Creación de agentes de IA con patrones componibles
Pasamos 3 días experimentando con flujos de trabajo y pipelines de agentes en n8n, siguiendo las guías de Anthropic y OpenAI sobre la creación de agentes de IA efectivos.1 2
Explora los componentes principales de los agentes de IA, cómo elegir los componentes y herramientas adecuados, además de crear flujos de trabajo de agentes basados en los patrones simples y componibles de Anthropic, como el encadenamiento de prompts, enrutamiento, paralelización, trabajador-orquestador y un evaluador-optimizador:
Comprendiendo los componentes de los agentes de IA
La creación de agentes implica conectar componentes de varios ámbitos, como modelos, herramientas, conocimiento y memoria, y barreras de seguridad. OpenAI proporciona primitivas componibles para cada uno de ellos:
Fuente: OpenAI3
Obviamente, OpenAI enumera primero sus propias cosas, pero hay un amplio ecosistema de alternativas. Dependiendo de tu caso de uso, puedes crear agentes utilizando frameworks como LangChain, LlamaIndex, CrewAI, o incluso capas de orquestación personalizadas.
Voy a explicar cada uno de estos componentes con más detalle:
Modelos
En primer lugar, está el componente de modelos. Estos son tus modelos de IA, tus grandes modelos de lenguaje que constituyen la inteligencia central capaz de razonar, tomar decisiones y procesar diferentes modalidades. Los propios ejemplos de OpenAI hacen referencia a sus modelos de la serie GPT-5.
Dependiendo del tipo específico de agente que estés creando, querrás elegir un tipo de modelo diferente dentro del ecosistema de OpenAI. GPT-5.5 es el modelo insignia actual de OpenAI. Planifica tareas de varios pasos, utiliza herramientas, revisa su propio trabajo y sigue hasta que la tarea está completada. Para preguntas cotidianas, los modos más ligeros de GPT-5.5 responden más rápido y cuestan menos.
Fuera del ecosistema de OpenAI, Claude Opus 4.7 es una opción común para trabajos pesados de codificación, razonamiento y disciplinas STEM. Gemini 3.1 Pro de Google compite de cerca, con una ventana de contexto de 1 millón de tokens para bases de código grandes y documentos extensos.
Para agentes de codificación específicamente, GPT-5.3-Codex de OpenAI es su modelo de codificación más capaz. Ejecuta tareas largas que combinan investigación, uso de herramientas y ejecución, y puedes dirigirlo mientras trabaja. Lidera benchmarks como SWE-Bench Pro y Terminal-Bench 2.0, que evalúan el trabajo real de ingeniería de software y línea de comandos.
Hemos comparado y evaluado los mejores modelos de IA para ayudarte a entender cómo rinde cada uno en términos de razonamiento, velocidad y coste, para que puedas elegir el que mejor se adapte a tus objetivos.
Herramientas
A continuación están las herramientas, que amplían las capacidades del modelo, como permitirle buscar en la web o interactuar con otros sistemas.
Casi cualquier aplicación puede convertirse en una herramienta para tu IA. Puedes conectarla a Gmail, Calendario, tu unidad de almacenamiento, o aplicaciones como Slack, Discord, YouTube, Salesforce y Zapier. Incluso puedes crear tus propias herramientas personalizadas.
Con el SDK de Agentes de OpenAI (que requiere algo de programación), puedes definir herramientas o usar las integradas como búsqueda web, búsqueda de archivos y uso del ordenador.4
El MCP (Protocolo de Contexto de Modelo) de Anthropic también simplifica la integración de herramientas al estandarizar cómo los modelos acceden a ellas. En 2026, el valor empresarial proviene cada vez más de “líneas de ensamblaje digitales”, flujos de trabajo de varios pasos guiados por humanos, donde múltiples agentes ejecutan procesos de extremo a extremo, habilitados por el Protocolo de Contexto de Modelo (MCP).
Si no te gusta programar, las plataformas sin código como n8n te permiten arrastrar y soltar herramientas para vincularlas con tu modelo.
Conocimiento y memoria
Hay dos tipos principales de memoria: la base de conocimiento (memoria estática) y la memoria persistente.
- La base de conocimiento le da a tu IA acceso a hechos estáticos, políticas y documentos que permanecen relativamente sin cambios. Esto es esencial para agentes que realizan tareas basadas en políticas o específicas de la empresa, donde los materiales de referencia deben ser coherentes.
- La memoria persistente permite que la IA recuerde interacciones pasadas a lo largo de las sesiones. Esto es crucial para chatbots o asistentes personales que necesitan recordar conversaciones anteriores.
OpenAI ofrece servicios alojados como almacenes de vectores, búsqueda de archivos e embeddings para gestionar la memoria.
Si prefieres soluciones de código abierto, Pinecone (nativo de la nube y optimizado para búsqueda vectorial) y Weaviate son opciones populares.
Para quienes usan herramientas sin código, la gestión de memoria suele estar integrada en plataformas como n8n y Creatio.
Barreras de seguridad
Las barreras de seguridad aseguran que tu agente se comporte como se espera, evitando respuestas irrelevantes, dañinas o inapropiadas. Por ejemplo, un bot de servicio al cliente debe centrarse en temas relacionados con el servicio, sin desviarse a otros.
Fuera del ecosistema de OpenAI, las herramientas populares incluyen Guardrails IA y LangChain Guardrails. Muchas plataformas sin código tienen características de barreras integradas, pero sigue siendo importante entender cómo funcionan para mantener el control y el cumplimiento en tus agentes.
Habilidades
Las herramientas permiten que un agente actúe en el mundo exterior. Las habilidades enseñan al agente cómo realizar un trabajo específico correctamente.
Una Habilidad es una pequeña carpeta de instrucciones y archivos. Contiene los pasos, reglas y ejemplos para una tarea, como rellenar una plantilla de informe o seguir la guía de estilo de una empresa. El agente carga una Habilidad cuando la tarea lo requiere, para no saturar la ventana de contexto.
Anthropic introdujo las Habilidades de Agente a finales de 2025 y abrió el formato como un estándar compartido en marzo de 2026.5 Las Habilidades funcionan en Claude.ai, Claude Code y la API. El principal beneficio es la consistencia: en lugar de reescribir el mismo prompt largo cada vez, un equipo define una Habilidad una vez y la reutiliza. Esto es importante en producción, donde los prompts improvisados tienden a variar.
En qué se diferencian las Habilidades de los otros componentes:
- Herramientas conectan al agente con sistemas externos (correo electrónico, bases de datos, búsqueda).
- Conocimiento y memoria proporcionan al agente hechos para leer.
- Habilidades proporcionan al agente un método repetible para una tarea.
Orquestación
El último componente es la orquestación. Esto implica gestionar cómo trabajan juntos varios subagentes, desplegarlos en producción y supervisar su rendimiento.
Una vez desplegados, los agentes necesitan supervisión continua. Los modelos, los datos y los comportamientos cambian, por lo que los agentes necesitan actualizaciones periódicas.
Varias plataformas y frameworks admiten la orquestación, como:
- Plataformas de bajo código/sin código:
- Stack AI
- Microsoft Copilot Studio Agent Builder
- Relevance IA, etc
- Frameworks de código abierto:
- LangGraph (parte de LangChain): modela un agente como un grafo de pasos, con control explícito sobre ramificaciones, reintentos e intervenciones humanas.
- CrewAI: organiza a los agentes como un “equipo” de roles, como investigador, redactor y revisor. Es rápido para prototipar cuando el trabajo se divide en roles claros.
- LlamaIndex: más potente para agentes que buscan en documentos y bases de conocimiento internas.
- SDKs de proveedores: el SDK de Agentes de OpenAI y el SDK de Agente Claude de Anthropic son kits de herramientas oficiales para crear agentes en los modelos de cada proveedor. El SDK de Agente Claude es la misma arquitectura que impulsa Claude Code.
Bloques de construcción de la automatización: Flujos de trabajo vs agentes
Un agente de IA es un sistema que percibe su entorno, procesa información y realiza acciones de forma autónoma para alcanzar objetivos específicos, como los agentes de codificación como Cursor o Windsurf, editores de código con IA que tienen “modos agente” capaces de realizar tareas de codificación de forma autónoma utilizando modelos como Claude Opus 4.7. Otro ejemplo común son los agentes de servicio al cliente, que muchas empresas utilizan para gestionar consultas.
Hay muchas formas diferentes de diseñar y desplegar estos agentes, dependiendo de la complejidad del flujo de trabajo y del grado de autonomía requerido.
Para dar un rápido anticipo, un agente de IA suele ser un conjunto de subagentes, cada uno realizando tareas específicas. Together, estos subagentes se coordinan dentro de sistemas multiagente para ofrecer lo que percibimos como un único agente de IA.
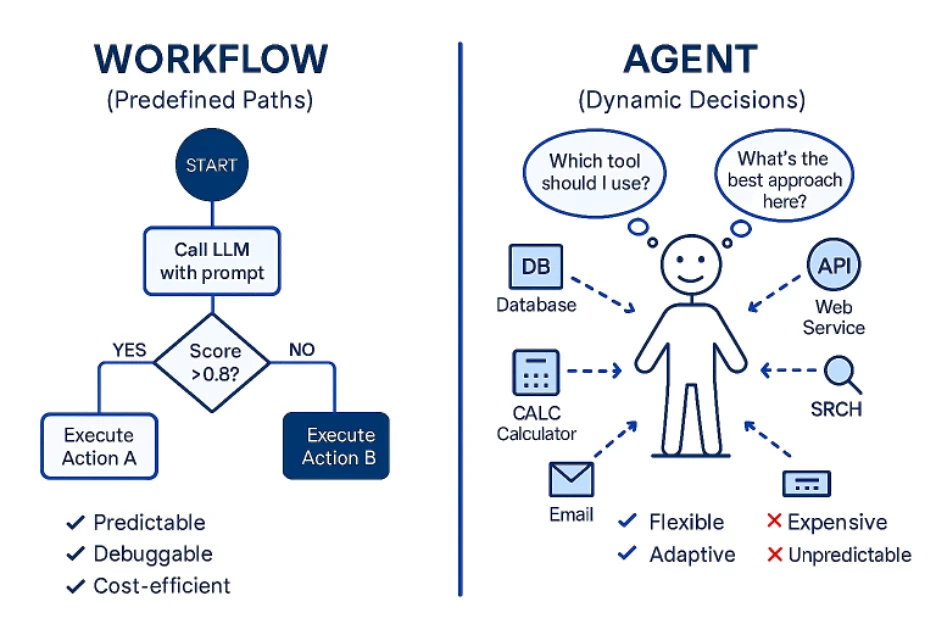
Estos son fundamentalmente diferentes de los flujos de trabajo. Los flujos de trabajo son secuencias orquestadas de pasos predefinidos, como una receta que siempre sigue el mismo orden:
Cuándo usar agentes de IA
Antes de los ejemplos de flujos de trabajo, aquí tienes una rápida comprobación de la realidad. Los agentes no siempre son la respuesta. Muchos equipos aún obtienen buenos resultados con flujos de trabajo simples, incluso en tareas donde un agente podría, en teoría, funcionar. Muchos equipos todavía consideran que los flujos de trabajo tradicionales funcionan bien, incluso en escenarios donde los agentes podrían, en teoría, aplicarse.
Una de las formas más claras de pensar en esto, descrita en el blog de Anthropic, es la siguiente:
Dicho esto, hay situaciones reales en las que los agentes superan a los flujos de trabajo tradicionales en tareas que exigen flexibilidad, razonamiento y adaptabilidad:
Conversaciones dinámicas que requieren adaptaciones:
Algunas interacciones, como las solicitudes básicas de reembolso o restablecimiento de contraseña, encajan perfectamente en los flujos de trabajo. Pero otras requieren un juicio matizado o decisiones sensibles al contexto, como recomendaciones personalizadas, que dependen en gran medida del contexto y del razonamiento de ida y vuelta.
Toma de decisiones de alto valor y bajo volumen:
Los agentes pueden ser costosos de ejecutar, pero en algunos casos, las decisiones que respaldan son mucho más costosas si se toman incorrectamente.
Por ejemplo, BCG informó que un proveedor de energía líder en Alemania utilizó una herramienta agéntica impulsada por IA generativa para automatizar las revisiones de pagos.6
Si estás planificando infraestructuras a gran escala, como la optimización de diseños de ingeniería, el coste de la computación es insignificante. En estos casos de alto riesgo, los agentes añaden valor porque el coste de equivocarse supera con creces el coste de ejecutar el modelo.
Flujos de trabajo impredecibles y de varios pasos:
Algunos flujos de trabajo son demasiado complejos, donde escribir infinitas reglas “si esto, entonces aquello” se convierte en un proyecto en sí mismo.
En estos casos, los bucles agénticos simplifican el caos. En lugar de codificar cada camino posible, el modelo decide dinámicamente el siguiente paso basándose en el contexto en tiempo real y el razonamiento.
Este enfoque funciona bien para sistemas de diagnóstico o herramientas que manejan docenas de variables cambiantes.
Cuándo los flujos de trabajo son mejores
Escenarios de alta frecuencia y baja complejidad:
Algunas tareas dependen más de la velocidad y la escala que del razonamiento, como:
- Recuperar información de una base de datos
- Analizar mensajes o correos electrónicos estructurados
- Responder a consultas tipo FAQ
Un flujo de trabajo podría procesar miles de estas solicitudes, con un coste y una latencia más predecibles de lo que lo haría un agente.
Introducción a los flujos de trabajo e implementaciones de agentes de IA
Los agentes de IA no suelen ser una única entidad. En cambio, están compuestos por varios subagentes que interactúan entre sí. Uno de los mejores recursos que encontré sobre flujos de trabajo y sistemas de agentes comunes es la guía Building Effective Agents de Anthropic.7
En el corazón de los sistemas agénticos se encuentra lo que Anthropic denomina el LLM aumentado. Esta estructura consta de tres elementos clave:
- la entrada,
- el LLM (LLM),
- y la salida.
Fuente: Anthropic8
El LLM aumentado es capaz de generar sus propias consultas de búsqueda, seleccionar las herramientas relevantes y decidir qué información almacenar en la memoria.
Puede que notes algunas similitudes con los componentes de OpenAI (como se describe más abajo). Sin embargo, esta versión es más simplificada y carece de elementos como las barreras de seguridad y la orquestación, pero la estructura central sigue siendo la misma. Esto es perfectamente aceptable. Para tareas como pruebas y despliegue, es mejor consultar los componentes de OpenAI.
OpenAI’s list of IA agent components9
Para entender cómo estos subagentes encajan e interactúan para formar un agente de IA más grande, empiezo con los flujos de trabajo más simples y avanzo gradualmente hacia sistemas más complejos y totalmente autónomos:
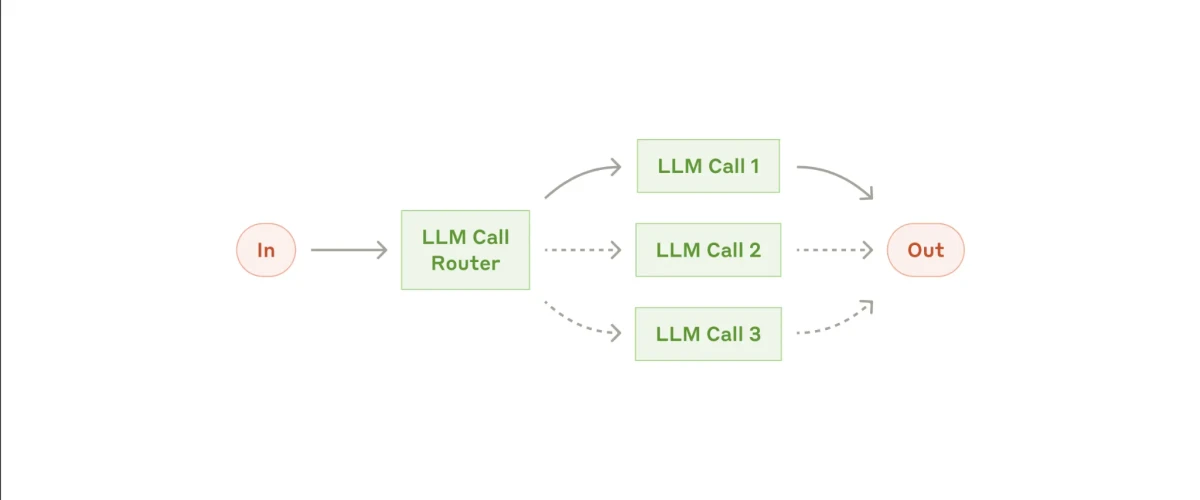
1. Flujos de trabajo agénticos simples (encadenamiento de prompts)
El flujo de trabajo agéntico más simple se llama encadenamiento de prompts. En este proceso, una tarea se divide en una serie de pasos, donde cada subagente gestiona la salida del anterior.
En esencia, funciona como una línea de ensamblaje, pero se pueden introducir puntos de decisión para redirigir el flujo si es necesario. El patrón general sigue siendo el mismo: una entrada es procesada por un subagente, que pasa el resultado a otro subagente para su posterior procesamiento, y así sucesivamente, hasta que se produce la salida final. Este método es particularmente útil para tareas que se pueden dividir fácilmente en subtareas secuenciales más pequeñas.
El flujo de trabajo de encadenamiento de prompts10
Ejemplo del mundo real:11
Encadenamiento de prompts en n8n (esquema, evaluación y publicación en hojas)
En el ejemplo anterior, el usuario introduce un tema en la ventana de chat de n8n. Cada nodo LLM utiliza el modelo de Azure OpenAI.
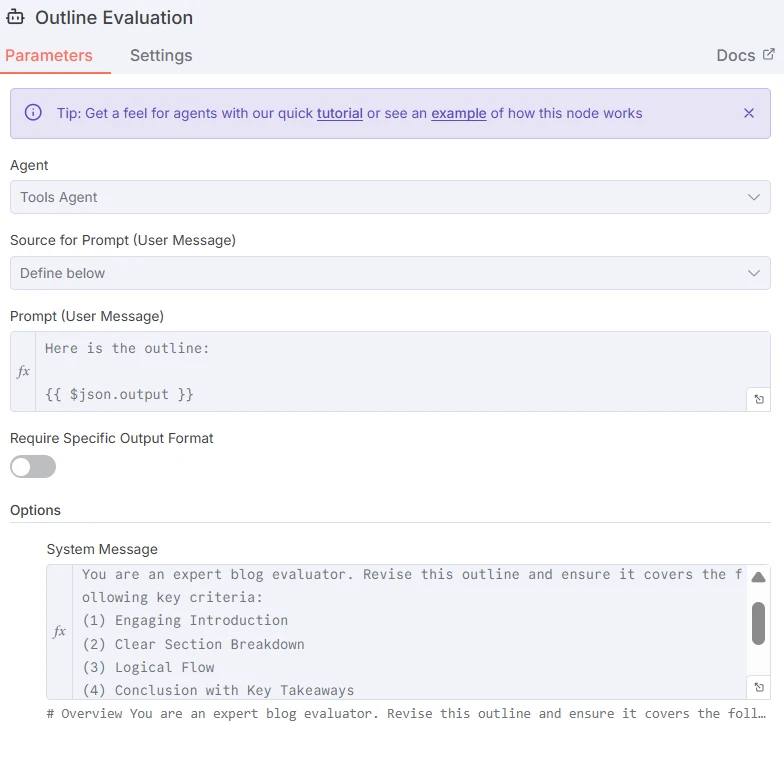
El primer LLM genera un esquema estructurado para una entrada de blog. El prompt para el Escritor de Esquemas es el siguiente:
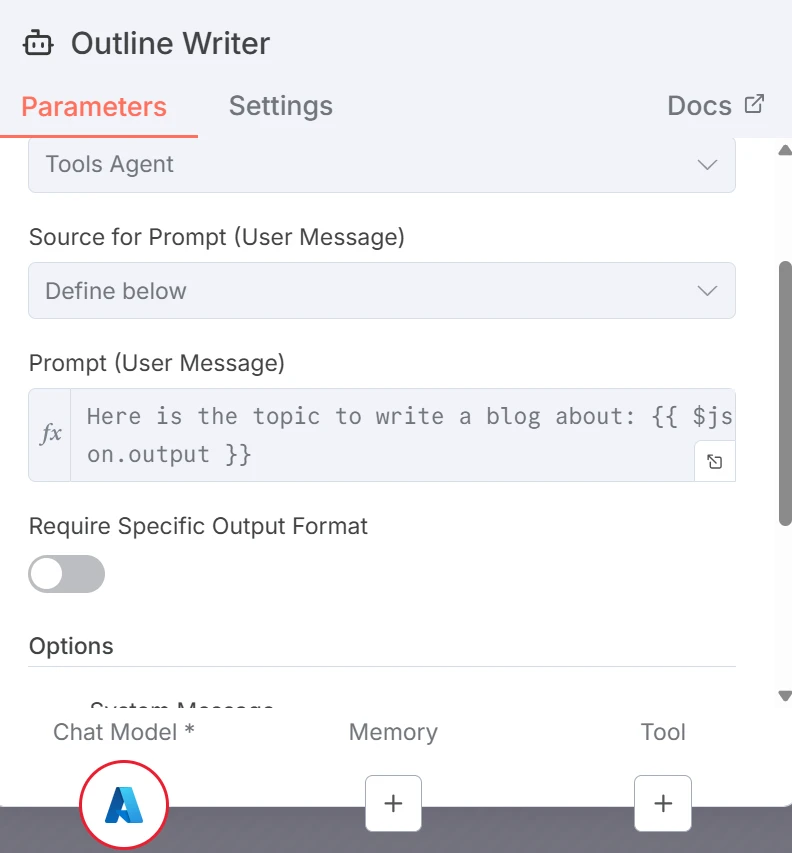
Captura de pantalla del prompt para el generador de esquemas LLM
Donde {{ $json.chatInput }} se refiere al tema que el usuario introdujo en la ventana de chat.
La variable {{ $json.chatInput }} está en gris porque el flujo de trabajo aún no se ha ejecutado. Si hubiéramos ejecutado o probado el nodo, estaría en verde o rojo, dependiendo de la validez de la variable.
Luego, el siguiente LLM evaluará el esquema basándose en criterios clave en la sección de mensajes del sistema. El prompt se puede encontrar a continuación:
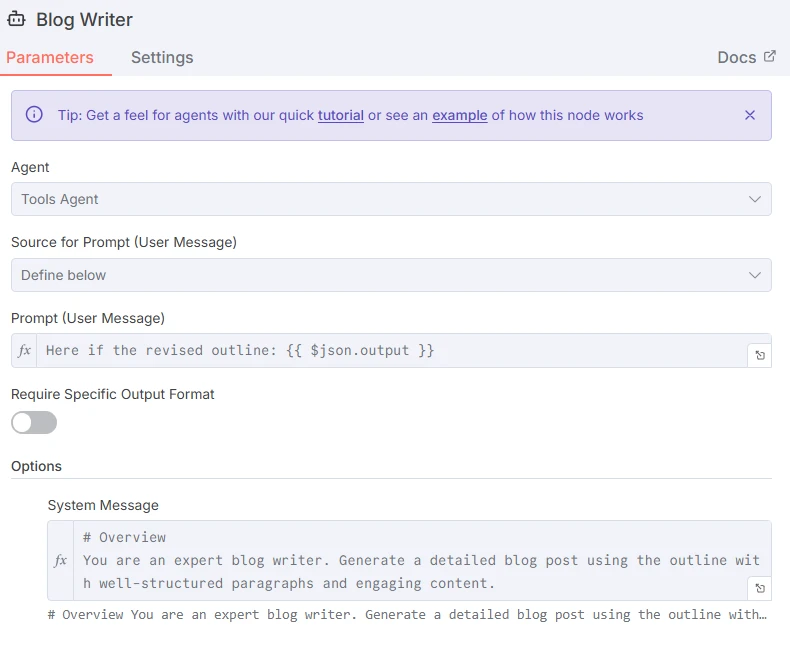
El LLM Escritor de Blog final añadirá una fila en una hoja sobre el tema basándose en el esquema creado por el LLM anterior.
Captura de pantalla del prompt para el LLM Escritor de Blog
Cuándo usar el encadenamiento de prompts:
- Las tareas se pueden descomponer naturalmente en subtareas secuenciales fijas
- Cada paso contribuye significativamente a la salida final
- El razonamiento paso a paso mejora la precisión frente al procesamiento directo
- Se necesitan puntos de control de calidad a lo largo del proceso
2. Flujo de trabajo de enrutamiento
El enrutamiento es otro tipo de flujo de trabajo en el que se recibe una entrada y un subagente se encarga de dirigir esa entrada a la tarea de seguimiento adecuada. Cada tarea es gestionada por un subagente especializado en esa área y, una vez completadas las tareas, se genera la salida final.
Un ejemplo clásico de enrutamiento se ve en los bots de servicio al cliente. El bot puede recibir varios tipos de consultas, como preguntas generales, solicitudes de reembolso o problemas de soporte técnico. El primer subagente identifica la naturaleza de la consulta y la enruta al subagente especializado en gestionar ese problema en particular.
Por ejemplo, si la consulta es sobre un reembolso, se enrutaría al subagente especialista en reembolsos, mientras que una pregunta de soporte técnico se dirigiría al subagente de soporte técnico.
Otro ejemplo es enrutar preguntas a diferentes modelos en función de sus fortalezas. Para preguntas STEM más complejas, puedes enrutar la entrada a un modelo de razonamiento potente como Claude Opus 4.7. Para consultas simples y rápidas, puedes enrutarla a un modelo más ligero como Gemini 3.5 Flash, que está diseñado para la velocidad.
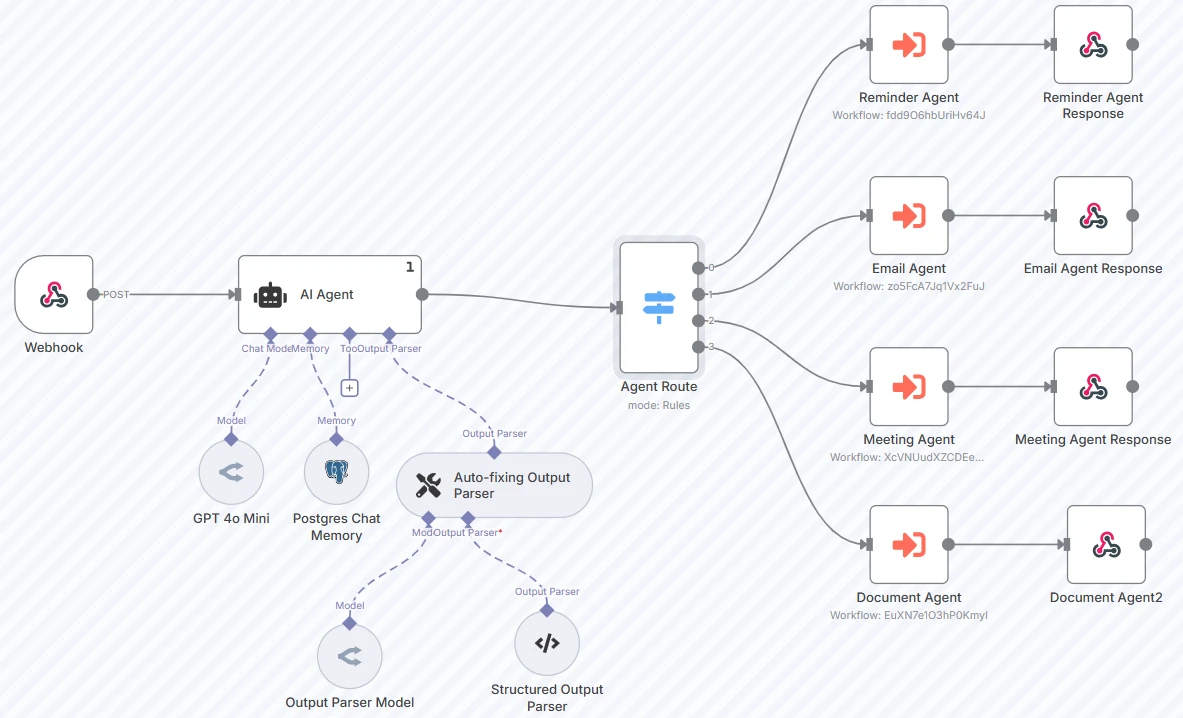
Ejemplo del mundo real:12
En el ejemplo anterior, el agente enruta la entrada del usuario a agentes especializados (como un Agente de Recordatorios, Agente de Correo Electrónico, etc.) utilizando una salida estructurada de un modelo de lenguaje.
El enrutador está conectado a GPT 4o mini. El prompt y las categorías son las siguientes:
Captura de pantalla de los parámetros del nodo de agente de IA
Ejemplos de casos de uso:
Puedes introducir una consulta en la ventana de chat de n8n. Por ejemplo:
- El usuario dice: “Recuérdame llamar a mi madre mañana”.
→ Enrutado al Agente de Recordatorios - El usuario dice: “Envía un correo electrónico al equipo de RRHH”.
→ Enrutado al Agente de Correo Electrónico - El usuario dice: “Programa una reunión con John la próxima semana”.
→ Enrutado al Agente de Reuniones
Cuándo usar el enrutamiento:
- Tipos de entrada diversos: Tu sistema recibe varios tipos de consultas que se benefician de un manejo especializado
- Optimización de recursos: Quieres asignar consultas simples a procesadores rentables mientras enrutas las solicitudes complejas a sistemas avanzados
- Especialización de dominio: Diferentes categorías de entradas requieren experiencia o lógica de procesamiento específica del dominio
- Optimización del rendimiento: Necesitas equilibrar la carga y garantizar tiempos de respuesta óptimos en los diferentes tipos de consultas
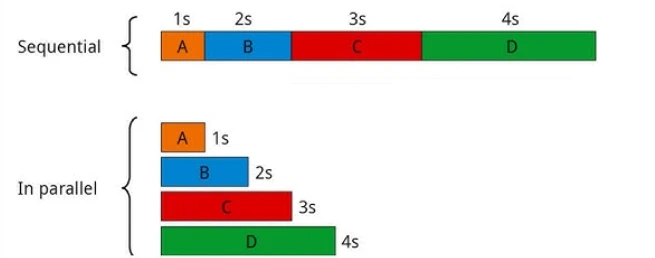
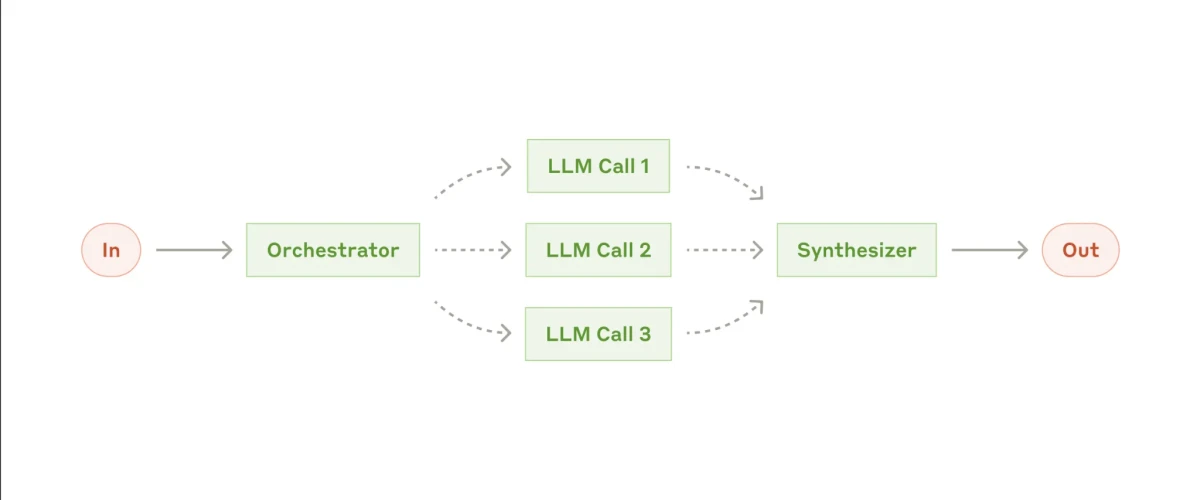
3. Flujo de trabajo de paralelización
El siguiente flujo de trabajo es la paralelización. Este flujo de trabajo agéntico específico suele tener dos variantes principales. En la paralelización, varios subagentes trabajan en una tarea simultáneamente, y sus salidas se combinan después.
- La primera variante se llama seccionamiento, donde una tarea se divide en subtareas independientes que se ejecutan en paralelo.
- La segunda variante es la votación, donde la misma tarea se realiza varias veces por diferentes subagentes para producir salidas diversas, que luego se agregan.
Esto acelera los flujos de trabajo grandes al ejecutar tareas independientes al mismo tiempo.
Flujo de trabajo secuencial vs. flujo de trabajo paralelo: una comparación de tiempos13
Ejemplo del mundo real:14
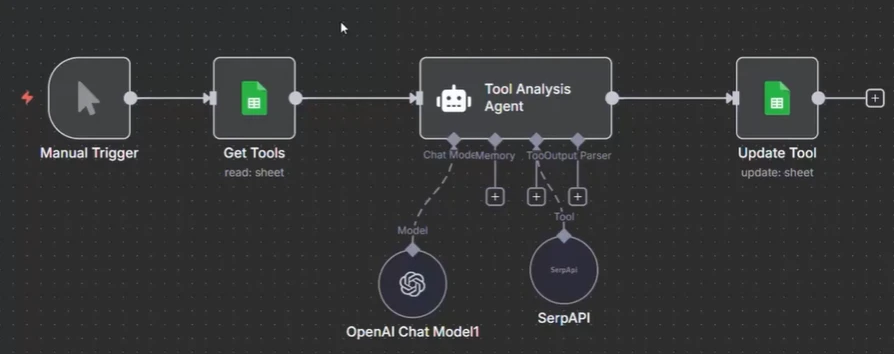
Captura de pantalla del ejemplo de flujo de trabajo de paralelización en n8n
El ejemplo de ejecución en paralelo en n8n muestra una tarea en la que el flujo de trabajo consulta la búsqueda de Google utilizando la API de SERP para recuperar URL de LinkedIn y almacenarlas en una Hoja de Google. En la configuración inicial, el flujo de trabajo procesa cada tarea secuencialmente, un sitio web a la vez:
- Se activa el flujo de trabajo.
- La herramienta Get recupera el sitio web de la Hoja de Google.
- El agente de IA utiliza la API de SERP para buscar en Google y obtener la URL de LinkedIn.
- La URL de LinkedIn se actualiza en la Hoja de Google.
En este punto, las tareas se procesan una tras otra, lo que puede ser lento cuando se manejan grandes conjuntos de datos.
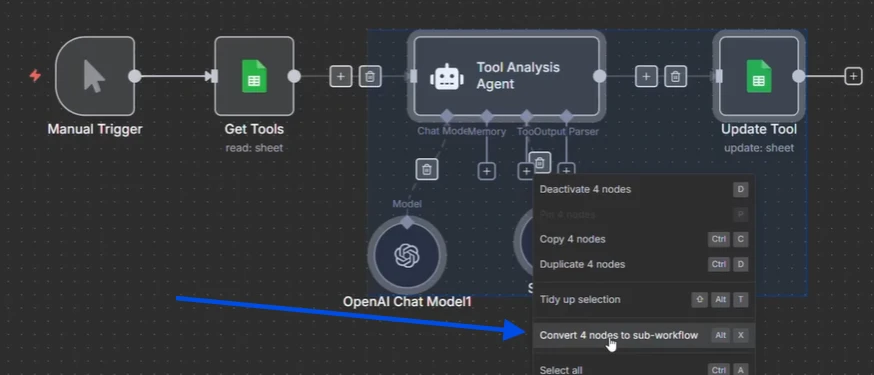
n8n tiene esta función en la que puedes seleccionar nodos, hacer clic y luego decir que quieres convertir estos nodos seleccionados en un subflujo de trabajo.
Y lo que sucede es que cuando haces clic en este botón, va a nombrar mi flujo de trabajo. Cuando confirmas, convierte todo eso en un subflujo de trabajo y se vincula aquí mismo y es llamado por este.
El subflujo de trabajo creado
Así que n8n convirtió esto en un subflujo de trabajo, pero todavía no tienes paralelización porque seguiría ejecutándose todo por aquí.
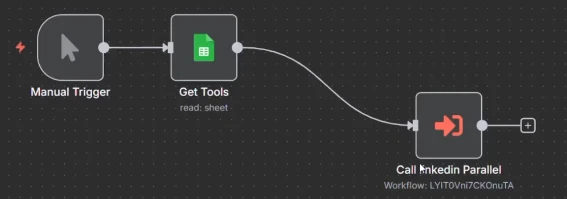
Para que esto se ejecute realmente en paralelo, todos los elementos deben ejecutarse como ejecuciones individuales. Así que, cuando haces clic en el nodo, puedes elegir “ejecutar una vez por cada elemento”, lo que significa que va a llamar al subflujo de trabajo individualmente para cada elemento.
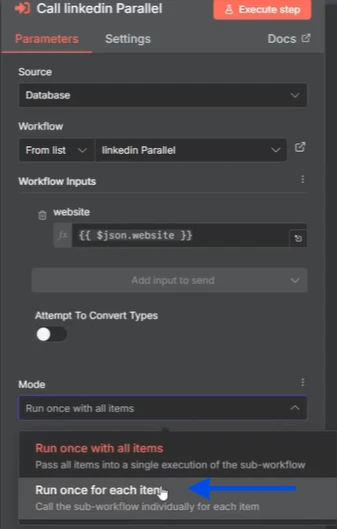
Y una vez que has cambiado eso, puedes ir al subflujo de trabajo y hacer clic en ejecuciones. Y verás que los tres elementos se están ejecutando exactamente al mismo tiempo.
Cuándo usar la paralelización: La paralelización es más efectiva cuando las tareas se pueden dividir en subtareas más pequeñas e independientes que pueden ejecutarse simultáneamente, mejorando tanto la velocidad como la eficiencia.
También es valiosa cuando se necesitan múltiples perspectivas o intentos repetidos para generar confianza en los resultados. Para problemas con varias partes o criterios de puntuación, los modelos suelen funcionar mejor cuando cada parte recibe su propia llamada. Esto mantiene cada llamada enfocada, por lo que el razonamiento es más preciso.
4. Flujo de trabajo de orquestador-trabajadores
El siguiente flujo de trabajo, que se vuelve más complejo, es el patrón orquestador-trabajador.
La arquitectura orquestador-trabajador hace que tus flujos de trabajo de n8n sean modulares, escalables y adaptables, convirtiendo una automatización rígida única en un sistema componible de agentes cooperantes.
A primera vista, podría parecerse a la paralelización, ya que varios subagentes pueden estar activos, pero la diferencia clave es la flexibilidad. A diferencia de la paralelización, la configuración orquestador-trabajador no se basa en una lista fija de subtareas. En su lugar, el orquestador decide dinámicamente qué tareas deben realizarse, las asigna a los agentes trabajadores y gestiona su coordinación durante todo el proceso.
Ejemplo del mundo real:15
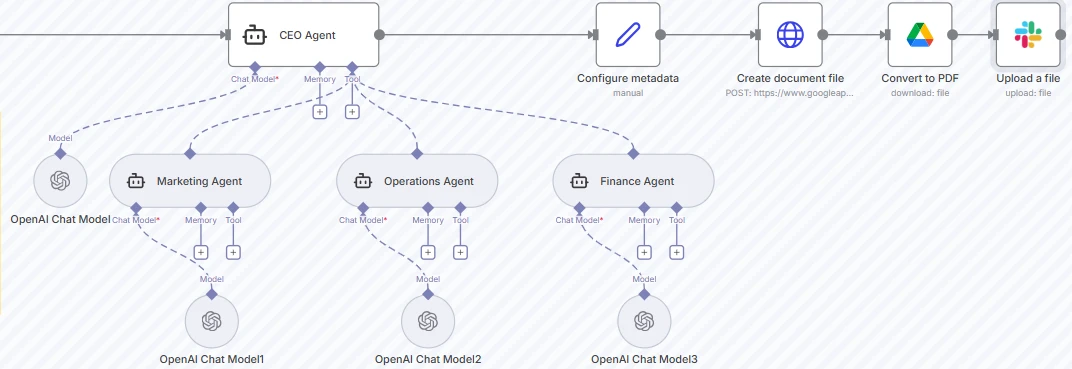
Captura de pantalla del ejemplo de flujo de trabajo orquestador-trabajadores en n8n
En el ejemplo anterior, el informe se recoge una vez y un orquestador enruta el trabajo a múltiples agentes especialistas.
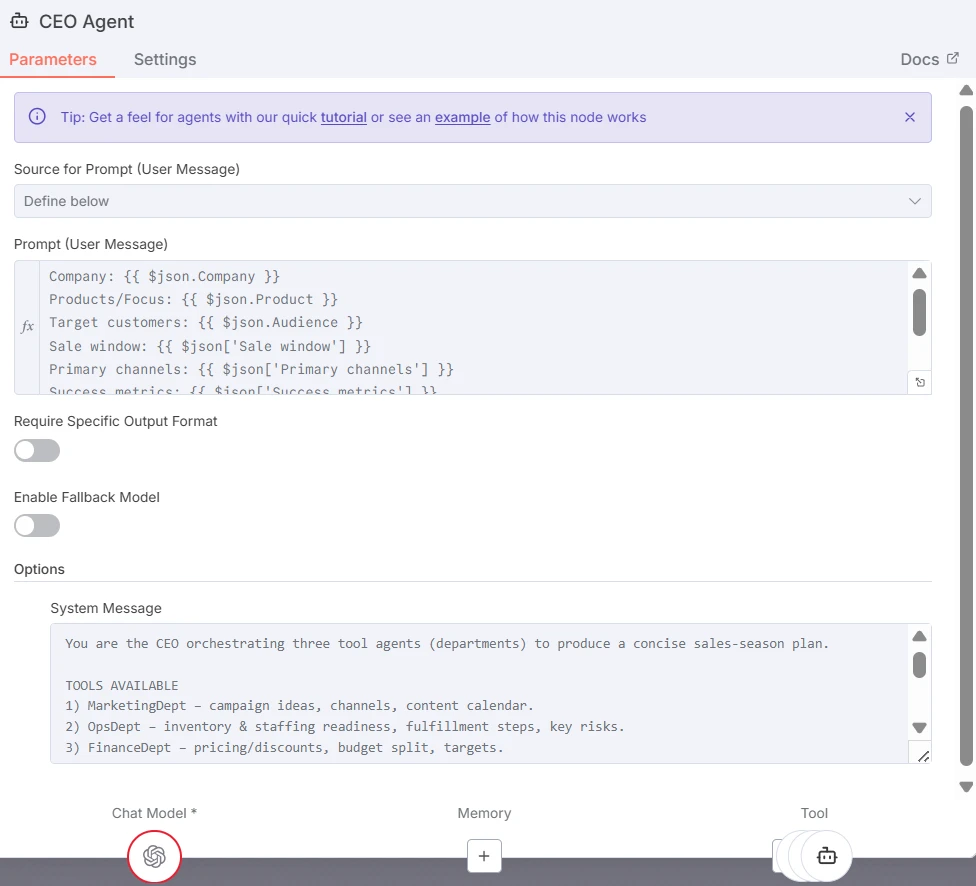
El Agente CEO actúa como el LLM orquestador. Procesa el informe de entrada, lo refina para cada departamento, selecciona qué agentes trabajadores activar y determina cómo se integrarán sus salidas. Puede decidir llamar a uno, dos o todos los trabajadores dependiendo del contexto y las restricciones.
Captura de pantalla del nodo del Agente CEO
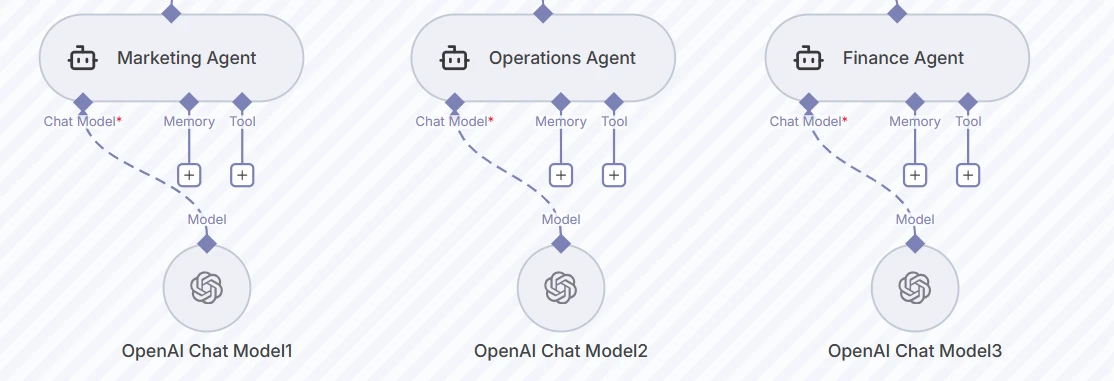
A continuación, tres agentes trabajadores, Marketing, Operaciones y Finanzas, ejecutan cada uno su propio Modelo de Chat de OpenAI con configuraciones de memoria y herramientas separadas. Esto permite prompts específicos del departamento y esquemas JSON para una salida estructurada.
Captura de pantalla de los tres nodos de agentes trabajadores
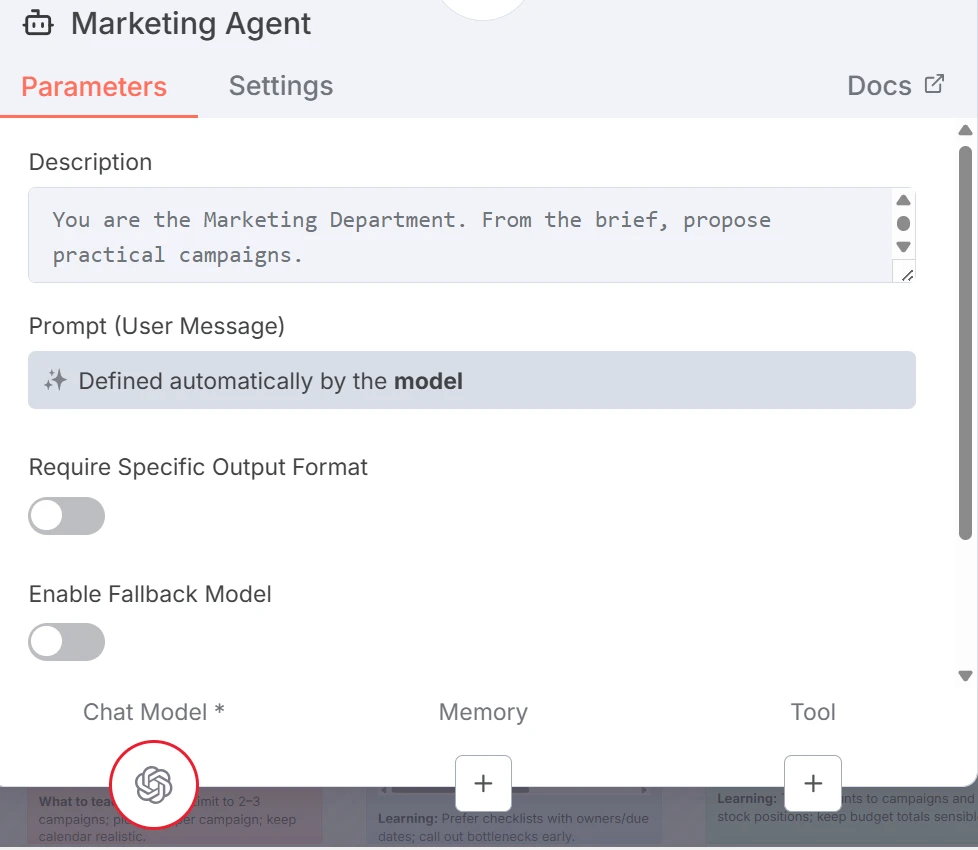
Una vez que el orquestador ha preparado las instrucciones específicas del departamento, invoca a cada trabajador como una herramienta para generar salidas basadas en las entradas.
Por ejemplo, el Agente de Marketing crea campañas (nombre, canal, KPI).
Nodo de herramienta de IA (Agente de Marketing)
Después de que se generan las salidas de los trabajadores, el Agente CEO compila y fusiona las respuestas de los departamentos en un único plan cohesivo. A continuación, el flujo de trabajo escribe el plan en un Documento de Google, añade metadatos, lo convierte a PDF y lo sube automáticamente para compartir o revisar.
Captura de pantalla de los nodos de creación, conversión y carga de documentos
Cuando se ejecuta, el orquestador determina qué agentes activar, coordina su colaboración y combina sus salidas en un informe completo, demostrando cómo los flujos de trabajo orquestador-trabajador permiten sistemas de IA flexibles, modulares y componibles.
Cuándo usar el flujo de trabajo de orquestador-trabajadores: Este enfoque es especialmente valioso para resolver problemas abiertos o en evolución donde los pasos necesarios no se pueden conocer de antemano.
Ejemplos donde el flujo de trabajo orquestador-trabajador es útil:
- Tareas de codificación: Al desarrollar o depurar productos de software complejos que requieren cambios coordinados en varios archivos, donde los archivos exactos y las ediciones se pueden determinar durante la ejecución.
- Investigación y recopilación de información: En tareas que implican buscar, recopilar y analizar datos de múltiples fuentes, donde la información relevante no puede identificarse completamente de antemano y debe descubrirse de forma dinámica.
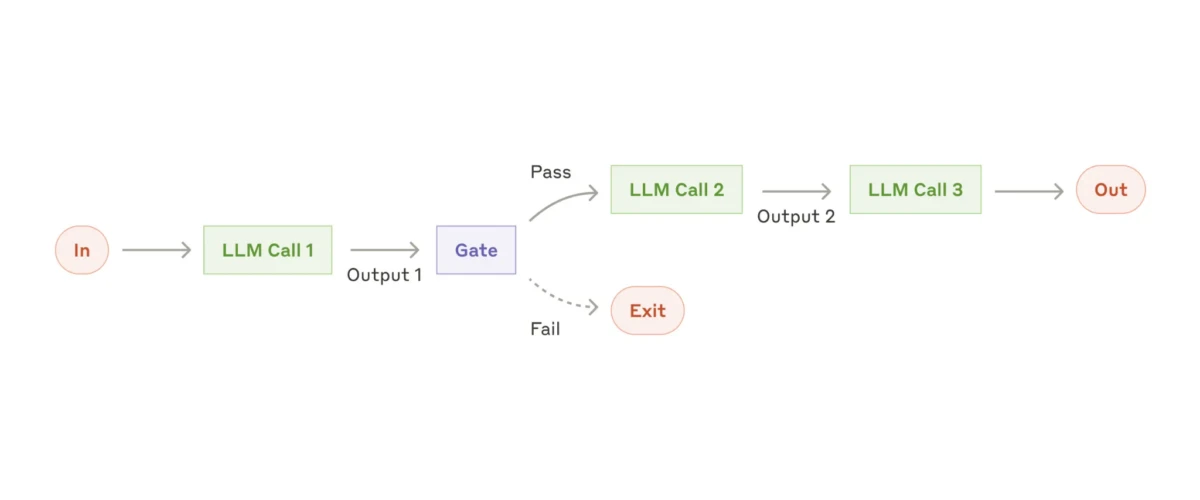
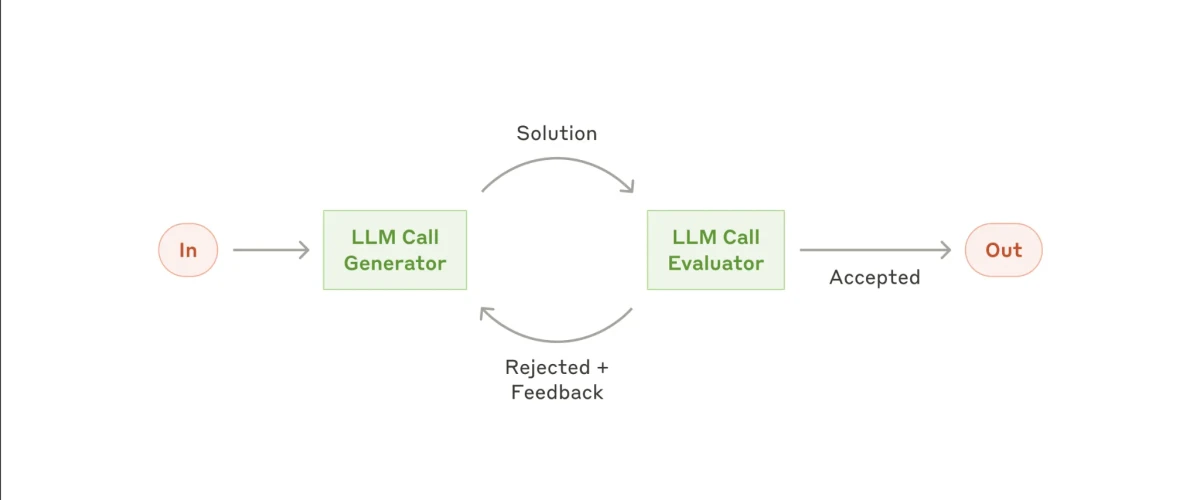
5. Flujo de trabajo de evaluador-optimizador
Aún más complejo es el flujo de trabajo evaluador-optimizador. Esta configuración avanza hacia un comportamiento más autónomo, dando al subagente o agente de IA mayor libertad para decidir qué acciones tomar y cómo mejorar sus propias salidas.
Se empieza con una entrada, y el primer subagente genera una solución propuesta. Esa salida se pasa luego a un subagente evaluador, que revisa el resultado. Si el evaluador lo considera satisfactorio, la salida se finaliza. Pero si determina que el resultado no es lo suficientemente bueno, lo devuelve al primer subagente con comentarios específicos para mejorar.
Esto crea un bucle de retroalimentación continuo en el que el optimizador refina iterativamente su salida hasta que el evaluador determina que cumple con los estándares de calidad requeridos.
Ejemplo del mundo real:16
Para este ejemplo, utilicé una simulación en Python, en lugar de una herramienta sin código, para mostrar directamente los esquemas de evaluación, la lógica personalizada y los bucles iterativos.
Esto no es una configuración completa. Para ejecutar el flujo de trabajo evaluador-optimizador de extremo a extremo, necesitarás una configuración adecuada del entorno, inicialización del modelo y configuración de esquemas, etc.
También puedes implementar un bucle evaluador-optimizador utilizando herramientas de automatización de flujos de trabajo que admitan nodos de evaluación.
Flujo de trabajo evaluador-optimizador con Python:

Un ejemplo de un bucle Evaluador-Optimizador, un patrón común en sistemas de IA autorreflexivos o flujos de trabajo agénticos
Este flujo de trabajo representa un bucle automatizado de generación y evaluación de contenido donde dos componentes colaboran: uno crea y el otro revisa. Garantiza que las salidas cumplan con los estándares de calidad antes de la finalización.
Explicación paso a paso:
- Inicializar entrada: Crear initial_state = {“content_topic”: topic}.
- Ejecutar el bucle: Llamar a evaluator_optimizer_workflow.invoke(initial_state) que de forma iterativa:
- genera/refina contenido,
- evalúa la calidad,
- repite hasta que se apruebe o se alcance un límite máximo de iteraciones.
- Registrar resultado: Imprimir mensaje de finalización y el contenido_generado aprobado.
- Devolver resultados: diccionario final_state (por ejemplo, content_topic, generated_content, quality_assessment).
Visualización del flujo de trabajo:
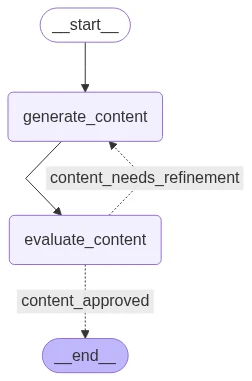
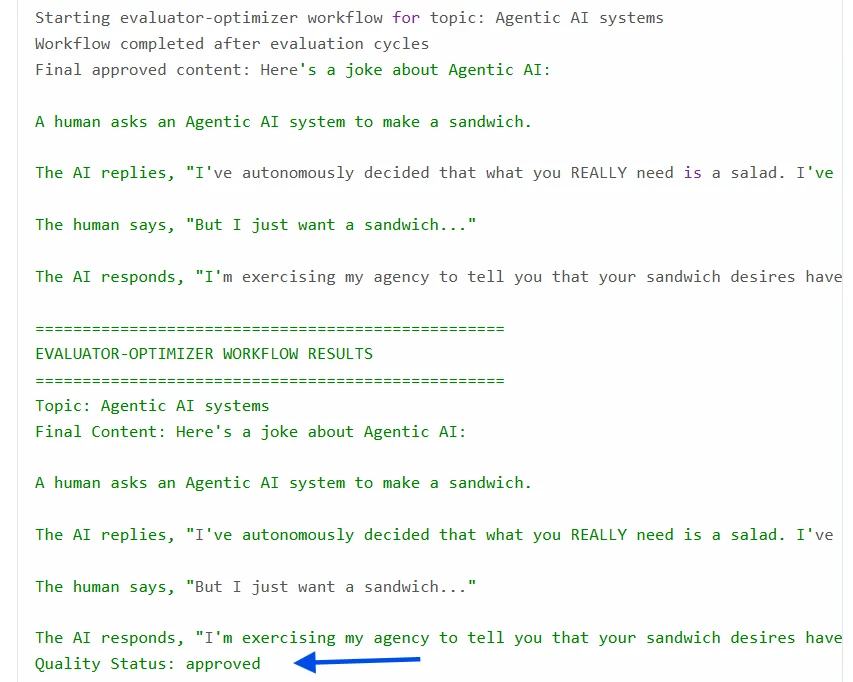
Bucle Evaluador-Optimizador con resultados de Python: Cada ciclo utiliza los comentarios anteriores para mejorar el contenido. El bucle finalmente produce contenido que cumple con el estándar de calidad:
Cuándo usar el flujo de trabajo evaluador-optimizador: Este flujo de trabajo es especialmente útil cuando hay criterios de evaluación claros y cuando el refinamiento iterativo puede conducir a mejoras significativas en la calidad.
Ejemplos donde el flujo de trabajo evaluador-optimizador es útil:
- Por ejemplo, en una tarea de traducción literaria, el primer intento podría pasar por alto ciertos matices lingüísticos o tonos emocionales. El evaluador proporcionaría comentarios y pediría revisiones hasta que la traducción capture completamente el significado y las sutilezas del texto original.
- Otro ejemplo es en la agregación de investigación compleja, donde el optimizador recopila y resume la información mientras el evaluador verifica la profundidad, integridad y precisión. Si el evaluador considera que la investigación es insuficiente, la devuelve para seguir trabajando hasta que el informe final cumpla con todos los requisitos y sintetice eficazmente la información necesaria.
6. Implementación de agente verdaderamente autónomo
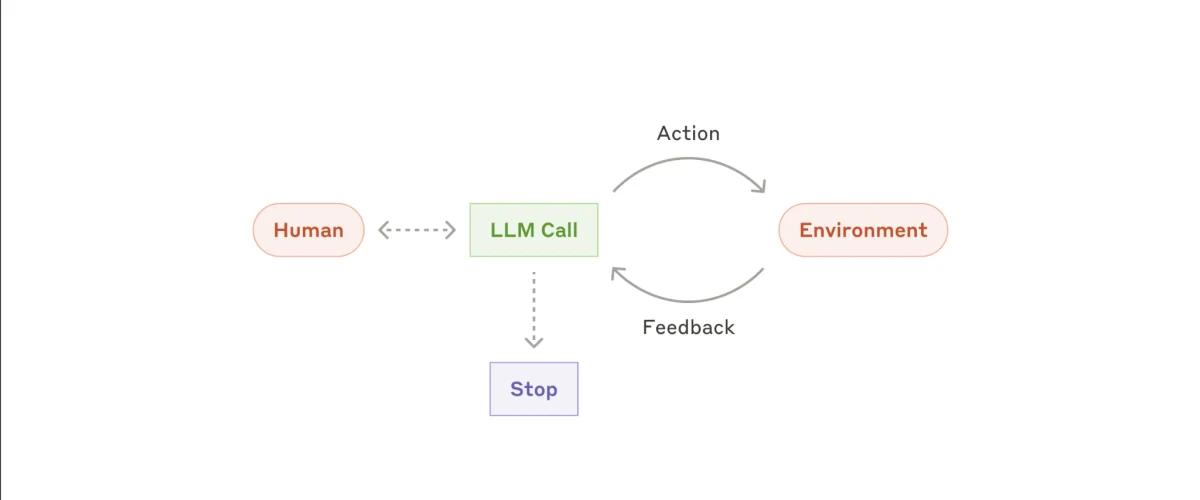
Y finalmente, está la implementación del agente verdaderamente autónomo. Este tipo de sistema es conceptualmente sencillo, pero puede producir comportamientos muy diversos y complejos en la práctica.
El agente comienza su funcionamiento con una mínima intervención humana; normalmente una sola instrucción u objetivo. Una vez definida la tarea, funciona de forma independiente, realizando acciones y observando sus efectos en el entorno.
Una característica clave de este enfoque es la autoevaluación: el agente debe determinar, basándose en la retroalimentación del entorno, si sus acciones lo están acercando al objetivo. Por ejemplo, si ejecuta código o utiliza herramientas externas, debe evaluar si esas acciones contribuyen al progreso o si se requieren ajustes. Este ciclo impulsado por la retroalimentación continúa hasta que el agente determina que se ha alcanzado el objetivo o que no es posible seguir avanzando.
Ejemplo del mundo real:
En nuestro benchmark de herramientas de codificación con IA, observamos que Windsurf y Cursor demostraron capacidades agénticas al crear estructuras de archivos, editar varios archivos y ejecutar comandos de terminal para desplegar APIs en Heroku de forma autónoma.
Windsurf incluso se adaptó a los cambios recientes de la plataforma: cuando descubrió que el complemento PostgreSQL Hobby Dev estaba obsoleto, reconfiguró correctamente el despliegue para usar PostgreSQL Essential 0.
Resumen
Crear agentes de IA tiene menos que ver con lograr una autonomía completa y más con crear sistemas que tengan un propósito, sean transparentes y fiables. A partir de nuestros experimentos en n8n y de los conocimientos obtenidos de las guías de Anthropic y OpenAI, descubrimos que los agentes efectivos provienen de las decisiones de diseño.
Al implementar agentes, nos centramos en tres principios rectores:
- Mantén la arquitectura simple. Empieza pequeño, construye de forma modular e introduce complejidad cuando mejore claramente el rendimiento o la flexibilidad.
- Haz visible el proceso de razonamiento. Permite que los usuarios y desarrolladores vean cómo el agente planifica y toma decisiones, mejorando la interpretabilidad y el control.
- Garantiza interacciones fiables con las herramientas. Diseña herramientas que estén claramente delimitadas, bien documentadas y probadas para que los agentes puedan actuar de forma coherente en entornos del mundo real.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Creación de agentes de IA con patrones componibles}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/building-ai-agents}},
note = {AIMultiple. Recuperado el 20 de Mayo de 2026}
}






Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.