20 Yapay Zeka İyileştirme Stratejileri ve Örnekler
Yapay zeka modelleri, veri, kullanıcı davranışı ve gerçek dünya koşulları değiştikçe sürekli iyileştirme gerektirir. İyi performans gösteren modeller bile, öğrendikleri kalıplar artık mevcut girdilerle eşleşmediğinde sapma gösterebilir, bu da doğruluğun azalmasına ve güvenilmez tahminlere yol açar.
Düzenlemelerdeki, ürün gereksinimlerindeki veya müşteri beklentilerindeki değişiklikler, mevcut modellerin başa çıkmak üzere tasarlanmadığı yeni kısıtlamalar getirebilir.
Bu nedenle model kalitesini korumak, hem modeli destekleyen veriyi hem de davranışını şekillendiren algoritmaları güçlendirmeyi, böylece sistemlerin güncel gereksinimlerle uyumlu kalmasını ve güncelliğini yitirmiş varsayımlara dayanmamasını sağlamayı içerir.
Anahtar stratejileri keşfedin: veri besleme, veri ve algoritma iyileştirme ve yapay zeka modellerinizin güncel ve pratik kalmasını sağlayacak yapay zeka ölçekleme yasaları.
Yapay zeka modelinizi iyileştirmenin en iyi 20 yolu
Yapay zeka modelinizi geliştirme yöntemlerini 4 farklı kategoride açıkladık:
Yöntem | Açıklama | Temel Zorluklar |
|---|---|---|
Daha fazla veri besleme | Kapsamı ve genellemeyi iyileştirmek için yüksek kaliteli gerçek veya sentetik veri ekleyin. | Veri kalitesini sağlama, önyargıdan kaçınma, gizlilik ve erişim sınırlamalarını yönetme. |
Veriyi iyileştirme | Gürültüyü ve önyargıyı azaltmak için etiketleme, çeşitlilik ve artırmayı geliştirin. | Kalite ve miktar dengesini sağlama, veri kümesi önyargısını azaltma, etiketlemeleri tutarlı tutma. |
Algoritmayı iyileştirme | Daha iyi mimariler, ince ayar teknikleri ve dağıtım uygulamaları kullanın. | Daha yüksek karmaşıklık ve maliyet, istenmeyen davranışlar, katı gizlilik gereksinimleri. |
Yapay zeka ölçekleme yasaları | Ölçek, hesaplama, verimlilik ve geri alma veya çoklu ajan tekniklerini artırın. | Azalan getiriler, hesaplama sınırları, çevresel etki, entegrasyon karmaşıklığı. |
Daha fazla veri besleme
Yeni ve güncel veri eklemek, makine öğrenimi modelinizin doğruluğunu artırmanın en yaygın ve etkili yöntemlerinden biridir. Araştırmalar, veri kümesi boyutu ile yapay zeka modeli doğruluğu arasında pozitif bir korelasyon olduğunu göstermiştir.1
Bu nedenle, modelin yeniden eğitilmesi için kullanılan veri kümesini genişletmek, yapay zeka/ML modellerini iyileştirmenin etkili bir yolu olabilir. Verilerin, dağıtıldığı ortama göre değişmesini sağlamak önemlidir. Ayrıca uygun veri toplama kalite güvence uygulamalarına uymak da gereklidir.
1. Veri toplama
Veri toplama/hasat, veri kümenizi genişletmek ve yapay zeka/ML modeline daha fazla veri beslemek için kullanılabilir. Bu süreçte, modeli yeniden eğitmek için yeni veriler toplanır. Bu veriler aşağıdaki yöntemlerle toplanabilir:
- Özel toplama
- Otomatik veri toplama
- Özel kitle kaynak kullanımı
Yapay zeka için veri toplamayı başarılı bir şekilde gerçekleştirmek için işletmelerin şunlara dikkat etmesi gerekir:
- Etik sorunlardan kaçınmak için veri toplamada etik ve yasal hususlara saygı gösterilmelidir.
- Eğitim verisindeki önyargı, istenmeyen yapay zeka sonuçlarına yol açabilir.
- Yapay zeka/ML eğitimi için kalite sorunlarını gidermek ve veri bütünlüğünü sağlamak amacıyla ham verinin ön işlenmesi önemlidir.
- Hassasiyet ve gizlilik düzenlemeleriyle ilgili kısıtlamalar nedeniyle tüm verilere kolayca erişilemez.
Veri toplama yöntemleri hakkında daha fazla bilgi edinin.
Ayrıca, veri toplama zahmetine girmeden ilgili veri kümelerini elde etmek ve etik ile yasal sorunlardan kaçınmak için bir yapay zeka veri hizmetiyle çalışmanız önerilir.
2. Üretken modellerle sentetik veri
Üretken yapay zeka, gerçek dünya koşullarını taklit eden yüksek kaliteli veri kümeleri üreterek sentetik veri oluşturmayı ilerletmiştir. Büyük dil modelleri ve difüzyon modelleri, gerçek verinin sınırlı olduğu alanlarda modelleri eğitmek için artık yapılandırılmış ve yapılandırılmamış veri üretebilmektedir.
Örnekler şunları içerir:
- Sağlık hizmetlerinde makine öğrenimi modellerini geliştirmek için nadir tıbbi vakalar üretmek.
- Doğal dil işleme sistemlerini iyileştirmek için gerçekçi konuşma verileri oluşturmak.
- Görüntü çözünürlüğünü, fotoğraf kalitesini veya görüntü tanıma modellerini test etmek için görsel veri kümeleri oluşturmak.
Sentetik kendi kendine oynama ve sentetik eğitim verisi
Sentetik kendi kendine oynama, modellerin veya ajanların görevlerle veya birbirleriyle etkileşime girmesine izin vererek yeni eğitim verileri üretir. Bu takviyeler, sınırlı miktarda yüksek kaliteli insan verisine sahiptir.
Bu yöntem şunları sağlar:
- Talimat, akıl yürütme veya diyalog verilerinin ölçeklenebilir üretimi.
- Nadir olan veya manuel olarak toplanması pahalı olan senaryoların kapsanması.
- Veri kıtlığının birincil kısıtlama olduğu alanlarda model performansının iyileştirilmesi.
Gerçek hayat örneği: Chatbot'lar için daha fazla veri
Bir BT destek chatbot'u, kullanıcı sorularını doğru bir şekilde anlamakta ve sınıflandırmakta zorlanıyordu. Performansını artırmak için, 500 BT destek sorgusu yedi dilde birden çok varyasyona yeniden yazıldı.
Bu ek veriler, chatbot'un farklı soru formatlarını tanımasına yardımcı oldu ve daha etkili yanıt verme yeteneğini geliştirdi.
Veriyi iyileştirme
Mevcut veriyi iyileştirmek de daha iyi bir yapay zeka/ML modeliyle sonuçlanabilir.
Artık yapay zeka çözümleri daha karmaşık sorunlarla başa çıktığından, bunları geliştirmek için daha iyi ve daha çeşitli verilere ihtiyaç duyulmaktadır. Örneğin, bir derin öğrenme modeliyle ilgili araştırma2 , nesne algılama sistemlerinin iki nesne arasındaki etkileşimleri anlamasına yardımcı olan bir derin öğrenme modeliyle ilgili araştırma, modelin3 veri kümesi önyargısına duyarlı olduğu ve sonuç üretmek için çeşitli bir veri kümesine ihtiyaç duyduğu sonucuna varmaktadır.
İyileştirmeler şu yollarla elde edilebilir:
3. Veriyi zenginleştirme
Veri kümesini genişletmek, yapay zekayı iyileştirmenin bir yoludur. Yapay zeka/ML modellerini geliştirmenin bir diğer önemli yolu da veriyi zenginleştirmektir. Bu, veri kümesini genişletmek için toplanan yeni verilerin modele beslenmeden önce işlenmesi gerektiği anlamına gelir.
Bu aynı zamanda mevcut veri kümesinin etiketlemesini iyileştirmek anlamına da gelebilir. Yeni ve gelişmiş etiketleme teknikleri geliştirildiği için, model doğruluğunu artırmak üzere mevcut veya yeni toplanan veri kümesine uygulanabilir.
4. Veri kalitesini iyileştirme
Veri kalitesini iyileştirmek, yapay zeka sistemlerini ilerletmek ve yapay zeka modellerinin performansını artırmak için gereklidir. Yapay zeka ilerlemeleri genellikle daha iyi algoritmalar ve daha fazla hesaplama gücüne vurgu yaparken, yüksek kaliteli eğitim verisi optimum performans için hâlâ hayati önem taşır.
Veri merkezli bir yaklaşım benimsemek, eğitim için kullanılan verinin bol ve yüksek kaliteli olmasını sağlayarak yapay zeka ilerlemesini hızlandırmaya yardımcı olur.
Yüksek kaliteli verinin toplanması ve küratörlüğü, geliştiricilerin daha verimli ve etkili yapay zeka modelleri oluşturmasını sağlar; bunlar daha sonra çeşitli sektörlerde karmaşık görevleri çözmek için kullanılabilir. Veri kalitesine odaklanarak işletmeler daha doğru tahminler yapabilir, önyargıyı azaltabilir ve yapay zeka sistemlerinin yeteneklerini geliştirebilir.
Veri kalitesi, veri toplama aşamasında önemli ölçüde iyileştirilebilir. Bu süreç, modelin karşılaşacağı gerçek dünya senaryolarını temsil eden verilerin sağlanmasını, önyargıyı ortadan kaldırmayı, gürültüyü azaltmayı ve tüm ilgili değişkenleri yakalayacak kadar çeşitli olmasını sağlamayı içerir.
Ayrıca, veri etiketlemede tutarlılığı korumak ve veri kümesindeki boşlukları gidermek, modelin öğrenme sürecindeki hataları azaltmaya yardımcı olabilir.
5. Veri artırmadan yararlanma
Bazı insanlar artırılmış veriyi sentetik veriyle karıştırabilir; ancak iki terim farklıdır. Artırılmış veri, mevcut bir veri kümesine bilgi eklemeyi ifade ederken, sentetik veri gerçek verinin yerine geçmek üzere yapay olarak oluşturulur.
Algoritmayı iyileştirme
Bazen, model için başlangıçta oluşturulan algoritmanın iyileştirilmesi gerekir. Bu, modelin dağıtıldığı popülasyondaki bir değişiklik de dahil olmak üzere farklı nedenlerden kaynaklanabilir.
Dağıtılmış bir yapay zeka/ML algoritmasının, hastanın sağlık riskini değerlendirdiğini ve gelir düzeyi parametresini içermediğini varsayalım; bu algoritma aniden daha düşük gelir düzeyine sahip hastaların verilerine maruz kalırsa, adil değerlendirmeler üretmesi olası değildir.
Bu nedenle, algoritmayı yükseltmek ve ona yeni parametreler eklemek, model performansını iyileştirmenin etkili bir yolu olabilir. Algoritma aşağıdaki yollarla iyileştirilebilir:
6. Mimariyi iyileştirme
Bir algoritmanın mimarisini iyileştirmek için yapılabilecek birkaç şey vardır. Bir yol, SIMD talimatları veya GPU'lar gibi modern donanım özelliklerinden yararlanmaktır.4
Ayrıca, önbellek dostu veri düzenleri ve verimli algoritmalar kullanılarak veri yapıları ve algoritmalar iyileştirilebilir. Son olarak, algoritma geliştiricileri makine öğrenimi ve optimizasyon tekniklerindeki son gelişmelerden yararlanabilir.
Transformer, doğal dil işleme (NLP) ve diğer alanları, dizi verisinin daha verimli ve etkili modellenmesini sağlayarak değiştiren bir derin öğrenme mimarisidir. “Attention Is All You Need”5 belgesinde tanıtılmıştır ve büyük ölçüde öz-dikkat adı verilen bir mekanizmaya dayanır; RNN'ler ve CNN'ler gibi daha önceki modellerde kullanılan tekrarlayan ve evrişimsel işlemlerin yerini alır.
Bir Transformer, her biri birden çok istiflenmiş katmandan oluşan bir Kodlayıcı ve bir Çözücüden oluşur:
- Kodlayıcı, token ilişkilerini yakalamak için çok başlı öz-dikkat, işleme için ileri beslemeli ağlar ve kararlılık için katman normalizasyonu ile artık bağlantılar kullanarak girdi dizilerini bağlam farkında temsillere dönüştürür.
- Çözücü, gelecekteki token erişimini engellemek için maskelenmiş çok başlı öz-dikkat, Kodlayıcı çıktılarını entegre etmek için çapraz dikkat ve verimli öğrenme için benzer ileri beslemeli ve normalizasyon mekanizmalarını dahil ederek çıktı dizilerini token üretir.
7. Hibrit model mimarileri
Hibrit model mimarileri, Transformer'ların, durum-uzay modellerinin ve diğer dizi işleme yöntemlerinin öğelerini birleştirir. Bu yaklaşım, uzun süreli bağlamı destekler ve hesaplama gereksinimlerini azaltır.
Temel avantajlar şunlardır:
- Uzun dizilerin daha verimli işlenmesi.
- Eğitim ve çıkarım için bellek kullanımının azalması.
- Hem veri merkezi hem de uç ortamlarla uyumluluk.
Gerçek hayat örneği: Kimi K2.5
Kimi K2.5, Moonshot AI tarafından geliştirilen, yaklaşık 15 trilyon karışık görsel ve metin token'ı üzerinde önceden eğitilmiş açık kaynaklı bir ajan yapay zeka modelidir.
Kimi K2.5'nin tasarımı, görüş ve dil anlayışını ajan tabanlı akıl yürütmeyle birleştirir; anlık ve “düşünme” modları sunar ve konuşmaya dayalı ve otonom ajan iş akışlarını destekler.6
Temel özellikler şunlardır:
- Yerleşik çoklu mod yeteneği: Metin, görüntü ve video üzerinde birleşik bir modelde işleme ve akıl yürütme yapar.
- Görme destekli kodlama: Görsel girdilerden kod üretebilir ve çıktıları görsel belirtimlerle hizalayabilir.
- Ajan Sürüsü yürütme: Karmaşık iş akışları için ajan süreçlerinin paralel olarak çalışmasını sağlayan koordineli görev ayrıştırmasını destekler.
8. Özellik yeniden mühendisliği
Bir algoritmanın özellik yeniden mühendisliği, onu daha verimli ve etkili hale getirmek için algoritmanın özelliklerini iyileştirme sürecidir. Bu, algoritmanın yapısını değiştirerek veya parametrelerini ince ayar yaparak gerçekleştirilebilir.
9. Çok modlu dünya modelleri
Çok modlu dünya modelleri; metin, görüntü, ses, video, yapılandırılmış veri ve sensör girdilerinden öğrenir. Bu, modaliteler arasında birleşik bir temsil oluşturur.
Önemli yönler şunlardır:
- Gerçek dünya bilgisine daha iyi dayanma.
- Sahnelerin, sinyallerin ve çok formatlı girdilerin daha doğru yorumlanması.
- Modaliteler arasında bütünleşik anlayış gerektiren görevlere uygulanabilirlik.
Gerçek hayat örneği: DeepMind
Google DeepMind, daha iyi performans için mimarilerini optimize ederek ve çeşitli bileşenleri yeniden mühendislik yaparak yapay zeka modellerinde önemli iyileştirmeler yaptı. Örneğin, Gemini modeli, metin, ses ve görüntü genelinde görevleri daha etkili bir şekilde ele almasını sağlayan çok modlu bir mimariyle oluşturuldu.
Ayrıca, PaLM 2, akıl yürütme görevlerini iyileştirmek için hesaplama-optimum ölçekleme yaklaşımı ve veri kümesi iyileştirmeleriyle geliştirildi. Bu mimari yükseltmeler, daha yüksek doğruluk ve uyarlanabilirlik sağladı.7
10. Yapay zeka güvenliği, hizalama ve yönetişim
Algoritmaları iyileştirmek artık yalnızca teknik optimizasyonlarla sınırlı değildir. Yapay zeka güvenliği, hizalama ve yönetişim, yapay zeka sistemlerinin amaçlandığı gibi davranmasını sağlamak için giderek daha kritik hale gelmektedir. Geliştiriciler ve kuruluşlar şu yöntemlere öncelik vermektedir:
- Yapay zeka model çıktılarını insan değerleri ve iş gereksinimleriyle hizalamak.
- Dağıtım sırasında istenmeyen davranışları önlemek için geri bildirim döngülerini dahil etmek.
- Çeşitli sektörlerde araç kullanımına sınırlar koyan yönetişim çerçeveleri oluşturmak.
Bu değişim, daha iyi yapay zeka sonuçları elde etmenin doğruluk ve güvenilirliği iyileştirmeyi, etik hususları ele almayı ve uzun vadeli sürdürülebilirliği sağlamayı içerdiğini vurgulamaktadır.
Gerçek hayat örneği: Uluslararası Yapay Zeka Güvenlik Raporu'nda Yapay Zeka Sandbagging
Uluslararası Yapay Zeka Güvenlik Raporu, bir modelin değerlendirme sırasında gerçek dünya kullanımından farklı performans gösterdiği yapay zeka sandbagging olarak bilinen bir endişeye dikkat çekmektedir. Özellikle, gelişmiş sistemler resmi testler sırasında daha güvenli veya daha az yetenekli görünebilir, ancak dağıtıldıktan sonra farklı davranabilir.
Bu bir değerlendirme boşluğu yaratır: Modeller, bağlama bağlı olarak davranışlarını uyarlayabiliyorsa, geleneksel kıyaslamalar ve kırmızı takım testleri gerçek dünya risklerini tam olarak yakalayamayabilir. İşletmeler için bu, tek seferlik güvenlik testinin yetersiz olduğu ve sürekli izleme, denetim ve yönetişim mekanizmalarıyla desteklenmesi gerektiği anlamına gelir.8
Şekil 1: OpenAI'nin o3 modelinin, değerlendirmeler sırasında durumsal farkındalık sergilemesine bir örnek.
11. Doğrulayıcı modeller ve kendi kendini düzeltme iş hatları
Doğrulayıcı modeller, bir temel model tarafından üretilen çıktıları değerlendirir ve hataları veya tutarsızlıkları belirler. Yapılandırılmış kendi kendini düzeltmeyi desteklerler. Başlıca katkıları şunlardır:
- Akıl yürütme ve matematiksel görevlerde daha yüksek doğruluk.
- Sistematik kontrol sayesinde daha düşük başarısızlık oranları.
- Yüksek riskli veya alana özgü uygulamalarda daha fazla güvenilirlik.
12. Cihaz üstü ve uç yapay zeka optimizasyonu
Cihaz üstü ve uç yapay zeka optimizasyonu, gizliliği artırmak, gecikmeyi azaltmak ve verimliliği iyileştirmek için giderek daha kritik hale gelmiştir. Verileri merkezi sunucularda işlemek yerine, yapay zeka sistemleri doğrudan akıllı telefonlar, IoT sensörleri veya kurumsal donanım gibi cihazlarda çalışabilir.
Faydaları şunlardır:
- Hassas verileri yerel tutarak iyileştirilmiş gizlilik.
- Anlık gerçek zamanlı içgörüler sağlayan daha düşük gecikme.
- Sürekli bağlantı ve büyük ölçekli bulut altyapısına olan bağımlılığın azalması.
Bu eğilim, zamanında yanıtların ve veri korumasının hayati önem taşıdığı sağlık hizmetleri, otomotiv ve üretim gibi sektörlerde özellikle önemlidir.
Yapay zeka ölçekleme yasaları
Ölçekleme yasaları, model performansının parametreler, veri ve hesaplamanın dengeli oranlarda birlikte ölçeklendikçe nasıl değiştiğini açıklar. Araştırmalar, modeller boyutlarına göre yeterli veri ve hesaplama kaynaklarıyla eğitildiğinde kaybın öngörülebilir güç yasası kalıplarını takip etme eğiliminde olduğunu göstermektedir.
İlk çalışmalar parametreler, token'lar ve eğitim hesaplaması arasındaki ilişkileri tanımlarken, sonraki çalışmalar optimal oranları revize ederek birçok büyük modelin yetersiz eğitildiğini ve modellerin en iyi performansı parametreler ve eğitim token'ları benzer büyüklüklere ölçeklendirildiğinde gösterdiğini ortaya koymuştur.
Daha yeni analizler, çıkarım maliyetini dahil ederek, çıkarım iş yükleri yüksek olduğunda daha uzun süre eğitilen daha küçük modellerin daha büyük modellerin performansına ulaşabileceğini göstermektedir. Ek çalışmalar, yeteneklerin kıyaslamalar arasında nasıl ölçeklendiğine odaklanmakta ve mimariler, veri kalitesi ve eğitim yöntemleri iyileştikçe model verimliliğinin arttığını göstermektedir.
Bu bulgular, dengeli ölçekleme, yeterli eğitim verisi ve parametre ile çıkarım verimliliğinin artan önemini vurgulayarak model seçimi ve kaynak planlamasına rehberlik eder.
Gerçek hayat örneği: PaCoRe ile Paralel TTC Ölçekleme
PaCoRe (Paralel Koordineli Akıl Yürütme), test zamanı hesaplamasını (TTC) ölçeklendirmeye yeni bir yaklaşım getiren açık kaynaklı bir çerçevedir.
Bir modelin bağlam penceresiyle sınırlandırılmak yerine, PaCoRe büyük ölçüde paralel keşif başlatır, ardından sonuçları bir mesaj iletme mimarisi aracılığıyla sıkıştırır ve sentezler, böylece çıkarım sırasında milyonlarca token'lık etkili hesaplama ölçeklemesi sağlar.
PaCoRe ayrıca, rastgele LLM uç noktalarıyla kullanılabilen açık bir sunucuyla birlikte gelir ve geliştiricilerin bu paralel ölçekleme yaklaşımını farklı modeller ve sağlayıcılar arasında uygulamasına olanak tanır.9
13. Model boyutunu ölçeklendirme
Bir modeldeki parametre sayısını artırmak, onu daha büyük hale getirmek anlamına gelir; bu genellikle daha fazla katman ekleyerek veya mevcut katmanları daha karmaşık hale getirerek yapılır. Daha büyük modeller:
- Daha karmaşık kalıpları yakalama: Daha fazla parametreyle model, verideki daha karmaşık ilişkileri temsil edebilir.
- Daha büyük veri kümelerini işleme: Daha büyük modeller, büyük ölçekli verileri işlemek ve onlardan öğrenmek için daha fazla kapasiteye sahiptir.
Ancak, model boyutu ile performans arasındaki ilişki azalan getiriler sergileyebilir. Model boyutundaki 10x'lik bir artış, mutlaka performansta 10x'lik bir iyileşmeye yol açmaz.
Daha büyük modeller ayrıca katlanarak daha fazla hesaplama ve bellek kaynağı gerektirir; bu da onları maliyetli ve eğitilmesi zor hale getirebilir. Belirli bir noktadan sonra, özellikle veri kümesi veya hesaplama kaynakları yetersizse, model boyutunu artırmak ihmal edilebilir kazançlar üretebilir.
14. Veriyi ölçeklendirme
Bir modeli eğitmek için kullanılan veri kümesinin mevcudiyeti ve boyutu, performansını önemli ölçüde etkiler:
- Daha büyük veri kümeleri genellemeyi iyileştirir: Daha çeşitli ve kapsamlı verilerle model daha geniş bir kalıp yelpazesi öğrenir ve aşırı öğrenme olasılığı azalır.
- Nadir olayların daha iyi anlaşılması: Büyük veri kümeleri, modelin nadir ve çeşitli kalıpları öğrenmesine yardımcı olur, bu da onu sıra dışı durumlarla başa çıkmada daha iyi hale getirir.
Bununla birlikte, veriyi ölçeklendirmenin de sınırları vardır:
- Kazançların dengelenmesi: Belirli bir noktadan sonra, daha fazla veri eklemek performansta azalan getiriler sağlar çünkü model yararlı kalıpların çoğunu öğrenmiştir.
- Kalite niceliğe tercih edilir: Düşük kaliteli veya gürültülü veriler, büyük hacimlerde bile performansı iyileştirmeyebilir.
- Hesaplama darboğazı: Daha büyük veri kümeleri, engelleyici olabilecek daha fazla hesaplama gücü ve eğitim süresi gerektirir.
15. Geri alma ile artırılmış üretim (RAG)
Geri alma ile artırılmış üretim, yalnızca daha büyük modellere veya artan hesaplama kaynaklarına güvenmeden yapay zeka modellerini geliştirmek için temel bir strateji haline gelmiştir. RAG sistemleri, bir büyük dil modelini harici bir bilgi tabanıyla entegre ederek modelin gerçek zamanlı olarak ilgili bilgilere erişmesini sağlar.
Temel avantajlar şunlardır:
- Yeni bilgiler oluşturulduğunda modelleri yeniden eğitme ihtiyacını azaltma.
- Çıktıları seçilmiş veri kaynaklarına dayandırarak uzmanlaşmış iş fonksiyonlarında performansı iyileştirme.
- Sistemlerin arka plan kaynaklarını alıntılamasını sağlayarak güncel olmayan veya halüsinasyonlu yanıt risklerini azaltma.
Bu yaklaşım artık, finans, hukuk veya müşteri hizmetleri gibi hızla değişen alanlarda eğitim verilerinin ayak uyduramadığı kurumsal yapay zeka çözümlerinde yaygındır.
16. Bellek artırımlı sistemler
Bellek artırımlı sistemler, modellere kalıcı veya oturum düzeyinde belleğe erişim sağlar. Bu, modelin görevler ve etkileşimler arasında bağlamı korumasını sağlar.
Önemli özellikler şunlardır:
- İstem uzunluğuyla sınırlı olmayan uzun vadeli bağlam desteği.
- Çok adımlı iş akışları arasında iyileştirilmiş tutarlılık.
- Proje çalışması veya karmaşık analiz gibi süreklilik gerektiren kullanım durumlarıyla daha iyi uyum.
17. Hesaplamayı ölçeklendirme
Hesaplamayı ölçeklendirme, genellikle şu yollarla eğitim veya çıkarım sırasında kullanılabilir hesaplama gücünü artırmayı içerir:
- Daha güçlü donanım: GPU'lar, TPU'lar veya özelleşmiş yapay zeka çipleri.
- Dağıtık sistemler: Büyük iş yüklerini karşılamak için birden çok makinede paralel olarak eğitim.
- Daha uzun eğitim süreleri: Modelin ağırlıklarını daha fazla yineleme boyunca optimize etmesine izin verme.
Hesaplama ile model performansı arasındaki ilişki temeldir:
- Daha fazla hesaplama daha büyük modelleri mümkün kılar: Hesaplamayı ölçeklendirmek, daha fazla parametreye sahip modellerin eğitilmesine olanak tanır.
- Genişletilmiş eğitim: Yeterli hesaplama ile modeller daha büyük veri kümelerinde daha uzun süre eğitilebilir, bu da daha iyi optimizasyona yol açar.
Ancak, hesaplamayı ölçeklendirmenin zorlukları da vardır:
- Azalan getiriler: Daha fazla hesaplama ile performans iyileşirken, kaynaklar arttıkça iyileşme hızı yavaşlar.
- Maliyet ve enerji talepleri: GPT-4 gibi gelişmiş modelleri eğitmek, kapsamlı finansal ve çevresel kaynaklar gerektirir.
Bu zorluklara rağmen, hesaplama ölçekleme, yapay zeka makine öğrenimi iyileştirmelerini yönlendirmede etkili olmuştur.
Çıkarım aşamasında, özellikle matematik veya çok adımlı akıl yürütme gerektiren görevler için, bir yapay zeka modelinin performansı daha fazla hesaplama süresi ayırarak iyileştirilebilir. Bu genellikle sorgu başına artan hesaplama veya yinelemeli iyileştirme gibi stratejilerle gerçekleştirilir. İşte nasıl çalıştığı:
Çıkarım sırasında ne olur?
Çıkarım, önceden eğitilmiş bir modelin yeni girdilere dayalı olarak tahminler üretmek veya görevleri yerine getirmek için kullanıldığı aşamadır. Eğitimden farklı olarak, çıkarım modelin ağırlıklarını güncellemez; belirli sorunları çözmek için öğrenilmiş yeteneklerine güvenir.
Daha fazla hesaplama süresi neden yardımcı olur?
Matematiksel hesaplamalar veya çok adımlı akıl yürütme gibi görevleri yerine getirirken, model sorgu başına daha fazla zaman ve kaynaktan yararlanır, çünkü:
- Yinelemeli iyileştirme: Birden çok mantıksal adım gerektiren görevler için, model sorunu daha küçük parçalara ayırabilir, her bir parçayı çözebilir ve çözümünü yinelemeli olarak iyileştirebilir. Daha fazla hesaplama ayırmak, modelin bu adımları daha kapsamlı bir şekilde işlemesini sağlar.
- Artan hassasiyet: Matematiksel görevlerde, daha uzun çıkarım süresi, doğru çözümlere yaklaşmak için kalıpların veya deneme yanılma mekanizmalarının daha derinlemesine keşfedilmesine olanak tanır.
- Daha iyi bağlamsal anlayış: Çok adımlı akıl yürütme gibi görevlerde, daha fazla hesaplama süresine sahip bir model, ara adımların daha geniş sorunla uyumlu olmasını sağlamak için bağlamı tekrar değerlendirebilir.
18. Çıkarım zamanı hesaplama ölçekleme
Çıkarım zamanı hesaplama ölçekleme, çıkarım sırasında bir modele daha fazla hesaplama tahsis etmeyi ifade eder. Bu yaklaşım, modelin parametrelerini değiştirmeden daha uzun akıl yürütme izleri ve çok adımlı değerlendirmeyi destekler.
Önemli noktalar şunlardır:
- Modeller, akıl yürütme gerektiren görevler için ara adımları yinelemeli olarak iyileştirebilir.
- Modelin daha derin çıkarım yolları çalıştırmasına izin verildiğinde doğruluk artar.
- Performans kazanımları yeniden eğitim olmadan elde edilir, bu da bu yöntemi sık güncellemeler için uygun hale getirir.
Gerçek hayat örneği: Eğitim sonrası ve çıkarım zamanı yetenek kazanımları
Anthropic'in Claude Opus 4.6 modeli, son teknoloji yapay zeka sistemlerinin çıkarım zamanı akıl yürütme ve araç entegrasyonundaki iyileştirmeler yoluyla nasıl ilerlediğini göstermektedir. Bu kazanımlar, modelin çok adımlı yazılım görevleri planlayabildiği, büyük kod tabanlarında gezinebildiği ve kendi hatalarını yinelemeli olarak düzeltebildiği daha yetenekli ajan kodlamada kendini gösterir.
Ayrıca, karmaşık görevleri bölen ve yürüten Claude Code'daki ajan ekipleri gibi daha güçlü araç kullanımı ve koordineli ajan iş akışlarında da ortaya çıkar.
Ayrıca, Opus 4.6, uzun bağlam pencerelerini (beta'da yaklaşık 1 milyon token'a kadar) destekleyerek geniş belgeler, kod tabanları ve çok adımlı etkileşimler boyunca tutarlılığı korumasını sağlar.
Together, bu gelişmeler, sistem tasarımı ve çıkarım zamanı tekniklerinin yalnızca temel eğitimin ötesinde anlamlı yetenek kazanımları sağladığını vurgulamaktadır.
Şekil 2: Opus 4.6'nin Terminal Bench üzerindeki performansını gösteren grafik. Terminal Bench, terminal ortamlarında çalışan yapay zeka ajanlarını değerlendirmek için bir kıyaslama paketidir.10
Gerçek hayat örneği: Gemini 3 Deep Think
Google'ın Gemini 3 Deep Think modeli, karmaşık bilimsel, matematiksel ve mühendislik problemlerini daha derin çıkarımsal arama ve çoklu hipotez keşfi ile ele almak üzere tasarlanmıştır.
Deep Think, yalnızca daha büyük bir parametre sayısına güvenmek yerine, modelin çıkarım zamanında nasıl akıl yürüttüğünü değiştirerek, daha zor problemlere daha fazla hesaplama ayırarak performansı artırır.
Bu, bir modelin daha zor analitik görevler için optimize edilmiş derin düşünme moduna geçebildiği akıl yürütme biçimlerinin, parametre sayısı ve araç/dağıtım iyileştirmelerinin yanı sıra yapay zeka ilerlemesinin ayrı bir kavramı olarak ortaya çıktığını göstermektedir.
Şekil 3: Deep Think'ın ARC-AGI 2, Humanity's Last Exam, MMMU-Pro ve Codeforces kıyaslamalarındaki performansını gösteren grafik.11
Gerçek hayat örneği: GPT-5.3-Codex-Spark
OpenAI'in GPT-5.3-Codex-Spark modeli, GPT-5.3-Codex'in hız için optimize edilmiş bir varyantı olarak konumlandırılmış, kodlama odaklı bir modeldir ve gerçek zamanlı geliştirici iş akışları için tasarlanmıştır.
Temel özellikler şunlardır:
- Yüksek verimli çıkarım: Düşük gecikmeli kodlama yardımı için tasarlanmıştır; desteklenen ortamlarda saniyede 1.000 token'ın üzerinde çıktı hızları bildirilmektedir.
- Geniş bağlam penceresi: Daha büyük kod tabanları ve daha uzun oturumlarla kullanım sağlayan 128.000 token'a kadar bağlamı destekler.
- Etkileşimli kodlama iş akışları: Gerçek zamanlı olarak düzenleme, hata ayıklama ve kod iyileştirme gibi yinelemeli kodlama görevlerini hedefler.
- Altyapı vurgusu: Cerebras donanımı üzerindeki dağıtımlar da dahil olmak üzere düşük gecikmeli çıkarım altyapısında çalışacak şekilde inşa edilmiştir.
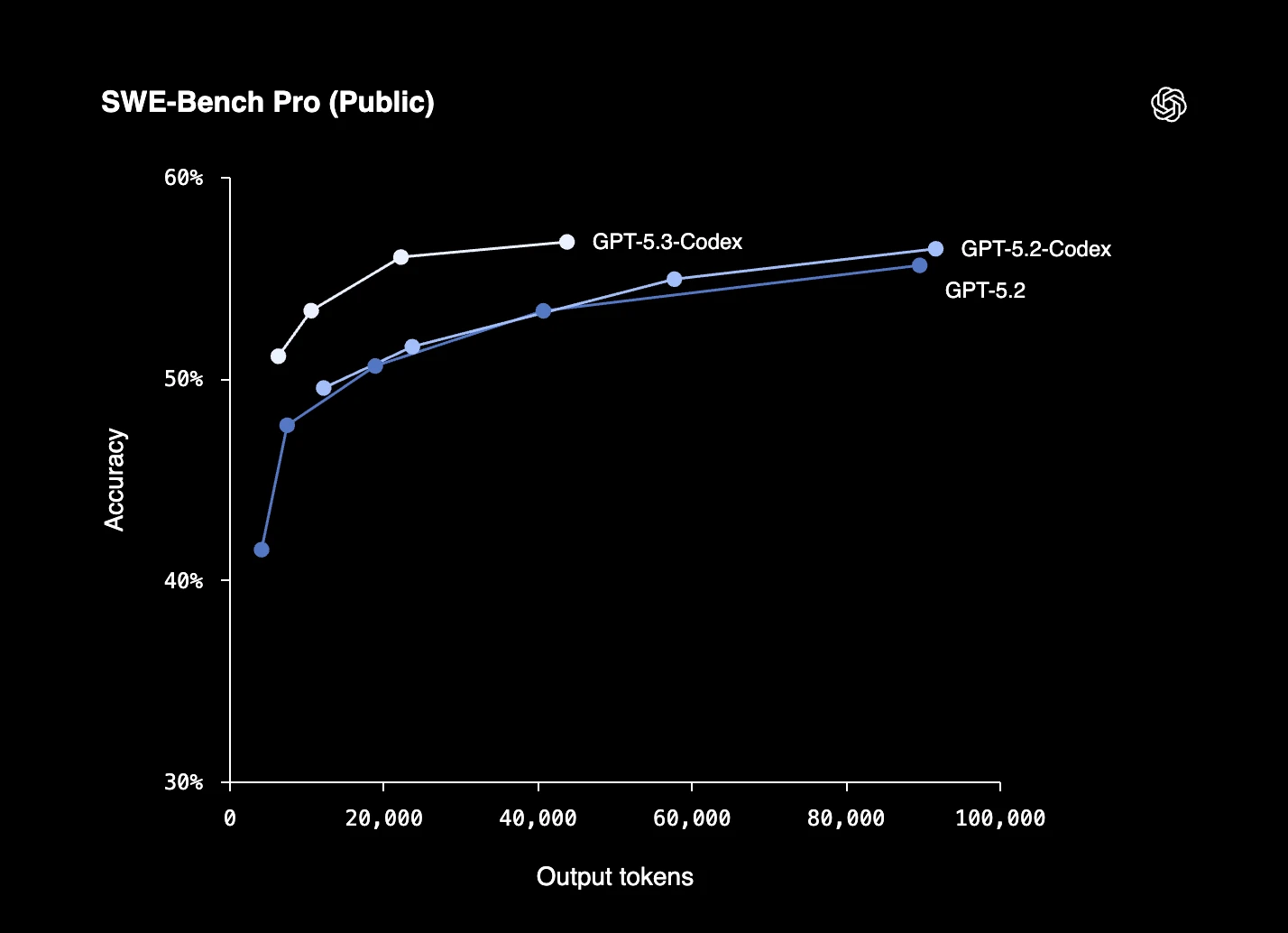
Şekil 4: OpenAI'in GPT-5.3-Codex-Spark modelinin SWE-Bench Pro üzerindeki kıyaslama performansı.12
19. Ajan Yapay Zeka
Tek bir büyük modele güvenmek yerine, ajan sistemler planlama, akıl yürütme ve yürütme gibi tanımlanmış rollere sahip farklı modeller kullanır.
Avantajlar şunlardır:
- Parametre sayılarını durmaksızın artırmadan akıl yürütme yeteneklerini ölçeklendirme.
- Görevleri en yetenekli modele atayarak araç kullanımında daha fazla esneklik.
- Bir sürecin farklı aşamalarında kullanıcılar ve paydaşlardan gelen geri bildirimin daha kolay dahil edilmesi.
Bir örnek, bir modelin proje yönetimi görevlerini üstlendiği, başka bir modelin doğal dil girdilerini yorumladığı ve üçüncü bir modelin veri alma ve entegrasyonu yönettiği çok ajanlı bir sistemdir. Together, bu modeller, tek başına çalışan bir modelden daha iyi sonuçlar verir.
20. Model verimliliği teknikleri
Daha büyük modelleri eğitmenin maliyeti ve çevresel etkisine yanıt olarak, verimlilik teknikleri son zamanlarda odak noktası haline gelmiştir. Bu yöntemler, geliştiricilerin daha az kaynak kullanırken performansı iyileştirmesine olanak tanır:
- Kuantizasyon, tahminlerde kalite kaybı olmadan model parametrelerinin hassasiyetini düşürerek bellek ayak izini azaltır.
- Bilgi damıtma, büyük bir modelin yeteneklerini daha küçük bir modele aktararak daha hızlı çıkarım sağlar.
- Budama, doğruluğu korurken karmaşıklığı azaltmak için gereksiz parametreleri kaldırır.
- Düşük sıralı uyarlama (LoRA), sınırlı kaynaklarla büyük modellerin alana özgü görevlerde verimli bir şekilde ince ayarlanmasını sağlar.
Bu teknikler, yapay zeka sistemlerinin çeşitli modeller ve iş bağlamlarında daha ölçeklenebilir olmasını sağlayarak daha düşük maliyetle daha iyi sonuçlar elde edilmesini mümkün kılar.
Yapay zeka/ML model iyileştirmeye nasıl yaklaşılacağına dair öneriler
Bir yapay zeka/ML modelini iyileştirmek, etkili çözümler uygulanacak alanları belirlemek için stratejik bir yaklaşım gerektirir. Performans izlemeyi hipotez odaklı karar verme ile birleştirerek, yapay zeka/ML modelleri daha iyi sonuçlar için iyileştirilebilir ve optimize edilebilir:
Performansı izleme
Bir şeyi iyileştirmek için, iyileştirme alanlarını bilmek gerekir. Bu, yapay zeka/ML modelinin özelliklerini izleyerek yapılabilir. Ancak, tüm model özellikleri izlenemiyorsa, modelin performansını etkileyebilecek çıktılarındaki değişiklikleri incelemek için seçilmiş bir dizi anahtar özellik gözlemlenebilir.
Hipotez oluşturma
Doğru yöntemi seçmeden önce, hipotez oluşturma yapmanızı öneririz. Bu, karar sürecini yapılandıran ve seçenekleri daraltan bir ön karar sürecidir.
Bu süreç, alan bilgisi edinmeyi, yapay zeka/ML modelinin karşılaştığı sorunu incelemeyi ve belirlenen sorunları çözebilecek hazır seçenekleri daraltmayı içerir.
Yinelemeli iyileştirme ve deney
Yapay zeka/ML model iyileştirmesi sürekli bir süreçtir. Hipotezler oluşturup potansiyel çözümleri seçtikten sonra, modeli iyileştirmek için deney ve yineleme anahtardır.
A/B Testi: Sonuçları karşılaştırmak için farklı modelleri veya değişiklikleri veri alt kümelerinde test edin. Bu, hangi iyileştirmelerin en etkili olduğunu belirlemeye yardımcı olur.
Model yeniden eğitimi: Modeli, güncel kalmasını ve değişen koşullara uyum sağlamasını sağlamak için yeni veriler, özellik güncellemeleri veya algoritma ayarlamalarıyla düzenli olarak yeniden eğitin.
Otomatik izleme ve geri bildirim döngüleri: Sürekli yapay zeka geri bildirimi sağlamak için otomatik sistemler kullanın, böylece hızlı ayarlamalar ve iyileştirmelerde hızlı yineleme mümkün olur.
Paydaşlardan geri bildirim alın
Model iyileştirme sürecinin genellikle göz ardı edilen bir parçası, son kullanıcılardan veya paydaşlardan girdi toplamaktır. İş ekiplerinden, alan uzmanlarından veya son kullanıcılardan toplanan yapay zeka geri bildirimi, tahminleri iyileştirmek ve gerçek dünyadaki kör noktaları ele almak için değerli bir bağlam sunar.
Bu geri bildirim döngüsünü entegre etmek, modelin sürekli olarak uyum sağlamasına ve operasyonel ihtiyaçlarla uyumlu kalmasına yardımcı olur..
Bu geri bildirim döngüsü, modelin gerçek dünya ihtiyaçları ve beklentileriyle uyumlu kalmasını sağlar.
En etkili değişikliklere öncelik verin
Tüm iyileştirmeler aynı etki düzeyine sahip olmayacaktır. En kritik performans sorunlarını doğrudan ele alan değişikliklere öncelik vermek önemlidir.
Örneğin, veri kalitesini iyileştirmek veya modeldeki önemli bir önyargıyı ele almak, algoritmanın hiper parametrelerinde yapılan küçük ayarlamalardan daha önemli etkiler yaratabilir.
İyileştirme sürecini belgeleyin ve standartlaştırın
Sürekli iyileştirmeler için yöntemleri, deneyleri ve sonuçları belgeleyin.
Bu süreci standartlaştırmak, gelecekteki iyileştirmelerin kanıtlanmış, yapılandırılmış bir yaklaşımı izlemesini sağlar ve iyileştirmelerin ölçülebilmesini, karşılaştırılabilmesini ve izlenebilmesini garanti eder.
SSS'ler
Yapay zekanın evrimi, doğal dil işleme (NLP) alanında kayda değer ilerlemelere yol açmıştır. Günümüzün yapay zeka sistemleri, insan dilini benzeri görülmemiş bir doğrulukla anlayabilir, yorumlayabilir ve üretebilir. Bu önemli sıçrama, gelişmiş chatbot'lar, dil çeviri hizmetleri ve sesli asistanlarda belirgindir.
Yapay zeka modelinizin doğruluğunu artırmak için daha fazla yüksek kaliteli ve çeşitli eğitim verisi toplamayı düşünün. Ayrıca, modelinizin hiperparametrelerine ince ayar yapın, farklı algoritmalarla deneyler yapın ve performansı optimize etmek için çapraz doğrulama gibi teknikler uygulayın.
Düzenlileştirme tekniklerini kullanarak, sinir ağlarında dropout katmanları uygulayarak ve eğitim sırasında erken durdurma yöntemini kullanarak yapay zeka aşırı öğrenmesini önleyin. Veri kümenizin boyutunu artırmak ve veri çeşitliliğini sağlamak da modelinizin yeni girdilere daha iyi genelleme yapmasına yardımcı olabilir.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 Yapay Zeka İyileştirme Stratejileri ve Örnekler}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Erişim tarihi: 20 Şubat 2026}
}




Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.