Top 3 Geradores de Documentos Sintéticos Benchmarkizados
Geradores de documentos sintéticos criam imagens de documentos realistas e anotadas que ajudam a treinar e avaliar modelos de aprendizado de máquina sem depender de grandes conjuntos de dados rotulados manualmente.
Benchmarkizamos 3 geradores de documentos sintéticos, Genalog, DocCreator e Tonic Textual, criando mais de 2.500 documentos sintéticos, comparando sua eficácia em layouts realistas, dados numéricos precisos e conjuntos de dados de treinamento para tarefas de análise de documentos.
Resultados do benchmark de geração de documentos
Os resultados mostram que
- Genalog e DocCreator são desempenhos fortes em utilidade e fidelidade, com o Genalog ligeiramente melhor em precisão numérica.
- Tonic Textual se destaca no realismo do layout visual, mas fica atrás em outras áreas, tornando-o mais adequado para tarefas que exigem documentos realistas.
Para mais informações sobre métricas, leia a metodologia do benchmark.
- Utilidade mede o quão bem os modelos treinados em dados sintéticos se saem em documentos reais.
- Fidelidade do layout mede o quão bem a disposição espacial dos elementos em documentos sintéticos corresponde aos reais.
- Fidelidade numérica verifica se os valores numéricos em documentos sintéticos se assemelham aos dados reais.
Comentário sobre os resultados: Para entender melhor as diferenças de desempenho, o benchmark também foi conduzido usando o conjunto de treinamento em vez do conjunto de teste separado. Esta avaliação secundária visou determinar se fornecer aos modelos material de treinamento melhoraria sua capacidade de reproduzir saídas estruturadas e numericamente precisas.
Os resultados mostram que, mesmo quando avaliados nos dados de treinamento, os modelos alcançaram pontuações ligeiramente mais altas. Isso indica que os resultados refletem o quão bem as ferramentas lidam com a tarefa em si. Os resultados moderados provavelmente são influenciados por limitações na qualidade do OCR e na capacidade do modelo treinado, e não no próprio procedimento de benchmarking.
Genalog
O Genalog teve o desempenho mais forte no geral. Seus documentos sintéticos foram muito eficazes para treinamento de modelos e mantiveram um bom equilíbrio entre elementos de layout realistas e precisão numérica. Os documentos gerados refletiram a estrutura e o espaçamento de formulários e recibos reais de perto, tornando-os adequados para uma variedade de tarefas de análise de documentos.
DocCreator
O DocCreator também produziu saídas de alta qualidade. Os documentos deste gerador de documentos foram quase tão úteis para treinamento quanto os do Genalog. Os layouts eram realistas e os documentos sintéticos preservavam as propriedades estatísticas dos números. A força do DocCreator reside em combinar geração de layout diversificada com seus modelos de degradação, tornando as saídas visualmente semelhantes a documentos reais digitalizados.
Tonic Textual
O Tonic Textual teve resultados mistos. Embora este gerador de documentos sintéticos produzisse layouts muito limpos e consistentes, os documentos foram menos eficazes para treinar modelos. Além disso, os números sintéticos nem sempre foram estatisticamente semelhantes aos dados reais. Isso sugere que o Tonic Textual é mais adequado para tarefas que focam na aparência do documento ou na substituição de PII que preserva a privacidade, em vez de treinamento em larga escala para tarefas de estrutura de layout e extração de informações.
Em março de 2026, o Tonic Textual mudou seu componente de ligação de entidades de um modelo baseado em LLM para um modelo baseado em BERT para melhorar a taxa de transferência.1 O mesmo lançamento (v391) também adicionou filtragem e classificação aprimoradas na página de Conjuntos de Dados.2
Visão Geral
Genalog é a ferramenta mais equilibrada, fornecendo layouts realistas e números precisos.
DocCreator é forte para layouts complexos e diversificados e degradação de documentos, com pequenas imprecisões numéricas.
Tonic Textual é ideal para tarefas focadas em layout, mas não para tarefas que precisam de dados numéricos precisos.
Visão Geral da Metodologia
Métricas de avaliação
Cada conjunto de dados gerado foi pontuado em relação aos dados originais usando as seguintes métricas:
Pontuação de utilidade
(Pontuação FIE): Uma pontuação entre 0 e 1, onde maior é melhor. É definida pela pontuação F1 do modelo LayoutLMv3 treinado nos dados sintéticos quando avaliado no conjunto de teste real. Uma pontuação alta indica que os dados sintéticos são um substituto altamente eficaz para dados reais.
Pontuações de fidelidade
Essas métricas medem o quão perto os documentos sintéticos se assemelham aos reais.
- Fidelidade do Layout (Pontuação EMD): A Distância do Movimentador da Terra (dEMD) mede a diferença entre a distribuição dos pontos centrais da caixa delimitadora nos documentos reais versus sintéticos. É um valor de 0 a 1, onde menor é melhor. Uma pontuação baixa significa que os elementos de layout espacial são bem preservados.
- Fidelidade Numérica (Distância K-S): A Distância de Kolmogorov-Smirnov (DKS) mede a diferença máxima entre as funções de distribuição cumulativa (CDFs) de valores numéricos (por exemplo, preços, quantidades) nos dados reais e sintéticos. Varia de 0 a 1, onde menor é melhor. Uma pontuação baixa significa que o gerador reproduz com precisão as propriedades estatísticas dos números.
Todas as métricas foram normalizadas durante o cálculo.
Conjuntos de Dados
FUNSD: Uma coleção de 199 formulários digitalizados caracterizados por texto ruidoso, layouts complexos e diversificados e anotações manuscritas. Foi baixado mais de 1.500 vezes no mês passado. Isso testa a capacidade de um gerador de lidar com dados não estruturados e imperfeitos. 3
- Dividimos a amostra em duas: 80% dos dados são usados para treinar o modelo, enquanto os 20% restantes são reservados para teste após o treinamento.
- Cada ferramenta produziu entre três e seis documentos sintéticos para cada original, resultando em um total de mais de 2.500 documentos sintéticos.
Avaliação de Tarefa
Para medir a utilidade, um modelo popular LayoutLMv3 com 22 mil estrelas no GitHub e mais de 750 mil downloads foi treinado nos dados sintéticos gerados por cada ferramenta de gerador de documentos sintéticos. 4
O desempenho deste modelo foi então avaliado em um conjunto de teste retido de documentos reais dos conjuntos de dados originais. Isso mede diretamente o quão útil os dados sintéticos são para uma tarefa do mundo real.
Ferramentas de Geração Sintética
Genalog
Uma biblioteca Python de código aberto da Microsoft para gerar imagens de documentos sintéticos com ruído sintético. Funciona pegando text + modelos de layout (escritos em HTML + CSS) e renderizando-os via WeasyPrint, depois aplicando efeitos de degradação (desfoque, sangramento, ruído sal-e-pimenta, operações morfológicas).5
DocCreator
Uma ferramenta multiplataforma e de código aberto para gerar imagens de documentos sintéticos com verdade associada. Foi amplamente utilizada em pesquisas de Análise e Reconhecimento de Imagens de Documentos (DIAR).6 ,7
Tonic Textual
Uma solução para redação e síntese em formatos de documentos do mundo real (PDF, Word). Ela afirma digitalizar documentos não estruturados, identificar entidades nomeadas (por exemplo, PII), redigir ou substituí-las por valores sintéticos e gerar documentos desidentificados em formatos semelhantes.
8 Métodos de degradação de documentos sintéticos
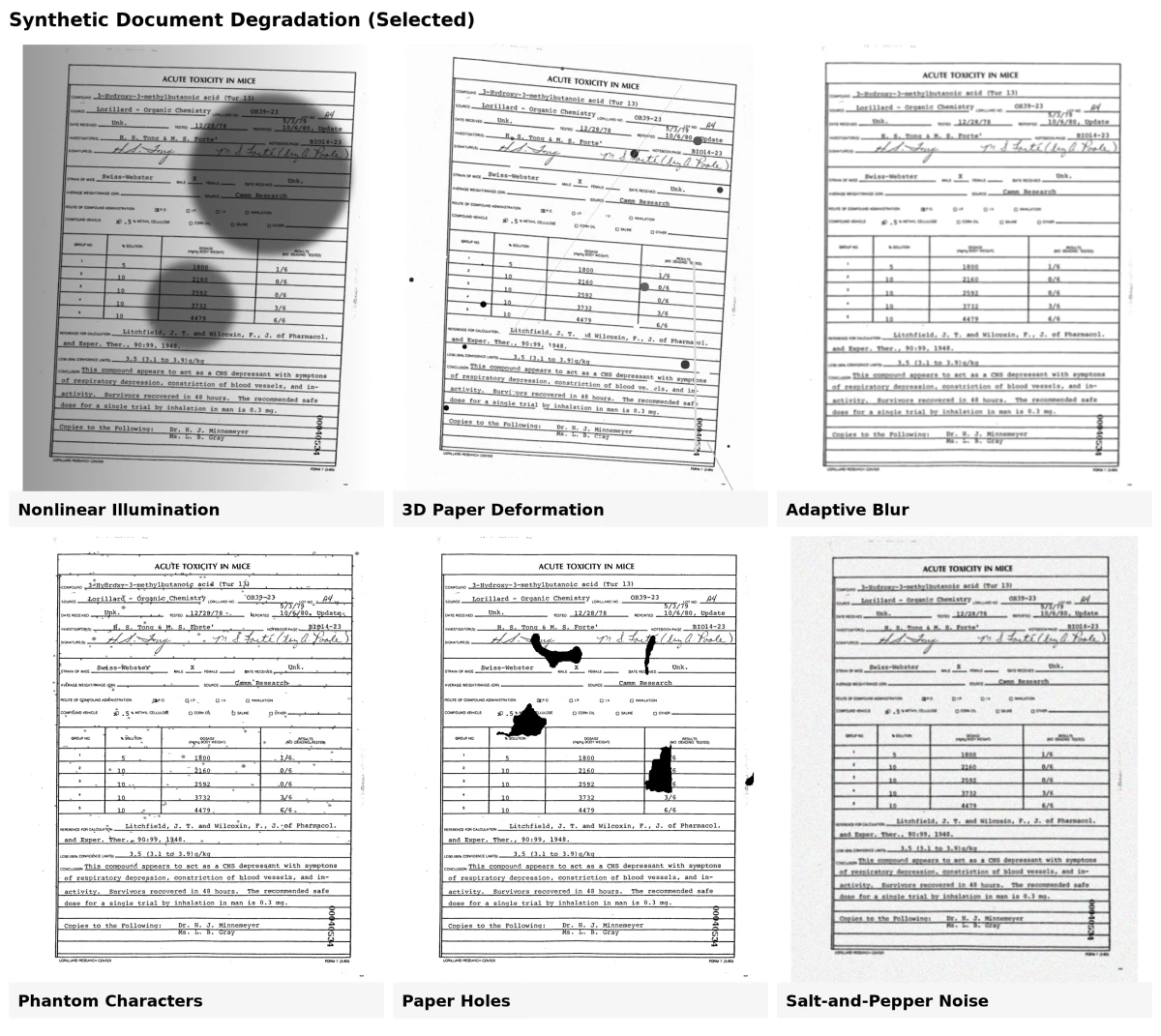
A geração de documentos sintéticos frequentemente inclui a adição de defeitos realistas para fazer com que dados artificiais se assemelhem a documentos do mundo real. Esses defeitos, ou modelos de degradação, ajudam a treinar modelos que se saem melhor em documentos ruidosos, envelhecidos ou digitalizados. Essas ferramentas aplicam várias transformações físicas e visuais para simular imperfeições comuns de documentos.8
1. Degradação de tinta
Este modelo simula desbotamento, manchas ou listras causados por envelhecimento ou impressão de baixa qualidade. Adiciona pequenas manchas de tinta ou remove partes de letras para imitar o decaimento real da tinta.
2. Caracteres fantasma
Ferramentas de impressão antigas frequentemente deixavam contornos tênues ou marcas "fantasmas" ao redor das letras. O modelo de caractere fantasma recria esses defeitos inserindo defeitos extraídos de digitalizações reais entre caracteres impressos.
3. Buracos no papel
Buracos de diferentes formas e tamanhos são adicionados aleatoriamente aos documentos, replicando rasgos ou marcas de perfuração vistas em papéis gastos.
4. Sangramento
Este efeito imita a tinta vazando do outro lado da página. Usa imagens frontal e traseira de um documento para recriar como a tinta transfere parcialmente através do papel.
5. Desfoque adaptativo
Digitalizar ou fotografar documentos frequentemente cria um leve desfoque. Este modelo compara exemplos reais desfocados e aplica um desfoque semelhante usando filtros Gaussianos, mantendo o resultado sutil e realista.
6. Deformação de papel 3D
Documentos podem dobrar, curvar ou curvar quando digitalizados ou fotografados. Usando malhas 3D de papéis reais, este modelo recria essas formas e efeitos de iluminação, ajudando a treinar modelos para análise de documentos baseada em câmera.
7. Iluminação não linear
Iluminação desigual durante a digitalização pode fazer com que um lado de um documento pareça mais escuro. Este modelo ajusta o brilho com base em ângulos de luz simulados e curvatura da página, reproduzindo o efeito de iluminação pobre.
8. Ruído sal-e-pimenta
Adiciona pixels pretos e brancos aleatórios para simular poeira, textura de papel ou ruído sensor de digitalização. Este efeito "sal-e-pimenta" ajuda a criar a aparência granulada de digitalizações digitais envelhecidas ou de baixa qualidade.
Geração de documentos sintéticos como solução para desafios de análise de layout
O desafio da análise de layout
Entender a estrutura de documentos é mais difícil do que ler o texto. Ferramentas de OCR podem extrair palavras, mas não explicam o papel de cada bloco, como títulos, tabelas ou figuras.
Para lidar com esse desafio, métodos foram desenvolvidos:
Métodos iniciais para análise de layout eram baseados em regras. Eles dependiam de regras geométricas e análise de textura para dividir páginas em blocos. Embora úteis, essas abordagens exigiam ajuste manual pesado e não se generalizavam bem.
Abordagens de aprendizado de máquina como Máquinas de Vetor de Suporte (SVMs) e Modelos de Mistura Gaussiana (GMMs) melhoraram isso aprendendo com dados.9 No entanto, eles ainda dependiam de recursos criados manualmente e lutavam com a diversidade de documentos do mundo real.
Aprendizado profundo transformou o campo. Redes neurais convolucionais (CNNs) tornaram possível tratar o reconhecimento de layout como detecção de objetos, identificando tabelas, figuras ou fórmulas da mesma forma que os modelos detectam objetos em imagens naturais.10 Alguns modelos também combinam recursos de texto e imagem para resultados mais precisos.
O desafio do aprendizado profundo: requer grandes conjuntos de dados rotulados para treinar.
Dados sintéticos como solução: O processo de geração de documentos sintéticos oferece uma maneira escalável de criar dados de treinamento anotados sem o custo de rotulagem manual.
Modelos generativos agora trazem possibilidades mais avançadas. Autoencoders variacionais (VAEs), modelos baseados em atenção e GANs podem aprender padrões estruturais de documentos e produzir novos layouts realistas.11
Principais Diferenças Entre Geradores de Documentos Sintéticos
Os três geradores de documentos sintéticos benchmarkizados diferem em foco, qualidade de saída e usabilidade:
- Genalog: Mais equilibrado para layouts realistas e precisão numérica. Seu fluxo de trabalho baseado em Python com modelos HTML/CSS e modelos de degradação o torna ideal para treinar modelos de aprendizado de máquina em diversas tarefas de análise de documentos.
- DocCreator: Forte na geração de documentos visualmente complexos e degradados, preservando a diversidade de layout. Ligeiramente menos preciso numericamente que o Genalog, mas eficaz para tarefas que exigem simulação realista de documentos digitalizados.
- Tonic Textual: Se destaca em layouts limpos e visualmente consistentes e síntese de dados que preserva a privacidade. Menos adequado para precisão numérica ou conjuntos de dados de treinamento completos, tornando-o melhor para tarefas focadas em layout ou substituição de PII.
Essas diferenças refletem suas abordagens principais: Genalog equilibra realismo e fidelidade de dados, DocCreator enfatiza variedade de layout e degradação de documentos, e Tonic Textual prioriza aparência e privacidade. Isso ajuda os usuários a selecionar a ferramenta certa com base se a prioridade é eficácia de treinamento, realismo de layout ou desidentificação de dados.
Outros geradores de documentos sintéticos comumente usados
YData SDK: Oferece um Gerador de Documentos Sintéticos capaz de produzir documentos sintéticos de alta qualidade em formatos PDF, DOCX ou HTML, frequentemente usado para contornar obstáculos de conformidade de privacidade.12
DoGe: Uma ferramenta de código aberto projetada especificamente para sintetizar digitalizações de documentos realistas com texto significativo, títulos e tabelas para treinamento de Document IA.13
DocXPand: Especializado na geração de documentos de identidade (passaportes, carteiras de identidade) com base em padrões ISO, preenchendo modelos com informações falsas e rostos gerados por IA.14
Leituras Adicionais
- Benchmark e Melhores Práticas de Geração de Dados Sintéticos
- Top 25 Casos de Uso de Dados Sintéticos
- Usuários Sintéticos Explicados: Top 7 Ferramentas de Pesquisa de Usuários de IA
Cite este benchmark
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{Top 3 Geradores de Documentos Sintéticos Benchmarkizados}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Acessado em 18 Março 2026}
}



Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.