Vergleich relationaler Fundamentaler Modelle
Wir haben SAP-RPT-1-OSS gegen Gradient Boosting (LightGBM, CatBoost) an 17 tabellarischen Datensätzen getestet, die das semantisch-numerische Spektrum, kleine/hohe semantische Tabellen, gemischte Geschäftsdatensätze und große numerische Datensätze mit geringer Semantik abdecken.
Unser Ziel ist es zu messen, wo ein relationales LLM seine vortrainierten semantischen Priors nutzen kann, um Vorteile gegenüber traditionellen Baummodellen zu erzielen, und wo es bei Skalierung oder geringer semantischer Struktur an Grenzen stößt.
SAP-RPT-1-OSS vs. Gradient Boosting: Benchmark-Ergebnisse
- Erfolgsrate: Stellt den durchschnittlichen normalisierten Score (0,0 bis 1,0) dar. Ein höherer Balken zeigt an, dass das Modell bei Datensätzen in dieser Kategorie konsistent näher am bestmöglichen Ergebnis liegt.
- 100 – 500 Zeilen (3 Datensätze):
- Eingeschlossen: wine (178), sonar (208), vote (435).
- Ergebnis: SAP erzielt bei 2 von 3 Datensätzen die besten Ergebnisse. Es erreicht die höchsten Scores bei wine und sonar, was darauf hindeutet, dass LLM-Priors vorteilhaft sein können, wenn Trainingsdaten knapp sind. Allerdings sicherte sich CatBoost beim vote-Datensatz einen knappen Sieg (innerhalb von 0,1 %), was zeigt, dass Baummodelle auch in kleinem Maßstab hochgradig wettbewerbsfähig bleiben.
- 501 – 1.000 Zeilen (3 Datensätze):
- Eingeschlossen: cylinder_bands (540), breast_cancer (569), credit_g (1.000).
- Ergebnis: SAP erzielt bei allen 3 Datensätzen die besten Ergebnisse. Bei cylinder_bands übertraf SAP LightGBM mit einem Vorsprung von 5,5 %, möglicherweise aufgrund einer besseren Handhabung semantischer Beschreibungen industrieller Defekte, obwohl weitere Ablationsstudien erforderlich wären, um diesen Mechanismus zu bestätigen.
- 1.000 – 10.000 Zeilen (5 Datensätze):
- Eingeschlossen: titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Ergebnis: SAP erzielt bei 4 von 5 Datensätzen die besten Ergebnisse und schneidet insbesondere bei textlastigen Aufgaben wie spambase und titanic besonders gut ab. Allerdings übertrifft CatBoost SAP bei compas signifikant um 10,4 %, was datensatzspezifische Merkmale aufzeigt, die Baummodelle auch in dieser Größenordnung bevorzugen.
- 10.000+ Zeilen (6 Datensätze):
- Eingeschlossen: california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Ergebnis: Mit zunehmendem Datenvolumen schwindet der potenzielle Vorteil des „Vorwissens“ des LLM. LightGBM und CatBoost erzielen bei 5 von 6 Datensätzen die besten Ergebnisse und bieten eine bessere Genauigkeit bei einem Bruchteil der Rechenkosten. Die einzige Ausnahme, california_housing, zeigt nur einen bescheidenen Vorteil von 1,7 % für SAP.
1. Tabelle der Benchmark-Ergebnisse-Datensätze
Im Folgenden finden Sie die vollständige Aufschlüsselung der Modellleistung über alle 17 Datensätze hinweg.
2. Kosten- und Effizienzanalyse
Wir haben die direkten Rechenkosten für jedes Modell basierend auf den RunPod H200-Instanzpreisen von 3,59 $ pro Stunde berechnet.
SAP-RPT-1-OSS verursacht deutlich höhere Kosten aufgrund der für die Text-Embedding-Vorverarbeitung benötigten Zeit und des hohen Speicheraufwands der LLM-Architektur. Im Gegensatz dazu erledigen LightGBM und CatBoost Aufgaben auf dieser Hardware fast sofort. Die unten aufgeführten Kosten spiegeln die gesamte Wandzeit (Vorverarbeitung + Training) für einen 3-fachen Kreuzvalidierungslauf wider.
Durchschnittliche Kosten pro Datensatz (17-Datensatz-Durchschnitt)
Kostenaufschlüsselung nach Datensatzgröße
- Kleine Datensätze (<1K Zeilen): SAP ist relativ günstig (≈ 0,03 $ pro Lauf). Die hohe Gewinnrate macht die Kosten hier vernachlässigbar.
- Große Datensätze (>20K Zeilen): SAP wird teuer.
- Beispiel: Das Training auf adult_income (48k Zeilen) dauert insgesamt ca. 12 Minuten für 3 Faltungen.
- Kosten: 12 Min X 0,06 $/Min = 0,72 $ pro Experiment.
- Vergleich: LightGBM erledigt die gleiche Aufgabe für 0,01 $.
Fazit: Obwohl 0,22 $ pro Datensatz absolut gesehen nicht teuer sind, ist SAP 22-mal teurer als die Basislinie. Dieser Kostenunterschied kann für kleine, semantikreiche Datensätze gerechtfertigt sein, bei denen SAP signifikante Genauigkeitsverbesserungen zeigt (z. B. cylinder_bands mit +5,5 % Steigerung), wird aber für große Datensätze schwerer zu rechtfertigen, bei denen Baummodelle bei einem Bruchteil der Kosten eine gleiche oder bessere Leistung erzielen.
3. Analyse-Rahmenwerk: Das semantische Spektrum
Um diese Ergebnisse zu interpretieren, ist es entscheidend zu verstehen, wie wir die Daten ausgewählt haben. Wir haben die Datensätze nicht zufällig ausgewählt; wir haben eine Suite von 17 Datensätzen kuratiert, die speziell ausgewählt wurden, um das Semantisch-Numerische Spektrum abzudecken.
Unsere Kernhypothese war, dass SAP (als LLM-basiert) dort glänzen würde, wo Daten linguistische Bedeutung haben, während Baummodelle bei rohen numerischen Berechnungen dominieren würden. Wir haben unsere Datensätze in drei verschiedene Cluster eingeteilt:
Cluster A: Datensätze mit hoher Semantik (6 Datensätze)
Eigenschaften: Merkmale enthalten reichhaltige Textbeschreibungen, kategorische Labels mit realer Bedeutung (z. B. „Ärztegebühren-Freeze“) oder domänenspezifische Terminologie.
- Datensätze:
- cylinder_bands: Industrielle Druckfehler.
- titanic: Passagiernamen und Titel.
- vote: Kongressabstimmungsprotokolle (Kategorisches „Ja/Nein“ zu Richtlinien).
- breast_cancer: Medizinische Tumorbeschreibungen.
- spambase: E-Mail-Worthäufigkeiten.
- wine: Chemische Ursprünge.
Cluster B: Gemischte Geschäftsdaten (6 Datensätze)
Eigenschaften: Das Standardtabellenformat, das in den meisten Unternehmensdatenbanken zu finden ist, eine Mischung aus numerischen Werten (Gehalt, Alter) und kategorischen Strings (Jobtitel, Rasse, Abteilung).
- Datensätze:
- employee_salaries: Jobtitel vs. Gehalt.
- compas: Kriminalgeschichte und Demografie (Sensible Attribute).
- adult_income: Volkszählungsdemografie.
- credit_g: Deutsche Kreditrisikoprofile.
- default_credit: Taiwaner Kreditausfalldaten.
- car_evaluation: Fahrzeugkaufparameter.
Cluster C: Daten mit geringer Semantik/reine numerische Daten (5 Datensätze)
Eigenschaften: Merkmale sind abstrakte Messungen, Sensorwerte oder physikalische Koordinaten. Die Spaltennamen sind oft unwichtig; nur die mathematischen Beziehungen zählen.
- Datensätze:
- higgs_100k: Physik-Teilchenkinematik.
- diamonds: Physikalische Abmessungen und Preis.
- sonar: Frequenzenergie-Rückstöße.
- california_housing: Lat/Long-Koordinaten und Volkszählungsstatistiken.
- house_sales: King County Immobilien (meist numerische Merkmale).
4. Tiefenanalyse: Wo SAP gewinnt vs. versagt
Die Anwendung des Analyse-Rahmenwerks auf unsere Ergebnisse zeigt vier verschiedene Leistungsmuster. Die folgende Tabelle fasst genau zusammen, wo SAP glänzt und wo es versagt.
Konzeptionelle Grundlagen relationaler fundamentaler Modelle
Das Hauptziel eines relationalen fundamentalen Modells ist es, genaue Vorhersagen zu treffen und diverse Aufgaben über strukturierte Tabellen hinweg durchzuführen. Diese Modelle müssen verstehen, wie Informationen über verschiedene Tabellen hinweg dargestellt werden, wie Entitäten durch Beziehungen verknüpft sind und wie zeitliche Informationen Ergebnisse beeinflussen.
Zu den Schlüsselkompetenzen solcher Modelle gehören:
- Schemageneralisierung: Die Fähigkeit, sich an neue relationale Schemata anzupassen, ohne von Grund auf neu trainiert zu werden.
- Einheitliche Eingabedarstellung: Handhabung verschiedener Spaltentypen wie numerische, kategorische und textuelle Merkmale.
- Integration von zeitlichem und strukturellem Kontext: Erfassung von Abhängigkeiten über die Zeit und zwischen Entitäten, die durch Primär- und Fremdschlüssel verknüpft sind.
- Übertragbarkeit: Durchführung von Vorhersageaufgaben auf neuen Datensätzen durch Vortraining und Zero-Shot-Lernen.
Griffin
Griffin ist einer der ersten groß angelegten Versuche, ein einheitliches relationales fundamentales Modell zu erstellen. Es stellt relationale Daten als temporales, heterogenes Graph dar, wobei jede Zeile ein Knoten wird und Kanten Fremdschlüsselbeziehungen entsprechen. Zu den Hauptmerkmalen gehören:
Einheitlicher Merkmals-Encoder
- Kategorische und Textmerkmale werden mit einem vortrainierten Text-Encoder kodiert, während numerische Werte einen gelernten Float-Encoder verwenden.
- Metadaten wie Tabellennamen, Spaltennamen und Kantentypen werden eingebettet, um dem Modell zu helfen, das relationale Schema zu erkennen.
- Task-Embeddings ermöglichen es einem einzelnen Modell, Regressions- und Klassifizierungsaufgaben mit gemeinsamen Decodern durchzuführen.
Nachrichtenübermittlung und Aufmerksamkeit
Griffin integriert Nachrichtenübertragungs-Neuronale Netze mit einem Cross-Attention-Modul. Die Nachrichtenübermittlungskomponente aggregiert Informationen innerhalb und über Relationen hinweg, während Cross-Attention sich auf relevante Zellen innerhalb jeder Zeile konzentriert. Dieses Design hilft dem Modell, mit verschiedenen Daten umzugehen und den Kontext zwischen verbundenen Entitäten beizubehalten.
Vortraining und Feinabstimmung
Das Modell wird auf Einzeltabellendatensätzen über eine Maskierte-Zellen-Vervollständigungsaufgabe vortrainiert und dann feinabgestimmt auf relationalen Datenbanken für spezifische Aufgaben. Experimente an großen relationalen Benchmarks zeigen, dass Griffin traditionelle GNN-Baselines und Einzeltabellenmodelle sowohl in der Genauigkeit als auch in der Effizienz des Transferlernens übertrifft.
Abbildung 1: Grafik, die das Griffin-Modell-Framework zeigt.1
Relationaler Transformer
Während sich Griffin auf Graph-Aggregation konzentriert, wendet der Relational Transformer (RT) Transformer-Architekturen direkt auf relationale Datenbanken an. Es behandelt jede Zelle als Token, das mit seinem Wert, Spaltennamen und Tabellennamen angereichert ist.
Eingabedarstellung
Jedes Token kombiniert:
- Ein Value-Embedding, das von seinem Datentyp (numerisch, Text oder Datum/Uhrzeit) abhängt.
- Ein Schema-Embedding wird aus dem Tabellen- und Spaltentext generiert.
- Ein Mask-Token wird verwendet, wenn der Wert während des Vortrainings versteckt ist.
Diese Struktur ermöglicht es RT, relationale Datenbanken mit verschiedenen Schemata zu verarbeiten, während ein konsistentes Eingabeformat beibehalten wird.
Relationale Aufmerksamkeit
RT führt einen relationalen Aufmerksamkeitsmechanismus ein, der auf Zellebene operiert. Dazu gehören:
- Spaltenaufmerksamkeit zum Erlernen von Werteverteilungen innerhalb von Spalten.
- Merkmal-Aufmerksamkeit zum Kombinieren von Attributen innerhalb derselben Zeile oder verknüpfter übergeordneter Zeilen.
- Nachbarn-Aufmerksamkeit zum Aggregieren von Informationen aus verbundenen untergeordneten Zeilen.
Zusammen bilden diese Aufmerksamkeitsschichten einen relationalen Graph-Transformer, der Abhängigkeiten über Zeilen, Spalten und Tabellen hinweg modelliert.
Trainings- und Transferergebnisse
RT wird auf relationalen Datenbanken aus RelBench vortrainiert. In Experimenten erreichte das vortrainierte Modell in Zero-Shot-Szenarien bis zu 94 % der Leistung vollständig überwachter Modelle. Es lernte auch schneller während der Feinabstimmung und benötigte weniger Trainingsschritte, um eine hohe Genauigkeit zu erreichen.2
Dieser Ansatz legt nahe, dass relationale Datenbanken übertragbare Muster über Domänen hinweg teilen und dass die Tokenisierung auf Zellebene eine praktische Grundlage für Vorhersageaufgaben auf strukturierten Daten bietet.
RelBench
RelBench wurde entwickelt, um das relationale Deep Learning voranzutreiben, das sich auf das End-to-End-Lernen aus Daten konzentriert, die über mehrere verwandte Tabellen in relationalen Datenbanken verteilt sind.
Da relationale Datenbanken nach wie vor das dominierende Datenverwaltungssystem in Industrie und Wissenschaft sind, bietet RelBench einen standardisierten und reproduzierbaren Rahmen zur Bewertung von Modellen, die direkt auf relationalen Strukturen operieren, anstatt sich auf manuelle Merkmalsflachung zu verlassen.
Frühere Versionen von RelBench führten 11 relationale Datenbanken ein, die Domänen wie Gesundheitswesen, soziale Netzwerke, E-Commerce und Sport abdecken, mit 70 Vorhersageaufgaben, die sowohl herausfordernd als auch domänenrelevant gestaltet sind.3
Im Januar 2026 wurde RelBench v2 veröffentlicht und fügte vier neue Datenbanken (SALT, RateBeer, arXiv und MIMIC-IV) sowie 40 zusätzliche Vorhersageaufgaben hinzu, einschließlich einer neuen Klasse von Autocomplete-Aufgaben, die Fähigkeit eines Modells bewerten, vorhandene Spalten innerhalb einer relationalen Datenbank vorherzusagen.
Das Release erweiterte auch den Datenzugriff durch CTU-Integration, ermöglichte den Zugriff auf mehr als 70 relationale Datensätze über ReDeLEx; fügte direkte SQL-Datenbankverbindlichkeit hinzu; und integrierte sieben Datensätze aus dem 4DBInfer-Repository im RelBench-Format.
Neben Datensätzen und Aufgaben bietet RelBench eine Open-Source-Referenzimplementierung für relationales Deep Learning auf Basis von Graph-Neuronalen Netzen, wobei PyTorch Geometric für die Graphkonstruktion und PyTorch Frame für tabellarische Modellierung verwendet wird, sowie eine öffentliche Rangliste, um den Fortschritt zu verfolgen.
Das v2-Release führte auch mehrere Verbesserungen der Benutzerfreundlichkeit und Leistung ein, einschließlich optionaler zeitlich zensierter Labels, Unterstützung der NDCG-Metrik bei der Link-Vorhersage, schnellere Generierung von Sentence-Embeddings und konfigurierbare Cache-Verwaltung.4
VIEIRA
VIEIRA verfolgt einen anderen Ansatz, indem es sich auf die Programmierung mit fundamentalen Modellen konzentriert, anstatt eine einzelne Vorhersagemaschine zu erstellen. Es erweitert den SCALLOP-Wahrscheinlichkeitslogik-Compiler mit einer deklarativen Sprache, die große Sprachmodelle, Vision-Modelle und andere vortrainierte Komponenten als fremde Prädikate integriert.5
Relationales Paradigma
In VIEIRA werden fundamentale Modelle als zustandslose Funktionen mit relationalen Eingaben und Ausgaben behandelt. Dies ermöglicht die Komposition von Modellen wie GPT, CLIP oder SAM gemäß logischen Regeln. Zum Beispiel:
- Ein Programm kann GPT verwenden, um Wissen aus Text zu extrahieren und es als strukturierte Relationen zu speichern.
- CLIP kann Bilder klassifizieren und sie mit Textlabels in einer Tabelle verknüpfen.
Anwendungen
Das Framework unterstützt:
- Datum- und Mathematik-Reasoning mit GPT.
- Verwandtschafts-Reasoning mit Textextraktion und logischem Schlussfolgern.
- Fragenbeantwortung, die Abruf und Schlussfolgern kombiniert.
- Visuelle Fragenbeantwortung und Bildbearbeitung durch multimodale Komposition.
Durch die Vereinheitlichung symbolischer Logik und neuronaler Inferenz ermöglicht VIEIRA Datenanalysten und Entwicklern, interpretierbare Systeme zu erstellen, die vortrainierte fundamentale Modelle verwenden, um Vorhersageabfragen über strukturierte Daten und Bilder zu beantworten.
Fallstudien
SAP Hana Cloud
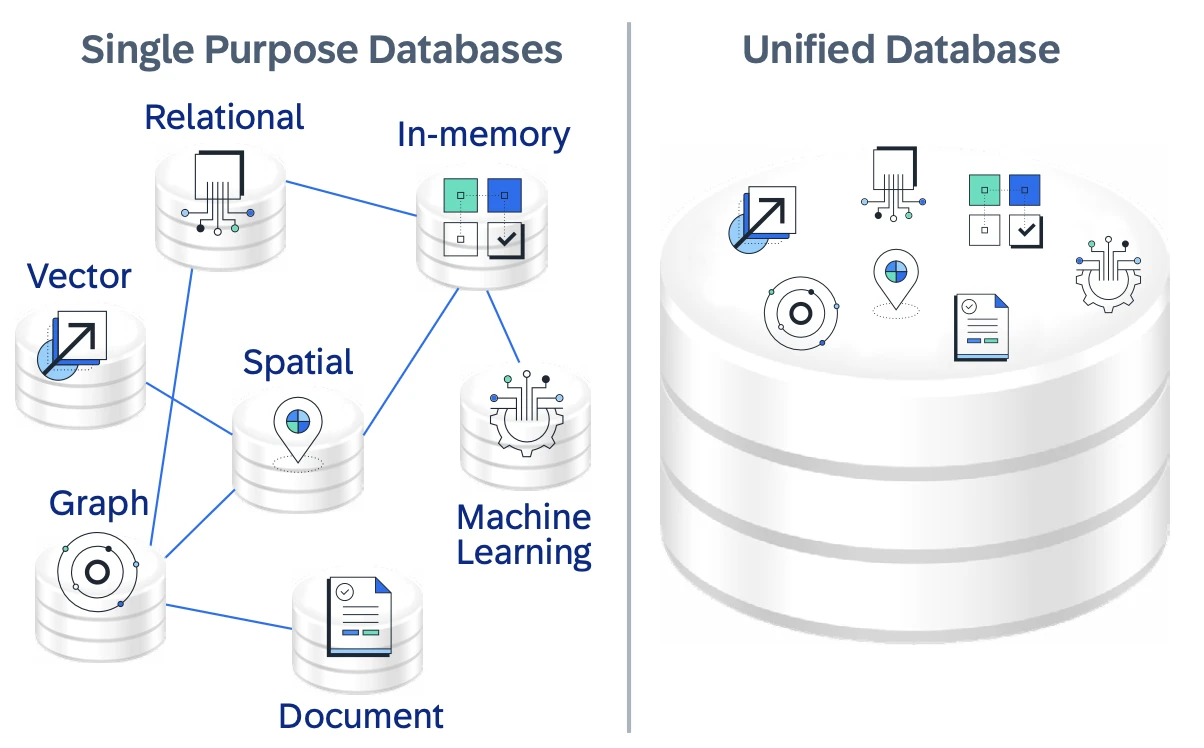
SAP HANA Cloud ist eine Cloud-native, vollständig verwaltete Datenbank als Dienst, die als einheitliche Datenbasis für Unternehmensanwendungen konzipiert ist, die Transaktionen, Analysen und KI kombinieren. Anstatt als einzelne relationale Datenbank zu dienen, ist SAP HANA Cloud als Multi-Model-Plattform positioniert, die es Organisationen ermöglicht, „intelligente Datenanwendungen“ auf operativen Geschäftsdaten aufzubauen.
SAP HANA Cloud kombiniert In-Memory-Verarbeitung mit plattenbasierter Speicherung und Data-Lake-Integration, um verschiedene Leistungs- und Kostenanforderungen zu unterstützen. Dieses flexible Design unterstützt Echtzeit-Workloads und skaliert dynamisch, wenn Datenvolumen und Nutzung schwanken.
Ein wichtiger Unterschied ist seine native Multi-Model-Engine, die relationale, JSON/Dokument-, Graph-, räumliche und Vektordaten innerhalb einer einzigen Datenbank unterstützt. Dies ermöglicht es Anwendungen, SQL-Abfragen, Graphbeziehungen und Vektorähnlichkeitssuche zu kombinieren, ohne Daten zwischen separaten Systemen zu verschieben, wodurch die Architektur vereinfacht und die Latenz reduziert wird.
Als Teil der SAP Business Technology Platform integriert sich SAP HANA Cloud direkt mit SAP- und Nicht-SAP-Datenquellen, einschließlich Live-Zugriff ohne Replikation, und bietet standardmäßig Sicherheit, Verfügbarkeit und Compliance auf Unternehmensebene.
Insgesamt ist SAP HANA Cloud eine relational-zentrierte, KI-native Datenplattform, bei der die relationale Datenbank als grundlegende Schicht für Analysen, Multi-Model-Daten und Unternehmens-KI-Anwendungen dient.
Abbildung 2: Bild, das Hanas einheitliche Datenbank und
Multi-Model-Datenverarbeitung zeigt.6
SAPs sap-rpt-1
sap-rpt-1 führt ein einzelnes relationales fundamentales Modell ein, das eine breite Palette von Vorhersageaufgaben durch In-Context-Lernen durchführt. Anstatt für jeden Anwendungsfall ein neues Modell neu zu trainieren, stellen Benutzer einige Beispiele ihres Zielmusters bereit, wie z. B. „Kunden, die pünktlich bezahlt haben“ und „Kunden, die spät bezahlt haben“. Das Modell erkennt dann das Muster und liefert sofort genaue Vorhersagen für neue Daten.
Das Modell ist mit einem zweidimensionalen Aufmerksamkeitsmechanismus entworfen, der Beziehungen über Zeilen und Spalten hinweg erfasst und Metadaten wie Tabellen- und Spaltennamen in Vektor-Embeddings einbettet. Dieses Design ermöglicht es ihm, die Semantik relationaler Schemata und die zeitlichen Informationen innerhalb von Geschäftstabellen zu verstehen.
SAPs Ansatz bringt mehrere Vorteile für Datenanalysten und Geschäftsanwender mit sich:
- Ein einzelnes Modell, das über mehrere Tabellen und Domänen hinweg funktioniert.
- Keine Notwendigkeit für wiederholte Feinabstimmung oder individuelle Entwicklung.
- Zugriff auf prädiktive Erkenntnisse in Minuten statt in Wochen.
- Integration mit bestehenden Data Warehouses und SAP-Systemen.
Durch die Einbettung von sap-rpt-1 in das SAP-Ökosystem können Geschäftsexperten direkt mit ihren eigenen Daten interagieren und Vorhersagen über intuitive Schnittstellen erhalten. Das Ergebnis ist ein schnellerer Weg von strukturierten Daten zu umsetzbaren Entscheidungen ohne manuelle Merkmalsentwicklung.
Abbildung 3: Fehlerreduktionsfaktor von sap-rpt-1-large gegenüber Narrow-KI-Baselines über SAP-Domänen hinweg.
Ende 2025 bestätigte SAP, dass SAP-RPT-1 über den generativen KI-Hub in SAP KI Foundation (SAP KI Core) allgemein verfügbar ist.
Das Modell wird in zwei Produktionsvarianten angeboten:
- SAP-RPT-1-small, optimiert für niedrige Latenz und hohe Durchsatzvorhersagen,
- SAP-RPT-1-large, entwickelt, um die prädiktive Genauigkeit zu priorisieren.
Diese Veröffentlichung formalisiert die Rolle von SAP-RPT-1 als einsetzbares fundamentales Modell innerhalb von SAPs Unternehmens-KI-Stack, anstatt eine reine Forschungsfähigkeit.
Zusätzlich bietet SAP den SAP-RPT Playground an, eine No-Code-, webbasierte Umgebung, in der Benutzer In-Context-Lernen mit eigenen oder von SAP bereitgestellten Beispieldaten testen können.
SAP-ABAP-1
SAP-ABAP-1 ist ein fundamentales Modell, das entwickelt wurde, um KI-basierte Produktivitätsanwendungsfälle für SAP-Kunden und -Partner zu unterstützen.
Es ist über den generativen KI-Hub von SAP verfügbar und wurde auf mehr als 250 Millionen Zeilen ABAP-Code, 30 Millionen Zeilen CDS-Code und umfangreicher technischer Dokumentation trainiert. Das Modell ist optimiert, um ABAP-Code zu verstehen und zu erklären, Best Practices aufzuzeigen und Zugang zu aktuellen SAP-Entwicklungswissen zu bieten.
SAP bietet kostenlosen Testzugang zu SAP-ABAP-1 über den generativen KI-Hub an, mit zusätzlichen Funktionen, die für 2026 geplant sind.7
Kumo.KI's KumoRFM: ein relationaler Graph-Transformer für prädiktive Analysen
Kumo.KI, gegründet von Stanford-Professor Jure Leskovec, schuf KumoRFM, ein relationales fundamentales Modell, das einen relationalen Graph-Transformer verwendet, um relationale Datenbanken und Data Warehouses zu analysieren. Es stellt relationale Daten als temporales, heterogenes Graph dar, wobei jede Entität ein Knoten ist und Primär- und Fremdschlüssel Kanten zwischen Tabellen bilden.
Dieser graphbasierte Ansatz ermöglicht es KumoRFM, gleichzeitig aus mehreren Tabellen zu lernen und sich an neue relationale Schemata anzupassen. Das Modell wird auf diversen Datenquellen vortrainiert und kann sich auf neue Datensätze verallgemeinern, ohne separate Modelle für jede Vorhersageaufgabe zu erstellen.
KumoRFM kann je nach Benutzerexpertise über verschiedene Schnittstellen verwendet werden:
- PQL (Predictive Query Language): Eine spezialisierte Abfragesprache zur Definition von Vorhersageabfragen auf strukturierten Daten.
- Natürliche Sprachschnittstelle: Für nicht-technische Benutzer werden natürliche Spracheingaben automatisch in PQL-Abfragen übersetzt.
- Python SDK: Ermöglicht Entwicklern die Integration des Modells in Unternehmens-KI-Pipelines und -Anwendungen.
KumoRFM-Architektur sampelt die Datenbank dynamisch, um Kontext-Subgraphen und Vorhersage-Subgraphen zu erstellen. Diese Subgraphen werden vom relationalen Graph-Transformer verarbeitet, der Abhängigkeiten und zeitliche Informationen über verwandte Entitäten hinweg erfasst. Durch In-Context-Lernen liefert das Modell genaue Vorhersagen und kann seinen Denkprozess erklären.
Kumo bietet zwei Bereitstellungsoptionen an, die für Unternehmensumgebungen geeignet sind:
- SaaS-Plattform: Ein cloudbasierter Dienst, der auf Apache Spark für einfachen Zugriff und Skalierung aufbaut
- Data Warehouse native: Ermöglicht es Organisationen, ihre eigenen Daten in Snowflake oder Databricks zu verwenden, ohne sie außerhalb ihrer sicheren Umgebung zu verschieben
Im Gegensatz zu traditionellen Wissensgraphen, die eine manuelle Schemadefinition erfordern, konstruiert KumoRFM seinen relationalen Graph automatisch aus strukturierten Quellen. Dies macht es gut geeignet für E-Commerce, Finanzen und Gesundheitswesen, wo Beziehungen, zeitliche Muster und sich entwickelnder Kontext für zuverlässige Vorhersagen entscheidend sind.
Zu den Schlüsselkompetenzen von KumoRFM gehören:
- Flexibilität über verschiedene Tabellen und Schemastrukturen hinweg.
- Kompatibilität mit einer Vielzahl von Spaltentypen und benutzerdefinierten Identifikatoren.
- Anpassung an spezifische Aufgaben zur Inferenzzeit.
- Hohe Genauigkeit und Interpretierbarkeit bei Vorhersageaufgaben.
Abbildung 4: Das Bild zeigt, wie Relationale Fundamentale Modelle (RFMs) über mehrere Domänen hinweg funktionieren, wie E-Commerce, Finanzen und Gesundheitswesen, um Vorhersagen zu treffen, Erklärungen zu liefern und Ergebnisse zu bewerten.8
Benchmark-Methodik
Benchmark-Setup & Umgebung
Um faire Vergleiche zwischen CPU-gebundenen Bäumen und GPU-beschleunigten Modellen zu gewährleisten, nutzten wir eine Hochleistungs-Umgebung, die beide effizient bewältigen konnte.
- Hardware: RunPod-Instanz mit einer NVIDIA H200 140GB GPU.
- Software: Python 3.12 mit fixierten Bibliotheken für Reproduzierbarkeit:
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Quelle: Offizielles GitHub)
- Reproduzierbarkeit: random_state=42 wurde konsistent über alle Aufteilungen, Initialisierungen und Modelle hinweg verwendet.
Datensätze: Das semantische Spektrum
Wir bewerteten die Modelle an 17 überwachten Lern-Datensätzen, die von OpenML und Scikit-Learn stammen. Anstatt eine zufällige Auswahl zu treffen, kuratierten wir diese Suite, um das „Semantisch-Numerische Spektrum“ abzudecken und die Hypothese zu testen, dass LLMs dort glänzen, wo Merkmale linguistische Bedeutung enthalten und nicht nur rohe Statistiken.
Das Inventar:
- Klein & semantisch (<1K Zeilen):
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Mittel/gemischt (1K – 10K Zeilen):
- credit_g (1K), titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Groß/numerisch (10K+ Zeilen):
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (auf 100K gesampelt).
Abgedeckte Aufgaben:
- 11 Binäre Klassifizierungsaufgaben
- 2 Multiklassen-Klassifizierungsaufgaben
- 4 Regressionsaufgaben
Modellkonfigurationen & Vorverarbeitung
Wir zielten auf einen realistischen „Praktiker-Vergleich“ ab, indem wir starke Standardwerte verwendeten, anstatt eine exhaustive Hyperparameter-Optimierung durchzuführen.
LightGBM & CatBoost
Um einen fairen Vergleich gegen das rechenintensive SAP-Modell zu gewährleisten, erhöhten wir die robusten Standard-Schätzer.
- LightGBM: n_estimators=500, learning_rate=0.05, num_leaves=31. Läuft auf CPU (n_jobs=-1).
- CatBoost: iterations=500, learning_rate=0.05, depth=6. Läuft auf GPU (task_type=„GPU“).
- Vorverarbeitung: Einfache Label-Kodierung für Kategorisches; keine Skalierung für Numerisches; Median/Modus-Imputation für fehlende Werte.
SAP-RPT-1-OSS
Wir konfigurierten SAP, um Leistung und Kosten basierend auf unseren vorläufigen Konfigurationsexperimenten auszugleichen.
- Konfiguration: max_context_size=4096, bagging=4.
- Hinweis:
- Kontext: Tests auf adult_income zeigten, dass die Erhöhung des Kontexts von 4096 auf 8192 die Laufzeit verdreifachte (4 min auf 12 min) für vernachlässigbaren Genauigkeitsgewinn (0,917 vs 0,917 ROC-AUC).
- Bagging: Die Erhöhung von bagging von 4 auf 8 (SAPs Standardeinstellung, die im Artikel verwendet wird9 ) bot abnehmende Grenzerträge.
- Vorverarbeitung: Keine. Das rohe pandas DataFrame wird direkt übergeben. Das Modell kodiert mit Text-Embeddings (sentence-transformers/all-MiniLM-L6-v2).
Evaluierungsprotokoll
Kreuzvalidierungsstrategie
Wir nutzten 3-Fach-Kreuzvalidierung mit Mischen.
- Wir reduzierten den Standard 5-Fach auf 3-Fach, um SAPs langsame Inferenzzeiten anzupassen (40 % Zeitersparnis) und gleichzeitig die statistische Gültigkeit aufrechtzuerhalten.
- Aufteilung: StratifiedKFold für Klassifizierung; Standard K-Fold für Regression.
Metriken & Diagnostik
Wir gingen über einfache Genauigkeit hinaus, um einen ganzheitlichen Blick auf die Modellleistung zu erfassen:
- Primäre Ranking-Metriken: ROC-AUC (Binär), Balanced Accuracy (Multiklasse), R² (Regression).
- Sekundäre Diagnostik: Wir verfolgten Matthews-Korrelationskoeffizient (MCC) und Log-Loss, um sicherzustellen, dass Gewinne keine Artefakte der Klassenungleichgewichte waren, und MAPE für die Regressionsfehlerkalibrierung.
- Kostenberechnung: Basierend auf der gesamten Wandzeit (Vorverarbeitung + Training + Inferenz) auf der RunPod H200-Instanz (3,59 $/Std.).
Statistische Signifikanz
Wir wandten einen Wilcoxon-Vorzeichen-Rang-Test (p<0,05) auf paarweise Modellvergleiche an, um festzustellen, ob Leistungsunterschiede statistisch signifikant oder zufälliges Rauschen waren.
Limitationen & interne Validität
Wir erkennen ausdrücklich die folgenden Einschränkungen in unserer Methodik an:
- Standardisierte Konfigurationen vs. Tuning: Wir nutzten feste, starke Standardkonfigurationen für alle Modelle, anstatt eine exhaustive Hyperparameter-Optimierung durchzuführen (z. B. verschachtelte CV oder Optuna-Sweeps). Obwohl dies eine konsistente Basislinie gewährleistet, ist es erwähnenswert, dass Baummodelle oft Leistungsgewinne mit datensatzspezifischem Tuning sehen, was die Spannen im „Wettbewerbsfähigen“ Cluster verengen könnte.
- Datenskala-Grenzen: Unsere Analyse konzentrierte sich auf Datensätze unter 100k Zeilen, um typische mittelgroße Unternehmensszenarien zu simulieren. Wir beobachteten, dass der Vorteil des LLM mit zunehmendem Datenvolumen schwindet, aber wir haben die Tests nicht auf Millionenzeilen-Skalen ausgedehnt, wo Inferenzlatenz und Kosten wahrscheinlich die primären Einschränkungen wären.
- Infrastruktur-Einheitlichkeit: Um eine konsistente Testumgebung aufrechtzuerhalten, führten wir alle Modelle auf derselben NVIDIA H200-Hardware aus. LightGBM und CatBoost sind stark für handelsübliche CPUs optimiert; daher wäre in einer Produktionsumgebung, die ausschließlich Baummodellen gewidmet ist, der Kostenunterschied wahrscheinlich größer.
- Generalisierung über Semantik hinaus: Unsere „Semantische Spektrum“-Hypothese sagte viele Ergebnisse erfolgreich voraus, aber die starke Leistung des LLM bei abstrakten Datensätzen wie sonar und california_housing deutet auf Fähigkeiten jenseits des linguistischen Verständnisses hin. Dies zeigt, dass das Modell möglicherweise auch hochdimensionale Regularisierungsmuster nutzt, ein Phänomen, das eine weitere Untersuchung über den Rahmen dieser ersten Studie hinaus erfordert.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{Vergleich relationaler Fundamentaler Modelle}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Abgerufen am 2. Juli 2026}
}


 über mehrere Domänen hinweg funktionieren.")
Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.