung des Links nicht extrahieren konnte.
- Nimble: 100 % über alle Tiefen hinweg
- Cloudflare: 91-94 %
- Firecrawl: 90 %
- Apify: 77-78 %, etwa 1 von 5 Links ohne Anker-Text
Die Crawl-Tiefe hatte für keinen Anbieter einen minimalen Einfluss auf die Füllraten, was darauf hindeutet, dass dies eine Eigenschaft der Parsing-Engine jedes Anbieters ist und nicht eine Crawl-Einstellung.
Link-Text-Füllrate bei Anbietern nach Domain
Ein Blick auf die Füllraten in verschiedenen Domains zeigt, wie die Komplexität der Seite die Qualität der Linkextraktion jedes Anbieters beeinflusst.
- Nimble behielt über alle Domains hinweg 100 % bei.
- Apify zeigte die größte Variation, 89 % auf amazon.com, fiel aber auf 66 % auf entrepreneur.com, was bedeutet, dass ein Drittel seiner Links auf dieser Seite ohne Anker-Text war. Dies deutet darauf hin, dass Apify bei inhaltsreichen Seiten mit komplexen Navigationsstrukturen mehr Schwierigkeiten hat.
- Firecrawl schnitt auf theregister.com am besten ab (98 %), fiel aber auf 81 % auf entrepreneur.com und folgte einem ähnlichen Muster wie Apify.
- Cloudflare war nach Nimble am konsistentesten und blieb unabhängig von der Domain zwischen 89-94 %.
Entrepreneur.com erwies sich als die schwierigste Domain für die Extraktion von Link-Text; sowohl Apify (66 %) als auch Firecrawl (81 %) erzielten dort ihre niedrigsten Werte, wahrscheinlich aufgrund der starken Nutzung verschachtelter Navigationsmenüs und dynamischer Inhaltselemente auf der Seite, die schwer sauber in Markdown umzuwandeln sind.
Gesamtzahl der Links in der Markdown-Ausgabe in verschiedenen Domains nach maximaler Tiefe
Die Varianz der Linkanzahl bei den Anbietern war konstant hoch (74-97 %), was darauf hindeutet, dass Anbieter sehr unterschiedliche Anzahlen von Links aus denselben Seiten extrahieren. Um einen detaillierteren Einblick in diese Diskrepanz zu erhalten, haben wir die Gesamtzahl der Markdown-Links pro Anbieter gemessen.
- Apify lieferte insgesamt die meisten Links zurück, insbesondere auf amazon.com mit über 420.000 Links bei Tiefe 5 (~423 pro Seite). Auf entrepreneur.com stabilisierte es sich unabhängig von der Tiefe bei etwa 63.000. Seine Ausgabe enthält neben Links zum Seiteninhalt auch Werbetrackern und Tracking-Pixel.
- Cloudflare erreichte auf entrepreneur.com bei Tiefe 10 einen Höchststand von 303.000, fiel aber bei Tiefe 20 auf 53.000. Auf derselben Homepage von entrepreneur.com extrahierte Cloudflare 434 Links im Vergleich zu 143 von Apify und erfasste vollständige Navigationsmenüs und Untermenüs.
- Firecrawl lieferte konstant 5-9.000 Links über alle Konfigurationen hinweg zurück, begrenzt durch seine geringe Seitenanzahl.
- Nimble lieferte insgesamt 3-40.000 Links zurück, durchschnittlich 5-28 Links pro Seite im Vergleich zu 60-420 bei anderen Anbietern. Auf der Homepage von entrepreneur.com lieferte Nimble 13 Links im Vergleich zu 434 von Cloudflare, begrenzt auf die Hauptartikelüberschriften. Seine 100%ige Füllrate spiegelt wider, dass alle enthaltenen Links Anker-Text hatten, anstatt eine umfassende Linkabdeckung anzuzeigen. Nimble gibt keine Standard-Markdown-Links aus. Seine Anzahl enthält entkommene HTML-Links, die in der Markdown-Ausgabe gefunden wurden.
Titel-Präsenzrate bei Anbietern
Die Titelähnlichkeit bei den Anbietern zeigte in allen Tests und Domains eine Abweichung von weniger als 1 %, was bestätigt, dass Anbieter, wenn sie einen Titel extrahieren, konsistent dasselbe Ergebnis zurückgeben. Die Titel-Präsenzrate blieb auch über alle maximalen Tiefenstufen hinweg zwischen 98-100 %, was zeigt, dass die Crawl-Tiefe keinen wesentlichen Einfluss auf die Titelaus extraction hat.
Wenn nach Domain aufgeschlüsselt, traten einige Unterschiede auf:
Auf entrepreneur.com und theregister.com erreichten die meisten Anbieter Titel-Präsenzen von 99-100 %. Amazon.com war die einzige Domain, in der signifikante Unterschiede auftraten: Firecrawl fiel auf 93 % und Nimble auf 95,9 %, während Apify 99,6 % beibehielt. Dies stimmt mit Amazons stärkerem Bot-Schutz überein, der Seitenantworten blockieren oder verzerren kann, was dazu führt, dass einige Anbieter Seiten ohne extrahierbare Titel zurückgeben.
Was ist ein Web Crawler?
Ein Web Crawler, manchmal auch „Spider“ oder „Agent“ genannt, ist ein Bot, der das Internet durchsucht, um Inhalte zu indexieren.
Crawler haben sich über Suchmaschinen hinaus entwickelt und dienen nun als Agente Datenebene. Sie fungieren als Augen für autonome KI-Agenten wie Claude Code und OpenAI Operator und unterstützen bei Echtzeit-Aufgaben wie Wettbewerbsforschung und mehrstufigen Transaktionen.
Was macht ein Web Crawler?
Web-Crawling wurde in drei Modi unterteilt, die jeweils für ein anderes Crawler-Ziel entwickelt wurden.
- Entdeckungsmodus (traditionell): Suchmaschinen-Bots wie Googlebot crawlen URLs zur Indexierung und helfen Menschen, Ergebnisse über Suchmaschinen zu finden.
- Abrufmodus (RAG): KI-Bots wie ChatGPT-User oder PerplexityBot rufen in Echtzeit bestimmte Seiten ab, um Benutzer-Prompts zu beantworten. Sie verwenden Markdown statt HTML, um den Token-Limits des KI-Modells zu entsprechen.
- Agenter Modus (Handlungsorientiert): Diese neue Art von Crawler im Jahr 2026 tut mehr als nur Inhalte lesen. Mit dem Model Context Protocol (MCP) können diese Bots mit Websites interagieren, um Flüge zu buchen oder Softwarebefehle auszuführen.
In der Vergangenheit verwendeten Crawler Selektoren wie XPath oder CSS, um Daten zu extrahieren. KI-native Extraktion ist zur Norm geworden.
Tools wie Firecrawl und Crawl4AI verwenden natürliche Sprachanweisungen, um Daten zu finden. Anstatt Regeln für jedes Element zu schreiben, können Entwickler dem Crawler sagen, er solle „den Produktpreis extrahieren“, und die KI findet den richtigen Wert, selbst wenn sich der Code der Website ändert.
Selbstbau vs. Kauf von Web Crawlern im KI-Zeitalter
1. Eigener Crawler
Ideal zum Schutz des geistigen Eigentums und zur Ermöglichung tiefer Anpassungen. Der Bau erfordert heute die Entwicklung einer proprietären Agenten-Schicht, nicht nur das Schreiben grundlegender Scrapy-Skripte.
- Wann bauen: Wählen Sie diesen Ansatz, wenn Ihr Crawler einen einzigartigen Wettbewerbsvorteil bietet. Bauen Sie beispielsweise Ihren eigenen, wenn Sie eine spezialisierte Suchmaschine entwickeln oder die vollständige Kontrolle über sensible oder regulierte Daten benötigen.
- Das Werkzeugset: Sie müssen nicht mehr bei Null anfangen. Entwickler nutzen jetzt das Model Context Protocol (MCP), um interne KI-Agenten mit dem Web interagieren zu lassen.
2. Verwendung von Web-Crawling-Tools & APIs
Gemanagte Tools haben sich von einfachen Scrapern zu autonomen Agenten weiterentwickelt.
- Wartungsfreie Extraktion: Moderne Tools wie Kadoa und Firecrawl verwenden selbstheilende KI. Sie geben die erforderlichen Daten an, z. B. „Produktpreis“, anstatt deren Standort im Code. Wenn sich das Website-Layout ändert, passt sich das Tool automatisch an.
- Compliance als Service: Viele Anbieter bieten integrierte Compliance mit dem EU-KI-Gesetz. Sie verwalten erforderliche Audit-Logs und Copyright-Auswahlprüfungen, die unabhängig schwierig zu implementieren sind.
- Geschwindigkeit zum Wert: Der Kauf einer Plattform kann Ihr Projekt innerhalb weniger Wochen vom Konzept in die Produktion bringen.
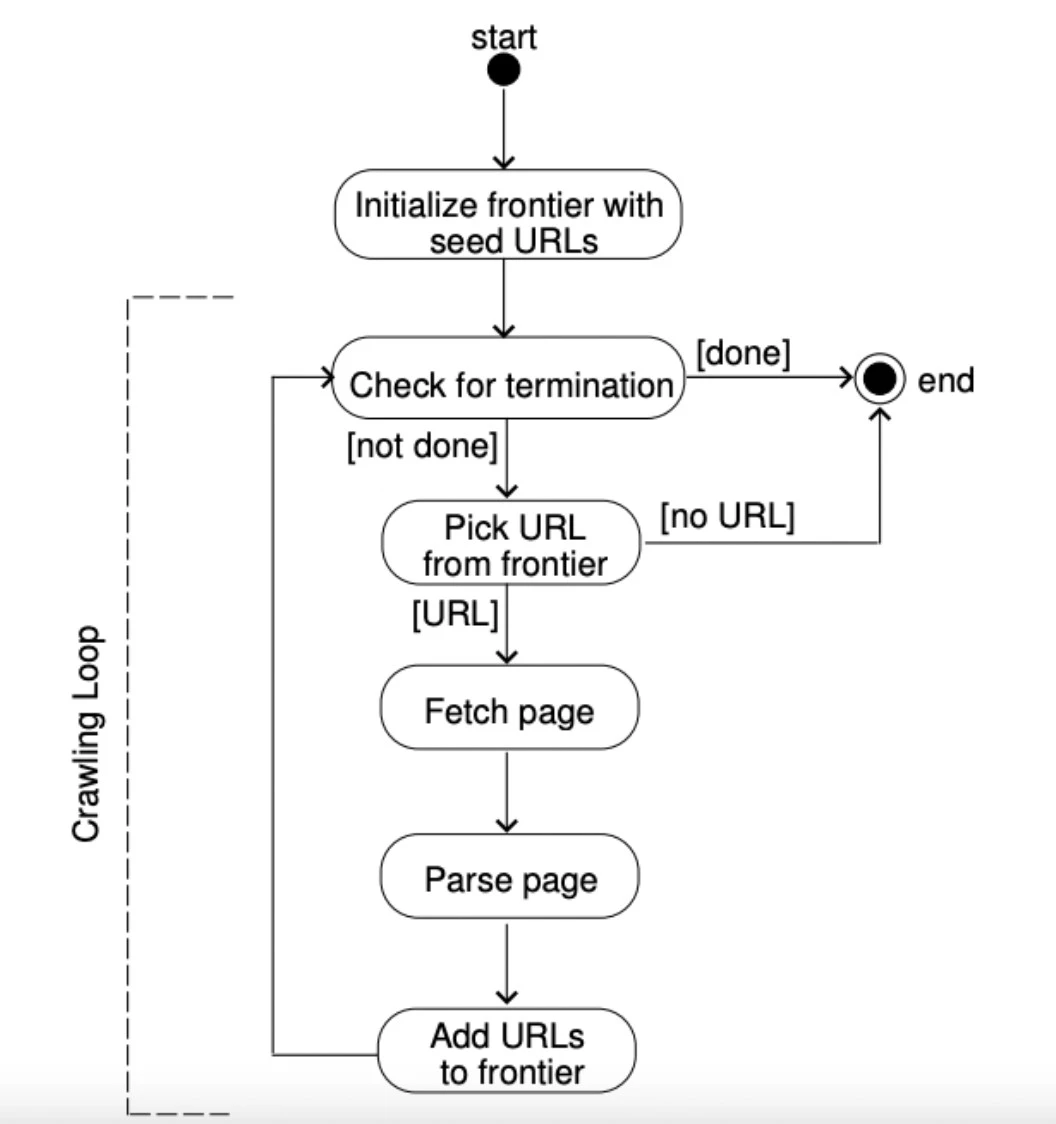
Abbildung 5: Eine Erklärung, wie eine URL-Frontier funktioniert.
Sind Web Crawler legal?
Im Allgemeinen ist Web-Crawling legal, aber je nachdem, wie und was Sie crawlen, könnten Sie sich schnell in einer rechtlichen Zwickmühle befinden. Vier Hauptsäulen bestimmen, ob Crawling (und das typischerweise folgende Scraping) legal ist:
1. Öffentlich vs. privat: Crawlen Sie nur Daten, die ohne Konto öffentlich verfügbar sind.
2. Persönliche Informationen: Halten Sie sich von PII (Namen, E-Mails und Adressen) fern, es sei denn, Sie haben eine rechtmäßige Grundlage.
3. Server-Gesundheit: Verwenden Sie Ratenlimits, um eine Verlangsamung des Servers zu vermeiden; vermeiden Sie das „DDOSen“ einer Website.
4. Urheberrecht: Artikel und Bilder sind urheberrechtlich geschützt, aber Fakten (Preise, Daten) nicht.
Was ist der Unterschied zwischen Web-Crawling und Web-Scraping?
Web-Scraping ist die Verwendung von Web Crawlern, um den gesamten Inhalt einer Zielseite zu scannen und zu speichern. Mit anderen Worten, Web-Scraping ist ein spezifischer Anwendungsfall von Web-Crawling, um einen gezielten Datensatz zu erstellen, z. B. das Abrufen aller Finanznachrichten für die Investitionsanalyse und die Suche nach spezifischen Firmennamen.
Traditionell extrahierte ein Web-Scraper Daten von der indexierten Webseite, sobald ein Web Crawler alle Elemente der Webseite gecrawlt und indexiert hatte. Heutzutage werden die Begriffe Scraping und Crawling jedoch synonym verwendet, wobei sich Crawler eher auf Suchmaschinen-Crawler bezieht. Da Unternehmen außer Suchmaschinen begannen, Webdaten zu verwenden, begann der Begriff Web-Scraper, den Begriff Web Crawler zu verdrängen.
Was sind die Herausforderungen des Web-Crawling?
1. Datenbank-Aktualität
Der Inhalt von Websites wird regelmäßig aktualisiert. Dynamische Webseiten ändern beispielsweise ihren Inhalt basierend auf den Aktivitäten und Verhaltensweisen der Besucher. Dies bedeutet, dass der Quellcode der Website nach dem Crawlen der Website nicht gleich bleibt. Um dem Benutzer die aktuellsten Informationen bereitzustellen, muss der Web Crawler diese Webseiten häufiger neu crawlen.
2. Crawler-Fallen
Websites setzen verschiedene Techniken ein, wie z. B. Crawler-Fallen, um Web Crawler daran zu hindern, auf bestimmte Webseiten zuzugreifen und diese zu crawlen. Eine Crawler-Falle oder Spider-Falle führt dazu, dass ein Web Crawler eine unendliche Anzahl von Anfragen stellt und in einem bösartigen Crawl-Kreislauf gefangen wird. Websites können auch unbeabsichtigt Crawler-Fallen erstellen. In jedem Fall gerät ein Crawler, wenn er auf eine Crawler-Falle stößt, in eine Art Endlosschleife, die Ressourcen des Crawlers verschwendet.
3. Netzwerkbandbreite
Das Herunterladen einer großen Anzahl irrelevanter Webseiten, die Verwendung eines verteilten Web Crawlers oder das Neucrawlen vieler Webseiten führen zu einem hohen Verbrauch der Netzwerkkapazität.
4. Duplizierte Seiten
Web Crawler-Bots crawlen hauptsächlich alle duplizierten Inhalte im Web; jedoch wird nur eine Version einer Seite indexiert. Duplizierter Inhalt macht es Suchmaschinen-Bots schwer zu bestimmen, welche Version von dupliziertem Inhalt indexiert und rangiert werden soll. Wenn Googlebot eine Gruppe identischer Webseiten in den Suchergebnissen entdeckt, indexiert und wählt es nur eine dieser Seiten aus, um als Antwort auf die Suchanfrage eines Benutzers anzuzeigen.
Top 3 Best Practices für Web-Crawling
1. Höflichkeit/Crawl-Rate
Websites legen eine Crawl-Rate fest, um die Anzahl der von Web Crawler-Bots gestellten Anfragen zu begrenzen. Die Crawl-Rate gibt an, wie viele Anfragen ein Web Crawler in einem bestimmten Zeitintervall (z. B. 100 Anfragen pro Stunde) an Ihre Website stellen kann. Es ermöglicht Website-Besitzern, die Bandbreite ihrer Webserver zu schützen und eine Überlastung des Servers zu reduzieren. Ein Web Crawler muss sich an das Crawl-Limit der Zielwebsite halten.
2. Robots.txt-Konformität
Eine robots.txt-Datei ist eine Textdatei, die im Stammverzeichnis einer Website platziert wird und Crawlern mitteilt, auf welche Seiten sie zugreifen dürfen oder nicht. Es ist ein freiwilliger Standard, was bedeutet, dass konforme Bots ihn respektieren, er den Zugriff jedoch technisch nicht verhindert. Die Einhaltung der robots.txt einer Website gilt als Best Practice, und in vielen Gerichtsbarkeiten kann das Ignorieren rechtliche oder reputative Risiken mit sich bringen.
3. IP-Rotation
Websites setzen verschiedene Anti-Scraping-Techniken wie CAPTCHAs ein, um Crawler-Verkehr zu verwalten und Web-Scraping-Aktivitäten zu reduzieren. Zum Beispiel ist Browser-Fingerprinting eine Tracking-Technik, die von Websites verwendet wird, um Informationen über Besucher zu sammeln, wie z. B. Sitzungsdauer oder Seitenaufrufe.
Diese Methode ermöglicht es Website-Besitzern, „nicht-menschlichen Verkehr“ zu erkennen und die IP-Adresse des Bots zu blockieren. Um eine Erkennung zu vermeiden, können Sie rotierende Proxys, wie z. B. residential Proxys, in Ihren Web Crawler integrieren.
Web Crawler Benchmark-Methodik
Wir haben vier Crawl APIs (Apify, Nimble, Cloudflare, Firecrawl) auf drei Domains mit unterschiedlicher Schwierigkeit getestet: amazon.com (starker Bot-Schutz), entrepreneur.com (komplexe Inhaltsseite) und theregister.com (Nachrichtenseite).
Gemeinsame Konfiguration
Alle Anbieter erhielten identische Kerneinstellungen, um einen fairen Vergleich zu gewährleisten:
- Sitemap: Deaktiviert, Anbieter müssen Seiten nur über HTML-Links entdecken
- Externe Links: Deaktiviert, Crawler bleiben innerhalb der Ziel-Domain
- Subdomains: Aktiviert, Subdomain-Seiten werden verfolgt (z. B. india.entrepreneur.com)
- JavaScript-Rendering: Aktiviert, alle Anbieter verwenden einen Headless-Browser
- Cache: Deaktiviert
- Seitenlimit: 1.000 Seiten pro Lauf
- Timeout: 7 Stunden (25.200 Sekunden)
- Umgang mit Ratenlimit: 20-Sekunden-Wartezeit mit bis zu 3 Wiederholungen bei HTTP 429
Jeder Anbieter wurde auf drei maximalen Tiefenstufen (5, 10, 20) über alle drei Domains hinweg getestet, insgesamt 36 Crawl-Läufe. Die Anbieter wurden sequentiell (nicht parallel) getestet, jede Kombination wurde einmal ausgeführt, und der Crawl-Status wurde jede Sekunde abgefragt.
Apify wurde mit dem website-content-crawler-Aktor konfiguriert, der Playwright/Firefox als Headless-Browser verwendet. Der Zugriff auf Subdomains wurde über Glob-Muster gesteuert, und der integrierte Proxy von Apify wurde für alle Anfragen verwendet.
Nimble, Cloudflare und Firecrawl wurden mit ihren jeweiligen REST APIs mit den oben beschriebenen gemeinsamen Einstellungen konfiguriert. Es wurden keine zusätzlichen anbieterspezifischen Konfigurationen über die standardisierten Parameter hinaus angewendet.
Für Cloudflare verwendeten wir den Workers Paid-Plan. Die gemeldeten Kosten spiegeln wider, was wir für das Crawlen von 1.000 Seiten unter diesem Plan ausgegeben haben. Cloudflare berechnet basierend auf der Browser-Rendering-Zeit und nicht nach Seitenanzahl.
Für Firecrawl verwendeten wir den Hobby-Plan. Die gemeldeten Kosten sind der anteilige Betrag für 1.000 Credits aus den in diesem Plan bereitgestellten Credits. Die effektiven Kosten pro Seite variieren je nach Planstufe und ob zusätzliche Credit-Pakete gekauft werden.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Web Crawler Benchmark zum Füttern von Websites mit KI}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Abgerufen am 2. Juli 2026}
}Cems Arbeit wurde von führenden globalen Publikationen zitiert, darunter Business Insider, Forbes, Washington Post, globalen Unternehmen wie Deloitte, HPE und NGOs wie dem World Economic Forum sowie supranationalen Organisationen wie der European Commission.
Während seiner Karriere war Cem als Tech-Berater, Tech-Einkäufer und Tech-Unternehmer tätig. Er beriet Unternehmen über ein Jahrzehnt lang bei McKinsey & Company und Altman Solon in Technologieentscheidungen. Er veröffentlichte auch einen McKinsey-Bericht zur Digitalisierung.
Er leitete die Technologiestrategie und Beschaffung eines Telekommunikationsunternehmens und berichtete dabei direkt an den CEO. Zudem führte er das kommerzielle Wachstum des Deep-Tech-Unternehmens Hypatos an, das innerhalb von 2 Jahren von null auf einen siebenstelligen jährlich wiederkehrenden Umsatz und eine neunstellige Bewertung anwuchs. Cems Arbeit bei Hypatos wurde von führenden Technologiepublikationen wie TechCrunch und Business Insider aufgegriffen.
Cem spricht regelmäßig auf internationalen Technologiekonferenzen. Er schloss sein Studium an der Bogazici University als Computer-Ingenieur ab und hat einen MBA von der Columbia Business School.

Kommentare 1
Teilen Sie Ihre Gedanken
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.