En Yaygın Web Kazıma Zorlukları
Web kazıma son yıllarda daha zor hale geldi. 2025'ten bu yana, yapay zeka ile ilgili kazıma önemli yasal endişeler uyandırdı. Platformlar ve altyapı sağlayıcıları, yapay zeka tarayıcılarını kontrol etmek ve veri toplama süreçlerini yönetmek için yeni yöntemler benimsedi.
Büyük web kazıma zorlukları nelerdir?
Web kazıyıcıları, veri sahipleri veya web sitesi sahipleri tarafından insanlar ile botlar arasındaki ayrımı yapmak ve insan olmayan erişimi bilgilerine sınırlamak amacıyla oluşturulan engeller nedeniyle karşılaştığı birçok teknik zorluk vardır. Web kazıma zorlukları şu ayrı kategorilere bölünebilir:
Hedef web sitelerinden kaynaklanan zorluklar:
- Güven skoru engeli (görünmez bot tespiti)
- Yapay zeka tarafından oluşturulan içerik ile verinin kirlenmesi
- Dinamik içerik
- Web sitesi yapısı değişiklikleri
- Anti-kazıma teknikleri (CAPTCHA engelleri, Robots.txt, IP engelleri, Bal kovanı tuzakları ve tarayıcı parmak izi oluşturma)
Web kazıma araçlarına özgü zorluklar:
- Ölçeklenebilirlik
- Yasal ve etik sorunlar
- Altyapı bakımı
Yasal ve uyum riskleri
Platformlar, sözleşme, haksız rekabet, gizlilik ve veri kötüye kullanımına dayanan yeni iddialarla karşı karşıya kalmaya devam ediyor. 2025'te Reddit, Anthropic'e, Anthropic'in izinsiz olarak Claude'u eğitmek için Reddit kullanıcı yorumlarını kazıdığını iddia ederek dava açtı. Dava, telif hakkından ziyade kullanım koşulları ve haksız rekabet sorunlarına odaklandı.
Güven skoru engeli (görünmez bot tespiti)
Statik engelleme (IP/Kullanıcı-Ajanı), sürekli davranışsal güven skoru ile değiştirildi. Modern anti-bot sağlayıcıları (Cloudflare, Akamai), bir tıklamadan önce fare titremesini ve kaydırma hızını izler.
Butona aniden atlayan veya matematiksel hassasiyetle tıklayan kazıyıcılar düşük bir güven skoru ile işaretlenir ve bu da hata mesajı olmadan verinin yüklenmemesine neden olan yumuşak engellerle sonuçlanır.
Çözüm:
Standart WebDriver/CDP tabanlı araçlar web siteleri tarafından kolayca tespit edilir. Doğrudan Chrome ile iletişim kuran ve otomasyon işaretleri bırakmayan Nodriver gibi modern kütüphaneleri veya özellikle gizlilik için tasarlanmış sertleştirilmiş bir Firefox sürümü olan Camoufox'u kullanın.1
Yapay zeka tarafından oluşturulan içerik kirliliği
Kazıyıcılar eğitim için veri yuttukça, kendi çıktı kalitelerini düşüren yapay zeka tarafından oluşturulan halüsinasyonları yanlışlıkla kazıyarak model çöküşü ile giderek daha fazla karşılaşırlar. Bu, veri doğruluğunu bir kalite kontrolü yerine teknik bir zorluk haline getirir.
Çözüm:
Kazılan metnin karmaşıklığını hesaplayan bir ön depolama doğrulama katmanı uygulayın. Yapay zeka tarafından oluşturulan içerik genellikle doğaya aykırı düşük bir karmaşıklığa sahiptir. Belirli bir özgünlük eşiğinin altında kalan verileri atın.
Dinamik web içeriği
Dinamik web içeriği, web kazıyıcıları için önemli bir zorluk oluşturur çünkü bilgiyi bir web sayfasında nasıl iletildiğini ve gösterildiğini temelde değiştirir.
Tüm içeriğin başlangıçtaki HTML dosyasında olduğu statik sitelerin aksine, dinamik siteler sayfayı genellikle kullanıcı davranışına yanıt olarak anında oluşturur. AJAX (Asenkron JavaScript ve XML) gibi teknolojiler dinamik web sitelerinin merkezindedir.
Temel sorun, standart kazıma araçlarının web tarayıcıları olmamasıdır. Bunlar, genellikle istediğiniz gerçek veriden yoksun olan, yer tutucular, yükleme animasyonları ve <script> etiketleri içerebilecek ancak genellikle istediğiniz gerçek veriden yoksun olan başlangıç HTML kabuğunu görür. Bu basit araçlar JavaScript'i çalıştırmaz.
Çözüm:
Bu zorlukların üstesinden gelmek için web kazıyıcılarının basit HTML ayrıştırıcılarından bir insanın tarayıcısı gibi bir web sayfasını tamamen işleyebilen araçlara evrilmesi gerekir.
Başsız bir tarayıcı, grafiksel kullanıcı arayüzü (GUI) olmayan bir web tarayıcısıdır. Arka planda çalışır ancak güçlü bir JavaScript motoru dahil olmak üzere standart bir tarayıcının tüm yeteneklerine sahiptir.
Selenium, Puppeteer ve Playwright gibi araçlar, tarayıcıları (Chrome, Firefox veya WebKit gibi) programatik olarak kontrol etmenizi sağlar. Bu gelişmiş araçları kullanarak, karmaşık, dinamik web siteleriyle etkileşime girebilen ve daha basit web kazıma yöntemlerine tamamen görünmez olacak içeriğe erişebilen web kazıyıcıları oluşturabilirsiniz.
Uzaktan tarayıcılar
Bir başka çözüm de kazıma tarayıcıları, ayrıca uzaktan tarayıcılar olarak da adlandırılır. Bunlar, web veri şirketleri tarafından yönetilen tarayıcılardır. Ayrıca web kazıyıcılarının JavaScript ile etkileşime girmesine de olanak tanır.
Web sitesi yapısı değişiklikleri
Web siteleri sürekli olarak iyileştirilmektedir. Bu değişiklikler bir sitenin düzenini, tasarımını veya altta yatan kodunu etkileyebilir. Küçük bir değişikliğin etkisi:
- Örneğin, bir geliştirici fiyat öğesinin sınıfını daha iyi bir açıklık için price'dan current-price'ya değiştirmeye karar verirse, kazıyıcının talimatları başarısız olur:
- Kazıyıcı artık fiyatı bulamayacaktır. Bir hata, boş bir değer veya daha kötüsü, yanlışlıkla benzer bir konumda bulunan yanlış veri parçasını yakalayabilir.
- Bu değişiklikler her zaman ve uyarı olmadan gerçekleşebileceğinden, kazıyıcının kodu sürekli olarak potansiyel ayarlamalara ihtiyaç duyar.
Çözüm
Çok spesifik ve kırılgan seçicilere güvenmek yerine, geliştiriciler daha akıllı olanları yazabilir. Örneğin, tam sınıfı price olan bir <span> aramak yerine, uyarlanabilir bir ayrıştırıcı, "Fiyat:" metninin yanında bulunan veya bir dolar işareti ($) içeren bir <span> arayabilir.
Otomatik kontroller, kazılan veriyi doğrulamak için periyodik olarak çalıştırılabilir. Fiyat alanının aniden tüm ürünler için boş değerler döndürmeye başladığını varsayalım. Bu durumda, sistem web sitesi yapısının muhtemelen değiştiğini ve ayrıştırıcının güncellenmesi gerektiğini geliştiriciye otomatik olarak bildirebilir.
LLM'ler
Yapay zeka modelleri, kazılacak öğeleri belirlemek için veya web sayfalarından veri toplamak için kullanılabilir. Kazımaya gecikme ve maliyet eklemelerine rağmen, web kazıyıcılarının uyarlanabilirliğini artırırlar.
Anti-kazıma teknikleri
Birçok web sitesi, web kazıma faaliyetlerini önlemek veya engellemek için anti-kazıma teknolojileri kullanır. Aşağıdaki noktalar, web kazıma sürecinde karşılaşılan en yaygın anti-bot önlemlerine genel bir bakış sunmaktadır:
CAPTCHA engelleri
Web siteleri, bir ziyaretçinin bir bot olabileceğinden şüphelendiklerinde CAPTCHA kullanır. Bu, kullanıcı kaydı, giriş formları, yorum bölümleri ve yüksek talep gören ürünler için ödeme süreçleri sırasında web sayfalarında yaygındır.
Aşırı agresif CAPTCHA uygulamaları, arama sonuçları için sayfaları dizine eklemek üzere web'i tarayan Google botu gibi "iyi botları" engelleyebilir. Eğer Google'ın tarayıcısı engellenirse, bir web sitesinin sayfaları düzgün bir şekilde dizine eklenmeyebilir ve bu da SEO uygulamalarını ve arama motoru sıralamasını olumsuz etkileyebilir.
Çözüm:
Bu engeli aşmak için kazıyıcılar bu zorlukları çözmek için bir mekanizmayla donatılmalıdır. Etkili olmalarına rağmen, bir CAPTCHA çözme hizmeti kullanmak, bu hizmetlerin genellikle çözülen CAPTCHA başına ücret alması nedeniyle web kazıma projesine başka bir karmaşıklık ve maliyet katmanı ekler.
Robots.txt
2025'ten bu yana, tarayıcı yönetişimi klasik robots.txt'nin ötesine genişledi. Cloudflare, yayıncıların tarayıcıları engellemesine, izin vermesine veya erişim için ücretlendirmesine olanak tanıyan yapay zeka tarayıcı kontrolleri, yönetilen robots.txt özellikleri, İçerik İmza Politikası ve Ödeme Başına Tarama araçlarını tanıttı.2
Çözüm:
Doğru yaklaşım, web verilerini almak için resmi olarak onaylanmış bir yol bulmaktır. En iyi alternatif, web sitesinin veri erişimi için bir API sunup sunmadığını görmektir. Eğer halka açık bir API mevcut değilse, sonraki adım doğrudan iletişimdir. Web sitesi sahibine veya veri sahibine ulaşabilir, kim olduğunuzu ve verilerle ne yapmayı planladığınızı açıklayabilirsiniz.
IP engelleme
IP engelleme (aynı zamanda IP yasaklama olarak da bilinir), web siteleri tarafından kullanılan en yaygın ve temel anti-kazıma önlemlerinden biridir. Bir web sitesinin sunucusu tek bir IP adresinden olağandışı yüksek trafik algıladığında, bunu şüpheli olarak işaretler. IP adresiniz engellendiğinde, kazıyıcınızdan gelen herhangi bir ek istek reddedilecektir.
Çözüm:
Bir proxy, kazıyıcınız ile hedef web sitesi arasında yer alan aracı bir sunucudur. Bir proxy üzerinden bir istek gönderdiğinizde, web sitesi isteğin kendi IP adresinizden değil, proxy'nin IP adresinden geldiğini görür. Bu amaçla iki güçlü proxy türü:
- Döndürmeli proxy'ler: Web kazıma aracınız bu havuzu kullanacak şekilde yapılandırılır ve her yeni istekle (veya belirli sayıda istekten sonra) otomatik olarak farklı bir IP adresine döner. Bu, isteklerinizi birden fazla IP adresi arasında dağıtır, böylece tek bir IP adresi web sitesinin hız sınırlarını aşmaz.
- Residential proxy'ler: Bir residential proxy havuzundaki IP adresleri, İnternet Servis Sağlayıcıları (ISP'ler) tarafından ev sahiplerine sağlanan gerçek, tüketici sınıfı internet bağlantılarına aittir. Trafik yasal bir konut IP adresinden kaynaklandığı için, bir web sitesinin bir kazıyıcının isteğini gerçek bir insan kullanıcının isteğinden ayırt etmesi neredeyse imkansızdır.
Bal kovanı tuzakları
Bal kovanları, hackerları çekmek ve web sitelerine erişmelerini engellemek için tasarlanmış bilgisayar sistemleridir. Bir bal kovanı tuzağı genellikle web sitesinin meşru bir parçası gibi görünür ve bir saldırganın hedefleyebileceği veri içerir.
Eğer bir tarama botu bir bal kovanı tuzak içeriğini çıkarmaya çalışırsa, sonsuz bir istek döngüsüne girer ve daha fazla veri çıkarmayı başaramaz.
Botlar neden buna aldanır
İnsan kullanıcı, web sitesinin işlenmiş, görsel sürümüyle etkileşime girer ve bu gizli bağlantıyı asla görmez veya tıklamaz. Ancak, birçok basit kazıyıcı sayfayı görsel olarak işlemez.
Bunlar, ham HTML kaynak kodunu ayrıştırarak ve buldukları tüm bağlantıları (<a href="..."> etiketleri) programatik olarak çıkararak çalışır. Bal kovanı bağlantısı HTML'de mevcut olduğu için, naif bot bunu diğer meşru bağlantılar gibi görüp takip edecektir.
Çözüm
Ham HTML'i ayrıştırmak yerine, Selenium, Puppeteer veya Playwright gibi bir başsız tarayıcı kullanın. Ayrıca, takip etmek istediğiniz bağlantılar için belirli, öngörülebilir konumlar tanımlayarak, kazıyıcınızın HTML'in belirsiz bir kısmına kasıtlı olarak yerleştirilmiş bir bal kovanı bağlantısına takılma şansını azaltabilirsiniz.
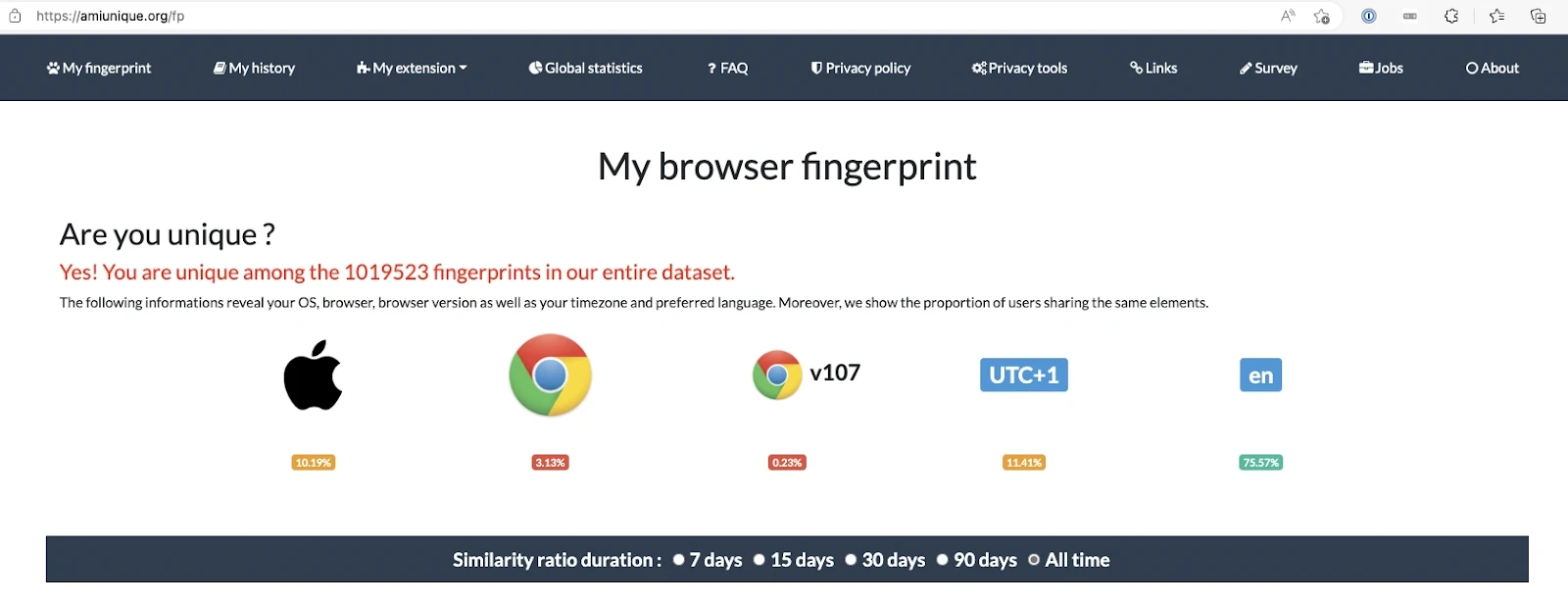
Tarayıcı parmak izi oluşturma
Tarayıcı parmak izi oluşturma, web sitelerinin ziyaretçileri hakkında IP adresleri aracılığıyla bilgi toplamak için kullandığı bir yöntemdir. Bir web sitesine her eriştiğinizde, cihazınız içeriğini yüklemek için siteyle bağlantı kurmak için bir istek gönderir. Bu, web sitesinin cihazınız hakkında tarayıcınız tarafından iletilen verileri almasına ve depolamasına olanak tanır.
Web siteleri, ziyaretçileri için önerileri özelleştirmelerini sağlayan tarayıcı parmak izi oluşturma kullanarak bir kullanıcının cihazı hakkında kapsamlı ayrıntılar toplayabilir. Örneğin, hedef web sitesi kullanıcı ajanlarınız, HTTP başlığınız, dil ayarlarınız ve yüklü eklentileriniz hakkında veri çıkarabilir.
Kaynak: AmIUnique
Kazıyıcılar için zorluk
Tarayıcı parmak izi oluşturma, kazıyıcıların varsayılan olarak garip ve tutarsız parmak izlerine sahip olduğu için önemli bir zorluk oluşturur.
- Genel parmak izleri: Basit bir kütüphane kullanan temel bir kazıyıcı, minimal bir başlık kümesi gönderecek ve hiçbir eklentisi, ekran çözünürlüğü veya diğer "insan" nitelikleri olmayacaktır.
- Tutarsız parmak izleri: Bir kazıyıcı döndürmeli proxy'ler kullanabilir, bu da IP adresinin bir istekte Almanya'dan ve bir sonraki istekte Japonya'dan görünmesine neden olabilir.
Çözüm
Selenium, Puppeteer veya Playwright gibi başsız tarayıcıları kullanın. Bunlar, basit HTTP kütüphanelerine kıyasla kutudan çıktığında daha eksiksiz ve inandırıcı bir parmak izi oluşturan gerçek tarayıcı motorlarıdır.
Ayrıca, standart, gerçek dünya User-Agent dizilerinin bir listesini koruyabilir ve bunları farklı oturumlar için döndürebilirsiniz. Gönderilen HTTP başlıklarının da gerçek bir tarayıcınınkilerle tutarlı olduğundan emin olun.
Ölçeklenebilirlik
Fiyatlandırma zekası, pazar araştırması ve müşteri tercihleri hakkında bilgi edinmek için birden fazla web sitesinden büyük miktarda web verisi kazımaya ihtiyacınız olabilir. Kazınacak veri miktarı arttıkça, birden fazla paralel istek yapmak için son derece ölçeklenebilir bir web kazıyıcısına ihtiyacınız vardır.
Çözüm:
Hızı artırmak ve büyük miktarda veriyi daha hızlı toplamak için asenkron istekleri işlemek üzere tasarlanmış bir web kazıyıcısı kullanmanız gerekir.
Asenkron veri kazıma, bir kazıyıcının her birinin yanıt vermesini beklemeksizin farklı web sitelerine birden fazla istek göndermesine olanak tanıyan bir tekniktir.
Örneğin, bir web sitesi yavaş yanıt verirse, asenkron bir kazıyıcı, bu sırada diğer, daha hızlı web sitelerine istek göndermeye ve işlemeye devam edebilir.
Altyapı bakımı
Optimum sunucu performansını korumak için, artan veri hacimlerini ve web kazıma karmaşıklıklarını karşılamak üzere depolama gibi kaynakları düzenli olarak yükseltmek veya genişletmek esastır. Gelişen taleplere ayak uydurmak için web kazıma altyapınızı sürekli olarak güncellemeniz gerekir.
Bir kazıma altyapısı oluşturmak ve yönetmek, geniş bir teknik beceri yelpazesi gerektirir. Bu, sunucu yönetimi, ağ yönetimi, veritabanı optimizasyonu ve anti-bot mekanizmalarını aşmak için gereken özel bilgiyi içerir.
Çözüm:
Web kazıma gereksinimlerinizi dış kaynakla sağlarken, hizmet sağlayıcının proxy döndürücü ve veri ayrıştırıcı gibi yerleşik özellikler sunduğundan emin olun. Ayrıca, sağlayıcı ölçeklenebilir seçenekler sunmalı ve değişen ihtiyaçları karşılamak için altyapısını düzenli olarak güncellemelidir.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{En Yaygın Web Kazıma Zorlukları}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/web-scraping-challenges}},
note = {AIMultiple. Erişim tarihi: 13 Mayıs 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.