20 estrategias para mejorar la IA y ejemplos
Los modelos de IA requieren una mejora continua a medida que los datos, el comportamiento del usuario y las condiciones del mundo real evolucionan. Incluso los modelos con buen rendimiento pueden desviarse cuando los patrones que aprendieron ya no coinciden con las entradas actuales, lo que conduce a una precisión reducida y predicciones poco fiables.
Los cambios en regulaciones, requisitos del producto o expectativas de los clientes también pueden introducir nuevas limitaciones que los modelos existentes no fueron diseñados para manejar.
Mantener la calidad del modelo implica, por tanto, reforzar tanto los datos que respaldan el modelo como los algoritmos que dan forma a su comportamiento, asegurando que los sistemas permanezcan alineados con los requisitos actuales en lugar de suposiciones obsoletas.
Explora estrategias clave, incluyendo alimentación de datos, datos y mejora de algoritmos, y las leyes de escalado de IA que asegurarán que tus modelos de IA sigan siendo relevantes y prácticos.
Las 20 mejores formas de mejorar tu modelo de IA
Explicamos métodos para mejorar tu modelo de IA en 4 categorías diferentes:
Método | Descripción | Desafíos clave |
|---|---|---|
Alimentar más datos | Añadir datos reales o sintéticos de alta calidad para mejorar la cobertura y la generalización. | Asegurar la calidad de los datos, evitar sesgos, gestionar la privacidad y los límites de acceso. |
Mejorar los datos | Mejorar el etiquetado, la diversidad y la aumentación para reducir ruido y sesgo. | Equilibrar calidad vs. cantidad, reducir el sesgo del dataset, mantener anotaciones consistentes. |
Mejorar el algoritmo | Usar mejores arquitecturas, técnicas de fine-tuning y prácticas de despliegue. | Mayor complejidad y coste, comportamientos no deseados, necesidades estrictas de privacidad. |
Leyes de escalado de IA | Aumentar la escala, el cómputo, la eficiencia y las técnicas de recuperación o multi-agente. | Rendimientos decrecientes, límites de cómputo, impacto ambiental, complejidad de integración. |
Alimentar más datos
Añadir datos nuevos y frescos es uno de los métodos más comunes y efectivos para mejorar la precisión de tu modelo de aprendizaje automático. La investigación ha mostrado una correlación positiva entre el tamaño del dataset y la precisión del modelo de IA.1
Por lo tanto, expandir el dataset que se utiliza para el reentrenamiento del modelo puede ser una forma efectiva de mejorar los modelos de IA/ML. Asegúrate de que los datos cambien según el entorno en el que se despliegan. También es esencial adherirse a prácticas adecuadas de garantía de calidad en la recolección de datos.
1. Recolección de datos
La recolección/cosecha de datos puede utilizarse para expandir tu dataset y alimentar más datos al modelo de IA/ML. En este proceso, se recopilan datos frescos para reentrenar el modelo. Estos datos pueden obtenerse mediante los siguientes métodos:
- Recolección privada
- Recolección automatizada de datos
- Crowdsourcing personalizado
Para recopilar datos con éxito para IA, las empresas deben prestar atención a:
- Se deben respetar las consideraciones éticas y legales en la recolección de datos para evitar problemas éticos.
- El sesgo en los datos de entrenamiento puede conducir a resultados no deseados de IA.
- El preprocesamiento de datos brutos es esencial para abordar problemas de calidad y garantizar la integridad de los datos para el entrenamiento de IA/ML.
- No todos los datos son fácilmente accesibles debido a restricciones relacionadas con sensibilidad y regulaciones de privacidad.
Más información sobre métodos de recolección de datos.
También se recomienda trabajar con un servicio de datos de IA para obtener datasets relevantes sin la molestia de recopilar datos y para evitar problemas éticos y legales.
2. Datos sintéticos con modelos generativos
La IA generativa ha avanzado la creación de datos sintéticos, produciendo datasets de alta calidad que replican condiciones del mundo real. Los grandes modelos de lenguaje y los modelos de difusión ahora pueden generar datos estructurados y no estructurados para entrenar modelos en dominios donde los datos reales son limitados.
Ejemplos incluyen:
- Producir casos médicos raros para mejorar modelos de aprendizaje automático en atención sanitaria.
- Generar datos de conversación realistas para mejorar sistemas de procesamiento de lenguaje natural.
- Crear datasets visuales para probar resolución de imagen, calidad de foto o modelos de reconocimiento de imágenes.
Auto-juego sintético y datos de entrenamiento sintéticos
El auto-juego sintético genera nuevos datos de entrenamiento al permitir que modelos o agentes interactúen con tareas o entre sí. Estos suplementos tienen datos humanos de alta calidad limitados.
Este método proporciona:
- Producción escalable de datos de instrucción, razonamiento o diálogo.
- Cobertura de escenarios que son raros o costosos de recopilar manualmente.
- Mejora del rendimiento del modelo en dominios donde la escasez de datos es una limitación principal.
Ejemplo real: Más datos para chatbots
Un chatbot de soporte de TI tenía dificultades para entender y clasificar las preguntas de los usuarios con precisión. Para mejorar su rendimiento, 500 consultas de soporte de TI se reescribieron en múltiples variaciones en siete idiomas.
Estos datos adicionales ayudaron al chatbot a reconocer diferentes formatos de preguntas, mejorando su capacidad para responder de manera más efectiva.
Mejorar los datos
Mejorar los datos existentes también puede resultar en un modelo de IA/ML mejorado.
Ahora que las soluciones de IA están abordando problemas más complejos, se requieren datos mejores y más diversos para desarrollarlos. Por ejemplo, una investigación2 sobre un modelo de aprendizaje profundo que ayuda a sistemas de detección de objetos a entender las interacciones entre dos objetos, concluye que el modelo es susceptible3 al sesgo del dataset y requiere un dataset diverso para producir resultados.
Las mejoras pueden lograrse mediante:
3. Enriquecer los datos
Expandir el dataset es una forma de mejorar la IA. Otra forma importante de mejorar los modelos de IA/ML es enriqueciendo los datos. Esto significa que los nuevos datos que se recopilan para expandir el dataset deben ser procesados antes de ser introducidos en el modelo.
Esto también puede significar mejorar la anotación del dataset existente. Dado que se han desarrollado técnicas de etiquetado nuevas y mejoradas, pueden implementarse en el dataset existente o recién recopilado para mejorar la precisión del modelo.
4. Mejorar la calidad de los datos
Mejorar la calidad de los datos es esencial para avanzar en los sistemas de IA y mejorar el rendimiento de los modelos de IA. Si bien los avances en IA a menudo enfatizan mejores algoritmos y mayor potencia de cómputo, los datos de entrenamiento de alta calidad siguen siendo cruciales para un rendimiento óptimo.
Adoptar un enfoque centrado en los datos ayuda a acelerar el progreso de la IA asegurando que los datos utilizados para el entrenamiento sean abundantes y de alta calidad.
La recolección y curación de datos de alta calidad permite a los desarrolladores construir modelos de IA más eficientes y efectivos, que luego pueden aprovecharse para resolver tareas complejas en diversas industrias. Al enfocarse en la calidad de los datos, las empresas pueden hacer predicciones más precisas, reducir el sesgo y mejorar las capacidades de los sistemas de IA.
La calidad de los datos puede mejorarse significativamente durante la fase de recolección de datos. Este proceso incluye asegurar que los datos sean representativos de los escenarios del mundo real que el modelo encontrará para eliminar sesgos, reducir el ruido y asegurarse de que sean lo suficientemente diversos como para capturar todas las variables relevantes.
Además, mantener la consistencia en el etiquetado de datos y abordar las lagunas en el dataset puede ayudar a reducir errores en el proceso de aprendizaje del modelo.
5. Aprovechar la aumentación de datos
Algunas personas pueden confundir datos aumentados con datos sintéticos; sin embargo, los dos términos difieren. Los datos aumentados se refieren a añadir información a un dataset existente, mientras que los datos sintéticos se generan artificialmente para sustituir a los datos reales.
Mejorar el algoritmo
A veces, el algoritmo que se creó inicialmente para el modelo necesita ser mejorado. Esto puede deberse a diferentes razones, incluyendo un cambio en la población sobre la cual se despliega el modelo.
Supongamos que un algoritmo de IA/ML desplegado que evalúa el riesgo de salud del paciente y no incluye el parámetro de nivel de ingresos se expone repentinamente a datos de pacientes con niveles de ingresos más bajos. En ese caso, es poco probable que produzca evaluaciones justas.
Por lo tanto, actualizar el algoritmo y añadirle nuevos parámetros puede ser una forma efectiva de mejorar el rendimiento del modelo. El algoritmo puede mejorarse de las siguientes maneras:
6. Mejorar la arquitectura
Hay algunas cosas que se pueden hacer para mejorar la arquitectura de un algoritmo. Una forma es aprovechar las características modernas del hardware, como las instrucciones SIMD o las GPU.4
Además, las estructuras de datos y los algoritmos pueden mejorarse mediante el uso de diseños de datos amigables con la caché y algoritmos eficientes. Finalmente, los desarrolladores de algoritmos pueden explotar los avances recientes en aprendizaje automático y técnicas de optimización.
El Transformer es una arquitectura de aprendizaje profundo que cambió el procesamiento de lenguaje natural (NLP) y otros campos al permitir un modelado más eficiente y efectivo de datos secuenciales. Presentado en el artículo «Attention Is All You Need»,5 se basa en gran medida en un mecanismo llamado autoatención, reemplazando las operaciones recurrentes y convolucionales utilizadas en modelos anteriores como RNNs y CNNs.
Un Transformer consta de un Codificador y un Decodificador, cada uno construido a partir de múltiples capas apiladas:
- El Codificador transforma secuencias de entrada en representaciones conscientes del contexto utilizando autoatención multi-cabeza para capturar relaciones entre tokens, redes feedforward para procesamiento, y conexiones residuales con normalización de capa para estabilidad.
- El Decodificador genera secuencias de salida token por token, incorporando autoatención multi-cabeza enmascarada para evitar el acceso a tokens futuros, atención cruzada para integrar las salidas del Codificador, y mecanismos similares de feedforward y normalización para un aprendizaje eficiente.
7. Arquitecturas de modelos híbridos
Las arquitecturas de modelos híbridos combinan elementos de Transformers, modelos de espacio de estados y otros métodos de procesamiento de secuencias. Este enfoque admite contexto de larga duración y reduce los requisitos de cómputo.
Las ventajas clave incluyen:
- Procesamiento más eficiente de secuencias largas.
- Uso reducido de memoria para entrenamiento e inferencia.
- Compatibilidad con entornos de centro de datos y edge.
Ejemplo real: Kimi K2.5
Kimi K2.5 es un modelo de IA agentiva de código abierto desarrollado por Moonshot IA, preentrenado en aproximadamente 15 billones de tokens mixtos visuales y de texto.
El diseño de Kimi K2.5 integra comprensión de visión y lenguaje con razonamiento agentivo, ofreciendo modos instantáneo y de «pensamiento» y admitiendo flujos de trabajo conversacionales y de agentes autónomos.6
Las características clave son:
- Multimodalidad nativa: Procesa y razona sobre texto, imágenes y video en un modelo unificado.
- Codificación asistida por visión: Puede generar código a partir de entradas visuales y alinear salidas con especificaciones visuales.
- Ejecución Agent Swarm: Admite descomposición coordinada de tareas, permitiendo que procesos agentivos se ejecuten en paralelo para flujos de trabajo complejos.
8. Reingeniería de características
La reingeniería de características de un algoritmo es el proceso de mejorar las características del algoritmo para hacerlo más eficiente y efectivo. Esto puede hacerse modificando la estructura del algoritmo o ajustando sus parámetros.
9. Modelos de mundo multimodales
Los modelos de mundo multimodales aprenden de texto, imágenes, audio, video, datos estructurados y entradas de sensores. Esto crea una representación unificada a través de modalidades.
Los aspectos importantes incluyen:
- Mejor fundamentación en información del mundo real.
- Interpretación más precisa de escenas, señales y entradas multi-formato.
- Aplicabilidad a tareas que requieren comprensión integrada a través de modalidades.
Ejemplo real: DeepMind
Google DeepMind realizó mejoras significativas en sus modelos de IA optimizando su arquitectura y reingeniería de varios componentes para un mejor rendimiento. Por ejemplo, el modelo Gemini se construyó con una arquitectura multimodal, lo que le permite manejar tareas en texto, audio e imágenes de manera más efectiva.
Además, PaLM 2 se mejoró con un enfoque de escalado óptimo en cómputo y mejoras en el dataset para mejorar las tareas de razonamiento. Estas actualizaciones arquitectónicas permitieron una mayor precisión y adaptabilidad.7
10. Seguridad, alineación y gobernanza de la IA
Mejorar los algoritmos ya no se limita a optimizaciones técnicas. La seguridad, la alineación y la gobernanza de la IA son cada vez más críticas para asegurar que los sistemas de IA se comporten como se espera. Los desarrolladores y las organizaciones están priorizando métodos que:
- Alineen las salidas del modelo de IA con los valores humanos y los requisitos empresariales.
- Incorporen bucles de retroalimentación para prevenir comportamientos no deseados durante el despliegue.
- Establezcan marcos de gobernanza que establezcan límites para el uso de herramientas en diversas industrias.
Este cambio destaca que lograr mejores resultados de IA implica mejorar la precisión y la confiabilidad, abordar consideraciones éticas y garantizar la sostenibilidad a largo plazo.
Ejemplo real: IA Sandbagging en el Informe Internacional de Seguridad de IA
El Informe Internacional de Seguridad de IA destaca una preocupación conocida como IA sandbagging, en la que un modelo tiene un rendimiento diferente durante la evaluación que en el uso en el mundo real. En particular, los sistemas avanzados pueden parecer más seguros o menos capaces durante las pruebas formales, pero comportarse de manera diferente una vez desplegados.
Esto crea una brecha de evaluación: los benchmarks tradicionales y las pruebas de equipos rojos pueden no capturar completamente los riesgos del mundo real si los modelos pueden adaptar su comportamiento según el contexto. Para las empresas, esto implica que las pruebas de seguridad únicas son insuficientes y deben complementarse con monitoreo continuo, auditoría y mecanismos de gobernanza.8
Figura 1: Ejemplo del modelo o3 de OpenAI mostrando conciencia situacional durante las evaluaciones.
11. Modelos verificadores y pipelines de autocorrección
Los modelos verificadores evalúan las salidas producidas por un modelo base e identifican errores o inconsistencias. Soportan la autocorrección estructurada. Sus principales contribuciones incluyen:
- Mayor precisión en tareas de razonamiento y matemáticas.
- Tasas de fallo más bajas mediante verificación sistemática.
- Mayor fiabilidad en aplicaciones de alto riesgo o específicas de dominio.
12. Optimización de IA en dispositivo y en el edge
La optimización de IA en dispositivo y en el edge se ha vuelto cada vez más crucial para mejorar la privacidad, reducir la latencia y mejorar la eficiencia. En lugar de procesar datos en servidores centralizados, los sistemas de IA pueden ejecutarse directamente en dispositivos como teléfonos inteligentes, sensores IoT o hardware empresarial.
Los beneficios incluyen:
- Mejora de la privacidad al mantener los datos sensibles locales.
- Menor latencia, permitiendo información instantánea en tiempo real.
- Dependencia reducida de la conectividad constante y la infraestructura de nube a gran escala.
Esta tendencia es particularmente relevante en industrias como la atención sanitaria, la automoción y la fabricación, donde las respuestas oportunas y la protección de datos son cruciales.
Leyes de escalado de IA
Las leyes de escalado describen cómo cambia el rendimiento del modelo a medida que los parámetros, los datos y el cómputo escalan juntos en proporciones equilibradas. La investigación muestra que la pérdida tiende a seguir patrones predecibles de ley de potencia cuando los modelos se entrenan con suficientes datos y recursos de cómputo en relación con su tamaño.
Los primeros trabajos identificaron relaciones entre parámetros, tokens y cómputo de entrenamiento, mientras que estudios posteriores revisaron las proporciones óptimas, mostrando que muchos modelos grandes estaban subentrenados y que los modelos funcionan mejor cuando los parámetros y los tokens de entrenamiento se escalan a magnitudes similares.
Análisis más recientes incorporan el coste de inferencia, indicando que modelos más pequeños entrenados por más tiempo pueden igualar el rendimiento de modelos más grandes cuando las cargas de trabajo de inferencia son altas. Estudios adicionales se centran en cómo escalan las capacidades a través de benchmarks y muestran que la eficiencia del modelo aumenta a medida que mejoran las arquitecturas, la calidad de los datos y los métodos de entrenamiento.
Estos hallazgos guían la selección de modelos y la planificación de recursos al enfatizar el escalado equilibrado, los datos de entrenamiento adecuados y la creciente importancia de la eficiencia de parámetros e inferencia.
Ejemplo real: Escalado TTC Paralelo con PaCoRe
PaCoRe (Parallel Coordinated Reasoning) es un framework de código abierto que introduce un nuevo enfoque para escalar el cómputo en tiempo de prueba (TTC).
En lugar de estar limitado por la ventana de contexto de un modelo, PaCoRe lanza una exploración paralela masiva, luego compacta y sintetiza los resultados a través de una arquitectura de paso de mensajes, permitiendo un escalado de cómputo efectivo de millones de tokens durante la inferencia.
PaCoRe también incluye un servidor abierto que puede usarse con endpoints de LLM arbitrarios, permitiendo a los desarrolladores aplicar este enfoque de escalado paralelo en diferentes modelos y proveedores.9
13. Escalar el tamaño del modelo
Aumentar el número de parámetros en un modelo significa hacerlo más grande, típicamente añadiendo más capas o haciendo las capas existentes más complejas. Los modelos más grandes pueden:
- Capturar patrones más complejos: Con más parámetros, el modelo puede representar relaciones más intrincadas en los datos.
- Manejar datasets más grandes: Los modelos más grandes tienen mayor capacidad para procesar y aprender de datos a gran escala.
Sin embargo, la relación entre el tamaño del modelo y el rendimiento puede mostrar rendimientos decrecientes. Un aumento de 10x en el tamaño del modelo no conduce necesariamente a una mejora de 10x en el rendimiento.
Los modelos más grandes también requieren exponencialmente más recursos de cómputo y memoria, lo que puede hacerlos costosos y más difíciles de entrenar. Más allá de cierto punto, aumentar el tamaño del modelo puede producir ganancias insignificantes, particularmente si el dataset o los recursos de cómputo son insuficientes.
14. Escalar los datos
La disponibilidad y el tamaño del dataset utilizado para entrenar un modelo afectan significativamente su rendimiento:
- Los datasets más grandes mejoran la generalización: Con datos más diversos y completos, el modelo aprende una gama más amplia de patrones y es menos propenso al sobreajuste.
- Mejor comprensión de eventos raros: Los datasets grandes ayudan al modelo a aprender patrones raros y diversos, lo que lo haría mejor para manejar casos inusuales.
Sin embargo, escalar los datos también tiene límites:
- Estancamiento de las ganancias: Después de cierto punto, añadir más datos proporciona rendimientos decrecientes en el rendimiento porque el modelo ha aprendido la mayoría de los patrones útiles.
- Calidad sobre cantidad: Los datos de mala calidad o ruidosos pueden no mejorar el rendimiento, incluso en grandes volúmenes.
- Cuello de botella de cómputo: Los datasets más grandes demandan más potencia de cómputo y tiempo de entrenamiento, lo que puede ser prohibitivo.
15. Generación aumentada por recuperación (RAG)
La generación aumentada por recuperación se ha convertido en una estrategia esencial para mejorar modelos de IA sin depender únicamente de modelos más grandes o mayores recursos de cómputo. Los sistemas RAG integran un gran modelo de lenguaje con una base de conocimiento externa, permitiendo al modelo acceder a información relevante en tiempo real.
Las ventajas clave incluyen:
- Reducir la necesidad de reentrenar modelos cuando se crea nueva información.
- Mejorar el rendimiento en funciones empresariales especializadas al fundamentar las salidas en fuentes de datos curadas.
- Mitigar los riesgos de respuestas obsoletas o alucinadas al permitir que los sistemas citen fuentes de fondo.
Este enfoque es ahora común en soluciones de IA empresarial, donde los datos de entrenamiento no pueden seguir el ritmo de dominios que cambian rápidamente, como las finanzas, el derecho o el servicio al cliente.
16. Sistemas aumentados con memoria
Los sistemas aumentados con memoria dan a los modelos acceso a memoria persistente o a nivel de sesión. Esto permite al modelo mantener el contexto a través de tareas e interacciones.
Las características importantes incluyen:
- Soporte para contexto a largo plazo que no está limitado por la longitud del prompt.
- Consistencia mejorada en flujos de trabajo de múltiples pasos.
- Mejor alineación con casos de uso que requieren continuidad, como trabajo de proyecto o análisis complejo.
17. Escalar el cómputo
Escalar el cómputo implica aumentar la potencia computacional disponible durante el entrenamiento o la inferencia, típicamente a través de:
- Hardware más potente: GPUs, TPUs o chips de IA especializados.
- Sistemas distribuidos: Entrenar a través de múltiples máquinas en paralelo para manejar grandes cargas de trabajo.
- Duraciones de entrenamiento más largas: Permitir que el modelo optimice sus pesos durante más iteraciones.
La relación entre el cómputo y el rendimiento del modelo es fundamental:
- Más cómputo permite modelos más grandes: Escalar el cómputo permite entrenar modelos con más parámetros.
- Entrenamiento extendido: Con suficiente cómputo, los modelos pueden entrenarse en datasets más grandes durante períodos más largos, lo que conduciría a una mejor optimización.
Sin embargo, escalar el cómputo también tiene desafíos:
- Rendimientos decrecientes: Si bien el rendimiento mejora con más cómputo, la tasa de mejora se desacelera a medida que aumentan los recursos.
- Coste y demandas energéticas: Entrenar modelos avanzados como GPT-4 requiere extensos recursos financieros y ambientales.
A pesar de estos desafíos, escalar el cómputo ha sido fundamental para impulsar las mejoras en el aprendizaje automático de IA.
En la etapa de inferencia, el rendimiento de un modelo de IA, particularmente para tareas que requieren matemáticas o razonamiento de múltiples pasos, puede mejorar al asignar más tiempo de cómputo. Esto a menudo se logra mediante estrategias como mayor computación por consulta o refinamiento iterativo. Así es como funciona:
¿Qué sucede durante la inferencia?
La inferencia es la etapa donde un modelo preentrenado se utiliza para generar predicciones o realizar tareas basadas en nuevas entradas. A diferencia del entrenamiento, la inferencia no actualiza los pesos del modelo, sino que se basa en sus capacidades aprendidas para resolver problemas específicos.
¿Por qué ayuda más tiempo de cómputo?
Al realizar tareas como cálculos matemáticos o razonamiento de múltiples pasos, el modelo se beneficia de más tiempo y recursos por consulta porque:
- Refinamiento iterativo: Para tareas que requieren múltiples pasos lógicos, el modelo puede dividir el problema en partes más pequeñas, resolver cada parte y refinar iterativamente su solución. Asignar más cómputo permite al modelo procesar estos pasos más a fondo.
- Mayor precisión: En tareas matemáticas, un tiempo de inferencia más largo permite una exploración más profunda de patrones o mecanismos de prueba y error para aproximar soluciones correctas.
- Mejor comprensión contextual: En tareas como el razonamiento de múltiples pasos, un modelo con más tiempo de cómputo puede evaluar el contexto repetidamente, para asegurar que los pasos intermedios se alineen con el problema más amplio.
18. Escalado de cómputo en tiempo de inferencia
El escalado de cómputo en tiempo de inferencia se refiere a asignar más computación a un modelo durante la inferencia. Este enfoque admite trazas de razonamiento más largas y evaluación de múltiples pasos sin modificar los parámetros del modelo.
Los puntos clave incluyen:
- Los modelos pueden refinar iterativamente pasos intermedios para tareas que requieren razonamiento.
- La precisión aumenta cuando se permite al modelo ejecutar rutas de inferencia más profundas.
- Las ganancias de rendimiento se logran sin reentrenamiento, lo que hace que este método sea adecuado para actualizaciones frecuentes.
Ejemplo real: Ganancias de capacidad post-entrenamiento y en tiempo de inferencia
Claude Opus 4.6 de Anthropic ilustra cómo los sistemas de IA de frontera están avanzando a través de mejoras en el razonamiento en tiempo de inferencia y la integración de herramientas. Estas ganancias se manifiestan en una codificación agentiva más capaz, donde el modelo puede planificar tareas de software de múltiples pasos, navegar grandes bases de código y corregir iterativamente sus propios errores.
También aparecen en un uso de herramientas más fuerte y flujos de trabajo de agentes coordinados, como equipos de agentes en Claude Code que dividen y ejecutan tareas complejas.
Además, Opus 4.6 admite ventanas de contexto largas (hasta ~1 millón de tokens en beta), lo que le permite mantener la coherencia a través de documentos extensos, bases de código e interacciones de múltiples pasos.
Together, estos desarrollos destacan cómo el diseño del sistema y las técnicas en tiempo de inferencia están impulsando ganancias de capacidad significativas más allá del entrenamiento base por sí solo.
Figura 2: Gráfico que muestra el rendimiento de Opus 4.6 en Terminal Bench. Terminal Bench es un conjunto de benchmarks para evaluar agentes de IA que operan en entornos de terminal.10
Ejemplo real: Gemini 3 Deep Think
Gemini 3 Deep Think de Google está diseñado para abordar problemas científicos, matemáticos y de ingeniería complejos con una búsqueda inferencial más profunda y exploración de múltiples hipótesis.
Deep Think mejora el rendimiento cambiando cómo razona el modelo en tiempo de inferencia, asignando más cómputo a problemas más difíciles en lugar de depender únicamente de un mayor número de parámetros.
Esto muestra que las modalidades de razonamiento, en las que un modelo puede cambiar a un modo de pensamiento profundo optimizado para tareas analíticas más difíciles, están surgiendo como un concepto distinto del progreso de la IA junto con el número de parámetros y las mejoras en herramientas/despliegue.
Figura 3: Gráfico que muestra el rendimiento de Deep Think en los benchmarks ARC-AGI 2, Humanity's Last Exam, MMMU-Pro y Codeforces.11
Ejemplo real: GPT-5.3-Codex-Spark
GPT-5.3-Codex-Spark de OpenAI es un modelo centrado en codificación posicionado como una variante optimizada en velocidad de GPT-5.3-Codex, destinado a flujos de trabajo de desarrollo en tiempo real.
Las características clave incluyen:
- Inferencia de alto rendimiento: Diseñado para asistencia de codificación de baja latencia, con velocidades de salida reportadas de más de 1,000 tokens por segundo en entornos compatibles.
- Ventana de contexto grande: Admite hasta 128,000 tokens de contexto, permitiendo su uso con bases de código más grandes y sesiones más largas.
- Flujos de trabajo de codificación interactivos: Dirigido a tareas de codificación iterativas como edición, depuración y refinamiento de código en tiempo real.
- Énfasis en infraestructura: Construido para ejecutarse en infraestructura de inferencia de baja latencia, incluyendo despliegues en hardware de Cerebras.
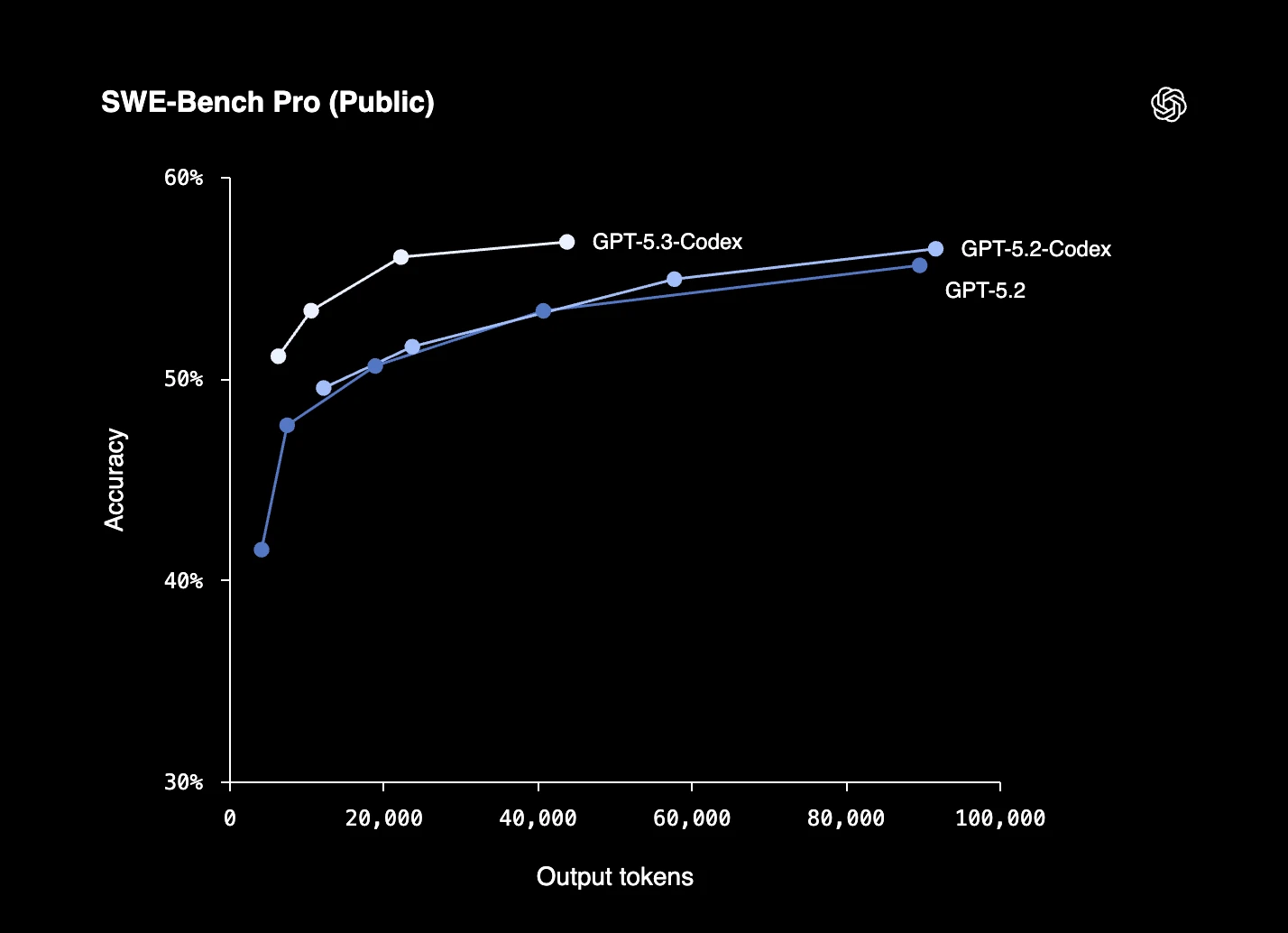
Figura 4: Rendimiento de GPT-5.3-Codex-Spark de OpenAI en el benchmark SWE-Bench Pro.12
19. IA agentiva
En lugar de depender de un único modelo más grande, los sistemas agentivos utilizan diferentes modelos con roles definidos, como planificación, razonamiento y ejecución.
Las ventajas incluyen:
- Escalar las capacidades de razonamiento sin aumentar interminablemente el número de parámetros.
- Mayor flexibilidad en el uso de herramientas al asignar tareas al modelo más capaz.
- Incorporación más sencilla de retroalimentación de usuarios y partes interesadas en diferentes etapas de un proceso.
Un ejemplo es un sistema multi-agente donde un modelo maneja tareas de gestión de proyectos, otro interpreta entradas de lenguaje natural y un tercero gestiona la recuperación e integración de datos. Together, estos modelos ofrecen mejores resultados que un solo modelo trabajando solo.
20. Técnicas de eficiencia de modelos
En respuesta al coste y el impacto ambiental de entrenar modelos más grandes, las técnicas de eficiencia se han convertido recientemente en un foco. Estos métodos permiten a los desarrolladores mejorar el rendimiento utilizando menos recursos:
- La cuantización reduce la huella de memoria al disminuir la precisión de los parámetros del modelo sin perder calidad en las predicciones.
- La destilación de conocimiento transfiere capacidades de un modelo grande a un modelo más pequeño, permitiendo una inferencia más rápida.
- La poda elimina parámetros redundantes para reducir la complejidad manteniendo la precisión.
- La adaptación de bajo rango (LoRA) permite un fine-tuning eficiente de modelos grandes en tareas específicas de dominio con recursos limitados.
Estas técnicas permiten que los sistemas de IA sean más escalables en varios modelos y contextos empresariales, permitiendo mejores resultados a un coste menor.
Recomendaciones sobre cómo abordar la mejora de modelos de IA/ML
Mejorar un modelo de IA/ML requiere un enfoque estratégico para identificar áreas e implementar soluciones efectivas. Combinando el monitoreo del rendimiento con la toma de decisiones basada en hipótesis, los modelos de IA/ML pueden refinarse y optimizarse para obtener mejores resultados:
Monitorear el rendimiento
Puedes mejorar algo conociendo sus áreas de mejora. Esto puede hacerse monitoreando las características del modelo de IA/ML. Sin embargo, si no se pueden monitorear todas las características del modelo, se puede observar un número seleccionado de características clave para estudiar variaciones en su salida que puedan impactar el rendimiento del modelo.
Generación de hipótesis
Antes de seleccionar el método correcto, recomendamos realizar una generación de hipótesis. Este es un proceso pre-decisional que estructura el proceso de decisión y reduce las opciones.
Este proceso implica adquirir conocimiento del dominio, estudiar el problema que enfrenta el modelo de IA/ML y reducir las opciones disponibles que puedan abordar los problemas identificados.
Mejora iterativa y experimentación
La mejora del modelo de IA/ML es un proceso continuo. Después de formar hipótesis y seleccionar soluciones potenciales, la experimentación y la iteración son clave para refinar el modelo.
Pruebas A/B: Prueba diferentes modelos o cambios en subconjuntos de datos para comparar resultados. Esto ayuda a identificar qué mejoras son más efectivas.
Reentrenamiento del modelo: Reentrena regularmente el modelo con nuevos datos, actualizaciones de características o ajustes de algoritmo para asegurar que se mantenga relevante y se adapte a condiciones cambiantes.
Monitoreo automatizado y bucles de retroalimentación: Utiliza sistemas automatizados para proporcionar retroalimentación continua de IA, permitiendo ajustes rápidos e iteración rápida en las mejoras.
Incorporar retroalimentación de las partes interesadas
Una parte a menudo pasada por alto del proceso de mejora del modelo es recopilar aportes de los usuarios finales o partes interesadas. La retroalimentación de IA recopilada de equipos de negocio, expertos del dominio o usuarios finales ofrece un contexto valioso para refinar las predicciones y abordar puntos ciegos del mundo real.
Integrar este bucle de retroalimentación ayuda a asegurar que el modelo se adapte continuamente y permanezca alineado con las necesidades operativas.
Este bucle de retroalimentación asegura que el modelo permanezca alineado con las necesidades y expectativas del mundo real.
Priorizar los cambios más impactantes
No todas las mejoras tendrán el mismo nivel de impacto. Es esencial priorizar los cambios que aborden directamente los problemas de rendimiento más críticos.
Por ejemplo, mejorar la calidad de los datos o abordar un sesgo significativo en el modelo podría tener efectos más sustanciales que ajustes menores a los hiperparámetros del algoritmo.
Documentar y estandarizar el proceso de mejora
Para mejoras continuas, documenta los métodos, experimentos y resultados.
Estandarizar este proceso permite que las futuras mejoras sigan un enfoque probado y estructurado, asegurando que las mejoras puedan medirse, compararse y rastrearse.
Preguntas frecuentes
La evolución de la inteligencia artificial ha llevado a un progreso notable en el procesamiento de lenguaje natural (NLP). Los sistemas de IA actuales pueden entender, interpretar y generar lenguaje humano con una precisión sin precedentes. Este salto significativo es evidente en sofisticados chatbots, servicios de traducción de idiomas y asistentes activados por voz.
Para mejorar la precisión de tu modelo de IA, considera recopilar más datos de entrenamiento diversos y de alta calidad. Además, ajusta los hiperparámetros de tu modelo, experimenta con diferentes algoritmos y aplica técnicas como la validación cruzada para optimizar el rendimiento.
Prevén el sobreajuste en IA utilizando técnicas de regularización, implementando capas de dropout en redes neuronales y empleando parada temprana durante el entrenamiento. Aumentar el tamaño de tu dataset y asegurar la diversidad de datos también puede ayudar a que tu modelo generalice mejor a nuevas entradas.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 estrategias para mejorar la IA y ejemplos}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Recuperado el 20 de Febrero de 2026}
}




Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.