AGI/Tekillik: 10,000 Tahmin Analiz Edildi
Yapay genel zeka (AGI), bir yapay zeka sisteminin tüm görevlerde insan bilişsel yetenekleriyle eşleşmesidir. AGI zaman çizelgesi hakkında 10,000 yapay zeka araştırmacısı, önde gelen girişimci ve topluluk tahminini analiz ettik:
AGI/tekillik gerçekleşecek mi? Çoğu yapay zeka uzmanına göre AGI kaçınılmazdır.
AGI'ye ne zaman ulaşacağız? 2020'lerin sonu ile 2030'ların başı arasında. ChatGPT'nin piyasaya sürülmesinden sonra AGI zaman çizelgesi kısaldı.
Yapay Genel Zeka zaman çizelgesi
Yukarıdaki zaman çizelgesi, 10 ankette 6,000'den fazla katılımcıdan, 18 yapay zeka araştırmacısının yanıtlarından ve Manifold, Kalshi ve Metaculus tahmin piyasalarından elde edilen topluluk içgörülerinden toplanan verilere dayanarak tekilliğin beklenen yılını göstermektedir.
Yukarıda görebileceğiniz gibi, anket katılımcıları giderek tekilliğin daha önce gerçekleşmesini beklemektedir. Bu grafiği oluşturmak için kullandığımız yöntemleri öğrenin.
Tahmin piyasalarından AGI tahminleri
Tahmin piyasaları ve topluluk içgörüsü tahminleri için şunları kullandık:
Katılımcıların kâr veya itibar için gelecekteki olayların olasılığı ve zamanlaması üzerine işlem yaptığı çevrimiçi tahmin piyasaları olan Manifold, Kalshi ve Metaculus'tan 3,900 tahmin. Ayrıca bu tahmin piyasalarından elde edilen ortalama tahmin tarihini de dahil ettik.
AGI hakkında diğer önemli sorular
AGI konusunda mevcut durumumuz nedir?
Dar yapay zeka belirli görevlerde insanları geçse de, zeki bir makine henüz mevcut değildir. Bazı araştırmacılar, büyük dil modellerinin ortaya çıkan genelci yetenekler sergilediğini belirtmektedir.1 AGI kıyaslama ölçütümüze göre, makineler otonom olarak ekonomik değer üretmekten henüz çok uzaktır.
AGI'ye nasıl ulaşabiliriz?
Ya transformer'lar gibi mevcut mimarilere daha fazla hesaplama gücü ve veri sağlayarak ya da yeni yaklaşımlar icat ederek. AGI'ye ulaşma veya onu doğrulama yöntemi konusunda henüz bilimsel bir fikir birliği yoktur.
Aşağıda bu zaman çizelgesini oluşturan tahminlerin bir özetini görebilir veya tam tabloyu inceleyebilirsiniz.
Yapay zeka araştırmacılarının katıldığı büyük anketlerin sonuçları
10 ankette 6,000'den fazla yapay zeka araştırmacısı ve uzmanının katıldığı, AGI/tekilliğin ne zaman gerçekleşebileceğini tahmin ettikleri sonuçları inceledik.
Tahminler değişiklik gösterse de, çoğu anket AGI'ye ulaşma olasılığının 50% olduğunu 2040 ile 2061 arasında göstermekte, bazıları süper zekanın birkaç on yıl içinde takip edebileceğini tahmin etmektedir.
Yapay Zekada İlerleme Üzerine Uzman Anketi
Ekim 2023'te, AI Impacts 2,778 yapay zeka araştırmacısına AGI'ye ne zaman ulaşılabileceğini sordu. Bu anket, 2022 anketiyle neredeyse aynı soruları içeriyordu. Yapay Zekada İlerleme Üzerine Uzman Anketi'nin sonuçlarına göre, üst düzey makine zekasının 2040 yılına kadar gerçekleşeceği tahmin ediliyor.2
Yapay Zekada İlerleme Üzerine Uzman Anketi
Anket, 2021 NIPS ve ICML konferanslarında yayın yapmış 738 uzmanla gerçekleştirildi. Yapay Zekada İlerleme Üzerine Uzman Anketi'nin sonuçlarına göre, uzmanlar üst düzey makine zekasının 2059 yılına kadar gerçekleşme olasılığının 50% olduğunu tahmin ediyor.3
Uzmanlar ayrıca donanım maliyeti, algoritmik ilerleme ve eğitim setleri üzerindeki çalışmaların yapay zeka ilerlemesindeki en büyük faktörler olacağını öngördü.
Yapay Zeka İlerleme Tahmini Anketi
Baobao Zhang 2019'da 296 yapay zeka uzmanına, makinelerin ekonomik olarak ilgili görevlerin 90%'ından fazlasını yerine getirmede medyan insan çalışanı ne zaman geçeceğini tahmin etmelerini sordu. Yapay Zeka İlerleme Tahmini Anketi'nin sonuçlarına göre, katılımcıların yarısı bunun 2060 yılından önce gerçekleşeceğini tahmin etti.4
AGI Zamanlaması Üzerine Yapay Zeka Uzmanları Anketi
2019'daki AGI Zamanlaması Üzerine Yapay Zeka Uzmanları Anketi'nden5 tahminler şöyledir:
- Katılımcıların 45%'i 2060 yılından önce bir tarih öngörüyor.
- Tüm katılımcıların 34%'ü 2060 yılından sonra bir tarih öngördü.
- Katılımcıların 21%'i tekilliğin asla gerçekleşmeyeceğini öngördü.
Yapay Zekanın İş Gücü Yer Değiştirmesi Üzerindeki Potansiyel Etkisi Anketi
Ross Gruetzemacher 2018'de 165 yapay zeka uzmanına, yapay zekanın iş gücü yer değiştirmesi üzerindeki potansiyel etkisini değerlendirmek için anket yaptı. Uzmanlardan, yapay zeka sistemlerinin, insanların şu anda ücret aldığı görevlerin 99%'unu, ortalama bir insanın seviyesine eşit veya onu aşan bir düzeyde yerine getirebileceği zamanı tahmin etmeleri istendi.
Yapay Zekanın İş Gücü Yer Değiştirmesi Üzerindeki Potansiyel Etkisi anketinin sonuçlarına göre, katılımcıların yarısı bu kilometre taşına 2068 yılından önce ulaşılacağını öngörürken, 75%'i önümüzdeki 100 yıl içinde gerçekleşeceğini tahmin etti.6
NIPS ve ICML konferanslarındaki yapay zeka uzmanları anketi
Mayıs 2017'de, 2015 NIPS ve ICML konferanslarında yayın yapmış 352 yapay zeka uzmanıyla anket yapıldı.7
NIPS ve ICML konferanslarındaki anket sonuçlarına göre, uzmanlar AGI'nin 2060 yılına kadar gerçekleşme olasılığını 50% olarak tahmin ediyor. Bununla birlikte, coğrafyaya dayalı önemli bir görüş farkı var:
- Asyalı katılımcılar AGI'yi 30 yıl içinde bekliyor,
- Kuzey Amerikalılar 74 yıl içinde bekliyor.
2030 yılına kadar otomatikleştirilmesi beklenen bazı önemli iş fonksiyonları arasında çağrı merkezi temsilcileri, kamyon şoförlüğü ve perakende satış yer alıyor.
Yapay Zekada Gelecekteki İlerleme anketi
Avrupa Bilişsel Sistemler Derneği başkanı Vincent C. Muller ve Oxford Üniversitesi'nden, süper zeka ve yapay genel zeka (AGI) üzerine 200'den fazla makale yayınlamış olan Nick Bostrom, 2012 ve 2013 yıllarında Yapay Zekada Gelecekteki İlerleme anketini gerçekleştirdi. 550 katılımcı şu soruyu yanıtladı: AGI'nin gerçekleşmesi ne zaman muhtemeldir?8
Yapay Zekada Gelecekteki İlerleme anketinin sonuçlarına göre:
- Ankete katılan yapay zeka uzmanları, AGI'nin muhtemelen (50%'den fazla şans) 2040 ile 2050 arasında ortaya çıkacağını ve 2075 yılına kadar ortaya çıkma olasılığının yüksek (90% şans) olduğunu tahmin ediyor.
- AGI'ye ulaşıldığında, çoğu uzman süper zekaya ilerlemenin nispeten hızlı olacağını, zaman aralığının 2 yıl kadar kısa (düşük ihtimal, 10% olasılık) ile yaklaşık 30 yıl (yüksek ihtimal, 75%) arasında değiştiğini belirtiyor.
AGI-09 konferansına katılan yapay zeka uzmanlarıyla anket
2009'daki AGI-09 konferansına katılan 21 yapay zeka uzmanıyla yapılan anket sonuçlarına göre, AGI 2050 civarında ve muhtemelen daha erken gerçekleşecek.9 Belirli yapay zeka başarılarına ilişkin tahminlerini aşağıda görebilirsiniz: Turing testini geçme, üçüncü sınıfı geçme, Nobel değerinde bilimsel atılımlar gerçekleştirme ve insanüstü zekaya ulaşma.
Şekil 1: Yapay Genel Zeka 2009 (AGI-09) konferansı katılımcılarına dağıtılan anketin sonuçları.
Topluluk içgörüleri
Ayrıca Samotsvety Forecasting ve Metaculus Topluluğu'nun AGI tahminlerini ve Manifold, Kalshi ve Polymarket'tan tahmin piyasası sonuçlarını değerlendirdik:
Samotsvety Forecasting
Samotsvety Forecasting, özellikle jeopolitik, teknoloji ve küresel riskler alanında, yapılandırılmış akıl yürütme ve nicel yöntemler kullanarak gerçek dünya olayları hakkında olasılıksal tahminler yapan bir tahminci ekibidir. Büyük tahmin platformlarında ve turnuvalarında (örn. INFER/CSET-Foretell), doğruluklarının Brier skoru gibi resmi puanlama ölçütleriyle ölçüldüğü güçlü bir rekabetçi geçmiş performans sergilemektedirler.10
Ocak 2026'da ekip, 8 tahminciyle AGI tahminlerini güncelledi.11 Toplu sonuçlar şöyledir:
- 2026'da AGI'ye ulaşma olasılığı 10%
- 2041 yılına kadar AGI'ye ulaşma olasılığı 50%
- 2164 yılına kadar AGI'ye ulaşma olasılığı 90%
2022'deki daha eski bir tahminde ekip, 20 yıl içinde (yaklaşık 2042'ye kadar) AGI olasılığını 32% ve 2100 yılına kadar 73% olarak tahmin etmişti, her ikisi de mevcut projeksiyonlarından daha düşüktü.12
Manifold Piyasası
Temmuz 2026 itibarıyla, 1,100'den fazla Manifold Piyasası katılımcısı, bir yapay zekanın "yüksek kaliteli, çekişmeli bir Turing testini" ilk kez geçeceği yılı 2035 olarak tahmin etti.13
Kalshi Tahmin Piyasası
Temmuz 2026 itibarıyla, Kalshi tahmin piyasası katılımcıları OpenAI'nin 2030 yılına kadar AGI'ye ulaşma olasılığının 40% olduğunu belirtiyor.14
Polymarket
Temmuz 2026'daki Polymarket tahmin sonuçları, OpenAI'nin 2027 yılına kadar AGI'ye ulaşma olasılığının 10% olduğunu gösterdi.15
Metaculus Topluluk Tahminleri
Temmuz 2026 itibarıyla:
- 1,800 katılımcı "İlk zayıf genel yapay zeka sistemi ne zaman tasarlanacak, test edilecek ve kamuya duyurulacak?" sorusunu yanıtladı ve tahmin 2028.16
- 180 katılımcı "Bir yapay zeka ilk kez uzun, bilgilendirilmiş, çekişmeli bir Turing testini ne zaman geçecek?" sorusunu yanıtladı ve tahminleri 2029.17
- 1,900 katılımcı "İlk genel yapay zeka sistemi ne zaman tasarlanacak, test edilecek ve kamuya duyurulacak?" sorusunu yanıtladı ve tahminleri 2032.18
2022'de, 81 katılımcı "En iyi tahminciler ilk Yapay Genel Zekanın ne zaman geliştirilip gösterilmesini bekleyecek?" sorusunu yanıtladı ve tahminleri 2035 oldu.19
Yapay zeka girişimcilerinden ve bireysel araştırmacılardan içgörüler
Yapay zeka girişimcileri de tekilliğe ne zaman ulaşacağımıza dair tahminler yapıyor ve araştırmacılardan daha iyimserler. Bu beklenen bir durumdur çünkü yapay zekaya artan ilgiden fayda sağlıyorlar.
Hızı ve gelişim yolu konusunda görüşleri farklılık gösteriyor. Anthropic'ten Amodei, hızlı kendi kendini güçlendiren ilerleme nedeniyle AGI'nin yakın vadede geleceğini beklerken, DeepMind'dan Hassabis bunu makul ancak ihtiyatlı buluyor ve bilimsel yaratıcılık ve otonom kendini geliştirme konusundaki çözülmemiş zorluklara işaret ediyor.
İşte en önde gelen 15 yapay zeka girişimcisi ve araştırmacısının tahminleri:
- DeepMind Technologies'ın kurucu ortağı Shane Legg, minimal AGI'yi, ortalama bir insanın yapabileceği tüm bilişsel görevleri, bir insana aynı görev verildiğinde bizi şaşırtacak şekilde başarısız olmadan güvenilir bir şekilde yerine getirebilen yapay bir ajan olarak tanımlıyor. Ocak 2026'daki tahmini, Minimal AGI'nin 2028 yılına kadar gerçekleşme olasılığının 50% olduğu yönünde.
- Legg'e göre, minimal AGI'ye ulaşmak, büyük bilimsel atılımlar veya sanatsal başarılar gibi insan zekasının en yüksek biçimlerini tam olarak anladığımız veya yeniden üretebileceğimiz anlamına gelmez. Tam AGI, yapay zeka tüm insan bilişi yelpazesiyle eşleşebildiğinde elde edilmiş olacaktır.20
- Anthropic CEO'su Dario Amodei, 2026 Davos Dünya Ekonomik Forumu'nda AGI düzeyindeki sistemlerin yakın vadede yaklaştığına dair güçlü bir güven ifade etti. AGI'nin muhtemelen birkaç yıl içinde (2027), muhtemelen yaygın olarak beklenenden daha erken gerçekleşeceğini belirtti.
- Kodlama ve yapay zeka araştırma otomasyonundaki hızlı ilerlemelerin merkezi olduğunu, yapay zeka sistemlerinin çoğu yazılım mühendisliği görevini uçtan uca ele almasını ve geri bildirim döngüleri aracılığıyla kendi gelişimlerini hızlandırmasını sağladığını savunuyor.
- Donanım kullanılabilirliği ve eğitim süresi gibi kısıtlamaları kabul etmesine rağmen, daha uzun bir zaman çizelgesini olası görmüyor ve bu döngüler olgunlaştığında hızlı bir ivmelenme bekliyor.21
- 2026'daki aynı etkinlikte, DeepMind'ın kurucusu Demis Hassabis daha ihtiyatlı bir bakış açısı sergileyerek, on yılın sonuna kadar (2030) AGI'ye ulaşma şansının kabaca 50% olduğu tahminini yineledi.
- Hassabis, kodlama ve matematik gibi doğrulanabilir alanlarda ilerlemenin hızlı olduğunu kabul ediyor, ancak bilimsel keşif ve yaratıcı akıl yürütmenin daha zor olmaya devam ettiğini vurguluyor.
- Yeni sorular ve teoriler üretmedeki çözülmemiş sınırlamalara dikkat çekiyor ve özellikle karmaşık, gerçek dünya alanlarında tamamen otonom kendini geliştirme konusunda belirsizlik ifade ediyor, bunun AGI zaman çizelgelerini daha az kesin hale getirdiğine inanıyor.
- Yapay zekanın akıl yürütme, programlama ve matematikteki ilerlemesini birleştiren, Google'ın eski CEO'su Eric Schmidt, Yapay Genel Zekaya doğru 3–5 yıl içinde ilerlediğimizi belirtiyor (Nisan 2025'te belirtildiği gibi).22
- Elon Musk, en zeki insanlardan daha zeki bir yapay zekanın 2026 yılına kadar geliştirilmesini bekliyor.23
- Şubat 2025'te, girişimci ve yatırımcı Masayoshi Son bunu 2-3 yıl içinde (yani 2027 veya 2028) öngördü.
- Mart 2024'te, Nvidia CEO'su Jensen Huang, beş yıl içinde yapay zekanın herhangi bir testte insan performansıyla eşleşeceğini veya onu aşacağını öngördü: 2029.24
- Bilgisayar bilimcisi, girişimci ve yazar Louis Rosenberg, 2030 yılına kadar.
- Bilgisayar bilimcisi, girişimci ve The Singularity Is Near dahil 5 ulusal çok satan kitabın yazarı Ray Kurzweil: Daha önce 2045, 2024'te 2032.25
- 2023'te Hinton, AGI'nin 5-20 yıl sürebileceğini belirtti.26
- OpenAI CEO'su Sam Altman, 2035 yılına kadar. 2024'teki "The Intelligence Age" başlıklı blog yazısında "birkaç bin gün"den bahsetti.
- Bir yapay zeka araştırmacısı olan Ajeya Cotra, eğitim hesaplamasının büyümesini analiz etti ve insan benzeri yeteneklere sahip yapay zekanın 2040 yılına kadar ortaya çıkma olasılığını 50% olarak tahmin etti.27
- MIT profesörü ve 1972'den 1997'ye kadar MIT Yapay Zeka Laboratuvarı direktörü olan Patrick Winston, 2040'tan bahsetti ve bunun gerçekleşecek bir tarih olmasına rağmen tahmin etmenin zor olduğunu vurguladı.
- Yapay zeka şirketi NNAISENSE'in kurucu ortağı ve İsviçre yapay zeka laboratuvarı IDSIA'nın direktörü Jürgen Schmidhuber, 2050 yılına kadar.28
AGI hakkında diğer yorumlar ve gelişmeler
AAAI Yapay Zeka Araştırmasının Geleceği Başkanlık Paneli
Çoğunlukla akademiden (67%) ve Kuzey Amerika'dan (53%) 475 katılımcıya yapay zekadaki ilerleme hakkında sorular soruldu. AAAI 2025 Yapay Zeka Araştırmasının Geleceği Başkanlık Paneli anketi AGI için bir zaman çizelgesi sormamış olsa da, katılımcıların 76%'sı mevcut yapay zeka yaklaşımlarını ölçeklendirmenin AGI'ye yol açmasının olası olmadığını paylaştı.29
OpenAI robotik hedeflerini genişletiyor
OpenAI, yapay genel zekayı ilerletme hedefinin bir parçası olarak robotiğe odaklanmasını artırıyor. Şirket, insansı robot sistemlerinde uzmanlar işe alıyor ve robotların fiziksel dünyada bağımsız olarak öğrenmesine ve hareket etmesine yardımcı olacak algoritmalar tasarlamak için bir ekip oluşturuyor.
Bu, OpenAI'nin dil ve görüntü modellerine olan önceki odağından bir kaymayı işaret ediyor. Şirket şimdi gelişmiş akıl yürütmeyi fiziksel etkileşimle birleştirmeyi hedefliyor, bu da robotiği AGI'yi test etme ve elde etme yolunda önemli bir adım olarak gördüğünü gösteriyor.
Bağlam ve çıkarımlar
2020 civarında ilk robotik ekibini kapattıktan sonra, OpenAI bu alanda aktif geliştirmeye geri dönüyor. Son işe alımlar ve potansiyel ortaklıklar, gerçek dünyada öğrenme ve manipülasyon yeteneğine sahip robotlar inşa etme yönünde yenilenen bir çabaya işaret ediyor.
Büyük ölçekli yapay zeka modellerini duyusal verilerle birleştirerek, OpenAI dijital ortamların dışında akıl yürütebilen ve çalışabilen sistemler yaratmayı amaçlıyor. İnsansı robotik uzmanlarının işe alınması ayrıca otomasyonun ötesine geçen ve insanların yanında güvenle çalışabilen robotlara yönelik uzun vadeli hedefleri gösteriyor.30
Microsoft'un GPT-4 ile erken deneyler raporu
Microsoft Research, 2023 yılında OpenAI'nin GPT-4'ünün erken bir sürümünü inceledi. Rapor, modelin önceki yapay zeka modellerinden daha fazla genel zeka gösterdiğini, matematik, kodlama ve hukuk gibi alanlarda insan düzeyinde performans sergilediğini iddia etti. Bu, GPT-4'ün yapay genel zekanın bir ön biçimi olup olmadığı konusunda tartışma başlattı. 31
MIT tarafından yapay genel zekaya giden yol raporu
Ağustos 2025'teki "Yapay genel zekaya giden yol" raporu, erken AGI benzeri sistemlerin 2026 ve 2028 arasında ortaya çıkmaya başlayabileceğini, belirli alanlarda insan düzeyinde akıl yürütme, metin, ses ve fiziksel arayüzler arasında çok modlu yetenekler ve sınırlı hedef odaklı otonomi gösterebileceğini öngörüyor.
Rapor, toplu tahminleri birleştiriyor ve bilgi transferi ve geniş akıl yürütme gibi birkaç genelleştirilmiş kilometre taşının 2028 yılına kadar elde edilme olasılığının 50% olduğunu öne sürüyor.
Daha uzun vadeli projeksiyonlar, hesaplama verimliliği, algoritmik atılımlar ve otonom öğrenmedeki ilerlemelere bağlı olarak, makinelerin ekonomik olarak değerli tüm görevlerde insan performansını yaklaşık 2047 yılına kadar aşabileceğini tahmin ediyor.32
AI Frontiers AGI olasılıkları hakkında
Yapay zeka tartışmaları ve diyalogları için bir platform olan AI Frontiers'tan Adam Khoja ve Laura Hiscott, nicel AGI tanımlarını kullanarak 2028 yılına kadar AGI'ye ulaşma olasılığını 50% ve 2030 yılına kadar 80% olasılık tahmin ediyor.33
Khoja ve Hiscott, Khoja, Dan Hendrycks ve ortak yazarları tarafından geliştirilen bir tanımı kullanarak yapay genel zekaya doğru ilerlemeyi değerlendiriyor.34 Onların çerçevesi on bilişsel yeteneği ölçüyor ve GPT-4'e 27% ve GPT-5'e 57% puan veriyor. Bu, mevcut modellerin tanımlanan AGI eşiğinin yaklaşık yarısında olduğunu gösteriyor.
Khoja ve Hiscott, AGI zaman çizelgeleri hakkındaki geleneksel tartışmaların tutarsız tanımlara dayandıkları için kesinlikten yoksun olduğunu savunuyor. Standartlaştırılmış çerçeveleri, mevcut modellerdeki belirli güçlü ve zayıf yönleri belirleyerek netlik yaratmayı amaçlıyor. Okuma, yazma, matematik ve genel bilginin insan temel çizgilerini karşıladığını veya aştığını ve artık sınırlayıcı faktörler olmadığını belirtiyorlar.
Yazarlar, görsel akıl yürütme, sezgisel fizik, işitsel işleme, algıya bağlı hız ve görsel ve işitsel çalışma belleğindeki kalan boşlukları vurguluyor. SPACE ve MindCube gibi kıyaslama ölçütlerinde hızlı iyileşme rapor ediyor ve bu boşlukların muhtemelen sürekli artan araştırmalarla giderilebileceğini öne sürüyorlar. Ayrıca halüsinasyonların bir endişe kaynağı olmaya devam ettiğini ancak önde gelen modeller arasındaki performans farklılıkları göz önüne alındığında ele alınabilir olduğunu gözlemliyorlar.
Khoja, Hiscott ve Hendrycks'e göre, kalan en önemli engel sürekli öğrenme ve uzun süreli bellek depolamadır. Mevcut sistemler oturumlar arasında bilgi tutamaz ve bu sınırlamayı çözmek en az bir anlamlı atılım gerektirecektir. Ancak yazarlar, büyük yapay zeka laboratuvarlarının artık bu alana öncelik verdiğini vurguluyor.
Yapay zeka tahminlerinde geçmişteki aşırı iyimserlikten ders çıkarmak
Yapay zeka araştırmacılarının daha önce aşırı iyimser olduğunu unutmayın. Örnekler şunları içerir:
- Geoff Hinton 2016'da 2021 veya 2026'ya kadar radyologlara ihtiyacımız olmayacağını iddia etti. Şimdiye kadar radyoloji tamamen otomatikleştirilmedi ve hastaneler binlerce radyologa ihtiyaç duyuyor.35
- Yapay zeka öncüsü Herbert A. Simon 1965'te: "makineler yirmi yıl içinde bir insanın yapabileceği her işi yapabilecek kapasitede olacak."36
- Japonya'nın Beşinci Nesil Bilgisayarı 1980'de "gündelik sohbetler yürütme" gibi hedeflerle on yıllık bir zaman çizelgesine sahipti.37
Bu tarihsel deneyim, çoğu mevcut bilim insanının AGI'yi 10-20 yıl gibi cesur zaman dilimlerinde tahmin etmekten kaçınmasına katkıda bulundu, ancak bu durum üretken yapay zekanın yükselişiyle değişti.
Tekilliğin ne olduğunu anlayın
Yapay zeka bizi korkutuyor ve meraklandırıyor. Neredeyse her hafta, haberlerde geliştiricilerin yarattıkları şeyden korkması veya çok zeki hale geldikleri için botları kapatması gibi yeni bir yapay zeka korkusu var.38
Bu mitlerin çoğu, yapay zeka ve GenAI alanlarının dışındaki kişiler tarafından yanlış yorumlanan araştırmalardan kaynaklanmaktadır. Bazı paydaşlar, daha fazla düzenlemeden kâr elde edebilecekleri veya onlara daha fazla dikkat çekebileceği için yapay zekadan korktuklarını iddia etmektedir.
Yapay zeka hakkındaki en büyük korku, makine zekasında hızlı bir artış getirmesi beklenen bir olay olan tekilliktir (Yapay Genel Zeka veya AGI olarak da adlandırılır). Bu, bir sistemin insan düzeyinde düşünmeyi insanüstü hız ve hızla erişilebilen, neredeyse mükemmel bellek ile birleştirmesiyle beklenir. Bazı uzmanlara göre tekillik aynı zamanda makine bilincini de ifade eder.
Böyle bir makine kendini geliştirebilir ve insan yeteneklerini aşabilir. Yapay zeka bir bilgisayar bilimi araştırma konusu olmadan önce bile, Asimov gibi bilim kurgu yazarları bu konuda endişeliydi. Zeki makinelerin iyiliğini sağlamak için mekanizmalar (yani Asimov'un Robot Yasaları) tasarlıyorlardı, bu bugün daha yaygın olarak uyum araştırması olarak adlandırılıyor.
Uzmanlar neden AGI'nin kaçınılmaz olduğuna inanıyor: Temel argümanlar ve kanıtlar
AGI'ye ulaşmak çılgınca bir tahmin gibi geliyor, ancak insan zekasının sabit ve makine zekasının büyüyor olduğunu düşündüğünüzde oldukça makul bir hedef gibi görünüyor. Zekalarında bir tür sert sınır olmadığı sürece makinelerin bizi geçmesi an meselesidir. Henüz böyle bir sınırla karşılaşmadık.
İnsan zekası, bilişsel yeteneklerimizi bir şekilde makinelerle birleştirmezsek sabittir. Elon Musk'ın neural lace girişimi bunu yapmayı hedefliyor, ancak beyin-bilgisayar arayüzleri üzerine araştırmalar erken aşamalardadır.39
Makine zekası algoritmalara, işlem gücüne ve verilere bağlıdır.
- İşlem gücü, Ar-Ge ve veri merkezlerine yatırım aktıkça katlanarak büyümektedir.
- Şimdiye kadar, makinelere işlem güçlerini ve belleklerini etkili bir şekilde kullanmaları için gerekli algoritmaları sağlamada iyiydik.
- Son olarak, işletmeler ve bireyler artan bir hızda dijital veri oluşturuyor. Sentetik veri modelleri bozabilir veya modelleri güçlendirebilir. Onları bozsa bile, veri küratörlüğü sayesinde bu çözülebilir bir sorundur.
Son başarılar
Opus 4.6
Şubat 2026'da, Claude 1M bağlam penceresi ve etkileyici kıyaslama sonuçlarıyla Opus 4.6'yı yayınladı.
Anthropic ayrıca, modellerin belirli alanlarda gezinmesine yardımcı olan markdown dosyaları olan Claude legal gibi eklentiler yayınlayarak kullanım durumlarına odaklanıyor. Bu, Claude'a küçük bir ekleme olmasına rağmen, SaaS ve hukuk yazılımları da dahil olmak üzere borsada bir satış dalgasını tetikledi.40
Gemini Derin Düşünme
Başka bir örnek, DeepMind'ın Gemini derin düşünme modudur ve 2025 Uluslararası Matematik Olimpiyatı'nda altın madalya performansı elde ederek yapay zekanın karmaşık problemler üzerinde akıl yürütme yeteneğinde önemli bir adım atmıştır.
Tamamen doğal dilde çalışan Gemini, resmi sembolik araçlara dayanmadan, resmi 4.5 saatlik yarışma penceresi içinde altı problemden beşini çözdü ve net, insan tarafından okunabilir kanıtlar üretti.
Yetenekleri birkaç yenilikten kaynaklanıyor: Derin Düşünme modu çözüm yollarının paralel keşfini sağlar, eğitim uzman düzeyinde matematiksel kanıtları içerir ve pekiştirmeli öğrenme stratejik yaklaşımını rafine eder.
Bu ilerleme, gelişmiş yapay zekanın artık bir zamanlar en iyi insan problem çözücülerine ayrılmış bir düzeyde sofistike, yorumlanabilir akıl yürütme yapabileceğini göstermektedir.41
Opencrawl
Opencrawl, LLM'leri ajanlara dönüştürmek için açık kaynaklı bir projedir. GitHub'daki en popüler projelerden biri haline geldi ve opencrawl ekosistemini başlattı.
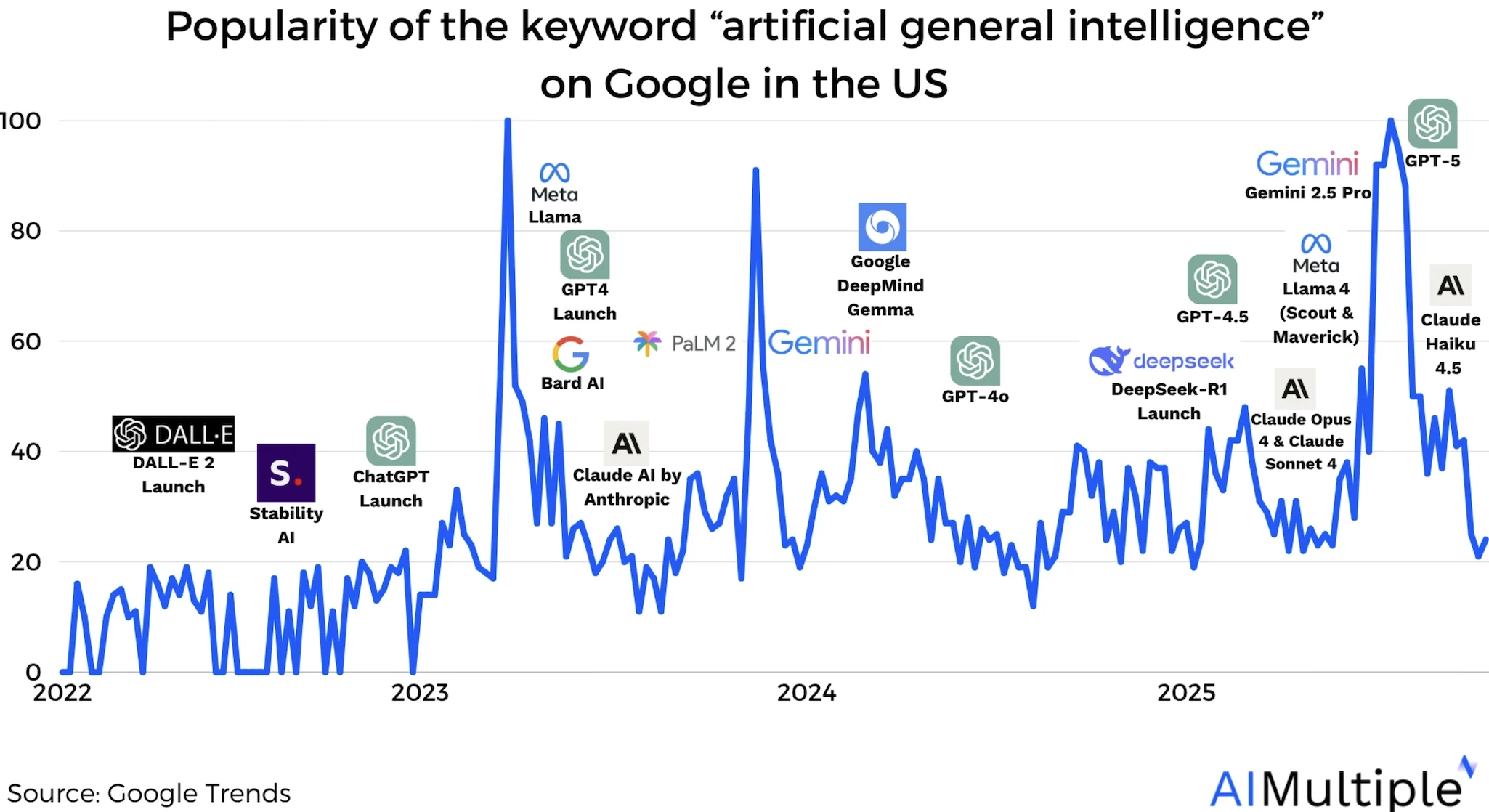
Üstel büyüme
Aşağıdaki, üstel büyümeyi anlamak için yararlı bir benzetmedir. Makineler şu anda çok zeki görünmeyebilir, ancak yakın gelecekte oldukça akıllı hale gelebilirler.
Yapay zeka hesaplama yeteneklerinde son büyüme
Şekil 2: Şekil, çeşitli kategorilerde gözlemlenen hesaplama büyüme modellerinin bir özetini göstermektedir: genel olarak kayda değer modeller (sol üst), frontier modeller (sağ üst), önde gelen dil modelleri (sol alt) ve önde gelen şirketlerin en iyi modelleri (sağ alt).
Yapay zeka modellerini eğitmek için hesaplama kaynakları önemli ölçüde arttı, dil modeli performansının yaklaşık üçte ikisi model ölçeği iyileştirmelerine atfediliyor.
2024 tarihli bir makaleye göre,42 yapay zeka modellerinin eğitiminde hesaplama kullanımındaki büyüme, kayda değer modeller, frontier modeller ve OpenAI, Google DeepMind ve Meta AI gibi önde gelen şirketlerdeki eğilimleri yansıtarak yılda yaklaşık 4-5x oranında sürekli olarak artmıştır (Bkz. Şekil 2).
Ancak, büyüme oranı 2018'den bu yana, özellikle frontier modeller için bir miktar yavaşladı, ancak dil modelleri 2020 ortasına kadar yılda 9x'e kadar daha hızlı bir büyüme yaşadı, ardından hız yılda 4-5x'e yavaşladı.
Yapay zeka hesaplama büyümesi için genel eğilim güçlü kalmaya devam ediyor ve projeksiyonlar, yeni zorluklar veya atılımlar olmadığı sürece yılda 4-5x'lik büyüme oranının devam edeceğini öne sürüyor. Bu büyüme, aralarında küçük farklılıklar olsa da, önde gelen yapay zeka şirketlerinin ölçeklendirme stratejilerinde de görülüyor.
Frontier model büyümesindeki yavaşlamaya rağmen, GPT-4 ve Gemini Ultra gibi bugün piyasaya sürülen daha büyük modeller, tahmin edilen büyüme yörüngesiyle yakından uyumludur.
Klasik hesaplama yavaşlarsa, kuantum hesaplama boşluğu doldurabilir
Klasik hesaplama bizi oldukça ileri götürdü. Klasik bilgisayarlardaki yapay zeka algoritmaları, satranç veya Go oynamak gibi belirli görevlerde insan performansını aşabilir. Örneğin, AlphaGo Zero, AlphaGo'yu 100-0 yendi. AlphaGo dünyanın en iyi oyuncularını yenmişti.43 Ancak, klasik bilgisayarların ne kadar hızlı olabileceğinin sınırlarına yaklaşıyoruz.
Yoğun bir tümleşik devredeki transistör sayısının yaklaşık her iki yılda bir ikiye katlandığı gözlemine dayanan Moore yasası, hesaplama maliyetinin yaklaşık her 2 yılda bir yarıya indiğini ima eder.
Öte yandan, çoğu uzman Moore yasasının bu on yıl içinde sona ereceğine inanıyor.44 Ancak, hesaplama verimliliğini artırmaya devam etme çabaları var.
Örneğin, DeepSeek, OpenAI gibi rakiplerinin maliyetinin çok altında bir akıl yürütme modeli sunarak R1 modeliyle küresel piyasaları şaşırttı.
Hâlâ gelişmekte olan bir teknoloji olan Kuantum Bilişim, Moore yasası sona erdikten sonra hesaplama maliyetlerini düşürmeye katkıda bulunabilir. Kuantum Bilişim, aynı anda farklı durumların değerlendirilmesine dayanırken, klasik bilgisayarlar bir seferde bir durum hesaplayabilir.
Kuantum bilişimin benzersiz doğası, şu anda ticari uygulamalarda en popüler yapay zeka mimarisi olan sinir ağlarını verimli bir şekilde eğitmek için kullanılabilir. Kararlı kuantum bilgisayarlarda çalışan yapay zeka algoritmaları, tekilliğin kilidini açma şansına sahiptir.
Neden bazı uzmanlar AGI'ye ulaşamayacağımıza inanıyor?
AGI'nin önemine veya varlığına karşı 3 büyük argüman var. Bunları yaygın karşı argümanlarıyla birlikte inceledik:
1- Zeka çok boyutludur
Bu nedenle, AGI farklı olacak, insan zekasından üstün olması zorunlu değildir.
Bu doğrudur ve insan zekası da hayvan zekasından farklıdır. Bazı hayvanlar, aylarca yüzlerce fındığı nereye sakladıklarını hatırlayan sincaplar gibi zihinsel becerilere sahiptir.
Derin öğrenmenin öncülerinden Yann LeCun, AGI kelimesini emekliye ayırmamız ve "gelişmiş makine zekası" elde etmeye odaklanmamız gerektiğine inanıyor.45 İnsan zihninin uzmanlaşmış olduğunu ve zekanın bir beceriler koleksiyonu ve yeni beceriler öğrenme yeteneği olduğunu savunuyor. Her insan, insan zekası görevlerinin bir alt kümesini gerçekleştirebilir.46
İnsanlar olarak, zekanın tüm spektrumunu bilmediğimiz ve deneyimleyemediğimiz için insan zihninin uzmanlaşma seviyesini anlamak da zordur.
Makinelerin insanüstü zeka sergilediği alanlarda, insanlar makineye özgü zayıflıklardan yararlanarak onları yenebildi. Örneğin, bir amatör, programın zayıflıklarını inceleyerek ve bunlardan yararlanarak dünya şampiyonlarını yenen Go programlarıyla aynı seviyedeki bir Go programını yenebildi.47
2- Zeka tüm sorunların çözümü değildir
Bilim
En iyi makine bile mevcut verileri analiz ederek kanser için bir tedavi bulamayabilir. Çoğu alanda yeni bilgi keşfetmek için gerçek dünya deneyleri yürütmesi ve sonuçları analiz etmesi gerekebilir.
Daha fazla zeka, daha iyi tasarlanmış ve yönetilen deneylere yol açarak deney başına daha fazla keşif sağlayabilir. Araştırma verimliliğinin tarihi bunu göstermelidir, ancak veriler oldukça gürültülüdür ve araştırmada azalan getiriler vardır. Newton hareketi gibi daha basit problemleri çözdükçe kuantum fiziği gibi daha zor problemlerle karşılaşırız.
Son olarak, bazı alanlarda, o alanın doğal rastgeleliği veya ölçülemezliği nedeniyle mükemmel tahminler mümkün olmayabilir. Örneğin, çok sayıda veriye rağmen, belirli yaşam sonuçlarını yüksek doğrulukla tahmin edemiyoruz.48
Ekonomi
Zeka, ekonomik değer üretimi için gerekli bileşen değildir.
- İnsan zekasının en yaygın kabul gören ölçüsü olan IQ, yaklaşık $40k üzerindeki değerler için net servetle ilişkili değildir (Aşağıdaki resme bakın):
Şekil 3: IQ, düşük servet seviyelerinde servetle ilişkilidir.49
Şekil 4: Yüksek servet seviyelerine odaklanırsak IQ servetle ilişkili değildir. Bu grafik, $40k altındaki net gelir seviyelerinin gizlenmiş olması dışında yukarıdakiyle aynıdır.
- Yatırım dünyasında, bir şirketin ekibinin zekası rekabetçilik faktörü olarak kabul edilmez. Diğer şirketlerin de zeki stratejiler belirleyebileceği örtük olarak varsayılır. Yatırımcılar, fikri mülkiyet, ölçek, kaynaklara özel erişim vb. gibi haksız avantajlara sahip işletmeleri tercih eder. Bu haksız avantajların çoğu yalnızca zeka ile kopyalanamaz.
3- AGI mümkün değildir çünkü insan beynini modellemek mümkün değildir
Teorik olarak, temel hesaplamalar yapabilen ve sonsuz bellek ve zamana erişebilen nispeten basit bir makineyle, insan beyni de dahil olmak üzere herhangi bir hesaplama makinesini modellemek mümkündür. Bu, 1950'de ortaya konan evrensel olarak kabul edilen Church-Turing hipotezidir. Ancak, belirtildiği gibi, belirli zor koşullar gerektirir: sonsuz zaman ve bellek.
Çoğu bilgisayar bilimcisi, insan beynini modellemenin sonsuz zaman ve bellekten daha azını alacağına inanıyor. Bununla birlikte, bu inancı kanıtlamanın matematiksel olarak sağlam bir yolu yoktur, çünkü beyni hesaplama gücünü kesin olarak karakterize edecek kadar iyi anlamıyoruz. Böyle bir makine inşa etmemiz gerekecek!
AGI'ye nasıl ulaşabiliriz?
Şekil 5: Frontier yapay zeka modellerinin zaman ufku, her modelin 50% güvenilirlikle tamamlayabileceği en uzun görevleri (insan eşdeğeri zamanda) göstermektedir.50
Yukarıdaki şekil, yapay zeka ajanlarının yeteneklerinin, 50% güvenilirlikle tamamlayabilecekleri en uzun görevleri ölçerek nasıl geliştiğini göstermektedir.
Temel bulgu, frontier modellerin üstesinden gelebileceği görev süresinin katlanarak büyüdüğü ve yaklaşık her yedi ayda bir ikiye katlandığıdır. Bu, Claude 3.7 Sonnet ve o1 gibi daha yeni modellerin artık bir insanın neredeyse bir saatini alacak görevleri tamamlayabileceği, GPT-2 gibi daha eski modellerin ise birkaç saniyeden uzun görevleri zar zor üstesinden gelebildiği anlamına gelir.
Gölgeli bölge istatistiksel belirsizliği yansıtır, ancak genel eğilim güvenilirdir. Bu model devam ederse, yapay zeka sistemleri yakında insanların günler hatta haftalar süren karmaşık görevleri üstlenebilir, bu da daha geniş otonomi ve AGI benzeri yeteneklere doğru önemli bir adımı işaret eder.
AGI'ye giden bir yol olarak ölçeklendirme
Frontier yapay zeka laboratuvarlarının liderleri, mevcut transformer tabanlı yaklaşımları ölçeklendirmenin AGI'yi sağlayabileceğine inanıyor, bu da birkaç yıl içinde AGI'ye ulaşma konusundaki tahminlerini besliyor.
AGI'ye önerilen bir yol, hesaplama ve veriyi artırarak transformer'lar gibi mevcut mimarileri ölçeklendirmek, bir diğeri ise tamamen yeni yaklaşımlar geliştirmektir.
Ölçeklendirme hipotezini desteklemek için, Epoch AI tarafından 2024'te yapılan bir rapor, yapay zeka hesaplama büyümesinin 2030'a kadar devam edip edemeyeceğini analiz etti.
Dört büyük kısıt belirlediler: güç kullanılabilirliği, çip üretim kapasitesi, veri kıtlığı ve işlem gecikmesi (Bkz. Şekil 6).
Bu zorluklara rağmen, altyapıya önemli yatırımlar yapıldığı varsayıldığında, on yılın sonuna kadar 2e29 FLOP'a kadar gerektiren modelleri eğitmenin mümkün olduğunu savunuyorlar.
Bu tür ilerlemeler, GPT-4 gibi günümüzün en son teknoloji modellerinden çok daha yetenekli yapay zeka sistemleri üreterek bizi AGI'ye yaklaştırabilir.51
Şekil 6: Grafik, güç, çip üretimi, veri ve gecikme gibi temel kısıtlar altında 2030 yılına kadar yapay zeka eğitim hesaplaması için tahmini üst sınırları göstermektedir; medyanlar 2e29 ila 3e31 FLOP arasında değişmektedir.
Ölçeklendirmenin ötesinde: Yeni mimarilerin gerekliliği
Ancak, Yann LeCun ve Richard Sutton gibi etkili yapay zeka bilim insanları, büyük dil modellerini ölçeklendirmenin insan düzeyinde zekaya yol açmayacağına inanıyor.52 53 AGI için yeni mimarilerin veya yaklaşımların gerekli olduğuna inanıyorlar.
AGI'ye ulaşıp ulaşmadığımızı nasıl ölçebiliriz?
Büyük dil modelleri her hafta yeni kıyaslama ölçütlerini aşıyor, ancak LLM'leri değerlendirmek, veri zehirlenmesi ve insan düzeyinde zeka için kabul edilmiş bir bilimsel tanımın olmaması gibi sorunlar nedeniyle zordur.
Bu endişeler, LLM'leri ölçeklendirmenin daha iyi performansa giden sürdürülebilir bir yol olmadığını, özellikle bilimsel ve yüksek riskli alanlarda vurgulayan son araştırmalardan54 elde edilen içgörülerle daha da güçleniyor. Yazarlar şunları gösteriyor:
- LLM'ler çok düşük ölçeklendirme üsleri (~0.1) sergiler, yani veri veya hesaplamadaki büyük artışlar bile çok küçük doğruluk kazanımları sağlar.
- LLM'lerin öğrenme gücü, Gaussian olmayan çıktılar üretme yeteneklerinden kaynaklanır, ancak bu aynı zamanda hata birikimlerine ve kırılgan tahminlere yol açar.
- Kayıp fonksiyonları gibi geleneksel ölçütler, gerçek yakınsama veya doğrulukla uyuşmayan sözde ölçütlerdir.
- Sentetik veya tekrarlayan veriler üzerinde eğitilen modellerin düzeltilebileceklerinden daha hızlı hata biriktirdiği bir Dejeneratif Yapay Zeka (DAI) rejimi ortaya çıkabilir.
Bu bulgular, standart kıyaslama ölçütlerinin güvenilirliğini sorgulamakta ve daha çeşitli ve gelişen değerlendirme stratejilerine olan ihtiyacı vurgulamaktadır.
Turing testi gibi eski ölçütler günümüz makineleri için yetersiz kalmakta ve ARC-AGI gibi yeni ölçütler daha geniş kıyaslama ölçütlerinin genelleme yeteneklerinden yoksun olabilir.
ARC-AGI gibi ortaya çıkan ölçütler, soyutlama ve genellemeyi test etmeyi amaçlar, ancak yine de veri kontaminasyonuna veya aşırı uyuma karşı dirençten yoksun olabilir.
Dahası, makalenin vurguladığı gibi, "iyi" kayıp puanları bile Gaussian olmayan dalgalanmalar ve eğitim kararsızlıkları nedeniyle altta yatan bilgi felaketlerini maskeleyebilir.55
LLM'lerin ilerlemesini nasıl takip edebiliriz?
Bu zorlukların üstesinden gelmek için kıyaslama konusunda birkaç yaklaşım vardır:
- Kıyaslama sorularını sık sık güncellemek. Gerçek hayat örneği: LiveBench
- Veri zehirlenmesini önlemek için holdout setleri kullanmak: AIMultiple'ın AGI kıyaslama ölçütü veya ARC-AGI gibi kıyaslama ölçütleri.
AGI'yi belirlemek için kıyaslamanın ötesindeki yaklaşımlar nelerdir?
AGI'yi tanımlamaya yardımcı olabilecek, potansiyel olarak güçlü ancak gecikmeli yapay zeka etkisi göstergeleri vardır.
Ekonomik büyüme
Microsoft CEO'su Satya Nadella, gelişmiş dünyada 10% büyümenin AGI'yi göstereceğini iddia ediyor.56 . Ancak, AGI, OpenAI ve Microsoft'un özel ortaklığını sona erdireceğinden, gecikmeli bir AGI tanımına sahip olma yönünde teşviği vardır.57
İşsizlik
AGI'nin şunları yapmasını bekliyoruz:
- Beyaz yakalı istihdamı, işgücündeki insanların payı olarak ölçüldüğünde küresel zirvesinin 10%'una düşürmek. Bu, emeğin gelirden aldığı pay yapay zeka nedeniyle önemli ölçüde azalırsa gerçekleşmelidir.
- GSYİH büyümesi devam ederken
Makinelerin insanlardan daha zeki ve verimli olduğu bir dünyada, bir bilgisayarın önünde oturması için bir insana ödeme yapmak rasyonel olmazdı. Bu nedenle, insanlar fiziksel dünyadaki işlerde gelişmeye devam ederken beyaz yakalı istihdamın düşmesini bekliyoruz.
İşgücü istatistiklerini toplayan devlet kurumları işleri ayrıntılı kategorilere ayırır, bu da beyaz yakalı istihdamı takip edilmesi kolay bir ölçüt haline getirir.
2019'dan 2024'e kadar beyaz yakalı istihdama ilişkin ABD Çalışma İstatistikleri Bürosu'ndan veri topladık.58 Açıklık ve tutarlılık için, beyaz yakalı çalışanları aşağıdaki meslek gruplarına ayırdık:
- Mimarlık ve Mühendislik Meslekleri
- İşletme ve Finansal Operasyonlar Meslekleri
- Bilgisayar ve Matematik Meslekleri
- Sağlık Uygulayıcıları ve Teknik Meslekler
- Hukuk Meslekleri
- Yaşam, Fizik ve Sosyal Bilimler Meslekleri
- Yönetim Meslekleri
- Ofis ve İdari Destek Meslekleri
- Satış ve İlgili Meslekler
Analizimize göre, beyaz yakalı çalışanların toplam istihdama oranı bu dönemde 45% ile 48% arasında dalgalanmıştır.
Bu aralık şimdiye kadar beyaz yakalı istihdamın payında göreceli bir istikrar olduğunu gösterse de, uzun vadeli bir eğilimin göstergesi değildir ve otomasyon ve yapay zeka benimsenmesi hızlandıkça önümüzdeki yıllarda daha belirgin değişimler bekliyoruz. Yapay zekanın beyaz yakalı ve giriş seviyesi istihdamı nasıl değiştireceğine dair daha fazla tahmin için yapay zeka iş kaybını okuyun.
AGI'yi hedeflemeli miyiz?
AGI'ye nihai hedef olarak odaklanmanın yapay zeka araştırmasını çarpıtabileceği konusunda uyaran bilgisayar bilimcileri var.59 Eleştiriler şunları içerir: Bir fikir birliği yanılsaması yaratmak, kıyaslama ölçütlerine aşırı uyum sağlamak, gömülü sosyal değerleri görmezden gelmek, abartının öncelikleri belirlemesine izin vermek, "genellik borcu" oluşturmak (temel tasarım sorularını ertelemek) ve marjinalleştirilmiş toplulukları ve yetersiz kaynaklara sahip araştırmacıları dışlamak.
Belirli, ölçülebilir ve şeffaf hedefler, AGI gibi belirsiz tanımlanmış bir hedeften daha iyi yapay zeka ilerlemesi için olacaktır.
AGI tahminlerinin ardındaki matematiksel akıl yürütme
Matematiksel akıl yürütme, AGI zaman çizelgelerini anlamanın ve tahmin etmenin merkezinde yer alır. Birçok projeksiyon, yapay genel zekanın ne zaman ortaya çıkabileceğine dair beklentilere rehberlik eden nicelleştirilebilir eğilimlere ve biçimsel modellere dayanır.
Ölçeklendirme yasaları ve hesaplama büyümesi
Matematiksel akıl yürütmenin bir ana bileşeni ölçeklendirme yasalarını analiz etmeyi içerir. Bunlar, model performansının daha fazla veri, parametre ve hesaplama ile öngörülebilir şekilde iyileştiğini gösterir.
Yapay zeka eğitim hesaplamasındaki yıllık 4-5× tutarlı büyüme, mevcut eğilimlerin devam ettiği varsayıldığında, AGI'nin bir veya yirmi yıl içinde ulaşılabilir olabileceği tahminlerini desteklemektedir.
Bu projeksiyonlar, matematiksel modellemenin temel bir kavramı olan güç yasası ilişkileriyle desteklenen, performans eğrilerine ve ekstrapolasyonlara deneysel uyumlara dayanır.
Olasılıksal tahmin
Araştırmacılar ayrıca AGI tahminlerine olasılıksal yöntemler uygular. Anketler genellikle uzmanlardan AGI'nin belirli yıllara kadar geliştirilme olasılığını tahmin etmelerini ister ve kümülatif olasılık dağılımları üretir.
Örneğin, 2040 yılına kadar 50% olasılık, gözlemlenen yapay zeka ilerlemesine dayalı Bayes tarzı güncelleme tarafından yönlendirilen belirsizlik altındaki fikir birliğini yansıtır.
Bu matematiksel akıl yürütme yaklaşımı, kesin tarihler gerektirmeden uzman belirsizliğini yakalar ve yeni veriler kullanılabilir hale geldikçe sürekli revizyona izin verir.
Teorik temeller
Bu tahminler, insan bilişinin makineler tarafından simüle edilebileceğini ima eden Church-Turing tezi ve zekayı bilginin sıkıştırılabilirliğiyle ilişkilendiren Kolmogorov karmaşıklığı gibi kavramlar dahil olmak üzere matematiksel akıl yürütmenin teorik unsurlarına dayanır.
Bu tür teoriler AGI'yi garanti etmese de, olasılığı ve ilgili hesaplama gereksinimleri hakkında düşünmek için bir çerçeve sağlar.
Yapay Genel Zeka hakkında daha fazlası
Google DeepMind'da Baş Araştırma Bilimcisi David Silver
Yapay Genel Zeka'nın (AGI), bilim, müzik veya spor gibi çeşitli alanlarda uzman olabilen insanlar gibi, çok çeşitli görevleri öğrenebilen ve mükemmelleşebilen yapay zeka sistemlerini ifade ettiğini açıklıyor.
Tek bir işlevle sınırlı dar yapay zekanın aksine, AGI insan uyum yeteneğini ve genel problem çözme yeteneğini yansıtmayı hedefler.
AGI'nin uzun vadeli bir hedef olduğunu, gerçek insan düzeyinde zekaya ulaşmanın muhtemelen birkaç atılım gerektireceğini ve kademeli olarak gelişeceğini belirtiyor (Aşağıdaki videoya bakın).
OpenAI'nin kurucu ortağı ve Baş Bilimcisi Ilya Sutskever
"AGI'ye Doğru Heyecan Verici, Tehlikeli Yolculuk" başlıklı TED Konuşmasında, Yapay Genel Zeka'ya (AGI) doğru hızlı ilerlemeyi araştırıyor.
Bu zaman çizelgesinde belirsizlik olduğunu kabul etmesine rağmen, AGI'nin önümüzdeki 5 ila 10 yıl içinde ortaya çıkabileceğini öngörüyor.
Sutskever, AGI'nin hem muazzam potansiyelini hem de derin risklerini vurgulayarak, gelişimini insani değerlerle uyumlu hale getirme ihtiyacını vurguluyor. Zorluklara rağmen, insanlığın bu güçlü teknolojiyi güvenle yönlendirebileceği konusunda iyimser (Aşağıdaki videoya bakın).
Bilgisayar bilimcisi ve girişimci Ray Kurzweil
İlkel aletlerden büyük dil modellerine kadar zeka artırıcı araçlar inşa etme yeteneğimizin izini sürerek altmış yılı aşkın yapay zeka ilerlemesini yansıtıyor.
Ayrıca Yapay Genel Zeka'nın 2029'a kadar geleceğini ve 2045'e kadar teknolojik tekilliğe yol açacağını öngörüyor. Hesaplama gücü, tıp ve biyoteknolojideki katlanarak ilerlemeleri vurguluyor.
Ayrıca yapay zeka tarafından üretilen tedaviler, dijital klinik deneyler ve bilimsel ilerlemenin yaşamı süresiz olarak uzatabileceği uzun ömür kaçış hızı gibi atılımları da öngörüyor (Aşağıdaki videoya bakın).
Turing ödülü sahibi Yann LeCun
LLM'lerin neden bize insan düzeyinde zeka veremeyeceğini ve oraya ulaşmak için en son yapay zeka yaklaşımlarını görün:
Yapay genel zeka tahminleri
Tekillik grafiği metodolojisi
AGI geliştirmenin beklenen yılını grafik üzerinde çizmek için, her kategori içindeki her yıl için tahminlerin ağırlıklı ortalamasını kullandık. Örneğin, 2022'de birden fazla Tahmin Piyasası tahmini varsa, ağırlıklı ortalamalarını hesapladık ve bu değeri çizdik.
- Bireysel tahminler için 18 yapay zeka uzmanının tahminlerini dahil ettik.
- Bilimsel tahminler için, AGI için zaman çizelgeleri sağlayan 10 hakemli makaleden anket sonuçlarını topladık.
- Tahmin piyasası sonuçları için 3 tahmin piyasasından (Manifold, Kalshi ve Metaculus) tahminleri dahil ettik.
Sonuç
AGI tahminleri son yıllarda belirgin şekilde değişti. Daha önceki anketler gelişini 2060'a yakın bir zamana yerleştirirken, son tahminler, özellikle girişimcilerden gelenler, 2026–2035 kadar erken bir tarihte ortaya çıkabileceğini öne sürüyor.
Bu değişim, büyük dil modellerindeki hızlı ilerlemeler ve artan hesaplama gücü tarafından besleniyor. Yine de, bu kazanımlara rağmen, günümüzün yapay zekası hâlâ insan düzeyinde zeka ile ilişkili genel esneklik ve otonomiden yoksundur.
Uzmanlar AGI'nin nasıl elde edileceği konusunda bölünmüş durumda; bazıları mevcut mimarileri ölçeklendirmenin yeterli olacağına inanırken, diğerleri yeni yöntemlerin gerekli olduğunu savunuyor.
Temel zorluklar arasında yüksek kaynak talepleri, belirsiz kıyaslama ölçütleri ve çözülmemiş etik kaygılar yer alıyor. AGI daha yakın olabilir, ancak gelişi hâlâ hem teknik atılımlara hem de dikkatli gözetime bağlıdır.
SSS'ler
Tekillik, makine zekasında hızlı bir artışla sonuçlanması beklenen varsayımsal bir olaydır.
Tekillik için, insan düzeyinde düşünmeyi insanüstü hız ve hızla erişilebilen, neredeyse mükemmel bellek ile birleştiren bir sisteme ihtiyacımız var.
Tekillik ayrıca makine bilinciyle sonuçlanmalıdır, ancak bilinç iyi tanımlanmadığı için bu konuda kesin olamayız. Böyle bir sistem kendini geliştirebilir ve insan yeteneklerini aşabilir.
Tekillik nispeten eski bir terim olsa da, AGI ve özellikle süper zeka aynı olayı tanımlamak için daha sık kullanılmaktadır.
Yapay Genel Zeka (AGI), insanlara eşit veya onları aşan bir düzeyde, geniş bir yelpazedeki entelektüel görevlerde anlayabilen, öğrenebilen ve bilgi uygulayabilen bir yapay zeka türünü ifade eder.
Dil çevirisi veya görüntü tanıma gibi belirli görevler için tasarlanmış dar yapay zekanın aksine, AGI genelleştirilmiş bilişsel yeteneklere sahip olacak, alışılmadık durumlarda akıl yürütme, planlama ve uyum sağlama imkanı verecektir.
AGI'nin geliştirilmesi, önemli bir araştırma hedefi ve etik ve felsefi tartışmanın konusu olmaya devam etmektedir.
Süper zeka, yaratıcılık, problem çözme ve sosyal anlayış dahil olmak üzere hemen tüm alanlarda en iyi insan zihinlerini önemli ölçüde aşan bir zekayı ifade eder.
Yapay bir sistemin her anlamlı entelektüel uğraşta insanlardan daha iyi performans gösterebileceği, AGI'nin ötesinde bir aşamayı temsil eder.
Bu kavram, üstün zekanın hakim olduğu bir dünyada kontrol, güvenlik ve insanlığın rolü için uzun vadeli sonuçlar hakkında kritik düşünceleri gündeme getirir.
Gelişmiş Makine Zekası (AMI), genel zekaya yaklaşan veya ona ulaşan yetkin yapay zeka sistemlerini içerir.
Henüz AGI ile ilişkili tam esneklik ve öz farkındalığa sahip olmasalar da, AMI sistemleri çeşitli görevlerde gelişmiş akıl yürütme, öğrenme ve uyum sağlama yeteneği gösterir.
Bu terim genellikle mevcut dar yapay zeka yeteneklerini aşan ancak tam genel zeka eşiğinin altında kalan yapay zeka sistemlerini belirtmek için kullanılır.
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{AGI/Tekillik: 10,000 Tahmin Analiz Edildi}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/artificial-general-intelligence-singularity-timing}},
note = {AIMultiple. Erişim tarihi: 22 Mayıs 2026}
}204 veri noktasının sonuçları ve zaman damgaları. Bu makalede kullanılan verileri, 2 CSV dosyası ve bir README içeren ZIP dosyası olarak indirin.





 gösteren grafik.")

Yorumlar 12
Düşüncelerinizi Paylaşın
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.
Does anyone know when this article was first published? I want to do a comparison of predictions vs reality for a project.
Hi Harper. The article was first published in mid-2017. But it's undergone constant updates since then to reflect the latest developments. Good luck with your project and let us know if we can help further!
I think we are far away from the point of singularity. It is not only that intelligence is multi dimensional, but also what is deemed as being intelligent (e.g., IQ, EQ) changes with time. People also change with time. So what is that point of singularity may change.
Hello, Yuvan. Thank you for your feedback.
Hello, Achieving the singularity from where we are now is relatively a simple jump, it is just time and advancements combined with a team somewhere who is dedicated to it and has the money to pull it off. The missing part of the equation would be asking the question "what is consciousness?" and understanding that. Then, understanding how to model that with non-biological machinery even at small levels, like modeling the consciousness of an amoeba or more advanced things like snakes and squirrels. Then if we know for certain what it is and how to model it, just run an adaptive evolution algorithm on itself, modeling out all of the processes in human cognition until it can beat them everywhere. Then, allow it to simply rebuild itself to continuously improve. The problem currently preventing this, is that human beings have no idea what consciousness is at all. It is a great mystery. One person thinks it is in the brain. Another thinks the brain is like a tuning fork, channeling the consciousness from somewhere else. It is a great mystery in science. When this problem is solved, then machine consciousness can be built most likely, depending on what it actually is. If consciousness is something weird, such as "human beings have spirits in other dimensions that are planned for their bodies by a supreme being. The brain creates a quantum resonant frequency that links it together with this already conscious entity, and then several universes are interacting simultaneously to create the actual experience of being self aware and sentient" well then, it will be very difficult to design a machine that does that same thing. It is more likely that we figure out how to model the resonance in the brain and then transfer an already existing consciousness of an animal or a human into a machine and keep it going, if that even makes any sense at all. However, maybe that's not how it works, and it is something simple like the holographic connection of energy patterns fluctuating in the mind - this can be modeled and a machine can be built that does these sorts of things with much more efficiency. Right now the mystery of the problem is consciousness itself. Hope that helps. I really enjoyed the robot soccer tournament. I also feel like a superhero at soccer now.
It's becoming clear that with all the brain and consciousness theories out there, the proof will be in the pudding. By this I mean, can any particular theory be used to create a human adult level conscious machine. My bet is on the late Gerald Edelman's Extended Theory of Neuronal Group Selection. The lead group in robotics based on this theory is the Neurorobotics Lab at UC at Irvine. Dr. Edelman distinguished between primary consciousness, which came first in evolution, and that humans share with other conscious animals, and higher order consciousness, which came to only humans with the acquisition of language. A machine with primary consciousness will probably have to come first. The thing I find special about the TNGS is the Darwin series of automata created at the Neurosciences Institute by Dr. Edelman and his colleagues in the 1990's and 2000's. These machines perform in the real world, not in a restricted simulated world, and display convincing physical behavior indicative of higher psychological functions necessary for consciousness, such as perceptual categorization, memory, and learning. They are based on realistic models of the parts of the biological brain that the theory claims subserve these functions. The extended TNGS allows for the emergence of consciousness based only on further evolutionary development of the brain areas responsible for these functions, in a parsimonious way. No other research I've encountered is anywhere near as convincing. I post because on almost every video and article about the brain and consciousness that I encounter, the attitude seems to be that we still know next to nothing about how the brain and consciousness work; that there's lots of data but no unifying theory. I believe the extended TNGS is that theory. My motivation is to keep that theory in front of the public. And obviously, I consider it the route to a truly conscious machine, primary and higher-order. My advice to people who want to create a conscious machine is to seriously ground themselves in the extended TNGS and the Darwin automata first, and proceed from there, by applying to Jeff Krichmar's lab at UC Irvine, possibly. Dr. Edelman's roadmap to a conscious machine is at https://arxiv.org/abs/2105.10461
I think Patrick Winston was joking when he said 20 years. From the linked quote: "I was recently asked a variant on this question. People have been saying we will have human-level intelligence in 20 years for the past 50 years. My answer: I’m ok with it. It will be true eventually." "Forced into a corner, with a knife at my throat, I would say 20 years, and I say that fully confident that it will be true eventually."
Great point! We should have read the source more carefully. I tried to explain his point better in the article.
I have the impression that the nerds that make this kind of prediction (replicate human brain) know a whole lot about computer programming but are ignorant about neuroscience/psychology. We are nor even scratching the surface about primary phenomenon, such as counsciousness / unconsciousness. How do you claim that you can replicate something that we are still far from understanding how it works?
Thank you for the comment. True, better understanding of the mind would help AGI research.
mmm... I'm not sure we can reach to this point: "benevolence of intelligent machines" Emotions and Feelings are there to guide our actions, to improve ourselves and to make a better world, can we make a machine to feel guilt of being smarter than us??
Saying human intelligence is fixed ignores that as we learn more about how the human brain works we may learn how to expand its capability's ie through some form of enhanced learning, targeted drugs, gene therapy, electro stimulation and not just direct brain computer connections being the only potential for doing this. More so currently hampered by our lack of understanding even the language you use has an effect on your cognitive ability's its one of the reasons deaf people were called dumb was the occurrence of language deprivation and how it negatively effected neurodevelopment it was a major problem when deaf children were forced to lip read instead of using sign language . But we will need more powerful AIs to achieve an understanding of our brains
People who say AGI will be here in 2060 are idiots and don't understand the flow of technology you'll see
@Vyn What do you mean? Do you mean to say it will take way before or way after 2060?
Thanks! I'll be quite happy if I get to see 2060
Intelligent doesn't solve our all problems maybe yes but certainly its essential and more intelligent you are faster you solve problems. If you are a chimp you can not even pour water to a glass. You do not even know what glass is used for. Yes if you are human being you still need to get up and grab the glass but intellegence is essential. I do not think human brain is impossible to create in a lab. I think earth is a lab. Anything found in nature can be replicate in the lab.
if P=NP then the singularity may happen also. Saying the human brain is impossible to recreate I dont agree with, but to say its intractable probably is approximately true. So P=NP, if you could solve that mystery (which is the millenial prize funnily) with an intractable calculation, that could make all the magic happen as well.
Thanks for the comment. Most computer scientists working on AI or machine learning would agree that it is possible to replicate human brain's capabilities.
The claim that "humans contribute most to the biomass" on the planet is likely to be wrong. Check out this paper for a careful estimation: https://www.pnas.org/content/115/25/6506
Thank you! That was insightful. Biology is not my strong suit, I should stick to computer science.
@AIMultiple Humble response, and great article. Thanks a ton :)
@B Thanks!