Web Sitelerini Yapay Zekaya Beslemek İçin Web Crawler Benchmark
Üç farklı zorluk seviyesinde alan adı üzerinde üç maksimum derinlik seviyesinde (5, 10, 20) ve 1.000 sayfa sınırıyla dört tarama API'sini karşılaştırdık; tarama kapsamını, yürütme süresini, bağlantı keşfini, markdown bağlantı kalitesini ve başlık çıkarma doğruluğunu ölçtük.
Eğer amacınız:
- Web sayfalarını yapılandırılmış veriye dönüştürmekse, web kazıma rehberimize bakın.
- Tüm web sitelerini taramaksa, okumaya devam edin.
Web crawlers benchmark
benchmark metodolojimizi okuyabilirsiniz.
Ortalama taranan sayfalar ile 1.000 sayfa başına maliyet
Maksimum derinliğe göre alan adları boyunca taranan sayfalar
Firecrawl, maksimum derinlikten bağımsız olarak theregister.com'da yaklaşık 100 sayfayı, tüm derinlik seviyelerinde entrepreneur.com'da yaklaşık 90 sayfayı ve Amazon'un agresif bot koruması nedeniyle muhtemelen amazon.com'da sadece yaklaşık 30 sayfayı tutarlı bir şekilde taradı. Dikkat çekici olarak, maksimum derinliği artırmak, herhangi bir alanda Firecrawl'ın tarayabildiği sayfa sayısında neredeyse hiçbir etkiye sahip olmadı.
Apify, en tutarlı performansı sergiledi; Amazon gibi yoğun korumalı sitelerde bile herhangi bir zorluk yaşamadan her derinlik seviyesinde her alanda 1.000 sayfalık maksimum tarama sınırına ulaştı.
Cloudflare, testler arasında tutarsız davranış sergiledi:
- theregister.com'da maksimum derinlik 5'te sadece 100 sayfa taradı, ancak maksimum derinlik 20'de neredeyse 1.000 sayfaya ulaştı.
- Daha önceki testlerde gözlemlediğimiz gibi, Cloudflare ara sıra sadece 1 sayfa tarar ve ardından görevi tamamen sonlandırır. Bunun bir önbellekleme sorunu olmadığını (önbellek devre dışı bırakıldı) doğruladık ve çalıştırmalar arasında 1 dakikaya kadar bekleme süreleriyle test ettik, ancak davranış devam etti. theregister.com'da maksimum derinlik 10'da bu tam sorun ortaya çıktı, Cloudflare durmadan önce sadece 1 sayfa taradı.
- entrepreneur.com'da Cloudflare, derinlik 5'te 780 sayfa taradı, derinlik 10'da 885'e yükseldi, ancak derinlik 20'de keskin bir şekilde sadece 172 sayfaya düştü. Bu düşüş, Cloudflare'in tarama zamanlayıcısının daha derin bağlantı zincirlerini önceliklendirmemesi veya zaman aşımına uğramasıyla veya tarama sınırının daha yüksek derinliklerde çok büyüdüğünde görevin erken sonlanmasına neden olan dahili bir eşzamanlılık sınırıyla ilişkili olabilir.
- amazon.com'da Cloudflare, derinlik 5'te 905 sayfa taradı, ancak sayı maksimum derinlik arttıkça istikrarlı bir şekilde azaldı, derinlik 10'da 809'a ve derinlik 20'de 795'e düştü; bu da daha derin tarama yapılandırmalarının Cloudflare'in gerçek sayfa alımından ziyade bağlantı keşfi yüküne daha fazla zaman harcamasına neden olabileceğini gösteriyor.
Nimble, theregister.com'da tüm derinlik seviyelerinde (1.000 / 1.000 / 999) 1.000 sayfa sınırına ulaştı veya yaklaştı. entrepreneur.com'da, derinlik 5'te 1.000 sayfa taradı ancak daha yüksek derinliklerde hafif düşüşler gösterdi (derinlik 10'da 896, derinlik 20'de 983), muhtemelen 7 saatlik zaman aşımının daha derin seviyelerde tam taramayı tamamlamadan önce gerçekleşmesi nedeniyle, tüm Nimble çalışmaları zaman aşımı durumuyla sonlandı. Amazon daha zorlayıcı oldu:
- Derinlik 5'te sadece 319 sayfayı yönetti, ancak derinlik 10'da 988 sayfaya sıçradı, ardından derinlik 20'de 906'ya düştü
- Bu tutarsızlık, muhtemelen Amazon'un bot koruma mekanizmaları ve Nimble'ın zaman aşımı kısıtlamalarının birleşimini yansıtıyor; daha derin taramalar her sayfayı işlemek için daha uzun sürer ve yolda daha fazla anti-bot zorlukla karşılaşabilir
Maksimum derinliğe göre alan adları boyunca yürütme süresi
Firecrawl, tüm alan adlarında en hızlı sağlayıcıydı, taramaları 5 dakikanın altında, tipik olarak 75-265 saniye arasında tamamladı. Bu hız, Firecrawl'ın aynı zamanda en az sayfayı taradığı için kapsam pahasına gelir. Esasen, erken durduğu için hızlı bitirir.
Apify, theregister.com'da derinlikten bağımsız olarak yaklaşık 2.200-2.400 saniye (~40 dakika) sürdü. entrepreneur.com ve amazon.com'da, yürütme süreleri daha büyük ve karmaşık site yapılarını yansıtarak 8.300-15.900 saniye (2-4 saat) arasında önemli ölçüde daha uzundu. Daha uzun sürelere rağmen, Apify tutarlı bir şekilde 1.000 sayfa sınırına ulaştı, kapsam-zaman oranı açısından en güvenilir olanı yaptı.
Cloudflare, tutarsız tarama sayılarını yansıtan zamanlamalar gösterdi:
- theregister.com'da derinlik 10'da, durmadan önce sadece 1 sayfa taradığı için sadece 1 saniyede tamamlandı.
- entrepreneur.com'da derinlik 20'de, sadece 172 sayfayı taradıktan sonra 10 saniyede bitti.
- Cloudflare tam bir taramayı tamamladığında, süreler 3.500 ila 25.200 saniye arasında değişir.
- Maksimum derinlik arttıkça, Cloudflare genişlikten ziyade daha derin sayfalara ulaşmayı önceliklendirmeye başlar, daha az sayfa tarar ancak daha hızlı tamamlar. amazon.com'da, yürütme süresi derinlik 5'te 25.200 saniyeden (zaman aşımı) derinlik 20'de sadece 5.660 saniyeye düştü, taranan sayfalar da 905'ten 795'e azaldı. Bu, Cloudflare'in tarayıcısının daha yüksek derinliklerde stratejisini değiştirdiğini, geniş keşiften ziyade derin gezinmeye daha fazla zaman harcadığını gösteriyor.
Nimble, tüm alan adlarında ve derinlik seviyelerinde her tek çalışmada 7 saatlik zaman aşımına (25.200 saniye) ulaştı. Bu dikkat çekicidir çünkü daha önceki maksimum derinlik 1 ile hızlı testlerimizde Nimble zaman aşımına uğramadan tamamlandı. 5-20 derinlikleri ve 1.000 sayfa sınırına sahip tam benchmark'ta, zaman aşımına ulaşana kadar tutarlı bir şekilde çalıştı. Buna rağmen, Nimble çoğu durumda hala yüksek sayıda sayfa taradı (~theregister.com ve entrepreneur.com'da 900-1.000), yani 7 saat boyunca aktif olarak tarıyor ancak basitçe tamamlanma sinyali vermiyor.
Maksimum derinliğe göre sağlayıcılar arasında bağlantı metni doluluk oranı
Markdown çıktı kalitesini değerlendirmek için, her sağlayıcının markdown'ındaki bağlantıların ne kadarının çapa metni (bağlantının tıklanabilir metin kısmı) içerdiğini ölçtük. Eksik çapa metni (örneğin, [About Us](/about) yerine [](/about)), tarayıcının bağlantının etiketini çıkarmayı başaramadığı anlamına gelir.
- Nimble: Tüm derinliklerde %100
- Cloudflare: %91-94
- Firecrawl: %90
- Apify: %77-78, yaklaşık 5 bağlantıda 1'i çapa metni eksik
Tarama derinliği, herhangi bir sağlayıcı için doluluk oranlarını minimal düzeyde etkiledi, bu da bunun bir tarama ayarı yerine her sağlayıcının ayrıştırma motorunun bir özelliği olduğunu gösteriyor.
Alan adlarına göre sağlayıcılar arasında bağlantı metni doluluk oranı
Farklı alan adlarındaki doluluk oranlarına bakmak, site karmaşıklığının her sağlayıcının bağlantı çıkarma kalitesini nasıl etkilediğini ortaya koyar.
- Nimble, tüm alan adlarında %100 korudu.
- Apify, en fazla varyasyonu gösterdi, amazon.com'da %89 ancak entrepreneur.com'da %66'ya düştü, yani o sitedeki bağlantılarının üçte biri çapa metni eksikti. Bu, Apify'ın karmaşık gezinme yapılarına sahip içerik yoğun sitelerle daha fazla mücadele ettiğini gösteriyor.
- Firecrawl, theregister.com'da (%98) en iyi performansı gösterdi ancak entrepreneur.com'da %81'e düştü, Apify'a benzer bir desen izledi.
- Cloudflare, Nimble'dan sonra en tutarlı olanıydı, alandan bağımsız olarak %89-94 arasında kaldı.
Entrepreneur.com, bağlantı metni çıkarma için en zorlayıcı alan oldu, hem Apify (%66) hem de Firecrawl (%81) en düşük puanlarını orada aldı, muhtemelen sitenin temiz bir şekilde markdown'a dönüştürülmesi daha zor olan iç içe geçmiş gezinme menülerinin ve dinamik içerik öğelerinin yoğun kullanımı nedeniyle.
Maksimum derinliğe göre alan adları boyunca markdown çıktısındaki toplam bağlantılar
Sağlayıcılar arasındaki bağlantı sayısı varyansı tutarlı bir şekilde yüksekti (%74-97), bu da sağlayıcıların aynı sayfalardan çok farklı sayıda bağlantı çıkardığını gösteriyor. Bu farklılığa daha detaylı bir bakış elde etmek için, sağlayıcı başına toplam markdown bağlantı sayısını ölçtük.
- Apify, özellikle amazon.com'da derinlik 5'te 420K'dan fazla bağlantı (~sayfa başına ~423) ile genel olarak en fazla bağlantıyı döndürdü. entrepreneur.com'da derinlikten bağımsız olarak 63K civarında stabilize oldu. Çıktısı, sayfa içeriği bağlantılarının yanı sıra reklam takipçilerini ve takip piksellerini içerir.
- Cloudflare, entrepreneur.com'da derinlik 10'da 303K'ya ulaştı ancak derinlik 20'de 53K'ya düştü. Aynı entrepreneur.com ana sayfasında, Cloudflare, Apify'ın 143'üne kıyasla 434 bağlantı çıkardı, tam gezinme menülerini ve alt menüleri yakaladı.
- Firecrawl, düşük sayfa sayısı ile sınırlı olarak tüm yapılandırmalarda tutarlı bir şekilde 5-9K bağlantı döndürdü.
- Nimble, toplam 3-40K bağlantı döndürdü, diğer sağlayıcıların 60-420'sine kıyasla sayfa başına ortalama 5-28 bağlantı. entrepreneur.com'un ana sayfasında, Nimble, ana makale başlıkları ile sınırlı olarak Cloudflare'in 434'üne karşı 13 bağlantı döndürdü. %100 doluluk oranı, dahil ettiği bağlantıların tamamının çapa metnine sahip olduğunu, kapsamlı bağlantı kapsamını göstermekten ziyade yansıtır. Nimble standart markdown bağlantıları çıkarmaz. Sayısı, markdown çıktısı içinde bulunan kaçış HTML bağlantılarını içerir.
Sağlayıcılar arasında başlık varlık oranı
Sağlayıcılar arasındaki başlık benzerliği, tüm testlerde ve alan adlarında %1'den az sapma gösterdi, sağlayıcılar bir başlık çıkardıklarında tutarlı bir şekilde aynı sonucu döndürdüğünü doğruladı. Başlık varlık oranı da tüm maksimum derinlik seviyelerinde %98-100 arasında kaldı, tarama derinliğinin başlık çıkarma üzerinde anlamlı bir etkisi olmadığını gösterdi.
Alan adlarına göre ayrıldığında, bazı farklar ortaya çıktı:
entrepreneur.com ve theregister.com'da, çoğu sağlayıcı %99-100 başlık varlık oranlarına ulaştı. amazon.com, anlamlı farkların ortaya çıktığı tek alan oldu, Firecrawl %93'e ve Nimble %95,9'a düştü, Apify ise %99,6'yı korudu. Bu, Amazon'un daha ağır bot korumasıyla uyumludur, bu da sayfa yanıtlarını engelleyebilir veya bozabilir, bazı sağlayıcıların çıkarılabilir başlıklar olmadan sayfalar döndürmesine neden olur.
Web crawler nedir?
Bazen "örümcek" veya "ajan" olarak da adlandırılan bir web crawler, içeriği indekslemek için interneti gezen bir bottur.
Crawler'lar arama motorlarının ötesine geçti ve artık Ajan Veri Katmanı olarak hizmet veriyor. Claude Code ve OpenAI Operator gibi otonom yapay zeka ajanları için gözler olarak hareket ediyorlar, rekabetçi araştırma ve çok adımlı işlemler gibi gerçek zamanlı görevlere yardımcı oluyorlar.
Web crawler ne yapar?
Web tarama, her biri farklı bir crawler hedefi için tasarlanmış üç moda ayrıldı.
- Keşif modu (geleneksel): Googlebot gibi arama motoru botları, indeksleme için URL'leri tarar, insanların arama motorları aracılığıyla sonuç bulmasına yardımcı olur.
- Getirme Modu (RAG): ChatGPT-User veya PerplexityBot gibi yapay zeka botları, kullanıcı isteklerine yanıt vermek için gerçek zamanlı olarak belirli sayfaları getirir. Yapay zeka modelinin token limitlerine uymak için HTML yerine markdown kullanırlar.
- Ajan Modu (Eylem Odaklı): 2026'daki bu yeni tarama türü, sadece içeriği okumaktan fazlasını yapar. Model Bağlam Protokolü (MCP) kullanarak, bu botlar uçak biletleri almak veya yazılım komutları çalıştırmak için web siteleriyle etkileşime girebilir.
Geçmişte, crawler'lar veri çıkarmak için XPath veya CSS gibi seçiciler kullanıyordu. AI-Native Extraction norm haline geldi.
Firecrawl ve Crawl4AI gibi araçlar, veri bulmak için doğal dil talimatları kullanır. Her öğe için kurallar yazmak yerine, geliştiriciler crawler'a "ürün fiyatını çıkar" diyebilir ve yapay zeka, web sitesinin kodu değişse bile doğru değeri bulacaktır.
Yapay zeka çağında web crawler'ları inşa etmek mi yoksa satın almak mı
1. Kendi Crawler'ınızı İnşa Etmek
Temel fikri mülkiyeti korumak ve derin özelleştirmeyi etkinleştirmek için idealdir. Şimdi inşa etmek, temel Scrapy komut dosyaları yazmak yerine, özel bir ajan katmanı geliştirmeyi gerektirir.
- Ne zaman inşa edilmeli: Crawler'ınız benzersiz bir rekabet avantajı sağlıyorsa bu yaklaşımı seçin. Örneğin, özel bir arama motoru geliştiriyorsanız veya hassas veya düzenlenmiş veriler üzerinde tam kontrol gerekiyorsa kendi crawler'ınızı inşa edin.
- Araç seti: Sıfırdan başlamanıza artık gerek yok. Geliştiriciler artık web ile etkileşime girmek için dahili yapay zeka ajanlarını etkinleştirmek üzere Model Bağlam Protokolü'nden (MCP) yararlanıyor.
2. Web Tarama Araçları ve API'leri Kullanmak
Yönetilen araçlar, temel kazıyıcılardan otonom ajanlara gelişti.
- Sıfır-bakım çıkarma: Kadoa ve Firecrawl gibi modern araçlar, kendini onaran yapay zeka kullanır. Kod içindeki konumundan ziyade "Ürün Fiyatı" gibi gerekli veriyi belirtirsiniz. Web sitesi düzeni değişirse, araç otomatik olarak uyum sağlar.
- Hizmet olarak uyumluluk: Birçok sağlayıcı, AB Yapay Zeka Yasası ile yerleşik uyumluluk sunar. Bağımsız olarak uygulaması zor olan gerekli denetim günlüklerini ve telif hakkı çıkartma kontrollerini yönetirler.
- Değere hız: Bir platform satın almak, projenizi haftalar içinde kavramdan üretime taşıyabilir.
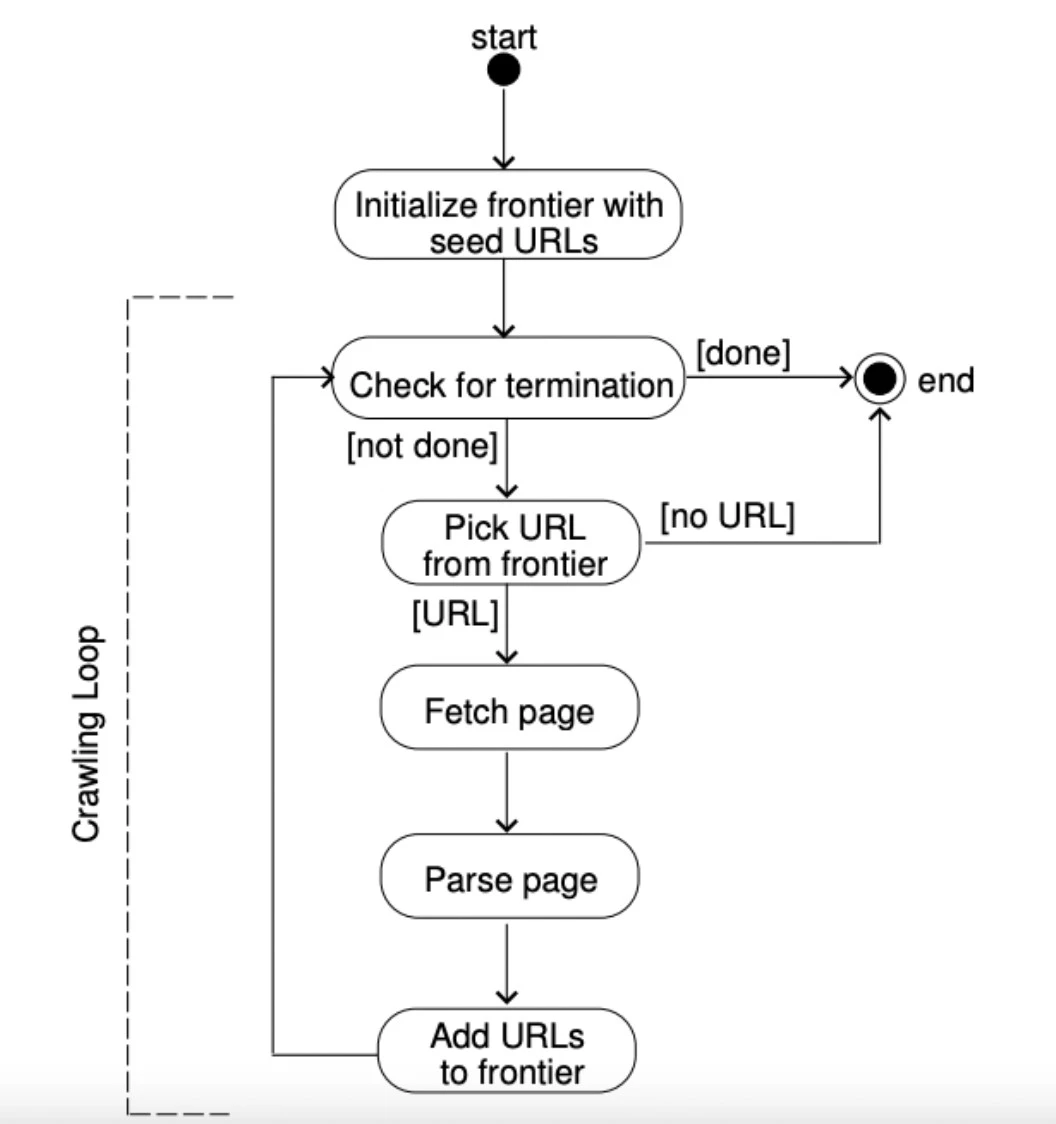
Şekil 5: Bir URL sınırının nasıl çalıştığının açıklaması.
Web crawler'lar yasal mı?
Genel olarak, web tarama yasaldır, ancak nasıl ve ne tarama yaptığınıza bağlı olarak hızla yasal bir sıkıntıya girebilirsiniz. Taramanın (ve genellikle takip eden kazımanın) yasal olup olmadığını belirleyen dört büyük sütun vardır:
1. Genel vs. özel: Hesap olmadan halka açık olarak erişilebilir olan verileri tarayın.
2. Kişisel bilgiler: Yasal bir temeliniz olmadığı sürece PII'den (isimler, e-postalar ve adresler) kaçının.
3. Sunucu sağlığı: Sunucuyu yavaşlatmaktan kaçınmak için hız sınırlarını kullanın; bir web sitesini "DDOSlamaktan" kaçının.
4. Telif Hakkı: Makaleler ve görseller telif hakkı ile korunur, ancak gerçekler (fiyatlar, tarihler) korunmaz.
Web tarama ve web kazıma arasındaki fark nedir?
Web kazıma, hedeflenen bir web sayfasından tüm içeriği taramak ve depolamak için web crawler'larını kullanmaktır. Başka bir deyişle, web kazıma, yatırım analizi için tüm finans haberlerini çekmek veya belirli şirket isimlerini aramak gibi hedeflenmiş bir veri seti oluşturmak için web taramanın belirli bir kullanım durumudur.
Geleneksel olarak, bir web crawler web sayfasının tüm öğelerini tarayıp indeksledikten sonra, bir web kazıyıcı indekslenmiş web sayfasından veri çıkarırdı. Ancak bu günlerde kazıma ve tarama terimleri, crawler'ın daha çok arama motoru crawler'larına atıfta bulunduğu farkıyla birbirinin yerine kullanılıyor. Arama motorları dışındaki şirketler web verilerini kullanmaya başladıkça, web kazıyıcı terimi web crawler teriminin yerini almaya başladı.
Web taramanın zorlukları nelerdir?
1. Veritabanı tazelik
Web sitelerinin içeriği düzenli olarak güncellenir. Örneğin, dinamik web sayfaları, ziyaretçilerin aktivitelerine ve davranışlarına göre içeriklerini değiştirir. Bu, web sitesini taradıktan sonra web sitesinin kaynak kodunun aynı kalmadığı anlamına gelir. Kullanıcıya en güncel bilgiyi sağlamak için web crawler, bu web sayfalarını daha sık yeniden taramalıdır.
2. Crawler tuzakları
Web siteleri, web crawler'ların belirli web sayfalarına erişmesini ve taramasını engellemek için crawler tuzakları gibi farklı teknikler uygular. Bir crawler tuzağı veya örümcek tuzağı, bir web crawler'ın sonsuz sayıda istek yapmasına ve kötü bir tarama döngüsünde sıkışmasına neden olur. Web siteleri aynı zamanda istemeden crawler tuzakları oluşturabilir. Her durumda, bir crawler bir crawler tuzağı ile karşılaştığında, crawler'ın kaynaklarını israf eden bir sonsuz döngüye benzer bir şeye girer.
3. Ağ Bant Genişliği
Çok sayıda alakasız web sayfasını indirmek, dağıtık bir web crawler kullanmak veya birçok web sayfasını yeniden taramak, yüksek bir ağ kapasitesi tüketim oranına yol açar.
4. Yinelenen sayfalar
Web crawler botları çoğunlukla web'deki tüm yinelenen içeriği tarar; ancak, bir sayfanın sadece bir versiyonu indekslenir. Yinelenen içerik, arama motoru botlarının yinelenen içeriğin hangi versiyonunu indeksleyip sıralayacağını belirlemesini zorlaştırır. Googlebot arama sonucunda bir grup özdeş web sayfası keşfettiğinde, bunlardan sadece birini indeksler ve bir kullanıcının arama sorgusuna yanıt olarak göstermek için seçer.
En iyi 3 web tarama uygulaması
1. Nezaket/Tarama hızı
Web siteleri, web crawler botları tarafından yapılan istek sayısını sınırlamak için bir tarama hızı belirler. Tarama hızı, bir web crawler'ın belirli bir zaman aralığında (örneğin, saatte 100 istek) web sitenize kaç istek yapabileceğini gösterir. Bu, web sitesi sahiplerinin web sunucularının bant genişliğini korumalarına ve sunucu aşırı yüklenmesini azaltmalarına olanak tanır. Bir web crawler, hedef web sitesinin tarama sınırına uymalıdır.
2. Robots.txt uyumluluğu
Bir robots.txt dosyası, bir web sitesinin köküne yerleştirilen ve crawler'lara hangi sayfalara erişmelerine izin verildiğini veya yasaklandığını bildiren bir metin dosyasıdır. Bu, gönüllü bir standarttır, yani uyumlu botlar buna saygı duyar ancak teknik olarak erişimi engellemez. Bir web sitesinin robots.txt'sine uymak, iyi bir uygulama olarak kabul edilir ve birçok yargı alanında, görmezden gelmek sizi yasal veya itibar riskine maruz bırakabilir.
3. IP rotasyonu
Web siteleri, crawler trafiğini yönetmek ve web kazıma faaliyetlerini azaltmak için farklı anti-kazıma teknikleri (CAPTCHA'lar gibi) uygular. Örneğin, tarayıcı parmak izi, ziyaretçiler hakkında oturum süresi veya sayfa görüntülemeleri gibi bilgiler toplamak için web siteleri tarafından kullanılan bir takip tekniğidir.
Bu yöntem, web sitesi sahiplerinin "insan dışı trafiği" tespit etmesine ve botun IP adresini engellemesine olanak tanır. Tespitten kaçınmak için, web crawler'ınıza döndürmeli proxy'ler, örneğin konut proxy'lerini entegre edebilirsiniz.
Web crawlers benchmark metodolojisi
Üç farklı zorluk seviyesinde alan adı üzerinde dört tarama API'sini (Apify, Nimble, Cloudflare, Firecrawl) test ettik: amazon.com (ağır bot koruması), entrepreneur.com (karmaşık içerik sitesi) ve theregister.com (haber sitesi).
Paylaşılan yapılandırma
Tüm sağlayıcılar adil bir karşılaştırma sağlamak için aynı temel ayarları aldı:
- Sitemap: Devre dışı, sağlayıcılar sadece HTML bağlantıları aracılığıyla sayfaları keşfetmelidir
- Dış bağlantılar: Devre dışı, crawler'lar hedef alan içinde kalır
- Alt alan adları: Etkin, alt alan sayfaları takip edilir (örneğin, india.entrepreneur.com)
- JavaScript render: Etkin, tüm sağlayıcılar bir headless tarayıcı kullanır
- Önbellek: Devre dışı
- Sayfa sınırı: Çalışma başına 1.000 sayfa
- Zaman aşımı: 7 saat (25.200 saniye)
- Hız sınırı yönetimi: HTTP 429'da 20 saniyelik bekleme ve en fazla 3 tekrar
Her sağlayıcı, tüm üç alanda üç maksimum derinlik seviyesinde (5, 10, 20) test edildi, toplam 36 tarama çalışması. Sağlayıcılar ardışık olarak (paralel olarak değil) test edildi, her kombinasyon bir kez çalıştırıldı ve tarama durumu her 1 saniyede bir sorgulandı.
Apify, headless tarayıcı olarak Playwright/Firefox kullanan website-content-crawler aktörü ile yapılandırıldı. Alt alan erişimi glob desenleri aracılığıyla kontrol edildi ve tüm istekler için Apify'ın yerleşik proxy'si kullanıldı.
Nimble, Cloudflare ve Firecrawl, yukarıda açıklanan paylaşılan ayarlarla respective REST API'leri kullanılarak yapılandırıldı. Standartlaştırılmış parametrelerin ötesinde ek sağlayıcıya özel yapılandırmalar uygulanmadı.
Cloudflare için, Workers Paid planını kullandık. Bildirilen maliyet, bu plan altında 1.000 sayfayı taramak için harcadığımızı yansıtır. Cloudflare, sayfa sayısı yerine tarayıcı render süresine göre ücret alır.
Firecrawl için, Hobby planını kullandık. Bildirilen maliyet, bu planda sağlanan kredilerden 1.000 kredi için orantılı miktardır. Sayfa başına etkili maliyet, plan seviyesine ve ekstra kredi paketleri satın alınıp alınmadığına bağlı olarak değişir.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Web Sitelerini Yapay Zekaya Beslemek İçin Web Crawler Benchmark}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Erişim tarihi: 2 Temmuz 2026}
}
Yorumlar 1
Düşüncelerinizi Paylaşın
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.