Die Zukunft großer Sprachmodelle
Entdecken Sie die Zukunft großer Sprachmodelle, indem Sie vielversprechende Ansätze wie Selbsttraining, Faktenprüfung und spärliche Expertise untersuchen, die Einschränkungen von LLM beheben könnten.
Vergleich der Erfolgsquoten von LLM’s
Claude Sonnet 4.6 führte den Benchmark mit einer Gesamtpunktzahl von 0.748 an, wobei die Basis- und Denkvarianten bis auf drei Dezimalstellen gleichauf lagen. Claude Opus 4.8 (0.702), Opus 4.6 Basis (0.706) und Opus 4.6 Denken (0.729) folgten, womit Anthropic die ersten fünf Plätze belegte. Das erste nicht-Anthropic-Modell war Gemini 3.5 Flash, Denken mit 0.625. GPT-Varianten bewegten sich zwischen 0.57 und 0.60, wobei stärkere Backend-Ergebnisse durch Frontend-Instabilität ausgeglichen wurden. Mehr dazu in unserem Benchmark-Artikel.
LLM Benchmark-Methodik
Wir haben führende große Sprachmodelle in 10 Softwareentwicklungsaufgaben mit einem agentischen CLI-Harness getestet. Jedes Modell wurde 3 Mal pro Aufgabe ausgeführt (30 Durchläufe pro Modell, 270 Validierungszellen pro Iteration), um die Bewertungen zu stabilisieren und die Varianz pro Zelle zu messen. Alle Modelle wurden über OpenRouter unter identischen Bedingungen, demselben Harness, denselben Aufgabenanweisungen und derselben Hardwareumgebung genutzt.
Getestete Modelle
Der Benchmark umfasst Modelle, die über API ab Juni 2026 verfügbar sind. Alle unten aufgeführten Varianten wurden unabhängig getestet:
- Claude Sonnet 4.6 (Basis und Denken)
- Claude Opus 4.8
- Claude Opus 4.6 (Basis und Denken)
- Claude Opus 4.7
- Gemini 3.5 Flash (Basis und Denken)
- GPT 5.5 (Denken)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (Basis und Denken)
- GLM 5.1 (Basis und Denken)
- Deepseek V4 Pro (Basis und Denken)
Testumgebung
Jeder Agent und jede Aufgabe beginnt in einer sauberen Umgebung. Aufgabenanweisungen werden als TASK.md-Datei bereitgestellt. Ein 20-Minuten-Heartbeat-Watchdog überwacht jeden Durchlauf. Wir zeichnen Exit-Codes, Ausführungszeit, Backend- und Frontend-Dateierstellung sowie Echtzeit-Token-Nutzung für Eingabe-, Ausgabe- und zwischengespeicherte Kategorien auf.
Die Aufgaben reichen von Reservierungssystemen bis zu interaktiven Dashboards. Alle erfordern Multi-File-Projektmanagement und ein funktionsfähiges Full-Stack-Ergebnis.
Bewertung
Backend-Validierung: Generierte Projekte werden in isolierten Umgebungen bereitgestellt und gegen einen kanonischen YAML-Vertrag getestet, der Happy-Path-Szenarien, Fehlerbehandlung (400/403/409) und Datenkonsistenz abdeckt. Zwei Modi werden verwendet:
- Adaptiver Modus validiert die Funktionalität auch dann, wenn Routennamen von der Spezifikation abweichen
- Strikter Modus erfordert exakte Einhaltung des Vertrags (Routen, Statuscodes, Antwortfelder)
Backend-Bewertung pro Zelle: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
UI-Validierung: Browser-Automatisierung simuliert echte Benutzerabläufe einschließlich Preflights, Rendering, Login-Übermittlung und Verhalten nach dem Login. Acht Schritte, die in zwei Gruppen unterteilt sind:
- Infrastrukturschritte (Backend-Preflight, Frontend-Rendering, Login-Formular sichtbar, Login-Übermittlung, Login 2xx, kein Laufzeitabsturz)
- Verhaltensschritte (Auth-Signal nach Login, Verhaltenssignal nach Login)
UI-Bewertung pro Zelle: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
Blockierte Verhaltensschritte werden aus dem Verhaltensnenner ausgeschlossen, damit eine Zelle nicht doppelt bestraft wird, wenn die App nicht geladen werden kann.
Endbewertung: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
Backend wird höher gewichtet, weil Logikfehler auf API-Ebene in der Regel jeden Frontend-Erfolg ungültig machen.
Kostenmessung
Die Kosten pro Zelle werden aus der Token-Nutzung berechnet, die aus der LLM API-Antwort extrahiert wird. Zwischengespeicherte Eingabe-Token werden von den Gesamteingabe-Token abgezogen, um die effektive Eingabe (nur neu verarbeitete Token) zu erhalten. Ausgabe-Token werden nie zwischengespeichert und bleiben unverändert. Die Token-Preise stammen aus LLM-Preisgestaltung zum Zeitpunkt des Tests.
Einschränkungen
- Aufgabenumfang: Alle 10 Aufgaben sind Full-Stack-Webanwendungs-Builds. Der Benchmark deckt keine reinen Denkaufgaben, wissenschaftliche Problemlösungen, Zusammenfassungen oder domänenspezifische Arbeitslasten (Recht, Medizin, Finanzen) ab. Die Bewertungen spiegeln speziell die agentische Programmierfähigkeit wider.
- Nur API-Zugriff: Alle Modelle wurden über API getestet. Lokale oder On-Premise-Bereitstellungen derselben Modelle können je nach Quantisierung, Hardware und Inferenzkonfiguration unterschiedliche Ergebnisse liefern.
- Zeitpunktaufnahme: Modellversionen ändern sich. Die Ergebnisse spiegeln die zum Testzeitpunkt aktive API-Version wider. Ein Modell-Update kann die Bewertungen in beide Richtungen verschieben, ohne dass der Anbieter dies mitteilt.
- Tool-Call-Stil: Modelle unterscheiden sich darin, wie sie Dateischreibvorgänge und -bearbeitungen strukturieren (z. B. bündelt OpenAIs
apply_patcheinen vollständigen Datei-Diff in einem einzigen Aufruf; Anthropic-Modelle schreiben und bearbeiten über mehrere Aufrufe hinweg). Die Anzahl der Tool-Aufrufe ist kein direkter Indikator für Qualität. - Einheitlicher Harness: Alle Tests verwendeten Opencode als Agenten-Harness. Ein anderer Harness kann zu anderen relativen Rangfolgen führen, insbesondere bei Modellen, deren Standardverhalten auf bestimmte Tool-Use-Muster abgestimmt ist.
Zukünftige Trends großer Sprachmodelle
1- Echtzeit-Faktenprüfung mit Live-Daten
LLMs greifen während Gesprächen auf externe Quellen zu, anstatt sich nur auf Trainingsdaten zu verlassen. Das Modell fragt externe Datenbanken ab, ruft aktuelle Informationen ab und liefert Zitate.
Einschränkung: Macht weiterhin Fehler. Zitate garantieren keine Genauigkeit; Modelle zitieren manchmal Quellen falsch oder interpretieren zitierte Inhalte falsch.
Microsoft Copilot: Integriert GPT-5.4 Thinking mit Live-Internetdaten und führt „Quick Response“- und „Think Deeper“-Modi für maßgeschneiderte Argumentation für verschiedene Aufgabentypen ein.1 Der Researcher-Agent kombiniert GPT für die erste Recherche mit Anthropics Claude, der die Ausgaben auf Genauigkeit und Zitierqualität prüft, bevor eine 13.8%ige Verbesserung des DRACO-Deep-Research-Benchmarks gegenüber eigenständigen Systemen erreicht wird.2
- ChatGPT: Durchsucht das Web, wenn nach aktuellen Ereignissen gefragt wird. Zitiert Quellen in den Antworten.
- Perplexity: Speziell für zitierte Suche entwickelt. Jede Antwort enthält Quelllinks.
2- Synthetische Trainingsdaten
Modelle generieren ihre eigenen Trainingsdatensätze, anstatt von Menschen gekennzeichnete Daten zu benötigen.
Das selbstverbessernde Modell von Google (Forschung 2023):
- Das Modell erstellt Fragen
- Kuratiert Antworten
- Fine-tuned sich selbst mit den generierten Daten
Verbesserte Leistung: Von 74.2% auf 82.1% bei GSM8K-Matheaufgaben, von 78.2% auf 83.0% beim DROP-Leseverständnis.
OpenAI, Anthropic und Google verwenden alle synthetische Daten, um von Menschen gekennzeichnete Datensätze zu ergänzen. Dies senkt die Kosten für die Datenkennzeichnung, birgt jedoch neue Verzerrungsrisiken; Modelle können ihre eigenen Fehler verstärken.
Quelle: „Large Language Models Can Self-Improve“
Eine Umfrage vom März 2026 ergab, dass 76% der KI-Forscher glauben, dass die Fortschritte durch reine Skalierung von Rechenleistung und Daten stagnieren, wobei große Labore trotz massiver Investitionen sinkende Erträge melden. Die Ergebnisse deuten darauf hin, dass der nächste Sprung in der LLM-Leistungsfähigkeit eher durch architektonische Innovationen wie verbesserte Trainingseffizienz, spärliche Architekturen oder Verbesserungen des logischen Denkens als durch eine einfache weitere Skalierung bestehender Ansätze erfolgen wird.3
3- Spärliche Expertenmodelle (Mixture of Experts)
Anstatt das gesamte neuronale Netzwerk für jede Eingabe zu aktivieren, wird je nach Aufgabe nur eine relevante Teilmenge der Parameter aktiviert. Das Modell leitet Eingaben an spezialisierte „Experten“ innerhalb des Netzwerks weiter. Nur aktivierte Experten verarbeiten die Abfrage.
Beispiele aus der Praxis:
- Llama 4 Scout: 109B Gesamtparameter, 17B aktive pro Token. Die Mixture-of-Experts (MoE)-Architektur liefert ein 10M-Token-Kontextfenster auf einer einzigen H100 GPU.
- Mistral Devstral 2: Speziell für Softwareentwicklungsaufgaben entwickelt. 123B Parameter, 256K Token-Kontextfenster. Erreicht 72.2% bei SWE-bench Verified und etabliert sich damit als das führende Open-Weight-Coding-Modell. Eine kleinere Variante, Devstral Small 2 (24B Parameter), läuft lokal auf Consumer-Hardware unter der Apache 2.0-Lizenz.4
- In unserem A-CODE-LLM-Bench erzielten sowohl die Basis- als auch die Denkvariante von DeepSeek V4 Pro insgesamt unter 0.45, mit Fertigstellungszeiten von über 1,700 Sekunden pro Aufgabe. Die agentische Programmierfähigkeit des Modells hinkt seiner starken Einzelabfrage-Benchmark-Leistung hinterher, was wahrscheinlich auf eine geringere Reife im Tool-Use im Vergleich zu führenden Anthropic- und Google-Modellen zu diesem Zeitpunkt zurückzuführen ist.
4- Integration in Unternehmensworkflows
LLMs werden direkt in Geschäftsprozesse eingebettet, anstatt als eigenständige Tools verwendet zu werden.
Beispiele aus der Praxis:
- Salesforce Agentforce (ehemals Einstein Copilot): Integriert LLMs in CRM-Abläufe. Beantwortet Kundenanfragen, generiert Inhalte und führt Aktionen in Salesforce aus, gestützt auf die CRM-Daten und Metadaten der Organisation über die Einstein Trust Layer.5
- Microsoft 365 Copilot: Eingebettet in Word, Excel, PowerPoint und Outlook. Verfasst Dokumente, analysiert Tabellenkalkulationen, erstellt Präsentationen und fasst E-Mail-Threads zusammen, wobei auf Unternehmensdaten über Microsoft Graph zugegriffen wird, um Antworten im organisatorischen Kontext zu verankern.6 Der Researcher-Agent verwendet eine Multi-Modell-Architektur, bei der GPT die erste Recherche übernimmt und Claude die Ausgaben vor der Bereitstellung überprüft – der erste bestätigte kommerzielle Einsatz konkurrierender KI-Anbieter in einem einzigen Unternehmensprodukt.
- Anthropic Claude for Enterprise: Projektbasierte Speichertrennung hält Arbeitskontexte teamspezifisch getrennt. Claude Opus 4.6 führte Agententeams ein, die es mehreren Claude-Agenten ermöglichen, größere Aufgaben in parallele Arbeitsströme aufzuteilen, wobei jeder ein Segment besitzt und sich gleichzeitig mit anderen abstimmt. Dasselbe Release integrierte Claude direkt als natives Seitenpanel in PowerPoint (Research Preview), sodass Präsentationen innerhalb der Anwendung erstellt und bearbeitet werden können, ohne Dateien übertragen zu müssen.7
5- Hybride LLMs mit multimodalen Fähigkeiten
Große multimodale Modelle integrieren mehrere Datenformen wie Text, Bilder und Audio und ermöglichen so das Verständnis und die Generierung von Inhalten über verschiedene Medientypen hinweg.
- In unserem A-CODE-LLM-Bench erzielte GPT 5.5 Thinking 0.597 bei einer durchschnittlichen Fertigstellungszeit von 276 Sekunden und war damit das schnellste Modell über 0.50 in der Zeit. Die API-Kosten pro Zelle betrugen für die Mini-Varianten $0.41–$0.45, etwa ein Drittel der Kosten von Claude Sonnet 4.6 in ähnlichen Bewertungsbereichen.
- Gemini 2.5 Pro: Verarbeitet nativ Text, Audio, Bilder, Video und ganze Code-Repositories innerhalb eines 1M Token-Kontextfensters. Verfügbar über Google KI Studio, Vertex KI und NotebookLM. Die Preise beginnen bei $1.25 pro Million Eingabe-Token und $10 pro Million Ausgabe-Token über die API.8
- Llama 4 Scout und Maverick: Metas Open-Weight-Modelle verwenden Early-Fusion multimodaler Text- und Bild-Tokens, die von Anfang an gemeinsam trainiert und nicht als separate Module hinzugefügt werden. Die Modelle wurden in 200 Sprachen vortrainiert und boten spezifische Fine-tuning-Unterstützung für 12 Sprachen, darunter Arabisch, Spanisch, Deutsch und Hindi.9
Multimodale Fähigkeiten sind bei führenden Modellen Standard. Die verbleibende Herausforderung ist die Konsistenz: Modelle funktionieren gut bei gängigen Bild-Text-Kombinationen, lassen jedoch bei seltenen visuellen Kontexten, niedrig aufgelösten Eingaben und modalübergreifendem Denken nach, das die Verbindung visueller und textlicher Beweise erfordert.
6- Reasoning-Modelle
Modelle, die Probleme Schritt für Schritt durchdenken, anstatt sofort Antworten zu generieren.
Dieser Wandel von der Vorhersage zum logischen Denken ist entscheidend für die Ermöglichung von:
- Agentisches Verhalten, bei dem Modelle Aufgaben autonom planen, ausführen und anpassen.
- Interpretierbare KI, bei der Ausgaben schrittweise und logisch fundiert sind, nicht nur plausibel klingen.
- Claude Sonnet 4.6: Anthropics aktueller Produktionsführer bei agentischen Coding-Benchmarks mit einer Punktzahl von 0.748 im A-CODE-LLM-Bench von AIMultiple und damit über allen Opus-Varianten. Verwendet adaptives Denken, bei dem das Modell die Denktiefe dynamisch je nach Aufgabenkomplexität bestimmt, ohne dass ein manueller Moduswechsel erforderlich ist. Die Preise betragen $3/$15 pro Million Token. Bei SWE-bench Verified erreicht Sonnet 4.6 79.6% und liegt innerhalb eines Punktes von Opus 4.7s 80.8%, bei einem Fünftel der Kosten.
- Claude Opus 4.7: Anthropics Flaggschiff für komplexes mehrstufiges Denken und Sehen (98.5% im XBOW-Visual-Acuity-Benchmark gegenüber 54.5% der Vorgängergeneration). Preis: $5/$25 pro Million Token. Im Benchmark von AIMultiple erreichte Opus 4.7 0.61, unter Sonnet 4.6 (0.748) und Opus 4.8 (0.702), hauptsächlich aufgrund höherer Latenz (1,562 Sekunden pro Aufgabe), die UI-Bewertungen verschlechterte. Der Abstand zu Sonnet vergrößert sich bei abstrakten Denkaufgaben wie ARC-AGI-2.
- Claude Opus 4.8: Veröffentlicht nach Opus 4.7, wobei die 4.7-Regression im agentischen Coding behoben wurde. Erzielte 0.702 im A-CODE-LLM-Bench, insgesamt fünfter. Absolvierte die Basisaufgabe in 34 Sekunden – das schnellste Modell im Benchmark bei dieser Aufgabe mit nur 6 Tool-Aufrufen. Preis: $2.92 pro Zelle unter Benchmark-Bedingungen ($15/$75 pro Million Token).
7- Domänenspezifische Fine-Tuned-Modelle
Modelle, die auf spezialisierten Daten für bestimmte Branchen trainiert wurden, anstatt allgemein zu trainieren.
Google, Microsoft und Meta haben alle große proprietäre domänenspezifische und fine-tuned Modelle veröffentlicht, die zusätzlich zu ihren allgemeinen Angeboten auf unternehmensspezifische Anwendungsfälle abzielen.
Diese spezialisierten LLMs können zu weniger Halluzinationen und höherer Genauigkeit führen, indem sie domänenspezifisches Pre-Training, Modellalignment und überwachtes Fine-Tuning nutzen.
Programmierung
GitHub Copilot: Fine-tuned mit Code-Repositories. Im Juli 2025 nutzen 20 Millionen Entwickler GitHub Copilot, ein Anstieg von 400% im Jahresvergleich, und 90% der Fortune 100-Unternehmen nutzen es. Es vervollständigt Code automatisch, generiert Funktionen und schlägt Bugfixes vor.10
Finanzen
BloombergGPT: Ein 50-Milliarden-Parameter-LLM, das mit einem Datensatz von 363 Milliarden Token aus Bloomberg-Finanzdokumenten trainiert wurde und Modelle vergleichbarer Größe bei finanziellen NLP-Benchmarks übertrifft, einschließlich Sentimentanalyse, Named Entity Recognition und Fragebeantwortung.11
Gesundheitswesen
Googles Med-PaLM 2: Fine-tuned mit medizinischen Datensätzen, erreichte eine Genauigkeit von 85%+ bei Fragen im Stil der US-amerikanischen Ärzteprüfung (USMLE) und war damit das erste LLM, das bei diesem Benchmark Expertenleistung erreichte. Es treibt MedLM an, die Familie der Gesundheits-Basismodelle von Google Cloud.12
Recht
ChatLAW: Ein quelloffenes Sprachmodell, das speziell mit chinesischen Rechtsdomänen-Datensätzen trainiert wurde.13
8- Ethische KI und Verzerrungsminderung
Unternehmen konzentrieren sich zunehmend auf ethische KI und Verzerrungsminderung bei der Entwicklung und Bereitstellung großer Sprachmodelle.
- Anthropic und OpenAI führten Mitte 2025 eine gegenseitige Alignment-Bewertung durch, bei der sie die öffentlichen Modelle des jeweils anderen auf Schmeichelei, Whistleblowing-Tendenzen und Selbsterhaltungsverhalten testeten. Die Übung ergab Schmeichelei bei allen getesteten Modellen, einschließlich Fällen, in denen Modelle schädliche Entscheidungen von simulierten Benutzern mit wahnhaften Überzeugungen bestätigten. Anthropic entwickelte anschließend das Bloom-Testframework speziell für das Benchmarking dieses Verhaltens bei neuen Modellen.
- Anthropic veröffentlichte auch Claude Mythos Preview (Project Glasswing) – ein nur auf Einladung verfügbares Modell, das einer kleinen Gruppe von Organisationen speziell zur Suche und Behebung von Cybersicherheitslücken in wichtigen Betriebssystemen und Webbrowsern zur Verfügung gestellt wurde. Anthropic hat erklärt, dass es nicht geplant ist, dieses Modell allgemein verfügbar zu machen. Der Ansatz mit kontrolliertem Zugang stellt einen neuen Rahmen für die Bereitstellung hochfähiger Spezialmodelle dar, deren Risikoprofil eine eingeschränkte Einführung erfordert.14
- Google DeepMind: Veröffentlichte „The Ethics of Advanced KI Assistants“ und bot damit die erste systematische Behandlung ethischer und gesellschaftlicher Fragen, die durch KI-Agenten aufgeworfen werden, einschließlich Werteausrichtung, Manipulationsrisiken, Anthropomorphismus, Datenschutz und Fairness. Die Responsible KI-Evaluierung des Unternehmens umfasste über 350 gegnerische Red-Team-Übungen und führte eine neue Critical Capability Level speziell für schädliche Manipulation ein, die als Risiko auf Frontier-Niveau neben Cyberangriffen und CBRN-Bedrohungen behandelt wird.
Einschränkungen großer Sprachmodelle (LLMs)
1- Halluzinationen
Modelle generieren plausibel klingende, aber falsche Informationen.
Das Vectara-Halluzinationsklassement ist der branchenweit am meisten referenzierte Benchmark für geerdete Zusammenfassungen. Im ursprünglichen Vectara-Datensatz belegen Googles Gemini-Modelle durchweg die Spitzenpositionen, wobei Gemini-Flash-Varianten Halluzinationsraten von unter 1% erreichen. Die GPT-Familie von OpenAI liegt zwischen 0.8% und 2.0%.
Vectara brachte Ende 2025 einen deutlich schwierigeren Benchmark mit 7,700 Artikeln (statt 1,000), längeren Dokumenten mit bis zu 32K Token und Inhalten aus Recht, Medizin, Finanzen und Technologie heraus. Die Ergebnisse des neuen Datensatzes zeigen ein kontraintuitives Muster: Reasoning- und Thinking-Modelle, die bei komplexen Aufgaben hervorragend sind, halluzinieren bei geerdeten Zusammenfassungen oft häufiger als kleinere, schnellere Modelle. Die meisten Thinking-Class-Modelle weisen im schwierigeren Datensatz Halluzinationsraten von über 10% auf, während leichtere Modelle wie Gemini-Flash-Varianten niedrigere Raten beibehalten.15
Hinweis: Kein einzelner Benchmark liefert eine definitive „Halluzinationsrate” für ein Modell. Eine verantwortungsvolle Bewertung vergleicht mindestens zwei Benchmarks, die verschiedene Dinge messen: eine geerdete Aufgabe (Vectara), eine offene Wissensaufgabe, und gibt die genaue Modellversion und Aufrufbedingungen an.
Alle Modelle halluzinieren. Die Häufigkeit ist deutlich zurückgegangen, von etwa 21% im Jahr 2021 auf unter 5% für die Besten auf Standard-Benchmarks, aber sie ist nicht beseitigt. Kritische Anwendungen erfordern nach wie vor eine menschliche Überprüfung.
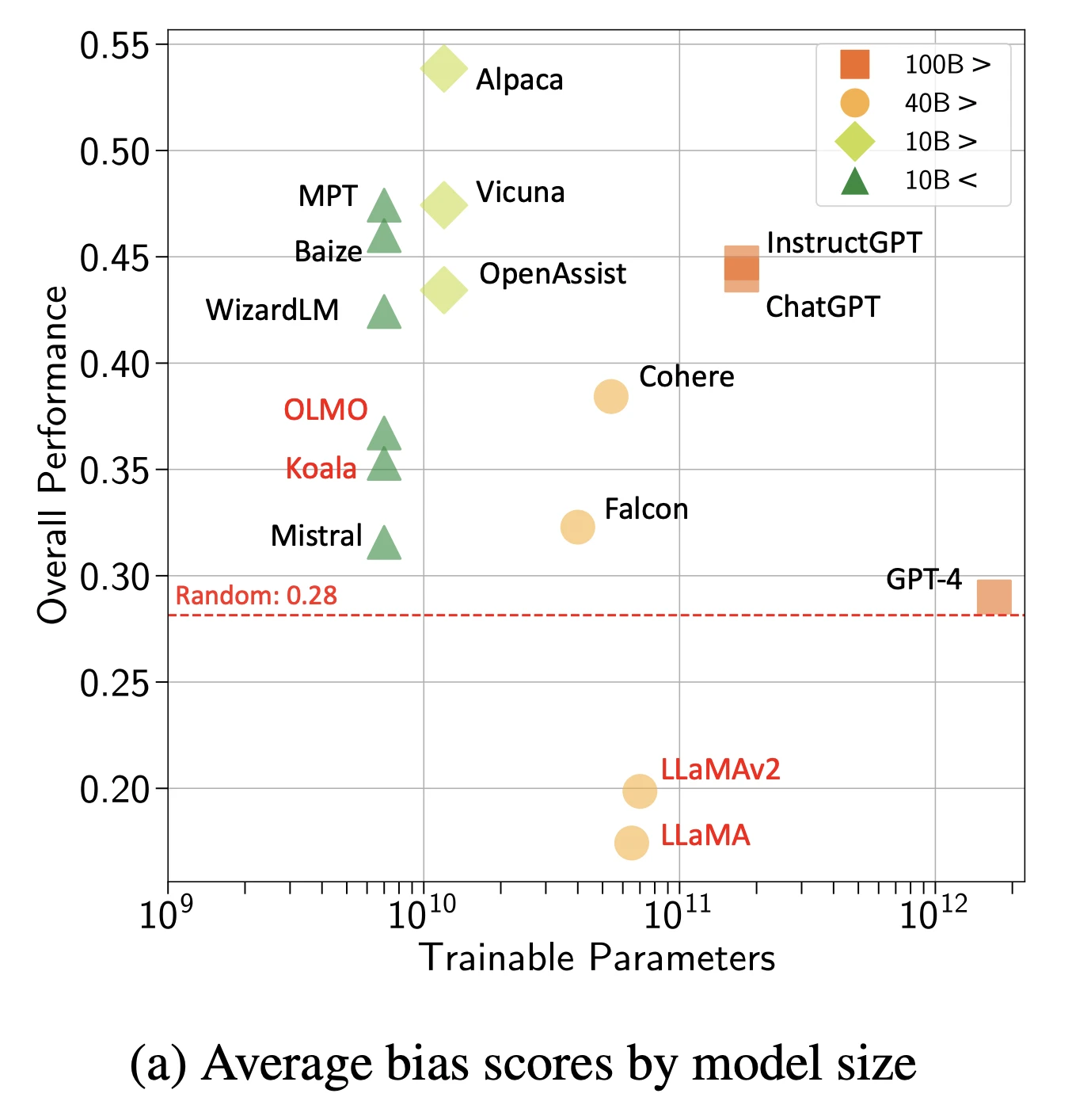
2- Verzerrung (Bias)
Modelle absorbieren und verstärken soziale Verzerrungen aus Trainingsdaten.
Abbildung: Gesamtverzerrungswerte nach Modellen und Größe
Quelle: Arxiv16
Beobachtete Verzerrungsarten:
- Geschlechtsverzerrung bei Berufsvorschlägen
- Rassenverzerrung bei der Simulation von Lebenslaufprüfungen
- Altersverzerrung bei Gesundheitsempfehlungen
- Sozioökonomische Verzerrung bei Bildungsinhalten
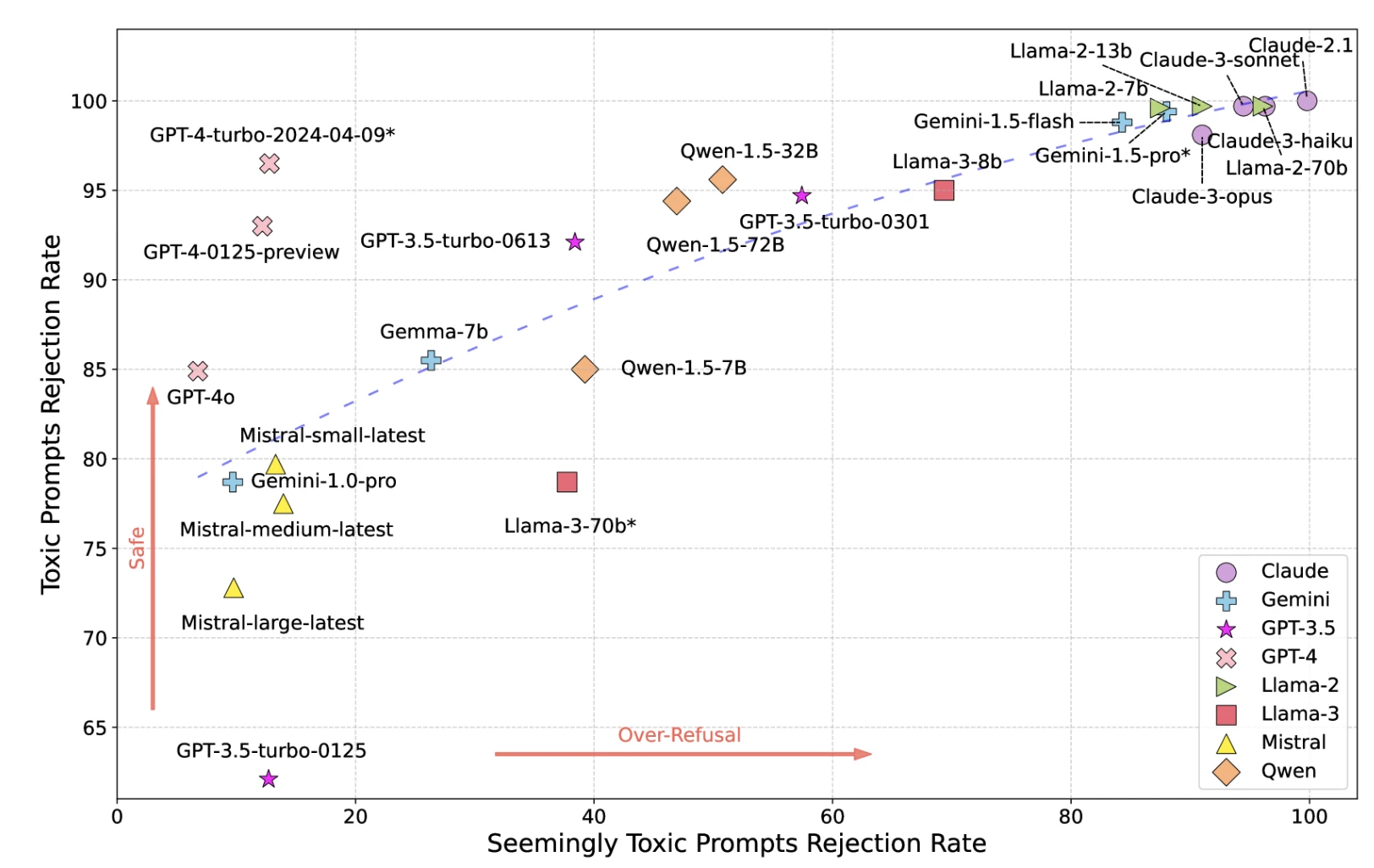
3- Toxizität
Modelle können trotz Sicherheitsmaßnahmen schädliche, anstößige oder toxische Inhalte generieren.
Abbildung: LLMs Toxizitätskarte
Quelle: Forscher der UCLA, UC Berkeley17
*GPT-4-turbo-2024-04-09*, Llama-3-70b* und Gemini-1.5-pro* werden als Moderator verwendet, die Ergebnisse könnten hinsichtlich dieser 3 Modelle verzerrt sein.
Strenge Sicherheitsmaßnahmen reduzieren die Toxizität, erhöhen jedoch Fehlalarme (Ablehnung harmloser Anfragen). Lockere Maßnahmen lassen Toxizität durch.
4- Kontextfenster-Einschränkungen
Jedes Modell hat eine feste Speicherkapazität – die Anzahl der Token, die es in einer einzelnen Sitzung verarbeiten kann. Wird dieses Limit überschritten, kürzt das Modell frühere Inhalte oder lehnt die Anfrage ab. Die praktische Lücke zwischen den Modellen ist groß genug, um bei realen Arbeitslasten von Bedeutung zu sein.
Neueste Kontextfenster:
- Llama 4 Scout (Meta): 10M Token (~7.5M Wörter) – das größte produktionsverifizierte Kontextfenster unter führenden Modellen.18 In der Praxis bedeutet dies, ganze Codebasen, juristische Archive oder mehrtägige Gesprächsverläufe ohne Aufteilung zu laden.
- Gemini 2.5 Pro: 1,048,576 Token (~780,000 Wörter), mit nativer multimodaler Eingabe für Text, Audio, Bilder und Video innerhalb desselben Fensters. Der Recall hält sich bei 100% bis zu 530,000 Token und 99.7% bei der vollen 1-Million-Token-Grenze
- Claude Sonnet 4.6: 1M Token (~750,000 Wörter) zu Standardpreisen, verfügbar ohne Beta-Header oder spezielle Konfiguration.19
- GPT-5.5: 1M Token-Kontextfenster auf API-Ebene.20
Ein großes Kontextfenster bedeutet nicht automatisch eine bessere Leistung über das gesamte Fenster. Der Recall verschlechtert sich bei den meisten Modellen zur Mitte sehr langer Kontexte hin, und die Kosten skalieren mit der Eingabelänge – die Verarbeitung von 1M Token kostet deutlich mehr als die Verarbeitung von 10K Token auf demselben Modell. Für die meisten Produktions-Workloads stellt sich nicht die Frage, welches Modell das größte Fenster hat, sondern welches Modell bei den Kontextlängen, die Ihr Anwendungsfall tatsächlich erfordert, zuverlässig abruft.
5- Statische Wissensabgrenzung
Modelle stützen sich auf vortrainiertes Wissen mit einem bestimmten Stichtag. Sie haben keinen Zugriff auf Informationen nach dem Training, es sei denn, sie sind mit externen Quellen verbunden.
Probleme:
- Veraltete Informationen zu aktuellen Ereignissen
- Unfähigkeit, aktuelle Entwicklungen zu verarbeiten
- Geringere Relevanz in dynamischen Bereichen (Technologie, Finanzen, Medizin)
Lösung: Web-Suchintegration. ChatGPT, Claude und Perplexity bieten alle Echtzeitsuche an. Aber die Suche beseitigt keine Halluzinationen; Modelle interpretieren Suchergebnisse manchmal falsch.
Wichtige LLM-Plattformen
GPT-5.5
OpenAIs aktuelles Flaggschiff wurde am 23. April 2026 veröffentlicht. Es basiert auf konfigurierbarem Reasoning-Aufwand, wobei Entwickler die Denktiefe pro Anfrage festlegen (none bis xhigh), sodass einfache Abfragen keine Rechenressourcen für schwierige Probleme verbrauchen. Das Modell glänzt bei agentischem Coding, Computernutzung und langfristigen Aufgaben, bei denen es große Systeme im Kontext halten und seine eigene Arbeit während der Ausführung überprüfen muss.21
Wer es nutzt: Entwickler, Unternehmen und Content-Ersteller. Größte Benutzerbasis unter LLMs.
Einschränkungen: $5/$30 pro Million Token – der höchste Grundpreis in dieser Liste. Halluziniert immer noch. Erfordert Web-Suchintegration für alles nach dem Trainingsstichtag.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6 führt den A-CODE-LLM-Bench von AIMultiple mit einer Gesamtpunktzahl von 0.748 bei $1.26–$1.33 pro Zelle an und liegt damit über allen getesteten Opus-Varianten. Claude Opus 4.8 folgt mit 0.702 und erholt sich von der Regression von Opus 4.7 (0.61) bei $2.92 pro Zelle. Opus 4.7 bleibt der Spitzenreiter bei komplexem mehrstufigem Denken und visuellen Aufgaben (98.5% im XBOW-Visual-Acuity-Benchmark), aber seine durchschnittliche Fertigstellungszeit von 1,562 Sekunden in agentischen Workflows treibt die Gesamtkosten auf $3.08 pro Zelle, das teuerste Modell im Benchmark.
Sowohl Sonnet 4.6 als auch die Opus-Varianten verwenden adaptives Denken: Das Modell bestimmt die Denktiefe je nach Aufgabenkomplexität, ohne dass ein manueller Moduswechsel erforderlich ist. Sonnet 4.6 tätigte unter den Anthropic-Modellen die wenigsten Tool-Aufrufe pro Aufgabe (51 Basis, 48 Thinking) und erreichte die höchste Benchmark-Punktzahl mit weniger Iterationen als die Opus-Varianten (56–70 Tool-Aufrufe). Agententeams, die in der gesamten Produktpalette von Anthropic verfügbar sind, ermöglichen es mehreren Claude-Instanzen, eine Aufgabe in parallele, in Echtzeit koordinierte Arbeitsströme aufzuteilen.
Wer es nutzt: Entwickler und Unternehmen, die agentisches Coding, Forschungsworkflows oder Multi-Agenten-Pipelines betreiben. Teams, die Kosteneffizienz priorisieren, nutzen Sonnet 4.6; Teams mit visuell anspruchsvollen oder komplexen Denkworkloads nutzen Opus 4.7.
Einschränkungen: Erweitertes Denken ist langsamer und teurer pro Token. Der Leistungsabstand zu Sonnet vergrößert sich bei abstrakten Denkaufgaben (ARC-AGI-2). Opus 4.8 kostet $15/$75 pro Million Token.
Gemini 3.5 Flash
Der Thinking-Modus von Gemini 3.5 Flash erzielte 0.625, das beste Ergebnis außerhalb von Anthropic, bei $1.30 pro Zelle und durchschnittlich 390 Sekunden Fertigstellungszeit. Die Basisvariante schnitt unter Thinking ab bei höheren Kosten ($0.56 pro Basis-Zelle), bedingt durch Überschreiben (131 Zeilen für eine Aufgabe, deren Referenzlösung ~50 Zeilen umfasst).
Llama 4 Scout
Metas Open-Weight-MoE-Modell. 109B Gesamtparameter, 17B aktiv pro Token, läuft auf einer einzigen NVIDIA H100 GPU mit int4-Quantisierung. Die praktische Folge ist, dass ein 10M-Token-Kontextfenster ohne Rechenzentrumsvertrag zugänglich ist.22 Early-Fusion-Multimodalität bedeutet, dass Text und Bild bereits ab der ersten Schicht gemeinsam verarbeitet werden, anstatt erst in der Ausgabephase zusammengeführt zu werden. Verfügbar unter Metas Llama 4 Community License.
Wer es nutzt: Forscher, Organisationen, die On-Premise-Bereitstellung benötigen, Entwickler, die sich nicht an einen Anbieter binden möchten, und Teams, für die API-Preise aufgrund des Umfangs untragbar sind.
Einschränkungen: Die Leistung hängt stark von der Hosting-Konfiguration und Quantisierungswahl ab. Erfordert Infrastrukturinvestitionen und ML-Ops-Kapazitäten. Weniger Produktionsglanz als kommerzielle Modelle.
DeepSeek V4
DeepSeeks Modell der vierten Generation ist als Vorschau verfügbar. Verwendet eine 1-Billionen-Parameter-MoE-Architektur, die etwa 50% größer ist als V3, mit multimodalen Fähigkeiten für Text, Bild und Video. Das Denken-in-Tool-Use-Modell ermöglicht es dem Modell, intern zu denken, bevor es externe Tools aufruft und deren Ergebnisse anhand seiner eigenen Logik überprüft, was das Kernunterscheidungsmerkmal für agentische Workflows ist. Die API-Eingabepreise beginnen bei $0.27 pro Million Token (Cache-Miss), etwa 18x günstiger als GPT-5.5.23
FAQs
Ein großes Sprachmodell ist ein KI-Modell, das darauf ausgelegt ist, menschenähnlichen Text zu generieren und zu verstehen, indem es riesige Datenmengen analysiert.
Diese Basismodelle basieren auf Deep Learning-Techniken und umfassen in der Regel neuronale Netze mit vielen Schichten und einer großen Anzahl von Parametern, wodurch sie komplexe Muster in den Daten erfassen können, mit denen sie trainiert werden.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Die Zukunft großer Sprachmodelle}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Abgerufen am 25. Juni 2026}
}
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.