Best AI Web Scraping Tools: Bright Data, Oxylabs & Apify
Sites change their layout and the fields you need from a page shift over time. These changes break manually-coded scrapers. AI scrapers can be updated with simple prompts and are able to self heal to provide consistent results.
We benchmarked top AI web scraping tools across the top 10 e-commerce domains to see their performance, and also compared how each one leverages AI.
AI web scraping benchmark
Each vendor takes a different approach to AI, and our goal was to compare those approaches and the trade-offs they bring. See the benchmark methodology section for more details on the testing process.
Price and currency data was extracted from the top 10 e-commerce sites worldwide.
Key findings about AI web scraping tools from the benchmark
- Watch for hallucinations when reading prompt-to-JSON output. When a tool fails to extract a price, usually because the page hit an anti-bot wall, some vendors return 0 instead of signaling failure. The value looks legitimate, but the product is not actually free. Other times, numbers that do not appear anywhere on the page can show up in the response. Any downstream system that trusts these values without checks will silently store wrong data.
- A null is more trustworthy than a fabricated zero. For example, Apify and Bright Data both returned null on pages where they could not read a price, while some of the vendors put a 0 in the same situation. A null tells you the value is missing and can be retried or skipped; a 0 looks like a real answer and gets through validation unnoticed.
- Vendors often return more fields than you asked for. Even when the prompt requests only price and currency, the response can include brand, description, image URLs, or related products. For example, Bright Data lets you lock the output schema at build time, so extras can be prevented upfront. With vendors that go directly from prompt to JSON and offer no customization layer in between, even adding “only” to the prompt is not a guarantee.
- The wrong element can get pulled. When a page shows multiple numbers, such as discounted and original prices, with-tax and without-tax labels, or regional pricing toggles, the tool may grab the one you did not want.
- Numbers can drift in subtle ways. A traditional scraper API pulls the price straight from a fixed selector, so the value is exactly what the page shows. Prompt-to-JSON tools might add extra decimals, truncate values, or return currency-converted approximations that do not appear on the page.
- Locale changes the answer. Some sites serve different prices depending on the visitor’s geo-IP. A vendor running US proxies will see one number on a Nordstrom page while a European user sees another. If you need a specific market’s pricing, you cannot rely on whichever proxy region the tool defaults to.Vendors that let you adjust the output schema, proxy region, or other parameters give you a way to catch and correct most of the problems above before they reach your data.
AI web scraping tools comparison
Time to first scraper: For tools that build a scraper with its own schema, how long the setup takes. “Single HTTP call” means there is no build step at all.
Fixed output schema: Whether the JSON structure stays the same across calls because you define it upfront, rather than the LLM deciding it at runtime.
Beyond things like pages changing constantly, in agentic pipelines you often need a simple API you can call: give a URL, get structured data back. But you can’t always find a ready scraper API for every domain you need to scrape regularly; and when you do, the fields you want may not be there, or you need to customize the schema to your own needs. There are different approaches that address these problems.
Build-once, call-many AI web scraping platforms
If you build your own scraper, you have to write the crawler, wire up proxies, run headless browsers, and handle queues, retries and anti-bot on your own.
AI has moved into scraping to cut that manual work and make setup simpler. It’s involved in most of these tools, but each vendor uses it differently and answers a different set of needs.
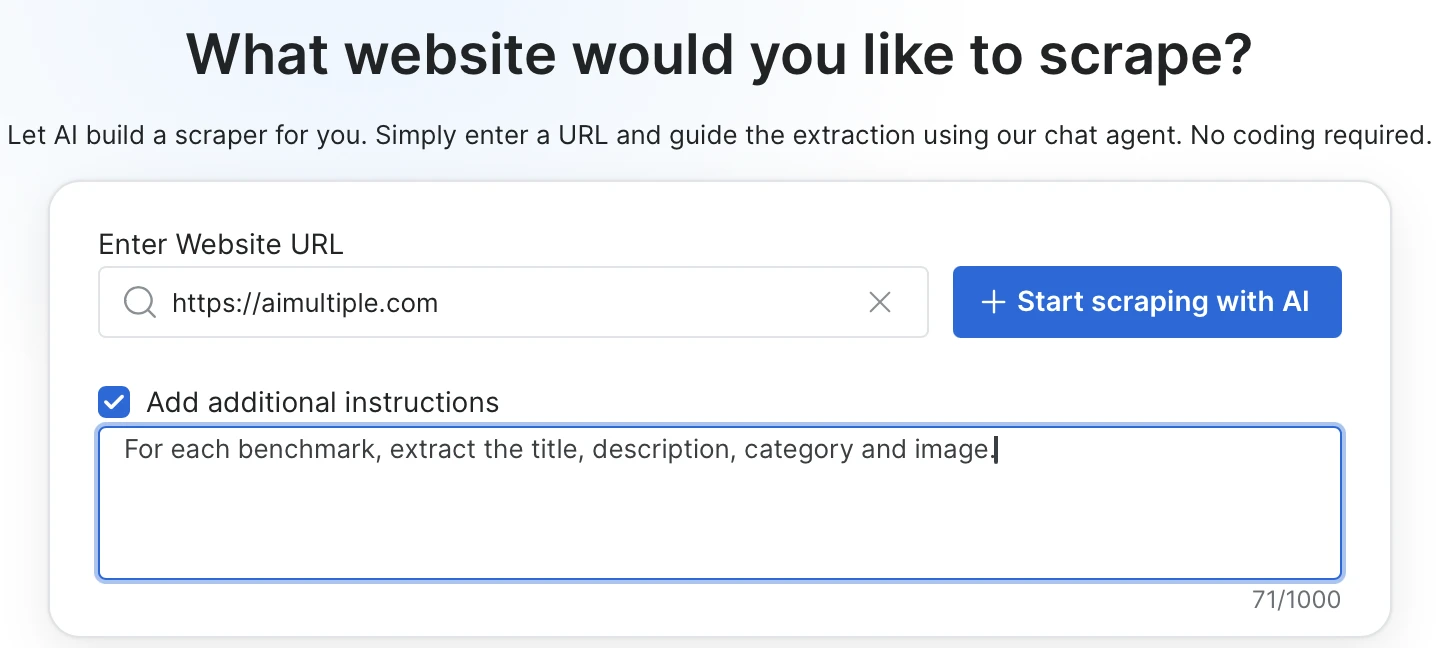
Bright Data Scraper Studio offers a two-phase approach where you build the scraper for any URL with a prompt and then call it as a stable API. You set it up once, and from then on you just pass in URLs.
You describe the fields you want to extract in plain language, and you can optionally add CSS selectors, required on-page actions, or page-load behavior.
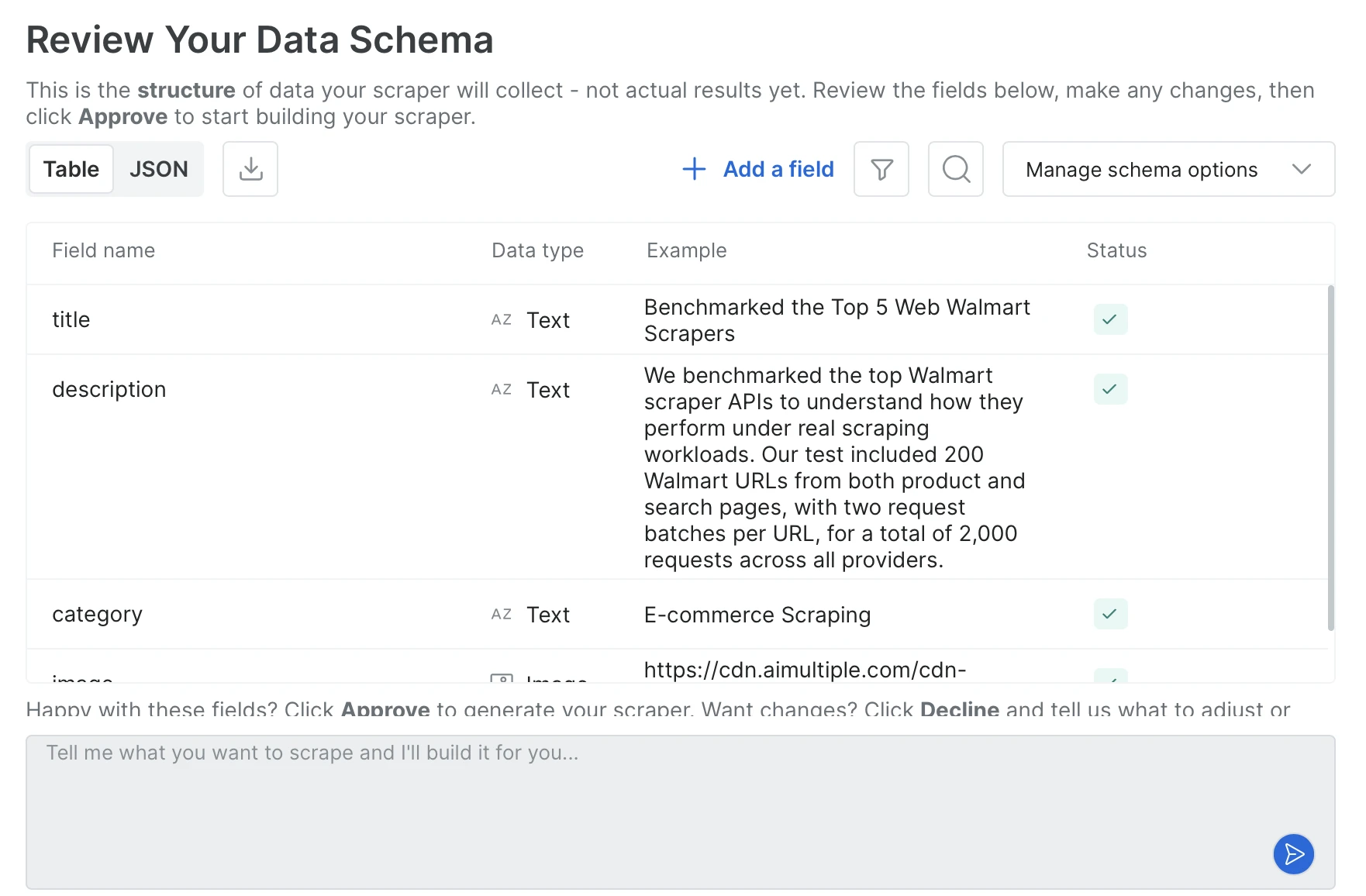
The agent generates the output schema from the prompt; you approve it by adding or removing fields or changing types, and then the scraper code is written.
- Fixed output schema: Once you approve the schema, the scraper is registered as a long-lived endpoint with a fixed identifier. Every call hits the same endpoint with just a URL, and the output schema stays the same across calls. In our tests, building a dedicated scraper took around 10 minutes on average.
- Two build methods: You can chat with the Agent in the browser, or use the Bright Data CLI to build the scraper from your terminal with a single command that takes a URL and a prompt. Both produce the same scraper.
- Coding-agent workflow: The terminal commands run unchanged inside Claude Code, Cursor and Codex, so the agent can build, run or self-heal a scraper without leaving the editor. You can also pin the scraper’s identifier in the agent’s rules file so future sessions reuse it.Results can be delivered through API, SDK, CLI, webhooks, or directly to cloud storage on S3, GCS, Azure, or OSS.
- Combined with pre-built scrapers: Bright Data maintains a library of ready scrapers for popular sites like Amazon, LinkedIn and Zillow.
- Self-Healing: When the site changes and the scraper breaks, you describe what broke in plain language; the AI produces a fix and shows it with sample output, and nothing goes live until you approve. Because the scraper’s identifier doesn’t change, every trigger, schedule and integration tied to it keeps working.
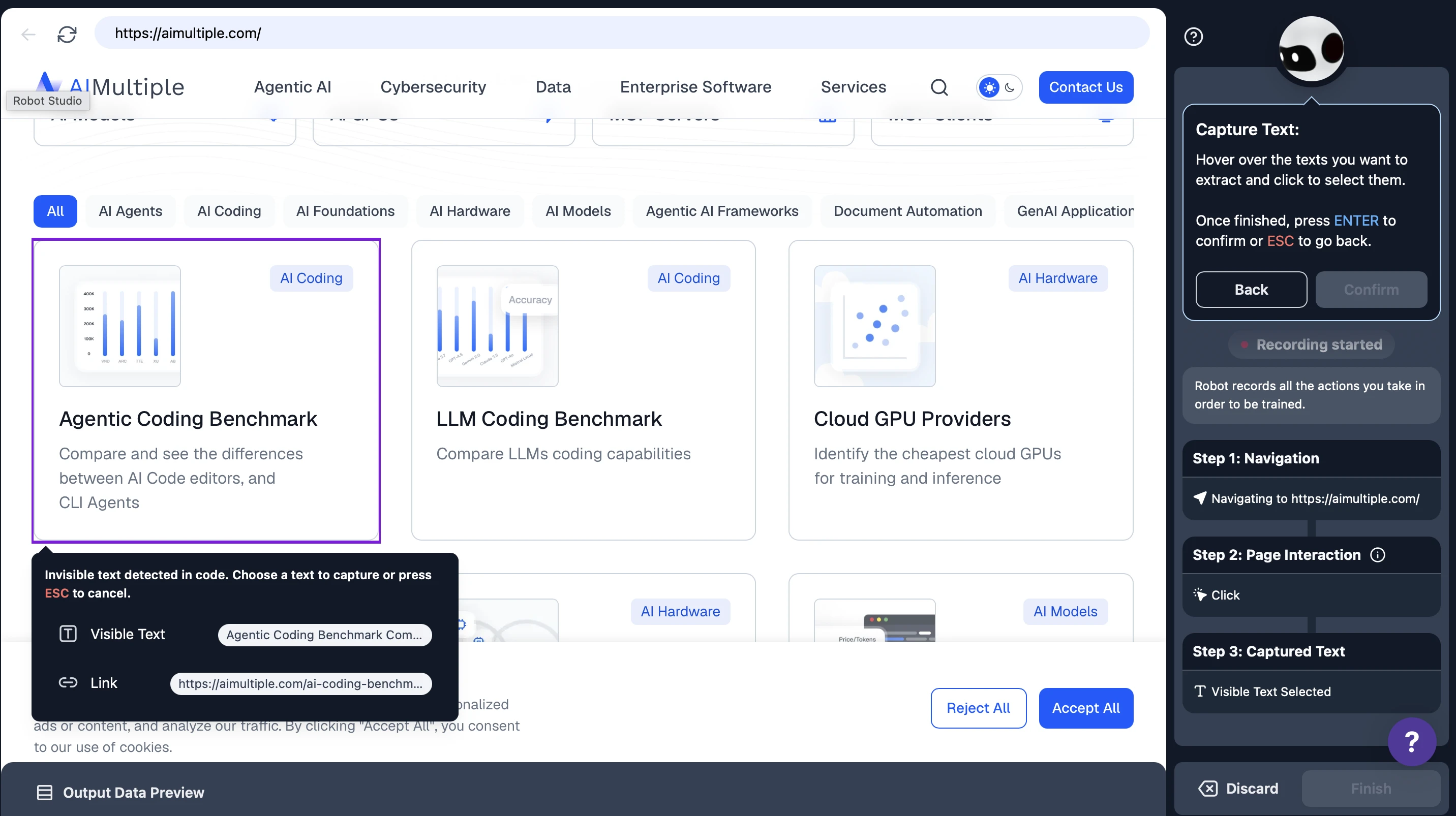
In Browse AI you still build the scraper yourself, but the setup is visual: you go to the target page and click to mark which fields should be captured, and the robot saves the navigation steps and the selected fields as a recording. That recording then runs over and over; when the page changes and the recording breaks, the robot is retrained.
- Visual setup with Robot Studio: Scrapers are built with a click → capture field → save flow.
- Built-in monitoring and alerting: Hourly, daily or weekly schedules + change detection + email/webhook alerts in the same product.
- Schema is formed from the captured fields: A separate capture step is added for each field; no prompt-to-schema.
- The AI layer sits in monitoring, not in build: It works on detecting page changes and adapting the robot; the build stage is recording-based.
One-shot AI extraction APIs
Oxylabs AI Studio is a suite of five separate AI applications under a single SDK (pip install oxylabs-ai-studio): AiScraper, AiCrawler, BrowserAgent, AiSearch, and AiMap. Nothing is persisted on the server side, every scrape call runs a fresh fetch plus LLM extraction.
- AiScraper flow: generate_schema(prompt=…) calls the LLM to produce a JSON schema, then scrape(url, schema) fetches the page and runs LLM extraction. You can keep and reuse the schema on your side, but the server does not register a long-lived scraper.
- Five applications, one SDK: AiScraper for single-URL structured extraction, AiCrawler for prompt-driven site traversal, BrowserAgent for on-page actions, AiSearch for natural-language search plus extraction, and AiMap for filtered URL maps of a site.
- Output formats: markdown (default), json, csv, toon (a token-optimized format), screenshot, and html (browser agent only).
- Notable parameters: render_javascript=”auto” lets the service decide whether JS rendering is needed, geo_location takes an ISO country code or name for proxy location, and max_credits sets a per-request spending cap.
Apify offers an open developer ecosystem where “Actors”, executable scraping and automation programs, are built and run on its platform. You can write your own Actor from scratch, start from a ready template, or use Actors that others have published in the Apify Store.
- AI extraction actor: Apify also has a ready-made apify/ai-web-scraper Actor that takes a natural-language prompt and returns structured JSON from any URL. You re-enter the prompt every run, and the JSON output is not guaranteed to stay consistent between calls, which is common behavior for prompt-driven tools.
- Build your own actor: If no ready scraper exists for your target site or none of them scrapes the data fields you want, you write your own Actor and decide which fields to extract, where they live on the page, and how to handle the rest. How long this takes depends on your coding skills and the complexity of the site. If you prefer not to build it on your own, you can also get help from Apify professional services.
- Combined with pre-built scrapers: A marketplace where developers publish their own Actors. Scrapers for popular sites are mostly published and maintained by third parties.
- Platform services: Actors come with scheduling, monitoring, dataset storage, proxy pool and API access out of the box.
- No coding-agent native flow: There’s no built-in workflow for Claude Code, Cursor or Codex to build or maintain Actors from inside the agent.
- Maintenance ownership: If you built the Actor yourself, you fix it when the site changes. If you’re using one from the Store, you wait for the Actor’s owner to ship the fix on their timeline.
Firecrawl turns a URL + prompt into JSON in a single synchronous call. Each request runs the full extraction pipeline at the moment the call is made, with the LLM reading the page and producing the JSON output on the fly.
- Prompt or schema: You can either pass a natural-language prompt or a JSON schema to shape the output.
- Runtime execution model: The extraction happens at request time on every call, so the output reflects the page as it looks at that moment and is shaped by the LLM each run.
- Stateless operation: Firecrawl does not store a scraper or schema definition between calls. Each request stands on its own, with the LLM and the live page determining the result.
- Agent: Firecrawl also offers an Agent product where the URL is optional. You describe what you want and the agent navigates the web to find it.
ScrapingBee uses the same single-call, stateless model as Firecrawl. The difference is in how you describe what you want.
- Three extraction modes: ai_query for a single field in natural language (returns a string), ai_extract_rules for a JSON schema where each field has its own description, and an advanced form of the same with types, enums, and nested output.
- ai_selector: Pass a CSS selector to focus the LLM on a specific part of the page. Faster and more accurate than letting it read the full DOM.
- Classic scraping in the same call: render_js for JS-heavy sites, screenshot, extract_rules for CSS/XPath extraction without AI, and json_response to get HTML, cookies, XHRs, and iframes in one envelope.
AI web scraping tools pricing
1 credit does not always mean 1 page across vendors. For example, Firecrawl charges 5 credits per AI-extracted page (1 base + 4 for JSON), while ScrapingBee charges 6 or more depending on JS rendering and proxy options. Check each vendor’s pricing page for the actual per-page cost.
How to choose right tool for your pipeline?
In practice, the right tool depends less on feature lists and more on what your pipeline does with the data over time. A few patterns are worth keeping in mind:
One-off or occasional scraping
If you just need data from a URL once and you’re fine describing it each time, one-shot AI extraction APIs are the fastest path. No scraper to build, no schema to register.
Repeated scraping in a pipeline
If you’re running the same scraper over and over and need a stable endpoint that returns the same schema every time, or if you need to customize the data fields for the URLs you want, a build-once, call-many platform fits better. Your pipeline just passes URLs in and the output shape stays predictable.
How long it takes to get there
Build time varies by approach. Writing a scraper or actor from scratch typically takes days to weeks, since the crawler, proxy wiring and retries are on you. Prompt-based platforms generate the schema and code in minutes. Recording-based tools also land in minutes, with point-and-click setup instead of a prompt. One-shot AI extraction APIs skip the build step; the first response comes back in a single HTTP call.
Site already covered by a ready scraper
Using a ready scraper for popular sites is usually faster than building your own, but who keeps it working depends on where it comes from. A vendor-maintained library is updated by the vendor when the site changes.
Site not covered by anything ready
Then the question becomes who fixes things when layouts shift. Building your own means the maintenance is on you. A recording-based tool means re-training the robot when things break. AI self-healing on code you own sits in between: the fix is proposed on your existing code, and you approve it before it goes live.
Building with coding agents
If your workflow runs through Claude Code, Cursor or Codex, it matters whether the tool exposes a CLI or MCP integration the agent can drive end to end, or whether the agent can only call a plain HTTP API.
AI web scraping benchmark methodology
To build the dataset, we selected the top 10 fashion and apparel sites worldwide from Semrush. For each site, a single product page was chosen, and the ground truth (price and currency) was recorded manually by visiting the page directly.
Five AI scraping tools were tested: Firecrawl’s Scrape API, Bright Data’s Scraper Studio, ScrapingBee’s AI Extract, Apify’s AI Web Scraper actor, and Oxylabs AI Studio’s AI Scraper. Each vendor received the same single-sentence prompt: “Extract price and the currency of the product and return json.”
Each URL was sent once to each vendor. There were no retries, fallbacks, schema enforcement, or post-processing steps. The raw response was stored as-is, exactly as the vendor returned it.
For validation, the raw JSON output was scanned with a regular expression for the expected price and currency. Price matching tolerates common formatting variations such as 26.49 and 26,49, 2,140 and 2140, and small decimal-precision differences. Currency matching accepts either the ISO code (USD) or the symbol ($).
Two metrics were tracked. Success rate is calculated per URL as a binary check for whether the price was correctly returned and another for the currency; the two are then averaged together to produce a single success score for each URL, and the scores are averaged across all ten URLs for each vendor. End-to-end completion time is the wall-clock duration from request to response, averaged across the ten URLs. For Bright Data, the one-time collector build is excluded.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{ipi2026,
author = {Şipi, Nazlı},
title = {{Best AI Web Scraping Tools: Bright Data, Oxylabs & Apify}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraper}},
note = {AIMultiple. Acessado em 23 Junho 2026}
}
Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.